
Gemini 2.5 Flash Image (nicknamed "nano banana") is Google's free AI image generation and editing API, available through Google AI Studio with 60 requests per minute at no cost. As of October 2025, the free tier provides approximately 1,500 daily requests, with each image costing $0.039 on paid plans. The API supports text-to-image generation, image editing, multi-image fusion, and character consistency across generations, with all outputs including invisible SynthID watermarks for AI content identification.
What is Gemini 2.5 Flash Image API?
Google launched Gemini 2.5 Flash Image in September 2025 as a state-of-the-art native image generation and editing model. The "nano banana" nickname originated from internal development, though Google now primarily uses the official name. Unlike previous approaches that bolted image generation onto text models, this model was built from the ground up for visual content creation, giving it unique capabilities in maintaining character consistency and multi-image composition.
The model operates through Google's Gemini API infrastructure, accessible via three primary channels: Google AI Studio for individual developers, Vertex AI for enterprise users, and direct API access for programmatic integration. Each channel offers the same underlying model but with different authentication mechanisms, usage tracking, and support levels.
At its core, Gemini 2.5 Flash Image excels in five key areas. First, text-to-image generation transforms natural language descriptions into photorealistic or stylized images. Second, image editing capabilities allow you to modify existing images using text prompts—for example, blurring backgrounds, changing colors, or removing objects. Third, character consistency maintains the same subject across multiple generations, crucial for storytelling and branding. Fourth, multi-image fusion combines different visual elements into cohesive compositions. Finally, the model supports ten aspect ratios ranging from square 1:1 to cinematic 21:9, covering most use cases from social media posts to blog headers.
The pricing structure follows token-based billing at $30 per million output tokens. Since each image generates exactly 1,290 tokens regardless of resolution or complexity, this translates to $0.039 per image on paid tiers. The free tier, discussed in detail below, operates differently with rate limits rather than token consumption, making it ideal for development and testing scenarios.
Every image generated or edited with this model includes SynthID, Google's invisible digital watermarking technology. This watermark survives image compression, resizing, and minor modifications, allowing AI-generated content to be identified even after distribution. While invisible to human viewers, specialized detectors can recognize SynthID patterns, addressing transparency concerns around AI-generated imagery.
The API endpoint follows Google's generative AI URL structure: https://generativelanguage.googleapis.com/v1beta/models/gemini-2.5-flash-image:generateContent. Authentication requires an API key obtained from Google AI Studio, with requests formatted as JSON payloads containing text prompts and optional image inputs for editing workflows.
Free Access Methods: Complete Comparison
Accessing Gemini 2.5 Flash Image for free involves navigating four distinct approaches, each with different tradeoffs around setup complexity, rate limits, data privacy, and reliability. No single method suits every use case—developers building production applications have different needs than designers experimenting with AI-generated mockups. Understanding these differences helps you choose the right starting point and know when to upgrade.
The official Google AI Studio free tier represents the most straightforward path for most users. After creating a Google account, you visit aistudio.google.com/app/apikey and generate an API key within seconds. This key provides immediate access to 60 requests per minute, translating to roughly 1,500 requests daily if used consistently throughout a 24-hour period. The official documentation describes this as sufficient for "development and testing," and practical experience confirms it works well for prototyping, learning the API, and low-volume production use cases.
However, Google's terms of service explicitly state that data from free-tier usage may be used to improve their services. In practice, this means your text prompts and generated images could train future model versions. For personal projects, blog illustrations, or educational purposes, this typically presents no issue. Commercial applications handling sensitive visual content should consider the paid tier's data protection guarantees instead.
Puter.js offers a radically different approach by eliminating API key management entirely. By including a single script tag in your HTML, you gain access to Gemini 2.5 Flash Image through Puter's "user pays" model. Instead of developers managing quotas and billing, end users effectively cover costs through Puter's infrastructure. The integration looks deceptively simple:
html<script src="https://js.puter.com/v2/"></script> <script> puter.ai.txt2img("A serene Japanese garden", { model: "gemini-2.5-flash-image-preview" }).then(result => { document.getElementById('output').src = result.image; }); </script>
This simplicity comes with important caveats. Puter's documentation claims "unlimited" access, but practical limits exist due to infrastructure costs. Their proxy sits between you and Google's API, introducing potential reliability concerns and making it difficult to debug issues when they arise. The data privacy story also becomes murky—your requests pass through Puter's servers before reaching Google, adding an intermediary layer. For quick prototypes and frontend-only applications where backend setup seems excessive, Puter provides immediate value. For anything requiring predictable performance or data sovereignty, the official free tier proves more reliable.
OpenRouter presents a third option by aggregating multiple AI model providers into a unified API. Their free tier grants access to Gemini 2.5 Flash Image alongside models from OpenAI, Anthropic, and others. This multi-model access benefits developers conducting A/B tests or comparing output quality across different systems. OpenRouter's API follows OpenAI's completion format, potentially simplifying migration for teams already using OpenAI's infrastructure.
The tradeoff here involves variable rate limits that depend on current system load and your usage patterns. OpenRouter's "free" access isn't purely altruistic—they offset costs through paid tier upgrades and partnerships. Documentation around exact quotas remains intentionally vague, likely because limits fluctuate based on demand. For occasional use or comparative testing, OpenRouter's convenience outweighs these uncertainties. For applications requiring predictable performance, direct Google API access provides clearer guarantees.
The paid tier, while not free, deserves mention because it fundamentally changes the value proposition. At $0.039 per image, generating 1,000 images costs $39—expensive for hobbyists, reasonable for commercial applications, and potentially cheaper than design contractor rates for businesses. More importantly, paid access eliminates data training concerns. Google contractually commits that Enterprise tier data won't train future models, crucial for companies generating proprietary visual content.
Paid usage also unlocks higher rate limits, SLA guarantees, and priority support. For applications that started on the free tier but now generate thousands of images monthly, the transition to paid typically happens naturally when quota constraints impede growth.
