Anthropic's Claude Opus 4.6 has reshaped the pricing landscape for frontier AI models, arriving at $5 per million input tokens and $25 per million output tokens for standard API access. That represents a striking 67% reduction compared to the previous Opus 4.1 generation, which charged $15 and $75 respectively. With multiple pricing tiers including a fast mode at 6x the standard rate, an extended 1M context window in beta, Batch API discounts of 50%, and prompt caching that slashes input costs by up to 90%, the actual price you pay depends heavily on which features you combine. This guide breaks down every pricing dimension of Claude Opus 4.6 as of February 2026, with verified data from Anthropic's official documentation, so you can calculate your true costs and choose the most cost-effective access strategy for your specific workload.
TL;DR
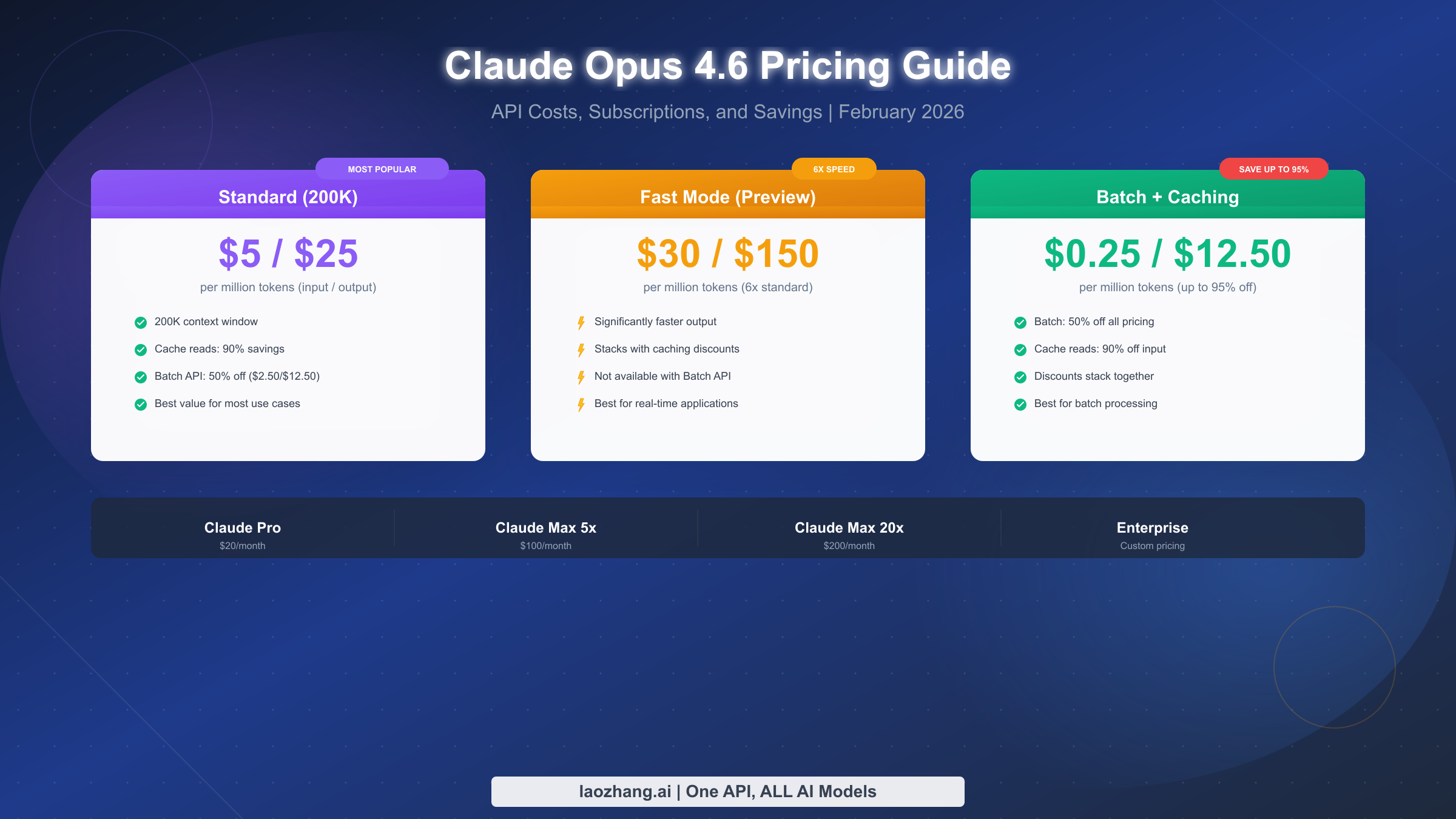
Claude Opus 4.6 costs $5/MTok input and $25/MTok output for standard API access, making it 67% cheaper than the previous Opus 4.1. Fast mode runs at $30/$150 MTok for speed-critical applications, representing a 6x premium. Extended 1M context beta costs $10/$37.50 MTok. Save up to 50% with Batch API and 90% on input via prompt caching. Stack both discounts to achieve $0.25/MTok input, a 95% savings from the base rate. Claude Pro subscription at $20/month gives conversational access to Opus 4.6 without per-token billing. All pricing verified from Anthropic official docs, February 2026.
What Is Claude Opus 4.6 and Why Does Pricing Matter?
