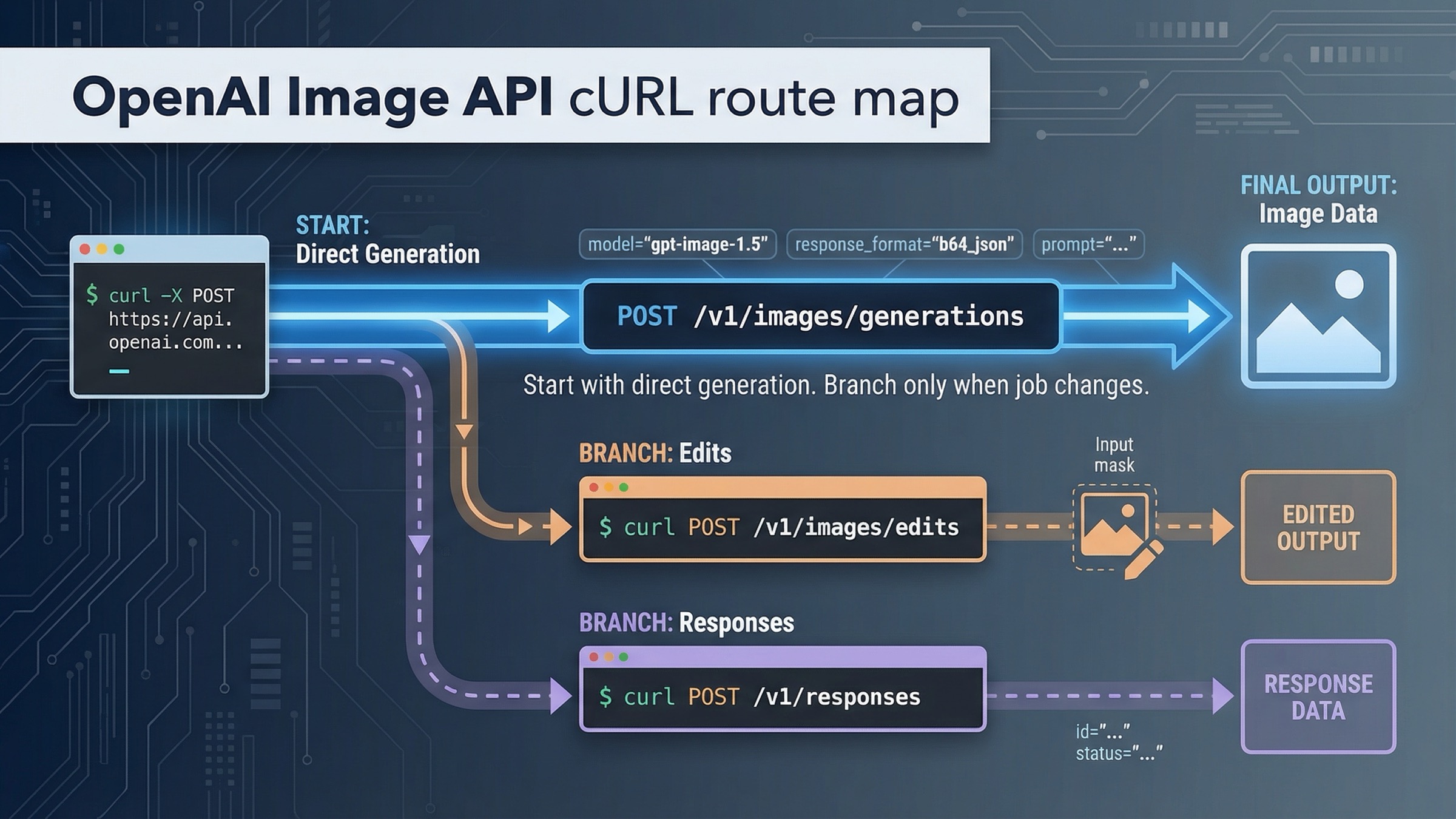
Si quieres una petición OpenAI image generation API cURL que hoy siga siendo fiable, empieza por POST /v1/images/generations, guarda la respuesta JSON y decodifica .data[0].b64_json. Ese sigue siendo el camino más corto y más seguro para una generación directa desde terminal o backend.
