As of March 19, 2026, Gemini 3.1 Pro is the stronger top-end model, but Gemini 2.5 Pro is still the better default for a surprising number of real production workloads. That sounds contradictory until you look at the official Google pages side by side. Gemini 3.1 Pro is the newer reasoning-first preview model, built and priced for harder agentic work. Gemini 2.5 Pro is the generally available model that remains cheaper, still has a free tier in the Gemini Developer API, and carries less operational uncertainty.
That means the real question is not "Which Gemini model wins on paper?" The real question is "Should I replace Gemini 2.5 Pro everywhere, or should I keep it as the stable default and only escalate to Gemini 3.1 Pro for the most difficult tasks?" Most current pages do not answer that clearly. They either repeat benchmark screenshots or quote raw specs without translating them into a routing decision. This article does the opposite: it starts with the decision, then shows which official facts support it.
TL;DR
If you only need the current answer, here it is. Choose Gemini 3.1 Pro when your bottleneck is hard reasoning, agentic coding, or tool-heavy workflows where better top-end performance matters more than preview risk or free-tier access. Choose Gemini 2.5 Pro when you want a stable GA default, cheaper token pricing, a free-tier path for testing, and fewer surprises in production.
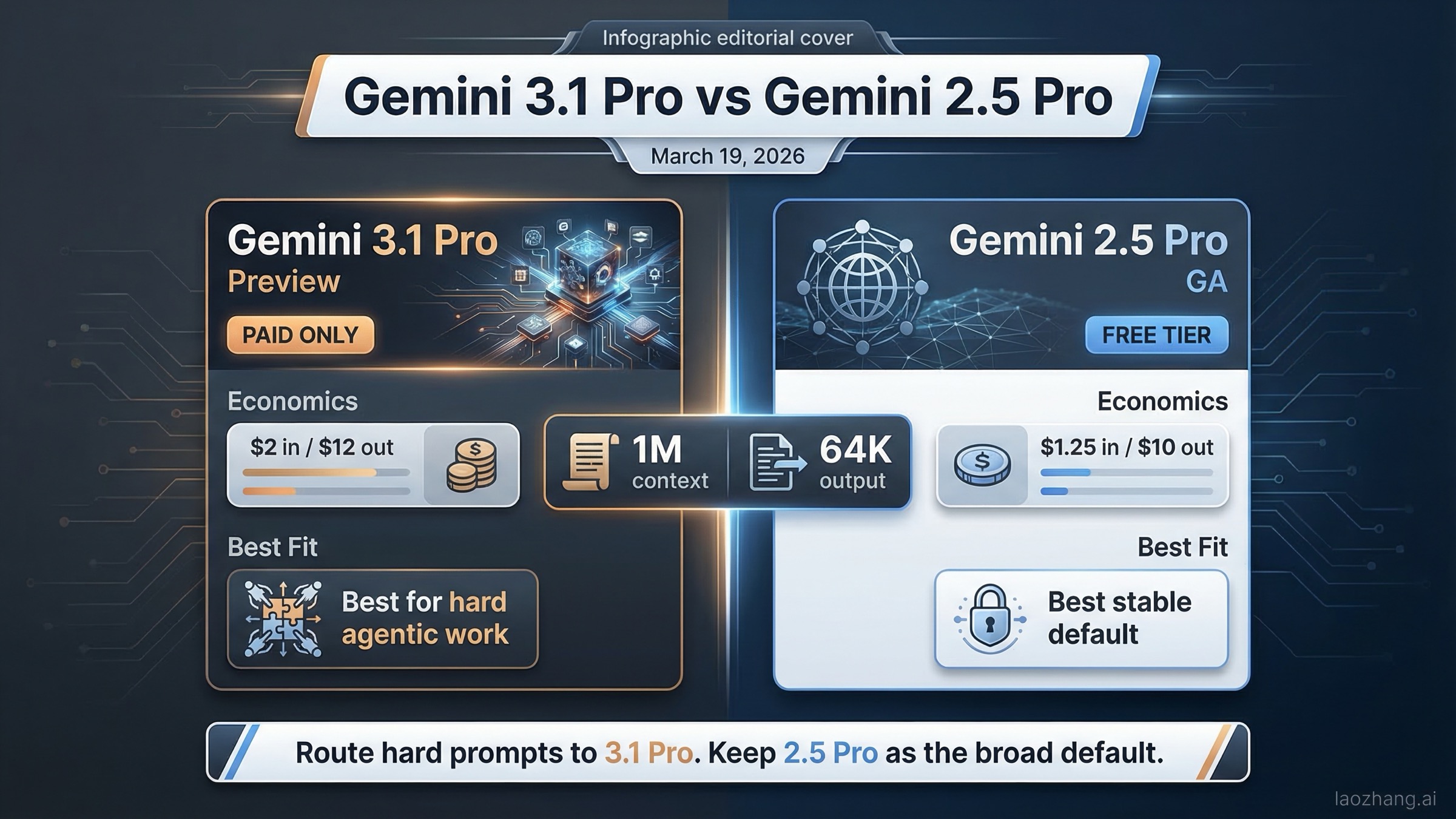
The official March 19, 2026 comparison looks like this:
| Area | Gemini 3.1 Pro | Gemini 2.5 Pro | What it means |
|---|---|---|---|
| Current status | Preview | Generally available | 3.1 is newer but still not the safest default for every production team |
| Model ID | gemini-3.1-pro-preview | gemini-2.5-pro | Migration requires explicit model routing, not blind replacement |
| Free tier | No | Yes | 2.5 Pro is easier for testing, staging, and low-risk experimentation |
| Standard input price | $2.00 / 1M tokens up to 200k | $1.25 / 1M tokens up to 200k | 3.1 costs 60% more on standard input |
| Standard output price | $12.00 / 1M tokens up to 200k | $10.00 / 1M tokens up to 200k | 3.1 costs 20% more on standard output |
| Long prompt price | $4.00 in / $18.00 out above 200k | $2.50 in / $15.00 out above 200k | The pricing gap persists on large prompts |
| Context window | 1M tokens | 1M tokens | 3.1 does not win on headline context size |
| Max output | 64K tokens | 64K tokens | 3.1 does not win on output ceiling either |
| Best fit | Harder agentic reasoning, advanced coding, frontier work | Stable production default, cost-sensitive deployment, free-tier testing | Use 3.1 as the premium lane, not automatically as the only lane |
Those rows come directly from the Gemini Developer API pricing page, the Gemini API models page, the Vertex AI model catalog, the Gemini 3.1 Pro model card, and the official Gemini 2.5 Pro model card PDF. The key insight is that Google is not asking you to trade 2.5 Pro for 3.1 Pro on raw limits. Both models expose a 1M-token context window and a 64K-token output limit. The trade is about model quality, pricing, and product maturity.
