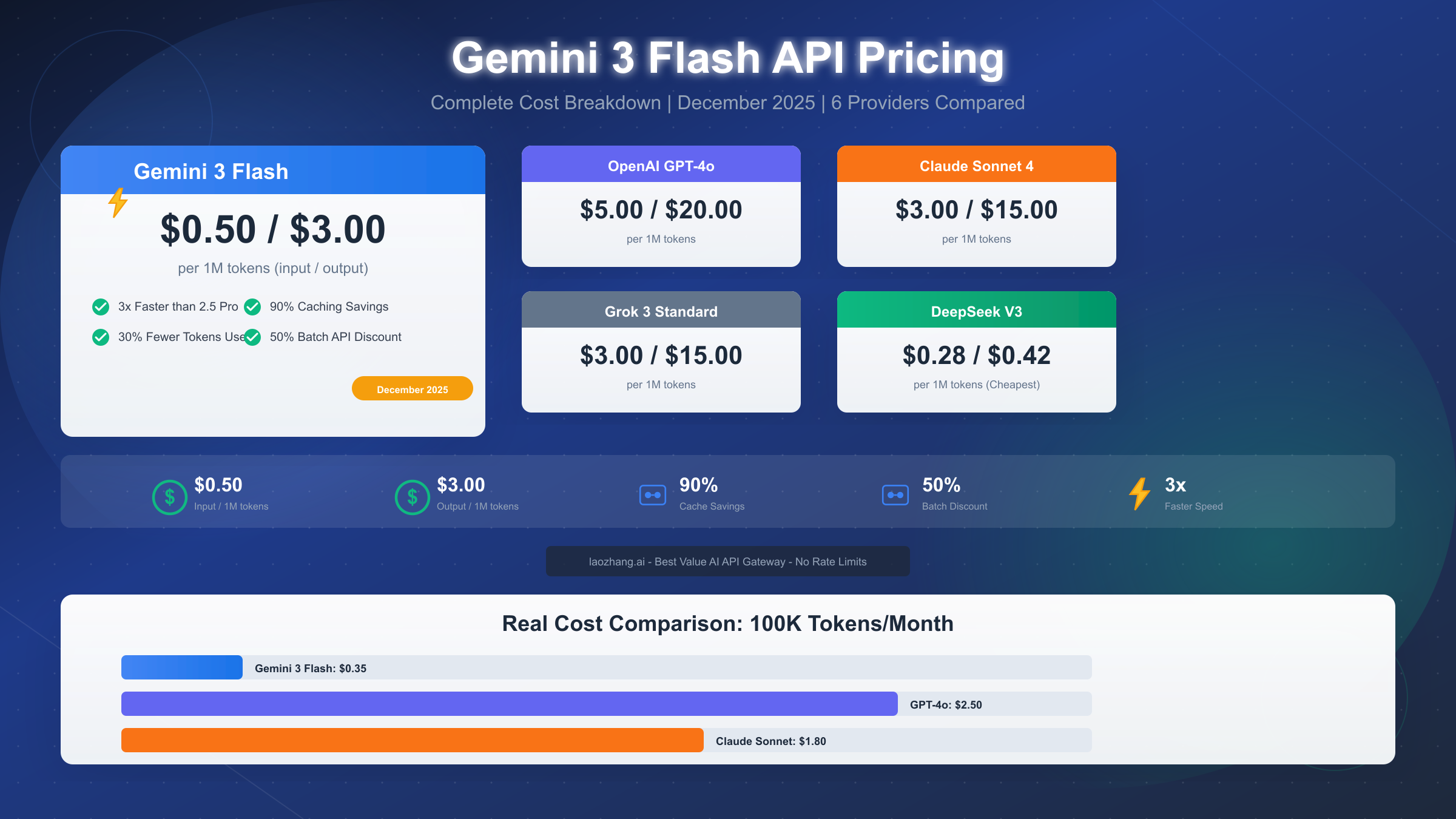
Google released Gemini 3 Flash on December 17, 2025, and it immediately became one of the most compelling options in the AI API market. At $0.50 per million input tokens and $3.00 per million output tokens, this model delivers frontier-level performance at Flash-tier pricing. For developers seeking the optimal balance of capability and cost, understanding the complete pricing structure—including context caching that saves 90% and batch API discounts of 50%—is essential for making informed decisions.