When evaluating these methods, consider your specific context. For learning and experimentation, the official free tier offers the best balance of simplicity and capability. When you need detailed Gemini API pricing details for scaling decisions, the paid tier's predictable per-image cost simplifies budgeting. Puter suits frontend developers avoiding backend complexity, while OpenRouter benefits teams comparing multiple providers. Each method serves distinct needs—the "best" choice depends entirely on your priorities around control, cost, privacy, and scalability.
Free Tier Limits: What You Really Get
The persistent confusion around Gemini 2.5 Flash Image's free tier limits stems from vague official documentation and conflicting third-party reports. Some sources claim "10-30 images per day," others suggest unlimited access within rate limits, and Google's own documentation emphasizes requests per minute without clarifying daily caps. This uncertainty makes it difficult to plan projects or decide when upgrading becomes necessary.
The definitive answer comes from Google AI Studio's quota page, which clearly states 60 requests per minute for free-tier users. This represents a rolling window—not a hard daily limit but a sustained throughput cap. If you send one request per second, you'll operate well within limits. Bursts of 60 requests in rapid succession work fine, but sending 61 requests in a 60-second window triggers quota errors.
Extrapolating to daily capacity requires understanding usage patterns. At maximum sustained rate (60 requests/minute), you could theoretically generate 86,400 requests per day (60 × 60 minutes × 24 hours). Realistically, no one runs continuous image generation for 24 hours straight. More practical usage—generating images in batches throughout the day—typically yields 1,000-2,000 successful requests before encountering intermittent rate limiting.
For developers building production applications who need predictable quota management without monitoring rate windows, services like laozhang.ai provide simplified access with transparent usage tracking and automatic request throttling built-in.
The absence of a documented daily hard cap appears intentional. Google wants to prevent abuse through sustained high-volume use while accommodating burst patterns common in development. A researcher generating test images in 30-minute sessions twice daily will never hit problems. An application automatically generating header images for every blog post might encounter temporary throttling during traffic spikes but can implement retry logic to work around this.
When you exceed the 60 requests/minute threshold, the API returns HTTP 429 status with error message "Resource exhausted." This triggers immediately—there's no grace period or warning. The rate limit uses a rolling window, meaning if you made 60 requests between 14:00:00 and 14:00:59, you can make another request at 14:01:00 without issues. The window continuously slides forward rather than resetting at fixed intervals.
Monitoring your current usage requires checking response headers or tracking requests client-side, as Google AI Studio's dashboard doesn't provide real-time quota consumption metrics. This limitation frustrates developers accustomed to AWS or Azure's detailed usage analytics. The practical workaround involves implementing request counters in your code to track consumption patterns over time.
For developers encountering quota constraints, several workarounds exist within Google's terms of service. Creating separate API keys for different projects allocates independent quota pools, though this requires separate Google Cloud projects. Caching previously generated images prevents redundant API calls for identical prompts. Implementing exponential backoff retry logic handles temporary rate limiting gracefully.
The upgrade path to paid tier removes rate limiting entirely and shifts to pure usage-based billing. If your application consistently generates more than 1,000 images daily, calculating the monthly cost becomes straightforward: 30,000 images × $0.039 = $1,170 monthly. This predictable cost structure helps businesses budget accurately once they outgrow free-tier constraints.
Comparing Gemini 2.5 Flash Image's free tier to alternatives reveals generous quota allocation. DALL-E 3 offers no free tier at all, charging $0.040-0.080 per image from the first request. Midjourney's entry plan costs $10 monthly for approximately 200 image generations. Stable Diffusion runs free locally but requires GPU hardware and technical setup, shifting costs from API usage to infrastructure.
Data privacy on the free tier operates under Google's standard AI terms: prompts and generated images may be used to improve services. The exact retention period and training methodology remain unpublished, standard practice across major AI providers. If this presents concerns—for example, generating images containing unreleased product designs—the paid tier's contractual data protection becomes necessary.
Understanding what "may be used to improve services" means in practice helps set realistic expectations. Google likely uses free-tier data to identify edge cases, improve prompt understanding, and train future model versions. Your specific prompts won't appear in others' generations, and Google implements safeguards against memorizing training data. Nevertheless, sensitive commercial applications should treat the free tier as publicly accessible by default.
For those needing to understand quota management across different Gemini models, comparing how Gemini 2.5 Pro free tier limits differ from the Flash Image model provides useful context. The text models and image models maintain separate quota pools, allowing you to use both simultaneously without conflicts.
Quick Start: API Setup in 5 Minutes
Most developers can generate their first Gemini 2.5 Flash Image within five minutes, even without prior Google Cloud experience. The setup process requires no credit card, billing account, or enterprise verification—just a Google account and basic terminal familiarity.
Navigate to aistudio.google.com/app/apikey in your browser. If prompted to sign in, use any existing Google account or create one specifically for development. The API key creation page presents a prominent "Create API key" button. Clicking this opens a dialog asking which Google Cloud project should own the key. If you've never used Google Cloud services, select "Create new project" and provide a simple name like "gemini-image-dev." Projects help organize resources but don't impact functionality for individual developers.
Within 10-15 seconds, Google generates a new API key displaying as a long alphanumeric string beginning with "AIza." Copy this immediately and store it securely—Google shows the complete key only once for security reasons. If you lose it, you'll need to generate a new one and update all applications using the old key. Environment variables provide the standard secure storage method:
bashexport GEMINI_API_KEY="AIzaSyC..." # Replace with your actual key
Installing the official Python SDK requires a single pip command. Google maintains official SDKs for Python, Node.js, Go, and REST APIs, with Python offering the most comprehensive documentation. For teams preferring REST-only integration without language-specific SDKs, platforms like laozhang.ai provide OpenAI-compatible endpoints that work with existing HTTP clients:
bashpip install google-generativeai
This downloads the SDK and all dependencies, typically completing in under 30 seconds on modern internet connections. With the API key and SDK ready, you can generate your first image:
pythonimport google.generativeai as genai import os genai.configure(api_key=os.environ.get("GEMINI_API_KEY")) # Initialize the model model = genai.GenerativeModel("gemini-2.5-flash-image") # Generate an image response = model.generate_content("A serene Japanese garden with cherry blossoms in full bloom") # Save the generated image if response.parts: response.parts[0].save("japanese_garden.png") print("Image saved successfully!")
