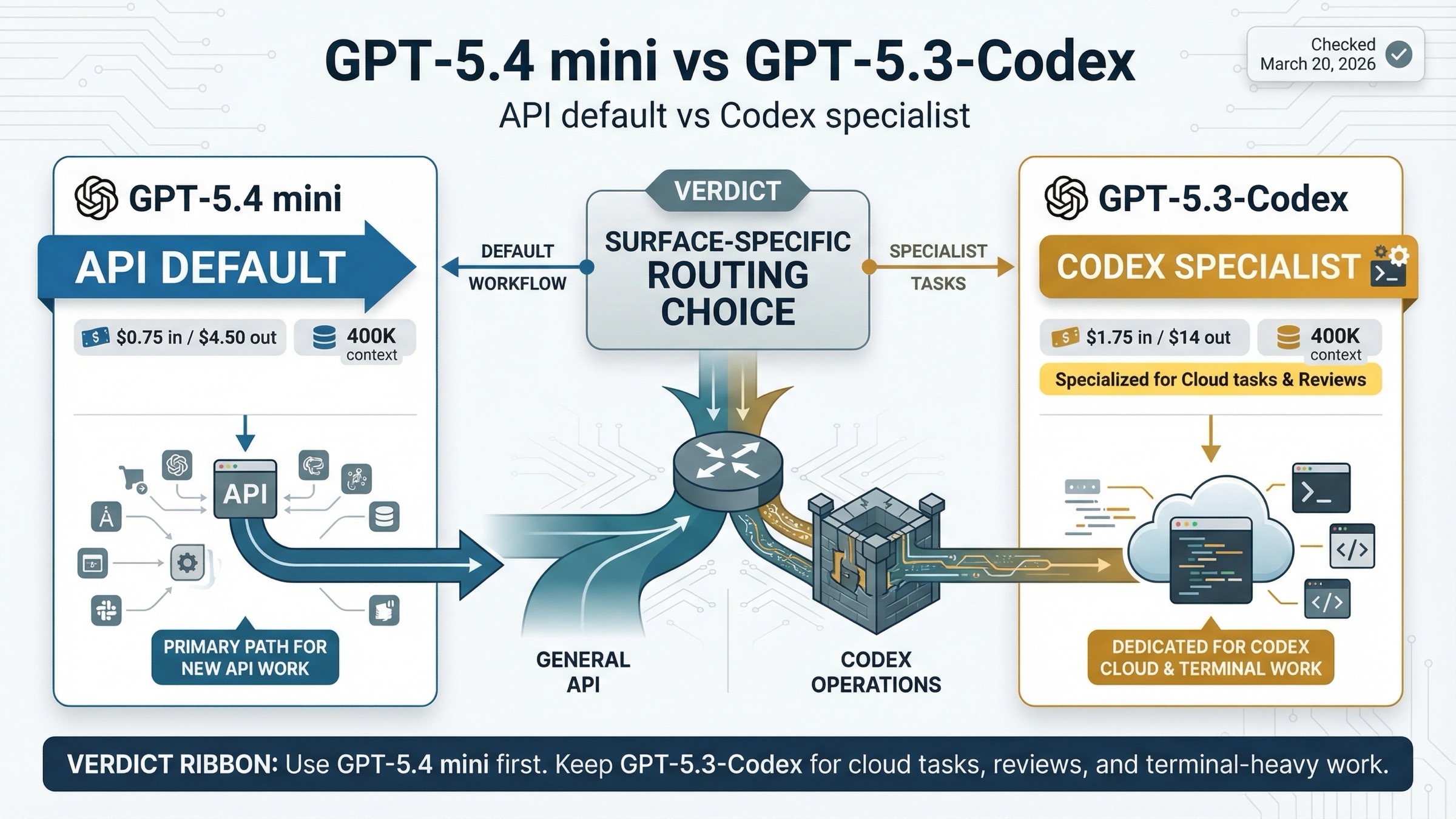
Use GPT-5.4 mini for new API and subagent work. Keep GPT-5.3-Codex for heavier specialist coding inside Codex when code review, terminal work, and deeper coding behavior matter more than small-model price efficiency.
The comparison only becomes clear once you separate surfaces. In the API, GPT-5.4 mini is the cheaper newer default for many high-volume coding workflows. In Codex-style environments, GPT-5.3-Codex still has a stronger specialist coding posture.
