
Comparing OpenAI API with alternatives in 2026? Here's the essential breakdown: GPT-4o costs $2.50 input/$10 output per million tokens, Claude 3.5 Sonnet offers $3/$15 with 200K context, and Gemini 2.5 Pro provides up to 2M tokens context at $1.25-$2.50 input. This comprehensive guide covers real-world pricing comparisons, detailed feature matrices, and step-by-step migration code examples to help you make the right choice for your specific use case.
TL;DR
Here's what you need to know about the major AI API platforms in 2026:
- OpenAI GPT-4o: Industry standard at $2.50/$10 per 1M tokens, 128K context, best ecosystem and SDK support
- Anthropic Claude 3.5 Sonnet: Premium at $3/$15, 200K context, superior coding performance and 90% prompt caching savings
- Google Gemini 2.5 Pro: Competitive at $1.25-$2.50 input, up to 2M context, free tier with 60 RPM
- Azure OpenAI: Same pricing as OpenAI, enterprise-grade security with SOC 2/HIPAA compliance
The right choice depends on your priorities: cost optimization (Gemini), coding quality (Claude), ecosystem maturity (OpenAI), or enterprise requirements (Azure).
Meet the Contenders - AI API Platforms Overview
The AI API landscape has matured significantly, with four major platforms competing for developers' attention. Each platform has carved out its own niche, offering distinct advantages that cater to different use cases and organizational requirements. Understanding these differences is crucial before diving into specific pricing and feature comparisons.
OpenAI remains the pioneer and market leader, having established the foundation for modern AI APIs with the GPT series. Their developer ecosystem is the most mature, with extensive documentation, community resources, and third-party integrations. Most AI tutorials and code examples you'll find online default to OpenAI's API format, making it the path of least resistance for many developers. The company continues to innovate with features like function calling, which has become an industry standard that competitors now emulate.
Anthropic, founded by former OpenAI researchers, has positioned Claude as the thinking developer's choice. Their focus on AI safety translates into models that excel at nuanced reasoning and following complex instructions. Claude has earned a particularly strong reputation in the developer community for coding tasks, where its ability to understand context and generate accurate code rivals or exceeds GPT-4. Anthropic's Constitutional AI approach results in models that are notably better at refusing harmful requests while remaining helpful for legitimate use cases.
Google's Gemini brings the might of Google's infrastructure and research to the API market. The platform's standout feature is its massive context window, capable of processing up to 2 million tokens in a single request. This capability opens up use cases that were previously impossible, such as analyzing entire codebases or processing lengthy documents without chunking. Google also offers the most generous free tier among major providers, making it an attractive option for experimentation and smaller projects.
Azure OpenAI provides access to OpenAI's models through Microsoft's enterprise cloud infrastructure. While the underlying models are identical to OpenAI's direct offerings, Azure adds enterprise-grade features like virtual network integration, private endpoints, and comprehensive compliance certifications. For organizations already invested in the Microsoft ecosystem or those with strict security requirements, Azure OpenAI provides a familiar and trusted platform.
If you're new to API access and need guidance on the basics, check out our complete guide to getting your OpenAI API key before diving into the comparisons below.
The competitive landscape continues to evolve rapidly. Just in the past year, we've seen dramatic price reductions across all platforms, context windows expanding by orders of magnitude, and multimodal capabilities becoming standard. The platform you choose today might not be your choice tomorrow, which makes understanding the migration paths and aggregator options particularly valuable. Building abstraction layers into your AI integrations from the start saves significant refactoring later as the market continues to shift.
What's particularly interesting is how each platform has responded to competitive pressure. OpenAI has focused on ecosystem depth and developer experience improvements. Anthropic has doubled down on safety and reasoning capabilities while slashing prompt caching costs. Google has pushed technical boundaries with massive context windows and multimodal innovations. Azure has strengthened enterprise integrations and compliance certifications. This differentiation means there's genuinely no single best platform—the right choice depends entirely on your specific requirements.
