
The OpenAI API has revolutionized how developers integrate artificial intelligence into their applications, powering everything from chatbots to content generation systems. At the heart of this integration lies the OpenAI API key – your gateway to accessing GPT-4, GPT-3.5, DALL-E, and other cutting-edge AI models. However, as powerful as these APIs are, their costs can quickly escalate, especially for startups and individual developers. This comprehensive guide will walk you through everything you need to know about OpenAI API keys, from initial setup to advanced implementation strategies, while introducing a game-changing solution that can reduce your API costs by up to 70%.
Understanding OpenAI API Keys
An OpenAI API key is a unique alphanumeric string that serves as your authentication credential when making requests to OpenAI's services. Think of it as a digital passport that identifies your account and tracks your usage for billing purposes. These keys typically follow the format sk-... followed by a long string of characters, and they're essential for accessing any of OpenAI's programmatic interfaces.
The API key system serves multiple critical functions in the OpenAI ecosystem. First and foremost, it provides secure authentication, ensuring that only authorized users can access the powerful AI models. This security layer protects both OpenAI's infrastructure and your account from unauthorized usage. Additionally, API keys enable precise usage tracking, allowing OpenAI to monitor requests, calculate costs, and enforce rate limits based on your subscription tier.
Behind the scenes, when you make an API request, your key is validated against OpenAI's authentication servers. This process happens in milliseconds, checking not only the key's validity but also your account status, available credits, and rate limit allowances. The system then logs the request details, including the model used, tokens consumed, and timestamp, creating a comprehensive audit trail for billing and analytics purposes.
The architecture supporting API keys is designed with redundancy and security in mind. OpenAI employs industry-standard encryption protocols to protect keys in transit and at rest. Each key is associated with specific permissions and scopes, allowing for granular control over what actions can be performed. This design philosophy extends to the API endpoints themselves, which are distributed across multiple data centers to ensure reliability and low latency regardless of your geographic location.
Understanding the technical foundations of API keys helps developers make informed decisions about implementation strategies. For instance, knowing that each API call incurs overhead for authentication and logging can guide decisions about request batching and caching strategies. Similarly, understanding the relationship between API keys and rate limits can help in designing systems that gracefully handle throttling scenarios.
How to Get Started with OpenAI API Keys
Getting started with OpenAI API keys requires a systematic approach to ensure smooth integration into your development workflow. The journey begins with creating an OpenAI account, a process that has evolved significantly since the platform's public launch. Navigate to platform.openai.com and complete the registration process, which includes email verification and acceptance of the terms of service. OpenAI has implemented additional verification steps for new accounts, including phone number verification, to prevent abuse and ensure platform integrity.
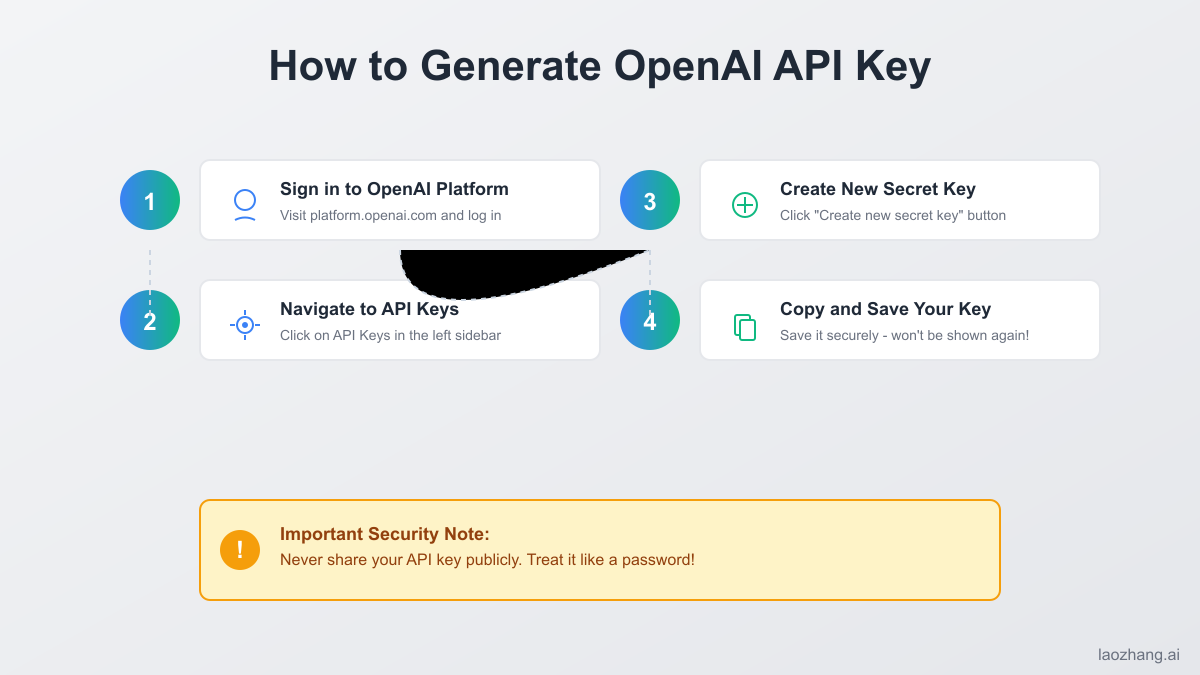
Once your account is activated, accessing the API keys section reveals a clean, intuitive interface designed for developer convenience. The API keys page, found under your account settings, displays any existing keys and provides options for creating new ones. When generating your first key, OpenAI prompts you to provide a descriptive name – a practice that becomes invaluable as your projects grow and you need to manage multiple keys across different environments.