TL;DR
If you only want the practical answer, use this rule:
| Model | Best for | Main reason to choose it | Main reason not to choose it |
|---|---|---|---|
| GPT-5.4 mini | New API builds, coding subagents, screenshot-heavy workers, cheap high-volume local Codex work | Cheaper than GPT-5.3-Codex, broader current tool matrix, and the active small-model recommendation | Weaker specialist coding benchmarks than GPT-5.3-Codex, and no current Codex cloud tasks or code reviews |
| GPT-5.3-Codex | Terminal-heavy coding, deeper specialist coding runs, Codex cloud tasks, Codex code reviews | Stronger coding-specific benchmark profile and fuller Codex product support | Much more expensive in the API and no longer the default small-model recommendation |
The shortest decision rule is:
- If you are building in the API and need a strong small model for coding, tool use, or subagents, start with GPT-5.4 mini.
- If your work happens mainly inside Codex and depends on cloud tasks or GitHub code reviews, keep GPT-5.3-Codex available.
- If your engineering flow is heavily terminal-first, GPT-5.3-Codex still has a real case because its benchmark profile remains stronger for that shape of work.
- If you are deciding from ChatGPT model-picker names, stop and separate that from this comparison. This article is mainly about API and Codex workflow choice, not the ChatGPT picker.
What Actually Changes Between GPT-5.4 mini and GPT-5.3-Codex
The easiest way to get this comparison wrong is to assume GPT-5.4 mini is just a cheaper, smaller version of the same job GPT-5.3-Codex was built for. That is not quite right.
According to OpenAI's current model pages, both models share several top-level specs:
- 400K context window
- 128K max output tokens
- Aug 31, 2025 knowledge cutoff
- text and image input support
That means context and freshness do not decide this comparison. If you only skim spec cards, the models look closer than they really are.
The real difference is product role.
OpenAI's current Using GPT-5.4 guide recommends gpt-5.4-mini for high-volume coding, computer use, and agent workflows that still need strong reasoning. That is the current small-model default posture.
By contrast, the current GPT-5.3-Codex model page still describes it as the most capable agentic coding model to date and says it is optimized for Codex or similar environments. That is a narrower, more specialist positioning.
So the mental model should be this:
| Question | Better fit |
|---|---|
| Need the current small-model default for API coding and subagents? | GPT-5.4 mini |
| Need the deeper coding specialist, especially in Codex workflows? | GPT-5.3-Codex |
| Need cloud tasks and code reviews in Codex? | GPT-5.3-Codex |
| Need cheaper local routine work in Codex or lower API cost? | GPT-5.4 mini |
This is why a broad "winner" label is not enough. The right recommendation changes depending on whether you are making an API routing decision or a Codex product decision.
Benchmarks That Matter for Real Coding Work

There is no single official page that directly pits GPT-5.4 mini against GPT-5.3-Codex in one shared table. But OpenAI does publish benchmark tables for both models on their respective launch pages, and those are enough to map the practical split.
From the official March 17, 2026 GPT-5.4 mini launch post, GPT-5.4 mini is listed at:
- 54.4% SWE-Bench Pro
- 60.0% Terminal-Bench 2.0
- 72.1% OSWorld-Verified
From the official February 5, 2026 GPT-5.3-Codex launch post, GPT-5.3-Codex is listed at:
- 56.8% SWE-Bench Pro
- 77.3% Terminal-Bench 2.0
- 64.7% OSWorld-Verified
Put side by side, the practical pattern is clear:
| Benchmark | GPT-5.4 mini | GPT-5.3-Codex | What it means |
|---|---|---|---|
| SWE-Bench Pro | 54.4% | 56.8% | GPT-5.3-Codex still has the stronger coding-specialist profile |
| Terminal-Bench 2.0 | 60.0% | 77.3% | GPT-5.3-Codex is much stronger for terminal-heavy engineering |
| OSWorld-Verified | 72.1% | 64.7% | GPT-5.4 mini is stronger for screenshot-grounded and computer-use-like work |
That benchmark split matches the product positioning surprisingly well.
If your work looks like shell operations, repo-local debugging, build tooling, CLI automation, and heavy terminal loops, GPT-5.3-Codex still has the better benchmark case. This is not a small rounding difference on Terminal-Bench. It is a large enough gap to matter for the kind of users who live in the terminal.
