
Short answer: for most developers, GPT-5.4 is now the better default. OpenAI launched GPT-5.4 on March 5, 2026 and explicitly says it absorbs the frontier coding capabilities of GPT-5.3-Codex while extending them into a broader mainline reasoning model. In practice, that means GPT-5.4 is the safer default when you want one model for coding, tool use, long-context repo work, and general professional tasks.
That does not make GPT-5.3-Codex irrelevant. GPT-5.3-Codex, launched on February 5, 2026, still keeps two meaningful advantages: it is cheaper on input tokens, and it still beats GPT-5.4 on Terminal-Bench 2.0. If your workload is mostly CLI-heavy engineering, shell-first automation, or short-to-medium coding sessions where you care more about speed-per-dollar than broad tool coverage, GPT-5.3-Codex still deserves a place in your routing stack.
This guide uses current OpenAI launch pages, current API model docs, and current pricing pages checked on March 19, 2026. It also separates official product facts from temporary rollout noise, because recent Codex access regressions confused a lot of discussion around these models without actually changing the long-term product story.
TL;DR
If you only want one recommendation, use GPT-5.4 as your default model in Codex and the API. Keep GPT-5.3-Codex as a specialist option when terminal-heavy tasks or lower input cost matter more than long context and broader tools.
| Category | GPT-5.4 | GPT-5.3-Codex | Practical takeaway |
|---|---|---|---|
| Release date | March 5, 2026 | February 5, 2026 | GPT-5.4 is the newer frontier default |
| Product role | Mainline reasoning and agentic work | Coding-specialized model | GPT-5.4 is broader, Codex is narrower |
| Input price | $2.50 / 1M | $1.75 / 1M | GPT-5.3-Codex is 30% cheaper on input |
| Output price | $15 / 1M | $14 / 1M | Output cost gap is small |
| Cached input | $0.25 / 1M | $0.175 / 1M | GPT-5.3-Codex stays cheaper in repeat-heavy flows |
| Context window | 1,050,000 | 400,000 | GPT-5.4 is far better for repo-scale context |
| Max output | 128,000 | 128,000 | Tie |
| Tools | Broad tool surface including computer use | Coding-focused positioning | GPT-5.4 fits broader agentic workflows |
| Best benchmark edge | GDPval, SWE-Bench Pro, OSWorld, Toolathlon, BrowseComp | Terminal-Bench 2.0 | GPT-5.4 wins overall, Codex still wins one important niche |
| Best for | Default coding, long-context work, mixed professional tasks | Terminal-heavy engineering, cheaper coding runs | Use both if you want optimal routing |
The crucial nuance is that GPT-5.4 is not just "GPT-5.3-Codex but newer." It is a stronger all-around default with more headroom. But GPT-5.3-Codex is not obsolete either, because the last 10% of workflow fit still matters in production.
What Actually Changed Between GPT-5.4 and GPT-5.3-Codex

The biggest change is product positioning. According to OpenAI's GPT-5.4 launch page, GPT-5.4 is now the first mainline reasoning model that incorporates GPT-5.3-Codex's frontier coding capabilities. That wording matters because it tells you how OpenAI wants you to choose: GPT-5.4 is no longer only a "reasoning" model that happens to code well. It is the broad default for serious work, coding included.
GPT-5.3-Codex, by contrast, launched as a coding-first product. On OpenAI's GPT-5.3-Codex announcement, the emphasis is speed, agentic coding, and performance in real software-engineering tasks. That framing explains why GPT-5.3-Codex still has defenders even after GPT-5.4 shipped. It was built to feel sharp inside Codex-like environments, not to be the best single model for every type of professional problem.
There is also a cleaner current split in the API docs. The models overview in the OpenAI API docs points developers toward GPT-5.4 for complex reasoning, coding, and agentic work, while GPT-5.3-Codex remains a coding-specialized option. That is a stronger signal than launch-day speculation because it reflects how the product is positioned today, not just how it debuted.
