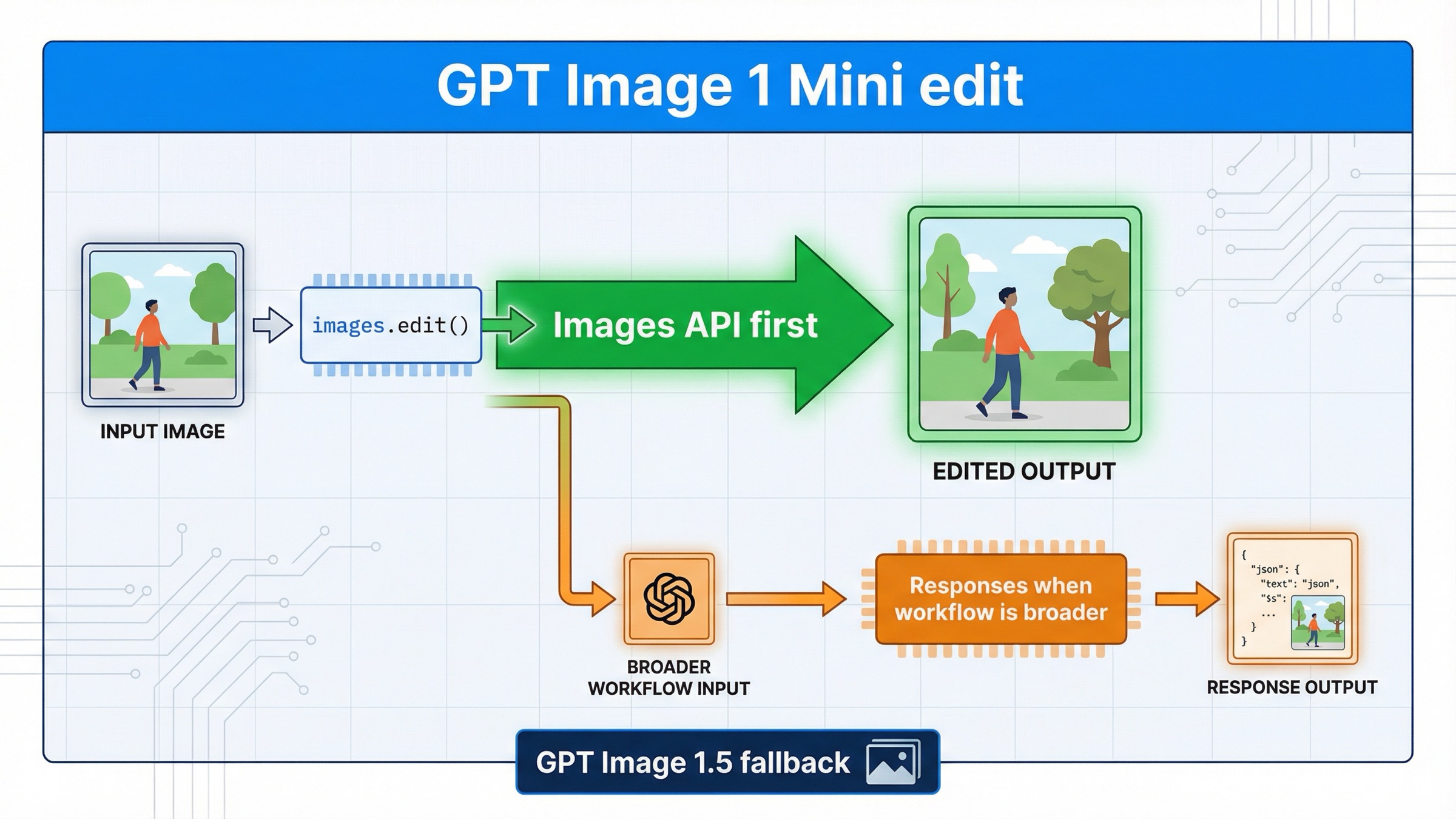
2026年3月29日時点で gpt-image-1-mini を使って画像編集をしたいなら、最も安全な初手は Responses ではなく、OpenAI Images API の直ルートです。SDK なら client.images.edit()、raw HTTP なら POST /v1/images/edits を先に使ってください。 Responses を先に検討すべきなのは、「画像を編集すること」自体が要件の中心ではなく、assistant・conversation・multi-tool workflow の一部として編集が入るケースです。
この結論をわざわざ分けて書く価値があるのは、現在の検索結果と公式ドキュメントが答えを複数ページに分散しているからです。現在の gpt-image-1-mini model page には v1/images/edits が明記されています。現行の image generation guide では、1つの prompt で1回の生成または編集をしたいなら Image API が最適だと説明されています。一方、現在の image generation tool guide で Responses 側の action がはっきり説明されているのは、主に gpt-image-1.5 と chatgpt-image-latest です。これらを合わせて読むと、平均的なページよりずっと実務的なルールが見えてきます。mini の direct edit は、まず /v1/images/edits から始めるべきです。
このルートは実装上も得です。Responses の例を先に見て、「新しそうで広い抽象だから、こちらのほうが正しいはずだ」と判断してしまう開発者は少なくありません。しかし gpt-image-1-mini の edit では、その直感が逆に回りやすいです。直ルートのほうが docs と整合しやすく、デバッグの範囲も狭く、mini 固有の限界も見失いません。
要点まとめ
- タスクが「この画像を編集したい」なら、まず
client.images.edit()またはPOST /v1/images/edits。 - 編集がより大きな assistant / multimodal workflow の一部なら Responses を検討。
- 複数画像の保持や品質の上振れが必要なら、早めに GPT Image 1.5 も比較する。
- コードを書き換える前に、課金 tier、組織 verification、project と API key の帰属を確認する。
| 状況 | まず選ぶべきルート | 理由 |
|---|---|---|
| 1枚または数枚の画像を編集して保存したい | images.edit() | mini で最も明確に文書化されている直ルートだから |
