
Pay for Gemini 3.1 Pro Preview when the workload is genuinely hard, tool-sensitive, and engineering-heavy. Default to Gemini 3.1 Flash-Lite for high-volume, latency-sensitive, cost-sensitive work that does not need Pro-level reasoning.
This is a routing decision first. Pro is not just a better benchmark label, and Flash-Lite is not just a cheaper copy. They are built for different production lanes, so the right answer depends on which lane you actually need.
TL;DR
If you only need the decision, use this rule:
- Choose Gemini 3.1 Pro Preview when mistakes are expensive, the job is multi-step, and better tool use or stronger software-engineering quality will save human review time.
- Choose Gemini 3.1 Flash-Lite Preview when the work is cheap-lane work: translation, extraction, labeling, summarization, routing, and other high-volume tasks where cost and throughput matter more than top-end reasoning.
- Use both if your traffic mix is real. Many teams should not replace one with the other. They should split-route.
The current official picture looks like this:
| Area | Gemini 3.1 Pro Preview | Gemini 3.1 Flash-Lite Preview | What it means |
|---|---|---|---|
| Current status | Preview | Preview | Neither is the safe GA default for every production team |
| Free tier | No | Yes | Flash-Lite is much easier to test, stage, and use for low-risk experiments |
| Standard input price | $2.00 / 1M tokens | $0.25 / 1M tokens | Pro costs 8x more on input |
| Standard output price | $12.00 / 1M tokens | $1.50 / 1M tokens | Pro also costs 8x more on output |
| Batch price up to 200k | $1.00 in / $6.00 out | Free tier, then $0.125 in / $0.75 out | Flash-Lite is dramatically better for cheap async volume |
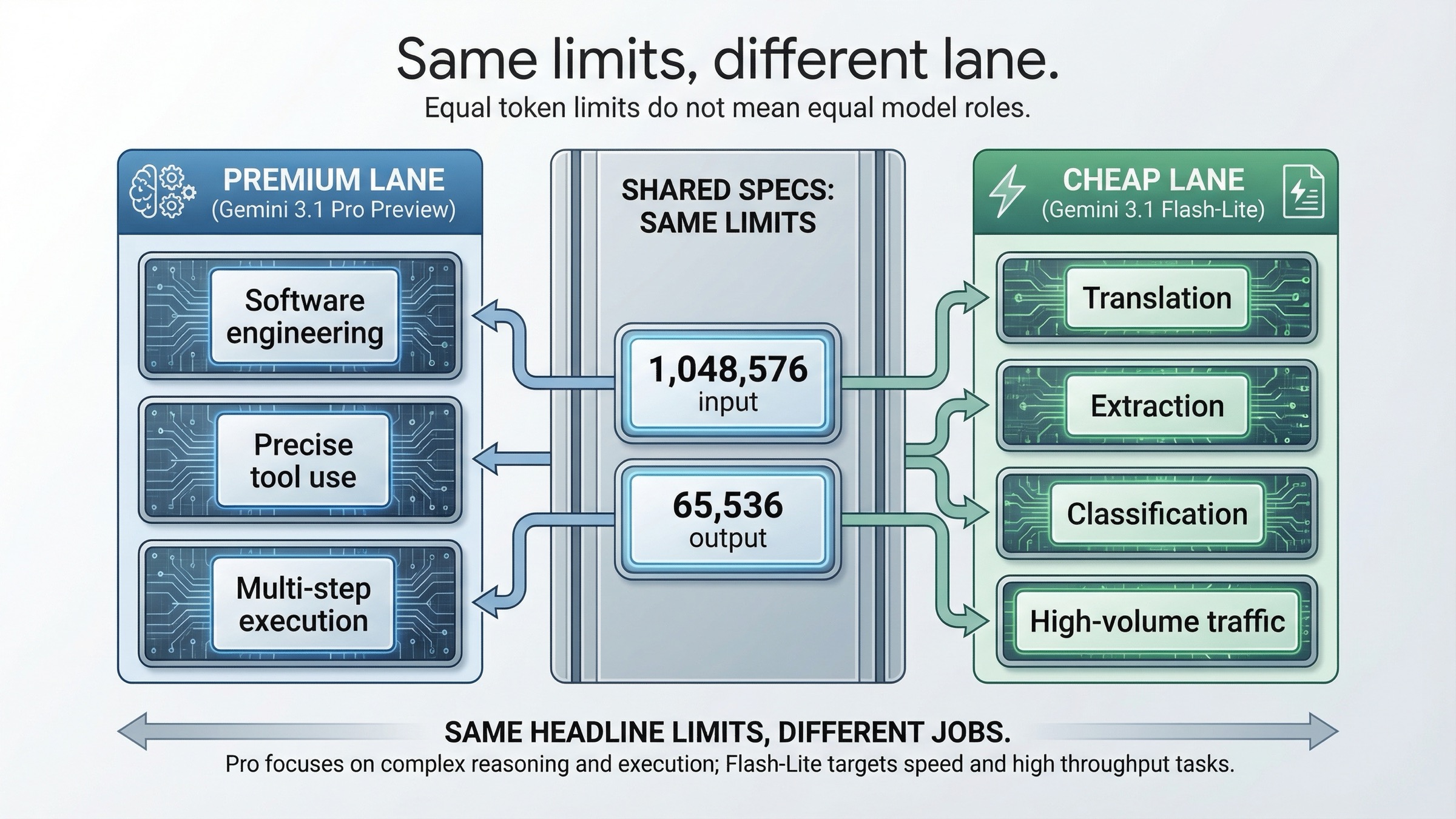
| Input token limit | 1,048,576 | 1,048,576 | Context window is not the buying decision |
| Output token limit | 65,536 | 65,536 | Output ceiling is not the buying decision either |
| Tier 1 batch queue ceiling | 5,000,000 tokens | 10,000,000 tokens | Flash-Lite is friendlier for large queued workloads |
| Best fit | Harder agentic work, software engineering, precise tool use | Translation, extraction, classification, low-latency high-volume traffic | This is the real routing split |
That table is the core recommendation. The rest of the article explains why the split is real, where the price gap is justified, and when you should run both models instead of forcing one to do everything.
Why This Comparison Is Really About Routing, Not Bigger Context
