Si hoy buscas gpt-image-1-mini examples que sigan funcionando a 29 de marzo de 2026, la regla mas segura es esta: generacion de una sola vez con Images API, edicion directa tambien con Images API, y Responses solo cuando de verdad necesitas un workflow de imagen de varias vueltas. Ese orden es lo mas util que la SERP de coincidencia exacta sigue sin dejar claro.
La razon no es una preferencia personal. La image generation guide actual de OpenAI sigue diciendo que Images API es la mejor eleccion cuando solo necesitas generar o editar una imagen desde un prompt. Y la pagina actual de gpt-image-1-mini confirma que mini es la ruta cost-efficient de GPT Image, no el default mas comodo para cualquier trabajo visual.
Por eso los tres ejemplos que siguen son los que merece la pena copiar primero. Si solo necesitas prompt-to-image, empieza por Ejemplo 1. Si ya tienes una imagen y quieres editarla, pasa al Ejemplo 2. Si tu producto necesita memoria de conversacion o refinamiento entre turnos, entonces si tiene sentido el Ejemplo 3. Todo lo demas es optimizacion posterior.
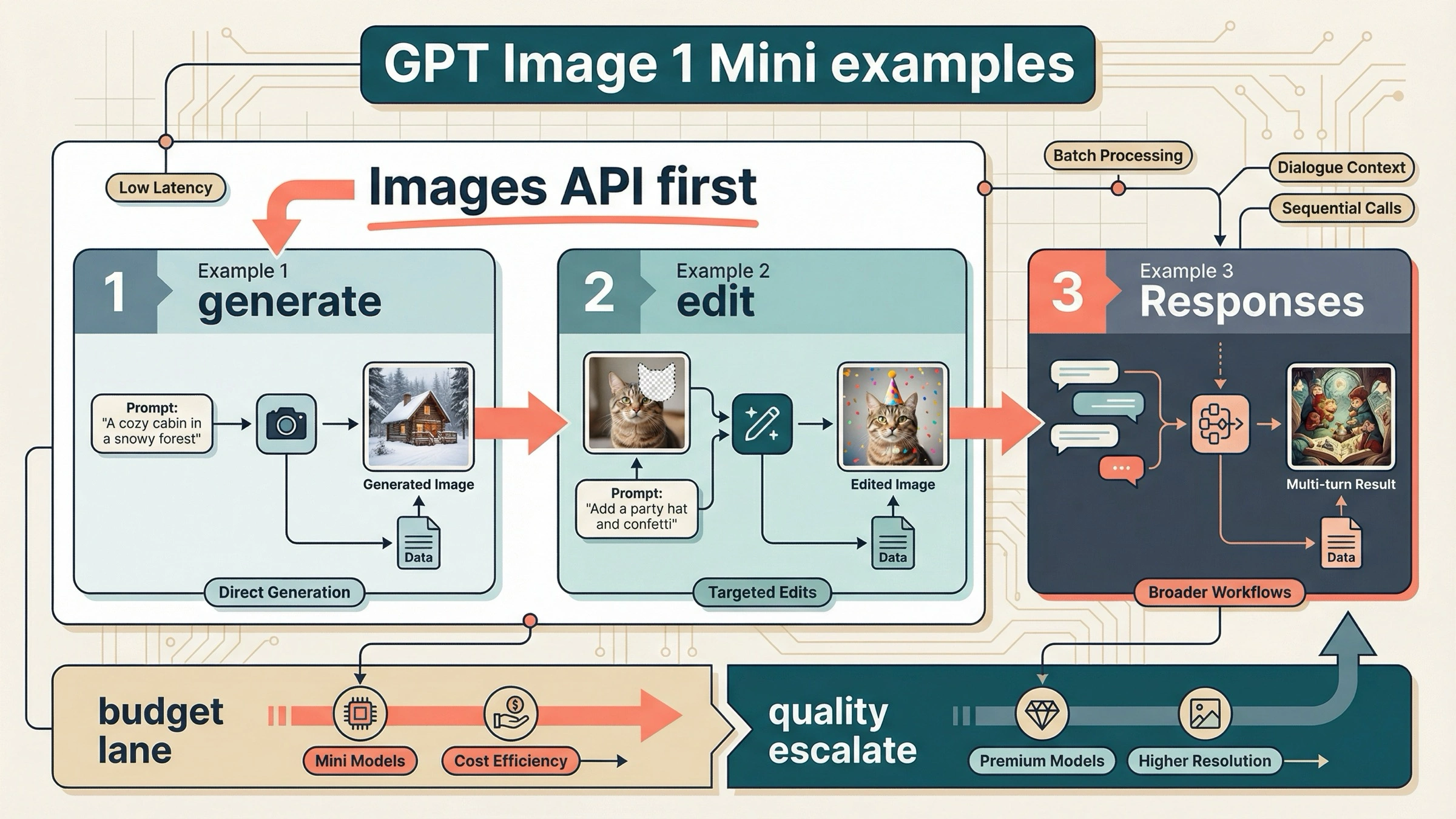
Los 3 ejemplos de gpt-image-1-mini que merece copiar primero
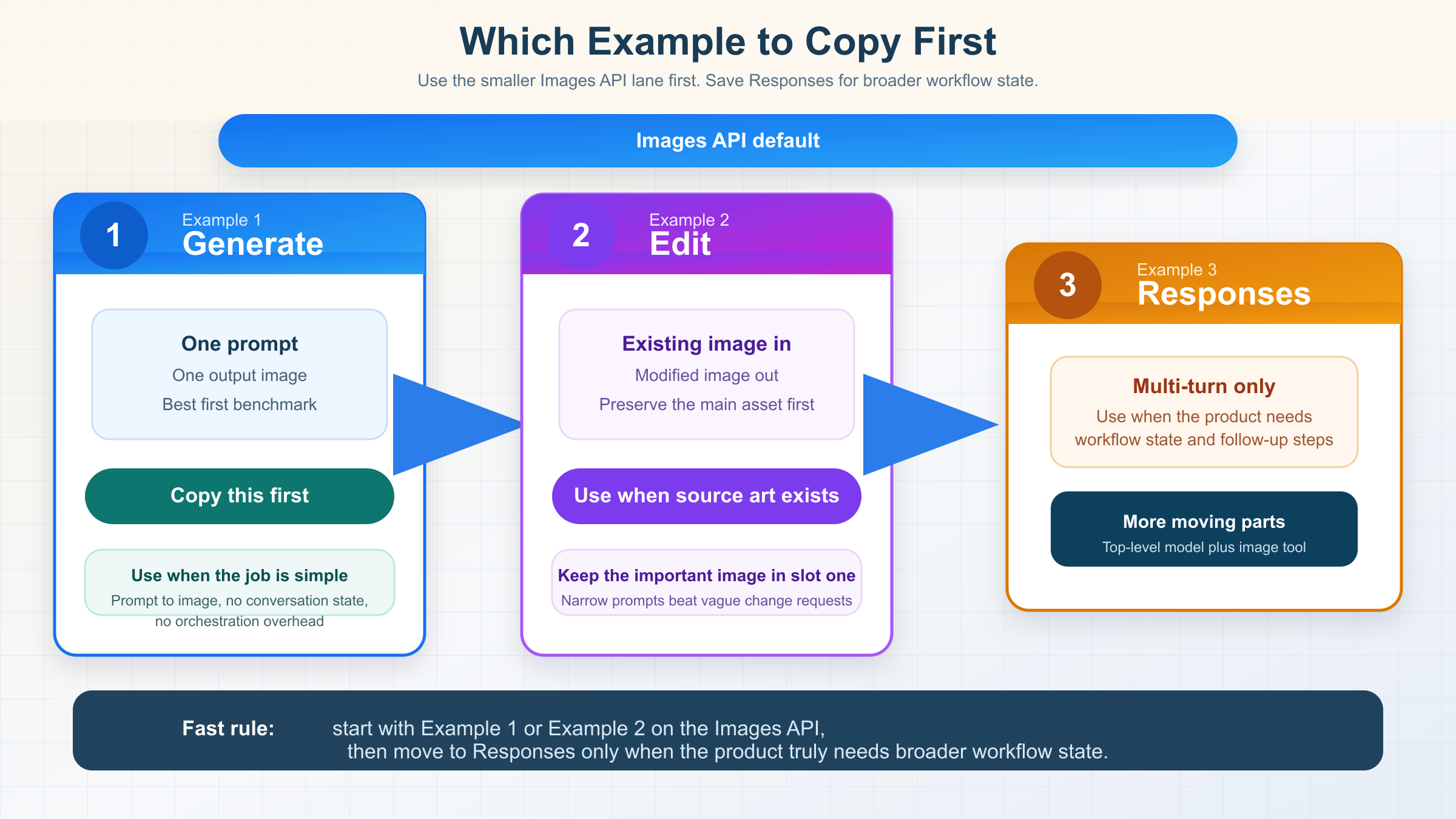
La query exacta esta llena de directorios de modelos, galerias de snippets y playgrounds de terceros. Muchos sirven para descubrir opciones, pero casi ninguno te dice que deberias probar primero. Esta tabla es la respuesta corta y honesta.
