
如果你要找截至 2026 年 3 月 29 日仍然能直接跑通的 gpt-image-1-mini 示例,默认顺序应该是:单次生成先走 Images API,直接编辑也先走 Images API,只有真的需要多轮图像工作流时才切到 Responses。 这是当前官方文档给出的最稳判断,但搜索结果里最常缺的,恰恰也是这层“先抄哪一个”的路线判断。
这个顺序并不是经验主义。OpenAI 当前的 image generation guide 仍然明确区分了两条路线:如果你只需要一次生成或一次编辑,Image API 是更直接的默认值;如果图像生成要嵌进对话、状态延续或多步骤流程,才考虑 Responses API。而当前 gpt-image-1-mini 模型页 也把 mini 描述成 GPT Image 1 的成本优化路线,不是“一切图像任务的最佳默认值”。
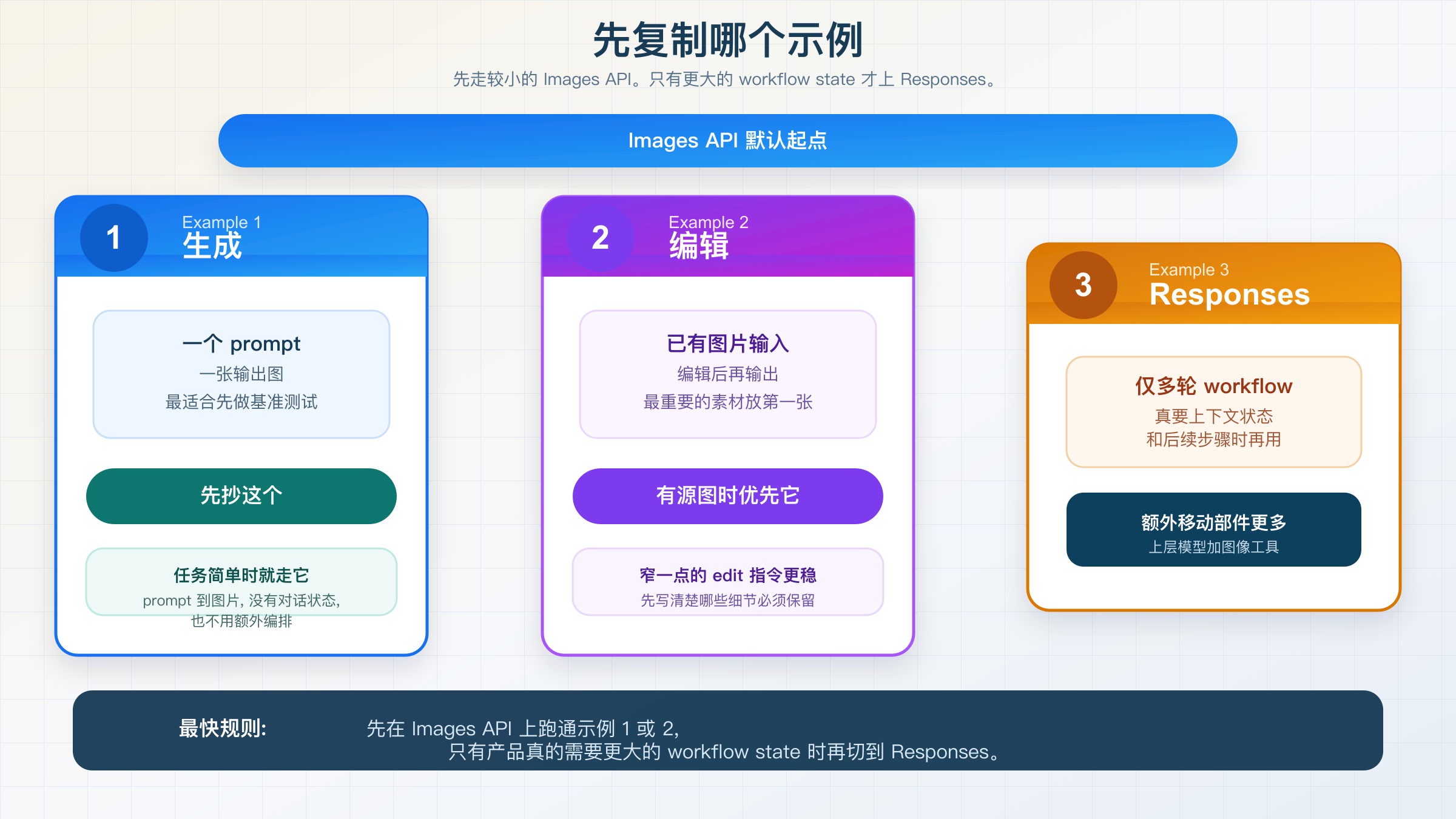
所以,这个关键词真正需要的不是一页更花哨的 prompt 图库,而是一个更诚实的起步顺序。只做 prompt-to-image,就先抄 Example 1。你已经有源图,只想做直接编辑,就先抄 Example 2。你的产品真的需要跨多轮迭代、让图像留在上下文里,再跳到 Example 3。其他优化,放到跑通之后。
最值得先复制的 3 个 gpt-image-1-mini 示例
这个 exact query 的第一页,混杂了模型目录、示例页和第三方网关 playground。它们最大的问题不是“代码一定错”,而是几乎都不告诉你 现在应该先复制哪个模式。下面这张表,就是这篇文章最短也最有用的答案。
| 如果你要做的是… | 先复制哪个示例 | API 路线 | 为什么先从这里开始 |
|---|---|---|---|
| 一个 prompt 生成一张图片 | Example 1 | Images API | 路径最短,最容易先证明 mini 这条线是不是适合你 |
| 在已有图片上做直接编辑 | Example 2 | Images API | 官方仍把单次编辑放在 Images API,而且 mini 的保真细节在这里最关键 |
| 在多轮对话里反复改图 | Example 3 | Responses API | 只有当上下文状态和更大的工作流真的重要时,这层抽象才值得加上去 |
在开始复制代码前,还有一个小但很实用的判断点。当前 tool guide 提醒,图像 prompt 往往更适合用 draw、edit 这种直接动词开头。看起来只是写法差异,但它能帮你快速识别哪些“示例页”只是把一段代码贴出来,哪些页面是真的在帮你提高第一次成功率。
如果你其实想找的是更宽泛的 OpenAI 图像 API 示例,而不是 mini 专题,下一篇更合适的是 OpenAI 图像生成 API 示例。这篇文章刻意更窄,只回答 mini 这一支现在该怎么抄。
示例 1:用 Images API 做单次图像生成
最适合先跑通的 mini 示例,通常就是最无聊的那个。你发一个 prompt,拿回 base64 图像字节,解码保存到本地。没有对话状态,没有额外工具层,也没有“是不是选错接口”的歧义。
jsimport fs from "fs"; import OpenAI from "openai"; const client = new OpenAI({ apiKey: process.env.OPENAI_API_KEY, }); const result = await client.images.generate({ model: "gpt-image-1-mini", prompt: "Draw a clean editorial illustration of a robot street photographer in bright morning light.", size: "1024x1024", quality: "medium", output_format: "jpeg", output_compression: 80, }); const imageBase64 = result.data[0].b64_json; fs.writeFileSync( "gpt-image-1-mini-generate.jpg", Buffer.from(imageBase64, "base64") );
Python 版本同样很直接:
