
Use GPT-5.4 when the outcome depends on stronger reasoning, fewer retries, or the much larger 1.05M context window. Use GPT-5.4 mini when you want a cheaper, faster, higher-volume default for coding, computer use, and agent workflows.
This is not an old-versus-new migration story. Both are current GPT-5.4-family models. The question is how much flagship headroom your workflow really needs and whether that extra headroom pays for itself.
TL;DR
If you want one recommendation, do not force one model everywhere. Use GPT-5.4 as the premium route and GPT-5.4 mini as the high-volume route. If you need only one default, choose based on whether your real bottleneck is quality or throughput.
| Category | GPT-5.4 | GPT-5.4 mini | Practical takeaway |
|---|---|---|---|
| Launch date | March 5, 2026 | March 17, 2026 | Both are current, but mini is newer and still in a fresher SERP cycle |
| Current official role | Default for broad general-purpose work and most coding tasks | High-volume coding, computer use, and agent workflows | This is a routing split inside the same family |
| Input price | $2.50 / 1M | $0.75 / 1M | GPT-5.4 costs about 3.3x more on input |
| Cached input | $0.25 / 1M | $0.075 / 1M | Mini is much cheaper in repeat-heavy flows |
| Output price | $15.00 / 1M | $4.50 / 1M | The premium for GPT-5.4 is large, not cosmetic |
| Context window | 1,050,000 | 400,000 | GPT-5.4 is the clear winner for very large repo and document work |
| Max output | 128,000 | 128,000 | Tie |
| Knowledge cutoff | Aug 31, 2025 | Aug 31, 2025 | This is not a freshness-gap story |
| Tool stack on model page | Broad Responses API tool support | Same broad Responses API tool support | Mini is not a tool-light model |
| Published top-tier caps on current model page | 15,000 RPM / 40,000,000 TPM | 30,000 RPM / 180,000,000 TPM | Mini has a much stronger throughput profile |
| Best fit | Harder reasoning, long context, premium output quality | Cheaper scale, subagents, coding assistants, computer-use loops | Route by workload, not by model prestige |
The simplest way to think about it is this:
- GPT-5.4 is the better answer when one wrong or weak answer costs more than the extra tokens.
- GPT-5.4 mini is the better answer when you need a lot of competent work at scale and the flagship delta is not worth the bill.
The Real Split: Flagship Intelligence vs High-Volume Throughput
The easiest mistake on this keyword is to compare these models like two unrelated releases. That hides the real choice.
OpenAI's current Using GPT-5.4 guide says gpt-5.4 is the default model for broad general-purpose work and most coding tasks. The same guide says gpt-5.4-mini is for high-volume coding, computer use, and agent workflows that still need strong reasoning. That wording matters because it tells you OpenAI is not treating mini as a toy or a stripped-down fallback. It is treating it as the small-model production lane.
So the right comparison is not:
- newer versus older
- premium versus cheap in a generic sense
The right comparison is:
- best intelligence and bigger context versus cheaper scale
- harder long-horizon work versus faster high-volume work
- premium default versus production workhorse
That is also why this keyword is stronger than it looks. Searchers usually are not asking which model has the prettier benchmark chart. They are asking which model should power:
- their main coding assistant
- their subagent or worker fleet
- their long-context repo analysis jobs
- their screenshot-heavy computer-use loops
- their default OpenAI route when they cannot afford to guess wrong
If you keep that decision in view, the comparison becomes much cleaner.