| mask や reference image を含む edit をしたい | images.edit() | ファイル入力、mask、出力処理が分かりやすい |
| 画像編集が長い会話や multi-tool workflow の一部 | Responses | 本当に必要なのは編集そのものより外側の orchestration |
| 複数 input を強く保持したい、ブランド素材を崩したくない | GPT Image 1.5 + images.edit() | OpenAI 自身が 1.5 を quality-first の分岐として示している |
direct な mini 編集なら、まず /v1/images/edits
この exact query で最も価値があるのは、複雑な API 世界観ではなく、最初の成功パターンを小さく保つことです。公式 docs はここで迷わせていません。mini のモデルページは v1/images/edits を挙げており、image guide も「1つの prompt で1回の生成または編集をするなら Image API がよい」と言っています。これは "gpt-image-1-mini edit" の大半の実務にそのまま当てはまります。
だから最初の成功目標は、意図的に地味であるべきです。
jsimport fs from "fs"; import OpenAI from "openai"; const client = new OpenAI({ apiKey: process.env.OPENAI_API_KEY, }); const result = await client.images.edit({ model: "gpt-image-1-mini", image: [fs.createReadStream("room.png")], prompt: "Replace the blank wall art with a framed abstract poster. Preserve the room layout, lighting, furniture, and camera angle. Do not change anything else.", input_fidelity: "high", size: "1024x1024", quality: "medium", output_format: "jpeg", output_compression: 80, }); const imageBase64 = result.data[0].b64_json; fs.writeFileSync("room-edited.jpg", Buffer.from(imageBase64, "base64"));
raw HTTP で確認するときは、ここが multipart form-data であり JSON ではないことも忘れないでください。
