
As of March 19, 2026, Gemini 3.1 Flash-Lite is the better pick if you want lower token cost, higher speed, and stronger official benchmark results for high-volume reasoning tasks. Gemini 2.5 Flash is still the safer default if you care more about stable status, free-tier grounding, and predictable production behavior. That is the real answer behind this keyword. It is not a generic "newer is better" story.
The confusion comes from the model names. A lot of developers assume a model called Flash-Lite must sit below an older full Flash model in every way. Google's own current docs say otherwise. On the official pricing page, Gemini 3.1 Flash-Lite is cheaper than Gemini 2.5 Flash on both input and output tokens. On the official DeepMind model page, it also beats Gemini 2.5 Flash on output speed and a long list of benchmarks. But the same official comparison still leaves Gemini 2.5 Flash ahead on FACTS and on MRCR at 1M context, while the Gemini 2.5 Flash model card keeps its deployment status at general availability.
That makes this a routing decision, not a bragging-rights decision. The useful question is not "Which one wins the screenshot?" The useful question is "Should I replace Gemini 2.5 Flash everywhere, or keep it as the stable default and move only the right workloads to Gemini 3.1 Flash-Lite?"
TL;DR
If you only need the answer, here it is. Choose Gemini 3.1 Flash-Lite when your workload is latency-sensitive, high-volume, and mostly about translation, classification, structured extraction, lightweight coding, or routing. Choose Gemini 2.5 Flash when you need the safer Stable lane, free-tier Google Search grounding, or you care more about grounded / long-context behavior than about launch-era speed gains.
The current official comparison looks like this:
| Area | Gemini 3.1 Flash-Lite | Gemini 2.5 Flash | What it means |
|---|---|---|---|
| Current status | Preview | Stable / GA | 3.1 is newer, but 2.5 is still the safer production default |
| Model ID | gemini-3.1-flash-lite-preview | gemini-2.5-flash | You should route explicitly, not hot-swap blindly |
| Standard input price | Free, then $0.25 / 1M | Free, then $0.30 / 1M | 3.1 is cheaper on input |
| Standard output price | Free, then $1.50 / 1M | Free, then $2.50 / 1M | 3.1 is materially cheaper on output |
| Context window | 1,048,576 tokens | 1,048,576 tokens | Context size is not the main differentiator |
| Max output | 65,536 tokens | 65,536 tokens | Output ceiling is also the same |
| Free-tier grounding | No free-tier Search grounding | Search grounding free up to 500 RPD | 2.5 is easier if built-in Google search is core to your app |
| Official speed comparison | 363 tokens/s on DeepMind table | 249 tokens/s on DeepMind table | 3.1 has the speed advantage |
| Official benchmark caveat | Better on GPQA, MMMU-Pro, LiveCodeBench, 128k MRCR | Better on FACTS and 1M MRCR | 3.1 is not a universal winner |
| Best fit | High-volume reasoning at low latency and lower cost | Stable production default with grounding-friendly behavior | Use 3.1 as the faster value lane, 2.5 as the steadier default |
Those rows come from the official Gemini API pricing page, the dedicated Gemini 3.1 Flash-Lite model page, the dedicated Gemini 2.5 Flash model page, the Gemini API release notes, and Google DeepMind's official Flash-Lite comparison page.
The practical recommendation is simple:
- Switch to Gemini 3.1 Flash-Lite first for translation, extraction, routing, and other high-throughput lanes where lower output cost and higher speed help immediately.
- Keep Gemini 2.5 Flash as the safer default when you depend on stable lifecycle guarantees, free-tier Search grounding, or you care a lot about factual grounding and 1M-context performance.
- If you can support split routing, do that. It is the most defensible answer on March 19, 2026.
Why This Comparison Is Weird
This comparison looks strange because it is not the tidy same-tier comparison people expect. Normally you would compare Gemini 3.1 Flash-Lite to Gemini 2.5 Flash-Lite, or Gemini 3 Flash to Gemini 2.5 Flash. But real production teams are not comparing marketing labels. They are comparing what they already use against what might replace it.
