
Gemini 3 Pro Image, officially known as gemini-3-pro-image-preview and codenamed "Nano Banana Pro," represents Google's most advanced AI image generation model available to developers. Unlike its faster sibling Gemini 2.5 Flash Image, Gemini 3 Pro Image specializes in premium 4K resolution output with exceptional text rendering capabilities. As of December 2025, third-party API providers offer access at approximately $0.05 per 4K image—roughly 80% cheaper than Google's official pricing of $0.24 per 4K image. These providers achieve "unlimited concurrency" through sophisticated API aggregation architecture, effectively bypassing Google's default rate limits of 5-500 requests per minute. This guide provides verified pricing breakdowns, provider comparisons, and complete implementation code.
What is Gemini 3 Pro Image (Nano Banana Pro)?
Google's Gemini 3 Pro Image model stands as the premium tier in their AI image generation lineup, designed specifically for professional and enterprise use cases requiring the highest quality output. Released through the Gemini API and Google AI Studio, this model introduces capabilities that distinguish it significantly from the more commonly discussed Gemini 2.5 Flash Image model.
The fundamental difference lies in output quality and resolution. While Gemini 2.5 Flash Image focuses on speed and cost efficiency with 1024x1024 pixel output, Gemini 3 Pro Image pushes boundaries with support for resolutions up to 4096x4096 pixels—true 4K quality that meets professional production standards. This four-fold increase in pixel density transforms the practical applications from simple web graphics to print-ready marketing materials, high-resolution product photography, and detailed architectural visualizations.
Technical Specifications of Gemini 3 Pro Image
The model's architecture introduces several advanced capabilities that justify its premium positioning. According to Google's official documentation (https://ai.google.dev/gemini-api/docs/image-generation ), the 64K token context window allows for remarkably detailed and nuanced prompts. Unlike simpler image generators that struggle with complex multi-element scenes, Gemini 3 Pro Image can process extensive descriptions covering composition, lighting, style, and specific visual elements while maintaining coherence across all elements.
Text rendering represents one of the model's most significant technical achievements. Professional applications frequently require images containing legible text—product labels, signage, user interface mockups, or infographic elements. Gemini 3 Pro Image generates sharp, readable text that integrates naturally with visual elements, a capability that has historically challenged AI image generators. This makes it particularly valuable for creating marketing assets, educational materials, and business presentations where text-image integration is essential.
The multi-image composition feature accepts up to 14 reference images, including 6 objects and 5 human subjects for consistency maintenance. This enables complex workflows like maintaining character consistency across multiple generated images, transferring visual styles from reference images, or composing scenes that incorporate specific product photographs with AI-generated backgrounds.
Gemini 3 Pro vs Gemini 2.5 Flash: When Pro is Worth the Premium
Understanding when to use each model optimizes both cost and output quality. For applications generating large volumes of standard-resolution images—social media content, thumbnail generation, or rapid prototyping—Gemini 2.5 Flash Image at $0.039 per 1K image delivers excellent value. However, specific use cases justify Gemini 3 Pro's higher cost structure.
E-commerce product photography benefits enormously from 4K resolution. When images will be zoomed, cropped, or displayed on high-resolution screens, the additional detail prevents pixelation and maintains professional appearance. Marketing agencies creating hero images for campaigns, billboard designs, or print advertisements require resolution that only the Pro model provides. Similarly, applications in architectural visualization, interior design, and fashion lookbooks demand the fidelity that 4K output delivers.
For those exploring the broader Gemini ecosystem, our Gemini 3.0 API complete guide covers the full range of capabilities beyond image generation, including the text and multimodal models that complement image generation workflows.
Thinking Mode: A Unique Pro Feature
One of Gemini 3 Pro Image's most innovative capabilities involves its "thinking mode" for complex prompts. When processing particularly intricate generation requests, the model can produce interim "thought images" that represent its reasoning process before arriving at the final output. This transparency into the generation process proves valuable for iterative refinement workflows—you can observe how the model interprets your prompt and adjust subsequent requests accordingly.
The thinking mode activates automatically for prompts exceeding certain complexity thresholds, particularly those involving multiple specific elements, precise spatial relationships, or detailed stylistic requirements. While this feature adds slight latency compared to direct generation, the improved accuracy for complex scenes typically justifies the additional processing time.
Google Search Grounding for Real-Time Data
The integration of Google Search grounding enables Gemini 3 Pro Image to generate imagery based on current real-world information. When your prompt references recent events, current product designs, or contemporary fashion trends, the model can incorporate search-derived context to produce more accurate and relevant outputs. This capability proves particularly valuable for marketing teams needing to reference current cultural moments or product designers working with recent design language trends.
However, note that when Google Search grounding is active, image-based search results are excluded from the grounding data for privacy and licensing reasons. The grounding draws primarily from text-based search results, which the model then interprets visually based on its training.