The key generation process itself is instantaneous, but the moment you create a key marks a critical juncture in your security practices. OpenAI displays the full key only once, immediately after creation. This design choice emphasizes the importance of secure key storage from the outset. Many developers make the mistake of temporarily storing keys in easily accessible locations, intending to move them later – a practice that often leads to security vulnerabilities.
Setting up your development environment to work with OpenAI API keys requires careful consideration of several factors. Modern development practices emphasize the separation of configuration from code, and API keys are a prime example of sensitive configuration that should never be hardcoded. Environment variables have emerged as the standard solution, supported across all major programming languages and deployment platforms. In local development, tools like dotenv for Node.js or python-dotenv for Python applications provide elegant solutions for managing environment-specific configurations.
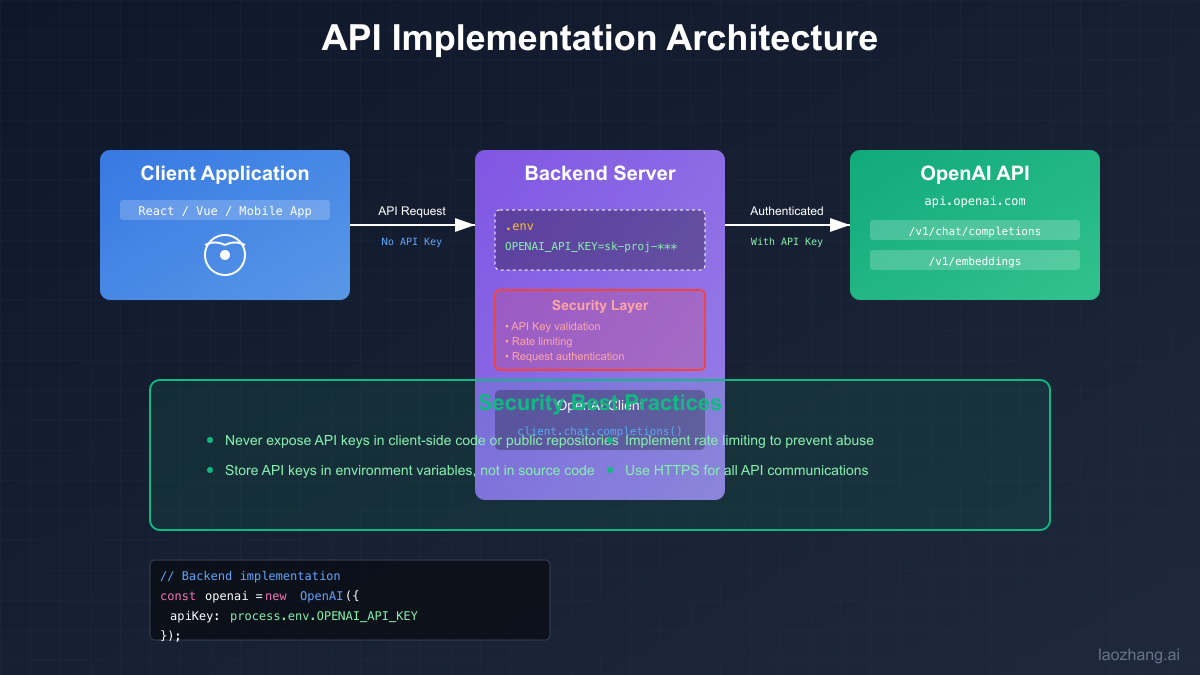
The integration process varies slightly depending on your chosen programming language and framework, but the principles remain consistent. For web applications, server-side key storage is mandatory – client-side exposure of API keys represents a critical security vulnerability that can lead to unauthorized usage and unexpected charges. Backend services should act as intermediaries, proxying requests to OpenAI while keeping keys secure. This architecture also provides opportunities for implementing additional features like request logging, rate limiting, and cost monitoring at the application level.
Security Best Practices for API Key Management
Security in API key management transcends basic password protection principles, requiring a comprehensive approach that addresses multiple threat vectors. The foundation of secure API key management lies in understanding that these keys are bearer tokens – possession alone grants access to your OpenAI account's capabilities and, consequently, incurs costs. This fundamental characteristic necessitates treating API keys with the same level of security as financial credentials.
The principle of least privilege applies directly to API key management. Rather than using a single master key across all environments and applications, create purpose-specific keys with descriptive names that clearly indicate their intended use. This segmentation strategy provides multiple benefits: it limits the blast radius of any potential compromise, simplifies key rotation procedures, and provides clearer audit trails for usage analysis. For example, separate keys for development, staging, and production environments allow for independent management and monitoring of each environment's usage patterns.
Key rotation represents another critical security practice often overlooked in initial implementations. Regular key rotation limits the window of opportunity for compromised keys and ensures that any undetected breaches have finite lifespans. Implementing automated key rotation requires careful orchestration to avoid service disruptions. A typical rotation strategy involves creating a new key, updating all services to use the new key, monitoring for any failed authentications indicating missed updates, and finally revoking the old key once all services have successfully migrated.