OpenAI's March 5, 2026 launch page also clarifies why surface-level anecdotes feel messier than the durable recommendation. GPT-5.4 Thinking started rolling out that day to ChatGPT Plus, Team, and Pro, GPT-5.4 Pro to Pro and Enterprise, and GPT-5.4 in Codex includes experimental support for the 1M context window. The same page says Codex requests above the standard 272K context count at 2x the normal usage rate. That matters because it confirms two things at once: GPT-5.4 really is the new mainline default, but interface-level behavior can still differ by surface and rollout state.
The right way to read this is simple: GPT-5.4 replaced GPT-5.3-Codex as the default recommendation, but not as the default answer to every workload. If your work spans code, tools, search, patching, long-context analysis, and decision support, GPT-5.4 is the better center of gravity. If your work is narrower and more terminal-centric, GPT-5.3-Codex can still be the better specialist.
One reason this comparison feels more confusing than it should is that people often mix three different surfaces together: the ChatGPT model picker, the Codex product surface, and the API model catalog. Those are related, but they do not always roll out at the same speed or fail in the same way. A good comparison should therefore treat launch pages and current model docs as the durable product layer, while treating forum threads and temporary access failures as operational noise around that layer.
Benchmarks That Matter for Real Coding Work
The most useful way to compare these models is not to ask which one wins the most charts. It is to ask which benchmark differences actually change developer outcomes.
| Benchmark | GPT-5.4 | GPT-5.3-Codex | What it means |
|---|---|---|---|
| GDPval | 83.0% | 70.9% | GPT-5.4 is better at aligned, high-quality instruction following |
| SWE-Bench Pro | 57.7% | 56.8% | GPT-5.4 has a slight edge on difficult software-engineering tasks |
| OSWorld-Verified | 75.0% | 74.0% | GPT-5.4 is a bit better in computer-operation style tasks |
| Toolathlon | 54.6% | 51.9% | GPT-5.4 handles tool-using workflows better overall |
| BrowseComp | 82.7% | 77.3% | GPT-5.4 is better when browsing and evidence gathering matter |
| Terminal-Bench 2.0 | 75.1% | 77.3% | GPT-5.3-Codex still has the stronger CLI-specific profile |
The headline here is that GPT-5.4 wins most of the board, but the one place where GPT-5.3-Codex still leads is not trivial. Terminal-Bench is exactly the sort of benchmark that maps well to shell-heavy engineering: file manipulation, environment work, scripting, and terminal-centric debugging. If your daily flow lives inside a terminal, that 2.2-point gap is more important than it looks.
For everyone else, the benchmark pattern strongly favors GPT-5.4. The GDPval jump from 70.9% to 83.0% matters because it suggests GPT-5.4 is more dependable when tasks become ambiguous, multi-step, or mixed across coding and reasoning. The SWE-Bench Pro difference is small, but the direction still favors GPT-5.4. Toolathlon and BrowseComp matter even more than many comparison pages admit, because real coding work increasingly includes search, patch application, docs reading, multi-tool coordination, and evidence-based iteration instead of pure autocomplete.
The practical interpretation is this:
- If your work is mostly "edit code, run shell commands, fix the issue quickly," GPT-5.3-Codex still has a strong claim.
- If your work is "understand a large codebase, use multiple tools, reason through tradeoffs, and produce reliable output across mixed tasks," GPT-5.4 is the better default.
That is also why the current community conversation feels split rather than settled. Developers working in slightly different environments are seeing different winners because the models are genuinely optimized for overlapping but not identical job shapes.
For readers who want another current coding-model comparison anchor, our guide to GPT-5.3 Codex vs Claude Opus 4.6 is useful because it shows just how much of GPT-5.3-Codex's reputation came from coding-specific performance rather than broad general-purpose work.
