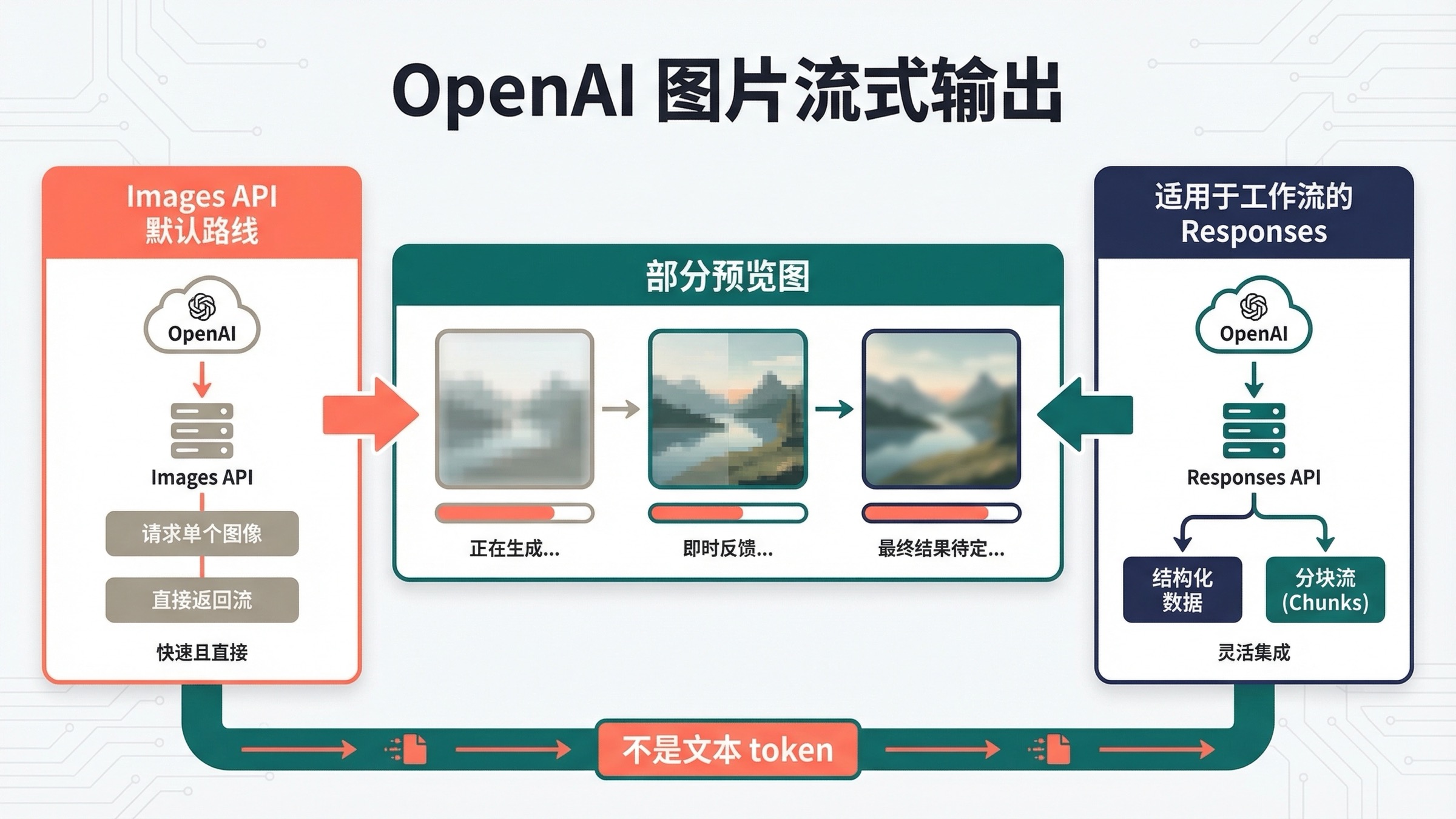
截至 2026 年 3 月 23 日,OpenAI 图片生成现在确实支持流式输出,但当前 streaming 的含义不是图像模型像文本模型那样按 token 连续吐内容,而是在生成过程中返回一小组“部分预览图”。 这件事听起来像细节,实际上会直接决定你的 UI 该怎么承诺、代码该从哪条路线开始,以及你会不会把官方文档误读成“前后矛盾”。
如果你做的是直接图片功能,当前最稳的默认路线很明确:先用 Images API,从 client.images.generate() 流出部分预览图。 如果图片生成只是更大助手、多模态流程或 agent workflow 里的一个工具,再改走 Responses API。多数页面的问题不是代码错,而是没有先把这一步讲清楚。
这个关键词一直让人觉得难,核心也在这里。当前 image generation guide 明确写了 Responses API 和 Image API 都支持 streaming image generation;但当前 GPT Image 1.5 模型页 的特性表里又仍然写着 Streaming: Not supported。如果你先看到模型页,再看到指南,就很容易误判成“OpenAI 图片 API 根本不能 stream”。这篇文章的任务,就是先把这层误解拆掉。
要点速览
- 现在确实支持 streaming,但当前流出来的是部分预览图,不是文本式 token stream。
- 直接图片功能先用 Images API,这是当前最短也最稳的默认路线。
- Responses API 更适合“图片生成只是更大工作流里一个工具”的场景。
- 两条路线的事件名不同:Images API 用
image_generation.partial_image,Responses API 用response.image_generation_call.partial_image。 - OpenAI 当前文档还明确提醒:
partial_images可以设成0到3,但即使你请求了 2 或 3,也不保证一定会收到完整数量。
先说结论:现在的 OpenAI 图片 streaming 到底指什么
这个搜索词最容易踩坑的地方,是把“图片 streaming”自动套用成文本生成的心智模型。开发者问这个问题时,通常真正想确认的是两件事:
- 我能不能在最终图片完成前,先给用户显示一些渐进式视觉反馈?
- 图片模型会不会像文本模型那样,持续输出一串小块直到完成?
OpenAI 当前文档给出的答案其实是:第一件事可以,第二件事不是现在这套图片 API 的语义。
现行的图片生成指南里,OpenAI 把 streaming 定义成 partial images。你可以请求一小组预览图,让用户在最终图完成前先看到进度感更强的可视反馈。指南还写得很清楚:partial_images 可以是 0 到 3,如果最终图片生成得太快,你可能不会收到你请求的全部预览图。