| Si necesitas... | Copia este ejemplo | API surface | Empieza aqui porque |
|---|---|---|---|
| Un prompt y una imagen de salida | Ejemplo 1 | Images API | Es la ruta oficial mas pequena y la forma mas rapida de conseguir un primer exito |
| Una edicion directa sobre una imagen existente | Ejemplo 2 | Images API | OpenAI sigue recomendando la ruta directa para edits de una sola pasada y aqui importan los detalles de mini |
| Refinamiento iterativo a lo largo de varios turnos | Ejemplo 3 | Responses API | Solo aqui se justifica de verdad el estado conversacional y la herramienta image_generation |
Hay un detalle mas que conviene recordar antes de copiar codigo. La guia actual de herramientas dice que los prompts de imagen suelen funcionar mejor con verbos directos como draw o edit. Parece un matiz menor, pero sirve para detectar paginas flojas: si una pagina solo pega una llamada y no te ayuda a redactar el prompt, normalmente tampoco te esta ayudando a conseguir un primer resultado estable.
Si quieres una pagina mas amplia sobre OpenAI image generation API centrada en la ruta flagship en lugar de mini, la siguiente lectura natural es OpenAI image generation API example. Esta guia es estrecha a proposito: solo responde que patrones mini siguen mereciendo la pena.
Ejemplo 1: generacion de una sola vez con Images API
Este es el mejor primer ejemplo porque reduce al minimo la superficie de fallo. Mandas un prompt, recibes bytes base64, los guardas en disco. Sin estado de conversacion. Sin enrutado de tools. Sin dudas sobre si elegiste la superficie equivocada.
jsimport fs from "fs"; import OpenAI from "openai"; const client = new OpenAI({ apiKey: process.env.OPENAI_API_KEY, }); const result = await client.images.generate({ model: "gpt-image-1-mini", prompt: "Draw a clean editorial illustration of a robot street photographer in bright morning light.", size: "1024x1024", quality: "medium", output_format: "jpeg", output_compression: 80, }); const imageBase64 = result.data[0].b64_json; fs.writeFileSync( "gpt-image-1-mini-generate.jpg", Buffer.from(imageBase64, "base64") );
La version en Python es igual de directa:
pythonfrom openai import OpenAI import base64 client = OpenAI() result = client.images.generate( model="gpt-image-1-mini", prompt="Draw a clean editorial illustration of a robot street photographer in bright morning light.", size="1024x1024", quality="medium", output_format="jpeg", output_compression=80, ) image_base64 = result.data[0].b64_json with open("gpt-image-1-mini-generate.jpg", "wb") as f: f.write(base64.b64decode(image_base64))
Y esta es la forma cruda en cURL:
bashcurl https://api.openai.com/v1/images/generations \ -H "Authorization: Bearer $OPENAI_API_KEY" \ -H "Content-Type: application/json" \ -d '{ "model": "gpt-image-1-mini", "prompt": "Draw a clean editorial illustration of a robot street photographer in bright morning light.", "size": "1024x1024", "quality": "medium", "output_format": "jpeg", "output_compression": 80 }' \ | jq -r '.data[0].b64_json' \ | base64 --decode > gpt-image-1-mini-generate.jpg
Este ejemplo es el default correcto por dos motivos.