Secure storage solutions have evolved beyond simple environment variables to address the complex needs of modern applications. Cloud providers offer specialized secret management services like AWS Secrets Manager, Azure Key Vault, and Google Cloud Secret Manager, which provide encryption at rest, access logging, and automated rotation capabilities. These services integrate seamlessly with their respective cloud ecosystems, enabling fine-grained access control through IAM policies. For organizations with multi-cloud or hybrid deployments, solutions like HashiCorp Vault provide vendor-agnostic secret management with advanced features like dynamic secrets and lease-based access control.
Monitoring and alerting systems play a crucial role in maintaining API key security. Implementing comprehensive logging for all API key usage allows for pattern analysis and anomaly detection. Sudden spikes in usage, requests from unusual geographic locations, or access patterns outside normal business hours can indicate compromised keys. Modern security information and event management (SIEM) systems can ingest API logs and apply machine learning algorithms to detect potential security incidents before they result in significant damage.
The human factor remains one of the most challenging aspects of API key security. Developer education programs should emphasize the risks associated with key exposure and provide clear guidelines for secure handling practices. Code review processes must include checks for hardcoded secrets, and automated scanning tools should be integrated into continuous integration pipelines to catch accidental key commits before they reach public repositories. When security incidents do occur, having a well-documented incident response plan that includes key revocation procedures, impact assessment protocols, and communication templates can minimize damage and restore normal operations quickly.
Cost Analysis and Optimization Strategies
Understanding the cost structure of OpenAI's API pricing requires diving deep into the token-based billing model that underlies all interactions with their language models. Tokens, the fundamental units of text processing in OpenAI's system, don't correspond directly to words or characters, making cost prediction challenging for newcomers. On average, one token represents approximately 4 characters in English text, though this ratio varies significantly across languages and content types. For example, code snippets often require more tokens due to special characters and formatting, while languages with complex character sets like Chinese or Japanese may consume tokens less efficiently.
The pricing model differentiates between input tokens (your prompts) and output tokens (the AI's responses), with output tokens typically costing more due to the computational intensity of generation. This asymmetry in pricing has profound implications for application design. Applications that require lengthy outputs, such as content generation tools or detailed analysis systems, face proportionally higher costs than those primarily processing user inputs. Understanding this dynamic enables developers to optimize their prompts and response handling strategies for cost efficiency.
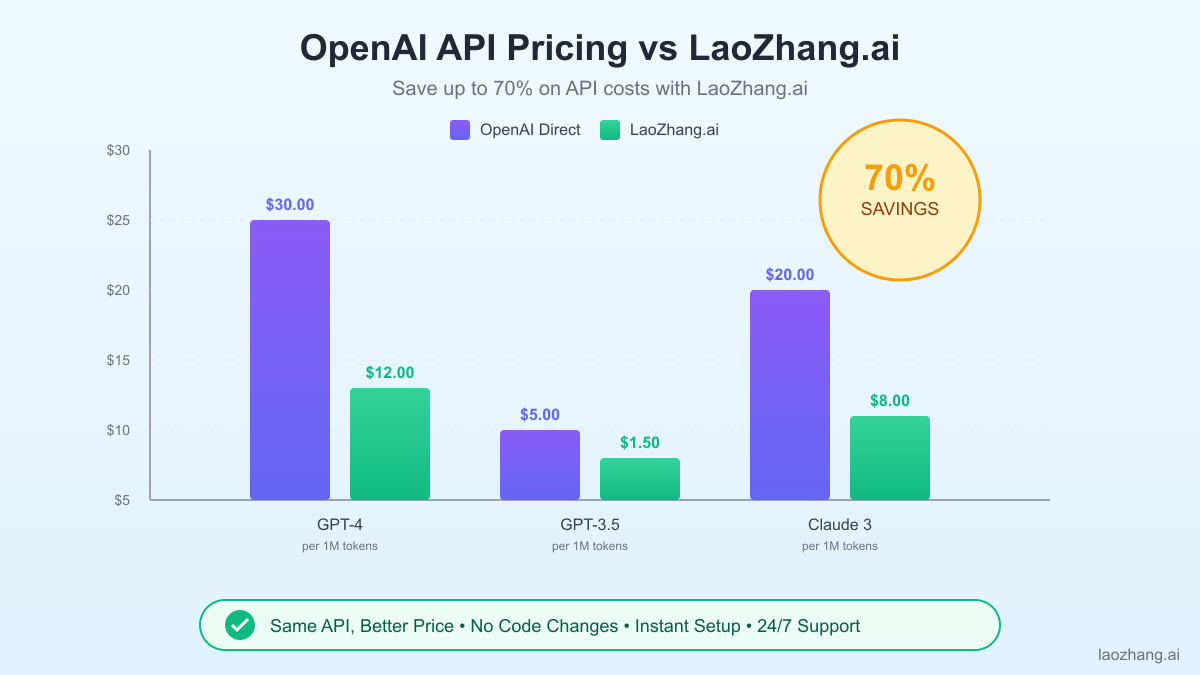
Real-world cost scenarios illuminate the financial implications of different usage patterns. A customer service chatbot handling 1,000 conversations daily, with average conversations of 500 input tokens and 200 output tokens, would incur approximately $21 per day using GPT-4, or over $600 monthly. The same workload using GPT-3.5-turbo would cost around $1.40 daily, highlighting the significant price-performance tradeoffs between models. These calculations assume direct OpenAI pricing and don't account for failed requests, retries, or development testing, which can add 20-30% to actual costs.