Gemini 3 Pro Image Pricing: Official vs Third-Party
The pricing structure for Gemini 3 Pro Image operates on a token-based model, with output costs varying by resolution. Understanding both official pricing and third-party alternatives enables informed decisions that can dramatically reduce production costs.
Official Google Pricing Breakdown
Google's pricing as documented on their official pricing page (https://ai.google.dev/gemini-api/docs/pricing ) structures costs around output tokens consumed per image. The base rate of $120 per million output tokens translates differently depending on resolution selection. For standard 1024x1024 images, each generation consumes approximately 1,290 tokens, resulting in $0.039 per image—competitive with alternatives like DALL-E 3. However, Gemini 3 Pro's strength lies in higher resolutions where the economics shift significantly.
At 2K resolution (2048x2048), images consume approximately 1,120 tokens each, pricing at $0.134 per image. The premium 4K resolution (4096x4096) requires roughly 2,000 tokens, establishing the $0.24 per image price point that positions this as a professional-tier service. These prices reflect Google's direct API access through AI Studio or Vertex AI.
Third-Party Pricing Reality Check
Third-party API providers have established a competitive market offering Gemini 3 Pro Image access at substantial discounts. Based on current market research as of December 2025, providers like laozhang.ai offer access at approximately $0.05 per 4K image, while others like Kie.ai price around $0.12 for equivalent output. These represent genuine cost reductions of 50-80% compared to direct Google pricing.
The mathematics supporting the "$0.05 equals 20% of official" claim holds up to scrutiny: $0.05 ÷ $0.24 = 0.208, or approximately 21% of Google's official 4K image price. This 79% discount sounds dramatic but reflects the economics of API aggregation businesses operating at scale.
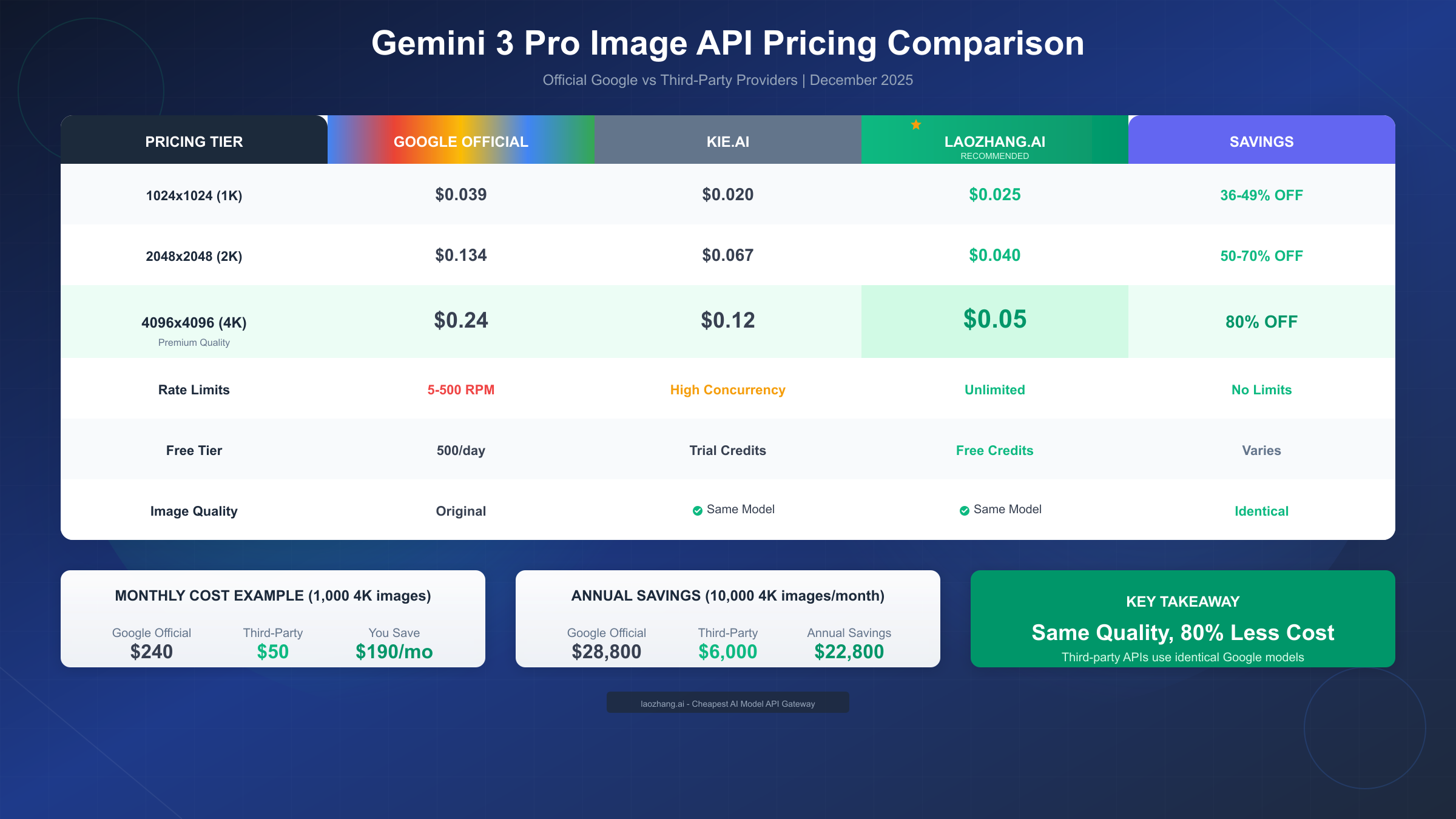
Why Third-Party Providers Offer Lower Prices
These providers achieve discounted pricing through several mechanisms. Volume purchasing power allows negotiation of enterprise rates from Google that individual developers cannot access. Operational efficiency through automated infrastructure reduces per-transaction overhead. Most importantly, API aggregation across multiple accounts distributes fixed costs across a larger request volume, enabling competitive pricing while maintaining profitability.