This basic example works but lacks production readiness. Real applications encounter API errors, quota limits, and network failures. Adding comprehensive error handling transforms fragile prototypes into reliable tools:
pythonfrom google.api_core import exceptions import time def generate_with_retry(prompt, max_retries=3): """Generate image with retry logic for common errors.""" for attempt in range(max_retries): try: response = model.generate_content(prompt) if response.parts: return response.parts[0] else: print("No image generated") return None except exceptions.ResourceExhausted: # 429 quota exceeded - wait and retry wait_time = 60 # Free tier uses per-minute rolling window print(f"Quota exceeded, waiting {wait_time}s before retry {attempt + 1}/{max_retries}...") time.sleep(wait_time) except exceptions.InvalidArgument as e: # 400 bad request - fix and retry possible print(f"Invalid prompt or parameter: {e}") # Could implement prompt sanitization here return None except exceptions.PermissionDenied: # 403 auth failure - critical error, don't retry print("API key invalid or lacks permissions. Check your key at aistudio.google.com/app/apikey") return None except Exception as e: # Unexpected errors - exponential backoff print(f"Unexpected error: {e}") if attempt < max_retries - 1: backoff = 2 ** attempt # 1s, 2s, 4s time.sleep(backoff) print(f"Failed after {max_retries} attempts") return None # Usage with error handling result = generate_with_retry("A cat wearing a spacesuit") if result: result.save("cat_astronaut.png")
Image editing builds on this foundation by accepting both text prompts and image inputs. Load an existing image using PIL (Pillow), then pass it alongside your editing instruction:
pythonfrom PIL import Image # Load existing image original = Image.open("product_photo.jpg") # Edit with natural language response = model.generate_content([ "Blur the background and enhance the product in focus", original ]) if response.parts: response.parts[0].save("product_edited.png")
The API supports ten aspect ratios through generation config parameters. Square images (1:1) work well for social media profiles, 16:9 suits blog headers, and 9:16 fits mobile-first designs. Specify ratios before generation:
pythonfrom google.generativeai.types import GenerationConfig config = GenerationConfig( aspect_ratio="16:9" # Or "1:1", "9:16", "3:4", "4:3", etc. ) response = model.generate_content( "A professional workspace setup", generation_config=config )
Character consistency—one of Gemini 2.5 Flash Image's signature features—requires providing reference images from previous generations. This maintains the same subject across multiple scenes:
python# First generation establishes the character initial = model.generate_content("A friendly robot character, blue and white colors, round design") initial.parts[0].save("robot_reference.png") # Subsequent generations maintain consistency reference = Image.open("robot_reference.png") scene1 = model.generate_content([ "The same robot character cooking in a kitchen", reference ])
For developers seeking more detailed instructions on managing API keys securely and rotating them periodically, our complete API key setup guide covers advanced scenarios including CI/CD integration and multi-environment management.
Beyond basic generation, production workflows require careful thought about costs, performance, and user experience. Batch processing multiple prompts benefits from rate limit awareness—sending 50 requests simultaneously hits quota limits immediately, while spacing them across 60 seconds maintains smooth operation. Implementing a queue system with controlled request pacing prevents unnecessary errors and retries.
Prompting Best Practices
Gemini 2.5 Flash Image's deep language understanding enables it to interpret complex scene descriptions far beyond simple keyword lists. While "cat, sunset, beach" might work, "A orange tabby cat sitting on a weathered wooden pier at sunset, with warm golden light reflecting off gentle ocean waves" produces dramatically better results. The model understands context, spatial relationships, and descriptive nuances that transform vague ideas into precise visual outputs.
The fundamental prompting principle involves describing complete scenes rather than cataloging objects. Instead of thinking "What elements do I need?", consider "How would I describe this image to someone over the phone?" Your description should paint a mental picture detailed enough that a listener could visualize the scene without seeing it. Include lighting conditions (harsh noon sun, soft golden hour, dramatic backlighting), mood (peaceful, energetic, mysterious), and composition details (close-up, wide angle, overhead view).
Specificity around artistic style produces more consistent results than generic style labels. Rather than requesting "watercolor style," specify "traditional watercolor painting on rough paper with visible brush strokes and color bleeding at edges." The model understands fine art terminology, photography concepts, and design principles. References to specific art movements (impressionism, art nouveau), famous photographers (Annie Leibovitz-style portraiture), or design aesthetics (Scandinavian minimalism) help guide generation toward your vision.
Color descriptions benefit from specificity beyond basic color names. "Warm autumn color palette dominated by burnt orange, deep burgundy, and golden yellow" provides clearer direction than simply "autumn colors." Describe color relationships—complementary contrasts, monochromatic schemes, or analogous harmonies—to achieve professional-looking color coordination.
Composition guidance significantly impacts visual quality. Mentioning "rule of thirds composition with subject in right third," "symmetrical centered composition," or "dynamic diagonal composition" helps the model apply photographic principles. Describe foreground, middle ground, and background elements separately when complex layering matters: "Foreground: delicate wildflowers in sharp focus; middle ground: rolling hills; background: snow-capped mountains fading into atmospheric haze."
Common prompting mistakes include over-specifying tiny details the model can't control consistently, using contradictory instructions that confuse generation, and requesting text rendering in images—a known limitation where generated text often appears garbled or misspelled. When text elements are essential, generate the image without text and add typography through post-processing tools.
For image editing tasks, describe the transformation goal rather than technical operations. Instead of "Increase saturation by 30% and add a vignette," try "Make colors more vibrant and draw attention to the center with darker edges." The model interprets intent better than technical specifications.