The fastest way to get this topic wrong is to assume Pro must win because it is the premium model, or to assume Flash-Lite must be "almost the same thing" because the name sounds like a smaller version of the same lane. The official docs do not support either simplification.
Start with what is the same. On the current official model pages, both models expose 1,048,576 input tokens and 65,536 output tokens. Both support the broad modern Gemini API surface, including search grounding, Google Maps grounding, URL context, structured outputs, caching, and batch. If you only skim the capability tables, they look closer than they actually are.
That is exactly why this comparison needs interpretation instead of spec-copying. Since both models already share the same headline window sizes, the real question becomes: what are you paying for, and what are you giving up?
The Gemini 3.1 Pro Preview page answers that pretty directly. Google says Pro improves thinking, token efficiency, factual consistency, and software-engineering behavior, and it emphasizes reliable multi-step execution plus precise tool usage. That is premium-lane language. It is the language you use when the model is supposed to carry more expensive work.
The Gemini 3.1 Flash-Lite Preview page uses very different language. It describes Flash-Lite as the most cost-efficient multimodal model for high-frequency lightweight tasks, high-volume agentic tasks, simple data extraction, translation, and extremely low-latency applications. That is not a weaker copy of Pro. It is a different optimization target.
This is why the right framing is not "which one is better?" The right framing is:
- Which workloads actually need Pro-quality reasoning and tool behavior?
- Which workloads are cheap-lane work that should stay on Flash-Lite?
- Is your traffic mix pure enough that one model can be the default, or mixed enough that split-routing is the sane answer?
If you keep that frame in mind, the current official evidence becomes much easier to use.
Pricing, Batch Economics, And Public Rate-Limit Reality on March 20, 2026

Pricing is where the recommendation stops being abstract.
On the current Gemini Developer API pricing page, Gemini 3.1 Pro Preview is paid-only. For prompts up to 200k tokens, Google lists $2.00 per 1M input tokens and $12.00 per 1M output tokens. Above 200k prompt tokens, the price rises to $4.00 input and $18.00 output. Batch pricing cuts that in half, but even the batch lane is still $1.00 input and $6.00 output up to 200k tokens.