That is why Gemini 2.5 Flash is the real baseline here. It has been the dependable, low-latency reasoning model in the public Gemini API. The dedicated Gemini 2.5 Flash page still lists it under Stable versions and gives it the familiar 1M context / 64K output shape. The Gemini 2.5 Flash model card goes further and says deployment status continues to be general availability.
Gemini 3.1 Flash-Lite is a different kind of launch. According to the official release notes, Google launched it on March 3, 2026 as the first Flash-Lite model in the Gemini 3 series. The dedicated model page positions it for translation, transcription, simple document processing, high-volume structured extraction, and model routing. In other words, Google is not pitching it as a toy. It is a serious low-cost lane with enough intelligence to threaten older mid-tier defaults.
That is the key mental model:
- Gemini 2.5 Flash is the stable workhorse.
- Gemini 3.1 Flash-Lite is the faster, cheaper, preview challenger.
- Gemini 2.5 Flash-Lite is still the absolute budget lane, but it is not the same question as this keyword.
If you skip that framing, the SERP gets confusing fast. You end up comparing the wrong neighbors or turning a routing decision into a naming debate.
Pricing, Free Tier, And Grounding On March 19, 2026

Pricing is the part of this comparison that most pages get half right. They are correct that Gemini 3.1 Flash-Lite is cheaper than Gemini 2.5 Flash. They usually do not explain the rest of the picture.
On the official Gemini Developer API pricing page, the current standard pricing is:
- Gemini 3.1 Flash-Lite Preview: free standard usage, then
\$0.25input and\$1.50output per 1M tokens - Gemini 2.5 Flash: free standard usage, then
\$0.30input and\$2.50output per 1M tokens
That means the newer model is cheaper on both sides of the bill:
- input is about 17% cheaper
- output is 40% cheaper
That output delta matters more than the input delta for a lot of real workloads. If you are generating summaries, classifications with rationale, short support replies, or structured extraction with verbose JSON, the output line item is often where the bill grows. On that dimension alone, Gemini 3.1 Flash-Lite makes a strong case.
Batch pricing preserves the same direction:
- Gemini 3.1 Flash-Lite Batch:
\$0.125input and\$0.75output - Gemini 2.5 Flash Batch:
\$0.15input and\$1.25output
So if your workload is asynchronous and cost-sensitive, 3.1 Flash-Lite still keeps the advantage.
But the official pricing page also shows why 2.5 Flash has not been cleanly displaced. The difference is grounding. On March 19, 2026:
- Gemini 2.5 Flash still lists free-tier Google Search grounding up to 500 RPD, plus free-tier Google Maps grounding at 500 RPD
- Gemini 3.1 Flash-Lite Preview shows no free-tier grounding, and instead lists paid-tier allowances of 5,000 prompts per month before charging for Search or Maps queries
That changes the real recommendation for grounded assistants. If your app already depends on Google's built-in Search tool, Gemini 2.5 Flash is easier to justify as the default because the public free-tier story is friendlier and the operational behavior is more mature. If your workflow does not depend on grounding, 3.1 Flash-Lite's cheaper output pricing looks much more attractive.
There is also one more cost trap that many quick takes skip: Gemini 3.1 Flash-Lite is cheaper than 2.5 Flash, but it is not the cheapest Gemini text model. The same pricing page shows Gemini 2.5 Flash-Lite at \$0.10 input and \$0.40 output. So if your only objective is absolute minimum token cost, your real alternative is not 2.5 Flash. It is 2.5 Flash-Lite. This article stays focused on the keyword, but that is still worth saying because readers regularly conflate these lanes.
If you need the broader cost context, our Gemini API pricing 2026 guide and Gemini API free quota 2026 guide break down the surrounding billing and free-tier details.
Benchmarks: Where 3.1 Flash-Lite Wins, And Where 2.5 Flash Still Matters

The strongest official comparison is the one Google put on the DeepMind Gemini 3.1 Flash-Lite page. That page compares Gemini 3.1 Flash-Lite High against Gemini 2.5 Flash Dynamic across price, speed, reasoning, coding, multimodal benchmarks, and long-context tests.
