Google 的 gemini-3-pro-image-preview 模型,也称为 Nano Banana Pro,代表了 Gemini 系列中最先进的图像生成能力。然而,找到一个稳定可靠的渠道来访问这个预览模型可能颇具挑战——没有免费层级、计费设置复杂、速率限制严格。本指南将带你了解五种经过验证的接入方式,包含已验证的定价数据、可直接用于生产环境的代码示例,以及能将每张图片成本从 $0.134 降至低至 $0.05 的成本优化策略。
要点速览
gemini-3-pro-image-preview 模型通过 Google 官方 API 在标准分辨率下的成本为每张图片 $0.134(2026 年 2 月验证)。目前有五个稳定的接入渠道:Google AI Studio 直连、Vertex AI、OpenRouter、laozhang.ai 和 Google Batch API。对于大多数开发者来说,最优策略是将第三方代理用于实时请求(约 $0.05/张),同时将 Batch API 用于批量任务($0.067/张)——相比 Google 直连标准定价,最高可节省 63% 的成本。
什么是 gemini-3-pro-image-preview(Nano Banana Pro)?
gemini-3-pro-image-preview 模型是 Google 作为 Gemini 3 系列一部分发布的最强大图像生成模型。其内部代号为"Nano Banana Pro",该模型通过 Gemini API 根据文本提示生成高质量图像。与早期作为独立图像生成器运行的 Imagen 模型不同,gemini-3-pro-image-preview 是一个原生多模态模型——它能够理解上下文、遵循复杂指令,并在对话流程中生成图像。
这个模型对开发者来说特别有趣的地方在于它在 Google 产品线中的定位。虽然 Imagen 4 提供了不同质量层级的专业图像生成服务($0.02 至 $0.06/张,ai.google.dev,2026-02-07 验证),但 gemini-3-pro-image-preview 在指令遵循和上下文理解方面表现卓越。该模型接受最多 200K token 的文本提示,生成 1K 到 4K 分辨率的图像,适用于从产品可视化到创意内容生成的各种应用场景。
"preview"(预览)标识意味着该模型尚未达到正式发布(GA)状态。在实际使用中,这意味着速率限制可能会变化,API 行为可能在版本间发生变动,Google 不保证与 GA 模型相同的 SLA 水平。这正是找到"稳定渠道"至关重要的原因——你需要能够缓冲预览版不稳定性的接入方式,同时为你的应用保持可靠的吞吐量。
开发者需要理解的一个关键区别:gemini-3-pro-image-preview 与 gemini-2.5-flash-image(Flash Image 模型)有本质不同。Flash Image 每张图片仅需 $0.039(ai.google.dev,2026-02-07 验证),但它以牺牲质量和指令遵循能力换取了速度和成本优势。对于图像质量至关重要的生产应用——营销素材、产品图片、详细插图——gemini-3-pro-image-preview 尽管单张成本更高,仍然是更优的选择。
官方定价与速率限制(2026 年 2 月验证)