This is where laozhang.ai emerges as a game-changing solution for cost-conscious developers. By leveraging wholesale API purchasing and advanced traffic optimization, laozhang.ai offers the same OpenAI models at up to 70% lower costs. This isn't achieved through inferior service or hidden limitations – the API endpoints remain fully compatible with OpenAI's official SDKs, ensuring zero changes to existing codebases. The cost savings come from economies of scale and intelligent request routing that maximizes efficiency while maintaining performance standards.
The financial impact of switching to laozhang.ai becomes even more pronounced at scale. That same customer service chatbot costing $600 monthly through direct OpenAI access would cost only $180 through laozhang.ai, resulting in annual savings of over $5,000. For startups and growing businesses, these savings can mean the difference between sustainable growth and burnout. The platform also provides detailed usage analytics and cost projection tools, enabling better budget planning and resource allocation decisions.
Beyond raw cost savings, optimization strategies can further reduce API expenses regardless of your chosen provider. Implementing intelligent caching mechanisms for frequently requested information can dramatically reduce API calls. For instance, a documentation assistant that repeatedly answers similar questions can cache responses for common queries, serving them directly without incurring API costs. Similarly, prompt engineering techniques that achieve desired outputs with fewer tokens directly translate to cost savings. Techniques like few-shot learning, where examples are provided in prompts, may increase input costs but often result in more accurate outputs that require fewer retries.
Implementation Guide with Code Examples
Implementing OpenAI API integration requires careful attention to error handling, rate limiting, and response processing. Modern applications demand robust implementations that gracefully handle the various failure modes inherent in distributed systems. This section provides production-ready code examples across multiple programming languages, demonstrating best practices for API integration while highlighting how laozhang.ai's compatibility makes migration seamless.
Python Implementation
Python remains the most popular language for AI development, and OpenAI's official Python library provides a solid foundation for integration. Here's a comprehensive example that demonstrates proper error handling, retry logic, and cost tracking:
pythonimport os import time import logging from typing import Optional, Dict, Any from openai import OpenAI from tenacity import retry, stop_after_attempt, wait_exponential logging.basicConfig(level=logging.INFO) logger = logging.getLogger(__name__) class OpenAIClient: def __init__(self, api_key: Optional[str] = None, base_url: Optional[str] = None): """ Initialize OpenAI client with support for custom base URLs. This allows seamless switching between OpenAI and laozhang.ai. """ self.api_key = api_key or os.getenv("OPENAI_API_KEY") # For laozhang.ai, set base_url to "https://api.laozhang.ai/v1" self.base_url = base_url or os.getenv("OPENAI_BASE_URL", "https://api.openai.com/v1" ) if not self.api_key: raise ValueError("API key must be provided or set in OPENAI_API_KEY environment variable") self.client = OpenAI( api_key=self.api_key, base_url=self.base_url ) self.total_tokens_used = 0 self.total_cost = 0.0 @retry( stop=stop_after_attempt(3), wait=wait_exponential(multiplier=1, min=4, max=10) ) def create_completion( self, model: str = "gpt-3.5-turbo", messages: list = None, temperature: float = 0.7, max_tokens: Optional[int] = None, **kwargs ) -> Dict[str, Any]: """ Create a chat completion with automatic retry and error handling. """ try: start_time = time.time() response = self.client.chat.completions.create( model=model, messages=messages or [{"role": "user", "content": "Hello!"}], temperature=temperature, max_tokens=max_tokens, **kwargs ) # Track usage and costs usage = response.usage self.total_tokens_used += usage.total_tokens # Calculate cost (prices as of 2024) if model == "gpt-4": input_cost = usage.prompt_tokens * 0.03 / 1000 output_cost = usage.completion_tokens * 0.06 / 1000 elif model == "gpt-3.5-turbo": input_cost = usage.prompt_tokens * 0.0015 / 1000 output_cost = usage.completion_tokens * 0.002 / 1000 else: input_cost = output_cost = 0 request_cost = input_cost + output_cost self.total_cost += request_cost # Log request details logger.info( f"Request completed in {time.time() - start_time:.2f}s | " f"Tokens: {usage.total_tokens} | Cost: ${request_cost:.4f} | " f"Total cost: ${self.total_cost:.4f}" ) return { "content": response.choices[0].message.content, "usage": usage.model_dump(), "cost": request_cost, "model": model, "request_time": time.time() - start_time } except Exception as e: logger.error(f"Error creating completion: {str(e)}") raise def stream_completion( self, model: str = "gpt-3.5-turbo", messages: list = None, **kwargs ): """ Stream a chat completion for real-time responses. """ try: stream = self.client.chat.completions.create( model=model, messages=messages or [{"role": "user", "content": "Hello!"}], stream=True, **kwargs ) for chunk in stream: if chunk.choices[0].delta.content is not None: yield chunk.choices[0].delta.content except Exception as e: logger.error(f"Error streaming completion: {str(e)}") raise # Example usage demonstrating migration to laozhang.ai if __name__ == "__main__": # Standard OpenAI usage standard_client = OpenAIClient() # Using laozhang.ai for 70% cost savings # Simply change the base_url - all other code remains the same! laozhang_client = OpenAIClient( api_key="your-laozhang-api-key", base_url="https://api.laozhang.ai/v1" ) # Example conversation messages = [ {"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "Explain quantum computing in simple terms."} ] # Both clients use identical syntax response = laozhang_client.create_completion( model="gpt-3.5-turbo", messages=messages, temperature=0.7, max_tokens=200 ) print(f"Response: {response['content']}") print(f"Cost saved by using laozhang.ai: ${response['cost'] * 0.7:.4f}")