The important rows look like this:
| Metric | Gemini 3.1 Flash-Lite | Gemini 2.5 Flash | Lean |
|---|---|---|---|
| Input price | $0.25 / 1M | $0.30 / 1M | 3.1 Flash-Lite |
| Output price | $1.50 / 1M | $2.50 / 1M | 3.1 Flash-Lite |
| Output speed | 363 tokens/s | 249 tokens/s | 3.1 Flash-Lite |
| Humanity's Last Exam | 16.0% | 11.0% | 3.1 Flash-Lite |
| GPQA Diamond | 86.9% | 82.8% | 3.1 Flash-Lite |
| MMMU-Pro | 76.8% | 66.7% | 3.1 Flash-Lite |
| LiveCodeBench | 72.0% | 62.6% | 3.1 Flash-Lite |
| MRCR v2 at 128k | 60.1% | 54.3% | 3.1 Flash-Lite |
| FACTS | 40.6% | 50.4% | Gemini 2.5 Flash |
| MRCR v2 at 1M | 12.3% | 21.0% | Gemini 2.5 Flash |
That is a much more nuanced story than most launch-style posts tell.
The pro-switch case is obvious:
- 3.1 Flash-Lite is faster
- 3.1 Flash-Lite is cheaper
- 3.1 Flash-Lite is ahead on the most visible reasoning, coding, and multimodal quality signals
If your workflow is translation, support summarization, structured extraction, lightweight coding, or classifier-style routing, those rows are persuasive. They fit exactly the use cases Google highlights on the dedicated model page.
But the keep-2.5 case is not fake either. The same official table shows 2.5 Flash ahead on:
- FACTS, which matters because it is the benchmark row closest to a grounded factuality story
- MRCR v2 at 1M context, which matters if your documents are truly long and you care about long-range retrieval behavior
That is the main reason I would not replace 2.5 Flash everywhere on day one. If your app leans heavily on grounded answers or very long document contexts, the official side-by-side still leaves 2.5 Flash with a defensible role.
Google's launch framing makes the performance story even stronger. In the official Google Blog launch post, Google says 3.1 Flash-Lite delivers a 2.5x faster time to first answer token and a 45% increase in output speed versus 2.5 Flash. Those are the headline numbers driving SERP clicks, and they are directionally consistent with the DeepMind table. But they still do not erase the caveat rows.
So the safe reading is this: Gemini 3.1 Flash-Lite is the better default for many high-volume low-latency reasoning tasks, but it is not the automatic winner for grounded or very-long-context production work.
Preview Risk, Rate Limits, And What Stable Still Buys You
Benchmark wins are only half the production decision. Lifecycle status still matters.
The official Gemini API rate-limits page says three things that are easy to miss in ranking pages:
- rate limits apply per project, not per API key
- preview models have more restrictive rate limits
- specified rate limits are not guaranteed and actual capacity may vary
That is the part of the docs that makes "Preview" meaningful. It does not mean "never ship this." It means you should treat the model like a moving lane rather than a settled baseline.
There is one upside on the same page that does favor 3.1 Flash-Lite. On the public Batch API table for Tier 1, Google lists:
- Gemini 3.1 Flash-Lite Preview: 10,000,000 enqueued batch tokens
- Gemini 2.5 Flash: 3,000,000 enqueued batch tokens
That is a real throughput signal. If you run large asynchronous queues, the public batch table makes 3.1 Flash-Lite look more scalable. But you still should not misread one table as a guaranteed production promise, because the same rate-limits page also warns that actual capacity may vary.
Stable still buys you three concrete things:
- Less lifecycle churn. The Gemini 2.5 Flash model page lists the model under Stable versions, while 3.1 Flash-Lite is explicitly Preview.
- Better public grounding story. The pricing page still gives 2.5 Flash a cleaner free-tier grounding lane.
- Easier default justification. When a customer-facing workflow breaks, "we kept the stable model as default" is easier to defend than "we promoted the preview lane because it benchmarked better."
That is why production teams should treat 3.1 Flash-Lite as a deliberate migration, not as a silent alias swap.