Pricing Comparison - The Real Numbers
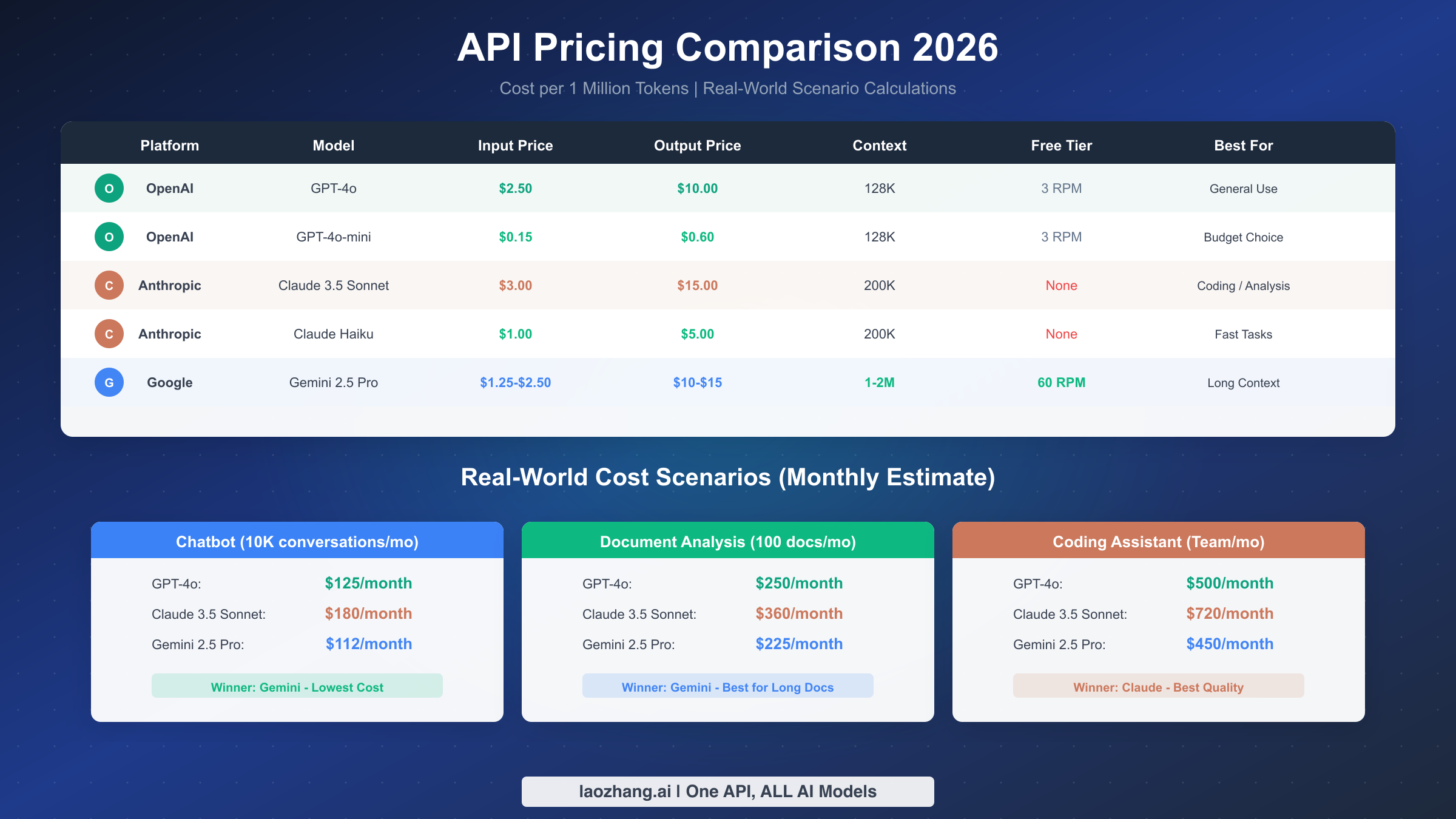
Understanding API pricing is essential for making informed decisions about which platform to use. The costs can vary dramatically depending on your usage patterns, and what looks cheap on paper might become expensive in practice. Let's break down the real numbers based on verified pricing data from January 2026.
OpenAI's pricing structure follows a straightforward input/output model. GPT-4o, their flagship model, charges $2.50 per million input tokens and $10.00 per million output tokens. The more economical GPT-4o-mini offers substantial savings at $0.15 input and $0.60 output per million tokens, making it suitable for high-volume applications where top-tier performance isn't critical. OpenAI also provides automatic prompt caching that can reduce input costs by 50% for repeated prompts within 5-10 minutes. For a deeper dive into OpenAI's pricing tiers and how to optimize costs, see our detailed OpenAI API pricing breakdown.
Anthropic's Claude commands premium pricing that reflects its performance advantages. Claude 3.5 Sonnet costs $3.00 input and $15.00 output per million tokens, while the faster Claude Haiku offers $1.00 input and $5.00 output. What sets Anthropic apart is their aggressive prompt caching discount—cached prompts cost 90% less, the best rate in the industry. This makes Claude particularly cost-effective for applications with repetitive prompts, such as coding assistants that repeatedly process the same system instructions. Our Claude API pricing details cover optimization strategies in depth.
Google Gemini presents the most competitive pricing combined with the only meaningful free tier among major providers. Gemini 2.5 Pro ranges from $1.25 to $2.50 for input tokens (depending on context length) and $10 to $15 for output. The free tier provides 60 requests per minute at no cost, which is genuinely usable for development and small-scale production. Gemini also offers custom TTL prompt caching, though it requires paid storage. See our Gemini API pricing structure for complete tier information.