What is Gemini 3 Flash?
Gemini 3 Flash represents Google's latest advancement in the Flash model line, designed to provide frontier-level intelligence at significantly lower costs than Pro-tier models. Released on December 17, 2025, this model has quickly become the default option in the consumer Gemini app while offering powerful API access for developers building production applications.
The core value proposition is remarkable. According to Google's official benchmarks, Gemini 3 Flash outperforms Gemini 2.5 Pro across 18 of 20 major evaluation categories while being 3x faster and costing 60-70% less. The model achieves 78% on SWE-bench Verified (surpassing even Gemini 3 Pro's 76%), 90.4% on GPQA Diamond, and 81.2% on MMMU Pro. These aren't incremental improvements—they represent a fundamental shift in what's possible at the Flash pricing tier.
Token efficiency adds another layer of value. Google reports that Gemini 3 Flash uses 30% fewer tokens on average compared to Gemini 2.5 Pro for typical tasks. When you combine lower per-token pricing with reduced token consumption, the effective cost advantage reaches approximately 75% compared to the previous Pro model. This means projects that previously required Pro-level investment can now achieve similar or better results at a fraction of the cost.
The model excels in multimodal capabilities. Beyond text processing, Gemini 3 Flash handles audio input at $1.00 per million tokens, supports image understanding, and can process video content. The 1 million token context window—8x larger than GPT-4o's 128K limit—enables handling of extensive documents, lengthy conversations, and complex multi-turn interactions without the context truncation that plagues other models.
Access is straightforward for developers. You can start using Gemini 3 Flash through Google AI Studio immediately, with production deployment available via the Gemini API or Vertex AI. The model is also accessible through the Gemini CLI, making it easy to integrate into development workflows. Consumer users get free access through the Gemini app, while API usage follows the paid pricing structure we'll detail in the next section.
Complete Pricing Breakdown (December 2025)
Understanding Gemini 3 Flash pricing requires looking at multiple dimensions: base token costs, context-length tiers, batch processing discounts, and context caching options. Here's the complete picture based on official Google documentation as of December 2025.
Standard API Pricing
The base pricing for Gemini 3 Flash Preview in the Gemini API and Vertex AI is as follows:
| Token Type | Standard Price (per 1M tokens) |
|---|---|
| Text Input | $0.50 |
| Image Input | $0.50 |
| Video Input | $0.50 |
| Audio Input | $1.00 |
| Text Output | $3.00 |
This represents a 67% increase from Gemini 2.5 Flash ($0.30 input, $2.50 output), but the performance gains more than justify the price difference. For context, this pricing remains dramatically cheaper than Gemini 3 Pro at $2.00-$4.00 input and $12.00-$18.00 output.
Batch API Pricing (50% Discount)
For workloads that don't require real-time responses, the Batch API offers substantial savings:
| Token Type | Batch Price (per 1M tokens) | Savings |
|---|---|---|
| Text/Image/Video Input | $0.25 | 50% |
| Audio Input | $0.50 | 50% |
| Text Output | $1.50 | 50% |
Batch processing is ideal for content generation, data processing, document analysis, and any use case where you can tolerate asynchronous processing. The 50% discount makes this the most cost-effective way to use Gemini 3 Flash for high-volume operations.
Context Caching Pricing
Context caching dramatically reduces costs when you repeatedly use the same context across multiple requests. This is particularly valuable for applications like customer support bots, document analysis systems, or any scenario with consistent system prompts.
| Caching Component | Price |
|---|---|
| Text/Image/Video Cache Read | $0.05 per 1M tokens |
| Audio Cache Read | $0.10 per 1M tokens |
| Cache Storage | $1.00 per 1M tokens per hour |
The cache read cost of $0.05 per million tokens represents a 90% reduction from the standard $0.50 input price. For applications with heavy prompt reuse, this translates to massive savings. If you're building a customer service bot with a 10,000-token system prompt that handles 1,000 requests per day, caching saves approximately $4.50 daily compared to sending the full context each time.
Comparing with previous Gemini models helps contextualize these prices. For detailed pricing across all Gemini models and historical context, see our comprehensive Gemini API pricing guide.