Primero, porque encaja con la regla actual de OpenAI. La guia de imagen sigue diciendo que Images API es la mejor eleccion cuando solo necesitas un trabajo de imagen por prompt. Asi que no es solo el ejemplo mas simple; tambien es el que mejor se alinea con la superficie oficial.
Segundo, porque es la forma mas limpia de medir si mini realmente te vale. La misma guia actual recomienda GPT Image 1.5 para la mejor experiencia, pero si tu prioridad real es abaratar la generacion, este ejemplo te da la ruta oficial mas barata para hacer el primer benchmark. Si la calidad ya es suficiente, mantienes mini. Si no, aprendes algo real antes de escalar por la ruta equivocada.
Haz la primera peticion de forma deliberadamente aburrida: imagen cuadrada, quality: "medium" y un prompt que diga draw sin rodeos. Guarda el archivo. Comprueba que la decodificacion funciona. Despues ya podras tocar transparencia, streaming o direccion artistica mas precisa. Antes de eso, la complejidad casi siempre sobra.
Hay un motivo practico para empezar asi: quality es tu primer mando de coste y latencia. En la pagina actual de mini, pasar de 1024x1024 low a $0.005 a medium a $0.011 y high a $0.036 cambia bastante el calculo. Si tu app genera borradores, variantes internas o visuales de poco riesgo, medium suele ser el benchmark inicial mas sensato. Sube solo cuando veas una brecha de calidad real.
Tambien es aqui donde la forma del prompt importa mas de lo que admiten muchas galerias. Mini responde mejor cuando le dices que crear, que estilo visual usar y que detalles no deberia olvidar. Un prompt como "make a cool robot photo" no sirve para evaluar el modelo. Uno mas concreto como "Draw a clean editorial illustration of a robot street photographer in bright morning light, with a visible camera strap and soft city reflections in the shop window" te da una lectura mas limpia sobre si mini encaja con tu producto.
| Parametro | Valor inicial seguro | Cambialo cuando |
|---|---|---|
size | 1024x1024 | Tengas una necesidad real de otro aspect ratio o de un recorte posterior |
quality | medium | Hayas medido que low se queda corto o que high te compensa |
output_format | jpeg | Tu pipeline necesite otro tipo de archivo o mas tolerancia para ediciones |
output_compression | 80 | El tamano del archivo o los artefactos de compresion importen mas |
La tabla parece basica, pero justamente esa capa es la que falta en demasiadas paginas de examples. Un buen primer ejemplo no es el que mete mas flags opcionales; es el que te deja una linea base estable antes de entrar en el intercambio entre calidad, formato y coste.
Ejemplo 2: edicion directa con input_fidelity
Si ya tienes una imagen y quieres modificarla, quedate en Images API. La documentacion actual sigue tratando los edits directos como parte de la misma ruta simple. No hace falta saltar a Responses solo porque el trabajo haya dejado de ser puro text-to-image.
jsimport fs from "fs"; import OpenAI from "openai"; const client = new OpenAI({ apiKey: process.env.OPENAI_API_KEY, }); const result = await client.images.edit({ model: "gpt-image-1-mini", image: [ fs.createReadStream("product-photo.jpg"), fs.createReadStream("brand-logo.png"), ], prompt: "Edit the first image by placing the logo from the second image onto the coffee cup label. Preserve the cup shape, lighting, camera angle, and table texture.", input_fidelity: "high", size: "1024x1024", quality: "medium", }); const imageBase64 = result.data[0].b64_json; fs.writeFileSync( "product-photo-edited.png", Buffer.from(imageBase64, "base64") );
Este es el ejemplo donde el detalle de mini de verdad importa.
La documentacion actual sobre input fidelity dice que con gpt-image-1 o gpt-image-1-mini, cuando usas input_fidelity: "high", la primera imagen de entrada se preserva con mas textura y detalle fino que las posteriores. Si una cara, un producto o un logo es el activo mas importante, tiene que ir en la posicion uno.
Ese es justo el dato que casi todas las paginas wrapper se saltan. Te muestran que los edits existen, pero no te cuentan que cambia de verdad el resultado.
Quedate con tres reglas practicas:
- Pon primero el activo que mas te importa preservar.