That is why the practical recommendation is simple:
- Use Gemini 3.1 Pro when the task is genuinely hard enough that stronger reasoning or agentic performance can save human review time.
- Keep Gemini 2.5 Pro as your default for everyday coding, broad production traffic, and any environment where free-tier access or GA stability matters.
- If you can support routing, do not pick just one. Default to 2.5 Pro and escalate to 3.1 Pro for the hardest prompts.
This is also why many teams comparing the two models feel confused. The newer model sounds like a universal upgrade, but the official pricing and status pages say otherwise. Gemini 3.1 Pro is better described as a premium lane than as a universal replacement.
What Actually Changed From 2.5 Pro to 3.1 Pro
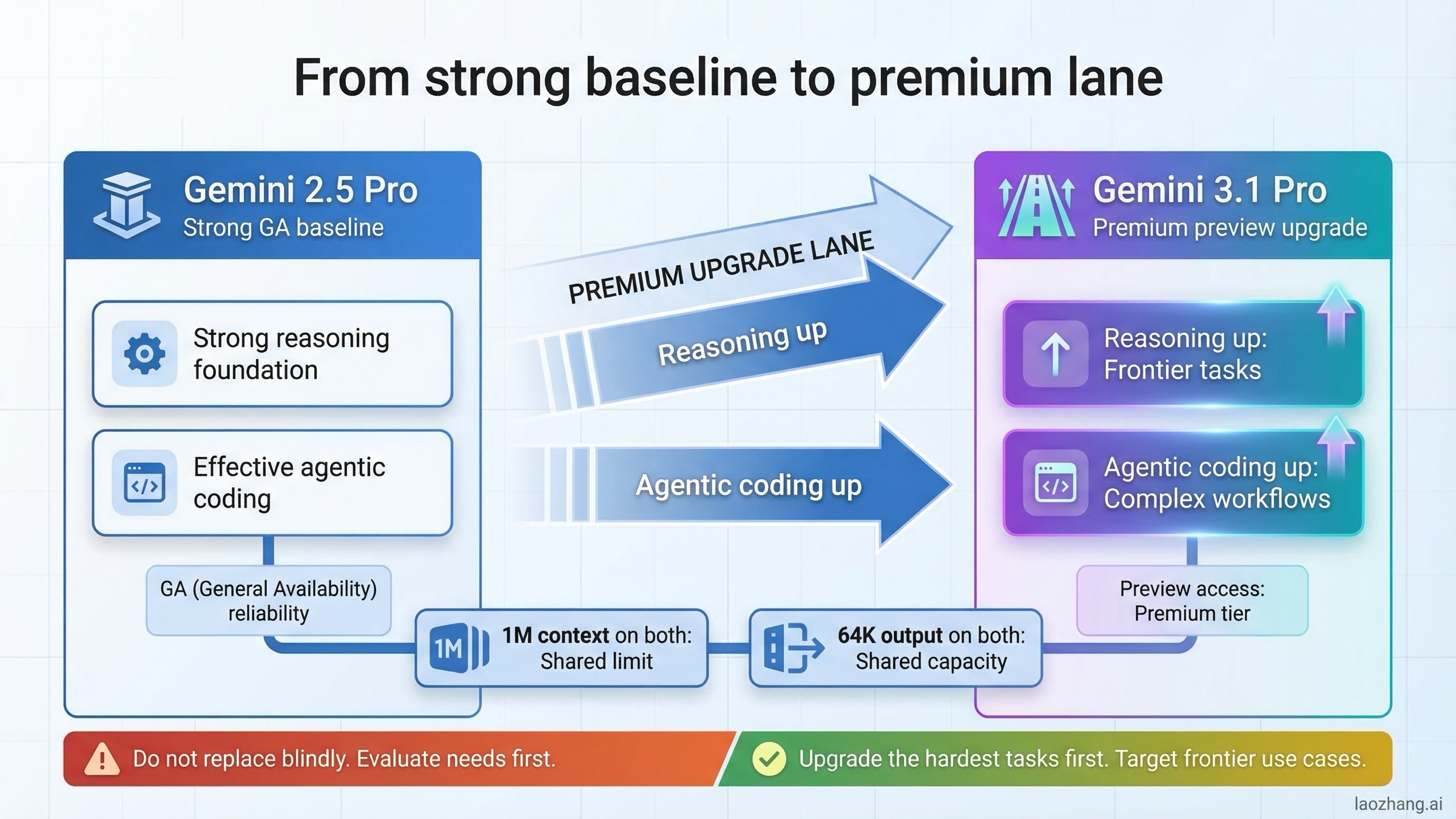
The easiest mistake in this comparison is to assume the move from 2.5 Pro to 3.1 Pro is mainly about longer context, bigger output limits, or a simple speed bump. It is not. The bigger shift is in Google’s positioning of the model family.