Provider Comparison: All Your Options
Choosing an AI API isn't just about Gemini—you need to understand how it stacks up against competitors. Here's a comprehensive comparison of the major providers available in December 2025.
| Provider | Model | Input (per 1M) | Output (per 1M) | Context | Rate Limit | Caching | Best For |
|---|---|---|---|---|---|---|---|
| Gemini 3 Flash | $0.50 | $3.00 | 1M tokens | 2000 RPM | Yes | Speed + Value | |
| Gemini 2.5 Flash | $0.30 | $2.50 | 1M tokens | 2000 RPM | Yes | Budget Option | |
| OpenAI | GPT-4o | $5.00 | $20.00 | 128K | 500 RPM | Yes | Ecosystem |
| Anthropic | Claude Sonnet 4 | $3.00 | $15.00 | 200K | 1000 RPM | Yes | Coding Tasks |
| xAI | Grok 3 Standard | $3.00 | $15.00 | 131K | 600 RPM | No | Real-time Data |
| DeepSeek | V3.2 | $0.28 | $0.42 | 128K | 60 RPM | No | Lowest Cost |
The cost differential is substantial. Gemini 3 Flash is 10x cheaper than GPT-4o for input tokens and nearly 7x cheaper for output. Even compared to Claude Sonnet 4, Gemini 3 Flash offers 6x lower input costs and 5x lower output costs. Only DeepSeek undercuts Gemini on raw pricing, but with significantly lower rate limits that restrict production viability.
Context window advantages matter for many applications. Gemini's 1M token context window is 8x larger than GPT-4o's 128K limit and 5x larger than Claude's 200K. For applications processing long documents, extensive codebases, or maintaining lengthy conversation history, this difference eliminates the need for complex chunking and summarization strategies that add latency and degrade quality.
Rate limits affect real-world usability. Gemini's 2000 RPM limit is 4x higher than GPT-4o's 500 RPM and double Claude's 1000 RPM. For high-traffic applications, this means fewer 429 errors and better user experience. DeepSeek's 60 RPM limit, while offering the lowest prices, makes it impractical for most production use cases.
For a deeper dive into Gemini 3's capabilities and features beyond pricing, check out our Gemini 3.0 API complete guide.

Free Tier vs Paid: December 2025 Reality
Google's approach to free tier access changed significantly in December 2025, and understanding these changes is crucial for budgeting and planning your API usage.
The free tier reduction caught many developers by surprise. Between December 6-7, 2025, Google reduced free tier rate limits by 50-80% without prominent announcement. Gemini 2.5 Pro was removed from the free tier entirely, and Gemini 2.5 Flash's daily free requests dropped dramatically—from approximately 250 to around 20 requests per day according to developer reports. This change affects anyone relying on free tier access for development or low-volume production.
Current free tier limits for Gemini 3 Flash Preview are more restrictive than previous models:
| Metric | Free Tier Limit |
|---|---|
| Requests per Minute (RPM) | 5-15 (varies) |
| Tokens per Minute (TPM) | 250,000 |
| Requests per Day (RPD) | 1,000 |
| Context Window | 1M tokens |
The 5 RPM limit means you can only make one API request every 12 seconds on average. This is explicitly designed for testing and prototyping rather than production use.
Paid tier benefits extend beyond rate limits. When you upgrade to paid access, you gain higher rate limits (2000+ RPM), access to context caching, Batch API availability, and crucially—your content is not used to improve Google's products. The free tier explicitly notes that "content used to improve our products," while paid tier content remains private.
The decision framework is straightforward. Use free tier for initial exploration and development. Move to paid tier when you need more than 20 reliable requests per day, require consistent availability, need context caching for cost optimization, or are building anything user-facing. For detailed strategies on maximizing free tier access and handling 429 errors, see our free tier rate limit solutions guide.
When upgrading makes financial sense: If your application makes more than 50 API calls per day with consistent availability requirements, the paid tier's reliability and features justify the cost. A typical startup spending $10-50/month on API calls gains far more value from reliable paid access than the frustration of hitting free tier limits during critical operations.
Cost Calculator: Real Project Scenarios
Abstract pricing per million tokens doesn't answer the real question: what will this cost for my specific project? Let's walk through three realistic scenarios to illustrate actual monthly costs.