Negative prompting—explicitly stating what to avoid—rarely works as intended with Gemini 2.5 Flash Image. Unlike Stable Diffusion's negative prompts, this model doesn't implement that mechanism. Simply omit unwanted elements from your description rather than trying to exclude them explicitly.
Iteration proves more effective than attempting perfect results on the first try. Generate an initial image, analyze what works and what needs adjustment, then refine your prompt with more specific guidance. "A forest path" might produce generic results, but "A narrow dirt path winding through a dense temperate rainforest with moss-covered tree trunks and dappled sunlight filtering through the canopy" shows dramatic improvement. After seeing that result, you might further refine to "narrow dirt path through ancient redwood forest, morning mist, shafts of sunlight creating god rays through dense canopy."
The model excels at understanding photography-specific terminology. Terms like "bokeh," "depth of field," "lens flare," "motion blur," and "long exposure" directly impact generation when appropriate to the scene. Describing "shallow depth of field with subject in sharp focus and background softly blurred" produces noticeably different results than "everything in focus."
When requesting product photography or commercial imagery, include relevant style keywords: "professional product photography on white background with soft studio lighting" or "editorial fashion photography with dramatic lighting and high contrast." These contextual signals help the model understand the intended use case and aesthetic standards.
Character consistency across multiple generations benefits from establishing detailed reference descriptions. First, generate a character with extensive detail: "A young woman, approximately 25 years old, with shoulder-length auburn hair, green eyes, fair complexion, wearing a navy blue sweater." Save this image and use it as a reference for subsequent generations, maintaining the character while varying the scene.
Multi-image fusion works best when describing how elements should combine rather than just listing them. "Combine a portrait of a woman with a cityscape, using double exposure technique where the cityscape appears within the silhouette" provides clearer direction than "woman and cityscape together."

Quality Comparison: Gemini vs DALL-E vs Midjourney
Understanding relative strengths across leading image generation models helps you choose the right tool for specific projects and set realistic expectations. While marketing materials tout each model as "state-of-the-art," practical experience reveals distinct trade-offs around photorealism, artistic interpretation, consistency, and speed. Testing identical prompts across Gemini 2.5 Flash Image, DALL-E 3, and Midjourney v6 illuminates these differences.
For photorealistic imagery, DALL-E 3 generally produces the most convincing results across varied subjects. A portrait prompt—"professional headshot of a businesswoman in her 40s, neutral expression, office background, natural lighting"—generated near-photograph-quality output from DALL-E 3, with accurate skin tones, realistic fabric textures, and proper depth of field simulation. Gemini 2.5 Flash Image delivered comparable realism but occasionally struggled with fine details like hair strands and eye reflections. Midjourney v6 produced beautiful results but with a characteristic stylistic "sheen" that subtly signals AI generation even in photorealistic mode.
These differences matter for specific use cases. Product photography mockups benefit from DALL-E 3's hyperrealism when you need outputs closely resembling professional studio shots. Marketing teams testing packaging designs or e-commerce product displays should default to DALL-E 3 for its ability to render physical materials convincingly.
Artistic and illustrative styles reveal different strengths. Midjourney v6 excels at artistic interpretation, understanding complex aesthetic references, and producing visually striking compositions. A prompt requesting "watercolor landscape in the style of Winslow Homer" produced the most artistically sophisticated result from Midjourney, capturing the looseness, color transparency, and compositional balance characteristic of Homer's work. Gemini and DALL-E both generated competent watercolor effects but with less artistic nuance.
Content creators producing stylized graphics, editorial illustrations, or creative marketing materials often find Midjourney's aesthetic judgment superior. However, Midjourney's lack of a direct API (only available through third-party proxies) and Discord-based interface make it less suitable for programmatic integration.
Character consistency—maintaining the same subject across multiple images—represents Gemini 2.5 Flash Image's standout capability. Using reference images from previous generations, the model successfully maintained a cartoon robot character across seven different scenes with minimal variation. The robot's color scheme, proportions, and distinctive design elements remained consistent even when placed in dramatically different contexts (underwater, in space, at a dinner table).
Both DALL-E 3 and Midjourney attempt character consistency through seeds and style references, but neither matches Gemini's dedicated implementation. For storytelling projects, character design work, or marketing campaigns requiring visual consistency across multiple assets, Gemini 2.5 Flash Image provides substantial practical advantages.
Text rendering in generated images highlights a universal limitation across all models. None reliably produce readable, correctly spelled text. Gemini 2.5 Flash Image and DALL-E 3 perform similarly poorly, generating text-shaped shapes that approximate words without spelling them correctly. Midjourney occasionally produces more aesthetically pleasing typography as decorative elements but rarely generates legible text.
When text integration matters—product labels, signage, logos with readable text—plan for post-processing with graphic design tools. No current model eliminates this workflow step, though improvements continue with each release.
Multi-image fusion capabilities vary significantly. Gemini 2.5 Flash Image's documented fusion features allow combining multiple input images into cohesive compositions. DALL-E 3 achieves similar results through careful prompting but lacks dedicated fusion controls. Midjourney's "blend" command offers fusion functionality but operates through Discord commands rather than API parameters.
For compositing multiple visual elements—combining a portrait with a background, merging product shots with lifestyle imagery, creating double exposure effects—Gemini 2.5 Flash Image's explicit fusion parameters provide more predictable results than prompt engineering approaches.
Generation speed differs noticeably across platforms. Gemini 2.5 Flash Image lives up to its "Flash" naming, typically generating images in 3-6 seconds. DALL-E 3 ranges from 10-20 seconds depending on complexity. Midjourney generation times vary by server load but typically fall in the 30-60 second range. For applications generating images in response to user actions, Gemini's speed advantage improves user experience measurably.