这意味着正确的产品预期不是“我可以拿到一条稳定的、像文本 token 一样的图像流”,而是“我可以拿到少量 preview images,让等待过程不那么黑盒”。这已经很有用,尤其适合需要让用户感受到进度的图片产品,但它和很多人脑中的“实时逐帧生成”并不是一回事。
也正因为如此,路线选择必须早点做。如果你的产品只是输入 prompt,收几个预览图,再拿到最终图,直接 Images API 就够了。如果你的产品需要会话状态、工具编排,或者需要主模型先决定何时调用图片生成,再去走 Responses API。两条路都对,但它们并不是同一个默认答案。
Images API 和 Responses API:先选对流式输出路线
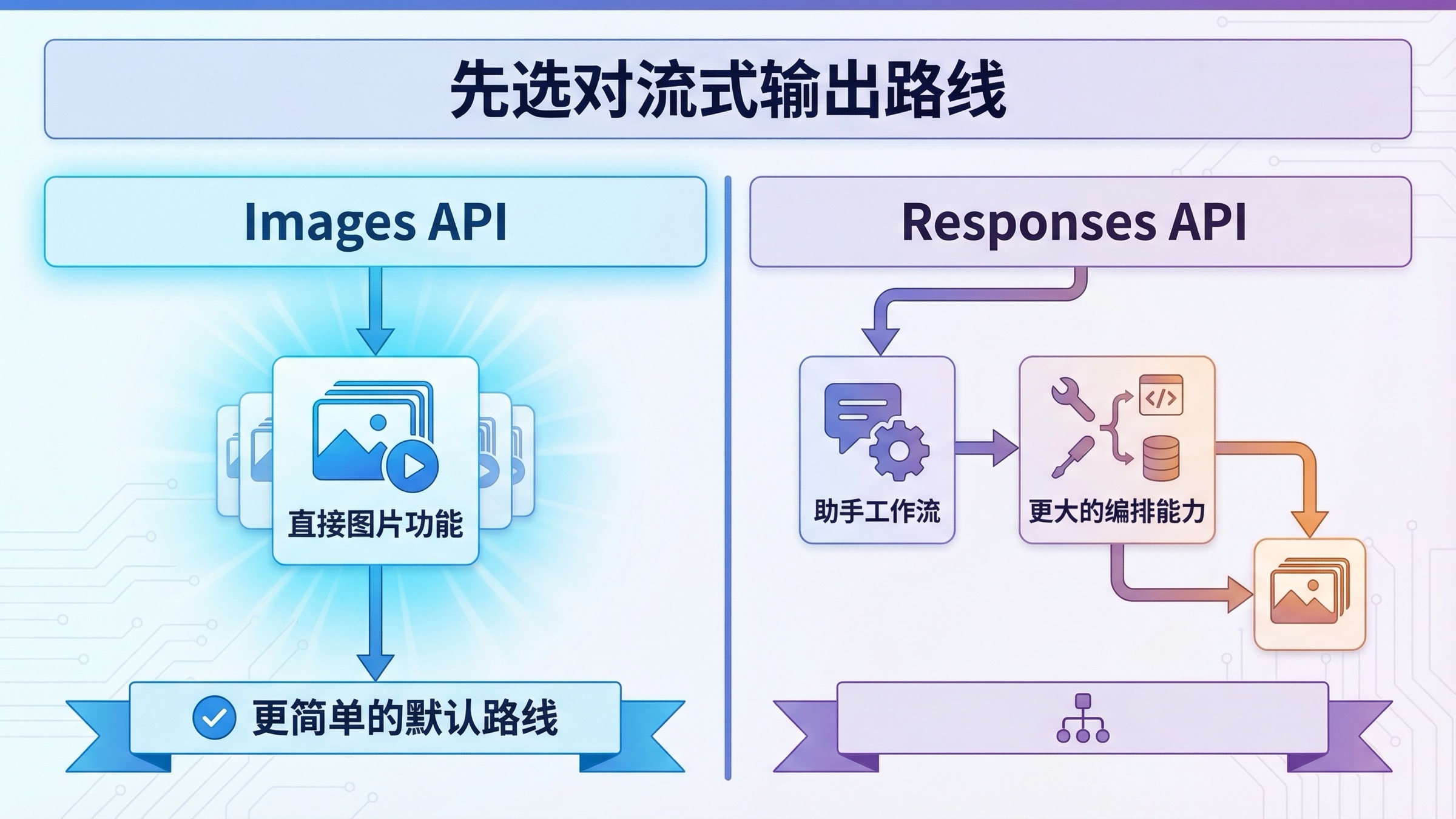
一旦你不再问“哪个接口更现代”,而是改问“我现在做的到底是哪种产品任务”,这个关键词会一下子简单很多。
| 场景 | 更合适的默认路线 | 原因 |
|---|---|---|
| 你做的是直接图片功能,要预览图和最终图 | Images API | 请求形态更直接、模型选择更明确、事件处理也更简单 |
| 图片生成只是更大助手或多模态流程的一步 | Responses API | 图片生成可以作为工具挂在更大的 workflow 里 |
| 你只想先证明 streaming 在自己账户上能跑通 | Images API | 变量更少,更容易先定位访问问题还是事件处理问题 |
| 你需要主模型改写 prompt 或协调其他工具 | Responses API | 这时工具式调用更自然 |
| 你第一次碰到这类文档矛盾 | 先跑 Images API,再决定要不要切 Responses | 可以先排掉一整层不必要的编排复杂度 |
实用规则可以压缩成一句话:如果图片生成本身就是功能主体,就先走 Images API;如果图片生成只是更大工作流中的一个工具,再切到 Responses API。
当前 Images and vision guide 其实也在支持这种分工。它写的是“可以用 Image API,也可以用 Responses API 来生成或编辑图片”,同时 Responses 示例又是用 gpt-4.1-mini 这类主模型挂 image_generation 工具。这说明在 OpenAI 当前的设计里,Responses 路线更像“主模型编排 + 图片工具”,而不是“图片模型自己承担一切”。
最快跑通的路线:先用 Images API 流式预览
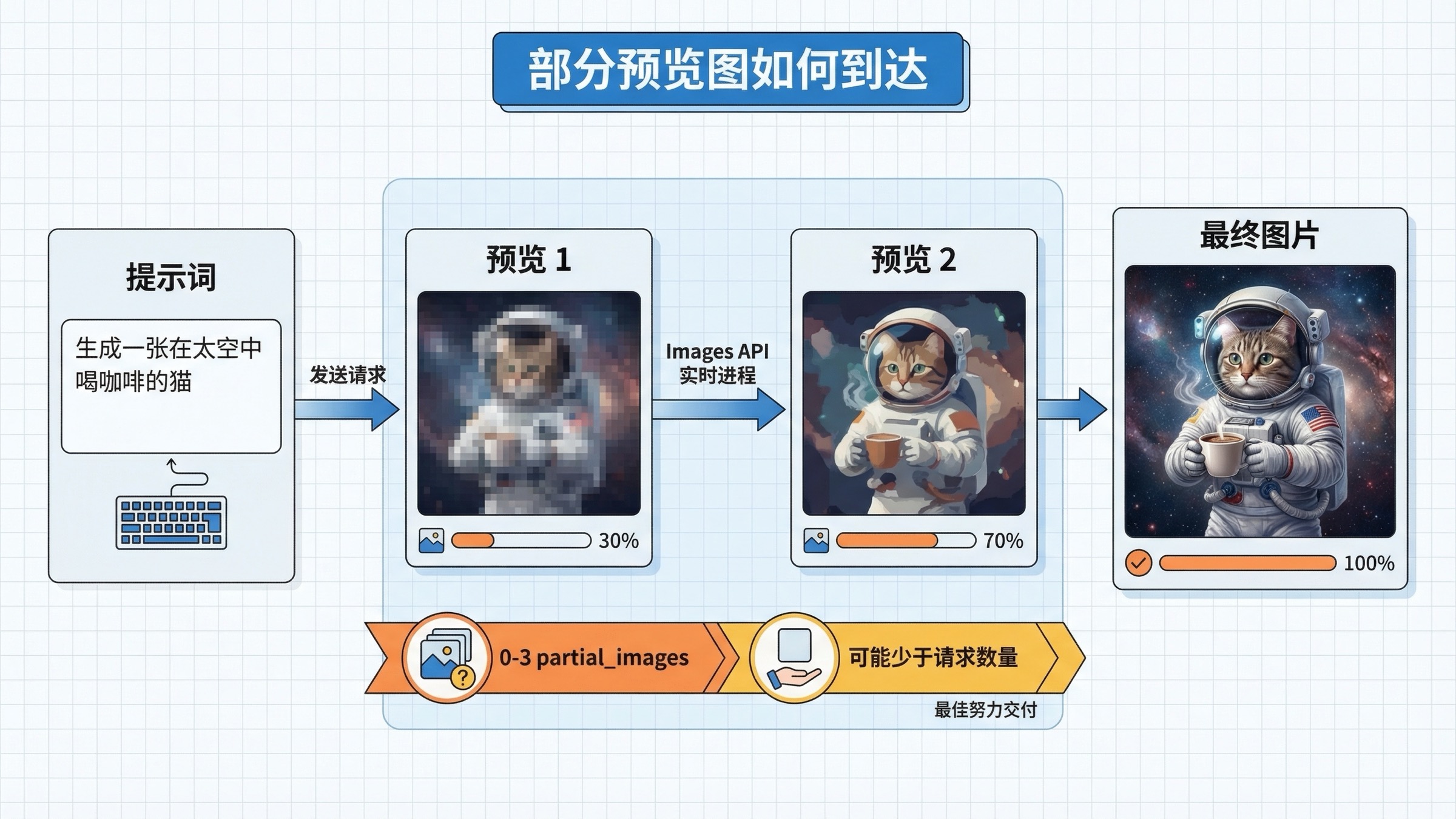
如果你的目标只是尽快验证“现在到底能不能 stream”,那 Images API 仍然是最好的起点。当前官方指南给出的直接模式非常清楚:gpt-image-1.5、stream: true、partial_images: 2。这也是我最推荐先跑通的一条线路。
JavaScript 示例:
jsimport fs from "fs"; import OpenAI from "openai"; const client = new OpenAI({ apiKey: process.env.OPENAI_API_KEY, }); const stream = await client.images.generate({ model: "gpt-image-1.5", prompt: "Create a clean editorial illustration of a camera drone hovering over a bright city skyline at sunrise", stream: true, partial_images: 2, }); for await (const event of stream) { if (event.type === "image_generation.partial_image") { const index = event.partial_image_index; const imageBytes = Buffer.from(event.b64_json, "base64"); fs.writeFileSync(`preview-${index}.png`, imageBytes); } }
Python 示例:
pythonfrom openai import OpenAI import base64 client = OpenAI() stream = client.images.generate( model="gpt-image-1.5", prompt="Create a clean editorial illustration of a camera drone hovering over a bright city skyline at sunrise", stream=True, partial_images=2, ) for event in stream: if event.type == "image_generation.partial_image": index = event.partial_image_index image_bytes = base64.b64decode(event.b64_json) with open(f"preview-{index}.png", "wb") as f: f.write(image_bytes)
这条路线最适合作为第一步,有三个原因。
第一,它验证的是最少变量的路径。你明确选当前图片模型,明确请求少量预览图,明确监听一个图片专用事件。对于“我这边到底能不能 stream”这种问题,这是最干净的排查方式。
第二,它让调试树更清晰。如果预览图没有来,你可以先查账户访问、模型选择、事件处理,而不用同时怀疑是不是更大的 Responses workflow 本身出了问题。当前 GPT Image 1.5 模型页仍然写着 Free not supported,并给出 Tier 1 从 100,000 TPM 和 5 IPM 起步 的图片限制,所以在怪 SDK 之前,先确认访问前提仍然值得做。