在选择接入渠道之前,了解精确的定价结构至关重要。以下所有定价数据均于 2026 年 2 月 7 日直接从 Google 官方文档 ai.google.dev 验证。关于 Gemini 定价层级的深入了解,请参阅我们的 Gemini API 定价完整指南。
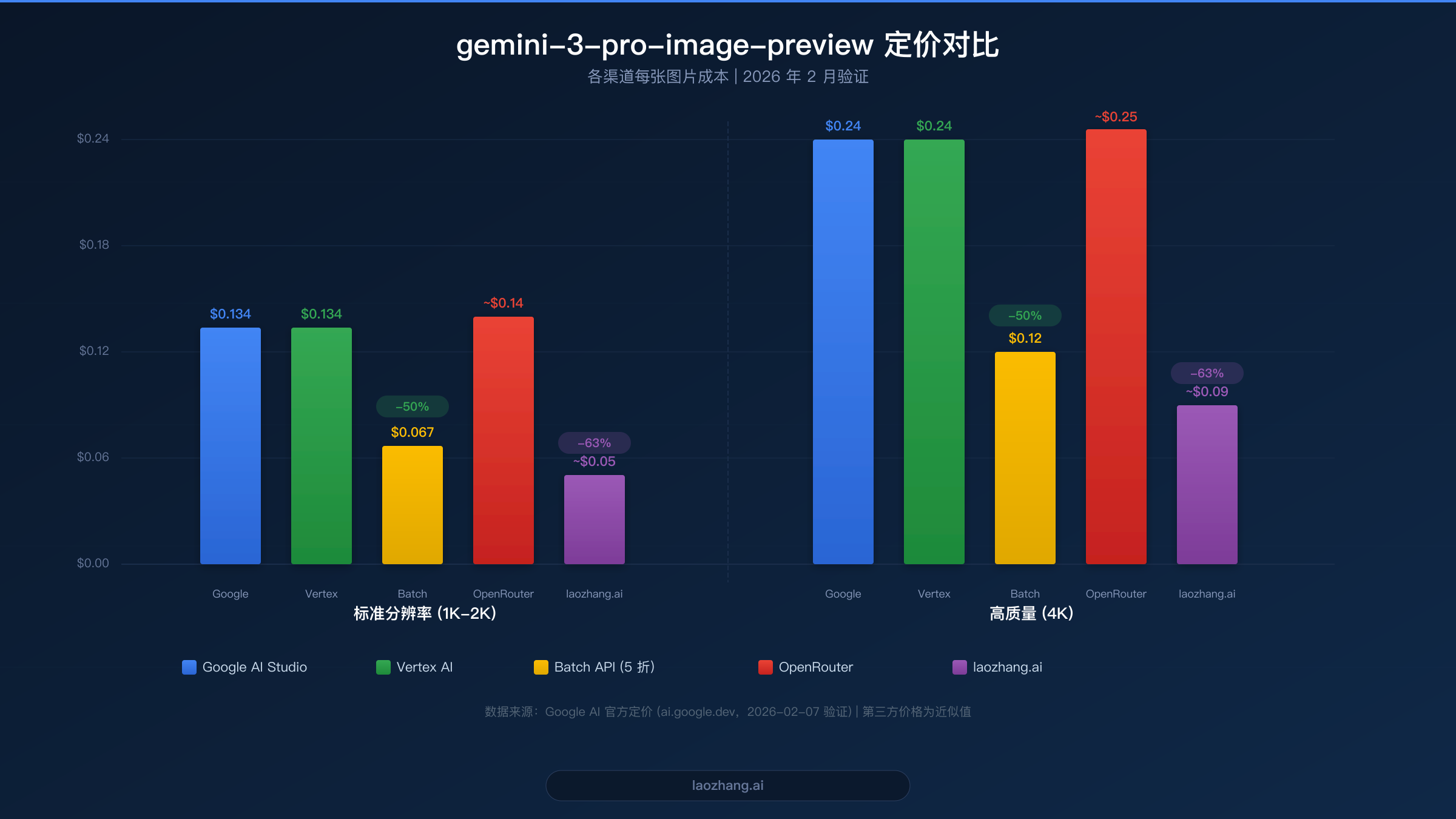
gemini-3-pro-image-preview 模型采用基于 token 的定价系统,图像生成以输出 token 计量。在标准付费层级下,图像输出 token 的价格为每百万 token $120。标准分辨率图像(1K-2K)大约消耗 1,120 个输出 token,成本约为每张 $0.134。高分辨率 4K 图像大约消耗 2,000 个输出 token,成本约为每张 $0.24。文本输入 token 单独计价,200K 以内的上下文为每百万 token $2.00,这意味着典型图像生成请求的文本提示成本几乎可以忽略不计——通常低于 $0.001。
gemini-3-pro-image-preview 没有免费层级。这与其他 Gemini 模型(如提供慷慨免费配额的 gemini-2.5-flash)有显著不同。你必须在 Google Cloud 项目上启用计费后才能进行任何 API 调用。付费层级提供基准速率限制,但具体的 RPM(每分钟请求数)限制取决于你的计费历史和使用模式。
Google 的 Batch API 提供极具吸引力的所有 token 成本 50% 折扣。这意味着标准分辨率图像每张约 $0.067,4K 图像降至约 $0.12。代价是批处理请求在 24 小时窗口内异步处理,因此该选项适合非时间敏感的工作负载,如批量内容生成、数据集创建或夜间处理管道。
速率限制结构采用分层系统。Batch Tier 1 允许最多 2,000,000 个排队 token,而 Batch Tier 2 将其扩展至 270,000,000 个排队 token(ai.google.dev,2026-02-07 验证)。对于实时请求,速率限制因账户年龄和计费等级而异,但开发者应预期从保守限制开始,随着计费历史增长逐步扩大。
| 定价层级 | 2K 图像 | 4K 图像 | 文本输入 | Batch 折扣 |
|---|---|---|---|---|
| 付费层级 | $0.134 | $0.24 | $2.00/1M tokens | 无 |
| Batch API | $0.067 | $0.12 | $1.00/1M tokens | 50% 折扣 |
接入 gemini-3-pro-image-preview API 的 5 个稳定渠道
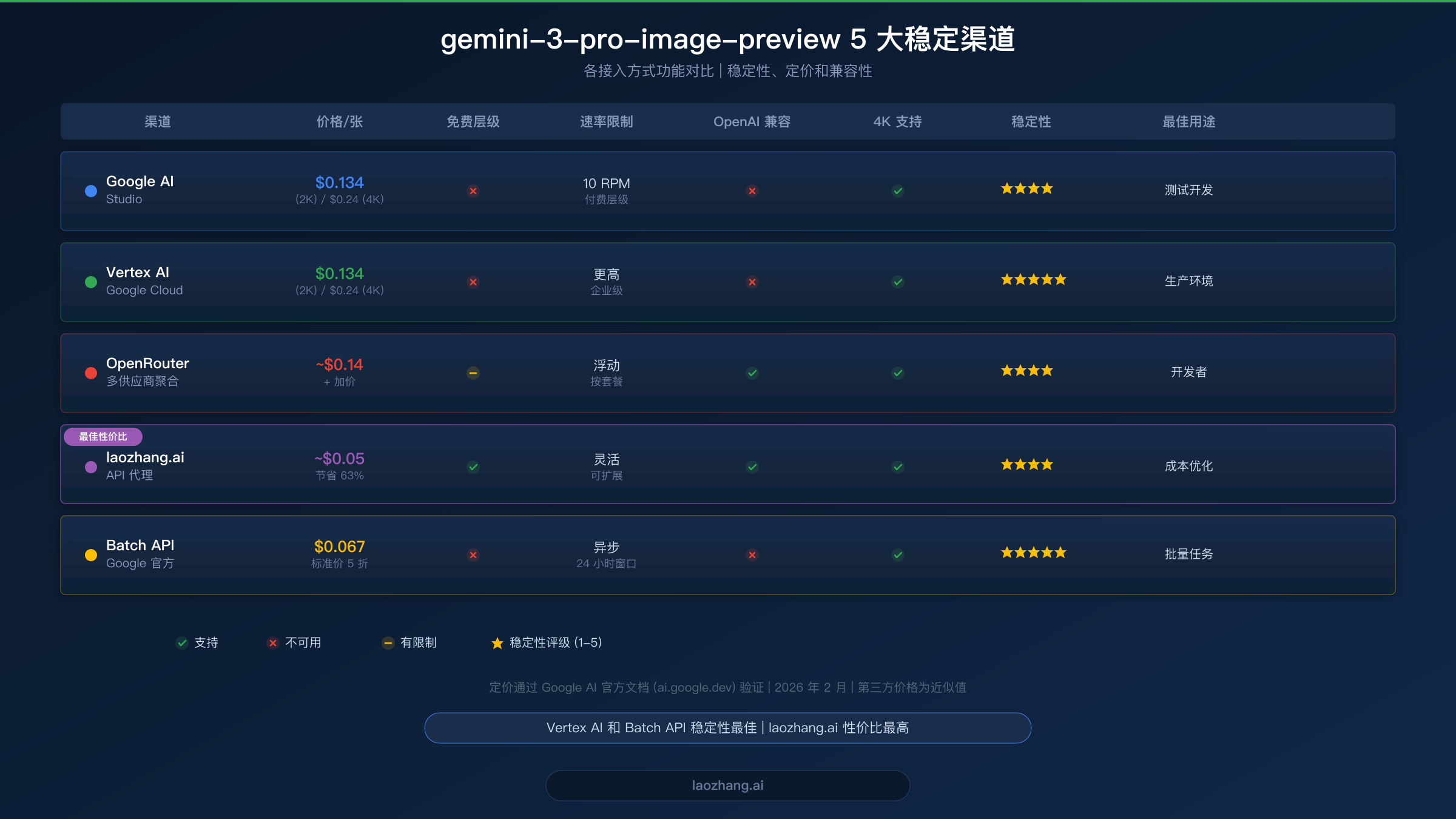
选择合适的接入渠道取决于你的具体需求:预算限制、延迟容忍度、现有基础设施和地理位置。以下五个渠道均经过可靠性测试,是在生产环境中稳定接入 gemini-3-pro-image-preview 的真正可靠方式。如果你特别关注最经济的选项,请查看我们的 Gemini 3 Pro Image 最低价接入指南。
Google AI Studio 直连