Benchmarks and Capability Gaps That Actually Matter
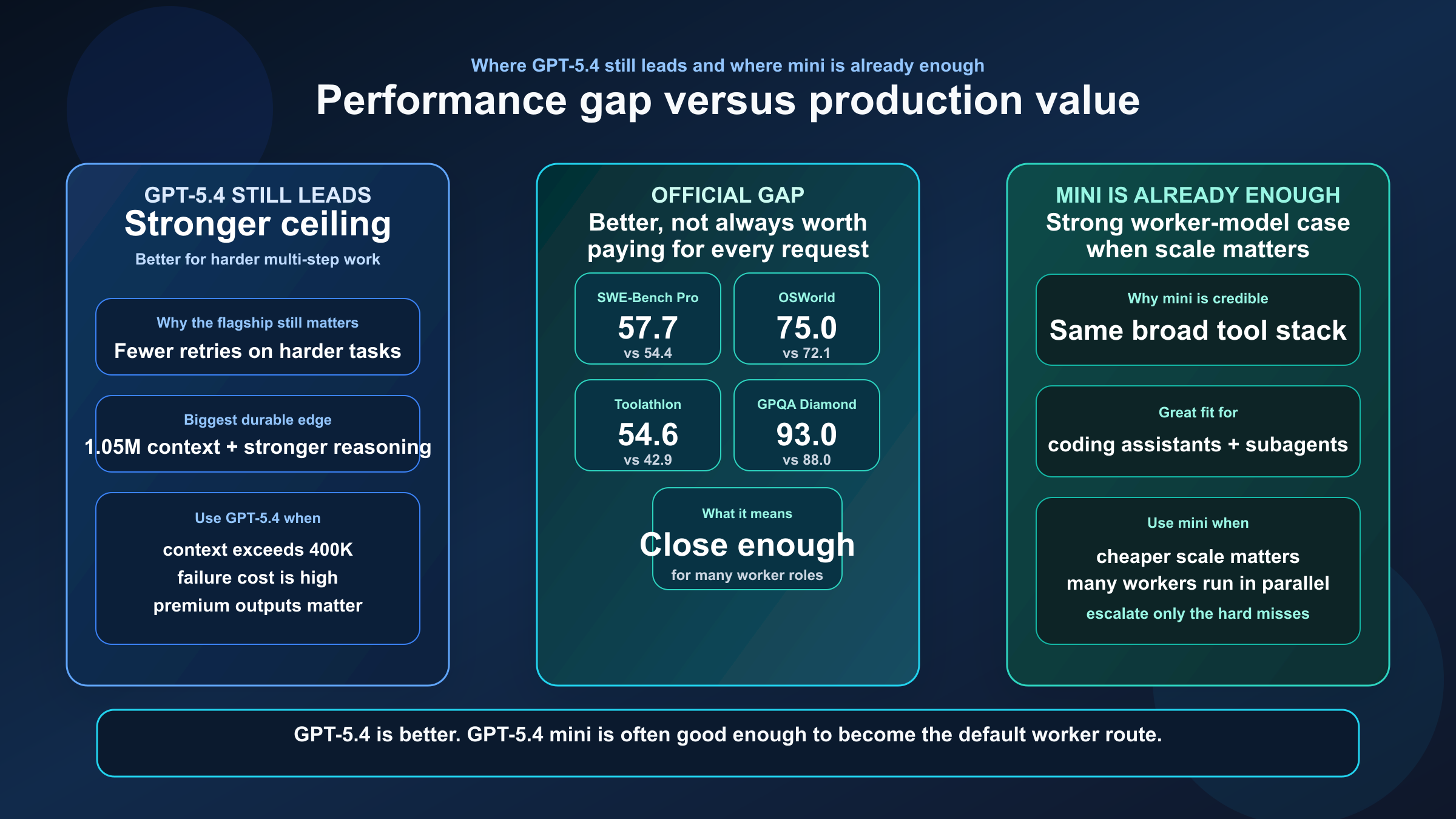
OpenAI's March 17, 2026 launch post for GPT-5.4 mini and nano gives the most useful official side-by-side benchmark table for this query.
| Benchmark | GPT-5.4 | GPT-5.4 mini | Why it matters |
|---|---|---|---|
| SWE-Bench Pro (Public) | 57.7% | 54.4% | GPT-5.4 is better on hard software issue resolution, but mini stays close |
| Terminal-Bench 2.0 | 75.1% | 60.0% | GPT-5.4 has a much larger edge in longer, tool-heavy terminal work |
| Toolathlon | 54.6% | 42.9% | Flagship still has the stronger multi-tool reliability ceiling |
| GPQA Diamond | 93.0% | 88.0% | GPT-5.4 keeps the stronger reasoning headroom |
| OSWorld-Verified | 75.0% | 72.1% | Mini is surprisingly close on computer use, which is why it is viable for agent fleets |
Three practical conclusions matter more than the raw scores.