On the current Vertex AI models page, Google lists Gemini 3.1 Pro in the preview section and describes it as the latest reasoning-first model optimized for complex agentic workflows and coding. The same page lists Gemini 2.5 Pro in the generally available section as the high-capability model for complex reasoning and coding. That wording matters. Google is essentially telling you that 3.1 Pro is the frontier step forward, while 2.5 Pro is the stable current standard.
The Gemini 3.1 Pro model card strengthens that message. Published on February 19, 2026, it says Gemini 3.1 Pro is Google’s most advanced model for complex tasks as of publication. The same card confirms 1M context, 64K output, and broad distribution through the Gemini app, Vertex AI, AI Studio, Gemini API, Google Antigravity, and NotebookLM. That is a strong product signal: Google wants 3.1 Pro to be the premium reasoning choice across its surfaces.
But the older Gemini 2.5 Pro model card, updated on June 27, 2025, shows why 2.5 Pro is still hard to retire. The card explicitly states that Gemini 2.5 Pro is now generally available. It also confirms the same 1M context and 64K output shape, which means that many teams switching to 3.1 Pro are not gaining a bigger context or output envelope. They are paying for a smarter model, not a roomier one.
This distinction becomes even clearer when you look at the final public 2.5 Pro product framing before 3.1 arrived. In Google’s May 6, 2025 product post, "Build rich, interactive web apps with an updated Gemini 2.5 Pro", the company highlighted better coding and web-app generation results and pointed to strong performance on WebDev Arena. That helped cement 2.5 Pro as the practical coding baseline for a lot of developers. So when 3.1 Pro arrived, users did not compare it to a weak predecessor. They compared it to a model that already had a strong reputation for real work.
That is the right mental model for the rest of this article:
- Gemini 2.5 Pro is not "the old weak one."
- Gemini 3.1 Pro is not "the same thing but free and faster."
- The comparison is really premium preview versus stable GA.
If you keep that frame in mind, the rest of the product and pricing signals start making sense.
Pricing, Free Tier, And Model Status on March 19, 2026

Pricing is where the upgrade decision becomes concrete. Many model comparisons hide the answer behind benchmark language, but the official Gemini Developer API pricing page makes the trade very clear on March 19, 2026.
For Gemini 3.1 Pro Preview, Google lists:
- No free tier
\$2.00input tokens per 1M up to 200k prompt tokens\$12.00output tokens per 1M up to 200k prompt tokens\$4.00input and\$18.00output above 200k prompt tokens- Batch pricing at half the standard token rate
For Gemini 2.5 Pro, Google lists:
- Free tier available
\$1.25input tokens per 1M up to 200k prompt tokens\$10.00output tokens per 1M up to 200k prompt tokens\$2.50input and\$15.00output above 200k prompt tokens- Batch pricing at half the standard token rate
That means the standard paid delta is not subtle:
- Input cost: 3.1 Pro is 60% more expensive than 2.5 Pro.
- Output cost: 3.1 Pro is 20% more expensive than 2.5 Pro.
- Free-tier access: 3.1 Pro removes it entirely.
If you are running a production application, that difference is manageable when the higher-end model meaningfully reduces retries, bad drafts, or human review. But if you are doing routine coding assistance, broad customer traffic, or staging work, the price increase is real and the free-tier loss is even more important. Many teams do not feel the token delta first. They feel the loss of a safe experimental lane.
A simple example makes this practical. Suppose you run a pipeline that sends 50 million input tokens and 10 million output tokens through one model in a month, with prompts mostly under 200k tokens. On raw published pricing, Gemini 2.5 Pro costs about:
- Input: 50 x $1.25 =
\$62.50 - Output: 10 x $10 =
\$100 - Total:
\$162.50
The same traffic on Gemini 3.1 Pro costs about:
- Input: 50 x $2.00 =
\$100 - Output: 10 x $12 =
\$120 - Total:
\$220
That is not catastrophic, but it is not trivial either. The cost uplift is roughly 35% in this example, before you consider that the 2.5 lane still supports a free tier for experimentation and low-volume usage while 3.1 does not.
Status matters just as much as pricing. The Gemini API models page and the Vertex AI model catalog both reinforce the same product split: 3.1 Pro is still preview, 2.5 Pro is already generally available. In practice, "preview" does not mean unusable. Plenty of teams ship preview models when the upside is worth it. But it does mean you should assume greater change risk in behavior, tooling, and deployment expectations.