Critically, third-party providers function as routing layers rather than separate image generation services. When you submit a generation request to laozhang.ai or similar providers, your prompt forwards to Google's actual Gemini API endpoints. The underlying model processing your request remains identical to direct Google access—the same neural network architecture, training data, and generation algorithms produce your images. This architectural reality means output quality remains consistent regardless of access path.
For comprehensive pricing across the entire Gemini model family, our Gemini API pricing guide provides detailed comparisons including text models and the Flash variants.
Volume Discount Opportunities
Enterprise customers generating substantial volumes benefit from additional discount opportunities beyond third-party pricing. Google offers committed use discounts for annual contracts exceeding $50,000 in projected usage, potentially reducing costs by up to 35% from standard rates. For organizations at this scale, comparing third-party pricing against enterprise-negotiated Google rates requires careful analysis of total cost including support, compliance, and operational factors.
Batch processing provides another cost optimization path. For analytics jobs, nightly content generation, or evaluation pipelines where real-time response isn't required, Google's Batch Mode offers approximately 50% discount over real-time pricing. Third-party providers increasingly offer similar batch processing options, compounding savings for latency-tolerant workloads.
Understanding Token Consumption Patterns
Optimizing costs requires understanding how different prompt types affect token consumption. While output tokens (the generated image) represent the primary cost driver, input tokens for prompts also factor into total costs. Complex prompts with extensive descriptions consume more input tokens, though this impact remains minor compared to output costs.
Multi-image composition requests involving reference images consume additional input tokens based on image resolution and quantity. When uploading reference images for style transfer or composition, consider resizing inputs to the minimum resolution that preserves necessary detail. This optimization reduces input token consumption without significantly impacting output quality.
How "Unlimited Concurrency" Actually Works
The claim of "unlimited concurrency" through third-party providers requires technical explanation to understand both its validity and limitations. Google implements rate limiting across all API access tiers, making this claim initially seem impossible.
Understanding Google's Official Rate Limits
Google structures API access through tiered rate limits designed to ensure service stability and fair resource distribution. Free tier users face the most restrictive limits: 5 requests per minute (RPM), 250,000 tokens per minute (TPM), and 100 requests per day (RPD). These limits increase substantially through paid tiers—Tier 1 users access 60 RPM, while Tier 3 enterprise accounts reach 2,000 RPM with unlimited daily requests.
For Gemini image generation specifically, Images Per Minute (IPM) tracks visual content generation separately from text processing, recognizing the significantly higher computational cost of image synthesis. Even at the highest official tier, 2,000 RPM represents a ceiling that high-volume applications can encounter during peak usage.