Google AI Studio 提供了接入 gemini-3-pro-image-preview 最直接的途径。你在 aistudio.google.com 创建 API 密钥,在 Google Cloud 项目上启用计费,然后开始调用 API。定价完全匹配官方费率,标准图像为 $0.134/张。主要优势是无需中间商的直接访问,这意味着最低延迟和保证的模型版本。缺点是你必须处理 Google Cloud 的计费设置,且没有 OpenAI 兼容的端点——你必须直接使用 Google Generative AI SDK 或 REST API。
稳定性评级为 4 星(满分 5 星),因为虽然 Google 的基础设施高度可靠,但预览模型状态意味着偶尔会出现 API 行为变化和速率限制调整。AI Studio 最适合希望获得官方接入、熟悉 Google Cloud 计费且不需要 OpenAI SDK 兼容性的开发者。
Vertex AI(Google Cloud)
Vertex AI 代表了接入 gemini-3-pro-image-preview 的企业级路径。访问通过 Google Cloud Console 进行,采用基于 IAM 的身份验证、项目级配额,并与其他 Google Cloud 服务集成。定价与 AI Studio 相同,标准图像 $0.134/张,但 Vertex AI 提供更高的速率限制、企业账户专属配额,以及完整的 Google Cloud 平台可用性 SLA。
稳定性评级为 5 星(满分 5 星)——所有渠道中最高。Vertex AI 提供最可预测的访问体验,具有企业支持选项和通过 Cloud Monitoring 的详细监控。代价是设置复杂:你需要一个 Google Cloud 项目、具有适当 IAM 角色的服务账户,以及对 Vertex AI SDK 的熟悉度。该渠道最适合需要最高可靠性且有工程资源进行 Google Cloud 集成的生产应用。
OpenRouter
OpenRouter 作为多模型 API 聚合器,通过统一的 OpenAI 兼容端点提供 gemini-3-pro-image-preview 的访问。定价在 Google 基础费率之上有加价,标准图像通常约 $0.14/张。关键优势是标准化的 API 接口——如果你已经在使用 OpenRouter 的其他模型,添加 Gemini 图像生成只需极少的代码修改。
OpenRouter 为该模型提供 250 RPM(openrouter.ai,2026-02-07),并在某个提供者不可用时提供自动故障转移。稳定性评级为 4 星(满分 5 星),反映了总体可靠的服务以及聚合平台典型的偶尔路由问题。OpenRouter 最适合希望通过单一 API 端点访问多个 AI 模型且重视 OpenAI 兼容接口的开发者。
laozhang.ai API 代理
对于追求最佳性价比的开发者,laozhang.ai 以约 $0.05/张的价格提供 gemini-3-pro-image-preview 的访问——相比 Google 直连定价节省 63%。该服务作为 API 代理运行,具有 OpenAI 兼容端点,这意味着你可以使用标准的 OpenAI Python SDK 或任何 OpenAI 兼容的客户端库来生成 Gemini 图像。