This is why the right production question is not "Can I afford 3.1 Pro?" It is "Do I need 3.1 Pro enough to justify paying more for a preview model when 2.5 Pro already covers the mainstream use case?" For a lot of traffic, the answer is still no. For the hardest reasoning lanes, it may be yes.
Why API Teams And Gemini App Users Do Not Make The Same Decision
One reason this keyword produces confusing search results is that it mixes together two very different buyers. Some searchers are deciding which API model to call in production. Others are trying to understand what the Gemini app exposes inside Google’s consumer and subscriber surfaces. Those are related questions, but they are not the same question.
Google’s own current page-one behavior reflects that split. For API users, the strongest sources are the Gemini Developer API pricing page, the Gemini API models page, the Vertex AI model catalog, and the official model cards. For app users, Google also surfaces support content such as the help page for Gemini Apps limits and upgrades, because a lot of users are really asking a plan-entitlement question: "Will I actually see this model in the app, and under what limits?"
If you are an API team, the choice between Gemini 3.1 Pro and Gemini 2.5 Pro is mainly about five things:
- model quality on your hardest tasks
- token price
- free-tier access
- operational maturity
- tool-side economics such as caching, batch, and grounding
If you are a Gemini app user, the decision is narrower. You care more about:
- which model the app currently exposes
- whether your subscription tier unlocks it
- how often you can use it
- whether the newer model feels better for your actual workflow
That difference matters because the API economics here are more nuanced than the usual "newer model costs more" headline.
On the current pricing page, Gemini 3.1 Pro Preview is not only paid-only, it is also more expensive across the surrounding features that serious API teams actually use. For prompts up to 200k tokens, the page lists:
- Gemini 3.1 Pro Preview context caching at
\$0.20per 1M tokens - Gemini 2.5 Pro context caching at
\$0.125per 1M tokens - the same storage price for both at
\$4.50 / 1,000,000 tokens per hour
Above 200k prompt tokens, the split continues:
- Gemini 3.1 Pro Preview context caching rises to
\$0.40 - Gemini 2.5 Pro context caching rises to
\$0.25
That is easy to miss if you only compare standard input and output rates. In real systems, the premium is not just the main token line item. If your application reuses large contexts, long system prompts, or bulky retrieved documents, the cost difference also shows up in the surrounding machinery.
Batch pricing is another good example. The top of Google’s pricing page describes paid access as including the Batch API with 50% cost reduction. When you inspect the per-model tables, both Gemini 3.1 Pro Preview and Gemini 2.5 Pro roughly follow that pattern. For prompts up to 200k tokens:
- Gemini 3.1 Pro Preview batch pricing is
\$1.00input and\$6.00output - Gemini 2.5 Pro batch pricing is
\$0.625input and\$5.00output
That means 3.1 Pro remains the more expensive lane even after the batch discount. If your traffic is asynchronous and cost-sensitive, batch does not erase the difference. It just lowers both lanes.
Grounding economics also matter if you rely on Google Search or Maps inside the Gemini tool stack. Here you need to read carefully, because the pricing tables are not phrased identically. Gemini 3.1 Pro Preview currently shows 5,000 prompts per month free for Search and Maps grounding, then \$14 / 1,000 search queries. Gemini 2.5 Pro shows 1,500 RPD free for grounded prompts, then \$35 / 1,000 grounded prompts for Search and \$25 / 1,000 grounded prompts for Maps. You should not flatten those into a fake apples-to-apples claim because the charging unit language differs. But you should notice the practical implication: once you start using tools seriously, the model choice is also a tool-billing choice.
This is why the free tier matters more than it seems. For a lot of teams, the free tier is not just about saving money on hobby usage. It is the cheapest way to keep a test lane alive:
- staging prompts
- new prompt-template experiments
- low-risk regression checks
- smoke tests for routing changes
Gemini 2.5 Pro still gives you that on-ramp. Gemini 3.1 Pro Preview does not.
That difference changes how smart teams usually adopt the newer model. They do not start by saying, "3.1 Pro is better, so everything moves." They start by saying, "2.5 Pro remains the low-friction validation lane, and 3.1 Pro becomes the premium lane we justify with harder tasks."
The support-page side of the SERP reinforces the same point from a different angle. When Google ranks help-center content for Gemini app limits, it is effectively acknowledging that many readers do not primarily need a benchmark chart. They need clarity about access surfaces. In the app, users are often asking a plan-and-availability question. In the API, developers are asking a workflow-and-economics question.
Those questions only partially overlap. An app user might reasonably choose the newer model whenever it appears in the model picker because the incremental cost is hidden inside a subscription. An API team cannot think that way. API teams need to know:
- whether the model stays predictable enough to run as a default
- whether the premium is acceptable at production scale
- whether caching and batch still preserve the business case
- whether a paid-only preview model should sit in the core lane or the escalation lane
That is why this article keeps returning to routing strategy. For app users, "Which one should I click?" may be enough. For API teams, the real question is, "Which one should carry the broad lane, and which one should handle the expensive edge cases?"
Once you separate those audiences, the comparison becomes much less confusing:
- App-first reading: newer model, probably try it when available, compare by felt quality.
- API-first reading: stable default versus premium lane, with price, caching, grounding, and batch costs all in scope.
For the rest of this guide, the API reading is the one that matters most. It is the stricter test, and it is the one most ranking pages still do not explain well.