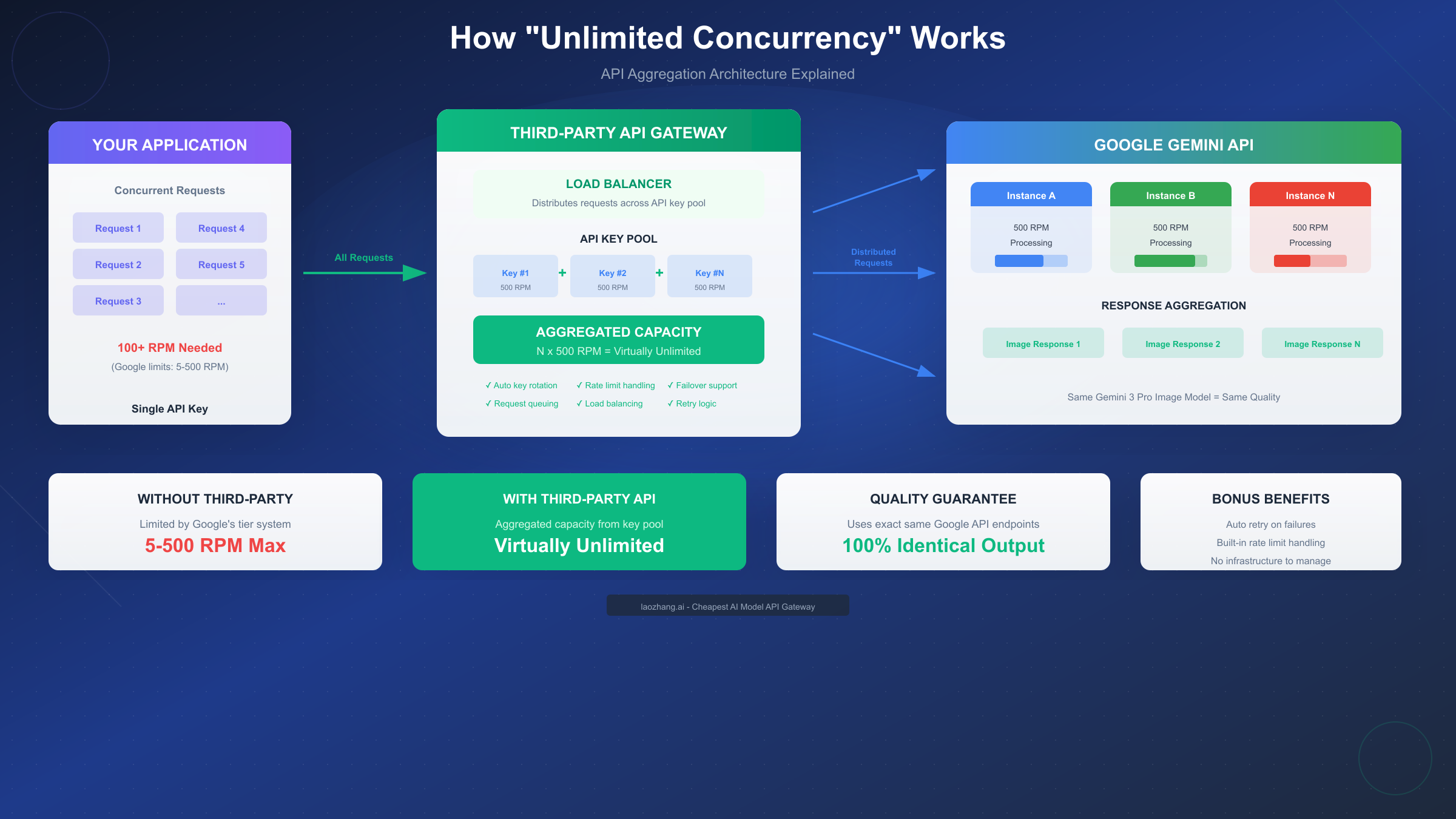
The API Aggregation Architecture
Third-party providers achieve effectively unlimited concurrency through a sophisticated technical architecture. Rather than operating a single API key with its associated rate limits, providers maintain pools of multiple API keys distributed across numerous accounts. When your application sends requests to the provider's endpoint, a load balancer distributes these requests across the key pool, effectively multiplying the available rate limit capacity.
Consider a provider maintaining 100 API keys, each with 500 RPM capacity. The theoretical aggregate capacity reaches 50,000 RPM—far exceeding any individual application's practical needs. Advanced implementations include automatic key rotation that distributes requests evenly to prevent any single key from approaching its limits. When one key experiences temporary throttling, requests automatically route to available alternatives.
Load Balancing and Failover Mechanisms
Professional API aggregation services implement multiple reliability layers. Request queuing absorbs traffic spikes by buffering requests during brief congestion periods rather than immediately returning errors. Intelligent routing algorithms consider each key's current utilization and historical performance when assigning new requests. Failover mechanisms detect failed or throttled keys within milliseconds, redirecting traffic to healthy alternatives before your application experiences noticeable latency increases.
Retry logic handles the inevitable edge cases where requests fail. Rather than passing failures directly to your application, the provider's infrastructure automatically retries failed requests against different keys, often resolving transient issues transparently. This abstraction layer means your application code remains simpler—you write against a single endpoint without implementing complex retry and failover logic yourself.
Practical Implications for Developers
From a practical development perspective, unlimited concurrency through third-party providers means your application architecture can ignore rate limit considerations during design. Whether generating 10 or 10,000 images per hour, the same simple API integration handles the load. This simplification accelerates development timelines and reduces operational complexity.