If your work looks more like screenshot interpretation, broader tool use, or smaller workers inside an agent system, GPT-5.4 mini starts to look stronger. Its OSWorld result is the most important clue there. It suggests the newer mini line is better aligned with the kind of UI-grounded or computer-use-adjacent work OpenAI now cares about in the GPT-5.4 family.
That is why the best summary is not "GPT-5.4 mini is better" or "GPT-5.3-Codex is stronger." The better summary is:
- GPT-5.3-Codex wins the deeper coding-specialist lane
- GPT-5.4 mini wins the cheaper modern small-model lane with stronger computer-use fit
For readers deciding whether they actually need the broader flagship model rather than either of these smaller choices, our GPT-5.4 vs GPT-5.3-Codex comparison is the better companion page.
API Pricing, Tool Support, and Rate-Limit Reality
The pricing story is where GPT-5.4 mini stops being a subtle recommendation and becomes a very practical one.
According to the current official model pages checked on March 20, 2026:
| Spec | GPT-5.4 mini | GPT-5.3-Codex |
|---|---|---|
| Input price | $0.75 / 1M tokens | $1.75 / 1M tokens |
| Cached input | $0.075 / 1M tokens | $0.175 / 1M tokens |
| Output price | $4.50 / 1M tokens | $14.00 / 1M tokens |
| Context window | 400K | 400K |
| Max output | 128K | 128K |
| Knowledge cutoff | Aug 31, 2025 | Aug 31, 2025 |
This is the opposite of what some users assume. GPT-5.3-Codex is not the budget option here. In the API, GPT-5.4 mini is dramatically cheaper:
- less than half the input price
- less than half the cached-input price
- less than one-third the output price
That changes the default recommendation immediately. If you are routing pure API traffic and the task fits GPT-5.4 mini well, there is very little reason to make GPT-5.3-Codex your default first test.
Tool posture also tilts toward GPT-5.4 mini in the API. The current GPT-5.4 mini model page lists support for:
- web search
- file search
- image generation
- code interpreter
- hosted shell
- apply patch
- skills
- computer use
- MCP
- tool search
The GPT-5.3-Codex model page presents a much narrower feature view. It supports structured outputs and function calling, but it does not expose the same broader Responses tool matrix that the GPT-5.4 mini page currently shows.
Rate limits do not rescue GPT-5.3-Codex as the obvious API default either. On the current model pages:
| Tier | GPT-5.4 mini TPM | GPT-5.3-Codex TPM |
|---|---|---|
| Tier 1 | 500,000 | 500,000 |
| Tier 2 | 2,000,000 | 1,000,000 |
| Tier 3 | 4,000,000 | 2,000,000 |
| Tier 4 | 10,000,000 | 4,000,000 |
| Tier 5 | 180,000,000 | 40,000,000 |
So if you are comparing API economics plus current published limits, GPT-5.4 mini has the more attractive shape for most new small-model builds.
This is why the API-side recommendation can be direct: default to GPT-5.4 mini unless your coding workload is specialized enough that GPT-5.3-Codex's benchmark edge matters more than the price and tool advantage.
If you are still deciding whether the newer small-model line is better than the older cheap mini line rather than Codex, the related page to read is GPT-5.4 mini vs GPT-5 mini.
Codex Changes the Recommendation
This is the section most current pages miss, and it is where the keyword becomes genuinely useful.
Inside Codex, GPT-5.4 mini is not simply a cheap replacement for GPT-5.3-Codex.