Node.js/TypeScript Implementation
For JavaScript developers, particularly those building web applications, proper TypeScript implementation ensures type safety and better development experience:
typescriptimport OpenAI from 'openai'; import { ChatCompletionMessageParam } from 'openai/resources/chat'; import pRetry from 'p-retry'; import winston from 'winston'; // Configure logger const logger = winston.createLogger({ level: 'info', format: winston.format.json(), transports: [ new winston.transports.Console({ format: winston.format.simple(), }), ], }); interface CompletionResult { content: string; usage: { promptTokens: number; completionTokens: number; totalTokens: number; }; cost: number; model: string; requestTime: number; } class OpenAIService { private client: OpenAI; private totalTokensUsed: number = 0; private totalCost: number = 0; constructor( apiKey: string = process.env.OPENAI_API_KEY || '', baseURL?: string ) { if (!apiKey) { throw new Error('API key is required'); } // For laozhang.ai, use baseURL: 'https://api.laozhang.ai/v1' this.client = new OpenAI({ apiKey, baseURL: baseURL || process.env.OPENAI_BASE_URL, }); } /** * Calculate the cost of a request based on model and token usage */ private calculateCost( model: string, promptTokens: number, completionTokens: number ): number { const pricing: Record<string, { input: number; output: number }> = { 'gpt-4': { input: 0.03, output: 0.06 }, 'gpt-3.5-turbo': { input: 0.0015, output: 0.002 }, 'gpt-3.5-turbo-16k': { input: 0.003, output: 0.004 }, }; const modelPricing = pricing[model] || { input: 0, output: 0 }; return ( (promptTokens * modelPricing.input) / 1000 + (completionTokens * modelPricing.output) / 1000 ); } /** * Create a chat completion with automatic retry and error handling */ async createCompletion( messages: ChatCompletionMessageParam[], options: { model?: string; temperature?: number; maxTokens?: number; stream?: false; } = {} ): Promise<CompletionResult> { const { model = 'gpt-3.5-turbo', temperature = 0.7, maxTokens, } = options; const startTime = Date.now(); try { const completion = await pRetry( async () => { return await this.client.chat.completions.create({ model, messages, temperature, max_tokens: maxTokens, stream: false, }); }, { retries: 3, onFailedAttempt: (error) => { logger.warn( `Attempt ${error.attemptNumber} failed. ${error.retriesLeft} retries left.` ); }, } ); const usage = completion.usage!; const cost = this.calculateCost( model, usage.prompt_tokens, usage.completion_tokens ); // Update tracking this.totalTokensUsed += usage.total_tokens; this.totalCost += cost; const requestTime = (Date.now() - startTime) / 1000; logger.info({ message: 'Completion created', model, tokens: usage.total_tokens, cost: cost.toFixed(4), totalCost: this.totalCost.toFixed(4), requestTime: requestTime.toFixed(2), }); return { content: completion.choices[0].message.content || '', usage: { promptTokens: usage.prompt_tokens, completionTokens: usage.completion_tokens, totalTokens: usage.total_tokens, }, cost, model, requestTime, }; } catch (error) { logger.error('Failed to create completion:', error); throw error; } } /** * Stream a chat completion for real-time responses */ async *streamCompletion( messages: ChatCompletionMessageParam[], options: { model?: string; temperature?: number; maxTokens?: number; } = {} ): AsyncGenerator<string, void, unknown> { const { model = 'gpt-3.5-turbo', temperature = 0.7, maxTokens, } = options; try { const stream = await this.client.chat.completions.create({ model, messages, temperature, max_tokens: maxTokens, stream: true, }); for await (const chunk of stream) { const content = chunk.choices[0]?.delta?.content; if (content) { yield content; } } } catch (error) { logger.error('Failed to stream completion:', error); throw error; } } /** * Get usage statistics */ getUsageStats() { return { totalTokensUsed: this.totalTokensUsed, totalCost: this.totalCost, averageCostPerRequest: this.totalTokensUsed > 0 ? this.totalCost / this.totalTokensUsed * 1000 : 0, }; } } // Example usage async function main() { // Using standard OpenAI const openaiService = new OpenAIService(process.env.OPENAI_API_KEY!); // Using laozhang.ai for 70% cost savings const laozhangService = new OpenAIService( process.env.LAOZHANG_API_KEY!, 'https://api.laozhang.ai/v1' ); const messages: ChatCompletionMessageParam[] = [ { role: 'system', content: 'You are a helpful assistant.' }, { role: 'user', content: 'What are the benefits of using TypeScript?' }, ]; // Same API, 70% less cost with laozhang.ai const result = await laozhangService.createCompletion(messages, { model: 'gpt-3.5-turbo', temperature: 0.7, maxTokens: 500, }); console.log('Response:', result.content); console.log(`Cost: $${result.cost.toFixed(4)}`); console.log(`Saved with laozhang.ai: $${(result.cost * 0.7).toFixed(4)}`); // Streaming example console.log('\nStreaming response:'); for await (const chunk of laozhangService.streamCompletion(messages)) { process.stdout.write(chunk); } } // Run example if called directly if (require.main === module) { main().catch(console.error); } export { OpenAIService, CompletionResult };