The trade-off involves introducing a third-party dependency into your infrastructure stack. While reputable providers maintain high uptime, their availability now affects your application's functionality. Evaluation criteria should include the provider's historical uptime statistics, support responsiveness, and contingency options if service interruption occurs.
Rate Limit Headers and Monitoring
Professional API implementations monitor rate limit status through response headers. Google's API returns headers indicating remaining quota, reset timing, and current tier limits. Third-party providers typically abstract this complexity—their responses don't expose the underlying Google rate limits since their key pool management handles distribution automatically.
For applications requiring visibility into rate limit status (perhaps for capacity planning or alerting), some providers offer dashboard interfaces showing aggregate request volumes and any throttling events. This monitoring capability varies across providers; evaluate this requirement during provider selection if operational visibility matters for your use case.
Geographic Distribution Considerations
Request latency varies based on geographic distance between your application and the processing infrastructure. Google operates Gemini API endpoints across multiple regions, and third-party providers may route requests through specific geographic paths. For latency-sensitive applications, testing response times from your deployment region to various providers helps identify optimal configurations.
Some third-party providers offer region-specific endpoints allowing you to minimize network latency by selecting endpoints geographically proximate to your application servers. This optimization matters most for real-time applications where sub-second latency differences impact user experience.
Best Third-Party Providers for Gemini 3 Pro Image
Selecting the right API provider involves balancing pricing, reliability, feature set, and support quality. The current market includes several established options, each with distinct characteristics suited to different use cases.
Provider Comparison Overview
Based on market research conducted in December 2025, the primary providers serving Gemini 3 Pro Image access include laozhang.ai, Kie.ai, and several smaller competitors. Direct Google API access through AI Studio remains available for those prioritizing official support over cost optimization.
Laozhang.ai positions itself as a comprehensive AI API gateway, offering access to multiple model families including OpenAI, Anthropic Claude, and Google Gemini through a unified interface. Pricing for Gemini 3 Pro Image sits at approximately $0.05 per 4K image—the 80% discount figure prominently featured in market discussions. The platform includes free trial credits for new users, enabling evaluation before commitment.
Kie.ai focuses specifically on image generation APIs, offering both Gemini 2.5 Flash (Nano Banana) and Gemini 3 Pro Image (Nano Banana Pro) access. Their pricing structure uses credits with approximately 24 credits per Gemini 3 Pro image, translating to roughly $0.12 per generation—a 50% discount from official pricing but more expensive than laozhang.ai's offering.
Trust and Reliability Factors
Beyond pricing, several factors influence provider selection for production applications. Uptime history indicates operational maturity—providers with documented 99.9%+ uptime demonstrate the infrastructure investment necessary for reliable service. While precise statistics aren't always publicly available, provider responsiveness to status page maintenance and incident communication signals operational transparency.
Data handling practices matter for applications processing sensitive content. Reputable providers explicitly document that image generation requests pass through without logging or storage—your prompts and generated images aren't retained beyond the immediate generation process. Enterprise customers should verify compliance certifications relevant to their industry, such as SOC 2, GDPR compliance, or HIPAA for healthcare applications.
Support responsiveness varies significantly across providers. Evaluate available support channels (email, chat, community forums), typical response times, and availability of technical documentation. For production applications, the ability to reach technical support during incidents can prove invaluable.
Recommendations by Use Case
For individual developers and small projects prioritizing cost minimization, laozhang.ai's aggressive pricing and free trial credits enable experimentation without financial commitment. The unified API access across multiple model families simplifies projects using various AI capabilities.
Teams requiring moderate volumes with budget constraints find Kie.ai's focused image generation offering provides good value. Their specialized focus on image APIs means documentation and examples specifically target image generation workflows.
Enterprise applications prioritizing support guarantees and compliance documentation may find direct Google API access through Vertex AI worth the premium. Google's enterprise support channels, SLA commitments, and compliance certifications address requirements that third-party providers may not match.
For getting started with API access generally, our Gemini API key setup guide walks through the initial configuration process applicable whether you choose direct Google access or third-party providers.
Migration Strategies Between Providers
Organizations already using one API provider occasionally need to migrate to alternatives—whether for pricing changes, feature requirements, or reliability concerns. Successful migration requires systematic planning rather than rushed switching.
Begin by implementing provider abstraction in your application code. Rather than hardcoding API endpoints and authentication directly in business logic, externalize these configurations. Environment variables or configuration management systems allow endpoint switching without code changes. This architectural pattern—often called "provider agnostic design"—enables zero-downtime migrations when properly implemented.
Testing migration in staging environments before production cutover identifies compatibility issues. While most providers aim for OpenAI-compatible API formats, subtle differences in error response structures, rate limit handling, or optional parameters occasionally cause unexpected behavior. Comprehensive testing covering success paths, error conditions, and edge cases ensures smooth transitions.