第三,它会逼你用对 UI 预期。当前指南已经写明:你可以请求 0 到 3 张 partial images,但可能收不到全部数量。换句话说,这是一种“让等待过程更可视化”的 best-effort preview,而不是精确帧数承诺。你的产品如果接受这个语义,Images API 往往已经足够。
如果你后面还要把整个 OpenAI 图片 API 路线讲给团队,可以继续看中文的 OpenAI Image API 教程。那篇更适合解释整条调用面,而这篇故意把范围收窄在 streaming 行为本身。
什么时候 Responses API 才是更好的 streaming 路线
Responses 路线不是错,只是不是这个关键词最应该默认给出的第一答案。
当前官方指南给出的 Responses 流式图片生成写法,大致是这样的:
jsimport fs from "fs"; import OpenAI from "openai"; const client = new OpenAI({ apiKey: process.env.OPENAI_API_KEY, }); const stream = await client.responses.create({ model: "gpt-5", input: "Create a transparent sticker-style icon of a paper airplane for a travel app", stream: true, tools: [{ type: "image_generation", partial_images: 2 }], }); for await (const event of stream) { if (event.type === "response.image_generation_call.partial_image") { const index = event.partial_image_index; const imageBytes = Buffer.from(event.partial_image_b64, "base64"); fs.writeFileSync(`preview-${index}.png`, imageBytes); } }
这条路线更适合下面这些场景:
- 你的助手有时候返回文本,有时候返回图片
- 你需要主模型先决定什么时候该调用图片生成
- 你希望图片生成和其他工具共享同一套会话或多步工作流
Responses 还有一个额外优势:当前官方指南里,主模型可以对图片生成调用里的 prompt 进行修订,你还能在完成后的 image generation call 里看到 revised_prompt。这说明当“主模型编排”本身就是产品价值时,Responses 路线确实更自然。
但这里有一个常见误区必须挡住:不要因为最后输出的是图片,就把 gpt-image-1.5 塞进 Responses 顶层 model 字段。 当前文档给出的心智模型,是 gpt-4.1、gpt-5 这样的主模型加上托管的 image_generation 工具。如果你把这层关系理解反了,最后调试的往往不是 streaming,而是路由本身。