Benchmarks: Where 3.1 Really Pulls Ahead, And Where The Comparison Is Messier
Benchmark sections in AI comparisons often sound more certain than they really are. That is especially dangerous here because the official Gemini 3.1 Pro model card and the official Gemini 2.5 Pro model card do not provide a single unified same-date table comparing 3.1 directly against 2.5 on every benchmark. The official numbers are still useful, but they must be read with care.
This is the directional picture from the two official model cards:
| Benchmark | Gemini 3.1 Pro official figure | Gemini 2.5 Pro official figure | Safe reading |
|---|---|---|---|
| Humanity's Last Exam | 44.4% | 21.6% | Strong evidence that 3.1 moves Google higher on frontier reasoning |
| GPQA Diamond | 94.3% | 86.4% | 3.1 looks materially stronger on scientific reasoning |
| SWE-Bench Verified | 80.6% | 59.6% | Directionally strong for 3.1, but the cards are not a single same-date harness |
| Terminal-Bench 2.0 | 68.5% | Not reported in 2.5 GA card | 3.1 is explicitly positioned for stronger agentic coding |
| APEX-Agents | 33.5% | Not reported in 2.5 GA card | Again points to stronger long-horizon agentic performance |
| Context / output | 1M / 64K | 1M / 64K | No headline win for 3.1 here |
The safest interpretation is that Gemini 3.1 Pro clearly improves Google’s own frontier reasoning and agentic story, but you should avoid pretending that every line in the two model cards is a laboratory-perfect head-to-head. Some metrics are directly comparable enough to be useful. Others are not.
Even with that caveat, the pattern is obvious. Gemini 3.1 Pro is the model Google wants you to reach for when the task is:
- multi-step and tool-heavy
- difficult enough that a better reasoning chain changes the result
- closer to agentic coding than routine autocomplete
- expensive in human review time when the first answer is weak
Gemini 2.5 Pro still looks good when the task is:
- high-quality but not frontier-difficult
- repeated at scale
- price-sensitive
- operationally broad rather than elite
That is why the benchmarks should change how you route traffic, not trick you into replacing everything. If your hardest 5% of tasks are much more valuable than your average 95%, 3.1 Pro may be worth its premium easily. If your workload is mostly steady coding help, retrieval-rich summarization, or structured business prompting, 2.5 Pro’s lower price and GA maturity are still compelling.
There is another subtle point here. Because both models already share 1M context and 64K output, the benchmark delta matters more than usual. You are not buying extra room. You are buying a better brain for certain classes of tasks. That makes workload discrimination more important than ever.
Latency, Long Context, And Production Reliability
The official pages make the capability difference easy to see, but they do not remove the operational question: how predictable is the newer model under real usage?
This is where the SERP gets interesting. Alongside official docs, Google search also surfaces user-friction material such as the Google AI Developers Forum thread titled "Gemini 3 significantly worse thant 2.5 Pro at long context. Temperature likely to blame". That thread is not a canonical platform specification, and you should not treat one forum post as a definitive platform fact. But it is a useful signal that some users are not evaluating the two models by launch-card ambition. They are evaluating them by whether the newer generation behaves reliably on long or difficult prompts.
That distinction matters because both official model cards advertise the same 1M context and 64K output. On paper, that suggests parity. In practice, equal maximum limits do not guarantee equal user experience. The real production questions are:
- Which model is more predictable on your actual prompt mix?
- Which model produces fewer expensive false starts?
- Which model requires less routing logic or fallback handling?
- Which model justifies its price premium through fewer retries or less human correction?
For many teams, Gemini 2.5 Pro remains the steadier answer because it is already GA and cheaper. Preview status is not the same thing as instability, but it is enough reason to avoid turning 3.1 Pro into a universal default before you measure it on your own traffic.
This is also the right place to separate capability risk from product risk. Gemini 3.1 Pro probably wins the capability argument for the hardest reasoning and agentic lanes. Gemini 2.5 Pro often wins the product argument for broad deployment because:
- it is GA, not preview
- it has a free tier
- it is cheaper
- many teams already know its behavior
That is why the safest large-scale pattern is usually progressive routing, not blanket replacement. Keep 2.5 Pro in the broad lane. Send only the prompts that actually need more intelligence to 3.1 Pro. If 3.1 meaningfully reduces failures or review load, expand its share over time. If not, you have not broken the whole system just to follow the newest label.
If your team is already deep in Google workflows, it is also worth checking related operational guidance such as our Gemini 3.1 Pro output limit guide, Gemini 3.1 Pro timeout guide, and Gemini API error troubleshooting guide. Those adjacent issues are often what decide whether a model is production-ready for your specific setup.
Which Model To Choose For Coding, Agents, Research, And Cost Control
The easiest way to make this comparison useful is to stop asking for an overall winner and start matching models to workloads.
| Workload | Better default | Why |
|---|---|---|
| Everyday coding assistance | Gemini 2.5 Pro | Cheaper, GA, still strong enough for mainstream coding help |
| Hard agentic coding | Gemini 3.1 Pro | Official positioning and benchmark story point to stronger agentic performance |
| Research-heavy analysis | Gemini 3.1 Pro | Better official frontier reasoning signals make the premium easier to justify |
| Long-context document work at scale | Gemini 2.5 Pro first, 3.1 Pro selectively | Same 1M context, but 2.5 is cheaper and safer as a default lane |
| Free-tier experimentation | Gemini 2.5 Pro | 3.1 Pro has no free tier |
| Broad production traffic | Gemini 2.5 Pro | GA status and lower cost reduce operational friction |
| Premium fallback lane | Gemini 3.1 Pro | Best use of the new model when not every request needs it |
For solo developers and small teams, the simplest good answer is usually: start on 2.5 Pro, keep a 3.1 Pro route for the toughest requests, and do not overcomplicate the system until the premium lane pays for itself.