bashcurl https://api.openai.com/v1/images/edits \ -H "Authorization: Bearer $OPENAI_API_KEY" \ -F "model=gpt-image-1-mini" \ -F "image[]=@room.png" \ -F 'prompt=Replace the blank wall art with a framed abstract poster. Preserve the room layout, lighting, furniture, and camera angle. Do not change anything else.' \ -F "input_fidelity=high" \ -F "size=1024x1024" \ -F "quality=medium"
この直ルートを最初に置くべき理由は3つあります。
1つ目は、モデル選択と API surface がきれいに揃うことです。mini が現在明示的にサポートしている endpoint を呼ぶので、より大きな orchestration layer に判断を委ねずに済みます。
2つ目は、デバッグの切り分けが簡単になることです。失敗した場合も、主に access、ファイル形式、prompt の書き方、出力処理のどこかを優先的に疑えばよく、Responses 側の model や tool config、conversation state まで一度に抱え込まずに済みます。
3つ目は、このページの役割がぶれないことです。より広い family-level の解説はすでに OpenAI image editing API ガイド にあります。このページはそこから一段狭く、**「mini で edit するなら最初に何をすべきか」**だけをはっきりさせるのが役目です。
Responses が本当に役立つ場面と、mini では境界線がより重要な理由
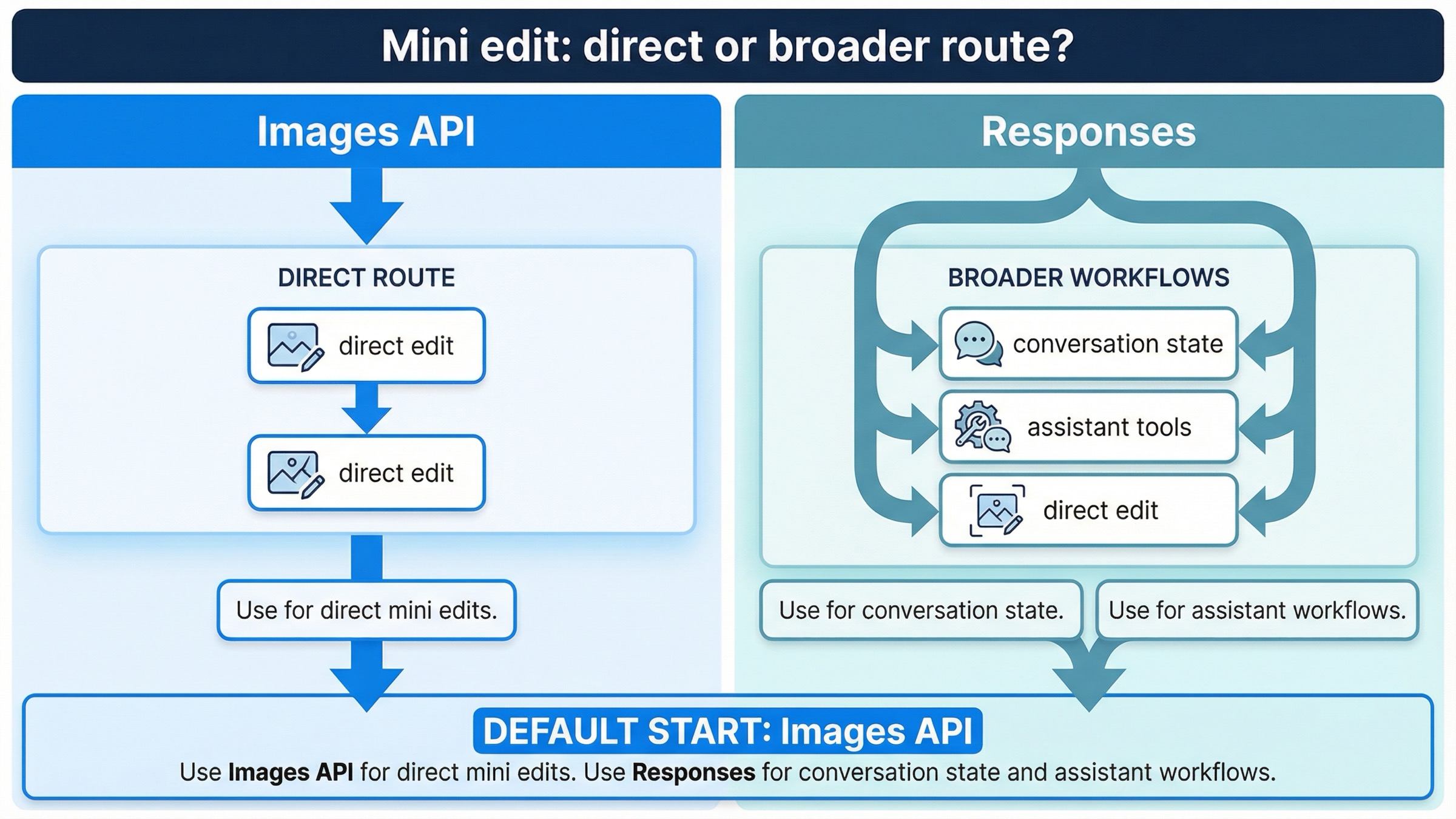
Responses は便利です。ただし、「gpt-image-1-mini で画像を編集したい」という要件そのものが主題なら、普通は最初の答えではありません。
その理由は、現在の image generation tool guide を読むとよく分かります。Responses では top-level model は gpt-4.1 や gpt-5 のようなテキストモデルである必要があり、GPT Image 系は top-level model ではなく tool 側で動きます。つまり Responses を選ぶ時点で、あなたは「mini の編集 endpoint」よりも、より大きい workflow abstraction を選んでいるわけです。