The first is that GPT-5.4 is clearly better, but GPT-5.4 mini is not far behind everywhere. If mini were dramatically worse across the board, this would be an easy premium-only recommendation. It is not. Mini stays close enough on coding and computer use that cost and throughput can easily outweigh the quality gap for many teams.
The second is that GPT-5.4's biggest edge is not "it writes better prose." Its edge is that it carries more headroom on the kinds of tasks that go wrong when the model has to:
- reason longer
- coordinate more tools
- recover from ambiguity
- maintain quality across multi-step work
That matters when the workflow is complex enough that retries are expensive.
The third is that GPT-5.4 mini's benchmark profile is exactly what makes it dangerous to underestimate. It is strong enough that many teams can get most of the value of the GPT-5.4 family while paying much less and pushing much more traffic through it.
That is why the comparison should never stop at "GPT-5.4 wins the table." The right question is whether those wins are worth paying for in your workflow.
If your team is also deciding whether the flagship should be compared with OpenAI's coding-specialized branch, our GPT-5.4 vs GPT-5.3-Codex guide is the better sibling read after this one.
Pricing, Context Window, and Published Rate Limits

This is where the article stops being theoretical.
According to the current GPT-5.4 model page, GPT-5.4 lists:
- $2.50 per 1M input tokens
- $0.25 per 1M cached input tokens
- $15.00 per 1M output tokens
- 1,050,000 context window
- 128,000 max output tokens
According to the current GPT-5.4 mini model page, GPT-5.4 mini lists:
- $0.75 per 1M input tokens
- $0.075 per 1M cached input tokens
- $4.50 per 1M output tokens
- 400,000 context window
- 128,000 max output tokens
So the pricing story is blunt:
- GPT-5.4 is about 3.3x the input price of GPT-5.4 mini
- GPT-5.4 is about 3.3x the cached-input price of GPT-5.4 mini
- GPT-5.4 is about 3.3x the output price of GPT-5.4 mini
That is a serious premium. If your workflow scales into millions of requests or many background agents, this is not a rounding error.
The context story is just as blunt in the other direction. GPT-5.4's 1.05M context window is much larger than GPT-5.4 mini's 400K. For full-repo reasoning, giant document sets, longer background trajectories, or workflows where compaction still leaves a lot of material in play, GPT-5.4 has a real advantage.
But there is one detail many quick comparison pages skip: the GPT-5.4 model page also says that for models with a 1.05M context window, prompts with more than 272K input tokens are priced at 2x input and 1.5x output for the full session. That does not make GPT-5.4 a bad deal. It just means the huge context window is a premium feature you should use deliberately.
There is also a throughput difference that matters more than many readers expect. On the current published model pages:
- GPT-5.4 shows a Tier 5 long-context table topping out at 15,000 RPM and 40,000,000 TPM
- GPT-5.4 mini shows a Tier 5 table topping out at 30,000 RPM and 180,000,000 TPM
That is a major practical reason GPT-5.4 mini can be the smarter production default for worker fleets, coding assistants, and high-volume automation. Even before you factor in price, the published throughput ceiling is much friendlier to scale.
One more useful nuance: both model pages currently show the same Aug 31, 2025 knowledge cutoff. That means you should not tell yourself "I need GPT-5.4 because mini is much staler." The freshness case is not there on the current docs. The real differences are quality headroom, context, cost, and throughput.
If you are comparing mini against the older budget branch rather than the flagship, read GPT-5.4 mini vs GPT-5 mini after this one.