Solo hay dos situaciones que deberían cambiar esa ruta por defecto. Si ya tienes imágenes de entrada y vas a modificarlas, cambia a POST /v1/images/edits con multipart. Si la generación de imagen es solo una herramienta dentro de un workflow multimodal más grande, cambia a POST /v1/responses con el tool image_generation. Todo lo demás suele ser complejidad prematura.
Este keyword sigue siendo más caótico de lo que debería porque OpenAI reparte la respuesta entre varias páginas. El image generation guide explica la ruta general y muchos parámetros. La referencia de Images API fija el contrato crudo. El tool guide de image_generation cubre la rama de Responses. Y, a 24 de marzo de 2026, la guía todavía mostraba un snippet GPT Image contra https://api.openai.com/v1/images, mientras que la referencia seguía nombrando /images/generations y /images/edits. Esta guía está hecha para cerrar esa brecha desde el punto de vista de curl.
Resumen rápido
- Empieza con
POST /v1/images/generationsygpt-image-1.5. - Los modelos GPT de imagen devuelven
b64_jsonpor defecto, no una URL alojada. - Pasa a
POST /v1/images/editssolo cuando ya tienes imágenes de entrada. - Pasa a
POST /v1/responsessolo cuando la imagen sea una herramienta dentro de un workflow mayor.
Empieza con POST /v1/images/generations para una salida directa

Si el trabajo real es "mandar un prompt desde terminal y recibir una imagen", Images API sigue siendo la mejor ruta inicial. La referencia de Images API documenta POST /images/generations como endpoint bruto, así que la URL completa es https://api.openai.com/v1/images/generations.
Ese es el punto de partida correcto porque reduce el primer bucle de éxito a lo esencial:
- enviar JSON
- recibir JSON
- extraer base64
- guardar una imagen
Además, encaja con la línea actual de modelos. La página oficial All models lista GPT Image 1.5 como el modelo de imagen actual de referencia, junto con chatgpt-image-latest, gpt-image-1 y gpt-image-1-mini. Eso significa que, para un ejemplo nuevo en cURL, la base correcta es gpt-image-1.5, no GPT Image 1 ni restos de la era DALL-E.
Usa primero esto:
bashcurl https://api.openai.com/v1/images/generations \ -H "Authorization: Bearer $OPENAI_API_KEY" \ -H "Content-Type: application/json" \ -d '{ "model": "gpt-image-1.5", "prompt": "Create a clean editorial illustration of a robot camera operator in a bright studio", "size": "1024x1024", "quality": "medium" }' > response.json
La clave es que la primera petición sea deliberadamente simple. La guía oficial sigue diciendo que las imágenes cuadradas suelen ser las más rápidas y que 1024x1024 es el tamaño por defecto. El primer intento no es el lugar para probar transparencia, streaming, compresión, orientación horizontal y edits complejos al mismo tiempo. Solo debe demostrar cinco cosas: que la cuenta tiene acceso, que el endpoint es correcto, que el body tiene forma válida, que el modelo existe y que puedes convertir la respuesta en un archivo útil.
La tabla siguiente resume la decisión que más importa:
| Situación | Mejor ruta cruda | Cómo usar model | Por qué esta es la ruta inicial |
|---|---|---|---|
| Texto a imagen en una sola petición | POST /v1/images/generations | gpt-image-1.5 | Es la ruta más corta y más fácil de depurar |
| Edición sobre imágenes ya existentes | POST /v1/images/edits | gpt-image-1.5 | Sigue siendo Images API, pero con multipart |
| Generación de imagen dentro de un workflow multimodal | POST /v1/responses | Un modelo principal como gpt-5 | Solo aquí tiene sentido la capa de tool orchestration |
Eso parece simple porque en realidad sí lo es cuando separas bien las superficies. El problema de muchas páginas que rankean es que meten generación, edits y Responses en el mismo saco y el lector termina sin saber cuál debería ser la primera llamada.
Si tu siguiente duda es el modelo más adecuado según calidad o coste, la guía que continúa mejor este punto es OpenAI image generation API models.