Scenario 1: Hobby Project (100K tokens/month)
A personal AI assistant, simple chatbot, or experimental project typically falls into this category.
| Component | Tokens | Rate | Cost |
|---|---|---|---|
| Input tokens | 70,000 | $0.50/1M | $0.035 |
| Output tokens | 30,000 | $3.00/1M | $0.090 |
| Total | 100,000 | $0.125 |
At just 12.5 cents per month, hobby projects are essentially free to run on Gemini 3 Flash. Even without optimization, you'd need to scale to 800K+ tokens monthly before hitting the $1 mark.
Comparison with alternatives: The same usage on GPT-4o would cost $0.95 (7.6x more), and Claude Sonnet 4 would cost $0.66 (5.3x more).
Scenario 2: Startup Application (1M tokens/month)
A customer-facing chatbot, content generation tool, or business automation handling moderate traffic.
| Component | Tokens | Standard | With Caching | With Batch |
|---|---|---|---|---|
| Input tokens | 700,000 | $0.35 | $0.035 (90% cached) | $0.175 |
| Output tokens | 300,000 | $0.90 | $0.90 | $0.45 |
| Total | 1,000,000 | $1.25 | $0.935 | $0.625 |
Standard pricing runs $1.25/month—remarkably affordable for a production application. With context caching (assuming 90% of input is cached system prompts), costs drop to under $1. Batch processing for non-urgent tasks cuts the bill in half.
Comparison with alternatives: GPT-4o at $9.50/month (7.6x), Claude Sonnet 4 at $6.60/month (5.3x), DeepSeek at $0.32/month (cheapest but rate-limited).
Scenario 3: Enterprise Application (10M tokens/month)
A high-traffic SaaS application, enterprise automation system, or data processing pipeline.
| Component | Tokens | Standard | Optimized (Mixed) |
|---|---|---|---|
| Input tokens | 7,000,000 | $3.50 | $0.70 (80% cached, 20% batch) |
| Output tokens | 3,000,000 | $9.00 | $5.40 (60% batch) |
| Total | 10,000,000 | $12.50 | $6.10 |
Even at enterprise scale, Gemini 3 Flash costs only $12.50/month at standard rates. With aggressive optimization—caching for repeated contexts and batch processing for non-urgent work—costs drop to $6.10, a 51% reduction.
The optimization payoff scales with volume. At 10M tokens, combining caching and batch processing saves $6.40/month. At 100M tokens, the same optimization saves $64/month. Enterprise applications should prioritize implementing both strategies from day one.
Cost Optimization Strategies
Beyond understanding pricing, implementing optimization strategies can dramatically reduce your actual costs. Here are the key techniques with practical implementation guidance.
Context caching is the biggest single optimization. For applications with consistent system prompts, few-shot examples, or recurring context, caching reduces input token costs by 90%. Implementation requires thinking about your prompt architecture:
pythonimport google.generativeai as genai cached_content = genai.caching.CachedContent.create( model="gemini-3-flash-preview", system_instruction="You are a helpful customer service agent...", contents=[ # Your few-shot examples {"role": "user", "parts": ["How do I reset my password?"]}, {"role": "model", "parts": ["To reset your password..."]}, # More examples... ], ttl=datetime.timedelta(hours=1), # Cache duration display_name="customer_service_context" ) # Use the cached context for requests model = genai.GenerativeModel.from_cached_content(cached_content) response = model.generate_content("User's actual question here")
The cache storage fee of $1.00 per million tokens per hour only makes sense for high-volume applications. Calculate your break-even: if cached context is 10,000 tokens and you make more than 10 requests per hour, caching saves money.
Batch API suits asynchronous workloads. Content generation, document processing, data analysis—anything that doesn't require real-time response benefits from 50% batch discounts:
pythonimport google.generativeai as genai from google.generativeai import types # Create a batch request batch_request = types.CreateBatchJobRequest( display_name="content_generation_batch", source_config=types.GcsSource( input_uri="gs://your-bucket/input.jsonl" ), dest_config=types.GcsDestination( output_uri_prefix="gs://your-bucket/output/" ), model="gemini-3-flash-preview" ) # Submit and monitor job = genai.batches.create(batch_request) print(f"Batch job created: {job.name}")
Token efficiency techniques reduce consumption. Gemini 3 Flash already uses 30% fewer tokens than 2.5 Pro, but you can optimize further. Use concise system prompts without redundancy. Structure output requests to minimize unnecessary verbosity. For classification tasks, request single-word or short-phrase responses rather than explanations.