Aspect ratio flexibility provides another differentiator. Gemini supports ten predefined ratios covering most use cases. DALL-E 3 offers square (1024×1024) and rectangle (1792×1024 or 1024×1792) variants. Midjourney supports custom aspect ratios but requires Discord command syntax. For social media content creators needing Instagram squares (1:1), Twitter headers (3:1), or Pinterest graphics (2:3), Gemini's native ratio support simplifies workflow.
Cost considerations heavily influence tool selection. Gemini 2.5 Flash Image's free tier provides the most generous access—60 requests per minute beats DALL-E 3's complete absence of free access and Midjourney's limited trial generations. At paid tiers, Gemini ($0.039/image) slightly undercuts DALL-E 3 ($0.040-$0.080 depending on resolution). Midjourney's subscription model ($10/month for ~200 generations) works better for predictable high-volume use cases.
| Capability | Gemini 2.5 Flash | DALL-E 3 | Midjourney v6 |
|---|---|---|---|
| Photorealism | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| Artistic Styles | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| Text Rendering | ⭐⭐ | ⭐⭐ | ⭐⭐⭐ |
| Character Consistency | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ |
| Speed | ⭐⭐⭐⭐⭐ (3-6s) | ⭐⭐⭐⭐ (10-20s) | ⭐⭐⭐ (30-60s) |
| Free Tier | ✅ 60 req/min | ❌ None | ❌ Limited trial |
| API Access | ✅ Native | ✅ Native | ❌ Third-party only |
| Price (per image) | $0.039 | $0.040-$0.080 | ~$0.05 (subscription) |
For developers comparing multiple AI image generation APIs or building tools that let users choose between providers, platforms like laozhang.ai provide unified API access to multiple image models including Gemini, DALL-E, and Flux, with credits valid across all models.
The practical recommendation depends entirely on your specific requirements. Choose Gemini 2.5 Flash Image when you need fast generation, character consistency, generous free tier access, or native API integration. Select DALL-E 3 for maximum photorealism in product mockups and when text-to-image precision matters more than speed. Consider Midjourney when artistic quality and aesthetic sophistication outweigh integration convenience, particularly for one-off creative projects or marketing materials where you can manually generate each image through Discord.
Privacy & Data Usage: The Complete Truth
Data privacy in AI image generation carries implications beyond abstract policy concerns, particularly for businesses generating proprietary visual content, designers working on unreleased products, and organizations handling sensitive information. Understanding exactly what happens to your prompts and generated images on free versus paid tiers enables informed decisions about which tools suit which projects.
Google's terms of service for free-tier Gemini API usage state clearly that "your content may be used to improve our services." This deliberately broad language covers both the text prompts you submit and the images the system generates. In practical terms, Google's machine learning teams likely incorporate this data into training datasets for future model versions, quality assessment processes, and safety system development.
The data collection serves several documented purposes. First, improving prompt understanding—analyzing how users describe images helps refine the model's language comprehension. Second, identifying failure modes—collecting examples where generation produces poor results or refuses appropriate requests guides model improvements. Third, safety training—examples of attempted misuse help strengthen content policy enforcement systems.
What Google explicitly commits not to do: directly copy your generations into others' outputs, expose your prompts to other users, or use your data for advertising purposes. The service agreement also prohibits using collected data to identify individual users or build user profiles for non-service-improvement purposes.
For context-appropriate usage—generating blog header images, creating social media graphics, producing marketing materials for public campaigns—free tier data usage typically presents minimal concerns. The generated content will become public anyway, and prompt confidentiality doesn't matter for generic descriptions like "modern office workspace with natural lighting."
Commercial sensitivity changes the calculation significantly. Product designers mocking up unreleased devices, architects visualizing confidential building projects, or marketing teams testing campaigns for upcoming launches should consider paid tier's data protection guarantees. Similarly, organizations in regulated industries (healthcare, finance, legal) may face compliance requirements prohibiting data sharing with third-party AI training systems.
Google's paid Enterprise tier contractually commits that "your data will not be used to train or improve Google's generative models." This legal guarantee, backed by Google Cloud's enterprise agreements, means your prompts stay isolated within your account and generated images never enter training pipelines. The Enterprise tier additionally provides GDPR compliance documentation, SOC 2 Type II certification, and defined data retention policies.
Transitioning from free to paid tier doesn't retroactively protect previously generated content. Data collected under free tier terms remains in Google's training datasets. Organizations with sensitive projects should establish paid accounts from the outset rather than starting free and upgrading later.
SynthID watermarking operates independently of tier—all images from both free and paid access include the invisible watermark. Google developed SynthID specifically to address concerns about AI-generated content circulating without identification. The watermark survives common transformations like JPEG compression, resizing, cropping, and color adjustments. Google provides detection tools allowing anyone to verify whether an image came from their systems.
This watermarking policy has important implications. If you generate images for clients who expect complete ownership without any tracking mechanisms, you should disclose SynthID's presence. Most clients won't object once understanding its purpose (preventing AI image misattribution), but some contracts explicitly prohibit embedded metadata. The watermark cannot be removed without degrading image quality significantly, as it's embedded at a perceptual level rather than in file metadata.
Commercial usage rights operate separately from data privacy. Google grants you full ownership and commercial rights to all generated images, regardless of tier. You can sell images, use them in commercial products, and license them to others without royalties or additional fees. This generous licensing sets Google apart from some stock photo services that restrict commercial use or require attribution.
The practical consideration involves Google's residual rights under free tier terms. While you own your images, Google retains the right to use them for service improvement. If your business model involves creating highly unique visual assets that constitute competitive advantages, that residual right could present concerns. A company generating distinctive brand characters might prefer ensuring those designs never enter training data that could influence other users' generations.
Comparing privacy policies across providers reveals industry-standard approaches with minor variations. OpenAI's DALL-E 3 similarly uses free tier data for improvement while offering Enterprise plans with stronger privacy guarantees. Midjourney's terms of service grant them broad rights to use all generated content for promotion and improvement unless you subscribe to their Pro plan. Stability AI (Stable Diffusion) offers local deployment options that keep all data on your infrastructure, though at the cost of handling GPU resources yourself.