Qué devuelve realmente la respuesta y cómo decodificarla sin romper el flujo

El mayor problema específico de cURL no suele ser el POST, sino lo que viene después.
La referencia de Images API deja clara una pieza crítica: el objeto Image contiene b64_json, revised_prompt y url, y para los modelos GPT de imagen el valor por defecto es b64_json, mientras que la salida por URL no es la ruta por defecto. Por eso una buena guía de cURL tiene que resolver también el paso de guardado.
La costumbre más segura es guardar primero la respuesta:
bashcurl https://api.openai.com/v1/images/generations \ -H "Authorization: Bearer $OPENAI_API_KEY" \ -H "Content-Type: application/json" \ -d '{ "model": "gpt-image-1.5", "prompt": "Create a clean editorial illustration of a robot camera operator in a bright studio", "size": "1024x1024", "quality": "medium" }' > response.json jq '.data[0] | {has_b64_json: has("b64_json"), revised_prompt, url}' response.json
Ese paso intermedio ahorra tiempo porque te deja inspeccionar el shape real antes de encadenar pipes. Si la petición devuelve 200 pero el archivo final sale corrupto o vacío, normalmente el fallo está en la decodificación, no en el endpoint.
En Linux o cualquier entorno con GNU base64, lo normal es que esto funcione:
bashjq -r '.data[0].b64_json' response.json | base64 --decode > openai-image.png
En macOS, la bandera suele ser -D:
bashjq -r '.data[0].b64_json' response.json | base64 -D > openai-image.png
Si quieres evitar del todo la diferencia entre BSD y GNU, la opción más estable es usar Python para la decodificación:
bashjq -r '.data[0].b64_json' response.json \ | python -c 'import sys, base64; sys.stdout.buffer.write(base64.b64decode(sys.stdin.read()))' \ > openai-image.png
Ese detalle ya mejora la media del SERP. Muchas páginas muestran el request, pero no cierran el último tramo del workflow. O bien asumen que la respuesta trae una URL, o bien usan un pipe que solo funciona en el sistema del autor.
Aquí también aparece la contradicción entre guía y referencia. La guía sigue mostrando un ejemplo GPT Image contra /v1/images, mientras que la referencia fija /images/generations como contrato crudo. Para una página centrada en curl, la recomendación más segura es tomar la referencia como base para nombres de endpoint y usar la guía para el porqué de la ruta.
Si luego quieres una página más amplia que combine JavaScript, Python y cURL, la continuación natural es OpenAI image generation API example. Esta guía es deliberadamente más estrecha porque su objetivo es que el flujo raw HTTP sea estable.
Usa multipart POST /v1/images/edits solo cuando ya tienes imágenes de entrada
Si ya partes de un asset real, no tiene sentido estirar la ruta de generación hasta convertirla en un tutorial de edición accidental. La ruta correcta sigue siendo Images API, pero en la rama de edits.
La referencia de Images API documenta POST /images/edits, y el image generation guide incluye un ejemplo actual con campos repetidos image[] en multipart.
La forma cruda es esta:
bashcurl -s -D >(grep -i x-request-id >&2) \ -o >(jq -r '.data[0].b64_json' | base64 --decode > edited-image.png) \ -X POST "https://api.openai.com/v1/images/edits" \ -H "Authorization: Bearer $OPENAI_API_KEY" \ -F "model=gpt-image-1.5" \ -F "image[]=@product-shot.png" \ -F "image[]=@logo.png" \ -F 'prompt=Place the logo on the product box as if it were printed on the packaging.'
La regla más importante aquí es sencilla: generación usa JSON; edits usa multipart. Muchos errores 400 no salen de un parámetro exótico, sino de intentar mandar una edición con la misma estructura JSON que usarías para un prompt sin archivos.
La segunda bifurcación es input_fidelity. La guía oficial explica que, con gpt-image-1.5, las primeras 5 imágenes de entrada pueden conservarse mejor si usas input_fidelity=high. Ese parámetro merece la pena cuando de verdad necesitas preservar composición, branding o detalles del sujeto. No merece la pena activarlo por costumbre.