Claude Opus 4.6 is Anthropic's most capable AI model released in early 2026, currently ranked as the number one non-reasoning model among 58 contenders evaluated on the ArtificialAnalysis.ai independent benchmark platform. The model represents a significant leap in capability while simultaneously delivering the largest price reduction Anthropic has ever offered on its flagship tier. Where the previous generation Claude Opus 4.1 commanded $15 per million input tokens and $75 per million output tokens, Opus 4.6 arrives at just $5 and $25 respectively. That 67% cost reduction makes frontier-level AI capability accessible to a substantially broader range of developers, startups, and enterprises than was previously economically viable with Anthropic's top-tier models.
Understanding the pricing structure matters because Claude Opus 4.6 does not have a single, flat rate. Instead, Anthropic has built a layered pricing system with at least five distinct cost tiers depending on how you access the model. Standard API access represents just the starting point. Fast mode, designed for latency-sensitive applications, charges a 6x premium at $30 and $150 per million tokens. The extended 1M context window, currently available in beta for Tier 4 organizations, introduces its own elevated pricing at $10 and $37.50 per million tokens when your input exceeds the standard 200K token threshold. Batch API processing offers a flat 50% discount across all token categories but delivers results within a 24-hour window rather than in real time. Prompt caching introduces yet another pricing layer with cache write premiums and dramatically reduced cache read costs. Each of these options can be combined in specific ways, creating a matrix of potential pricing that ranges from the full standard rate down to as little as $0.25 per million input tokens when batch processing and cache reads are stacked together.
For developers building production applications, the difference between naive API usage and an optimized strategy can translate to thousands of dollars per month in cost savings. A team processing 100,000 API calls daily might spend $15,000 per month at standard rates but only $2,000 with proper optimization, representing an 87% reduction in AI infrastructure costs. This guide provides the complete pricing map so you can navigate these options effectively. If you are looking for a broader overview of how Claude's pricing fits within Anthropic's full model lineup, our Claude API pricing guide covers every model tier from Haiku to Opus. And for readers who want to compare the current Opus 4.6 pricing against the previous generation Opus pricing, that resource details the Opus 4.1 cost structure that Opus 4.6 has now replaced at significantly lower rates.
Complete API Pricing Breakdown
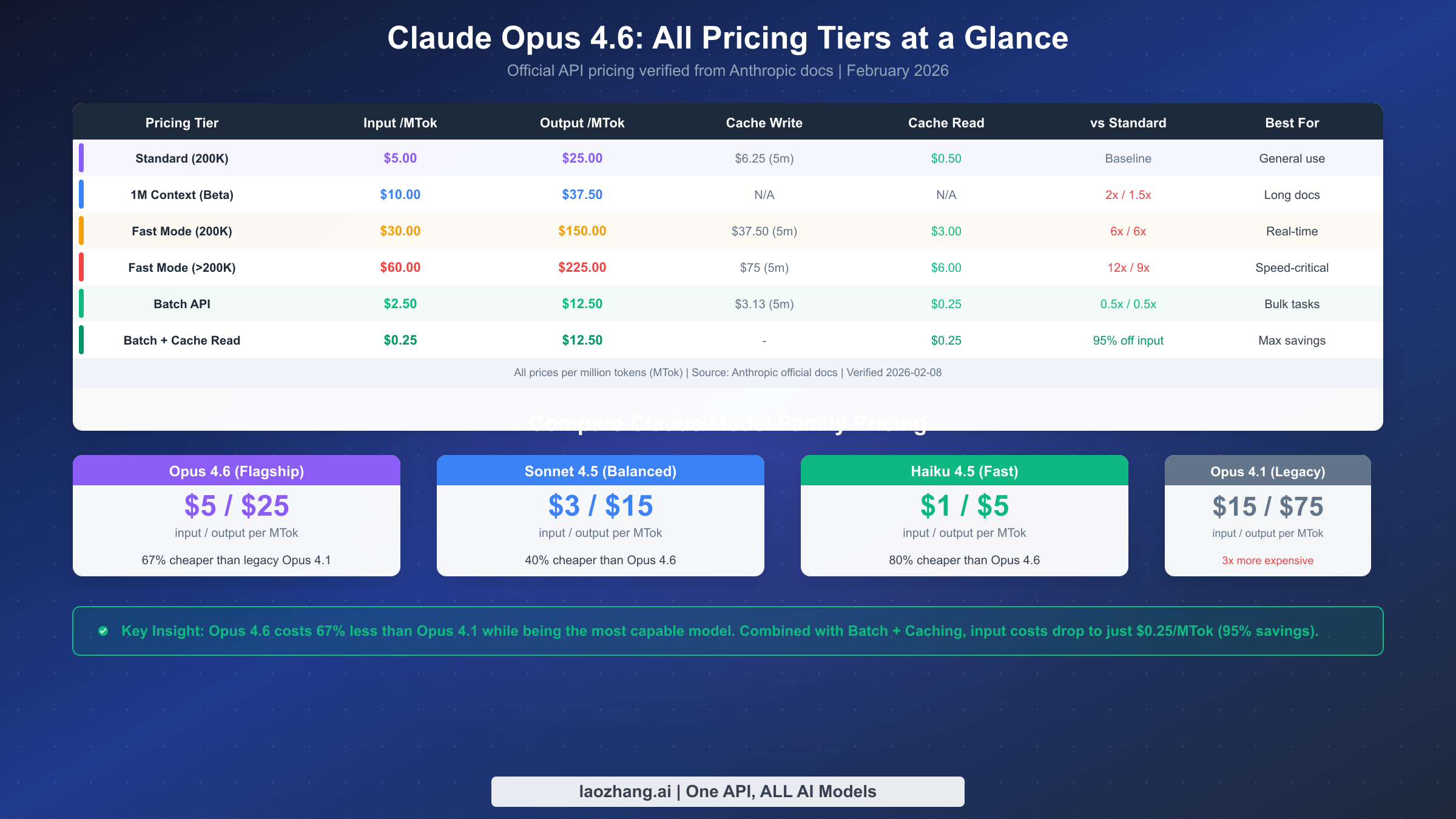
The foundation of Claude Opus 4.6 pricing is the standard per-token rate that applies to all synchronous API calls. Anthropic charges based on million-token units (MTok), with separate rates for input tokens, which include your system prompt, conversation history, and current message, and output tokens, which represent the model's generated response. The following table presents the complete pricing for all current Claude models available through the Anthropic API, providing the context needed to understand where Opus 4.6 sits within the broader product lineup and how its pricing compares to both cheaper alternatives and its own predecessor.