所以更准确的结论不是“Responses 更新,所以都用它”,而是:当编排是重点时用 Responses,当图片功能本身是重点时先用 Images API。
为什么官方文档看起来互相矛盾

这正是这个关键词存在的真正原因,也是多数页面仍然没有讲透的地方。
当前 image generation guide 明确写着 Responses API 和 Image API 都支持 streaming image generation,并且给出了两条路线各自的事件循环示例。
但当前 GPT Image 1.5 模型页 的特性表里,又仍然写着 Streaming: Not supported。
同时,GPT-5 模型页 又写着 streaming is supported,并且说明 image_generation 工具在 Responses API 里是 supported。
把这三页放在一起看,其实可以得到一个比较干净的解释:
- 图片生成指南讲的是API 层面的 partial-preview streaming 行为
- GPT-5 页面讲的是主模型在 Responses 里的 streaming 与工具支持
- GPT Image 模型卡并不是在承诺“图片模型本身像文本模型那样流式输出 token”
这也和 OpenAI 真正发布出来的示例是一致的。如果你的问题是“我的应用能不能在最终图片完成前先收到预览图”,答案是 可以。如果你的问题是“图片模型会不会像文本模型一样一小段一小段连续往外流”,那当前官方图片指南给出的答案并不是这个语义。
这同时也解释了为什么很多旧教程到现在还在误导。OpenAI 在 2025 年 4 月 23 日 发布 gpt-image-1 API 时,官方博文里写的是“先上 Images API,Responses support coming soon”。如果你的认知停留在那个时间点,就很容易继续沿用“图片只能走 Images API,而且 streaming 不是现在的重点”这种旧路线。今天的文档已经往前走了,但搜索结果和旧页面不会自动一起更新。
最常见的实现误区
这类问题大多数不是深层算法问题,而是路线、命名和预期的问题。
1. 事件名抄错了
Images API 当前监听的是 image_generation.partial_image。Responses API 当前监听的是 response.image_generation_call.partial_image。它们不是一回事。如果你把一条路线的事件名带到另一条路线里,最后看起来像“没 stream”,其实只是事件处理写错了。
2. 直接图片功能却一上来走 Responses
如果你的产品只是 prompt、几张预览图、一个最终结果,那么 Images API 会给你更干净的第一成功路径。Responses 并不是不能做,而是它给你加了一层没必要过早承担的编排复杂度。
3. 把 partial_images 当成固定帧数承诺