For larger engineering teams, the answer becomes architectural. If you are already operating a routing layer, then Gemini 3.1 Pro is easy to justify as the high-intelligence lane while 2.5 Pro remains the bulk lane. That is especially true if your stack already depends on model routing, tiered retries, or task classification. In that setup, the worst decision is often not "using the older model." The worst decision is "sending every request to the expensive preview model whether it needs it or not."
For research or evaluation-heavy teams, 3.1 Pro deserves more weight. The official 3.1 model card tells a stronger frontier reasoning story than the 2.5 GA card, and if your workload depends on difficult synthesis, multi-step tool use, or agentic coding loops, the premium may be justified more often. But even there, keep the pricing reality in view. Stronger is not the same as costless.
For cost-sensitive production, 2.5 Pro remains extremely hard to beat. The combination of GA status, free-tier access, and lower per-token rates means it still has a better economics story for broad deployment. If you do not have evidence that 3.1 materially improves the business outcome, then 2.5 Pro is still the rational default.
This is also the one place where a relay or multi-model gateway can matter. If your real challenge is not just choosing between two Gemini generations but routing between them cleanly in one codebase, a gateway such as laozhang.ai can be relevant because the job becomes traffic shaping, cost control, and fallback management rather than one-model loyalty. That is only worth mentioning because the comparison here is operational by nature. If you are comparing models in production, routing strategy is part of the product choice.
What To Benchmark Before You Promote 3.1 Pro
The most common implementation mistake after reading a comparison like this is to run one or two impressive prompts on Gemini 3.1 Pro, decide it feels smarter, and then treat that as enough proof to change the default model everywhere. That is not a serious evaluation process. The price and maturity tradeoffs here are real enough that you should benchmark like an operator, not like a curious user.
Start by splitting your workload into buckets that reflect how your system actually creates value. A useful default looks like this:
| Evaluation bucket | Typical examples | Model question you are really asking |
|---|---|---|
| Routine coding and editing | refactors, small tests, straightforward bug fixes | Is 3.1 actually better enough to justify paying more on common work? |
| Hard agentic coding | multi-step repo changes, tool-heavy repair loops, long execution chains | Does 3.1 reduce first-pass failure enough to save review time? |
| Long-context analysis | large documents, long transcripts, multi-file reasoning | Does 3.1 stay better once the prompt becomes bulky and messy? |
| Grounded research or tool use | search-backed answers, tool orchestration, external lookups | Do the tool-calling gains justify the premium and grounding costs? |
| Cost-sensitive bulk traffic | high-volume routine requests | Is there any reason not to keep 2.5 Pro as the default lane? |
If you only test one bucket, you will almost certainly misread the upgrade. Gemini 3.1 Pro can be clearly worth it in the hard agentic bucket and still be the wrong default for the bulk traffic bucket. That is exactly why the routing recommendation exists.
The second rule is that you should measure accepted work, not just raw model output quality. In other words, the important metric is not "Which answer sounded better to me?" The important metric is "Which model produced the cheaper acceptable result after retries, corrections, and review?"
That usually means tracking at least these fields:
- first-pass acceptance rate
- human correction minutes
- retry rate
- p95 latency
- token cost
- caching cost where applicable
- grounding cost where applicable
- fallback rate to another model or workflow
Without those numbers, you do not actually know whether 3.1 Pro is cheaper or more expensive at the business level. A more expensive model can still win if it reduces correction time enough. A smarter model can still lose if the improvement only appears on the hardest 3% of traffic while the other 97% gets needlessly more expensive.
This is where many teams discover that "benchmark winner" and "default winner" are different categories.
To benchmark responsibly, you want to keep the comparison conditions as stable as possible:
- Freeze the prompt templates for the duration of the test.
- Keep the tool set the same across both models.
- Use the same temperature and reasoning configuration where the APIs allow fair comparison.
- Test on real production-like prompts, not public toy tasks.
- Separate easy tasks from hard tasks before you average the results.
That last point is critical. If you average everything together, the hard-task gains from 3.1 Pro can disappear into a sea of routine tasks that 2.5 Pro already handles well. The opposite mistake also happens: teams over-sample "hero tasks" and then convince themselves the premium lane should become the universal lane. Both errors come from mixing buckets that should be evaluated separately.
The third rule is that you need to test for operational behavior, not just for correctness. Because both models already offer 1M context and 64K output on paper, the real difference often shows up in workflow behavior:
- how often the answer needs one more retry
- whether tool orchestration holds together on long chains
- whether long-context prompts stay coherent
- whether the response structure is easier or harder to post-process
- whether the model behaves predictably week over week
This is where preview status matters. A preview model can absolutely be good enough for production. But if you promote a preview model to the broad default lane, you are also promoting its change risk. That is not automatically wrong. It just means the bar should be higher.
A sensible promotion test for Gemini 3.1 Pro looks something like this:
- Collect a representative prompt set from the last 2 to 4 weeks of real work.
- Label each prompt by task type and business importance.
- Run the same prompt set on Gemini 2.5 Pro and Gemini 3.1 Pro.