| Model | Input /MTok | Output /MTok | Cache Write (5 min) | Cache Read | Context Window |
|---|---|---|---|---|---|
| Claude Opus 4.6 | $5.00 | $25.00 | $6.25 | $0.50 | 200K (1M beta) |
| Claude Sonnet 4.5 | $3.00 | $15.00 | $3.75 | $0.30 | 200K |
| Claude Haiku 4.5 | $1.00 | $5.00 | $1.25 | $0.10 | 200K |
| Claude Opus 4.1 (legacy) | $15.00 | $75.00 | $18.75 | $1.50 | 200K |
Several important nuances apply beyond the base rates shown above. The extended 1M context window, currently in beta and restricted to Tier 4 organizations, triggers a premium rate structure when your total input exceeds the standard 200K token threshold. Under this extended context pricing, input tokens cost $10 per MTok and output tokens cost $37.50 per MTok. Critically, when the extended context pricing activates, all tokens in the request are charged at the premium rate, not just the tokens beyond the 200K boundary. This means a request with 250K input tokens would bill entirely at $10/MTok rather than billing the first 200K at $5 and the remaining 50K at $10. The 1-hour cache write option under extended context costs $10 per MTok, which is double the standard base rate, while cache reads remain at $0.50 per MTok regardless of context length.
Beyond token-based pricing, Anthropic applies additional charges for specialized features that your application may invoke. Web search functionality, which allows Claude to retrieve real-time information during conversations, costs $10 per 1,000 search queries. Code execution, a feature that enables Claude to run code in a sandboxed environment, provides 1,550 free hours per month per organization and then charges $0.05 per hour for usage beyond that threshold. For organizations requiring data residency guarantees, Anthropic offers a US-only deployment option that applies a 1.1x multiplier to all token categories, meaning standard Opus 4.6 input would cost $5.50 per MTok and output would cost $27.50 per MTok under data residency pricing. These supplementary costs are relatively minor for most use cases but can become significant at enterprise scale if web search or code execution features are heavily utilized. For a complete breakdown of rate limits and tier requirements that determine your access level, our guide on API rate limits and tier requirements covers the full tier system from Tier 1 through Tier 4.
The pricing structure also varies when Opus 4.6 is accessed through third-party cloud providers. Amazon Bedrock and Google Cloud Vertex AI both offer Claude Opus 4.6 as a hosted model, but their pricing may differ from the direct Anthropic API rates listed above. Organizations already committed to AWS or GCP infrastructure may find that the convenience of unified billing and existing security configurations justifies any price differential. However, for pure cost optimization, the direct Anthropic API with its full suite of discount mechanisms typically offers the lowest effective per-token cost, particularly when batch processing and prompt caching are fully leveraged.
Fast Mode Pricing: When the 6x Premium Makes Sense
Fast mode is a Research Preview feature currently exclusive to Claude Opus 4.6. It delivers significantly reduced latency for time-sensitive applications at a substantial cost premium. The pricing structure for fast mode doubles depending on context length: requests within the standard 200K context window cost $30 per million input tokens and $150 per million output tokens, which represents a 6x multiplier over the standard rates. For requests that utilize the extended context beyond 200K tokens, fast mode pricing escalates further to $60 per million input tokens and $225 per million output tokens. This places fast mode at between 6x and 12x the standard rate depending on context utilization, making it the most expensive way to access Claude Opus 4.6 by a significant margin.
The key question for any developer considering fast mode is whether the latency reduction justifies the 6x cost increase. The answer depends entirely on the economic value of response time in your specific application. For real-time chatbots serving paying customers, where every additional second of wait time increases abandonment rates, the premium may be easily justified. Customer-facing applications in financial services, healthcare triage, or live support scenarios where users are waiting for immediate responses represent strong candidates for fast mode deployment. Similarly, competitive programming platforms, real-time coding assistants, and interactive educational tools where perceived responsiveness directly affects user satisfaction and retention can benefit from the reduced latency.
