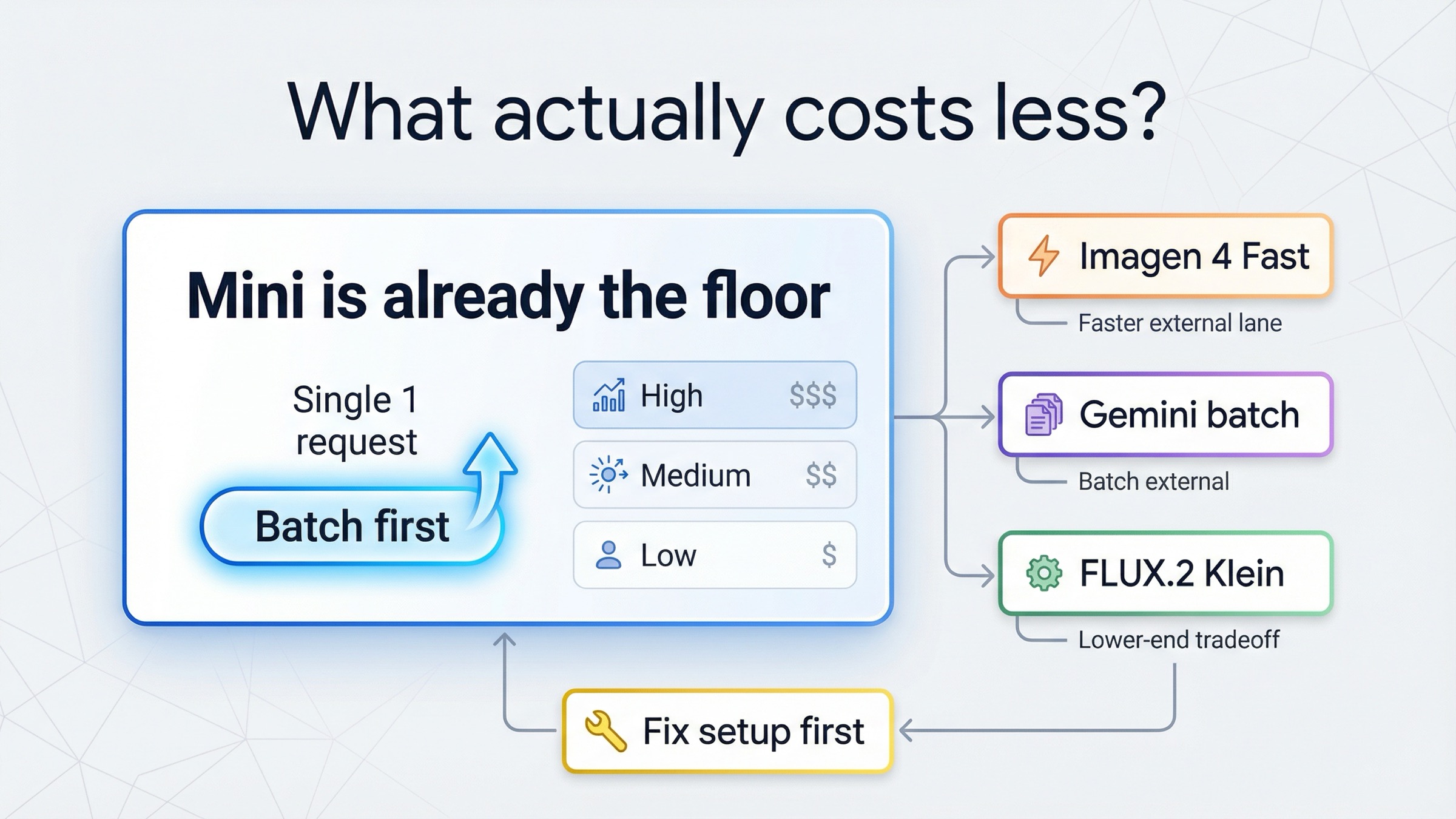
A 29 de marzo de 2026, no hay ningún mainstream hosted API que gane de forma consistente a gpt-image-1-mini en sus filas low y medium. La página actual del modelo gpt-image-1-mini sigue mostrando \$0.005, \$0.011 y \$0.036 para 1024x1024 cuadrado en low, medium y high. Eso cambia por completo la respuesta a este keyword: si tu problema es solo el precio, el primer movimiento no suele ser cambiar de vendor, sino seguir en mini y probar Batch.