Azure OpenAI matches OpenAI's pricing exactly but operates on a different billing model tied to Azure subscriptions. The value proposition isn't in cost savings but in enterprise features like reserved capacity, private networking, and consolidated billing with other Azure services.
Real-World Cost Scenarios
Abstract per-token pricing doesn't tell the full story. Here's what these numbers mean in practical scenarios, calculated based on typical usage patterns:
Chatbot Application (10,000 conversations per month): Assuming an average of 500 input tokens and 500 output tokens per conversation, your monthly costs would be approximately $125 with GPT-4o, $180 with Claude 3.5 Sonnet, and $112 with Gemini 2.5 Pro. For budget-conscious deployments, GPT-4o-mini drops this to roughly $8 per month, making AI-powered chatbots accessible even for small projects.
Document Analysis (100 long documents per month): Processing 50,000-token documents with 2,000-token summaries changes the calculus. GPT-4o would cost around $250 monthly, Claude about $360, and Gemini approximately $225. However, Gemini's ability to process entire documents without chunking (thanks to its 2M context window) can reduce complexity and improve accuracy.
Coding Assistant (Development team usage): A team generating 50,000 tokens of code output daily, with 100,000 tokens of context input, would spend approximately $500/month on GPT-4o, $720 on Claude 3.5 Sonnet, or $450 on Gemini. Despite the higher cost, many teams choose Claude for coding due to its superior code quality, finding the investment worthwhile.
Hidden Costs and Pricing Pitfalls
Beyond the headline rates, several factors can significantly impact your actual costs. Understanding these nuances prevents budget surprises and helps you optimize spending from day one.
Token counting differences matter more than most developers realize. While all platforms use similar tokenization schemes, the exact mappings vary. A prompt that tokenizes to 1,000 tokens on OpenAI might become 1,100 or 900 tokens on Claude or Gemini. For high-volume applications, these differences compound. The safest approach is to test representative samples across platforms before committing, using each provider's tokenization API to get accurate estimates.
Rate limit tiers can force you into higher spending brackets than pure token costs would suggest. If your application needs higher throughput than the free tier provides, you might pay significantly more just to unlock rate limits rather than for actual token usage. OpenAI's tier system, for example, requires substantial spending history to access higher rate limits, which can bottleneck growing applications.
Retry and error handling costs often surprise teams. When requests fail due to rate limits or temporary outages, retry attempts consume additional tokens. Platforms differ in how they handle partial failures—some count tokens even for failed requests, while others refund them. Building robust retry logic with exponential backoff reduces these hidden costs significantly.
Regional pricing and compliance overhead add costs for global applications. If you need to route requests through specific regions for data residency requirements, you may face higher latency, which increases token usage for interactive applications. Azure OpenAI's regional deployment options provide control but require careful architecture planning.
Feature Deep Dive - Capabilities That Matter

Beyond pricing, the functional capabilities of each platform can make or break your application. These differences become particularly important as you scale or tackle specialized use cases. Let's examine the features that matter most to developers and enterprises.
Context window size represents one of the most significant differentiators. OpenAI's GPT-4o and Azure OpenAI support 128K tokens, which handles most use cases comfortably. Claude extends this to 200K tokens, providing extra headroom for document-heavy applications. Gemini 2.5 Pro dominates this category with support for 1-2 million tokens, enabling entirely new application categories like codebase analysis or processing entire books in a single prompt. This isn't just a marketing number—developers report successfully processing 100+ file repositories in single API calls.
Multimodal capabilities have become table stakes, but implementation quality varies. All four platforms now support image input, allowing you to send screenshots, diagrams, or photographs for analysis. Audio input is available on OpenAI, Google, and Azure, with Anthropic requiring a separate API for speech processing. Video understanding remains Gemini's exclusive advantage—you can upload video files directly to the API for analysis, a capability that no competitor currently matches.
Prompt Caching Deep Comparison
Prompt caching has emerged as a critical cost optimization feature, but the implementations differ substantially across platforms. Understanding these differences can save you significant money on production workloads.
OpenAI's automatic caching activates when you reuse the same prompt prefix within a 5-10 minute window. Cached input tokens cost 50% less, with no configuration required. This works well for typical chat applications but provides limited control. The cache duration resets on each hit, so active conversations maintain their cache indefinitely.
Anthropic's explicit caching offers the most aggressive discounts—cached reads cost only 10% of standard input rates (90% savings). However, initial cache writes incur a 25% premium, so the feature only pays off when you hit the cache multiple times. The 5-minute TTL is shorter than OpenAI's, requiring careful prompt design to maximize hits. For applications like coding assistants that repeatedly process the same instructions, Claude's caching provides substantial savings.