pythonfrom openai import OpenAI import base64 client = OpenAI() result = client.images.generate( model="gpt-image-1-mini", prompt="Draw a clean editorial illustration of a robot street photographer in bright morning light.", size="1024x1024", quality="medium", output_format="jpeg", output_compression=80, ) image_base64 = result.data[0].b64_json with open("gpt-image-1-mini-generate.jpg", "wb") as f: f.write(base64.b64decode(image_base64))
raw cURL 形态也一样简单:
bashcurl https://api.openai.com/v1/images/generations \ -H "Authorization: Bearer $OPENAI_API_KEY" \ -H "Content-Type: application/json" \ -d '{ "model": "gpt-image-1-mini", "prompt": "Draw a clean editorial illustration of a robot street photographer in bright morning light.", "size": "1024x1024", "quality": "medium", "output_format": "jpeg", "output_compression": 80 }' \ | jq -r '.data[0].b64_json' \ | base64 --decode > gpt-image-1-mini-generate.jpg
这个示例之所以应该排在第一,不只是因为它短,而是因为它和官方的当前路线判断完全一致。OpenAI 现在仍然把“一个 prompt,完成一次生成”的任务放在 Image API 上。如果你只是想确认 mini 这条成本优先路线是否足够,这也是最容易先得到明确结论的方式。
另外,quality 往往是你第一个真正该调的成本旋钮。当前 mini 模型页列出的 1024x1024 输出价格是 low $0.005、medium $0.011、high $0.036。这个差距已经足够大,不值得一上来就因为“更稳”而默认 high。如果你的工作是草图、低风险变体或便宜的 prompt benchmark,先从 medium 起步更合理。
| 参数 | 更安全的起始值 | 什么时候再改 |
|---|---|---|
size | 1024x1024 | 你已经确认产品需要别的长宽比 |
quality | medium | 你测过 low 不够,或能证明 high 真能省返工 |
output_format | jpeg | 下游流程明确需要别的格式 |
output_compression | 80 | 体积或压缩痕迹成了真实问题 |
很多“示例页”漏掉的,正是这张表背后的思路。强示例不是参数越多越好,而是先给你一个稳定基线,让你知道后面每一步到底在换什么。
示例 2:用 input_fidelity 做直接图像编辑
如果你手里已经有源图,只是想在现有图片上修改,那就继续留在 Images API。当前文档仍把这种“单次编辑”放在更直接的图像接口里,而不是要求你先切到 Responses。
jsimport fs from "fs"; import OpenAI from "openai"; const client = new OpenAI({ apiKey: process.env.OPENAI_API_KEY, }); const result = await client.images.edit({ model: "gpt-image-1-mini", image: [ fs.createReadStream("product-photo.jpg"), fs.createReadStream("brand-logo.png"), ], prompt: "Edit the first image by placing the logo from the second image onto the coffee cup label. Preserve the cup shape, lighting, camera angle, and table texture.", input_fidelity: "high", size: "1024x1024", quality: "medium", }); const imageBase64 = result.data[0].b64_json; fs.writeFileSync( "product-photo-edited.png", Buffer.from(imageBase64, "base64") );