Ese es justo el punto que las páginas de pricing más flojas suelen ocultar. Te dicen que Imagen 4 Fast cuesta 0.02, que gemini-2.5-flash-image batch cuesta 0.0195 o que FLUX.2 Klein empieza en 0.014 o 0.015, pero no te dicen si esos rows son más baratos que mini en general, solo más baratos que mini high, o solo más baratos porque cambian el tipo de trabajo, la calidad objetivo o la vida útil de la route.
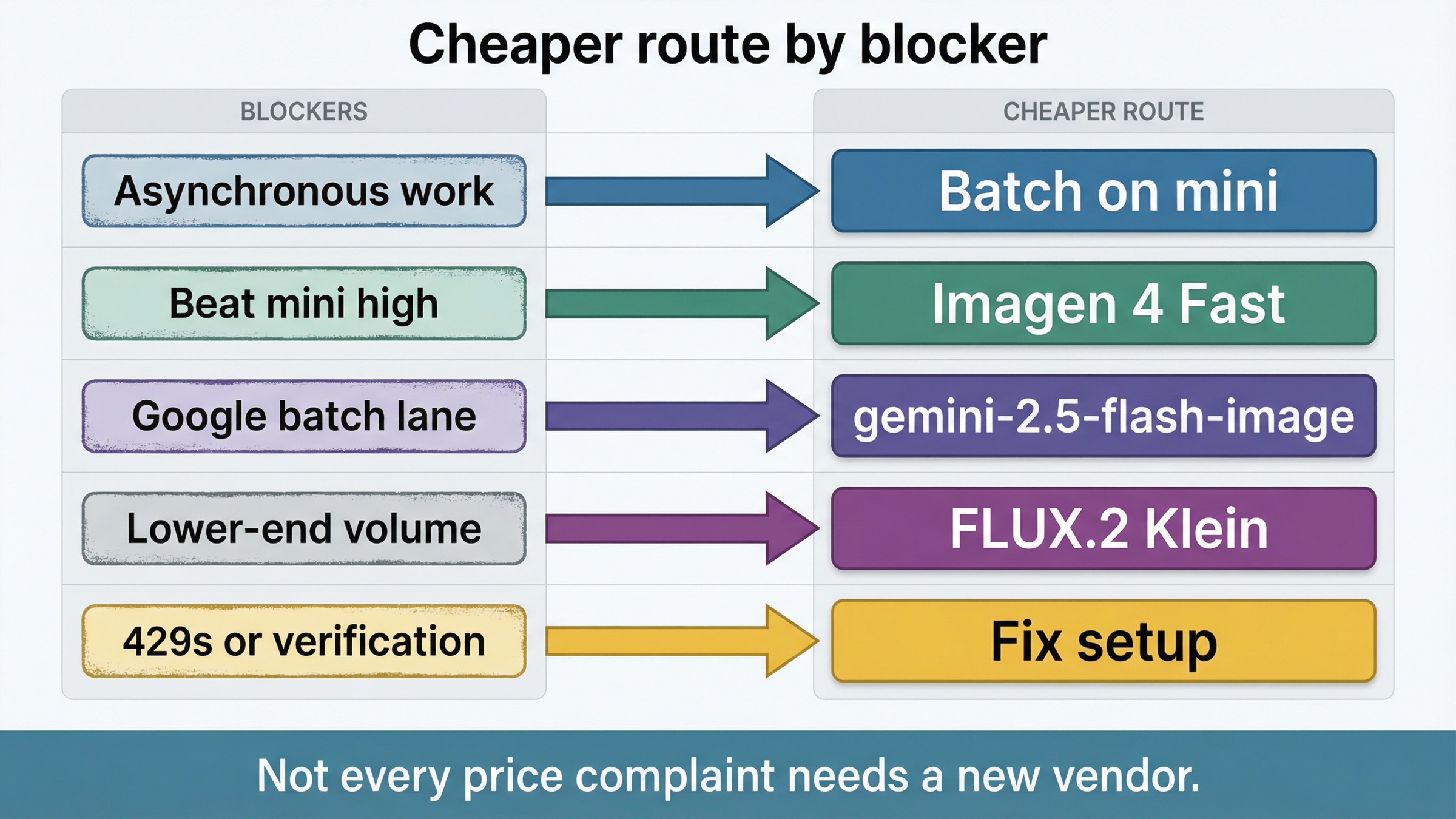
Además, parte de las búsquedas de “alternativa más barata” ni siquiera son problemas de modelo. A veces el problema real es que tu carga podría ir por Batch, o que te está frenando la verificación, el tier o la route API. OpenAI ya deja claro en su API Pricing que Batch ahorra un 50% en inputs y outputs. Por eso esta página no trata de inventar otro ganador universal. Trata de responder qué cuesta menos de verdad después de separar mini live, mini + Batch, Google rows, FLUX.2 Klein y setup friction.