Google's context caching takes a different approach, charging for cached storage based on time and token count. You get full control over cache TTL, from minutes to hours, but must actively manage cache lifecycles. This model works well for batch processing scenarios where you process many requests against the same context.
Enterprise Security and Compliance
For organizations with regulatory requirements, security features often drive platform selection regardless of pricing or performance. The platforms differ significantly in their compliance postures and security architectures.
SOC 2 Type II certification is now standard across all four platforms, providing baseline assurance for data handling practices. However, the depth of compliance varies. Azure OpenAI leads with the most comprehensive certification portfolio, including FedRAMP High authorization for government workloads, HIPAA BAA for healthcare, and industry-specific attestations for financial services.
Data handling policies reveal important philosophical differences. Anthropic commits to zero data retention for API customers—your prompts and completions never train their models and are deleted after processing. OpenAI offers similar opt-out options but defaults to using API data for training unless explicitly disabled. Google's data practices fall between these extremes, with clear retention policies but more complex opt-out procedures.
Network security options matter for sensitive deployments. Azure OpenAI supports virtual network integration and private endpoints, keeping traffic entirely within your Azure infrastructure. OpenAI and Anthropic offer IP allowlisting and API key rotation, but traffic traverses the public internet. Google Cloud's VPC Service Controls provide network isolation for Gemini, though configuration is more complex than Azure's approach.
Performance and Reliability Comparison
Beyond features listed on marketing pages, real-world performance characteristics significantly impact production applications. Latency, throughput, and uptime patterns vary notably across providers and deserve careful consideration.
Response latency varies by model, request complexity, and time of day. In typical conditions, OpenAI and Claude deliver first-token responses in 200-400ms for most requests, with full responses completing in 1-3 seconds for average-length outputs. Gemini tends to run slightly slower, particularly for its larger context models, with first-token latency often reaching 500-800ms. Azure OpenAI matches OpenAI's performance in most scenarios but may exhibit additional latency depending on your deployment region and network configuration.
Streaming performance matters significantly for interactive applications. All four platforms support streaming responses, but the consistency differs. OpenAI provides the smoothest streaming experience with even token delivery, while Claude occasionally exhibits bursting patterns where tokens arrive in clusters. For chat interfaces where users watch text appear in real-time, these differences affect perceived quality even when total response time is similar.
Uptime and reliability have improved across the board, but historical patterns differ. OpenAI has experienced several high-profile outages during peak usage periods, particularly around major launches. Claude historically showed better stability but with occasional API endpoint issues. Gemini's free tier is more prone to rate limiting and degraded performance during high-demand periods. Azure OpenAI benefits from Azure's enterprise SLA commitments, providing the most formal reliability guarantees.
Capacity planning requires understanding each provider's scaling characteristics. OpenAI uses a tiered system where spending history unlocks higher rate limits. Anthropic offers higher default limits but requires enterprise agreements for the highest tiers. Google provides the most generous free limits but paid tier capacity requires GCP capacity planning. For applications expecting significant growth, understanding these scaling paths prevents bottlenecks.
The Aggregator Approach - One Key for All Models
If comparing individual platforms feels overwhelming, there's an alternative approach gaining traction: API aggregators that provide unified access to multiple models through a single integration. This approach solves several practical problems that become apparent as organizations mature their AI strategies.
The multi-model problem emerges naturally as teams experiment with different platforms. You might discover that Claude excels at code review, GPT-4o handles customer service conversations better, and Gemini's long context is perfect for document summarization. Managing separate API keys, billing relationships, and integration code for each platform creates operational overhead that scales poorly.
API aggregator platforms like laozhang.ai provide a unified interface to multiple models. You integrate once using an OpenAI-compatible API format, then route requests to any supported model by simply changing the model parameter. Billing consolidates to a single invoice, and you gain the flexibility to switch models without code changes.
The practical benefits extend beyond convenience. Aggregators often provide:
- Unified rate limiting and queuing: Automatically handle retry logic and rate limits across providers
- Cost optimization tools: Dashboard visibility into spending across models, with suggestions for cost reduction
- Failover capabilities: Automatic routing to backup models if your primary choice experiences downtime
- Simplified compliance: Single vendor relationship simplifies procurement and security reviews
For teams that need multiple models or want flexibility to experiment, the aggregator approach reduces complexity while maintaining access to best-in-class capabilities from each provider. The marginal cost premium is often offset by reduced integration time and operational overhead.
Implementing Multi-Model Architecture
Moving beyond single-provider integration requires thoughtful architecture decisions. The most successful implementations share several common patterns that balance flexibility with maintainability.