- Usa
input_fidelity: "high"solo cuando la preservacion extra compense el mayor gasto de tokens de imagen. - Haz la instruccion de edit estrecha: di que debe cambiar, pero tambien que debe quedarse igual.
Si mas adelante anades una mask, recuerda que los edits de GPT Image siguen siendo generativos, no cirugia local determinista al estilo Photoshop. La guia indica que imagen y mask deben coincidir en tamano y formato, y que la mask necesita alpha channel. Sirve para dirigir la edicion, pero no convierte el proceso en compositing pixel-perfect.
Hay otro detalle de integracion que rompe muchos ejemplos cuando salen del SDK. El SDK te oculta el multipart form-data. Si reimplementas la misma llamada sobre HTTP crudo, tienes que mandar los archivos como partes de archivo reales, no como binarios empaquetados en JSON. Suena obvio, pero es una de las razones por las que un ejemplo de tercero puede parecer mas "simple" mientras deja fuera justo la parte que necesitas en produccion.
El mejor modelo mental para edits con varias imagenes es este: la primera imagen es el lienzo que mas te interesa preservar, y las siguientes son referencias de las que quieres tomar elementos. No es una garantia absoluta de composicion, pero si se alinea con la regla oficial de input_fidelity y mejora bastante el prompt. Dicho de otro modo: no entierres la imagen principal en la segunda o tercera posicion y luego culpes al modelo por la deriva.
Si lo que de verdad te interesa es el caso de uso de edit y no los examples en general, el siguiente paso es GPT Image 1 Mini edit. Esta pagina se queda deliberadamente en el nivel de eleccion del ejemplo.
Ejemplo 3: usa Responses solo en workflows de varias vueltas
Este es el ejemplo correcto solo cuando el producto realmente necesita estado conversacional o refinamiento iterativo a traves de varios turnos. No es el primer snippet que deberias copiar para un trabajo de una sola llamada.
El matiz importante es este. En Responses API, el model de nivel superior es un modelo mainline capaz de texto como gpt-5 o gpt-4.1. La tool alojada image_generation usa modelos GPT Image por debajo, pero gpt-image-1-mini no es el valor que debes poner en el campo model de arriba. Esa sigue siendo una de las confusiones que mas paginas wrapper provocan.
jsimport fs from "fs"; import OpenAI from "openai"; const client = new OpenAI({ apiKey: process.env.OPENAI_API_KEY, }); const response = await client.responses.create({ model: "gpt-5", input: "Generate an image of a gray tabby cat reading a newspaper at a cafe table.", tools: [{ type: "image_generation" }], }); const firstImage = response.output .filter((item) => item.type === "image_generation_call") .map((item) => item.result)[0]; fs.writeFileSync("cat-cafe.png", Buffer.from(firstImage, "base64")); const followUp = await client.responses.create({ model: "gpt-5", previous_response_id: response.id, input: "Now make it look like a realistic magazine photo.", tools: [{ type: "image_generation" }], }); const secondImage = followUp.output .filter((item) => item.type === "image_generation_call") .map((item) => item.result)[0]; fs.writeFileSync("cat-cafe-realistic.png", Buffer.from(secondImage, "base64"));
Esta es la ruta correcta cuando el trabajo ya no es realmente "una sola imagen". Es la ruta correcta cuando tu producto necesita memoria visual entre turnos, o cuando la generacion de imagen es una tool dentro de un workflow mayor.
Tambien es la ruta incorrecta cuando tu necesidad sigue siendo simple.
Ese es el punto que la SERP sigue embarrando. Muchas paginas de gateway o playground hacen que Responses parezca la respuesta mas moderna. OpenAI es mas preciso que eso: la respuesta mas moderna es la que encaja con el trabajo. Si solo quieres generar o editar una imagen de forma directa, Images API sigue siendo la superficie oficial mas limpia.
Hay otro motivo para dejar este ejemplo en tercer lugar: Responses mete dos decisiones nuevas de golpe. Ahora debes elegir el modelo razonador superior y tambien decidir cuando llamar a la tool de imagen dentro de un workflow mayor. Para un assistant eso puede ser correcto, pero para el primer benchmark de mini es una superficie de depuracion peor. Si todavia no has demostrado que mini te da calidad aceptable en Images API, Responses suele hacer el experimento mas confuso, no mas claro.