En cURL, eso significa añadir otro campo:
bashcurl -s \ -X POST "https://api.openai.com/v1/images/edits" \ -H "Authorization: Bearer $OPENAI_API_KEY" \ -F "model=gpt-image-1.5" \ -F "image[]=@woman.jpg" \ -F "image[]=@logo.png" \ -F "input_fidelity=high" \ -F 'prompt=Add the logo to the woman'\''s jacket as if stitched into the fabric.' \ > edit-response.json
Aquí es donde muchas guías amplias se desvían. Ven que el caso ya es "más avanzado" y mandan al lector a Responses. Esa conclusión es errónea. Editing sigue siendo un caso directo de Images API. Lo que cambia es la forma del request, no la superficie correcta.
Si necesitas una guía completa de edición y no solo la decisión de ruta, la siguiente pieza adecuada es OpenAI image editing API.
Cambia a /v1/responses solo cuando la imagen sea parte de un workflow mayor
El tool guide de image_generation resuelve otro problema: cómo generar imágenes cuando esa generación ya no es el producto principal, sino una herramienta dentro de una interacción más amplia.
La regla clave aquí es de nivel de campo: los modelos GPT de imagen no son valores válidos para el campo model de nivel superior en Responses API. Si usas /v1/responses, el campo superior debe ser algo como gpt-5, y el tool image_generation se ocupa de la capa de imagen por debajo.
La forma cruda se ve así:
bashcurl https://api.openai.com/v1/responses \ -H "Authorization: Bearer $OPENAI_API_KEY" \ -H "Content-Type: application/json" \ -d '{ "model": "gpt-5", "input": "Generate a transparent sticker-style icon of a paper airplane for a travel app", "tools": [ { "type": "image_generation", "background": "transparent", "quality": "high" } ] }' > responses-output.json jq -r '.output[] | select(.type=="image_generation_call") | .result' responses-output.json \ | python -c 'import sys, base64; sys.stdout.buffer.write(base64.b64decode(sys.stdin.read()))' \ > plane.png
Esta ruta solo es mejor cuando:
- la misma llamada puede producir texto e imagen
- el modelo debe decidir cuándo invocar la generación de imagen
- la imagen es una pieza dentro de un assistant o un workflow multimodal
Es peor como primer paso cuando:
- solo quieres probar una generación directa