Resumen rápido
Si solo necesitas la decisión operativa, empieza por aquí.
| Si lo que buscas realmente es... | La ruta más barata o más creíble hoy | Ancla de precio actual | Por qué encaja | Tradeoff principal |
|---|---|---|---|---|
| conservar la ruta de imagen más barata dentro de OpenAI | seguir con gpt-image-1-mini | \$0.005 / \$0.011 / \$0.036 | mini ya es la lane de coste dentro de OpenAI | mantienes su techo de calidad |
| bajar más el coste sin cambiar de modelo y con carga asíncrona | mini + Batch | OpenAI indica 50% de descuento en inputs y outputs | primero abaratas el workflow, no el vendor | OpenAI no publica una tarjeta separada por imagen para mini Batch |
| ganar solo contra mini high con una route simple de Google | Imagen 4 Fast | \$0.02/imagen | sí baja de 0.036 | sigue por encima de mini low y medium, y Google ya publica fecha de cierre |
| usar el row de imagen más bajo que hoy publica Google | gemini-2.5-flash-image batch | \$0.0195/imagen | también gana a mini high | sigue por encima de mini low y medium, y también tiene fecha de cierre |
| aceptar una lane externa más low-end y de alto throughput | FLUX.2 Klein | desde \$0.014 o \$0.015 | puede bajar de mini high en ciertos trabajos | se cobra por megapixel y no equivale a una replacement lineal de mini |
| corregir una fricción de 429, verification o tier | quedarte en OpenAI y arreglar setup | no hace falta cambiar de modelo | un vendor switch no arregla account state | primero toca limpiar la route |
La regla corta es esta: más barato que mini high no significa más barato que mini en general.
Por qué mini ya es el floor actual

El valor real de esta página empieza cuando dejas de tratar mini como si fuera un único precio.
El catálogo actual de modelos de OpenAI sigue dejando clara la familia: GPT Image 1.5 es el modelo state-of-the-art, GPT Image 1 es la generación previa y gpt-image-1-mini es la rama cost-efficient. Eso importa porque mini no es un resto barato ni una lane olvidada. Es el floor de coste oficial que OpenAI sigue publicando hoy.
En cuanto separas low, medium y high, la pregunta cambia. Muchos comparadores amplios ven un row externo de 0.02 o 0.0195 y se apresuran a decir “hay algo más barato que mini”. Pero eso solo es verdad frente a mini high. No lo es frente a mini low ni frente a mini medium. Si tu trabajo ya cabe en low o medium, el supuesto ahorro externo desaparece.
Aquí entra Batch. La API Pricing de OpenAI dice que Batch aplica un 50% de descuento en inputs y outputs para trabajo asíncrono. La página de mini también expone Batch como endpoint válido. OpenAI no publica un “precio por imagen en Batch” separado para mini, así que conviene tratarlo como una optimización de workflow y no como una nueva tarjeta cerrada. Aun así, el orden de decisión cambia por completo: si puedes poner el trabajo en cola, el primer cheaper move serio suele ser mini + Batch.