Comprobaciones previas antes de culpar al ejemplo
Mini es la ruta barata de imagen, pero no es una ruta gratuita.
Tal como estaba publicado el 29 de marzo de 2026, la pagina oficial de mini lista precios de 1024x1024 en $0.005 low, $0.011 medium y $0.036 high. La misma pagina tambien indica que Free no esta soportado y muestra Tier 1 a partir de 100,000 TPM y 5 IPM.
Eso importa porque un buen ejemplo puede fallar igualmente si tu cuenta no esta lista para el modelo.
El articulo actual de OpenAI sobre model availability por usage tier y verification status dice que gpt-image-1 y gpt-image-1-mini estan disponibles para usuarios de API en tiers 1 a 5, con parte del acceso sujeta a organization verification. Y el articulo actual de API organization verification anade el detalle operativo que tantas galerias omiten: la verificacion puede desbloquear capacidades de generacion de imagen, el estado puede tardar hasta 30 minutos en propagarse y, si persisten errores de "not verified", a menudo ayuda generar una API key nueva.
Con eso, el orden de depuracion queda bastante limpio:
- Confirma que la API key pertenece al proyecto y organizacion correctos.
- Confirma que la cuenta esta en un tier que soporte acceso de mini para imagen.
- Si sigue fallando, revisa el estado de organization verification.
- Espera los 30 minutos completos si la verificacion acaba de completarse.
- Genera una API key nueva antes de reescribir un ejemplo que ya era valido.
Si tu bloqueo real es el acceso y no el snippet, la siguiente lectura util es OpenAI image generation API verification.
Como diagnosticar los fallos mas comunes de los ejemplos de gpt-image-1-mini
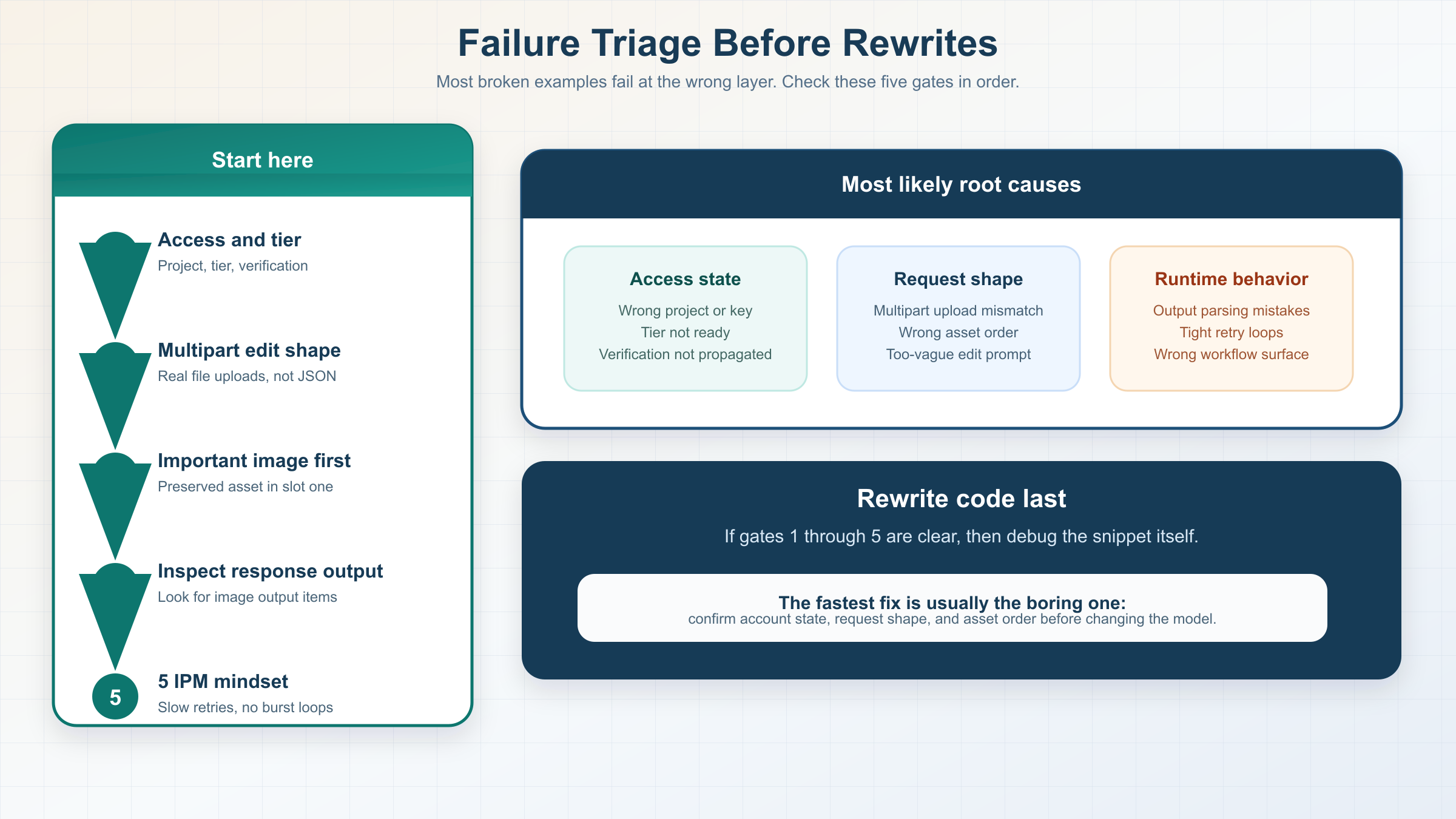
Cuando un example copiado falla, la causa real suele ser bastante mas aburrida de lo que sugiere la SERP. La mayoria de errores vienen de elegir la superficie equivocada, usar la superficie correcta con una request shape incorrecta o depurar el estado de la cuenta demasiado tarde.
| Sintoma | Causa probable | Que revisar primero |
|---|---|---|
| El ejemplo de generacion devuelve errores de acceso o disponibilidad | El proyecto, el tier o la verificacion no estan listos para mini | Confirma la organizacion, el tier, la verificacion y si la API key se creo despues de terminar la verificacion |