这一段里最值得记住的,不是“mini 也支持编辑”,而是 mini 的编辑细节真的会改变结果。OpenAI 当前的 input fidelity 说明 写得很明确:当你在 gpt-image-1 或 gpt-image-1-mini 上使用 input_fidelity: "high" 时,第一张输入图 会得到更强的纹理与细节保留。所以,如果某一张脸、某个产品图、某个 logo 更重要,它就应该放在 slot one。
这也是第一页很多 wrapper 页面最容易跳过的地方。它们告诉你“编辑可以做”,却不告诉你 什么操作才会明显改变最终效果。在 mini 编辑场景里,实用规则通常只有三条:
- 最重要的源图先放第一位。
- 只有在细节保真真的值得额外图像输入成本时,再开
input_fidelity: "high"。 - prompt 不只说“改哪里”,还要说“哪些东西不准动”。
如果你后面再加 mask,也要记住 GPT Image 编辑依然是 prompt 驱动的生成式编辑,不是 Photoshop 式的像素级局部修补。官方 guide 也提醒,image 和 mask 需要尺寸、格式一致,而且 mask 需要 alpha 通道。它是一个很有用的控制手段,但不该被误解成完全确定性的局部替换。
另一个实际集成里很常见的坑,是从 SDK 迁移到 raw HTTP 时忽略了 multipart form-data。SDK 会帮你把文件上传部分隐藏掉,可一旦你自己发 HTTP 请求,就必须把图片当真实文件 part 传,而不是把二进制内容随手塞进 JSON。很多第三方示例“看起来更短”,但真正进生产时正是这一步最容易漏。
如果你要解决的是更深的 mini 编辑工作流,而不仅仅是示例起步,下一篇更适合的是 GPT Image 1 Mini 编辑。这篇文章仍然停留在“先抄哪个例子”的层级。
示例 3:只有在多轮工作流里才用 Responses
这个示例排第三,不是因为它不对,而是因为它只在一种更大的产品需求下才真正值得。那就是:你的图像生成不再是“一次请求做完”,而是要和对话、上下文状态、后续跟进一起工作。
它最容易让人踩坑的一点,是 Responses 的顶层 model 不是 gpt-image-1-mini。当前官方说明很清楚:Responses 里的 hosted image_generation 工具会调用 GPT Image 模型,但 顶层 model 字段应该是可调用工具的主线文本模型,例如 gpt-4.1 或 gpt-5。
jsimport fs from "fs"; import OpenAI from "openai"; const client = new OpenAI({ apiKey: process.env.OPENAI_API_KEY, }); const response = await client.responses.create({ model: "gpt-5", input: "Generate an image of a gray tabby cat reading a newspaper at a cafe table.", tools: [{ type: "image_generation" }], }); const firstImage = response.output .filter((item) => item.type === "image_generation_call") .map((item) => item.result)[0]; fs.writeFileSync("cat-cafe.png", Buffer.from(firstImage, "base64")); const followUp = await client.responses.create({ model: "gpt-5", previous_response_id: response.id, input: "Now