Flash-Lite is a different world. The same pricing page says Gemini 3.1 Flash-Lite Preview has a free tier, and the paid rates are only $0.25 input and $1.50 output per 1M tokens. The batch lane is cheaper again: $0.125 input and $0.75 output, plus a free batch tier on the entry surface.
This is not a small premium. It is an 8x premium on both standard input and standard output pricing. That matters because it changes what "good enough" means. If Pro is only slightly better for your job, it is probably not worth paying for by default. If Pro is materially better at avoiding bad tool calls, broken code patches, or failed multi-step plans, then the premium may be justified very quickly. But the model has to earn that gap.
The public rate-limit picture points in the same direction. Google's current rate-limits page now tells developers to look in AI Studio for the active RPM and TPM numbers, which means you should not hard-code one public table into long-lived docs. But the page still exposes something very useful: Tier 1 Batch API enqueued-token limits. There, Google lists 5,000,000 tokens for Gemini 3.1 Pro Preview and 10,000,000 for Gemini 3.1 Flash-Lite Preview.
That matters more than it may look at first glance. A lot of real production traffic is not interactive chat. It is background work:
- translation batches
- extraction queues
- document labeling
- summarization pipelines
- large routing jobs
For those workloads, Flash-Lite is not just cheaper. It is also friendlier to big queued throughput.
Grounding does not rescue Pro into a universal default either. The pricing page shows both models with 5,000 free grounding prompts per month in paid usage before charging $14 per 1,000 search queries or $14 per 1,000 maps queries. So if your mental shortcut was "maybe Pro is the one with the better grounding deal," the current public pricing page does not support that.
The economic conclusion is simple. If the work is high-volume and routine enough that you are watching every million tokens, Flash-Lite should be your default until Pro proves it can pay its own bill.
When Gemini 3.1 Pro Preview Actually Earns Its Premium
This is the part many cheap-model-first comparisons flatten too aggressively. There are real workloads where Pro is the better buy even at 8x the token price.
The current official Pro page is explicit about why: Google is selling Gemini 3.1 Pro Preview as the better lane for software engineering, reliable multi-step execution, and precise tool usage. The official Gemini 3.1 Pro model card strengthens that story. Published on February 19, 2026, it calls Pro Google's most advanced model for complex tasks as of publication and reports stronger results on harder evaluation sets such as Humanity's Last Exam, GPQA Diamond, Terminal-Bench 2.0, SWE-Bench Verified, and APEX-Agents.
You should still read those benchmarks carefully. A benchmark table is not a promise that your exact workload will be proportionally better. But the directional message is clear. Pro is where Google wants you when the job is hard enough that model quality compounds:
- multi-step agent plans
- tool-heavy coding flows
- tasks where one bad tool decision creates a long failure chain
- complex reasoning where cheap retries still cost more than one better answer
- software-engineering tasks where a stronger first draft saves real developer time
There is also one practical surface difference that matters more than many broad comparison pages admit. The official Pro docs expose a separate gemini-3.1-pro-preview-customtools endpoint for mixed bash and custom-tool workflows. That does not mean every agent should run on Pro. But it does line up with real user behavior. A Reddit thread titled "I had to switch to 3.1 Pro Preview Custom Tools for my Agent" is not canonical evidence of platform guarantees, but it is a useful friction signal. It shows the kind of buyer who is searching this keyword: someone trying to get a real tool-sensitive system to behave properly.
That is the right place to think about Pro's price. Not as a universal upgrade. As a premium lane where quality failures are expensive enough that stronger reasoning or better tool handling can more than pay for the token delta.
The practical rule is:
Use Pro when the cost of bad answers is much higher than the cost of tokens.
If that is not true for your workload, Pro usually does not deserve to be the default.
When Gemini 3.1 Flash-Lite Preview Should Stay Your Default
Flash-Lite is easy to underrate because so much AI comparison content is benchmark-first. The current Google docs do not describe it as a throwaway model. They describe it as the cost-efficient lane for real work that happens at scale.
The official Gemini 3.1 Flash-Lite Preview page and Gemini 3.1 Flash-Lite model card point to the same set of workloads:
- translation
- classification
- simple data extraction
- high-frequency, low-latency calls
- large async queues
- lightweight agent flows where the steps are easy and the economics matter more than frontier reasoning
That is a huge amount of production traffic.