Router-based architectures make intelligent decisions about which model handles each request. A central router component examines incoming requests—looking at task type, user tier, content length, or explicit routing hints—and directs them to the appropriate provider. This pattern enables A/B testing, gradual migrations, and cost optimization without client changes. The router can be as simple as a switch statement or as sophisticated as an ML-based classifier.
Fallback chains provide resilience against provider outages. When your primary model fails or returns errors, the system automatically tries alternative providers. This pattern requires careful thought about response compatibility—if Claude's output format differs from GPT-4o's, your application must handle both. Using OpenAI-compatible API formats across an aggregator like laozhang.ai simplifies this significantly.
Cost-aware routing optimizes spending in real-time. By tracking per-request costs and accumulated spending, routers can shift traffic between equivalent models based on budget constraints. This approach particularly benefits applications with variable workloads, directing overflow traffic to cheaper alternatives during peak periods while maintaining quality for priority requests.
Quality-based routing leverages each model's strengths. Coding tasks route to Claude for its superior code generation. Long-document analysis goes to Gemini for its extended context. Customer-facing conversations use GPT-4o for its conversational fluidity. This specialization improves overall quality while potentially reducing costs by avoiding overkill for simple tasks.
The implementation complexity of multi-model architectures pays dividends as your AI usage matures. Starting with a simple abstraction layer—even if initially routing everything to a single provider—makes future optimization much easier than retrofitting a tightly-coupled integration.
Migration Guide - Switching Made Easy
Switching AI providers doesn't have to mean rewriting your application from scratch. The major platforms have converged on similar API patterns, making migration straightforward with proper planning. Here's practical code for the most common migration paths.
OpenAI to Anthropic Claude Migration
The core concepts translate directly: messages become conversations, system prompts map to system parameters, and response handling follows similar patterns. Here's a complete migration example in Python:
pythonfrom openai import OpenAI openai_client = OpenAI(api_key="your-openai-key") def chat_openai(user_message: str, system_prompt: str = "You are a helpful assistant."): response = openai_client.chat.completions.create( model="gpt-4o", messages=[ {"role": "system", "content": system_prompt}, {"role": "user", "content": user_message} ], max_tokens=1000 ) return response.choices[0].message.content # Anthropic Claude Migration from anthropic import Anthropic claude_client = Anthropic(api_key="your-anthropic-key") def chat_claude(user_message: str, system_prompt: str = "You are a helpful assistant."): response = claude_client.messages.create( model="claude-3-5-sonnet-20241022", system=system_prompt, # System prompt is a separate parameter messages=[ {"role": "user", "content": user_message} ], max_tokens=1000 ) return response.content[0].text # Response structure differs slightly
Key differences to note: Claude accepts the system prompt as a separate parameter rather than a message, and the response content is accessed through response.content[0].text rather than response.choices[0].message.content. Error handling patterns are similar, with both libraries raising specific exception types for rate limits, authentication failures, and API errors.
OpenAI to Google Gemini Migration
Gemini's API structure differs more significantly, but the concepts remain consistent:
python# OpenAI Original Implementation from openai import OpenAI openai_client = OpenAI(api_key="your-openai-key") def chat_openai(user_message: str): response = openai_client.chat.completions.create( model="gpt-4o", messages=[{"role": "user", "content": user_message}], max_tokens=1000 ) return response.choices[0].message.content # Google Gemini Migration import google.generativeai as genai genai.configure(api_key="your-gemini-key") model = genai.GenerativeModel("gemini-2.5-pro") def chat_gemini(user_message: str): response = model.generate_content( user_message, generation_config=genai.GenerationConfig( max_output_tokens=1000 ) ) return response.text
For JavaScript applications, here's the equivalent migration:
javascript// OpenAI Original import OpenAI from 'openai'; const openai = new OpenAI({ apiKey: 'your-openai-key' }); async function chatOpenAI(message) { const response = await openai.chat.completions.create({ model: 'gpt-4o', messages: [{ role: 'user', content: message }], max_tokens: 1000 }); return response.choices[0].message.content; } // Anthropic Claude Migration import Anthropic from '@anthropic-ai/sdk'; const anthropic = new Anthropic({ apiKey: 'your-anthropic-key' }); async function chatClaude(message) { const response = await anthropic.messages.create({ model: 'claude-3-5-sonnet-20241022', max_tokens: 1000, messages: [{ role: 'user', content: message }] }); return response.content[0].text; }
Migration Best Practices
Beyond the code changes, successful migrations require attention to several practical concerns:
Prompt optimization often yields better results than direct translation. Each model has different strengths—Claude responds well to detailed context and explicit reasoning requests, while Gemini excels with structured output formats. Invest time in prompt engineering after migration to maximize quality.