Service Level Agreements and Guarantees
Enterprise deployments benefit from understanding SLA terms across provider options. Google's enterprise Vertex AI offering includes formal SLA commitments with defined uptime percentages and service credit provisions for failures. Third-party providers vary significantly in SLA formality—some offer written guarantees with financial remedies, while others provide only best-effort service without contractual commitments.
For production applications where downtime creates measurable business impact, SLA terms factor into total cost of ownership calculations. A provider charging slightly more but offering robust SLA protection may prove more economical than cheaper alternatives without guaranteed availability.
Quick Start: Gemini 3 Pro Image API Integration
Implementing Gemini 3 Pro Image generation requires understanding the API structure, authentication flow, and request formatting. This section provides working code examples that demonstrate integration patterns applicable to both direct Google access and third-party providers.
Basic Python Implementation
The following Python example demonstrates core integration patterns. This code works with third-party providers like laozhang.ai by modifying the base URL while maintaining the same request structure:
pythonimport requests import base64 import os from datetime import datetime class GeminiProImageGenerator: def __init__(self, api_key: str, base_url: str = None): """ Initialize the Gemini 3 Pro Image generator. Args: api_key: Your API key (laozhang.ai or Google) base_url: Custom base URL for third-party providers """ self.api_key = api_key # Default to Google's endpoint, override for third-party self.base_url = base_url or "https://generativelanguage.googleapis.com/v1beta" self.model = "gemini-3-pro-image-preview" def generate_image( self, prompt: str, resolution: str = "4K", aspect_ratio: str = "1:1" ) -> dict: """ Generate an image using Gemini 3 Pro Image. Args: prompt: Text description of desired image resolution: "1K", "2K", or "4K" aspect_ratio: One of "1:1", "16:9", "9:16", "4:3", "3:2" Returns: Dictionary containing image data and metadata """ endpoint = f"{self.base_url}/models/{self.model}:generateContent" headers = { "Content-Type": "application/json", "Authorization": f"Bearer {self.api_key}" } payload = { "contents": [{ "parts": [{ "text": prompt }] }], "generationConfig": { "responseModalities": ["IMAGE", "TEXT"], "imageGenerationConfig": { "outputResolution": resolution, "aspectRatio": aspect_ratio } } } response = requests.post(endpoint, headers=headers, json=payload) response.raise_for_status() return self._parse_response(response.json()) def _parse_response(self, response_data: dict) -> dict: """Extract image data from API response.""" result = { "success": False, "image_data": None, "mime_type": None, "text_response": None } if "candidates" in response_data: for candidate in response_data["candidates"]: for part in candidate.get("content", {}).get("parts", []): if "inlineData" in part: result["image_data"] = part["inlineData"]["data"] result["mime_type"] = part["inlineData"]["mimeType"] result["success"] = True elif "text" in part: result["text_response"] = part["text"] return result def save_image(self, image_data: str, filename: str) -> str: """Save base64 image data to file.""" image_bytes = base64.b64decode(image_data) filepath = f"{filename}_{datetime.now().strftime('%Y%m%d_%H%M%S')}.png" with open(filepath, "wb") as f: f.write(image_bytes) return filepath if __name__ == "__main__": # Initialize with laozhang.ai endpoint generator = GeminiProImageGenerator( api_key=os.environ.get("LAOZHANG_API_KEY"), base_url="https://api.laozhang.ai/v1" # Third-party endpoint ) # Generate a 4K product image result = generator.generate_image( prompt="""Professional product photography of a modern wireless headphone on a minimalist white background. Soft studio lighting with subtle shadows. Ultra high detail, commercial quality.""", resolution="4K", aspect_ratio="1:1" ) if result["success"]: saved_path = generator.save_image( result["image_data"], "product_shot" ) print(f"Image saved to: {saved_path}") else: print("Generation failed:", result.get("text_response"))
Configuration for Different Providers
The code structure above adapts to different providers through the base_url parameter. For direct Google API access, omit the parameter to use the default endpoint. For laozhang.ai or similar providers, substitute their specific API endpoint. Authentication methods may vary—some providers use API keys in headers, others in query parameters. Consult your chosen provider's documentation for exact requirements.
Error Handling Best Practices
Production implementations should expand error handling beyond the basic example above. Network timeouts, rate limit responses, and content policy rejections each require specific handling strategies. Implementing exponential backoff for transient failures prevents overwhelming the API during temporary issues while ensuring eventual success for valid requests.
For those new to Gemini API integration, our Gemini 2.5 Flash Image API guide provides additional context on the API structure that applies to both Flash and Pro models.