However, fast mode carries important limitations that constrain its applicability. It is not available with the Batch API, meaning you cannot combine the speed benefits of fast mode with the 50% batch discount. It does stack with prompt caching though, which creates an interesting optimization: fast mode with cached prompt reads costs $3 per million input tokens and $150 per million output tokens, preserving the significant input savings from caching while maintaining the output premium. Fast mode also stacks with the data residency 1.1x multiplier, bringing those costs to $33 and $165 per million tokens for US-only deployment. No other major AI provider currently offers a comparable speed-premium tier: neither OpenAI's GPT-5.2 nor Google's Gemini 3 Pro provide an option to pay more for faster inference on the same model, making this a uniquely Anthropic capability that is valuable for latency-sensitive production workloads where Claude is the preferred model.
Calculating the ROI of fast mode requires understanding the specific economics of your application. Consider a customer support chatbot where each interaction generates approximately 2,000 output tokens. At standard pricing, that interaction costs $0.05 in output tokens. At fast mode pricing, the same interaction costs $0.30, an additional $0.25 per interaction. If faster responses reduce customer churn by even 0.1% across 10,000 monthly interactions for a SaaS product with $100 average revenue per customer, the $2,500 in additional fast mode costs could prevent $10,000 in churn losses. This type of calculation is highly application-specific, but the general principle holds: fast mode makes financial sense only when the value of reduced latency exceeds the 5x additional cost per request.
Subscription Plans Compared: Pro, Max, Team and Enterprise
For users who interact with Claude primarily through the conversational web interface or mobile applications rather than the API, Anthropic offers a tiered subscription model that provides access to Opus 4.6 without per-token billing. These subscriptions are designed for individual professionals, teams, and enterprises who need reliable access to Claude's capabilities without the complexity of managing API keys, monitoring token usage, and optimizing request patterns. The following table summarizes all current subscription tiers as of February 2026, including the recent price adjustment to the Max 5x plan.
| Plan | Monthly Cost | Opus 4.6 Access | Key Features |
|---|---|---|---|
| Free | $0 | No (Sonnet only) | Basic Sonnet access, limited messages |
| Claude Pro | $20/mo | Full access | Higher message limits, priority access |
| Claude Max 5x | $100/mo | Full access | 5x Pro usage volume, extended context |
| Claude Max 20x | $200/mo | Full access | 20x Pro usage volume, maximum capacity |
| Team | $25-150/seat/mo | Full access | Admin console, collaboration, SSO |
| Enterprise | Custom pricing | Full access | Dedicated support, SLA, custom deployment |
The Claude Pro plan at $20 per month represents the entry point for Opus 4.6 access through the subscription model. It provides a significantly higher message allowance than the free tier, priority access during peak demand periods, and the ability to use Opus 4.6 for complex reasoning tasks that the free tier's Sonnet-only access cannot handle. For individual users who primarily need Claude for writing, analysis, research, and general productivity tasks, Pro offers excellent value compared to API pricing. A user who sends approximately 50 messages per day with average-length conversations would likely spend considerably more than $20 per month at API rates, making the subscription a cost-effective choice for conversational use patterns.
The Max plans, recently restructured with the 5x tier dropping from $200 to $100 per month, target power users who consistently hit the Pro plan's usage limits. The 5x tier provides five times the message volume of Pro, while the 20x tier at $200 monthly offers twenty times the Pro allowance and represents the highest-capacity individual subscription Anthropic sells. Team plans start at $25 per seat per month and scale up to $150 per seat for larger deployments, adding administrative controls, usage analytics, workspace collaboration features, and single sign-on integration. Enterprise plans offer custom pricing that includes dedicated account management, service level agreements with guaranteed uptime and response time commitments, custom deployment options, and the ability to negotiate volume-based token pricing for organizations with substantial usage.
Choosing between subscription and API access comes down to your usage pattern and integration needs. Subscriptions are ideal for conversational use, where a human interacts directly with Claude through the web interface, desktop application, or mobile app. API access is necessary for programmatic integration, where your software sends requests to Claude and processes the responses automatically. Many organizations use both: subscriptions for their team's direct Claude usage and API access for their production applications. It is also worth noting that the Claude Pro subscription at $20 per month competes directly with Google's AI Pro plan at $19.99 per month and OpenAI's ChatGPT Plus at $20 per month. All three provide access to their respective flagship models at roughly equivalent subscription prices, making the choice between them more about model capability preferences and ecosystem integration than about subscription cost differences.
5 Proven Cost Optimization Strategies

The gap between what naive API usage costs and what an optimized implementation costs can be enormous. A developer who simply sends requests to the Opus 4.6 standard endpoint pays the full $5 input and $25 output rate on every single call. But by combining Anthropic's official discount mechanisms, the effective cost on input tokens can drop by up to 95%, and the overall bill can shrink by 80% or more depending on workload characteristics. The following five strategies are ranked by their impact and ease of implementation, with concrete calculations showing exactly how much each one saves. These are not theoretical possibilities but production-tested approaches that organizations running Claude at scale use to manage their AI infrastructure costs.