- todavía estás verificando acceso o nombres de modelo
- sigues depurando la salida y la decodificación
La regla operativa es muy simple: no empieces por Responses solo porque suene más moderno. Empieza por Responses cuando la orquestación sea el trabajo real.
Si quieres una explicación más amplia de esa bifurcación, la continuación adecuada es OpenAI image API tutorial. Para este keyword, mantener la rama de Responses estrecha es precisamente lo que da claridad.
Troubleshooting: qué errores de cURL apuntan a payload y cuáles apuntan a access
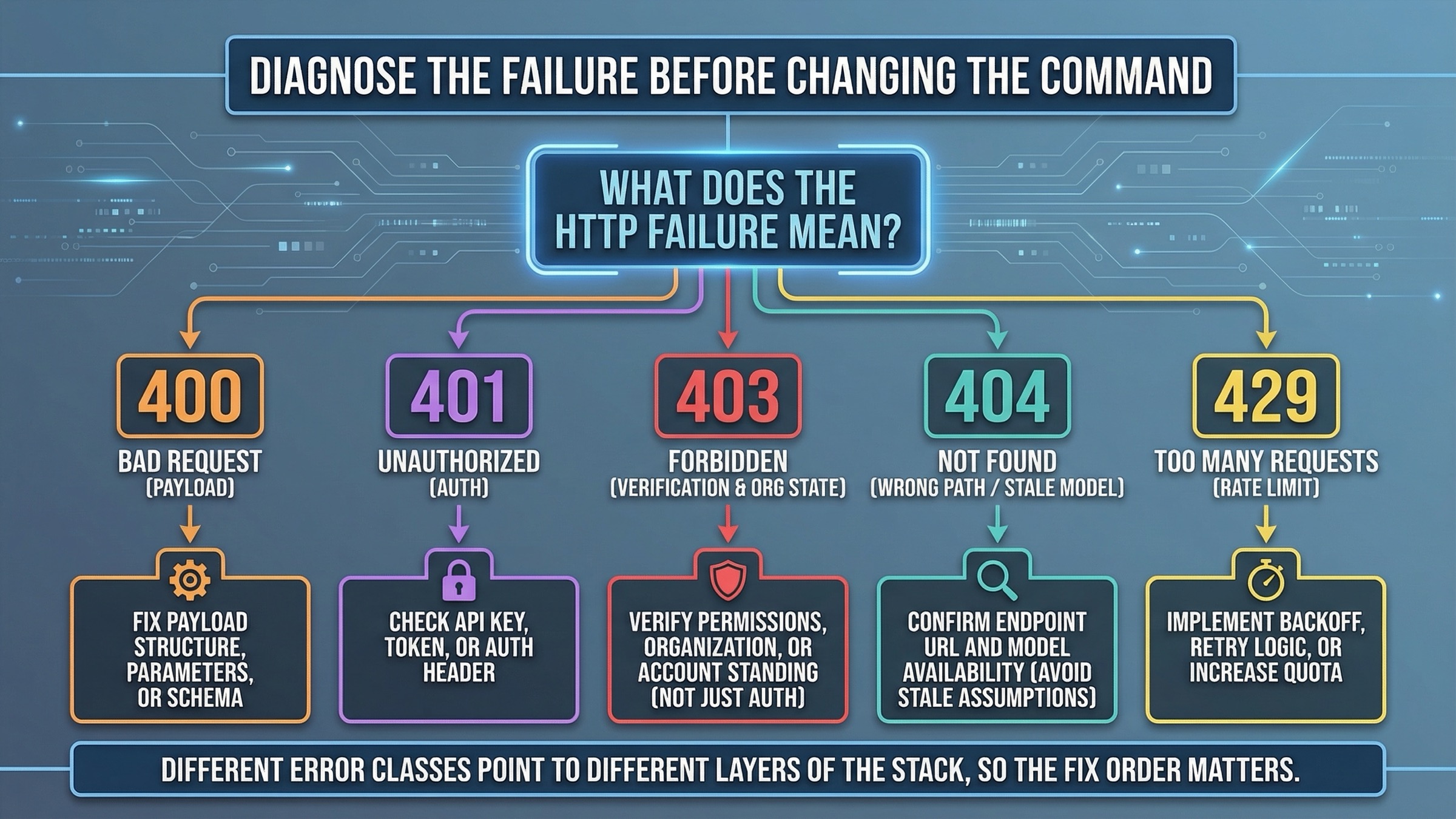
Aquí es donde muchas páginas que rankean se quedan cortas.
Cuando una llamada de cURL falla, la pregunta correcta no es "¿qué parámetro cambio ahora?", sino "¿qué clase de fallo es este?" La respuesta depende de si el problema está en el body, en la clave, en el estado de la organización, en una suposición vieja sobre el modelo o en un límite de cuenta.
Usa esta tabla primero:
| Lo que ves | Lo que suele significar | Qué revisar primero |
|---|---|---|
400 Bad Request | JSON inválido, Content-Type incorrecto o un edit mandado como JSON | Revisa endpoint, shape del body y si deberías usar -d o -F |
401 Unauthorized | Clave mala, ausente o mal pasada en headers | Revisa OPENAI_API_KEY, expansión de shell y la clave del proyecto correcto |
403 con wording de verification o image access | El problema parece más de cuenta que de comando | Revisa organización, verification, propagación y una clave nueva |
404 o model not found | Endpoint incorrecto, supuesto antiguo o snippet desactualizado | Revisa path y nombre de modelo antes de tocar el prompt |
429 o límite de tasa | Es un problema de tier o throughput, no de sintaxis | Revisa rate limits, tier y frecuencia de peticiones |
La rama 403 es especialmente importante porque a menudo parece un fallo del comando cuando en realidad es un problema de estado de cuenta. La página oficial API Organization Verification dice que la verificación desbloquea capacidades de generación de imágenes en la API y que, si el mensaje de "not verified" persiste, debes esperar hasta 30 minutos, crear una API key nueva, refrescar la sesión y confirmar que estás en la organización correcta.