この違いは mini では特に大事です。というのも、現時点の docs で Responses 側の action が明示的に書かれているのは主に gpt-image-1.5 と chatgpt-image-latest であり、mini を一番はっきりした Responses edit contract として前面に出してはいません。ここでの推論は狭く、かつ実務的です。mini edit を確実に、文書に沿って、デバッグしやすく始めたいなら direct Images API のほうが契約面が明快です。
Responses が向いているのは、たとえば次のようなケースです。
- previous response IDs や image generation call IDs を使った多段の画像編集
- reasoning、tools、image edits が混ざる assistant
- 画像編集が長い会話の中で進む UX
- 1つの request の中で tool を使い分ける必要がある場合
覚えておくべきルールはシンプルです。
- 「画像編集そのものが機能」:
images.edit()から始める - 「画像編集はより大きな機能の1つの tool」: Responses を検討する
もし本当に知りたいのが mini の全体ルートなら、次に読むべきは gpt-image-1-mini API ガイド です。このページは intentional に scope を絞っています。
mini における mask、reference image、input_fidelity
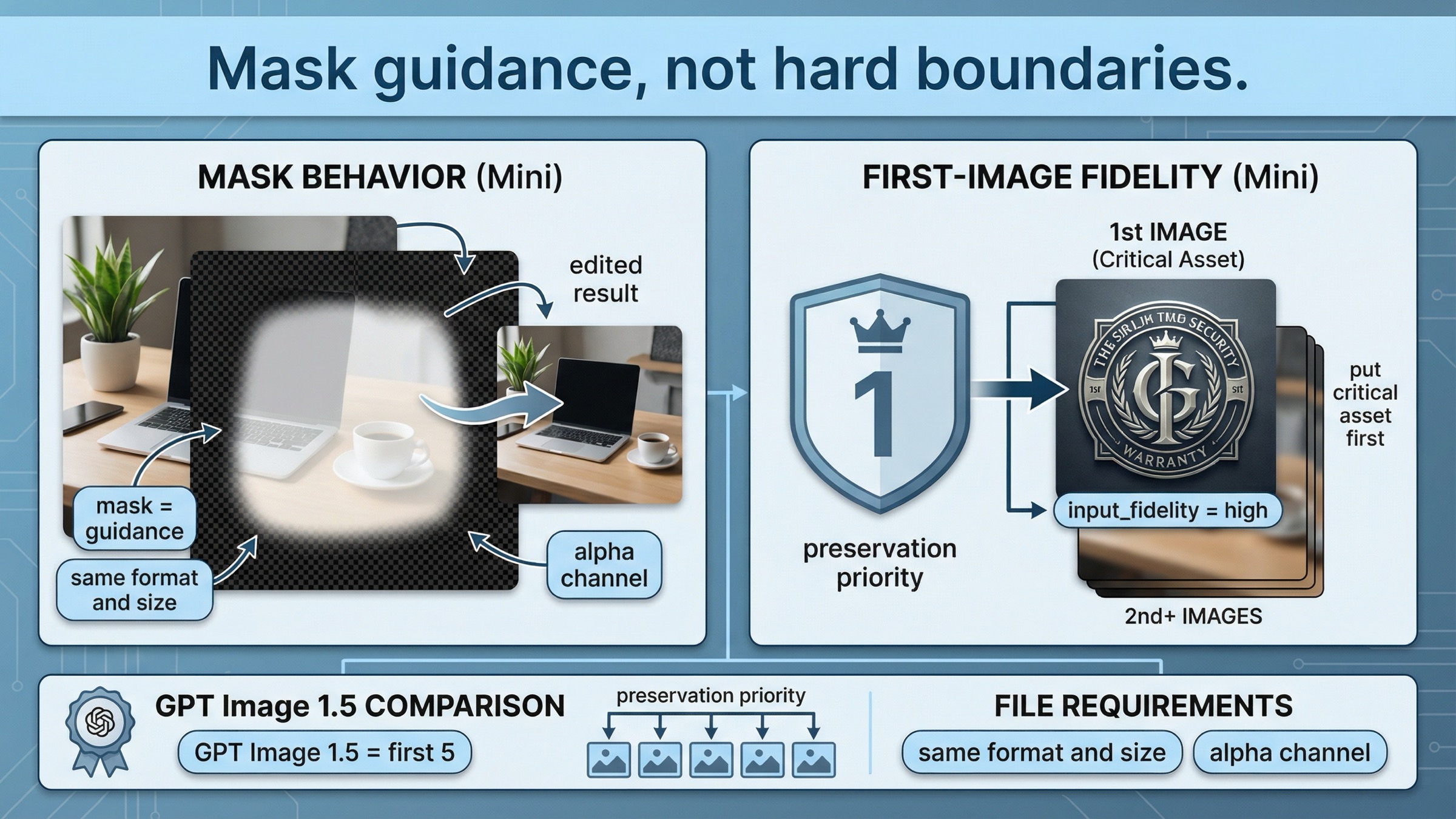
ここはこのページの中でも特に価値が高い部分です。多くのページが見落としている mini 固有の edit 挙動がここに集まっています。
現在の image generation guide の edit セクション では、画像と mask は 同じフォーマット・同じサイズ でなければならず、合計サイズは 50 MB 未満、mask には alpha channel が必要だと説明されています。ただし本当に重要なのは、GPT Image の mask editing が今も prompt-based だという点です。つまり mask は編集を導くヒントですが、Photoshop のようなピクセル単位の硬い制約ではありません。
だから mini で mask を使うときは、mask を 強いガイド と考えるべきであって、「ここだけを絶対に変えて、他は一切触らない」という保証だと考えるべきではありません。
もう1つ重要なのが、現在の input_fidelity ドキュメント にある mini-specific な挙動です。OpenAI は、gpt-image-1 または gpt-image-1-mini に高い input fidelity を指定した場合、最初の入力画像がより強くテクスチャや細部を保持すると説明しています。顔、ロゴ、商品、パッケージなど絶対に崩したくない visual anchor があるなら、それを 1番目の input に置くべきです。GPT Image 1.5 が強いのは、この preservation が最初の 5枚 まで広いことです。