Esto también evita caer en respuestas viejas. La guía actual de image generation deja claro que DALL-E 2 y DALL-E 3 dejarán de aceptar requests el 12 de mayo de 2026. Aunque veas algún row antiguo por ahí, no es una default route fuerte para un artículo actual sobre coste.
Si quieres el mapa de precios dentro de OpenAI y no tanto la decisión de mercado, el siguiente paso natural es GPT Image 1 Mini pricing. Si lo que buscas es una visión más ancha del mercado, OpenAI image generation API cheaper alternative cubre mejor la parte transversal.
Esta es la tabla que más ayuda a no leer mal los números:
| Ruta | Superficie de precio actual | Qué gana de verdad | Caveat principal |
|---|---|---|---|
| mini live | \$0.005 / \$0.011 / \$0.036 | floor actual dentro de OpenAI | sigues dentro del techo de calidad de mini |
| mini + Batch | 50% menos en inputs y outputs | probablemente el mismo modelo más barato si el trabajo cabe en cola | OpenAI no publica una tarjeta per-image separada |
| Imagen 4 Fast | \$0.02/imagen | mini high | fecha de cierre 2026-06-24 |
gemini-2.5-flash-image batch | \$0.0195/imagen | mini high | fecha de cierre 2026-10-02 |
| FLUX.2 Klein | desde \$0.014 / \$0.015 | parte de las comparaciones low-end contra mini high | cobro por megapixel y otra clase de trabajo |
Esta tabla es la tesis del artículo. Todo lo demás solo explica cuándo es honesta cada fila.
Cuándo Google sí es más barato
Google importa aquí, pero solo si no se exagera.
La ruta más limpia es Imagen 4 Fast. Google la publica hoy a \$0.02/imagen en la página de precios del Gemini Developer API. Si comparas contra mini high y quieres una hosted generation lane sencilla, esa respuesta es legítima.
Pero el caveat tiene que ir pegado al precio. La página de deprecations de Google ya lista imagen-4.0-fast-generate-001 con fecha de cierre 2026-06-24. Eso no invalida Imagen 4 Fast hoy, pero sí la convierte en una route más de corto horizonte que en un default de largo plazo.
gemini-2.5-flash-image batch exige aún más cuidado. Google publica \$0.0195/imagen en batch y \$0.039/imagen en standard. Ese batch row parece muy bueno porque también baja de mini high. Pero Google también marca 2026-10-02 como fecha de cierre para esa línea. Es un low row real, pero también con reloj.
Por eso la lectura útil de Google se reduce a tres frases:
- Imagen 4 Fast tiene sentido si quieres una route hosted de Google más barata que mini high
gemini-2.5-flash-imagebatch tiene sentido si aceptas una window de vida más corta- ninguna de las dos es más barata que mini low o mini medium
Mientras esas tres frases sigan visibles, la página no le estará prometiendo demasiado a Google.
BFL es más barato porque el trabajo cambia
Black Forest Labs entra en esta conversación por una razón distinta.
La pricing page actual da una lane realmente más barata de entrada: FLUX.2 [klein] 4B desde 0.014 y FLUX.2 [klein] 9B desde 0.015. Eso basta para competir contra mini high en ciertos casos. Pero no significa que de repente exista un clon de mini más barato para cualquier trabajo.
La propia página de BFL describe Klein como una route pensada para real-time, high-volume y un equilibrio diferente entre calidad y velocidad. Ahí está la clave: su ahorro viene porque el trabajo deja de parecerse al que resuelve mini en OpenAI y pasa a otra lane más low-end, más throughput-first y cobrada por megapixel.
Esa diferencia también ayuda a dejar fuera lo que no toca en este artículo. En la misma página, FLUX.1 Kontext [pro] sale a 0.04. Eso ya demuestra que no todo lo de BFL es más barato que mini. Kontext puede ser mejor cuando el coste real está en los retries y las ediciones, pero no pertenece al bucket de “más barato que mini” como respuesta por defecto. Si lo que necesitas es quality fit en lugar de price fit, la página correcta vuelve a ser GPT Image 1 Mini alternative.