Pricing, Context Window, and Tool Coverage

Once you move beyond benchmark bragging rights, the most important differences are cost, context, and tools.
| Feature | GPT-5.4 | GPT-5.3-Codex | Why it matters |
|---|---|---|---|
| Input | $2.50 / 1M | $1.75 / 1M | GPT-5.3-Codex is meaningfully cheaper for prompt-heavy work |
| Cached input | $0.25 / 1M | $0.175 / 1M | Repeated-context coding still costs less on Codex |
| Output | $15 / 1M | $14 / 1M | Output costs are close enough that output alone should not decide the choice |
| Context window | 1,050,000 | 400,000 | GPT-5.4 handles much larger repo and document contexts |
| Max output | 128,000 | 128,000 | Long-form generation ceiling is effectively tied |
| Long-context pricing note | Above 272K prompt tokens, 2x input and 1.5x output for full session | No equivalent published multiplier | GPT-5.4's big context is real, but expensive at the far end |
| Tool breadth | Includes web search, file search, image generation, code interpreter, hosted shell, apply patch, skills, MCP, computer use, tool search | Coding-oriented model page and endpoints | GPT-5.4 is much easier to justify as the one default model |
The pricing story is more nuanced than "GPT-5.4 is expensive." The output difference is small: $15 versus $14 per million. The bigger gap is input: $2.50 versus $1.75. That means GPT-5.3-Codex becomes especially attractive in prompt-heavy workflows where you repeatedly send lots of code or repo context but do not need GPT-5.4's broader capabilities.
The context-window story is also easy to oversell if you ignore cost. GPT-5.4's 1,050,000-token context is a real upgrade over GPT-5.3-Codex's 400,000. For architecture review, repo-level understanding, and long-running agentic sessions, that is a major practical advantage. But OpenAI's current GPT-5.4 model doc also says prompts above 272K input tokens are charged at 2x input and 1.5x output for the whole session. That means you should not blindly route every large prompt to GPT-5.4 just because it fits. The model gives you a bigger ceiling, not a free lunch.
Tool support makes the bigger strategic difference. GPT-5.4's model doc confirms support for web search, hosted shell, apply patch, MCP, computer use, and other tool surfaces that matter when coding work spills into multi-step operations. That is a big reason why GPT-5.4 is the stronger default in mixed workflows. GPT-5.3-Codex still feels like a specialist. GPT-5.4 feels like a workhorse.