Gradual rollout reduces risk. Start by routing a small percentage of production traffic to the new provider, monitoring for quality and performance issues. Most teams find that 1-2 weeks of parallel running reveals edge cases that testing misses.
Cost monitoring during migration prevents surprises. Set up spending alerts before switching, as usage patterns that were economical on one platform might prove expensive on another. The token counting methods differ subtly between providers, sometimes resulting in higher-than-expected charges.
Common Migration Challenges and Solutions
Real-world migrations rarely go exactly as planned. Anticipating common issues accelerates your migration timeline and reduces production incidents.
Response format inconsistencies catch many teams off-guard. Even for simple text completions, models differ in formatting, whitespace handling, and punctuation preferences. Claude tends toward more formal language and longer sentences. GPT-4o is more conversational. Gemini varies significantly based on prompt structure. If your application parses model outputs programmatically, expect to adjust parsing logic.
Prompt sensitivity differences require re-optimization. A prompt that works perfectly on OpenAI might underperform on Claude or vice versa. System prompts particularly benefit from model-specific tuning. Claude responds well to clear role definitions and explicit constraints, while GPT-4o handles more implicit instructions effectively. Budget time for prompt engineering as part of any migration.
Function calling compatibility has improved but isn't perfect. OpenAI originated the function/tool calling paradigm, and while Claude and Gemini have adopted similar patterns, edge cases exist. Complex schemas, optional parameters, and nested objects sometimes behave differently. Test your tool definitions thoroughly on the target platform before production migration.
Streaming and timeout handling requires adjustment. The timing characteristics differ between providers—chunk sizes, connection behavior, and timeout defaults all vary. Applications that worked fine with OpenAI's streaming might need adjusted buffer sizes or timeout values for Claude or Gemini. Monitor for timeout errors during migration testing.
Rate limit and retry logic needs platform-specific tuning. The error codes, retry-after headers, and backoff recommendations differ between providers. A retry implementation optimized for OpenAI's rate limiting might behave suboptimally on other platforms. Review each provider's documentation for their specific retry recommendations.
Which Platform Should You Choose?
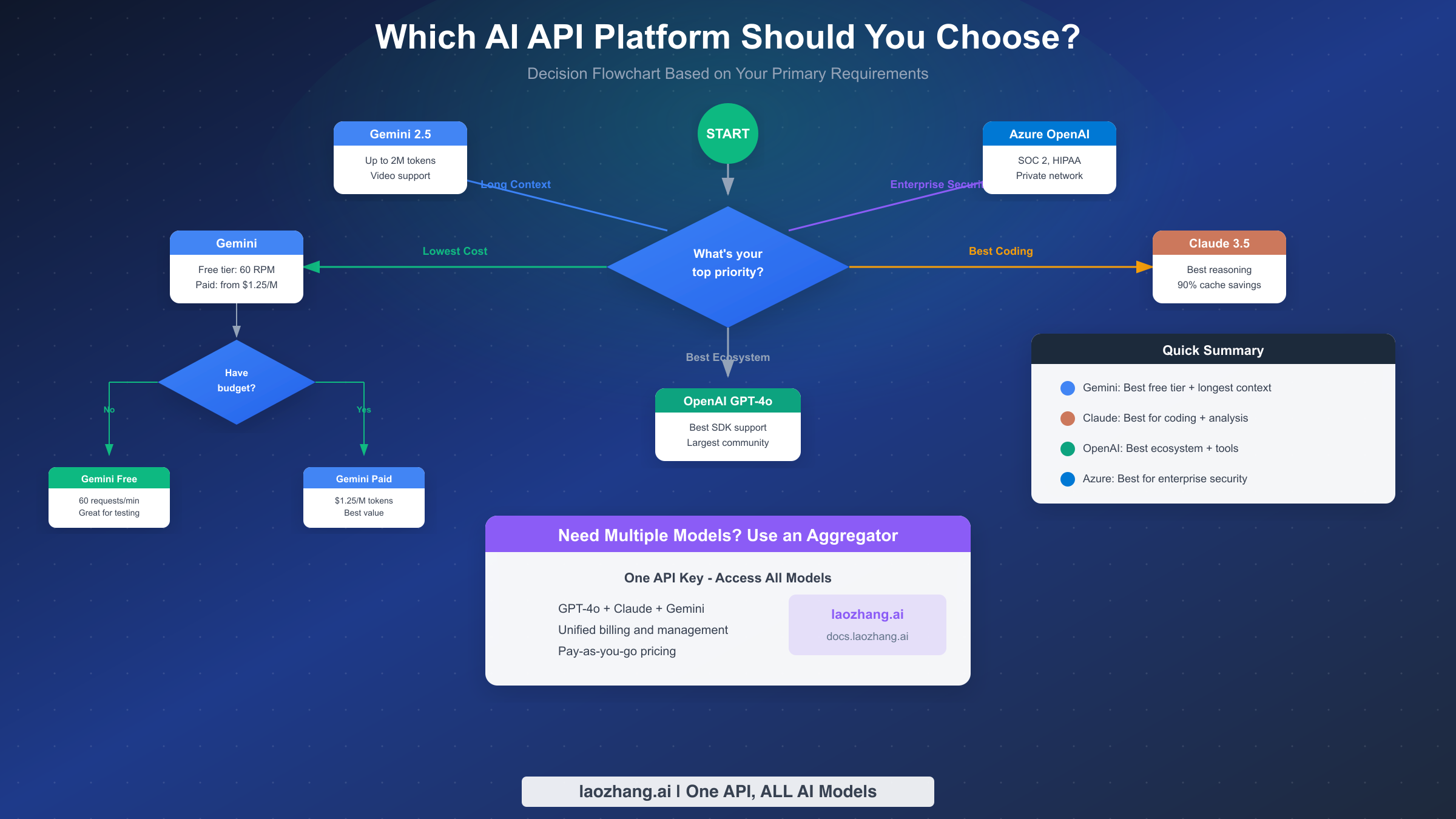
After examining pricing, features, and migration paths, the choice ultimately depends on your specific priorities. Here's a decision framework based on common use cases and requirements.
Choose OpenAI GPT-4o if you value ecosystem maturity and developer experience. OpenAI's documentation, community resources, and third-party integrations are unmatched. Most AI tutorials assume OpenAI's API, reducing learning curve. The function calling implementation is the most robust, and you'll find the widest selection of SDKs and tools. This is the safe, well-traveled path—not always the cheapest or most powerful, but reliable and well-supported.
Choose Anthropic Claude if your application is code-heavy or requires careful reasoning. Claude consistently outperforms competitors on coding benchmarks and complex multi-step tasks. The 90% prompt caching discount makes it surprisingly economical for applications with repetitive prompts. Claude's safety-focused training also produces outputs that require less filtering, reducing moderation costs. For development tools, IDE integrations, and code generation applications, Claude is increasingly the default choice among experienced teams.