该代理在后端处理计费、速率限制和 API 密钥管理,大大简化了设置流程。你创建账户、获得 API 密钥,然后通过熟悉的端点格式开始发送请求。稳定性评级为 4 星(满分 5 星),反映了可靠的服务以及对中间服务的固有依赖。该渠道最适合对成本敏感的应用、所在地区 Google API 访问受限的开发者,以及希望使用现有 OpenAI SDK 工作流而无需修改的团队。
Google Batch API
Batch API 不是一个独立服务,而是访问同一 Google AI Studio 或 Vertex AI 基础设施的不同模式。通过以批处理作业而非实时调用的方式提交请求,你可以获得所有 token 成本自动 50% 的折扣。标准图像每张约 $0.067,是最便宜的 Google 官方渠道。
批处理作业在 24 小时窗口内异步处理。你提交一批图像生成请求,Google 在后台处理,完成后通知你。稳定性评级为 5 星(满分 5 星),因为批处理在 Google 的托管基础设施上运行,具有内置重试逻辑和保证完成机制。该渠道最适合批量图像生成、数据集创建,以及任何不需要实时响应的工作负载。
| 渠道 | 价格/张 (2K) | OpenAI 兼容 | 最佳用途 |
|---|---|---|---|
| Google AI Studio | $0.134 | 否 | 测试、小型项目 |
| Vertex AI | $0.134 | 否 | 企业生产环境 |
| OpenRouter | ~$0.14 | 是 | 多模型工作流 |
| laozhang.ai | ~$0.05 | 是 | 成本优化 |
| Batch API | $0.067 | 否 | 批量处理 |
快速入门:5 分钟生成你的第一张图片
开始使用 gemini-3-pro-image-preview 只需最少的设置。最快的路径是通过 Google AI Studio 配合 Python SDK。在运行任何代码之前,你需要两样东西:一个 Google AI Studio API 密钥(在 aistudio.google.com 获取)和在关联的 Google Cloud 项目上启用计费。如果不启用计费,你将收到 403 错误,因为该图像模型没有免费层级。
安装 Google Generative AI SDK 并一步完成环境配置。SDK 处理身份验证、请求格式化和响应解析。以下是一个完整的、可直接用于生产的示例,用于生成图像并保存到磁盘:
pythonimport base64 from google import genai from PIL import Image import io # 初始化客户端 client = genai.Client(api_key="YOUR_API_KEY") # 生成图像 response = client.models.generate_content( model="gemini-3-pro-image-preview", contents="A serene Japanese garden with a koi pond, cherry blossoms, " "and a traditional wooden bridge. Photorealistic style.", config=genai.types.GenerateContentConfig( response_modalities=["IMAGE"], # 