This difference also changes how you should think about routing. If your system classifies tasks before sending them to a model, the classifier does not need to ask only "how hard is this coding problem?" It should also ask "will this job need browsing, patching, multi-tool iteration, or very large context?" The more often the answer is yes, the stronger the case for making GPT-5.4 the default route and preserving GPT-5.3-Codex only as a lower-cost specialist lane.
If you are still working out broader OpenAI billing logic, our older but still useful OpenAI API key pricing guide can help frame how token costs affect production design, even though the exact flagship model prices have evolved.
Which Model Should You Use for Each Workflow
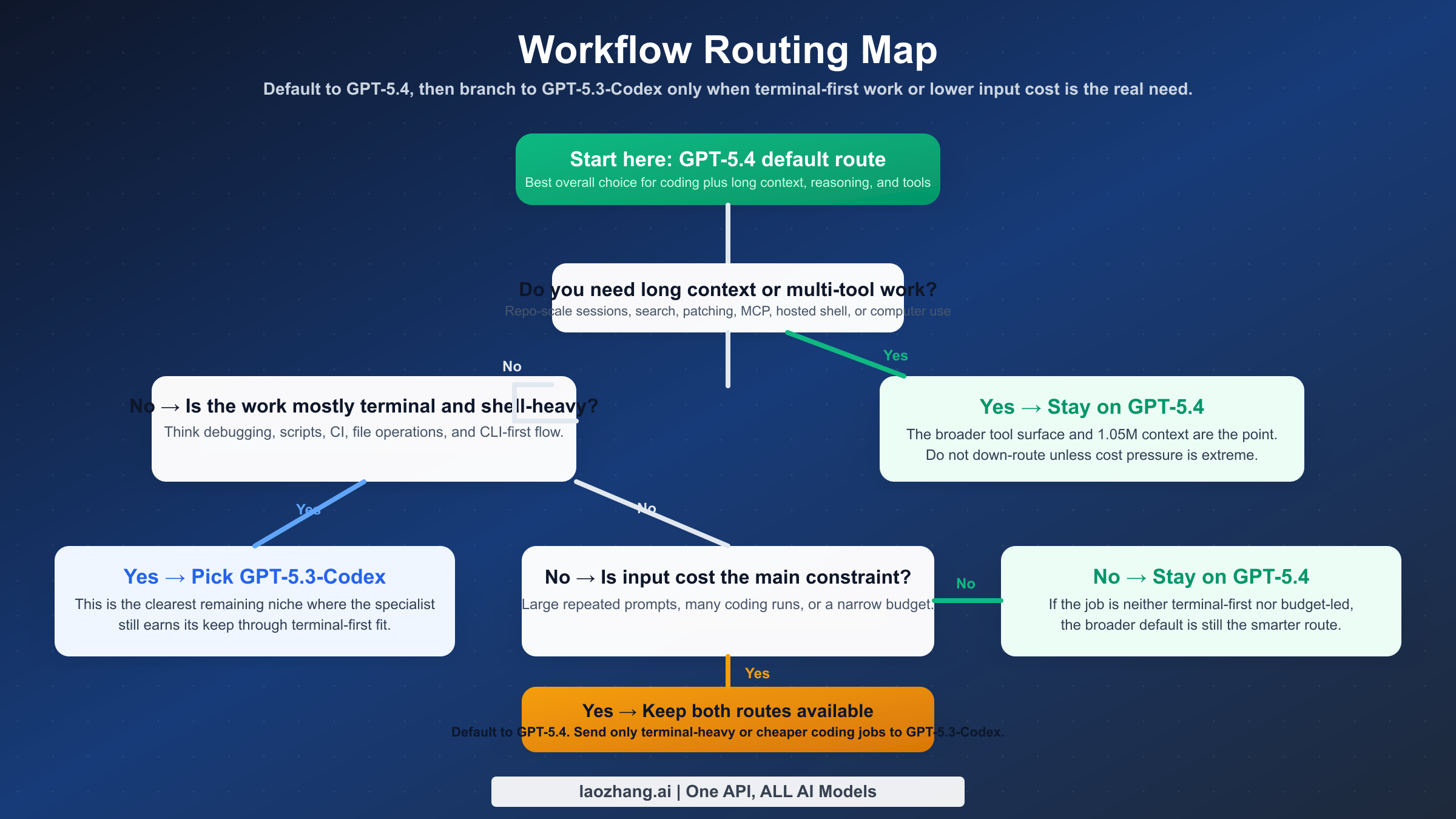
This is the decision table most comparison pages skip, even though it is the real reason the keyword exists.
| Workflow | Use GPT-5.4 | Use GPT-5.3-Codex | Why |
|---|---|---|---|
| Default model in Codex for most developers | Yes | No | GPT-5.4 is broader and now the official default-style positioning |
| Terminal-heavy engineering and shell-first debugging | Sometimes | Yes | GPT-5.3-Codex still leads on Terminal-Bench 2.0 |
| Long-context repo analysis | Yes | Rarely | 1.05M context materially changes what fits in one session |
| Multi-tool agentic workflows | Yes | Rarely | GPT-5.4's tool surface is much broader |
| Budget-sensitive coding with large repeated prompts | Sometimes | Yes | Lower input and cached-input costs still matter |
| Mixed professional work beyond code | Yes | No | GPT-5.4 is a better one-model default |
For a solo developer or a small engineering team, GPT-5.4 should be the default unless you already know your workload is unusually terminal-heavy. It reduces routing complexity, gives you more room for long-context tasks, and handles mixed work better when coding turns into planning, searching, or writing.
For a platform, DevOps, or infrastructure engineer, the answer is more balanced. If your tasks are mostly shell commands, environment fixes, deployment scripts, CI work, and command-line debugging, GPT-5.3-Codex can still feel better per dollar. Its remaining benchmark edge is not academic in that environment.
For staff engineers, tech leads, or architecture-heavy work, GPT-5.4 is easier to justify. You are more likely to benefit from the larger context window, better general reasoning, and stronger mixed-tool posture. Those jobs are rarely just terminal work. They are interpretation, decision support, synthesis, and long-range context management.