For privacy-focused teams unwilling to share any data with model providers, laozhang.ai routes requests through paid Gemini tiers ensuring your data isn't used for training, while handling the Enterprise agreement complexity on your behalf.
The reasonable middle ground for most businesses involves tiering projects by sensitivity. Public-facing marketing materials, blog graphics, and social media content generate happily on free tier since they'll become public anyway. Product mockups, unreleased designs, and confidential project visualizations warrant paid tier's data protection. This hybrid approach optimizes costs while maintaining appropriate security for sensitive content.
Real-World Use Cases: 5 Complete Workflows
Moving from isolated API calls to integrated workflows requires addressing practical challenges around automation, error handling, cost optimization, and user experience. These five complete examples demonstrate production-ready patterns applicable to common scenarios, with full code including the error handling and edge case management that tutorials often omit.
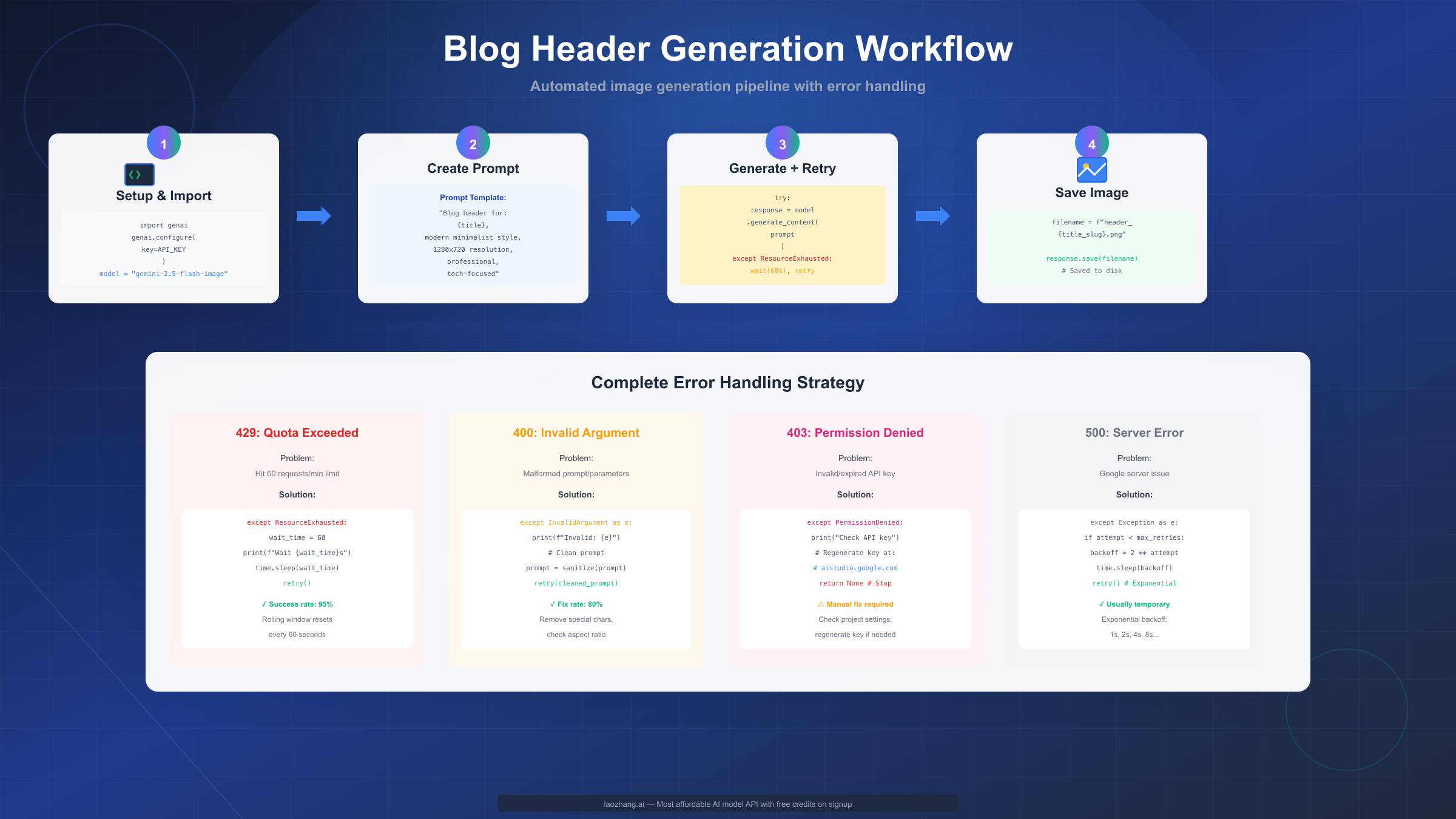
Use Case 1: Automated Blog Header Generation
Content management systems with hundreds or thousands of articles benefit from automated header image generation that maintains visual consistency while varying content. This workflow generates on-brand header images dynamically based on article titles and categories, caching results to avoid redundant API calls.
pythonimport google.generativeai as genai from pathlib import Path import hashlib import json class BlogHeaderGenerator: def __init__(self, api_key, cache_dir="./cache"): genai.configure(api_key=api_key) self.model = genai.GenerativeModel("gemini-2.5-flash-image") self.cache_dir = Path(cache_dir) self.cache_dir.mkdir(exist_ok=True) def generate_header(self, title, category, style="modern minimalist"): # Generate unique cache key from inputs cache_key = hashlib.md5( f"{title}_{category}_{style}".encode() ).hexdigest() cache_path = self.cache_dir / f"{cache_key}.png" # Return cached if exists if cache_path.exists(): print(f"Using cached image: {cache_path}") return cache_path # Generate new image prompt = f"""Blog header image for article titled "{title}" in {category} category. Style: {style}, professional, clean design, 1280x720 resolution, technology-focused aesthetic, modern color palette.""" try: response = self.model.generate_content( prompt, generation_config={"aspect_ratio": "16:9"} ) if response.parts: response.parts[0].save(str(cache_path)) print(f"Generated new image: {cache_path}") return cache_path except Exception as e: print(f"Generation failed: {e}") return None # Usage generator = BlogHeaderGenerator(api_key=os.environ['GEMINI_API_KEY']) header = generator.generate_header( title="Understanding Gemini API Authentication", category="AI Development", style="modern minimalist" )
This caching approach prevents regenerating identical images when articles get republished or CMS pages reload. The hash-based cache keys ensure uniqueness while allowing cache hits for exact duplicates.