当前指南已经说得很清楚:partial_images 可以是 0 到 3,但实际可能少于你请求的数量。你应该把它当成 best-effort 进度信号,而不是“我请求 2,就一定能拿到 2 帧”的协议。
4. 把模型卡和指南当成同一层含义
它们不是同一层。指南讲的是 API 路径怎么返回预览图;模型卡讲的是更泛化的模型特性表。如果把两者硬压成一个意思,要么你会低估当前支持,要么你会高估它真正保证的行为。
5. 访问前提没确认,就先开始改代码
当前 GPT Image 1.5 模型页仍然写着 Free 不支持图片访问,发布博文也仍然提醒一部分开发者可能需要组织验证。如果你第一条流式测试没有任何结果,不要马上认定是事件循环有 bug。先确认组织、tier、模型访问是否真的已经就绪。
6. 还在沿用 gpt-image-1 时代的默认假设
2026 年的新工作默认应该锚定在 gpt-image-1.5,而不是继续沿用 gpt-image-1 刚上线时的 mental model。如果你下一步还要梳理当前 OpenAI 图片模型线路,可以看英文 fallback 的 OpenAI image generation API models guide。
FAQ
我能不能强制拿到固定两张预览图?
不能。OpenAI 当前指南写的是 partial_images 可以设成 0 到 3,但如果最终图生成得更快,你可能收不到完整数量。正确做法是把它当成 best-effort preview,而不是固定帧协议。
这个问题应该直接去看 Realtime API 吗?
至少就当前官方图片指南来说,不应该把 Realtime 当成这个关键词的默认答案。OpenAI 现在明确给出的图片 streaming 路线,是 Images API 和 Responses API 上的 partial-preview 事件。
到底该用哪个模型名?
如果你走的是直接 Images API 路线,先用 gpt-image-1.5。如果你走的是 Responses 路线,就按当前文档习惯,把 gpt-4.1 或 gpt-5 这类主模型放在顶层 model 字段,再挂 image_generation 工具。
最后建议
如果你只记住一句话,就记这句:现在 OpenAI 图片生成的 streaming,指的是“部分预览图流式返回”,而不是图像模型像文本那样按 token 连续输出;对大多数直接图片功能来说,Images API 仍然是最稳的默认起点。
这个答案比单纯说一句“能 stream”更有用,因为它会直接告诉你下一步该做什么。先用 gpt-image-1.5 在 Images API 上跑通一条最小流式请求,确认你的 UI 能正确处理少量 best-effort 预览图。只有当这条路线已经跑通,而且产品真的需要更大的编排能力时,再切到 Responses API。
如果你接下来要补的是整条图片调用面,可以继续看中文的 OpenAI Image API 教程;如果你真正卡住的是图片编辑路线,而不是流式预览,可以看中文的 OpenAI 图片编辑 API 指南。