これは単なる実装メモではありません。edit request の組み立て方そのものを変えるルールです。
mini が使いやすいのは次のような仕事です。
- 1枚の主画像と小さな reference image
- 1つの顔や1つのロゴが明確に最優先の preservation target である場合
- 1シーンに対して主な変更点が1つだけある場合
- 社内向けの mockup や creative variant のような低〜中程度のリスクの編集
逆に、次のような仕事では早めに慎重になるべきです。
- 複数の reference image が同じくらい重要
- 複数のブランド要素を同時に壊さず保持したい
- typography や layout のズレにほとんど余裕がない
- 失敗1回の手戻りコストが高い商用素材
実装パターン自体はシンプルです。
jsconst result = await client.images.edit({ model: "gpt-image-1-mini", image: [ fs.createReadStream("base-scene.jpg"), fs.createReadStream("logo.png"), ], prompt: "Place the logo from image 2 onto the tote bag in image 1. Preserve the model, pose, bag shape, camera framing, and lighting.", input_fidelity: "high", });
大事なのはコードの形ではなく、入力順序です。mini では1枚目が最も強い preservation slot です。
先に価格・制限・verification を確認し、その後でコードを疑う
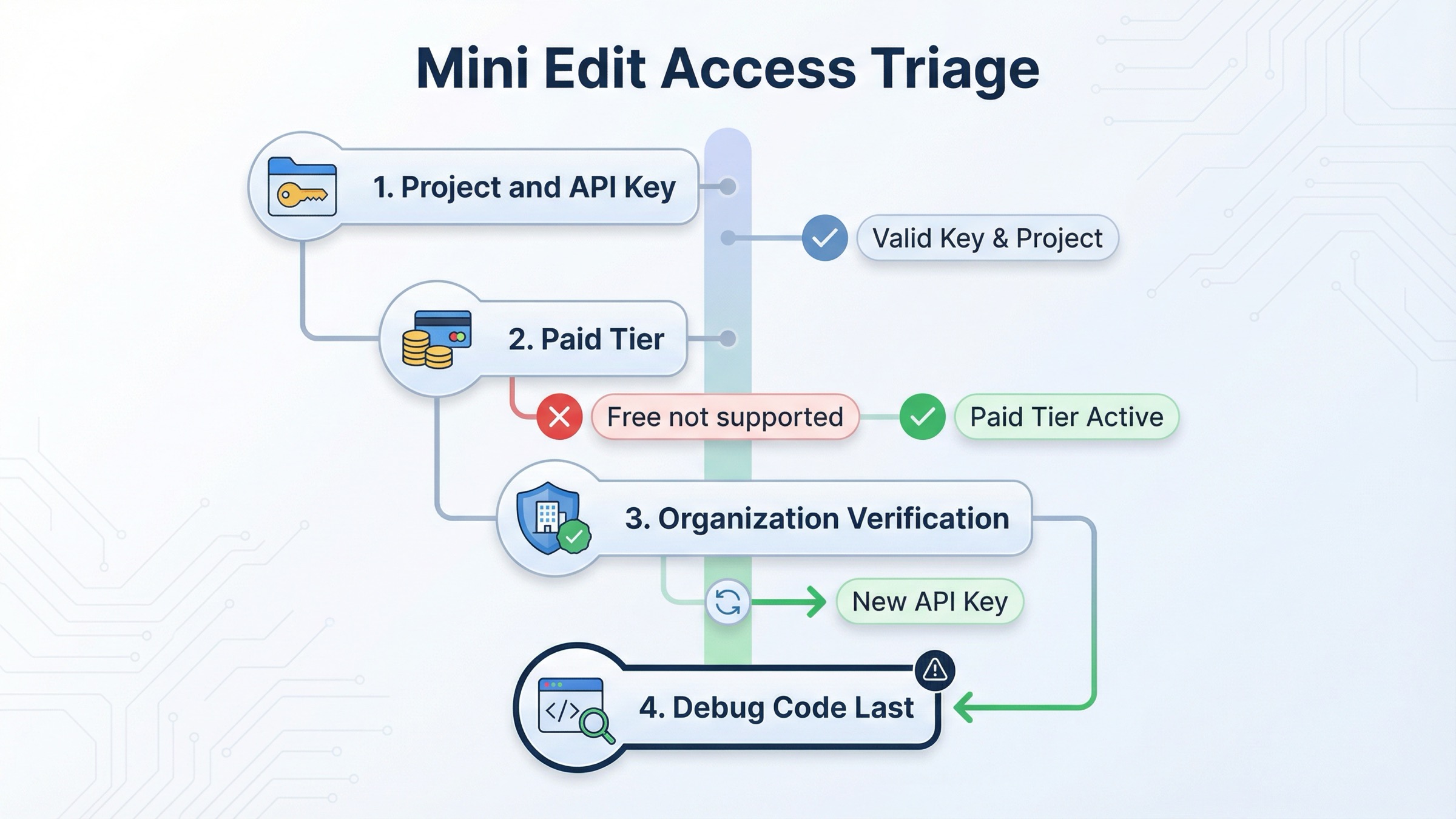
exact-match の記事が読者の時間を無駄にしやすいのはここです。sample code を先に並べる一方で、「そもそも account state が整っていないかもしれない」という話を後回しにしがちです。
2026年3月29日時点の gpt-image-1-mini model page では、1024x1024 の価格は low $0.005、medium $0.011、high $0.036 のままです。同じページには Free not supported とあり、Tier 1 の開始点として 100,000 TPM と 5 IPM も示されています。