Choose Google Gemini if cost optimization or long-context processing is your priority. The free tier provides genuine utility for development and small-scale production. The 2M token context window enables use cases impossible on other platforms—analyzing entire codebases, processing lengthy legal documents, or maintaining conversation history across thousands of messages. If you're processing long documents or building applications that benefit from extensive context, Gemini's technical advantages justify its slightly less mature ecosystem.
Choose Azure OpenAI if enterprise security requirements drive your decisions. The Microsoft integration provides familiar security controls, compliance certifications, and procurement processes for large organizations. Virtual network integration keeps sensitive data within your infrastructure. For healthcare, financial services, or government applications, Azure's compliance portfolio often makes it the only viable option regardless of other considerations.
The Multi-Model Strategy
Increasingly, sophisticated teams adopt a multi-model approach rather than selecting a single provider. This strategy assigns different models to different tasks based on their strengths:
- Routing simple queries to GPT-4o-mini or Claude Haiku for cost efficiency
- Sending coding tasks to Claude 3.5 Sonnet for quality
- Processing long documents with Gemini 2.5 Pro's extended context
- Handling sensitive enterprise data through Azure OpenAI's secure infrastructure
This approach requires more integration work initially but optimizes for both cost and quality across diverse use cases. API aggregator platforms like laozhang.ai simplify this architecture by providing unified access through a single integration.
For those interested in exploring free options while evaluating platforms, our guide to free Gemini API access covers the most generous free tier available today.
Future-Proofing Your AI Integration
The AI landscape evolves rapidly, and today's optimal choice might not remain optimal next year. Building flexibility into your integration from the start saves significant refactoring costs.
Abstraction layers provide the most straightforward protection. Rather than calling provider APIs directly throughout your codebase, centralize AI interactions behind an internal interface. This layer can start simple—just wrapping API calls—and grow to include routing, caching, and monitoring. When you need to switch providers or add new models, changes happen in one place rather than scattered across your application.
Feature flag systems enable gradual transitions between providers. By wrapping model selection in feature flags, you can shift traffic between providers without deployments. This capability proves valuable for testing new models, responding to outages, and optimizing costs in real-time.
Monitoring and observability provide the data needed for informed decisions. Track not just costs but also latency, error rates, and quality metrics across providers. When a new model releases or pricing changes, this data tells you whether switching makes sense for your specific workload.
Regular evaluation cycles keep your stack current. Set calendar reminders to reassess your platform choices quarterly. The AI API market changes fast—a provider that was expensive last quarter might have slashed prices, or a new model might dramatically outperform your current choice. Teams that evaluate regularly capture these opportunities.