Batch Generation Patterns
Applications requiring multiple images benefit from batched generation strategies. Rather than sequentially awaiting each image completion, concurrent request patterns dramatically improve throughput. The following pattern demonstrates parallel generation using Python's asyncio:
pythonimport asyncio import aiohttp async def generate_batch(prompts: list, api_key: str, base_url: str): """Generate multiple images concurrently.""" async with aiohttp.ClientSession() as session: tasks = [ generate_single_async(session, prompt, api_key, base_url) for prompt in prompts ] return await asyncio.gather(*tasks) async def generate_single_async(session, prompt, api_key, base_url): """Async single image generation.""" endpoint = f"{base_url}/models/gemini-3-pro-image-preview:generateContent" headers = {"Authorization": f"Bearer {api_key}"} payload = { "contents": [{"parts": [{"text": prompt}]}], "generationConfig": {"responseModalities": ["IMAGE"]} } async with session.post(endpoint, json=payload, headers=headers) as response: return await response.json() # Generate 10 images concurrently prompts = [f"Product photo variant {i}" for i in range(10)] results = asyncio.run(generate_batch(prompts, api_key, base_url))
This pattern particularly benefits from third-party providers' unlimited concurrency—all requests execute simultaneously without rate limit concerns.
Prompt Engineering for Consistent Results
Achieving consistent, high-quality outputs requires understanding effective prompt construction for Gemini 3 Pro Image. The model responds well to structured prompts that clearly separate subject description, style guidance, and technical requirements.
Effective prompts typically follow this pattern: begin with the primary subject and composition, follow with style and aesthetic guidance, then specify technical parameters. For example: "Professional portrait photograph of a business executive in a modern office setting. Corporate headshot style with soft natural lighting. High resolution, sharp focus on face, blurred background, neutral color palette."
Negative prompting—specifying what to exclude—helps avoid common generation artifacts. Including phrases like "no text," "no watermarks," or "no distortion" in prompts guides the model away from problematic outputs that might require regeneration.
Cost Calculator: Real-World Scenarios
Understanding actual costs requires mapping pricing structures to realistic usage patterns. This section provides concrete calculations for various application scales and use cases.
Monthly Cost Projections by Volume
The following table illustrates monthly costs across different volume tiers, comparing Google's official 4K pricing ($0.24) with third-party access at $0.05:
| Monthly Images | Google Official | Third-Party ($0.05) | Monthly Savings |
|---|---|---|---|
| 100 | $24 | $5 | $19 |
| 500 | $120 | $25 | $95 |
| 1,000 | $240 | $50 | $190 |
| 5,000 | $1,200 | $250 | $950 |
| 10,000 | $2,400 | $500 | $1,900 |
| 50,000 | $12,000 | $2,500 | $9,500 |
At enterprise scale generating 50,000 4K images monthly, the annual cost difference reaches $114,000—substantial enough to fund additional engineering resources or marketing initiatives.
Resolution-Based Cost Optimization
Not every use case requires 4K resolution. Understanding when lower resolutions suffice enables significant cost optimization:
| Use Case | Recommended Resolution | Official Price | Third-Party Price |
|---|---|---|---|
| Social media thumbnails | 1K | $0.039 | ~$0.02 |
| Blog post images | 1K-2K | $0.039-$0.134 | ~$0.02-$0.04 |
| E-commerce products | 2K-4K | $0.134-$0.24 | ~$0.04-$0.05 |
| Print marketing | 4K | $0.24 | ~$0.05 |
| Billboard/large format | 4K | $0.24 | ~$0.05 |
Applications generating mixed-resolution content can implement logic that selects appropriate resolution based on output destination, automatically optimizing costs without compromising quality where it matters.
Hidden Cost Considerations
Beyond per-image pricing, production deployments involve additional cost factors. API request overhead for failed or retried requests adds small increments that accumulate at scale. Storage costs for generated images—whether cloud object storage or CDN delivery—often exceed generation costs for high-volume applications. Processing costs for post-generation operations like resizing, format conversion, or watermarking add operational overhead.
Third-party providers often absorb retry costs within their pricing, as failed requests against their key pool don't typically increment your usage counter. This implicit benefit reduces effective per-image costs compared to direct API access where every request counts against your quota regardless of success.
Break-Even Analysis
For teams considering building their own API aggregation infrastructure versus using third-party providers, the economics rarely favor self-hosting. The engineering investment in building reliable load balancing, key management, and failover systems requires significant upfront development. Ongoing operational costs for monitoring, maintenance, and key procurement typically exceed the margin captured by third-party providers. Only at extreme scale—millions of monthly generations—does self-hosting potentially become economical, and even then the operational complexity often argues against it.
ROI Calculation Framework
Evaluating the return on investment for AI image generation requires considering both cost savings and value generation. The cost side includes not only per-image API costs but also development time, operational overhead, and potential failure costs from generation issues requiring regeneration.
Value generation varies dramatically by application. E-commerce product images directly drive conversion rates—studies consistently show that high-quality product photography increases purchase likelihood by 40-60%. For such applications, the incremental revenue from improved imagery typically dwarfs generation costs, making even official Google pricing attractive.