- Score the outputs with blinded human review where practical.
- Record latency and retry behavior alongside quality.
- Compare cost per accepted answer, not just cost per token.
- Keep the test running long enough to notice operational variance, not just launch-day novelty.
If your team has the volume, do not stop at an offline benchmark. Run a controlled live routing experiment:
- keep Gemini 2.5 Pro as the default
- send a narrow slice of the hardest requests to Gemini 3.1 Pro
- compare business outcomes on that slice
- expand only if the lift is durable
That approach mirrors the actual product split. Gemini 2.5 Pro is already the stable broad lane. Gemini 3.1 Pro is the premium lane that needs to earn its share.
The fourth rule is to benchmark tool-side cost behavior, not just the model response. This is where the pricing page becomes more useful than many benchmark posts. If your production system depends on long prompts, caching, batch jobs, or grounding, then the upgrade decision is partly about infrastructure economics:
- Does 3.1 still make sense when caching is more expensive?
- Does batch preserve the margin enough for asynchronous jobs?
- Does the grounded-workflow unit pricing stay acceptable at your volume?
- Does the absence of a free-tier lane slow down experimentation?
Those questions matter because they change who the upgrade is for. A team doing high-stakes internal research may happily pay the premium. A consumer product serving a large volume of mid-difficulty requests may decide the premium only makes sense for escalations.
The fifth rule is to define the promotion gate before you look at the results. Otherwise the organization will unconsciously move the goalposts. A strong gate might be:
- Gemini 3.1 Pro must beat Gemini 2.5 Pro by a meaningful margin on the hard-task bucket.
- The latency increase must stay inside your service-level budget.
- Cost per accepted answer must remain within an agreed premium band.
- Preview behavior must remain stable through a multi-day or multi-week check.
- The bulk-traffic bucket must either stay on 2.5 Pro or show an actual business reason to move.
If 3.1 Pro clears those gates, promote it where it won. If it does not, keep it in the specialty lane. That is still a successful evaluation. The point of a benchmark is not to force adoption. The point is to make the routing logic more intelligent.
One practical pattern works especially well here:
- classify requests into low, medium, and high difficulty
- keep
gemini-2.5-profor low and most medium work - route high-difficulty or high-review-cost work to
gemini-3.1-pro-preview - monitor the hard bucket every week and re-check promotion rules monthly
That gives you most of the upside of the newer model without forcing the whole business onto the more expensive preview lane.
If you want one sentence to remember from this entire section, use this one: benchmark the premium lane against your correction budget, not against your curiosity. Gemini 3.1 Pro only deserves default status if it improves the expensive part of your workflow often enough to outweigh its higher price and lower maturity.
Migration Strategy: Replace, Split-Route, Or Stay On 2.5 Pro
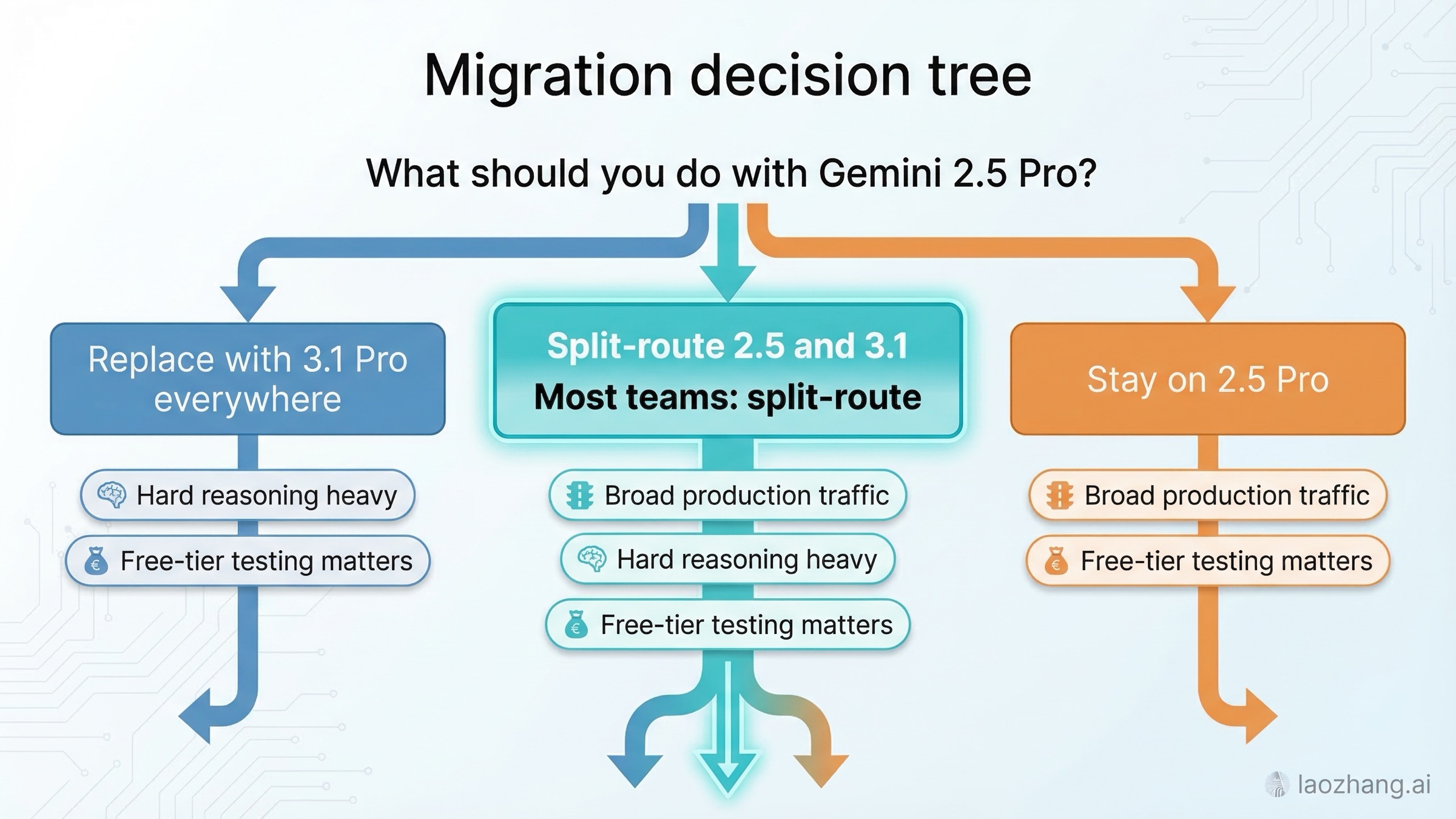
Most teams should choose one of three migration patterns.