現在の model availability article は、GPT-image-1 と GPT-image-1-mini が tier 1 から 5 の API ユーザーに提供されている一方で、一部の access は organization verification に左右されると説明しています。現在の organization verification article では、verification の反映に 最大30分 かかることや、検証済みなのに “not verified” が残る場合は 新しい API key の発行で解決することがある、とも書かれています。
だから正しい troubleshooting order は次の通りです。
- API key が正しい project / organization に紐づいているか確認する
- mini の image access を使える paid tier にいるか確認する
- まだ access 問題らしいなら organization verification を確認する
- 反映待ちの30分をしっかり待つ
- 組織が verified でも症状が残るなら API key を作り直す
- ここまで確認してからコードを書き換える
これは重要です。direct mini edit request は、コードが正しくても account state が整っていなければ失敗します。もし根本原因が権限や verification にあるなら、prompt を改善しても、Responses に全面移行しても直りません。
もし本当のボトルネックが edit logic ではなく access なら、次に読むべきは OpenAI image generation API verification guide です。コスト計算が主題なら GPT Image 1 Mini pricing のほうが役立ちます。
exact query のページが見落としやすいトラブルシュート
1つ目の典型的な失敗は、最初から間違った API surface に乗ることです。タスクが1回の direct edit なら、「Responses の例をよく見るから」という理由だけで大きい抽象に飛ばないほうがいいです。
2つ目は、Responses の model mental model を取り違えることです。GPT Image 系は top-level model ではなく、画像処理は tool 側で動きます。Responses に移るなら、その時点で route の意味が変わっています。
3つ目は、mask を hard-boundary pixel control だと思い込むことです。GPT Image の mask editing は prompt-driven であり、完全な輪郭固定を保証しません。極小の局所修正が必須なら、その前提を早めに検証すべきです。