Strategy 1: Prompt Caching for 90% Input Savings. Prompt caching is the single most impactful cost optimization available for Claude Opus 4.6, particularly for applications that reuse a consistent system prompt or include substantial shared context across multiple requests. When you designate portions of your prompt for caching, the first request incurs a cache write cost of $6.25 per million tokens, which is 1.25x the standard input rate, with a 5-minute time-to-live. Every subsequent request within that 5-minute window that hits the cache pays only $0.50 per million cached tokens, which is just 10% of the standard input rate. For applications that need longer cache persistence, a 1-hour cache write option is available at $10 per million tokens, which is 2x the base rate, but still provides the same $0.50 read cost. Consider a coding assistant application with a 10,000-token system prompt that handles 100 requests per 5-minute window. Without caching, those 100 requests cost $0.05 in system prompt input alone. With caching, the first request pays $0.0625 for the cache write, and the remaining 99 requests pay only $0.00495 total in cache reads, a combined cost of roughly $0.067 compared to $0.50, which is an 87% savings on just the system prompt portion. For a deeper walkthrough of implementing prompt caching in production, our detailed prompt caching implementation guide covers the technical setup and best practices.
Strategy 2: Batch API for 50% Off Everything. The Batch API offers a straightforward 50% discount on all token categories for Opus 4.6. Standard input drops from $5.00 to $2.50 per million tokens, and standard output drops from $25.00 to $12.50 per million tokens. The tradeoff is that batch requests are processed asynchronously with results guaranteed within 24 hours rather than returned in real time. This makes batch processing ideal for workloads where immediate response is not required: content generation pipelines, data classification tasks, document summarization backlogs, bulk analysis jobs, and overnight processing runs. The 50% discount applies uniformly across input tokens, output tokens, cache writes, and cache reads, making it the simplest discount to calculate and apply.
Strategy 3: Stack Batch and Cache Discounts for 95% Input Savings. Anthropic officially supports combining the Batch API discount with prompt caching, and the savings compound dramatically. Starting from the $5.00 standard input rate, the Batch API reduces it to $2.50. Then, if the input tokens hit a prompt cache, the cache read discount further reduces the cost to $0.25 per million tokens. That is a 95% reduction from the standard rate, transforming what would be a $500 bill for 100 million input tokens into a $25 bill. This stacking works because the Batch API applies a 50% modifier to all token categories, and prompt caching independently applies its own read discount. The combination is particularly powerful for batch processing jobs that share common prompts or context, such as classifying thousands of documents against the same rubric or generating summaries for a large corpus using a consistent instruction set.
Strategy 4: Smart Model Routing Across the Claude Family. Not every request requires Opus 4.6's full capability. A well-architected system routes requests to the most cost-effective model that can handle each task: Haiku 4.5 at $1/$5 for simple classification, entity extraction, and short-form generation tasks; Sonnet 4.5 at $3/$15 for moderate-complexity tasks like summarization, translation, and standard conversation; and Opus 4.6 at $5/$25 reserved for complex reasoning, nuanced analysis, and tasks where maximum quality justifies the premium. An intelligent routing layer that sends 60% of requests to Haiku, 30% to Sonnet, and only 10% to Opus can reduce average per-request costs by 60% to 80% compared to sending everything to Opus, while maintaining high quality on the tasks that genuinely require it.
Strategy 5: Internal Abstraction and Request Governance. For teams working with multiple AI providers, the more durable optimization is to keep your own routing, logging, and billing analysis clean enough that you can compare providers without rebuilding the application. That gives you flexibility on model choice while keeping Claude access anchored to official billing and official account settings.
The following table illustrates what these optimization strategies mean in practice for organizations at different scales, comparing unoptimized standard API usage against a fully optimized approach combining batch processing, caching, and model routing.
| Usage Scale | Standard Cost | Optimized Cost | Monthly Savings |
|---|---|---|---|
| Solo developer (1K calls/day) | ~$150/mo | ~$30/mo | 80% ($120) |
| Startup (10K calls/day) | ~$1,500/mo | ~$250/mo | 83% ($1,250) |
| Enterprise (100K calls/day) | ~$15,000/mo | ~$2,000/mo | 87% ($13,000) |
Claude Opus 4.6 vs GPT-5.2 vs Gemini 3 Pro: Price Comparison
Choosing between the three major frontier AI models requires understanding not just their raw per-token prices but their complete cost profiles including discounts, context limits, and unique features. Claude Opus 4.6, OpenAI's GPT-5.2, and Google's Gemini 3 Pro represent the current state of the art from their respective companies, each with distinct pricing philosophies that favor different types of workloads. The raw numbers tell only part of the story because the discount mechanisms, context window pricing, and subscription options create very different effective costs depending on how you use each model. The following comparison uses verified pricing data as of February 2026 to provide an accurate side-by-side analysis.