make it look like a realistic magazine photo.", tools: [{ type: "image_generation" }], }); const secondImage = followUp.output .filter((item) => item.type === "image_generation_call") .map((item) => item.result)[0]; fs.writeFileSync("cat-cafe-realistic.png", Buffer.from(secondImage, "base64"));
这个路线的价值,在于 图像已经成为更大工作流的一部分。当前官方文档对比了两条路径:Responses 比 Images API 多出的,是多轮编辑能力和更灵活的图像输入上下文。也正因为如此,如果你的任务本来就只是单次生成或单次直接编辑,它反而会让调试面变得更大。
这也是为什么我不建议把 Responses 当成所有 mini 示例的默认起点。你一旦先上 Responses,就同时引入了两个决定:一是顶层主线模型该用谁,二是图像生成到底是不是这条工作流里真的必要的一环。对于“第一次先跑通 mini”这个目标来说,这通常只会让问题更难定位。
在怀疑示例之前,先做这些准备检查
mini 是 OpenAI 当前更便宜的图片路线,但它不是 free 路线。截至 2026 年 3 月 29 日,当前 mini 模型页列出的 1024x1024 输出价格是 $0.005 / $0.011 / $0.036,同时页面也明确写着 Free not supported,Tier 1 从 100,000 TPM 和 5 IPM 起步。
这意味着:一段好示例也可能失败,原因却根本不在代码本身,而在你的账户状态还没准备好。OpenAI 当前的 model availability 文章 说明,gpt-image-1 和 gpt-image-1-mini 当前对 Tier 1 到 Tier 5 的 API 用户开放,但部分能力可能受 organization verification 影响。而 organization verification 文章 还补了一条最容易被示例页忽略的实际提示:验证状态传播最多可能需要 30 分钟,很多 lingering 的 not verified 错误,重新生成 API key 以后才会消失。
所以,排错顺序应该先固定下来:
- 确认 API key 属于正确的 project 和 organization。
- 确认账户所在 tier 确实支持 mini 图像访问。
- 如果仍然提示访问异常,检查 organization verification 状态。
- 如果验证刚完成,完整等完 30 分钟传播窗口。
- 在重写一个本来正确的示例前,先新建一把 API key。
如果你真正卡住的是 access state,而不是示例本身,下一篇应该先看 OpenAI 图像生成 API 验证。
排查常见 gpt-image-1-mini 示例失败问题

多数“示例坏了”的情况,根本原因其实比 SERP 看起来更普通。通常不是模型突然不行,而是你选错了接口、请求形态不对,或者过早把问题归咎到代码本身。
| 症状 | 最可能的原因 | 先检查什么 |
|---|---|---|
| 生成示例直接返回 access 或 availability 错误 | project、tier 或 verification 还没准备好 | 先核对组织、层级、验证状态,以及 API key 是否在验证完成后创建 |
| 编辑示例能跑,但忽略参考图 | 重要图片没放第一位,或 prompt 没写清必须保留的内容 | 把要保真的图放到 slot one,并把 prompt 改成“改什么 + 保留什么” |
| 离开 SDK 后 edit 请求开始报错 | raw HTTP 没有正确发送 multipart 文件上传 | 重新按 multipart form-data 发请求,不要把二进制包进 JSON |
| Responses 示例返回文字却没有可用图片 | 响应解析方式不对,或你根本不该先测 Responses | 检查 response.output 里的 image_generation_call 项,先证明你真的需要这层架构 |
| 很快撞上速率限制 | 图像接口的节奏和文本接口差很多 | 记住 mini 当前 Tier 1 只有 5 IPM,别在短时间里持续重试同一示例 |