Java Implementation
For enterprise applications and Android development, Java implementation with proper exception handling and resource management:
javaimport com.fasterxml.jackson.databind.ObjectMapper; import okhttp3.*; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import java.io.IOException; import java.time.Duration; import java.util.*; import java.util.concurrent.CompletableFuture; import java.util.concurrent.TimeUnit; public class OpenAIClient { private static final Logger logger = LoggerFactory.getLogger(OpenAIClient.class); private static final MediaType JSON = MediaType.parse("application/json; charset=utf-8"); private final OkHttpClient httpClient; private final ObjectMapper objectMapper; private final String apiKey; private final String baseUrl; private long totalTokensUsed = 0; private double totalCost = 0.0; // Pricing per 1K tokens (as of 2024) private static final Map<String, ModelPricing> MODEL_PRICING = Map.of( "gpt-4", new ModelPricing(0.03, 0.06), "gpt-3.5-turbo", new ModelPricing(0.0015, 0.002), "gpt-3.5-turbo-16k", new ModelPricing(0.003, 0.004) ); public OpenAIClient(String apiKey) { this(apiKey, "https://api.openai.com/v1" ); } public OpenAIClient(String apiKey, String baseUrl) { this.apiKey = Objects.requireNonNull(apiKey, "API key cannot be null"); this.baseUrl = baseUrl; this.objectMapper = new ObjectMapper(); this.httpClient = new OkHttpClient.Builder() .connectTimeout(Duration.ofSeconds(30)) .readTimeout(Duration.ofSeconds(60)) .writeTimeout(Duration.ofSeconds(60)) .addInterceptor(new RetryInterceptor(3)) .addInterceptor(chain -> { Request original = chain.request(); Request request = original.newBuilder() .header("Authorization", "Bearer " + this.apiKey) .header("Content-Type", "application/json") .build(); return chain.proceed(request); }) .build(); } public CompletionResult createCompletion(CompletionRequest request) throws IOException { long startTime = System.currentTimeMillis(); String jsonBody = objectMapper.writeValueAsString(request); RequestBody body = RequestBody.create(jsonBody, JSON); Request httpRequest = new Request.Builder() .url(baseUrl + "/chat/completions") .post(body) .build(); try (Response response = httpClient.newCall(httpRequest).execute()) { if (!response.isSuccessful()) { throw new IOException("Unexpected response code: " + response); } String responseBody = response.body().string(); CompletionResponse completionResponse = objectMapper.readValue( responseBody, CompletionResponse.class ); // Calculate cost Usage usage = completionResponse.getUsage(); double cost = calculateCost(request.getModel(), usage); // Update tracking totalTokensUsed += usage.getTotalTokens(); totalCost += cost; long requestTime = System.currentTimeMillis() - startTime; logger.info("Request completed in {}ms | Tokens: {} | Cost: ${} | Total cost: ${}", requestTime, usage.getTotalTokens(), String.format("%.4f", cost), String.format("%.4f", totalCost)); return new CompletionResult( completionResponse.getChoices().get(0).getMessage().getContent(), usage, cost, request.getModel(), requestTime ); } } public CompletableFuture<CompletionResult> createCompletionAsync(CompletionRequest request) { return CompletableFuture.supplyAsync(() -> { try { return createCompletion(request); } catch (IOException e) { throw new RuntimeException("Failed to create completion", e); } }); } private double calculateCost(String model, Usage usage) { ModelPricing pricing = MODEL_PRICING.getOrDefault(model, new ModelPricing(0, 0)); return (usage.getPromptTokens() * pricing.inputCost / 1000.0) + (usage.getCompletionTokens() * pricing.outputCost / 1000.0); } // Data classes public static class CompletionRequest { private String model = "gpt-3.5-turbo"; private List<Message> messages; private Double temperature = 0.7; private Integer maxTokens; // Builder pattern for cleaner API public static class Builder { private CompletionRequest request = new CompletionRequest(); public Builder model(String model) { request.model = model; return this; } public Builder messages(List<Message> messages) { request.messages = messages; return this; } public Builder addMessage(String role, String content) { if (request.messages == null) { request.messages = new ArrayList<>(); } request.messages.add(new Message(role, content)); return this; } public Builder temperature(double temperature) { request.temperature = temperature; return this; } public Builder maxTokens(int maxTokens) { request.maxTokens = maxTokens; return this; } public CompletionRequest build() { if (request.messages == null || request.messages.isEmpty()) { throw new IllegalStateException("Messages cannot be empty"); } return request; } } // Getters and setters... public String getModel() { return model; } public List<Message> getMessages() { return messages; } public Double getTemperature() { return temperature; } public Integer getMaxTokens() { return maxTokens; } } public static class Message { private String role; private String content; public Message(String role, String content) { this.role = role; this.content = content; } // Getters and setters... public String getRole() { return role; } public String getContent() { return content; } } public static class CompletionResult { private final String content; private final Usage usage; private final double cost; private final String model; private final long requestTime; public CompletionResult(String content, Usage usage, double cost, String model, long requestTime) { this.content = content; this.usage = usage; this.cost = cost; this.model = model; this.requestTime = requestTime; } // Getters... public String getContent() { return content; } public Usage getUsage() { return usage; } public double getCost() { return cost; } public String getModel() { return model; } public long getRequestTime() { return requestTime; } } // Supporting classes for JSON parsing private static class CompletionResponse { private List<Choice> choices; private Usage usage; // Getters and setters... public List<Choice> getChoices() { return choices; } public Usage getUsage() { return usage; } } private static class Choice { private Message message; public Message getMessage() { return message; } } public static class Usage { private int promptTokens; private int completionTokens; private int totalTokens; // Getters... public int getPromptTokens() { return promptTokens; } public int getCompletionTokens() { return completionTokens; } public int getTotalTokens() { return totalTokens; } } private static class ModelPricing { final double inputCost; final double outputCost; ModelPricing(double inputCost, double outputCost) { this.inputCost = inputCost; this.outputCost = outputCost; } } // Retry interceptor for resilience private static class RetryInterceptor implements Interceptor { private final int maxRetries; RetryInterceptor(int maxRetries) { this.maxRetries = maxRetries; } @Override public Response intercept(Chain chain) throws IOException { Request request = chain.request(); Response response = null; IOException lastException = null; for (int i = 0; i <= maxRetries; i++) { try { if (response != null) { response.close(); } response = chain.proceed(request); if (response.isSuccessful()) { return response; } // Retry on server errors if (response.code() >= 500) { lastException = new IOException("Server error: " + response.code()); Thread.sleep((long) Math.pow(2, i) * 1000); // Exponential backoff continue; } return response; // Don't retry client errors } catch (IOException e) { lastException = e; if (i < maxRetries) { try { Thread.sleep((long) Math.pow(2, i) * 1000); } catch (InterruptedException ie) { Thread.currentThread().interrupt(); throw new IOException("Interrupted during retry", ie); } } } catch (InterruptedException e) { Thread.currentThread().interrupt(); throw new IOException("Interrupted during retry", e); } } throw lastException != null ? lastException : new IOException("Max retries exceeded"); } } // Example usage public static void main(String[] args) { // Using standard OpenAI OpenAIClient openaiClient = new OpenAIClient(System.getenv("OPENAI_API_KEY")); // Using laozhang.ai for 70% cost savings OpenAIClient laozhangClient = new OpenAIClient( System.getenv("LAOZHANG_API_KEY"), "https://api.laozhang.ai/v1" ); try { CompletionRequest request = new CompletionRequest.Builder() .model("gpt-3.5-turbo") .addMessage("system", "You are a helpful assistant.") .addMessage("user", "Explain the benefits of using Java for enterprise applications.") .temperature(0.7) .maxTokens(500) .build(); // Same code works with both clients CompletionResult result = laozhangClient.createCompletion(request); System.out.println("Response: " + result.getContent()); System.out.printf("Cost: $%.4f%n", result.getCost()); System.out.printf("Saved with laozhang.ai: $%.4f%n", result.getCost() * 0.7); } catch (IOException e) { logger.error("Failed to create completion", e); } } }
Troubleshooting Common Issues
The journey of integrating OpenAI APIs often encounters predictable challenges that, while frustrating, have well-established solutions. Understanding these common issues and their resolutions can save hours of debugging and prevent costly mistakes that impact both development velocity and API expenses.
Authentication errors represent the most frequent initial hurdle developers face. The "Invalid API Key" error typically stems from one of several causes: incorrect key copying (missing characters or including extra whitespace), using a key from a different environment (development vs. production), or attempting to use a revoked or expired key. The solution requires systematic verification: confirm the key matches exactly what's shown in the OpenAI dashboard, ensure environment variables are properly loaded, and verify the key hasn't been revoked due to security concerns or billing issues.
Rate limiting presents another significant challenge, particularly for applications experiencing rapid growth. OpenAI implements multiple types of rate limits: requests per minute (RPM), requests per day (RPD), and tokens per minute (TPM). When limits are exceeded, the API returns 429 status codes with headers indicating when requests can resume. Proper handling requires implementing exponential backoff strategies, request queuing systems, and potentially distributing load across multiple API keys. However, laozhang.ai's infrastructure provides higher rate limits out of the box, often eliminating these issues entirely for growing applications.
Token limit errors occur when requests exceed model-specific context windows. GPT-4 supports up to 8,192 tokens in standard configuration, while GPT-3.5-turbo handles 4,096 tokens. These limits include both input and output tokens, meaning lengthy prompts leave less room for responses. Solutions involve implementing intelligent prompt truncation, conversation summarization for chat applications, and strategic use of system messages to maintain context efficiently. Advanced applications might implement sliding window approaches, maintaining only the most recent and relevant conversation history.