Frequently Asked Questions
Is Azure OpenAI cheaper than OpenAI direct?
No, the per-token pricing is identical. Azure OpenAI's value comes from enterprise features like virtual network integration, private endpoints, and consolidated billing with other Azure services. You might see cost benefits through Azure commitment discounts or reserved capacity pricing, but the base API costs match OpenAI's direct pricing.
What is the best alternative to OpenAI API for coding?
Anthropic's Claude 3.5 Sonnet consistently ranks as the top choice for coding applications. Independent benchmarks show Claude outperforming GPT-4 on code generation, debugging, and code review tasks. The 90% prompt caching discount also makes Claude cost-effective for coding assistants that repeatedly process the same instructions and context.
How does Claude compare to GPT-4?
Claude 3.5 Sonnet and GPT-4o are broadly comparable in capability, with each excelling in different areas. Claude tends to produce better code and follow complex instructions more reliably, while GPT-4o has superior function calling and a more mature ecosystem. For conversational AI and general-purpose applications, the difference is often negligible; for specialized tasks, testing both is recommended.
Is Gemini API really free?
Yes, Google offers a genuine free tier with 60 requests per minute at no cost. This covers Gemini's capable models and includes vision capabilities. The free tier is sufficient for development, testing, and small-scale production applications. Paid tiers offer higher rate limits and additional features but aren't required to get started.
Can I use multiple AI APIs together?
Absolutely. Many production applications route different requests to different providers based on task requirements. API aggregator platforms like laozhang.ai simplify this by providing unified access to multiple models through a single API integration. You can switch between GPT-4o, Claude, and Gemini by changing a single model parameter without managing separate integrations.
Which platform has the longest context window?
Google Gemini 2.5 Pro leads with support for 1-2 million tokens in a single request, far exceeding competitors. Claude offers 200K tokens, while OpenAI and Azure OpenAI support 128K tokens. The context window matters most for applications processing long documents, maintaining extensive conversation history, or analyzing large codebases.
How do I optimize costs when using AI APIs?
Several strategies significantly reduce API costs across all providers. First, implement prompt caching effectively—Claude offers 90% savings on cached reads, and OpenAI provides 50% discounts for repeated prompts. Second, use appropriate model tiers: route simple queries to cheaper models like GPT-4o-mini or Claude Haiku rather than always using flagship models. Third, optimize your prompts to be concise while still effective—unnecessary verbose instructions waste tokens. Fourth, consider batch processing where latency permits, as some providers offer better rates for async workloads. Finally, API aggregators like laozhang.ai can help optimize routing and provide consolidated billing visibility.
What's the learning curve for switching platforms?
For developers familiar with one platform, switching to another typically takes 1-2 days of focused work for basic integration, and 1-2 weeks to optimize for production quality. The core concepts translate directly—all platforms use message-based conversations with system prompts, user messages, and assistant responses. The main learning curve involves understanding platform-specific features like prompt caching, function calling nuances, and model-specific prompt optimization. Teams that abstract their AI calls behind an internal interface find switching much easier than those with direct API calls throughout their codebase.
Should I use an API aggregator or integrate directly?
The answer depends on your scale and requirements. For simple single-model applications, direct integration is straightforward and avoids the additional dependency. However, as your needs grow to include multiple models, cost optimization, or high-availability requirements, aggregators provide significant value. They simplify multi-model routing, consolidate billing, and provide fallback capabilities that would otherwise require custom engineering. The marginal cost overhead is typically 10-20% but is often recovered through better routing and reduced integration time. For enterprise deployments requiring strict compliance, evaluate whether the aggregator meets your security requirements.
How reliable are the free tiers for production use?
Free tiers serve development and small-scale production adequately but shouldn't be relied upon for critical applications. Google's Gemini free tier at 60 RPM is the most generous and handles reasonable development and testing workloads. However, free tiers typically offer no SLA guarantees, may experience rate limiting during peak periods, and could change or disappear with minimal notice. For production applications with real users depending on reliability, budget for paid tiers that include SLA commitments. Use free tiers for exploration, prototyping, and development environments rather than production backends.
What happens if a provider has an outage?
Outages occur on all platforms periodically, though frequency and duration vary. OpenAI has historically experienced outages during high-demand periods, particularly around major announcements. Having a fallback strategy is prudent for production applications. Options include: maintaining integration with a backup provider that can handle traffic during outages, implementing graceful degradation that queues requests for later processing, or using an API aggregator with automatic failover. Monitor each provider's status pages and consider subscribing to incident notifications. For business-critical applications, negotiate SLAs that include incident credits and understand the escalation paths for reporting issues.