| El ejemplo de edit corre pero ignora el asset de referencia | La imagen importante no iba primero o el prompt no decia que debia mantenerse fijo | Pon primero la imagen a preservar y reescribe el prompt alrededor de los detalles que deben quedarse |
| El edit falla al salir del SDK | La request cruda no esta enviando el multipart con archivos reales | Reconstruye la llamada como multipart form-data con file parts reales en lugar de binarios dentro de JSON |
| El ejemplo con Responses devuelve texto pero no una imagen util | Estas procesando mal response.output o esa arquitectura no era la que necesitabas probar | Busca items image_generation_call dentro de response.output y demuestra que Responses era necesario |
| Te topas con rate limits antes de lo esperado | Las cuotas de imagen de mini son mucho mas pequenas que las costumbres de los modelos de texto | Revisa el IPM oficial, frena los reintentos y deja de golpear el mismo example en bucle |
La ultima fila merece subrayado. A 29 de marzo de 2026, la pagina oficial de mini sigue mostrando Tier 1 a 5 IPM. Eso es minusculo comparado con la forma en que muchos desarrolladores prueban endpoints de chat o texto. Si repites el mismo example varias veces mientras cambias prompts o el orden de assets, puedes fabricar un fallo aparentemente aleatorio cuando el problema real es simplemente el throughput por minuto.
Si el ejemplo de generacion funciona pero el de edit no, lo mas probable no es que "mini edits este roto". Lo normal es que haya cambiado el orden de assets, el alcance del prompt o la forma multipart. Si los examples directos de Images API funcionan y el de Responses se siente mas fragil, lo mas probable es que hayas introducido complejidad de workflow antes de tener una linea base estable.
Cuando Mini basta y cuando conviene copiar antes un ejemplo de GPT Image 1.5

Esta es la pregunta que casi ninguna pagina de examples responde de frente.
La guia actual de imagen de OpenAI dice que gpt-image-1.5 es el modelo GPT Image mas reciente y mas avanzado, y recomienda GPT Image 1.5 para la mejor experiencia. La misma guia dice que puedes usar gpt-image-1-mini cuando buscas una opcion mas rentable y la calidad de imagen no es la prioridad.