Por eso la frase correcta aquí no es “FLUX es más barato”, sino esta: FLUX.2 Klein solo es una cheaper alternative real cuando aceptas una lane externa más low-end, más throughput-first y no una replacement uno a uno de mini.
Cuando el problema es setup y no precio
Una parte importante de este keyword mezcla problema de precio con problema de acceso.
La página actual de API Organization Verification de OpenAI deja varios puntos claros: la verificación desbloquea capacidades de imagen, no requiere spending thresholds, el estado puede tardar hasta 30 minutos en actualizarse y a menudo conviene generar una API key nueva si el error de “not verified” persiste. Nada de eso es pricing, pero sí cambia por completo la decisión.
La discusión actual de la comunidad sobre errores de rate limit en gpt-image-1 cuenta la misma historia desde el lado del usuario. Hay gente que ni siquiera llega a generar una imagen antes de encontrarse con 429, estados raros de tier o claves que necesitan regenerarse. Esa experiencia hace que todo parezca caro, pero sigue siendo setup friction.
Por eso conviene dejar una regla muy simple y muy visible: si el bloqueo está en tier, verification, route o account state, arréglalo primero y luego vuelve a comparar precios. Si no haces esa separación, no estás comparando economics; estás comparando experiencias de fallo.
Si lo que quieres es dejar limpia la integración de OpenAI antes de decidir si migras, la lectura más útil es OpenAI image API tutorial.
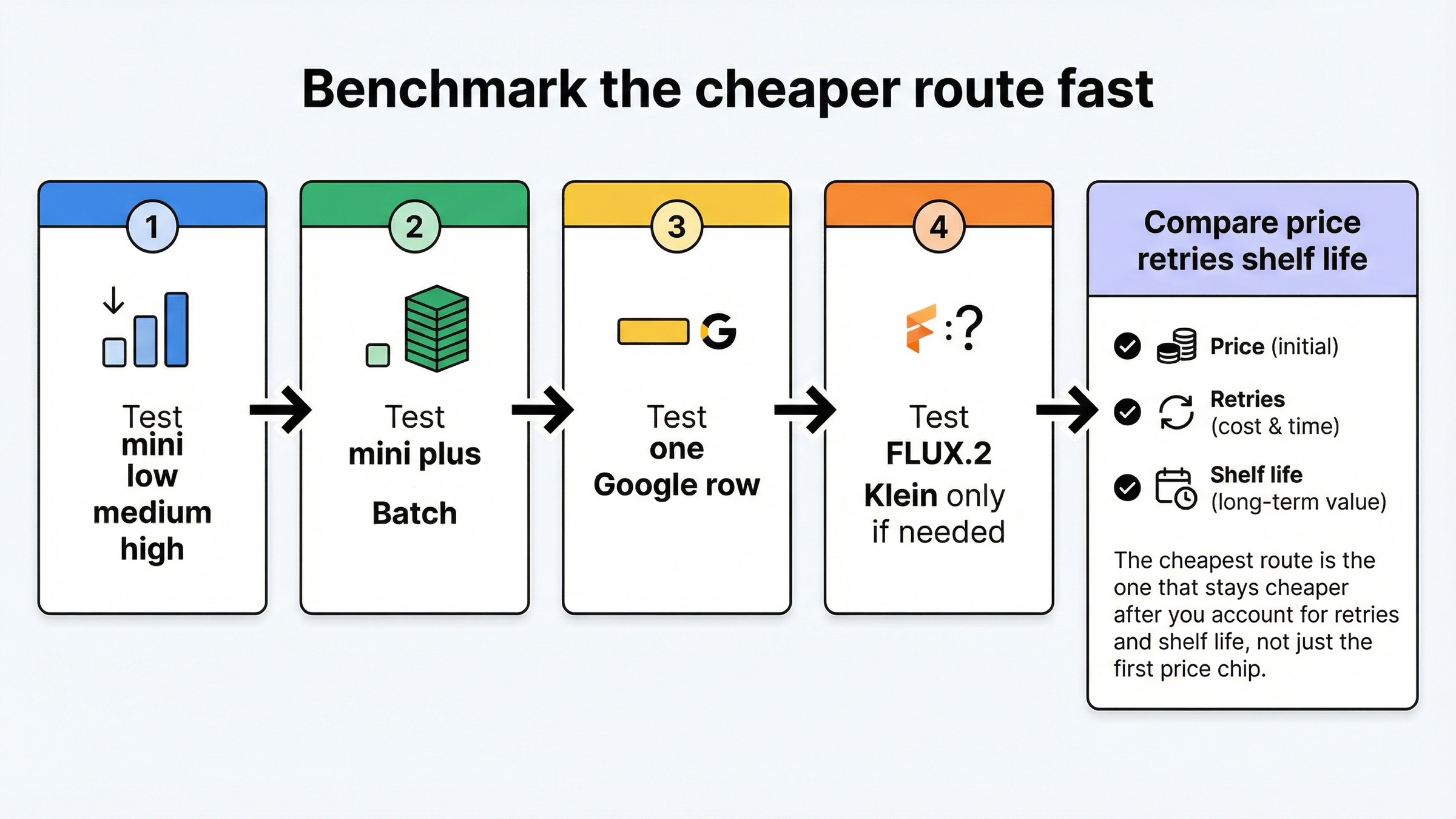
Cómo probaría la route más barata en una tarde
No empieces por la marca. Empieza por el coste real que quieres bajar.
- Ejecuta primero mini low, medium y high. Si ni siquiera sabes con qué fila estás comparando, este keyword ya está mal planteado.
- Si la carga puede ir en cola, prueba mini + Batch. Suele ser la primera route de ahorro seria porque sigues dentro de la misma familia.
- Después añade una sola route de Google, no varias a la vez. Si el problema es mini high, compara Imagen 4 Fast o