If your system is mostly taking known inputs and producing constrained outputs, Flash-Lite is often the smarter default not because it is "almost as good," but because it is optimized for a different kind of work. A lot of extraction, labeling, templated summarization, and translation pipelines do not benefit enough from Pro to justify an 8x price increase. In those jobs, paying the premium is often just buying a nicer model than the task requires.
The free tier makes the same conclusion even stronger for teams that care about staging and experimentation. With Flash-Lite, you still have an easier low-risk lane for:
- prompt-template experiments
- staging checks
- low-volume QA
- route testing before you turn on paid traffic
That is operationally useful. A paid-only premium lane changes how teams test. A cheaper lane with a free tier changes how teams learn.
This is also why I would not describe Flash-Lite as merely the model you use when you are broke. It is the correct model whenever the job is cheap-lane work. Good routing is not about always picking the most powerful model. It is about not paying premium-model prices for work that does not need premium-model behavior.
If your backlog is full of translation, extraction, labeling, and large-volume background jobs, Flash-Lite should not be your fallback. It should probably be your starting point.
Replace, Split-Route, Or Keep Both
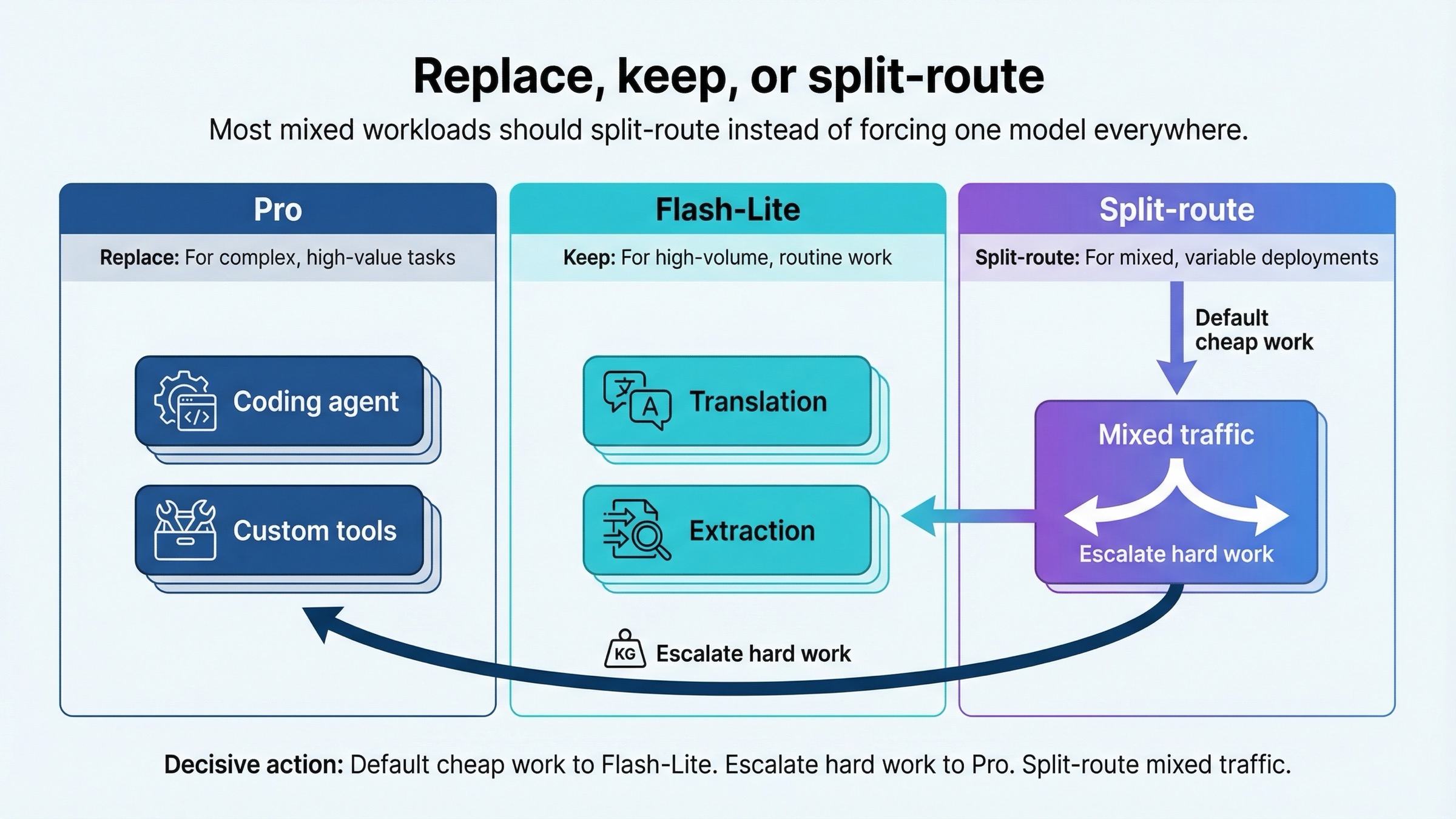
For most serious teams, the answer is not full replacement in either direction.