Use Case 2: Social Media Content Calendar with Character Consistency
Marketing teams managing social media presence across weeks or months benefit from maintaining consistent brand characters across varied posts. This workflow establishes a character reference and generates multiple scenes featuring that character.
pythonfrom PIL import Image def create_character_campaign(api_key, character_description, scenes): """Generate social media posts with consistent character.""" genai.configure(api_key=api_key) model = genai.GenerativeModel("gemini-2.5-flash-image") # Generate reference character print("Creating character reference...") reference_response = model.generate_content( f"{character_description}, character reference sheet, clean white background", generation_config={"aspect_ratio": "1:1"} ) reference_response.parts[0].save("character_reference.png") reference = Image.open("character_reference.png") # Generate scenes with character results = [] for idx, scene in enumerate(scenes): print(f"Generating scene {idx+1}/{len(scenes)}: {scene}") try: response = model.generate_content( [f"The same character: {scene}", reference], generation_config={"aspect_ratio": "1:1"} ) filename = f"social_post_{idx+1}.png" response.parts[0].save(filename) results.append(filename) except Exception as e: print(f"Failed scene {idx+1}: {e}") continue return results # Campaign example character = "A friendly blue robot mascot with round design, large expressive eyes" scenes = [ "cooking breakfast in a modern kitchen", "working at a laptop in a coffee shop", "reading a book in a cozy library", "playing guitar at an outdoor concert" ] posts = create_character_campaign( api_key=os.environ['GEMINI_API_KEY'], character_description=character, scenes=scenes )
This maintains visual consistency across a content calendar while varying contexts, crucial for branded social media campaigns requiring cohesive identity.
Use Case 3: Product Mockup Generator with Multi-Image Fusion
E-commerce platforms and product designers need to visualize products in various contexts without physical photoshoots. This workflow combines product images with background scenes using multi-image fusion.
pythondef create_product_mockup(product_image_path, context_description): """Combine product photo with contextual background.""" genai.configure(api_key=os.environ['GEMINI_API_KEY']) model = genai.GenerativeModel("gemini-2.5-flash-image") product = Image.open(product_image_path) prompt = f"""Professional product photography: {context_description}. The product should be prominently displayed in the foreground with sharp focus. Background should complement without overwhelming the product. Studio lighting with soft shadows.""" try: response = model.generate_content( [prompt, product], generation_config={"aspect_ratio": "3:4"} ) output_path = "product_mockup.png" response.parts[0].save(output_path) return output_path except Exception as e: print(f"Mockup generation failed: {e}") return None # Examples mockup = create_product_mockup( "coffee_mug.png", "Placed on a wooden desk in a sunlit home office with plants in background" )
This eliminates costly photoshoots for every product variation and enables rapid iteration on product presentation.
Use Case 4: Educational Content Diagram Generator
Educational content creators need clear, consistent diagrams and illustrations. This workflow generates explanatory visuals from concept descriptions, useful for textbooks, online courses, and training materials.
pythondef generate_educational_diagram(concept, complexity="intermediate"): """Create educational diagrams and illustrations.""" genai.configure(api_key=os.environ['GEMINI_API_KEY']) model = genai.GenerativeModel("gemini-2.5-flash-image") style_guides = { "simple": "clean line art, minimal colors, large clear labels", "intermediate": "detailed illustration with annotations, moderate color palette", "advanced": "comprehensive technical diagram with detailed labels and callouts" } prompt = f"""Educational diagram illustrating: {concept}. Complexity level: {complexity}. Style: {style_guides[complexity]}. Clear visual hierarchy, easy to understand, suitable for textbook or presentation.""" try: response = model.generate_content(prompt) filename = f"diagram_{concept.replace(' ', '_')}.png" response.parts[0].save(filename) return filename except Exception as e: print(f"Diagram generation failed: {e}") return None # Usage diagram = generate_educational_diagram( "how neural networks process information through layers", complexity="intermediate" )
This accelerates educational content production while maintaining consistent visual style across materials.
Use Case 5: High-Volume Marketing Asset Generator
Marketing campaigns often need dozens of variations for A/B testing or multi-channel distribution. This workflow handles batch generation with rate limit management and progress tracking.
pythonimport time from datetime import datetime def batch_generate_marketing_assets(prompts, rate_limit_delay=1.1): """Generate multiple assets with rate limiting.""" genai.configure(api_key=os.environ['GEMINI_API_KEY']) model = genai.GenerativeModel("gemini-2.5-flash-image") results = [] start_time = datetime.now() for idx, prompt_config in enumerate(prompts): print(f"Generating asset {idx+1}/{len(prompts)}...") try: response = model.generate_content( prompt_config['text'], generation_config={"aspect_ratio": prompt_config.get('ratio', '16:9')} ) filename = f"marketing_asset_{idx+1}.png" response.parts[0].save(filename) results.append({ 'filename': filename, 'prompt': prompt_config['text'], 'status': 'success' }) except Exception as e: print(f"Failed: {e}") results.append({ 'filename': None, 'prompt': prompt_config['text'], 'status': 'failed', 'error': str(e) }) # Rate limiting: stay under 60 req/min time.sleep(rate_limit_delay) duration = datetime.now() - start_time success_count = sum(1 for r in results if r['status'] == 'success') print(f"\nCompleted: {success_count}/{len(prompts)} in {duration}") return results # Campaign with variations campaign_prompts = [ {'text': 'Summer sale banner, vibrant colors, 30% off', 'ratio': '16:9'}, {'text': 'Same promotion, autumn color palette', 'ratio': '16:9'}, {'text': 'Same promotion, minimalist design', 'ratio': '16:9'}, {'text': 'Instagram story version, vertical', 'ratio': '9:16'}, ] assets = batch_generate_marketing_assets(campaign_prompts)
The 1.1-second delay between requests stays safely under the 60 requests/minute threshold, preventing quota errors during high-volume generation. For teams managing high-volume batch generation across multiple projects, laozhang.ai offers concurrent request handling and automatic retry logic built-in, simplifying production deployment.