Pattern 1: Replace with Gemini 3.1 Pro everywhere. This only makes sense when your workload is unusually concentrated in hard reasoning or agentic coding and you are comfortable shipping a preview model as the default. It is the most aggressive path and the one most likely to disappoint if you have not measured prompt quality, latency tolerance, and cost impact on real traffic.
Pattern 2: Split-route between 2.5 Pro and 3.1 Pro. This is the best general answer. Keep Gemini 2.5 Pro as the default lane. Escalate to Gemini 3.1 Pro when the task matches one or more of these criteria:
- The prompt is high stakes and human review is expensive.
- The first-pass failure rate on 2.5 Pro is already hurting throughput.
- The task is clearly agentic or multi-step rather than single-shot.
- The request needs stronger reasoning more than it needs lower cost.
A simple routing policy can be enough:
tsfunction chooseGeminiModel(task: { requiresAgenticCoding: boolean; reasoningDifficulty: "low" | "medium" | "high"; costSensitive: boolean; needsFreeTierFallback: boolean; }) { if (task.needsFreeTierFallback || task.costSensitive) { return "gemini-2.5-pro"; } if (task.requiresAgenticCoding || task.reasoningDifficulty === "high") { return "gemini-3.1-pro-preview"; } return "gemini-2.5-pro"; }
Pattern 3: Stay on 2.5 Pro for now. This is not the conservative answer because you are afraid of innovation. It is the rational answer when your current quality is already good enough, you depend on free-tier testing, or the extra 3.1 capability does not obviously produce a better business outcome. A model upgrade is only a real upgrade if it improves the workflow that matters.
The cleanest migration checklist looks like this:
- Benchmark both models on your own prompts, not on generic internet tasks.
- Track output quality and human correction time together, not just token cost.
- Keep 2.5 Pro as a fallback until 3.1 Pro proves itself on production-like traffic.
- Do not assume 3.1 is better just because the official model card is stronger.
- Promote 3.1 only where the measured gain is worth the price and preview risk.
That last point is the whole article in one sentence. Gemini 3.1 Pro is the model you promote by evidence, not the model you adopt everywhere by default.
FAQ
Is Gemini 3.1 Pro better than Gemini 2.5 Pro? Yes for top-end reasoning and agentic work, based on Google’s current positioning and the official Gemini 3.1 Pro model card. No if you mean "better in every practical way." Gemini 2.5 Pro is still cheaper, GA, and available on the free tier, so it remains the better default for many teams.
Does Gemini 3.1 Pro give you a larger context window or output limit? No. As of March 19, 2026, the official documentation for both models says they support a 1M-token context window and 64K-token output. The main differences are model quality, pricing, and status, not headline limit expansion.
Is Gemini 3.1 Pro more expensive? Yes. On the official Gemini Developer API pricing page, 3.1 Pro costs \$2.00 input and \$12.00 output per 1M tokens for prompts up to 200k tokens. Gemini 2.5 Pro costs \$1.25 input and \$10.00 output under the same standard tier, and it still has a free tier.
Should I migrate all traffic from Gemini 2.5 Pro to Gemini 3.1 Pro? Usually no. The better default is to keep 2.5 Pro as the broad lane and route only the hardest requests to 3.1 Pro. Full replacement makes sense only when the stronger reasoning actually changes your business outcome enough to justify the higher price and preview status.
Are the benchmark numbers perfectly apples-to-apples? No. They are official numbers, but they do not come from one single unified same-date head-to-head document. Use them directionally and combine them with pricing, status, and workload fit instead of treating every row as a perfect lab comparison.
Does this comparison matter the same way for Gemini app users and API users? Not exactly. App users care more about plan access and the model picker. API users care more about free-tier access, token rates, batch pricing, and routing logic. That is why this article focuses on the production API decision while still noting that Google surfaces model-access questions heavily in support pages for app users.
Bottom line
If you want the strongest current Gemini model for hard reasoning and agentic workflows, choose Gemini 3.1 Pro. If you want the best default for stable, price-conscious, broad production use, choose Gemini 2.5 Pro. If you can route by task, use both and let the workload decide.