Which Model To Use For Which Workload
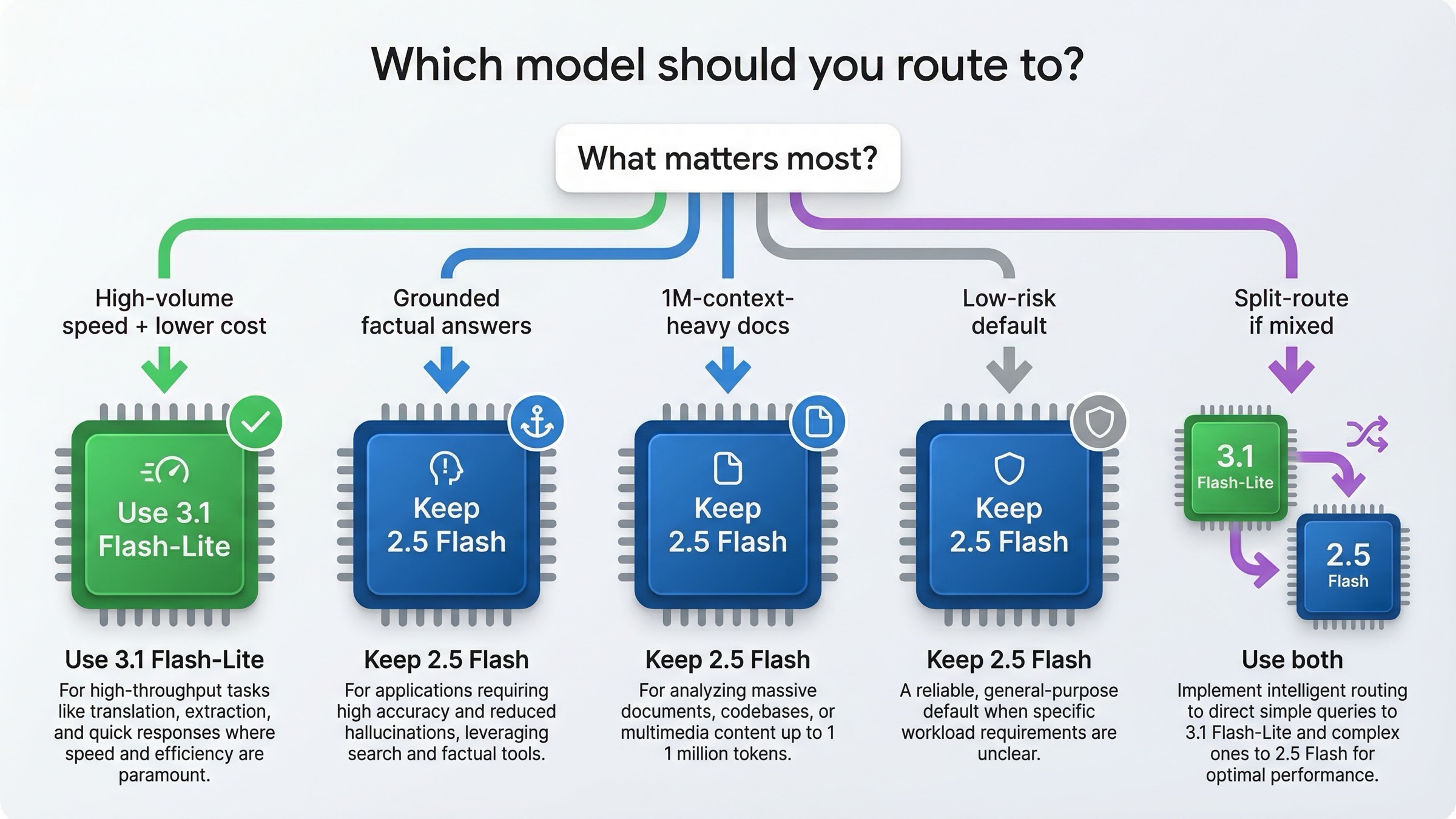
The easiest way to make this article useful is to turn the comparison into routing advice.