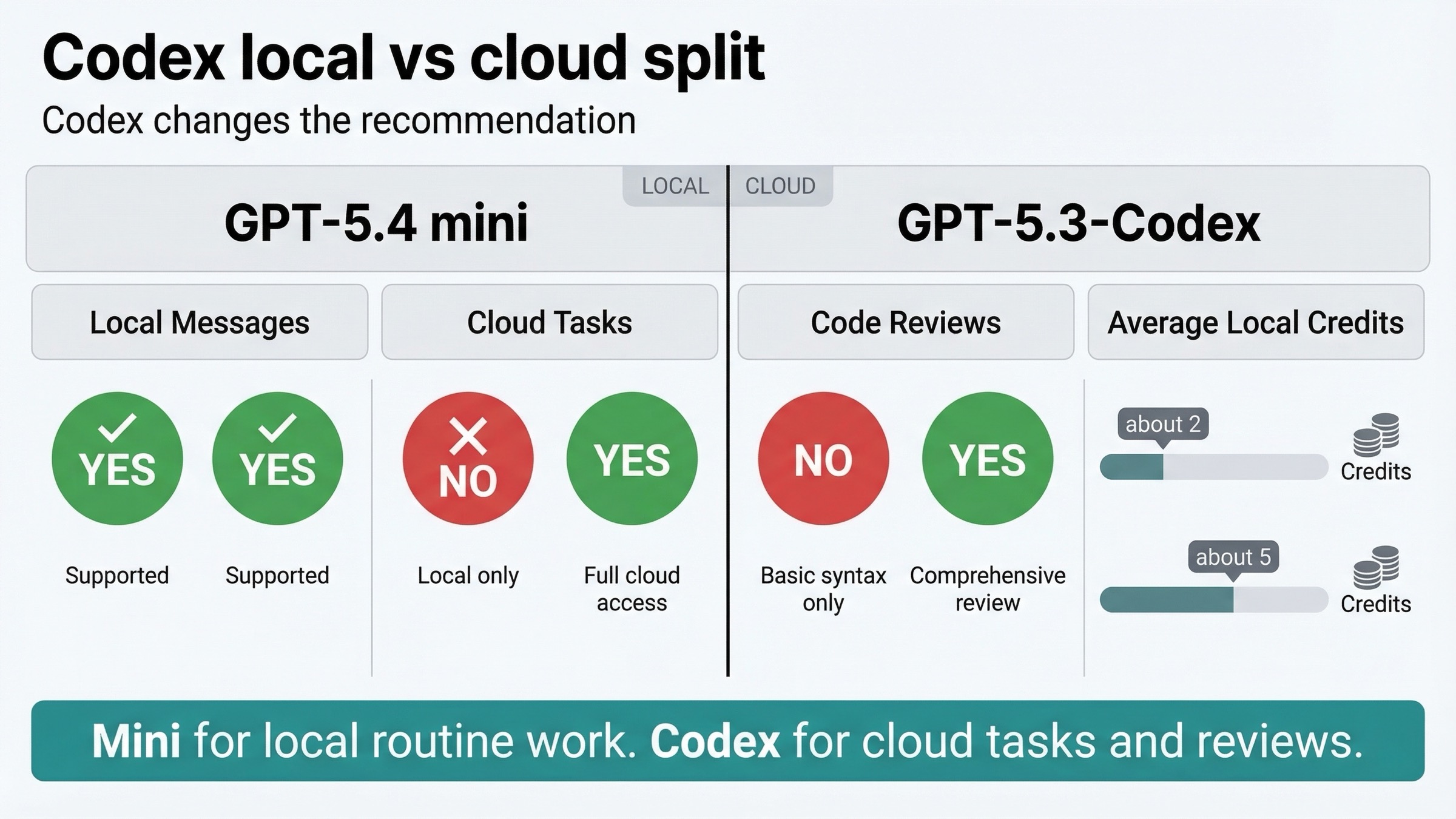
The current Codex pricing page says:
- GPT-5.4 mini gives up to 3.3x higher local-message limits
- GPT-5.4 mini uses about 2 credits for an average local task
- GPT-5.3-Codex uses about 5 credits for an average local task
That makes GPT-5.4 mini extremely attractive for:
- routine local coding tasks
- quick file reads or edits
- cheap supporting work in the Codex app, CLI, IDE extension, or web
But the same page also shows the crucial caveat:
| Codex capability | GPT-5.4 mini | GPT-5.3-Codex |
|---|---|---|
| Local messages | Yes | Yes |
| Cloud tasks | No | Yes |
| Code reviews | No | Yes |
This is the most important fact in the whole article.
If your Codex workflow depends on cloud tasks or GitHub code reviews, GPT-5.4 mini is not a full substitute today. GPT-5.3-Codex still owns those lanes.
That means the right Codex recommendation is not identical to the right API recommendation:
- Codex local routine work: GPT-5.4 mini is often the smarter default
- Codex cloud tasks and code reviews: GPT-5.3-Codex still matters
This also explains a lot of March 2026 user confusion. Community threads on Reddit complained about GPT-5.4 or GPT-5.3-Codex availability shifts in different plans and surfaces, but those posts mostly describe temporary UI or access friction. They do not change the durable product fact that GPT-5.4 mini and GPT-5.3-Codex currently occupy different Codex jobs.
So if you work mainly inside Codex, the question should not be "Which one replaces the other?" It should be "Which one should I use for local work, and which one do I still need for cloud or review workflows?"