Asi que la regla honesta no es "mini ya es el default". La regla honesta es esta:
- Copia antes los examples de mini cuando el coste sea la primera restriccion.
- Copia antes los examples de GPT Image 1.5 cuando la calidad, los edits de mas valor o un numero menor de retries pesen mas que el precio minimo por imagen.
Mini encaja bien en:
- conceptos internos
- variantes de marketing de bajo riesgo
- benchmarks baratos de prompt
- generacion en lote donde el volumen importe antes que la perfeccion
GPT Image 1.5 es la opcion mas segura cuando te importa mas:
- mejor calidad global
- activos de produccion con mas valor
- fallos de edit mas caros
- workflows donde el coste del retry pesa mas que el precio nominal por imagen
Hay un matiz mas que si importa cuando escalas. La pagina de API pricing de OpenAI dice que Batch API ahorra un 50% en inputs y outputs. Eso no borra la ventaja de coste de mini, pero si hace que la eleccion del modelo dependa mas del workflow en trabajos asincronos. Si tu equipo puede batchar generacion de imagen, la ruta flagship puede acercarse mas de lo que parece en una tabla plana.
Ese es exactamente el motivo por el que una buena pagina de examples no deberia quedarse en "codigo que corre". Un example barato solo es el example correcto cuando la salida supera tu liston de calidad sin forzar demasiados retries, ediciones manuales o limpieza humana. En cuanto los retries se acumulan, el modelo nominalmente mas barato puede convertirse en el sistema mas lento y caro en la practica.
Si quieres el desglose completo de coste, sigue por GPT Image 1 Mini pricing. Si quieres la decision cualitativa mas amplia sobre si mini merece la pena, la siguiente lectura es GPT Image 1 Mini review.
Los errores que estas paginas wrapper siguen provocando
El primer error es copiar la abstraccion equivocada. Si solo necesitas un prompt y una imagen de salida, no empieces por Responses solo porque parezca mas nuevo. La propia documentacion de OpenAI sigue apuntando a Images API para ese trabajo.
El segundo error es poner el modelo equivocado en el campo model de Responses. Si usas la tool alojada image_generation, el modelo superior debe ser algo como gpt-5 o gpt-4.1. No metas gpt-image-1-mini ahi solo porque la pagina que copiaste nunca explico la diferencia.
El tercer error es olvidar la regla de la primera imagen en mini edits. Si lo que mas te importa es preservar una cara, un producto o un logo, esa imagen va primero. Ese es el detalle mini-specific que cambia resultados reales.
El cuarto error es tratar la ruta mas barata como si fuera el mejor default. Muchas wrappers venden mini como si barato significara correcto. Los docs oficiales no dicen eso. Dicen que mini es la ruta rentable, mientras que GPT Image 1.5 sigue siendo la ruta de mejor experiencia.
El quinto error es depurar codigo antes de depurar el estado de la cuenta. Si el proyecto esta en el tier equivocado, la org no esta verificada o la propagacion no ha terminado, tu example puede fallar aunque la request shape sea correcta.
El sexto error es copiar vocabulario de gateways de terceros dentro de la API oficial sin volver a comprobar antes los docs de OpenAI. Esas paginas a menudo comprimen varias decisiones de modelo y endpoint dentro de una sola abstraccion de UI. Puede ser util dentro de su producto. Deja de serlo cuando esas mismas etiquetas se pegan en codigo OpenAI-native como si el mapeo fuera uno a uno.
Ese es el valor real que una pagina fuerte de examples deberia anadir: no un snippet mas, sino mejor orden.
Conclusion
Si buscabas gpt-image-1-mini examples, los tres anteriores son los que merece la pena copiar primero. Usa Images API para generacion de una sola vez. Usa Images API otra vez para edits directos con input_fidelity. Pasa a Responses solo cuando el producto necesite de verdad un workflow de imagen de varias vueltas.
Y quedate con una regla por encima de las demas: mini es la ruta barata, no la ruta universal. Si los examples funcionan y la calidad ya es suficiente, quedate en mini. Si el workflow empieza a salir caro por retries, copia la misma ruta con GPT Image 1.5 en lugar de obligar a mini a hacer un trabajo de flagship.