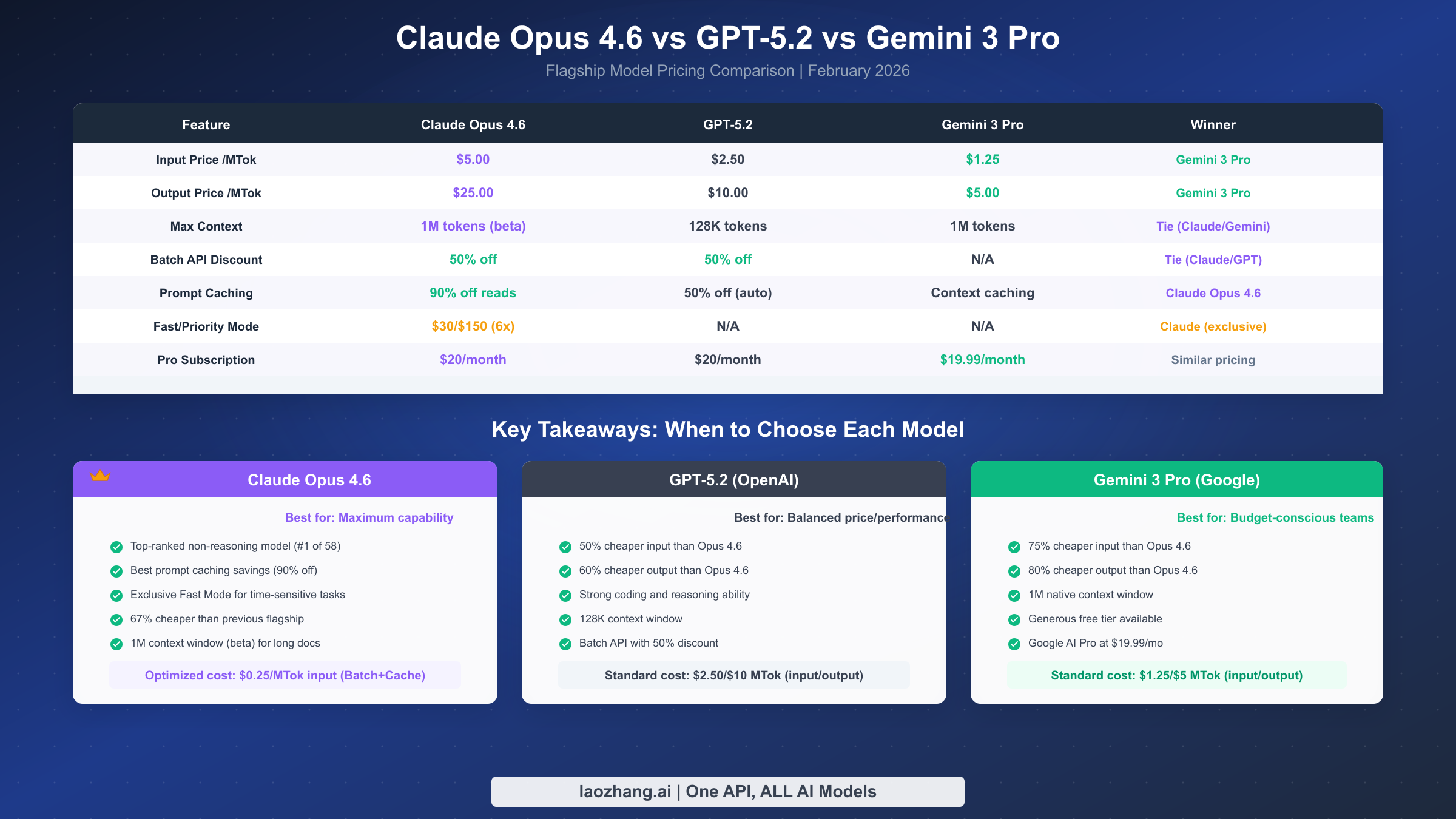
| Feature | Claude Opus 4.6 | GPT-5.2 | Gemini 3 Pro |
|---|---|---|---|
| Standard Input /MTok | $5.00 | $2.50 | $1.25 |
| Standard Output /MTok | $25.00 | $10.00 | $5.00 |
| Maximum Context Window | 1M tokens (beta) | 128K tokens | 1M tokens |
| Batch API Discount | 50% off all tokens | 50% off all tokens | Not available |
| Prompt Caching Savings | 90% on cached reads | 50% auto-caching | Context caching available |
| Fast/Priority Mode | $30/$150 MTok (6x) | Not available | Not available |
| Subscription Access | $20/mo (Claude Pro) | $20/mo (ChatGPT Plus) | $19.99/mo (AI Pro) |
At standard rates, Claude Opus 4.6 is the most expensive of the three flagship models by a meaningful margin. It costs 2x more than GPT-5.2 on input tokens and 2.5x more on output tokens. Compared to Gemini 3 Pro, the gap widens further: Opus costs 4x more on input and 5x more on output. For workloads that simply call the API at standard rates without any optimization, GPT-5.2 and especially Gemini 3 Pro offer substantially lower per-token costs. This price differential reflects Anthropic's positioning of Opus as the premium capability tier where users pay for the model's top-ranked benchmark performance and specialized features like fast mode.
However, the comparison shifts dramatically when discount mechanisms are factored in. Claude Opus 4.6 has the most aggressive caching discount of the three: cached reads cost just 10% of the base rate ($0.50/MTok), compared to GPT-5.2's 50% auto-caching discount and Gemini 3 Pro's context caching which varies by implementation. When Batch API and caching are combined, Claude Opus 4.6 achieves an input cost of $0.25 per million tokens, which is actually cheaper than Gemini 3 Pro's standard input rate of $1.25 per million tokens. This inversion means that for batch workloads with high cache hit rates, Claude Opus 4.6 can be the least expensive option despite having the highest standard rates. The fast mode feature is exclusive to Claude and has no equivalent from OpenAI or Google, giving Anthropic a unique offering for latency-sensitive applications willing to pay the 6x premium.