Marketing content creation represents another high-ROI application. Traditional stock photography licenses cost $50-500 per image for commercial use, with custom photography costing significantly more. AI generation at $0.05-0.24 per image represents 99%+ cost reduction while enabling unlimited customization.
Scaling Considerations
Applications anticipating rapid growth should architect for scale from the outset. Request queuing systems absorb traffic spikes without overwhelming API backends. Caching previously generated images for repeated prompts eliminates redundant API calls—many applications discover significant prompt overlap during analysis.
Consider implementing tiered generation strategies where preview-quality images (1K resolution, rapid turnaround) support user-facing generation previews, while final high-quality images (4K resolution) generate only for confirmed selections. This approach dramatically reduces unnecessary 4K generation costs in applications where users iterate on prompts before finalizing.
Frequently Asked Questions
Is the image quality identical between Google's official API and third-party providers?
Yes, output quality remains identical because third-party providers route requests to the same Google Gemini infrastructure. These services function as API gateways, not alternative image generation systems. Your prompt reaches Google's servers, processes through the identical Gemini 3 Pro Image model, and returns the generated image through the provider's routing layer. The only difference involves the access path—the computational processing producing your image remains unchanged.
How do third-party providers offer 80% discounts while still being profitable?
Third-party API businesses achieve profitability through volume economics. They purchase API access at enterprise rates unavailable to individual developers, spread operational infrastructure costs across thousands of customers, and operate with minimal per-transaction overhead through automation. The 80% discount from retail pricing still leaves margin when base costs sit substantially below retail rates. Additionally, customer acquisition through competitive pricing builds user bases that generate consistent revenue over time.
What happens if a third-party provider experiences downtime?
Service interruption at your chosen provider means your application cannot generate images until service restoration. Mitigation strategies include implementing fallback logic that routes to alternative providers during outages, maintaining direct Google API credentials as emergency backup, or queuing generation requests during brief outages for later processing. Selecting providers with strong uptime records and responsive status communication reduces exposure to extended interruptions.
Are there content policy differences between direct and third-party access?
All requests ultimately reach Google's API endpoints and undergo the same content policy filtering. Gemini image generation includes built-in safety systems that refuse certain request types regardless of access method. Third-party providers cannot bypass these restrictions—they merely provide an alternative access path to the same filtered service. Some providers may implement additional restrictions based on their terms of service, potentially being more conservative than Google's baseline policies.
Should I be concerned about data privacy with third-party providers?
Reputable providers explicitly document pass-through data handling—your prompts and generated images transit their infrastructure without logging or retention. Verification involves reviewing the provider's privacy policy and, for sensitive applications, requesting documentation of their data handling practices. For highly regulated industries, direct Google API access through Vertex AI with enterprise agreements may provide the compliance documentation your legal team requires.
What's the best provider for getting started?
For initial exploration and development, laozhang.ai's combination of competitive pricing, free trial credits, and unified multi-model access provides low-friction entry. The free credits enable experimentation without financial commitment, while the familiar OpenAI-compatible API format reduces learning curve for developers experienced with other AI APIs. As projects mature and specific requirements emerge, evaluating alternatives against your actual usage patterns ensures optimal long-term provider selection.
Can I switch providers later without rewriting my application?
Most third-party providers implement OpenAI-compatible API formats, meaning switching requires only endpoint URL and authentication credential changes. The core request and response structures remain consistent. Designing your application with provider configuration externalized (environment variables or configuration files) rather than hardcoded enables seamless provider transitions when requirements evolve.
Conclusion
Gemini 3 Pro Image represents Google's premium AI image generation capability, offering 4K resolution output with advanced features that justify its positioning above the faster Gemini 2.5 Flash Image model. For developers and businesses requiring professional-quality generated images, understanding the pricing landscape reveals substantial optimization opportunities through third-party API providers.
The $0.05 per 4K image pricing available through providers like laozhang.ai—verified as approximately 21% of Google's official $0.24 rate—enables production applications that would be cost-prohibitive at official pricing. The "unlimited concurrency" these providers offer through API aggregation architecture eliminates rate limit concerns that otherwise constrain high-volume applications.
Selecting the appropriate access method depends on your specific requirements. Cost-sensitive projects benefit from third-party pricing while maintaining identical output quality. Applications requiring enterprise compliance documentation or direct vendor support relationships may prefer direct Google access despite higher costs. Most development scenarios find third-party providers deliver the optimal balance of cost, capability, and convenience.
For projects exploring the broader Gemini ecosystem, combining image generation with text capabilities creates powerful multimodal applications. The unified API access offered by comprehensive providers simplifies integration across model families, accelerating development while maintaining cost efficiency across all AI capabilities your applications require.