| Workload | Pick first | Why |
|---|---|---|
| Translation at scale | Gemini 3.1 Flash-Lite | Google explicitly positions it for translation, and the price/speed profile fits perfectly |
| Structured extraction and JSON pipelines | Gemini 3.1 Flash-Lite | Stronger speed and lower output cost matter more than stable lifecycle here |
| Task routing and classifier layers | Gemini 3.1 Flash-Lite | The official model page literally uses routing as a best-fit example |
| Lightweight coding and UI generation | Gemini 3.1 Flash-Lite | Better LiveCodeBench and lower latency make it the more interesting lane |
| Search-grounded factual assistants | Gemini 2.5 Flash first | Free-tier grounding and better FACTS score make 2.5 the safer starting point |
| Very long document reasoning near 1M context | Gemini 2.5 Flash first | It still wins the official MRCR row at 1M |
| Broad production default when risk tolerance is low | Gemini 2.5 Flash | Stable / GA still matters |
| Split-route setups | Both | 2.5 for grounded / long-context lanes, 3.1 for fast high-volume lanes |
One more nuance matters here: thinking controls differ. The official Gemini 2.5 Flash model card describes 2.5 Flash as Google's first fully hybrid reasoning model with configurable thinking budgets. The 3.1 Flash-Lite launch instead emphasizes reasoning levels. That may sound minor, but it matters if you are already tuning your inference budget carefully. If thinking behavior is central to your architecture, our Gemini API thinking-level guide is worth reviewing before you migrate.
How To Migrate Without Regretting It
The best March 2026 migration plan is not "switch everything." It is a staged rollout.
Start with three buckets:
- Low-risk, high-volume lanes
Move translation, extraction, classification, and routing jobs to Gemini 3.1 Flash-Lite first. These are the places where the cheaper output pricing and faster responses are most likely to help immediately.
- Grounded and long-context lanes
Keep Gemini 2.5 Flash as the default for assistants that depend on built-in Search grounding, or for document workflows where your evals really stress the 1M context window. Those are the two most obvious reasons not to promote 3.1 Flash-Lite blindly.
- Fallback and regression lane
Do not delete your 2.5 Flash route just because 3.1 Flash-Lite looks better in public tables. Keep a fallback until your own prompts, latency budget, and error patterns say otherwise. If you need help building that regression discipline, our Gemini API error troubleshooting guide and Gemini API rate-limits-per-tier guide cover the operational side.
The most defensible migration stance on March 19, 2026 is:
- Switch first if speed and token cost are your bottlenecks.
- Wait or split-route if your app depends on grounding quality, very-long-context retrieval, or a stricter stability requirement.
- Do not confuse "cheaper than 2.5 Flash" with "best Gemini price overall."
FAQ
Is Gemini 3.1 Flash-Lite better than Gemini 2.5 Flash?
Mostly yes, if your definition of better is faster output, cheaper input and output pricing, and stronger official benchmark scores on reasoning, coding, and multimodal tasks. No, if your definition of better includes stable lifecycle status, free-tier grounding, or stronger official results on FACTS and MRCR at 1M context.
Is Gemini 3.1 Flash-Lite really cheaper?
Yes against Gemini 2.5 Flash. The official pricing page lists \$0.25 input and \$1.50 output for Gemini 3.1 Flash-Lite versus \$0.30 input and \$2.50 output for Gemini 2.5 Flash. But it is not cheaper than Gemini 2.5 Flash-Lite, which is a different comparison.
Does Gemini 3.1 Flash-Lite beat 2.5 Flash everywhere?
No. Google's own DeepMind comparison page still shows Gemini 2.5 Flash ahead on FACTS and on MRCR v2 at 1M context. That is the most important caveat missing from many launch-style comparison posts.
Should I compare Gemini 3.1 Flash-Lite to Gemini 2.5 Flash-Lite instead?
If your only question is absolute minimum token cost, yes, that is the more natural comparison. But many real teams are asking whether the new cheap Gemini 3 lane is good enough to replace the older stable 2.5 Flash workhorse. That is why this comparison still matters.
Should production teams switch now?
Switch selectively now. Do not replace everything now. The strongest current move is to pilot Gemini 3.1 Flash-Lite on fast high-volume lanes, keep Gemini 2.5 Flash for grounded or stability-sensitive paths, and let your own evals decide whether a full migration is worth it.