Tool Support: Mini Is Not a Tool-Light Model
This is one of the biggest places where current page-one summaries are weak.
If you only skim launch posts, it is easy to assume GPT-5.4 mini is the "cheaper but less capable tools" version. The current model pages do not really support that conclusion.
Both the current GPT-5.4 and GPT-5.4 mini model pages list support for the same broad Responses API tool stack:
- web search
- file search
- image generation
- code interpreter
- hosted shell
- apply patch
- skills
- computer use
- MCP
- tool search
That does not mean the models are equal. GPT-5.4 still has the stronger overall benchmark profile and the larger context window, so it should usually do better on harder multi-step work. But it does mean the comparison is not "premium model with tools" versus "mini model without tools."
The better way to frame it is:
- GPT-5.4 gives you the stronger ceiling on hard, messy, multi-step work
- GPT-5.4 mini gives you a very similar product surface with much better economics
That is exactly why this keyword needs routing guidance. If mini lacked the tools, the decision would be simpler.
When GPT-5.4 Is Worth Paying For
GPT-5.4 is worth the premium when a stronger answer saves more time or money than the token delta costs.
Choose GPT-5.4 when you need:
- very large repo or document context in one pass
- harder multi-step reasoning with fewer retries
- better performance on complex tool-heavy workflows
- the highest-confidence route for premium customer-facing or business-critical outputs
- one strong model that can move between reasoning, coding, analysis, and tool use without much compromise
Here are the common cases where GPT-5.4 is the better default:
Long-context engineering work. If your agent needs to hold a large codebase, multiple specs, logs, and docs together, GPT-5.4's 1.05M window is a real operational advantage.
High-stakes automation. If a weaker answer causes expensive retries, broken workflows, or noisy downstream review, the premium often pays for itself.
Premium coding and reasoning blended together. GPT-5.4 is easier to justify when the workflow is not only patch generation, but also diagnosis, decision-making, synthesis, and verification.
Fewer model routes. Some teams are better off paying for one stronger model than maintaining a complicated routing stack too early.
A useful rule is this: if you would be annoyed by mini's mistakes more than you would notice GPT-5.4's higher bill, use GPT-5.4.
When GPT-5.4 mini Is the Smarter Default
GPT-5.4 mini is the smarter default when your bottleneck is scale, not maximum single-request intelligence.
Choose GPT-5.4 mini when you need:
- many coding or agent requests per minute
- cheaper high-volume worker execution
- subagents that do useful work fast without demanding flagship pricing
- computer-use loops where you care about competence and speed more than maximum headroom
- a strong small-model path that still supports the modern GPT-5.4 tool surface
This is where mini becomes hard to ignore.
If you are building:
- delegated coding workers
- automated bug triage loops
- screenshot-driven UI agents
- batch review systems
- background assistants that touch tools frequently
then GPT-5.4 mini often gives you a better operating point. The model is much cheaper, the current published throughput ceilings are much higher, and the capability gap is smaller than many buyers expect.
That does not make mini the best answer for everything. It means mini is the better production workhorse when you need a lot of competent work and do not want every request billed like a flagship request.
For many teams, the best answer is:
- GPT-5.4 for the planner, escalations, and harder branches
- GPT-5.4 mini for the workers
That pattern fits OpenAI's own current positioning better than forcing everything onto one branch.
API and Codex Guidance vs ChatGPT Surface Reality
This is where many comparison pages become less useful than the docs they summarize.
On the API and Codex side, the answer is fairly clean:
- GPT-5.4 is the main default
- GPT-5.4 mini is the smaller, faster, cheaper variant for high-volume work
On the ChatGPT side, the current behavior is messier.
OpenAI's current ChatGPT release notes say that on March 18, 2026, GPT-5.4 mini rolled out in ChatGPT. The same release note says:
- GPT-5.4 mini is available to Free and Go users via the Thinking feature
- for many paid users, GPT-5.4 mini is used as a fallback for GPT-5.4 Thinking when rate limits are reached
- GPT-5.4 mini does not appear as a selectable model in the picker
That matters because it prevents a common mistake: assuming ChatGPT picker behavior is the same thing as API model selection.