最后一行特别容易被低估。截至 2026 年 3 月 29 日,mini 当前 Tier 1 是 5 IPM。 这比很多开发者测试文本接口时的习惯节奏小得多。如果你边改 prompt、边换素材顺序、边连点重试,很容易把配额问题误判成“这个示例有随机 bug”。
如果 Example 1 能通、Example 2 不通,最常见的解释不是“mini 编辑坏了”,而是素材顺序、prompt 范围或 multipart 形态变了。反过来,如果 Images API 的例子都能跑,而 Responses 看起来不稳定,通常也不是 Responses 本身失效,而是你在建立单轮基线之前就把工作流复杂度拉高了。
什么时候 Mini 已经够用,什么时候该改抄 GPT Image 1.5

大多数 exact examples 页面最不愿意正面回答的,其实就是这一段:代码能跑,不等于模型就该选 mini。 OpenAI 当前的 image generation guide 仍然把 gpt-image-1.5 定位成最新、最先进的 GPT Image 模型,并明确建议“如果要最佳体验,就先用 GPT Image 1.5”。同一份 guide 才接着说:如果你追求更有成本效率、而图像质量不是第一优先级,可以用 gpt-image-1-mini。
所以更诚实的规则不是“mini 已经成默认”,而是:
- 当成本是第一约束时,先复制 mini 示例。
- 当输出质量、复杂编辑或重试成本更重要时,先复制 GPT Image 1.5 的同一路线示例。
mini 更适合的,是这些类型的工作:
- 内部概念图
- 低风险营销变体
- 便宜的 prompt benchmark
- 先看量、再看精度的批量生成任务
而 GPT Image 1.5 更安全的起点,往往对应这些条件:
- 你更在意整体图像质量
- 失败一次的返工成本更高
- 你的编辑任务本身更贵、更难
- 你要的是更少重试,而不是最低标价
还有一个经常被忽略的现实细节。OpenAI 的 API pricing 页面 说明 Batch API 对输入与输出都能省 50%。这不会抹掉 mini 的低价优势,但它会让“到底该用哪条线”更像工作流决策,而不是一张价格表就能定完的事。
如果你只想看完整价格拆解,下一篇更适合的是 GPT Image 1 Mini 价格。如果你想看更宽的产品判断,则看 GPT Image 1 Mini 评测。
第三方示例页最常制造的误导
第一种误导,是 把更大的抽象误当成更现代的默认值。如果你只需要一个 prompt 生成一张图,或者对一张图做一次直接修改,就不要因为 Responses 看起来“更高级”而先上它。官方文档现在仍然把你拉回 Images API。
第二种误导,是 把错误的模型放进 Responses 顶层 model 字段。如果你走 hosted image_generation 工具,顶层模型应该是 gpt-5 或 gpt-4.1 这类主线文本模型,而不是把 gpt-image-1-mini 强塞进去。
第三种误导,是 忘了 mini 编辑里的第一张图规则。你最想保住的脸、产品图、logo,就应该先放第一位。这不是小技巧,而是当前官方文档已经写明的结果差异。
第四种误导,是 把“最便宜”直接等同于“最该默认”。官方对 mini 的定位是成本优先路线,而不是体验优先路线。只盯单价,很容易让你把本该由 GPT Image 1.5 处理的高价值工作流,也塞进 mini。
第五种误导,是 还没检查账户状态,就先怀疑示例失效。如果 tier 不对、组织未验证、传播窗口未结束,哪怕示例本身完全正确,也会表现得像“接口坏了”。
第六种误导,是 把网关产品里的词汇直接抄回 OpenAI 原生 API。第三方页面可以用自己的 UI 抽象把多层决策压成一个按钮,但这不代表它们的命名可以一比一映射到官方接口字段。示例页真正该增加的价值,不是再贴一段代码,而是告诉你什么抽象应该留在第三方产品内部,什么才是 OpenAI 原生调用里真正该写的东西。
最后的判断
如果你搜的是 gpt-image-1-mini 示例,当前最值得先复制的就是上面这三种模式:单次生成先走 Images API,直接编辑也先走 Images API,只有在产品真的需要多轮图像上下文时才转去 Responses。
而且请把一句话放在最前面:mini 是更便宜的路线,不是万能路线。 如果示例跑通了、质量也够用,就继续留在 mini;如果为了达到可交付质量开始频繁重试、反复返工,那就不要再硬撑 mini,而是改抄同一路由下的 GPT Image 1.5。