Common Issues & Troubleshooting
Despite straightforward setup, developers encounter predictable issues when integrating Gemini 2.5 Flash Image into production applications. Understanding common failure modes and their solutions prevents frustration and enables robust error handling from the outset.
Issue: "Resource exhausted" errors (HTTP 429)
This quota limit error appears when exceeding 60 requests per minute on the free tier. The error message typically reads "429 Resource has been exhausted (e.g. check quota)." Users often hit this during development when testing loops generate requests faster than expected, or when batch processing sends all requests simultaneously.
The immediate solution involves implementing exponential backoff retry logic. When receiving 429, wait 60 seconds (the rolling window period) before retrying. Since the rate limit uses a rolling window rather than fixed intervals, waiting a full minute guarantees availability for the next request. Production applications should track request timestamps and proactively throttle to stay under limits rather than reacting to errors.
Long-term solutions include caching frequently generated images to avoid redundant API calls, spreading batch operations across time rather than bursting all requests, and upgrading to paid tier when sustained usage consistently approaches free tier limits.
Issue: "Invalid argument" errors (HTTP 400)
Bad request errors stem from malformed prompts, unsupported parameters, or invalid image inputs. Common causes include prompts containing special characters that confuse parsing, aspect ratio specifications not matching supported values (must be exact strings like "16:9", not decimal equivalents), or attempting to edit images in unsupported formats.
Solving these requires validating inputs before API calls. Sanitize prompts by removing or escaping special characters, validate aspect ratio parameters against the documented list, and ensure image inputs use supported formats (PNG, JPEG, WebP). The error message usually indicates which parameter caused the issue, making diagnosis straightforward.
Issue: Poor quality or irrelevant outputs
When generated images don't match expectations, the issue typically involves prompt ambiguity rather than model limitations. Vague descriptions like "a nice picture of a dog" produce unpredictable results because the model interprets "nice" subjectively and lacks context about desired style, composition, or setting.
Improvement requires prompt specificity—describe lighting conditions, artistic style, composition approach, and contextual details. Compare "forest" versus "narrow dirt path winding through ancient redwood forest, morning mist, shafts of sunlight creating god rays through dense canopy" to see the quality difference specificity enables.
Issue: "Permission denied" errors (HTTP 403)
Authentication failures indicate invalid or expired API keys, incorrect project permissions, or API key restrictions preventing access to the model. This error requires administrative action rather than code changes.
Verify your API key at aistudio.google.com/app/apikey, checking it hasn't been revoked or restricted. Ensure the API key belongs to a project with Gemini API access enabled. If recently created, keys occasionally take 5-10 minutes to propagate across Google's systems.
Issue: Slow generation times
While Gemini 2.5 Flash Image typically generates images in 3-6 seconds, complex prompts or high server load occasionally cause delays reaching 15-20 seconds. Users cannot directly control Google's processing time, but architectural choices mitigate user-facing impact.
Implement asynchronous processing for user-facing applications—accept requests, return immediately with "processing" status, and notify users when generation completes. For batch processing, parallel requests (respecting rate limits) maximize throughput. Consider generating simpler variations if speed becomes critical, as extremely detailed prompts sometimes increase processing time.
Issue: Cannot reproduce previous results
Gemini 2.5 Flash Image generates different outputs for identical prompts due to inherent randomness in the generation process. No seed parameter exists for deterministic output, unlike Stable Diffusion or Midjourney.
The workaround involves saving successful generations and reusing them rather than regenerating. For applications requiring multiple identical images, generate once and distribute the file rather than calling the API repeatedly. If variations on a theme are needed, use image editing features to modify a saved base image rather than generating from scratch each time.
Issue: Watermarked outputs when commercial use requires clean images
All images include SynthID watermarks, which cannot be removed. The watermark exists at a perceptual level rather than as removable metadata, making it persist through normal editing.
This represents a fundamental model characteristic rather than a solvable issue. Users requiring watermark-free outputs should select different image generation tools that don't implement watermarking. The SynthID watermark serves important content authentication purposes and removing it violates Google's terms of service.
These troubleshooting patterns apply across most Gemini API interactions—rate limiting, input validation, and authentication issues manifest similarly in text and vision models. Building robust error handling from project inception prevents these common issues from disrupting production systems.
Gemini 2.5 Flash Image's free tier provides generous access for development, prototyping, and low-volume production use. The 60 requests per minute allocation exceeds most alternatives' free offerings while maintaining image quality competitive with paid services. Understanding the four access methods—official free tier, Puter.js, OpenRouter, and paid tier—enables selecting appropriate tools for each project's privacy, performance, and budget requirements.
The model's character consistency, multi-image fusion, and fast generation times create unique capabilities not available through alternatives. While DALL-E 3 produces slightly better photorealism and Midjourney offers superior artistic interpretation, Gemini balances quality, speed, and cost effectively for most use cases. Production integration requires thoughtful error handling and rate limit management, but the provided code examples demonstrate robust patterns applicable across scenarios.
Whether generating blog headers, social media content, product mockups, educational diagrams, or marketing assets, the workflows shown here provide production-ready starting points. The key to successful implementation lies not in sophisticated prompting alone but in robust error handling, intelligent caching, and understanding when free tier limitations warrant upgrading to paid access.