4つ目は、最重要 asset を最初の input に置かないことです。顔、ロゴ、主役商品が1番目でないなら、mini が持つ最も強い preservation slot を自分で手放していることになります。
5つ目は、access を確認する前に prompt をいじり続けることです。tier、verification、project context がずれているなら、より長い prompt は解決策になりません。
6つ目は、1つの安い edit request に多すぎることを要求することです。現在の limitations にもある通り、複雑な prompt は 最大2分 かかることがあり、精密なテキスト配置や複数参照の一貫性、構図制御ではまだ壁があります。ブランド lockup、文字精度、複数 input の保持が同時に必要なら、route よりも model choice を疑うべきです。
より実務的な順序は次の通りです。
- まず最小の direct edit を1回試す
- いちばん大事な input を1番目に置く
- 保持が本当に必要なときだけ
input_fidelity="high"を付ける - 複雑な変更を1回で押し切らず、近い結果なら2段階の edit に分ける
この順序のほうが、prompt をさらに長くするより時間を節約することが多いです。
mini edit で十分な場面と、GPT Image 1.5 に上げたほうが安全な場面

このキーワードの本当の判断は、「mini か Responses か」ではなく、「mini で十分か、それとも 1.5 に上げるべきか」です。
現在の model comparison section で OpenAI は、gpt-image-1.5 が全体として最良の品質体験であり、gpt-image-1-mini は品質より cost を優先したい場合の選択肢だと説明しています。これを edit-workflow に翻訳すると、次のようになります。
mini で十分なことが多いのは、
- 社内向けの creative variation
- 低リスクな ecommerce mockup や room edit
- 1枚の主画像が中心の product edit
- まず安い benchmark を回してから quality lane に上げるか判断したい場合
- コストのほうが最大品質より重要な workflow
GPT Image 1.5 のほうが安全なのは、
- 複数の重要な reference image を1回で扱うとき
- ブランド要素の preservation がより厳しいとき
- typography や layout に厳密さが求められるとき
- 失敗の手戻りコストが高い marketing asset を扱うとき
- 現時点の OpenAI 画像編集で最も安全な default quality lane を取りたいとき