For teams routing requests automatically, the best answer is often both. Default to GPT-5.4. Fall back to GPT-5.3-Codex when the task is shell-dominant, code-local, and highly input-sensitive. If you already use a gateway layer such as laozhang.ai for model routing, this split is straightforward to operationalize because the question becomes workload classification, not vendor switching.
When GPT-5.3-Codex Still Makes Sense
Many articles flatten the answer into "GPT-5.4 replaces GPT-5.3-Codex." That is directionally true at the product-positioning level, but it is too blunt for real engineering use.
GPT-5.3-Codex still makes sense in four cases. The first is terminal-first work. If the job is closer to shell operations than broad agentic reasoning, GPT-5.3-Codex still has benchmark evidence on its side. The second is input-heavy cost control. A 30% cheaper input price matters when you send large prompts all day. The third is specialized coding environments where you do not need GPT-5.4's broader tool breadth. The fourth is fallback routing, where keeping GPT-5.3-Codex available gives you a second strong coding path instead of forcing everything through one newer model.
This is also where community posts are worth reading carefully but not literally. Recent March 2026 threads about GPT-5.4 and GPT-5.3-Codex access breaking in some Codex plans are useful as friction signals, but they do not overturn the official product story. They tell you that model-surface behavior can still be messy. They do not prove that GPT-5.3-Codex is being abandoned or that GPT-5.4 is a bad default.
A better operating rule is this: treat GPT-5.4 as the primary route and GPT-5.3-Codex as the tactical exception. That reflects both the official documentation and the real edge cases developers still care about.
Migration Checklist: Moving from GPT-5.3-Codex to GPT-5.4
If your team already uses GPT-5.3-Codex as the default, the smartest migration is incremental rather than ideological.
- Switch your default route to GPT-5.4 for general coding, long-context repo work, and any tool-heavy agentic tasks.
- Keep GPT-5.3-Codex available for terminal-heavy workflows, especially shell-first debugging and scripting.
- Add cost monitoring around large prompts so GPT-5.4 sessions above 272K input tokens do not silently inflate spend.
- Re-test your highest-value tasks instead of trusting benchmark tables alone. Compare one long-context repo task, one terminal workflow, and one multi-tool task.
- Document a fallback rule for temporary Codex access regressions so your team does not confuse service noise with a model-choice decision.
That migration pattern is stronger than a hard cutover because it reflects how these models are actually differentiated. GPT-5.4 should become the center. GPT-5.3-Codex should become a deliberate specialist, not a forgotten legacy option.
If part of your team is still focused on ChatGPT-side model access rather than API routing, our guide to ChatGPT Plus vs free speed and quota behavior for GPT-5 may help clarify where product-surface confusion starts before you even get to model quality.
FAQ
Is GPT-5.4 strictly better than GPT-5.3-Codex?
No. GPT-5.4 is better overall and should be the default for most users, but GPT-5.3-Codex still keeps a real edge on Terminal-Bench 2.0 and remains cheaper on input tokens. If your work is highly terminal-centric or very prompt-heavy, GPT-5.3-Codex can still be the better tactical choice.
Is the GPT-5.4 price increase worth it?
Usually yes, if you actually use the broader capabilities. The input price increase is meaningful, but the output gap is small, and GPT-5.4 gives you a much larger context window plus a broader tool surface. If you only need short coding runs and shell work, the extra spend is harder to justify.
Does GPT-5.4 really replace GPT-5.3-Codex in Codex?
At the product-positioning level, yes. OpenAI now presents GPT-5.4 as the mainline frontier default for coding and agentic work. At the workflow level, no. GPT-5.3-Codex still has a narrower but legitimate role for terminal-heavy and cheaper coding routes.
Should I worry about recent Codex access issues when choosing between them? You should notice them, but you should not over-interpret them. Community reports from March 2026 are useful signals that surface behavior can still be rough. They are not strong evidence that the official product direction has changed. Use official model docs and launch pages for the durable facts, and treat outage-style threads as temporary operational context.