Choosing between these three models comes down to workload characteristics and optimization willingness. Select Claude Opus 4.6 when maximum model capability is the priority, when prompt caching is highly applicable to your use case, when fast mode addresses a genuine latency requirement, or when the 1M context beta provides essential capability for your document processing needs. Select GPT-5.2 when you need a balance between capability and cost at standard rates, when your workloads are moderately sized and do not benefit as heavily from aggressive caching, or when OpenAI's ecosystem of tools, plugins, and integrations is a factor. Select Gemini 3 Pro when budget is the dominant consideration, when you are processing high volumes at standard rates without batch or caching optimizations, when Google Cloud integration is important, or when the generous free tier for development and testing matters to your project economics.
A practical cost scenario illustrates the real-world implications of these differences. Consider a content generation pipeline that processes 10 million input tokens and generates 2 million output tokens per day, with a 70% cache hit rate on input. At standard rates without optimization, the daily cost would be $50 input plus $50 output for Claude Opus 4.6, compared to $25 input plus $20 output for GPT-5.2, and $12.50 input plus $10 output for Gemini 3 Pro. However, applying Claude's batch and caching optimizations transforms the calculation entirely: batch-cached input drops to $2.50, and batch output to $25, for a total daily cost of $27.50. That optimized Claude total is lower than unoptimized GPT-5.2 and only marginally higher than unoptimized Gemini, while delivering the strongest model capability in the market. The takeaway is that pricing comparisons are only meaningful when they account for the optimization tools each provider makes available, and Claude's optimization stack is currently the most aggressive of the three.
How to Access Claude Opus 4.6 at Lower Cost
There are four primary methods for accessing Claude Opus 4.6 at costs below the standard API rate, each suited to different use cases and organizational contexts. The optimal approach depends on whether you need programmatic API access or conversational usage, whether your workloads can tolerate batch processing latency, and whether you prefer direct integration with Anthropic or consolidated access through a multi-provider platform. Understanding all four options ensures you select the strategy that delivers the best cost-to-value ratio for your specific requirements, rather than defaulting to the most obvious but potentially most expensive path.
Method 1: Anthropic API with Batch Processing and Prompt Caching. The official Anthropic API offers the deepest discounts when both optimization mechanisms are combined. For workloads that can tolerate up to 24-hour delivery times and maintain high cache hit rates, the effective input cost drops to $0.25 per million tokens, a 95% reduction from the $5.00 standard rate. Output costs drop to $12.50 per million tokens through batch processing alone. This method requires direct Anthropic API access, which means setting up an Anthropic account, adding payment information, reaching at least Tier 1 through usage history, and implementing the batch and caching APIs in your application code. The technical overhead is moderate but the savings are substantial for organizations with predictable, high-volume workloads.
Method 2: Claude Pro Subscription for Conversational Access. At $20 per month, the Claude Pro subscription provides access to Opus 4.6 through Anthropic's web interface, desktop application, and mobile apps without any per-token charges. For users whose primary interaction with Claude is conversational, writing assistance, analysis, brainstorming, research, and general productivity tasks, the Pro subscription typically offers better value than API access. A user who exchanges the equivalent of 5 million tokens per month in conversation would pay hundreds of dollars at API rates but only $20 through the subscription. The limitation is that subscription access does not support programmatic integration, so it cannot be used for automated workflows, production applications, or batch processing.
Method 3: Intelligent Model Routing Starting with Lower Tiers. Rather than changing access providers, design your application so that simple tasks are routed to cheaper models first and only the hardest work escalates to Opus. That usually captures most of the cost benefit teams want while keeping account setup, billing, and support paths aligned with the official provider.
Method 4: Intelligent Model Routing Starting with Lower Tiers. Rather than defaulting to Opus 4.6 for every request, implement a routing layer that starts with Haiku 4.5 at $1 per million input tokens and escalates to Sonnet 4.5 or Opus 4.6 only when the task complexity warrants it. This approach requires upfront investment in building classification logic that determines request complexity, but the long-term savings are substantial. A well-calibrated router that sends 60% of traffic to Haiku, 30% to Sonnet, and only 10% to Opus can achieve average per-request costs that are 70% lower than sending everything to Opus while maintaining equivalent output quality on the tasks where Opus's additional capability actually matters. The routing logic itself can even be powered by a fast, cheap Haiku classification call, adding minimal overhead to the request pipeline. Many production deployments implement this as a two-stage pipeline: the first stage uses Haiku to classify the incoming request into complexity tiers based on task type, input length, and required reasoning depth, and the second stage routes the request to the appropriate model. This architecture adds only pennies in classification cost per request while potentially saving dollars on the downstream model invocation, making it one of the highest-ROI engineering investments for teams running Claude at scale across diverse use cases.