Billing and cost overruns represent perhaps the most painful category of issues, often discovered only after significant expenses have been incurred. Common causes include development environments accidentally using production keys, infinite loops in retry logic, and underestimating token usage for specific use cases. Prevention strategies include implementing hard spending limits in OpenAI's dashboard, creating separate keys for different environments with appropriate spending caps, and building internal cost monitoring that alerts before limits are reached. This is where laozhang.ai's cost savings become particularly valuable – the same budget stretches 70% further, providing more room for growth and experimentation.
Network and connectivity issues manifest in various ways: timeout errors, SSL certificate problems, and intermittent connection failures. These often stem from corporate proxy configurations, firewall rules, or regional network instabilities. Solutions include implementing proper timeout handling (typically 30-60 seconds for completion requests), using retry mechanisms with exponential backoff, and ensuring proxy configurations are correctly set in HTTP clients. For applications requiring high reliability, implementing circuit breaker patterns prevents cascading failures when API endpoints become temporarily unavailable.
Response parsing errors often catch developers off guard, particularly when handling streaming responses or dealing with incomplete outputs. The API might return partial JSON in error cases, or streaming connections might terminate unexpectedly. Robust error handling requires validating response structure before processing, implementing proper stream error handling that gracefully manages connection drops, and maintaining fallback behaviors for when responses don't match expected formats. Additionally, logging raw responses during development helps identify edge cases that might not be apparent from documentation alone.
Future Outlook and Industry Trends
The landscape of AI APIs continues to evolve at a breathtaking pace, with implications that extend far beyond simple technological upgrades. The trajectory of OpenAI's API development suggests several key trends that developers must prepare for to remain competitive and efficient in their implementations.
Model proliferation and specialization represent a fundamental shift in how AI services are consumed. Rather than relying on monolithic, general-purpose models, the future points toward an ecosystem of specialized models optimized for specific tasks. We're already seeing this with OpenAI's function calling models, embedding models, and fine-tuned variants. This specialization trend means developers need to build flexible architectures that can seamlessly switch between models based on task requirements, balancing performance, cost, and accuracy dynamically.
Pricing pressures and market competition are reshaping the economic landscape of AI services. As more providers enter the market and existing players optimize their infrastructure, we're witnessing a consistent downward trend in API pricing. However, this commoditization of basic AI capabilities is coupled with premium pricing for cutting-edge models and specialized features. Services like laozhang.ai represent the vanguard of this trend, leveraging economies of scale to provide enterprise-grade AI capabilities at fraction of traditional costs. This democratization of AI access enables startups and individual developers to build sophisticated applications that were previously economically unfeasible.
The integration paradigm is shifting from simple request-response patterns to more sophisticated, context-aware systems. Future APIs will likely support persistent conversation contexts, multi-modal inputs combining text, images, and structured data, and real-time collaboration features. Developers should architect their systems with these capabilities in mind, implementing abstraction layers that can accommodate new interaction patterns without requiring fundamental rewrites.
Regulatory compliance and AI governance are emerging as critical considerations for API integration. As governments worldwide develop AI regulations, API providers must implement features supporting compliance requirements: audit trails, data residency options, and bias detection mechanisms. Forward-thinking developers are already building these considerations into their applications, creating abstraction layers that can adapt to changing regulatory landscapes across different jurisdictions.
Edge computing and local AI processing represent another frontier in API evolution. While cloud-based APIs currently dominate, the future likely holds a hybrid model where certain operations run locally for privacy, latency, or cost reasons, while others leverage cloud APIs for maximum capability. This architectural shift requires developers to design systems that can seamlessly operate across local and cloud environments, managing model deployment, version control, and performance optimization across distributed systems.
The convergence of AI APIs with other cloud services promises to unlock new categories of applications. Integration with vector databases for long-term memory, real-time data streams for contextual awareness, and automated workflow systems for complex task orchestration are becoming standard patterns. Developers who master these integration patterns will be positioned to build the next generation of AI-powered applications that go beyond simple chat interfaces to become truly intelligent systems.
Conclusion
The OpenAI API key represents more than just an authentication mechanism – it's your gateway to building intelligent applications that can transform businesses and create new possibilities. Throughout this comprehensive guide, we've explored the technical foundations, security imperatives, and cost optimization strategies that separate successful implementations from costly failures.
The shift from experimental prototypes to production-ready AI applications requires careful attention to numerous factors: robust error handling, comprehensive security measures, and most critically, sustainable cost management. While OpenAI's direct pricing model has enabled incredible innovation, the financial burden can quickly become prohibitive for growing applications. This is where alternative providers like laozhang.ai demonstrate their value, offering identical API compatibility with up to 70% cost savings through optimized infrastructure and economies of scale.
As we look toward the future, the AI API landscape will continue to evolve rapidly. New models, pricing structures, and capabilities will emerge, but the fundamental principles we've discussed – security, reliability, and cost efficiency – will remain paramount. By implementing the best practices outlined in this guide and leveraging cost-effective providers like laozhang.ai, developers can build sustainable, scalable AI applications that deliver real value without breaking the budget.
The journey from API key to production application may seem daunting, but with the right knowledge, tools, and partners, it becomes an exciting opportunity to harness the power of artificial intelligence. Whether you're building a simple chatbot or a complex AI-powered system, remember that success lies not just in the technology itself, but in how thoughtfully and efficiently you implement it. Start with secure foundations, optimize relentlessly, and always keep an eye on costs – your future self and your budget will thank you.