Which Model Should You Use for Each Workflow
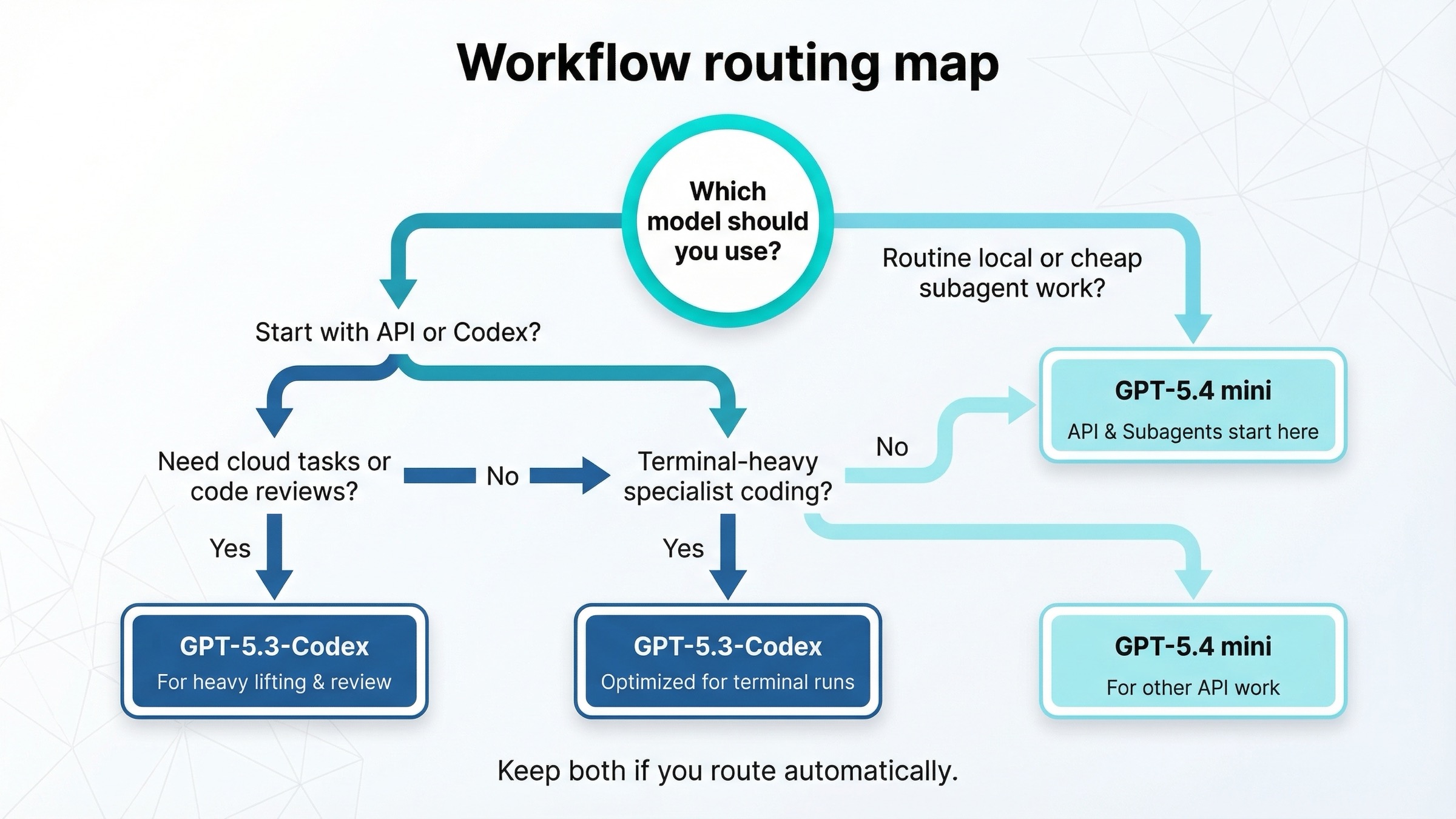
This is the decision matrix most users actually need.