Frequently Asked Questions
Is there a free tier for Claude Opus 4.6 API access? Anthropic does not offer a free API tier for Claude Opus 4.6. The free plan available at claude.ai provides limited conversational access using Claude Sonnet only, with no Opus capability. To access Opus 4.6 through the API, you need a funded Anthropic account with a minimum prepayment depending on your tier level. However, the Claude Pro subscription at $20 per month provides access to Opus 4.6 through the conversational interface without per-token billing, which serves as the most affordable entry point for individual users who do not need programmatic API access. New Anthropic API accounts typically receive a small credit allocation for initial testing, but this is subject to change and should not be relied upon as a sustained free access mechanism. For developers who want to explore Claude capabilities before committing to API spending, the Pro subscription offers the lowest-risk way to evaluate Opus 4.6 on real tasks.
How does Claude API billing work? Anthropic bills Claude API usage on a pay-as-you-go basis, charging per million tokens processed across both input and output. Input tokens include everything you send to the model: your system prompt, conversation history, uploaded documents, and the current user message. Output tokens represent everything the model generates in response. Billing is calculated at the per-million-token rates specified for each model and access tier, with charges accumulated and applied to your prepaid account balance. When your balance runs low, you can configure automatic top-up to avoid service interruption. Batch API requests are billed at 50% of the standard rate, and prompt cache reads are billed at the reduced cache read rate. All charges appear in the Anthropic dashboard with detailed breakdowns by model, token type, and time period, giving you full visibility into your spending patterns.
Can I use prompt caching with the Batch API? Yes, prompt caching and Batch API discounts stack together, and this combination produces the deepest possible discount on Claude Opus 4.6 input tokens. When you submit a batch request with cached prompts, the cache read cost is calculated using the Batch API's 50% discount on top of the already reduced cache read rate. Specifically, standard cache reads cost $0.50 per million tokens, and applying the 50% batch discount brings this down to $0.25 per million tokens. This represents a 95% reduction from the standard $5.00 input rate. The cache write cost also benefits from the batch discount: a 5-minute cache write costs $3.125 per million tokens in batch mode instead of the standard $6.25. This stacking is officially supported by Anthropic and represents the optimal cost configuration for high-volume workloads that share common prompts.
What is the 1M context beta and how do I access it? The 1M token context window for Claude Opus 4.6 is a beta feature available exclusively to organizations that have reached Tier 4 status with Anthropic. Tier 4 requires significant usage history and spending commitments, placing this feature firmly in the enterprise category. When activated, the extended context allows you to send inputs exceeding the standard 200K token limit up to 1 million tokens, which is valuable for processing very large documents, extensive codebases, or lengthy conversation histories. The critical pricing detail is that when your input exceeds 200K tokens, the premium rate of $10 per million input tokens and $37.50 per million output tokens applies to all tokens in the request, not just the tokens beyond the 200K threshold. This means a 300K-token request would be billed entirely at the $10 rate rather than splitting between standard and premium rates, making it important to consider whether your use case genuinely requires the extended context or whether chunking strategies could keep individual requests within the standard 200K window at standard pricing.
Is Claude Opus 4.6 worth the premium over GPT-5.2? The value proposition of Opus 4.6 versus GPT-5.2 depends on three factors: the complexity of your tasks, your optimization strategy, and whether you need Opus-exclusive features. At standard rates, GPT-5.2 costs roughly 50-60% less than Opus 4.6, making it the clear budget choice for straightforward workloads. However, Opus 4.6 holds the top benchmark ranking among non-reasoning models and offers two exclusive features that have no GPT-5.2 equivalent: fast mode for latency-critical applications and the most aggressive prompt caching discount in the industry at 90% versus GPT-5.2's 50%. For organizations that can leverage prompt caching heavily, the effective cost gap between the two models narrows substantially, and for batch-plus-cache workloads, Opus input actually becomes cheaper than GPT-5.2 standard input. Choose Opus when you need maximum capability or when caching and batch processing are central to your architecture. Choose GPT-5.2 when standard-rate simplicity and lower baseline costs are priorities.
How do I enable Fast Mode for Claude Opus 4.6? Fast mode is available as a Research Preview feature, meaning its availability and pricing may change as Anthropic evaluates its performance and demand. To use fast mode, you set the appropriate parameter in your API request when calling the Opus 4.6 model. The specific implementation involves adding a speed tier configuration to your API call, which routes your request to optimized infrastructure with lower latency. Fast mode is compatible with prompt caching but not with the Batch API, and it applies the data residency multiplier if US-only processing is enabled. Because it is in Research Preview status, Anthropic may adjust the 6x pricing premium, modify availability, or change the feature's behavior based on operational experience. Monitor the Anthropic changelog and API documentation for updates to fast mode's status and any pricing adjustments that may occur as it transitions from preview to general availability.
What happens if I exceed my prepaid balance? When your Anthropic account balance reaches zero, API requests will begin failing with authentication errors rather than being processed and billed retroactively. Anthropic provides balance monitoring through the API dashboard, and you can configure automatic top-up thresholds that trigger a credit card charge when your balance drops below a specified amount. For production applications, setting up auto-top-up is strongly recommended to prevent service interruptions. Enterprise customers on custom plans may have different billing arrangements including net-30 invoicing, where charges accumulate and are billed monthly rather than drawn from a prepaid balance. Understanding your billing configuration is important for maintaining uninterrupted API access, particularly for applications serving end users who would be affected by unexpected downtime.