Model selection based on task complexity matters. Not every request needs Gemini 3 Flash. Gemini 2.5 Flash-Lite at $0.10 input / $0.40 output handles simple tasks like classification, extraction, and formatting at 5x lower cost. Route complex reasoning and creative tasks to 3 Flash while delegating simpler operations to cheaper models.
Budget Alternative: laozhang.ai
For developers seeking even lower costs or needing to bypass rate limits, third-party API aggregators offer compelling alternatives. laozhang.ai provides access to Gemini models and other major AI APIs through a unified gateway with several distinct advantages.
The pricing model is straightforward. Text model pricing matches or undercuts official rates, while image models are priced per-request at roughly 50% of official costs. A $100 top-up (approximately 700 RMB) includes a $10 bonus, effectively giving you access at about 84% of official pricing—roughly a 16% discount before considering any volume benefits.
Rate limits are the primary differentiator. While official Gemini API limits you to 2000 RPM (already generous), laozhang.ai removes these restrictions entirely. For applications with burst traffic, concurrent user spikes, or batch processing needs, unlimited rate limits eliminate a significant operational headache.
Integration requires minimal code changes. The API is OpenAI-compatible, meaning you change the base URL and API key while keeping your existing code structure:
pythonfrom openai import OpenAI # Configure for laozhang.ai gateway client = OpenAI( api_key="your-laozhang-api-key", base_url="https://api.laozhang.ai/v1" ) # Use Gemini through the gateway response = client.chat.completions.create( model="gemini-3-flash-preview", messages=[ {"role": "user", "content": "Your prompt here"} ] )
Model aggregation simplifies multi-provider strategies. Rather than managing separate API keys and SDKs for Google, OpenAI, Anthropic, and others, laozhang.ai provides unified access. This reduces integration complexity and enables easy model switching for A/B testing or fallback strategies.
For developers building production applications, the combination of lower effective pricing, unlimited rate limits, and simplified integration makes aggregator services worth evaluating. Documentation is available at https://docs.laozhang.ai/ and you can test image generation capabilities at https://images.laozhang.ai/.
For additional context on getting started with Gemini API access, see our Gemini API key setup guide.
Choosing Your Pricing Tier
With all the pricing data and optimization strategies covered, here's a decision framework for selecting the right approach based on your specific situation.
Hobbyist or Experimenter: Start with the free tier for exploration. Gemini 3 Flash Preview is available at no cost for up to 1,000 requests per day. Upgrade to paid only when you hit consistent rate limits or need production reliability.
Indie Developer or Small Startup: Use paid Gemini 3 Flash with context caching enabled. Expected monthly cost: $5-50 depending on usage. Focus on implementing caching for system prompts early—it's the highest-ROI optimization at this scale.
Growing Startup or Mid-Size Business: Combine Gemini 3 Flash for complex tasks with 2.5 Flash-Lite for simple operations. Implement batch processing for non-urgent workloads. Consider laozhang.ai if rate limits become restrictive during traffic spikes. Expected monthly cost: $50-500.
Enterprise Application: Evaluate Vertex AI for enterprise features, security compliance, and dedicated support. Use aggressive optimization (caching + batch + model routing) to minimize per-request costs. Expected monthly cost: $500+ with potential for significant optimization savings.
Cost-Sensitive Use Cases: DeepSeek offers the lowest raw pricing at $0.28/$0.42 per million tokens, but the 60 RPM rate limit makes it impractical for most production scenarios. For budget-constrained projects that can tolerate lower throughput, it remains an option. laozhang.ai provides a middle ground with competitive pricing and no rate limits.
The key insight is that Gemini 3 Flash hits a remarkable price-performance sweet spot. At $0.50/$3.00 per million tokens with 2000 RPM rate limits and 1M context window, it offers capabilities that cost 5-10x more on competing platforms. Combined with 90% caching discounts and 50% batch savings, it's currently the most cost-effective option for most AI application development.
Whether you're building a simple hobby project or scaling an enterprise application, understanding these pricing structures and optimization strategies ensures you're getting maximum value from every API dollar spent. The December 2025 release of Gemini 3 Flash has fundamentally shifted what's possible at accessible price points—take advantage of it.