gemini-2.5-flash-imagebatch, pero no ensucies el benchmark con rutas que no responden al mismo coste. - Añade FLUX.2 Klein solo si de verdad aceptas una lane más low-end y de alto throughput.
- Compara al final tres cosas: precio por keepable image, número de retries y cuánto tiempo de vida real tiene la route.
Ese último punto es justo el que los comparadores amplios casi nunca dejan claro. La row más barata no es toda la respuesta. La route más barata es la que sigue siendo barata después de contar retries, fricción y shelf life.
FAQ
¿Existe hoy una hosted API mainstream claramente más barata que gpt-image-1-mini en general?
No. Las filas externas que hoy parecen más baratas solo ganan frente a mini high, o dependen de Batch, o cambian lo suficiente el trabajo como para que ya no estés comprando lo mismo que con mini.
Si quiero seguir en mini, ¿qué debería probar primero?
Primero confirma si mini low o mini medium ya alcanzan el objetivo. Después prueba Batch si el trabajo puede ser asíncrono. Suele ser la primera palanca de ahorro honesta antes de plantear una migración.
¿Debería pasarme a Google solo porque veo un precio más bajo?
Solo si tu comparación real es contra mini high y aceptas la fecha de cierre de la route. Imagen 4 Fast y gemini-2.5-flash-image batch pueden parecer más baratas en ese marco estrecho, pero no ganan a mini low ni a mini medium.
Conclusión
La alternativa más barata a gpt-image-1-mini no es otro ganador universal.
Si lo que quieres es seguir bajando coste, quédate en mini y prueba Batch primero. Si tu comparación real es contra mini high, entonces las rows baratas de Google empiezan a tener sentido. Si aceptas una route externa más low-end y de alto throughput, FLUX.2 Klein puede encajar. Y si ahora mismo estás bloqueado por verificación, tier o route choice, arregla setup antes de convertirlo en una decisión de vendor.
Ese es el punto que el SERP todavía no deja claro: mini ya es el floor. La decisión real no es “qué modelo nuevo es más barato”, sino si debes abaratar el mismo modelo, abaratar el workflow o dejar de leer un problema de setup como si fuera un problema de pricing.