If you replace Flash-Lite with Pro everywhere, you usually overpay for routine work. If you replace Pro with Flash-Lite everywhere, you often discover too late that your hardest tool-sensitive flows were being carried by the extra model quality. That is why the most defensible answer for mixed workloads is still split-routing.
Use this operating guide:
| Workload | Better default | Why |
|---|---|---|
| Tool-heavy coding agent | Gemini 3.1 Pro Preview | Better fit for reliable multi-step execution and software-engineering behavior |
| Custom-tool orchestration | Gemini 3.1 Pro Preview | Pro has the clearer tool-sensitive product story and customtools surface |
| Translation at scale | Gemini 3.1 Flash-Lite Preview | Much cheaper, free-tier friendly, and aligned with the official positioning |
| Structured extraction and labeling | Gemini 3.1 Flash-Lite Preview | Cheap-lane work where Pro often does not earn 8x cost |
| Large async batch queue | Gemini 3.1 Flash-Lite Preview | Lower batch price and larger public Tier 1 batch queue ceiling |
| Mixed production traffic | Split-route | Use Flash-Lite by default and escalate hard cases to Pro |
In practice, that often means a three-step rollout:
- Start new high-volume pipelines on Flash-Lite unless you already know the work is hard enough to break cheap-lane models.
- Benchmark Pro only on the slices where quality failures are expensive: coding, planning, complex tool use, or long multi-step tasks.
- Keep the default on Flash-Lite and escalate specific classes of prompts to Pro if the quality delta is real.
This is also the cleanest way to avoid article-template advice like "Pro for quality, Lite for cost." That sentence is too shallow to run a system on. You need a routing rule. The routing rule is this:
Default to Flash-Lite for cheap-lane work. Escalate to Pro only where the higher-quality answer saves more money than the token premium costs.
If you want a sibling comparison that helps position Flash-Lite against a stronger non-Pro fast model, our Gemini 3.1 Flash-Lite vs Gemini 3 Flash guide is the next page to read. If you want to see how Google's premium lane compares with an older stable premium option, our Gemini 3.1 Pro vs Gemini 2.5 Pro comparison covers that decision.
For quota planning, it is also worth checking our Gemini API rate limits per tier guide and Gemini API context caching cost guide, because the model choice is only part of the production bill.
FAQ
Is Gemini 3.1 Pro Preview better than Gemini 3.1 Flash-Lite Preview?
Yes for harder tasks. The current official docs and model cards clearly position Pro as the stronger lane for software engineering, multi-step execution, and harder reasoning. But "better" does not mean "better default for every call." Flash-Lite is often the better operational choice for cheap high-volume work.
Which one is cheaper?
Flash-Lite by a large margin. On the March 20, 2026 pricing page, Pro is $2.00 input and $12.00 output per 1M tokens up to 200k prompt tokens, while Flash-Lite is $0.25 input and $1.50 output. That is an 8x gap on both sides.
Do both models have the same token limits?
Yes. The current official model pages list 1,048,576 input tokens and 65,536 output tokens for both. That is why this comparison should not be framed as a bigger-context decision.
Which one should I use for coding agents?
Start with Pro if the agent is tool-heavy, multi-step, and expensive to review. Start with Flash-Lite only if the coding task is lightweight enough that cost matters more than first-pass quality.
Which one should I use for translation or extraction at scale?
Flash-Lite. That is exactly the kind of workload the official docs describe it for, and the price plus batch queue advantages make it the much more natural default.