La otra pista oficial viene de API Model Availability by Usage Tier and Verification Status, donde OpenAI dice que gpt-image-1 y gpt-image-1-mini están disponibles para tiers 1 a 5, con parte del acceso sujeto a organización verificada. Si ves 403 o 429, no empieces por culpar al JSON.
La rama 404 es distinta. El hilo oficial de rollout de GPT-Image-1.5 muestra que, durante el despliegue inicial de diciembre de 2025, algunos desarrolladores recibieron errores tipo "the model does not exist". Eso explica por qué todavía aparecen snippets viejos en buscadores. Lo que no significa es que ese deba ser el diagnóstico por defecto hoy. Hoy lo primero es revalidar path, modelo y documentación actual.
Hay otro caso que ni siquiera es HTTP: el request devuelve 200 pero el archivo final sale vacío o ilegible. Entonces el fallo suele estar en la decodificación, no en la API. Por eso conviene guardar response.json antes de encadenar toda la tubería.
Otro hábito útil es exponer el x-request-id cuando puedas:
bashcurl -s -D >(grep -i x-request-id >&2) \ -o response.json \ https://api.openai.com/v1/images/generations \ -H "Authorization: Bearer $OPENAI_API_KEY" \ -H "Content-Type: application/json" \ -d '{ "model": "gpt-image-1.5", "prompt": "Create a clean editorial illustration of a robot camera operator in a bright studio", "size": "1024x1024", "quality": "medium" }'
No arregla nada por sí solo, pero reduce mucho el tiempo perdido cuando el siguiente paso ya es soporte o una comprobación del estado de cuenta.
Si tu problema encaja claramente con verification y no con el body, la continuación adecuada es OpenAI image generation API verification.
Cambia parámetros solo después de que la primera petición funcione
Una vez que la ruta base funciona, entonces sí tiene sentido optimizar. La guía y la referencia oficiales destacan sobre todo estos parámetros:
size:1024x1024,1024x1536,1536x1024oautoquality:low,medium,highoautobackground:transparent,opaqueoautooutput_format:png,webpojpeg
La clave no es memorizar la lista, sino respetar el orden. En un workflow raw HTTP, no suele tener sentido empezar ajustando prompt y formato cuando ni siquiera has probado que el endpoint, el acceso, el modelo y la decodificación están bien.
Para la mayoría de primeras pruebas, el mejor punto de partida sigue siendo:
size: "1024x1024"quality: "medium"- sin
backgroundsalvo necesidad real - sin optimización de formato hasta que la ruta básica esté cerrada
Si necesitas transparencia, entonces sí merece la pena añadirlo explícitamente:
bashcurl https://api.openai.com/v1/images/generations \ -H "Authorization: Bearer $OPENAI_API_KEY" \ -H "Content-Type: application/json" \ -d '{ "model": "gpt-image-1.5", "prompt": "Draw a transparent sticker-style icon of a paper airplane for a travel app", "size": "1024x1024", "quality": "high", "background": "transparent", "output_format": "png" }' > transparent-response.json
Si lo que te importa más es peso o velocidad de transferencia, deja jpeg o webp para la segunda fase. Si lo que te interesa es streaming o partial_images, eso ya pertenece a la rama de optimización, no al primer flujo que este keyword debería resolver.
El orden más seguro sigue siendo este:
- demostrar que el endpoint responde
- demostrar que la salida se decodifica
- demostrar que elegiste la superficie correcta
- luego ajustar
quality,size,backgroundy prompt
Si tu siguiente decisión ya es de coste y no de cURL, la mejor continuación es OpenAI image generation API pricing.
Recomendación final
Si solo quieres una regla corta, quédate con esta: empieza por POST /v1/images/generations, decodifica b64_json, cambia a POST /v1/images/edits solo cuando ya tengas imágenes de entrada y cambia a POST /v1/responses solo cuando la imagen sea parte de un workflow tool-driven más grande.
Esa regla mejora la media del SERP porque resuelve el workflow completo de shell, no solo una petición vistosa. Junta en una misma página lo que hoy está repartido entre guía, referencia, modelo y help center: ruta correcta, modelo actual, shape de salida, decodificación y orden de troubleshooting.