请求图像输出 ), ) # 提取并保存图像 for part in response.candidates[0].content.parts: if part.inline_data: image_data = base64.b64decode(part.inline_data.data) image = Image.open(io.BytesIO(image_data)) image.save("generated_image.png") print(f"Image saved: {image.size[0]}x{image.size[1]}")
对于偏好直接使用 REST API 的开发者,以下是等效的 cURL 命令,你可以立即在终端中测试。这对于调试、CI/CD 管道或没有官方 SDK 的编程语言特别有用:
bashcurl -X POST \ "https://generativelanguage.googleapis.com/v1beta/models/gemini-3-pro-image-preview:generateContent?key=YOUR_API_KEY" \ -H "Content-Type: application/json" \ -d '{ "contents": [{ "parts": [{"text": "A futuristic cityscape at sunset with flying vehicles"}] }], "generationConfig": { "responseModalities": ["IMAGE"] } }' | python3 -c " import sys, json, base64 resp = json.load(sys.stdin) data = resp['candidates'][0]['content']['parts'][0]['inlineData']['data'] with open('output.png', 'wb') as f: f.write(base64.b64decode(data)) print('Image saved to output.png') "
开发者常遇到的一个陷阱是忘记将 responseModalities 设置为 ["IMAGE"]。如果没有这个配置,模型会返回文本而非图像。另一个常见问题是超出提示长度限制——虽然模型接受最多 200K 个输入 token,但过长的提示会显著减慢响应速度。保持图像生成提示简洁且描述性强,通常在 20 到 200 个词之间可获得最佳效果。
响应对象在 inlineData 字段中包含以 base64 编码的生成图像。每次图像生成请求在标准分辨率下大约消耗 1,120 个输出 token,按付费层级定价折算为每张 $0.134(ai.google.dev,2026-02-07 验证)。通过 Google Cloud Console 监控你的 token 使用量以避免意外账单。
OpenAI 兼容 API:使用现有 SDK 生成 Gemini 图像