It is not.
If you are deciding what to build against, trust the API model docs and latest-model guide first. If you are explaining what people actually see inside ChatGPT, you also need the release notes. Those are different questions.
If your team is stuck on ChatGPT-surface quota behavior rather than API routing, ChatGPT Plus vs free speed and quota behavior for GPT-5 is the better follow-up read.
Practical Routing Rules for Teams
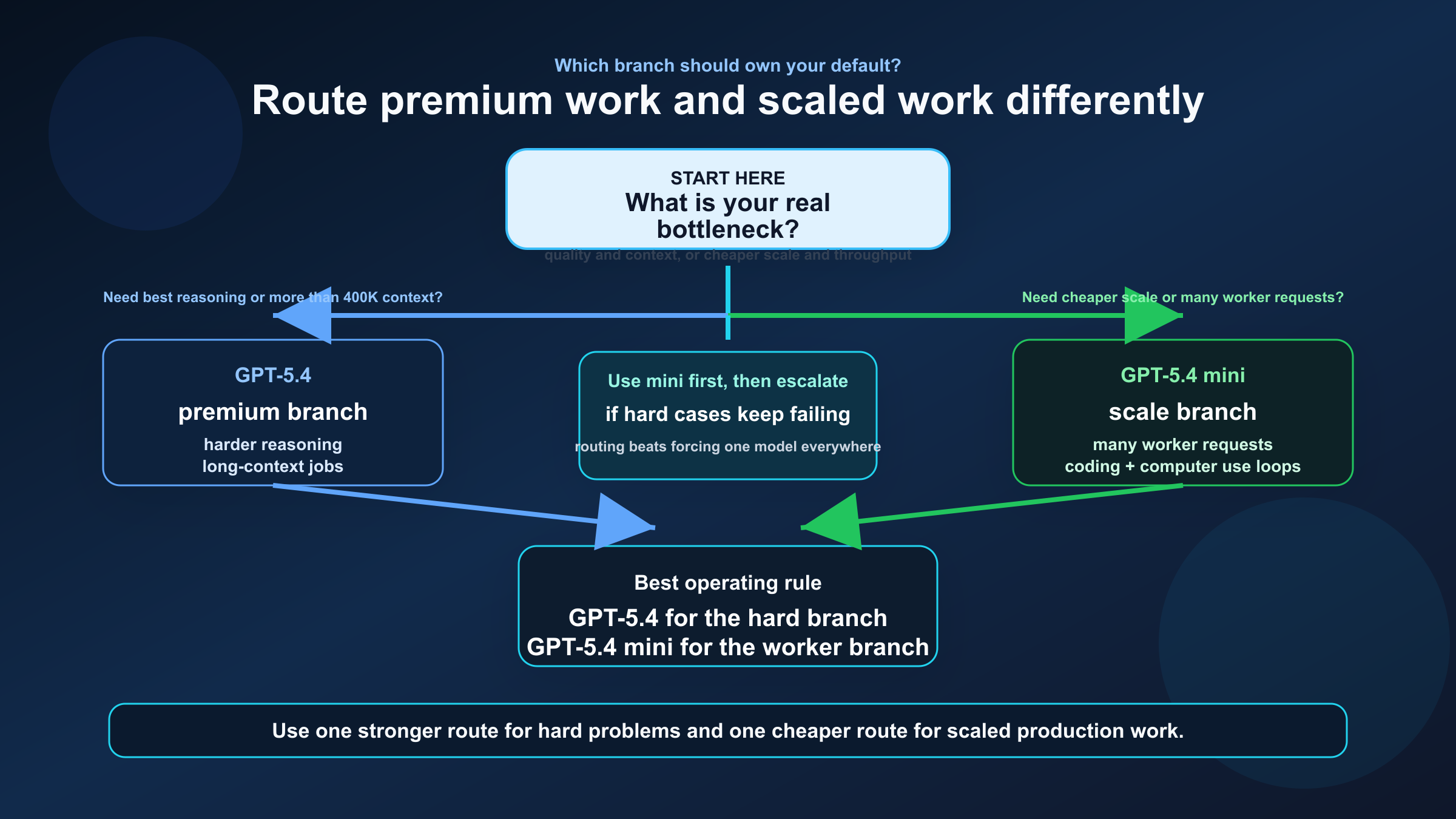
If you want a simple production playbook, use this one.