| Workflow | Use GPT-5.4 mini | Use GPT-5.3-Codex | Why |
|---|---|---|---|
| New API default for coding workers | Yes | Rarely | GPT-5.4 mini is cheaper, current, and broadly tool-capable |
| Cheap subagents under a larger planner | Yes | Rarely | This is exactly the lane OpenAI now describes for mini |
| Screenshot-heavy or computer-use-like worker | Yes | Sometimes | GPT-5.4 mini's OSWorld result and tool posture are stronger |
| Terminal-heavy engineering | Sometimes | Yes | GPT-5.3-Codex still has the much better Terminal-Bench result |
| Codex local routine work | Yes | Sometimes | GPT-5.4 mini stretches local quotas further |
| Codex cloud tasks | No | Yes | GPT-5.3-Codex still owns this slot |
| Codex GitHub code reviews | No | Yes | GPT-5.3-Codex still owns this slot |
| One specialist model for deeper coding loops | Sometimes | Yes | GPT-5.3-Codex remains the stronger specialist choice |
For a typical API team, the answer is simple: start with GPT-5.4 mini and only route to GPT-5.3-Codex when the task is clearly coding-specialist or terminal-heavy.
For a typical Codex power user, the best answer is often both:
- GPT-5.4 mini for cheap, high-volume local work
- GPT-5.3-Codex for cloud tasks, code reviews, and the harder coding lane
That is a better architecture than forcing every job through one model just because it is newer or more specialist.
When GPT-5.3-Codex Still Makes Sense
Many comparison pages flatten this into "GPT-5.4 mini is newer, so use that." That would make this article shorter, but it would also make it less correct.
GPT-5.3-Codex still makes sense in four situations.
First, terminal-heavy work. If your real job is close to shell operations, repo-local debugging, scripting, and CLI-driven engineering, GPT-5.3-Codex still has the strongest evidence in its favor.
Second, Codex cloud workflows. This is the cleanest reason to keep it. If you rely on cloud tasks or code reviews, GPT-5.3-Codex is still the model with the current product support.
Third, deeper specialist coding runs. The benchmark split suggests GPT-5.3-Codex still has the better profile for harder coding-specific work, even though GPT-5.4 mini is the better cheap modern default.
Fourth, fallback routing. Some teams should not think in terms of one permanent winner. A better rule is:
- mini first for cheap, broad, current small-model work
- Codex second for specialist coding or Codex cloud tasks
That is a healthier routing design than letting an older specialist model remain the default out of inertia.
If you also need to compare GPT-5.3-Codex with a non-OpenAI specialist coding model, GPT-5.3-Codex vs Claude Opus 4.6 is the better next read.
FAQ
Is GPT-5.4 mini better than GPT-5.3-Codex for coding?
Not across every coding benchmark. GPT-5.3-Codex is still stronger on SWE-Bench Pro and much stronger on Terminal-Bench 2.0. But GPT-5.4 mini is much cheaper in the API, is the current small-model recommendation, and looks better for screenshot-heavy or computer-use-adjacent work.
Why is GPT-5.4 mini the default recommendation if GPT-5.3-Codex scores better on coding benchmarks?
Because the default recommendation is not based on one benchmark row. It is based on the full operating picture: API price, current tool support, rate limits, product direction, and the fact that many coding systems are really mixed tool-and-agent systems rather than pure terminal agents.
Does GPT-5.4 mini replace GPT-5.3-Codex inside Codex?
No, not completely. GPT-5.4 mini is excellent for local routine work in Codex, but the current Codex pricing page still shows no cloud tasks and no code reviews for GPT-5.4 mini. GPT-5.3-Codex still matters there.
Should ChatGPT naming affect this choice?
Only if your real question is about ChatGPT plan behavior. The current Help Center says GPT-5.3 is still the default ChatGPT line while GPT-5.4 Thinking is a separate paid-tier choice. That is a different surface from choosing API or Codex models.
Which model should a new team test first?
For API work, test GPT-5.4 mini first. For Codex-heavy work, test GPT-5.4 mini for local routine work and GPT-5.3-Codex for cloud-task or review workflows. That gets you to the practical answer faster than forcing one universal winner.
Final Recommendation
If you want one line to take back to your team, use this one: GPT-5.4 mini is the right default for new API and subagent work, but GPT-5.3-Codex is still the model to keep when your work is terminal-heavy or depends on Codex cloud tasks and reviews.
That recommendation is stronger than a generic "newer versus older" answer because it matches the actual March 2026 product reality:
- GPT-5.4 mini is cheaper and more attractive in the API
- GPT-5.3-Codex still keeps the stronger specialist coding profile
- Codex plan behavior means the models are not interchangeable
So the real choice is not whether one of these models should completely erase the other. The real choice is whether you are disciplined enough to give each one the lane it is actually best at.