だから正直な recommendation は「mini vs Responses」ではありません。mini-specific edit は direct Images API から始める。そこで mini の限界が見えたら、route をいじり続けるのではなく GPT Image 1.5 に上げる。
mini の全体的なコスト対品質の評価を見たいなら GPT Image 1 Mini review が次の読み物です。OpenAI image family 全体のルートを見たいなら OpenAI Image API tutorial に進んでください。1.5 のコスト観点まで踏み込みたいなら GPT Image 1.5 pricing API が適切です。
FAQ
gpt-image-1-mini は今、直接画像編集できますか。
はい。現在の gpt-image-1-mini model page には v1/images/edits が明記されているので、direct Images API は mini edit の有効な current route です。
1回だけ編集したい場合でも、なぜ最初から Responses を使わないのですか。
current image guide が、1つの prompt で1回の image job を行うなら Image API が最適だと述べているからです。Responses は、より大きな会話や tool workflow が必要な場面で価値を持ちます。
mask を使えば、masked area だけを正確に変更できますか。
いいえ。現在の docs は、GPT Image masking を prompt-based と説明しています。mask は編集を導きますが、厳密なピクセル境界を保証するものではありません。
どの時点で mini から GPT Image 1.5 に切り替えるべきですか。
複数画像の保持、ブランド要素の安定性、layout-sensitive asset、あるいは quality-first default が必要になった時点で、早めに GPT Image 1.5 を benchmark するべきです。
最後のおすすめ
2026年3月29日時点で、gpt-image-1-mini で画像を編集したいなら、まず images.edit() または POST /v1/images/edits から始めてください。 それが現在の docs で最も明確で、最もデバッグしやすく、mini 固有の挙動を見失いにくいルートです。
Responses に進むのは、画像編集が assistant / multimodal workflow の一部として本当に必要なときだけです。そしてもう1つの判断は別にしてください。mini が足りないなら、route の最適化に時間を使いすぎず、GPT Image 1.5 を benchmark するべきです。