| Workload | Default model | Why | When to override |
|---|---|---|---|
| Long-context repo analysis | GPT-5.4 | Bigger context and stronger reasoning ceiling | Override to mini only if the task stays far below 400K and cost dominates |
| Planner / orchestrator agent | GPT-5.4 | Better for harder multi-step decisions | Override to mini if the planner is lightweight and cost-sensitive |
| Subagent workers | GPT-5.4 mini | Better economics and throughput | Escalate to GPT-5.4 when failure cost is high |
| Coding assistant at scale | GPT-5.4 mini | Strong enough while much cheaper | Use GPT-5.4 for harder branches or higher-quality review |
| Premium customer-facing or business-critical generation | GPT-5.4 | Better quality headroom | Only drop to mini if results are measurably close and budget pressure is severe |
| Screenshot-heavy computer-use loops | GPT-5.4 mini | Strong computer-use performance with better scale economics | Escalate to GPT-5.4 when UI complexity or failure cost rises |
If you are setting policy for a team, the most defensible setup is:
- Default the hard branch to GPT-5.4.
- Default the high-volume branch to GPT-5.4 mini.
- Measure where GPT-5.4 reduces retries or rework enough to justify its premium.
- Escalate to GPT-5.4 instead of paying flagship prices for every request.
That gives you a clean routing story without pretending the models serve the same cost envelope.
FAQ
Is GPT-5.4 mini good enough for serious coding agents?
Often yes. On the current official comparison, GPT-5.4 mini stays relatively close to GPT-5.4 on SWE-Bench Pro and OSWorld-Verified while costing much less and exposing the same broad tool surface. That makes it a credible worker-model choice.
Does GPT-5.4 mini have fewer tools than GPT-5.4?
Not on the current model pages. Both currently list support for web search, file search, image generation, code interpreter, hosted shell, apply patch, skills, computer use, MCP, and tool search. The bigger differences are quality headroom, context, speed posture, and cost.
Is GPT-5.4 worth the extra cost?
Yes when stronger reasoning, fewer retries, and much larger context change the outcome. No when your workload is high-volume enough that GPT-5.4 mini already does the job and the extra spend does not buy enough user value.
Is the 1.05M context window the main reason to choose GPT-5.4?
It is one of the strongest reasons, but not the only one. GPT-5.4 also carries a stronger reasoning and tool-heavy benchmark profile. That said, if your workload lives comfortably inside 400K context, the context premium matters less.
Which is better for Codex-style subagents?
For many subagent roles, GPT-5.4 mini is the better default because it is cheaper and built for high-volume coding, computer use, and agent workflows. Use GPT-5.4 for the harder planner or escalation branch.
Does ChatGPT tell the same story as the API?
No. The API and latest-model docs present GPT-5.4 as the main default and GPT-5.4 mini as the smaller, faster variant. ChatGPT currently uses GPT-5.4 mini mainly as a Thinking path or fallback depending on plan and usage, not as a standard picker choice.
If you need one line to take back to your team, use this:
GPT-5.4 is the premium default when quality and context matter most. GPT-5.4 mini is the smarter production default when you need cheaper, faster, higher-volume work without dropping out of the modern GPT-5.4 tool ecosystem.
That is the practical answer to this keyword as of March 20, 2026. The models are not competing for exactly the same job. Your real task is to decide which one should own the expensive branch and which one should own the scaled branch.