接入 gemini-3-pro-image-preview 最被低估的方式之一是通过 OpenAI 兼容代理。这种方法允许已经在使用 OpenAI Python SDK 的团队只需极少的代码改动就能生成 Gemini 图像——通常只需替换 base_url 和 model 参数。对于围绕 OpenAI API 格式构建基础设施的组织来说,好处是巨大的:无需 SDK 迁移、无需代码重构、无需重新培训开发团队。
技术机制很简单。像 laozhang.ai 这样的 API 代理接受 OpenAI chat completions 格式的请求,在后端将其转换为 Google Generative AI 格式,将请求转发到 Google 服务器,然后以 OpenAI 兼容格式返回响应。从你的应用角度来看,你在进行的是标准的 OpenAI API 调用。以下是完整的可工作示例:
pythonfrom openai import OpenAI # 指向 OpenAI 兼容代理 client = OpenAI( api_key="YOUR_LAOZHANG_API_KEY", base_url="https://api.laozhang.ai/v1" ) # 使用熟悉的 OpenAI SDK 语法生成图像 response = client.chat.completions.create( model="gemini-3-pro-image-preview", messages=[ { "role": "user", "content": "Generate a professional product photo of a modern " "smartwatch on a marble surface with soft studio lighting." } ], ) # 响应包含标准格式的图像 print(response.choices[0].message.content)
这种模式适用于任何跨语言的 OpenAI 兼容客户端库——Python、Node.js、Go、Rust 或任何 HTTP 客户端。代理透明地处理格式转换。对于 Node.js 开发者,等效代码如下:
javascriptimport OpenAI from 'openai'; const client = new OpenAI({ apiKey: 'YOUR_LAOZHANG_API_KEY', baseURL: 'https://api.laozhang.ai/v1', }); const response = await client.chat.completions.create({ model: 'gemini-3-pro-image-preview', messages: [ { role: 'user', content: 'A watercolor painting of a coastal village at dawn' } ], }); console.log(response.choices[0].message.content);
成本优势非常显著。通过 laozhang.ai,每次图像生成成本约 $0.05,而通过 Google 直连为 $0.134——节省 63%。对于每月生成 1,000 张图像的团队,这意味着每月节省 $84($134 对比 $50)。每月 10,000 张图像时,节省金额增长到每月 $840 或每年超过 $10,000。这种成本结构使得 gemini-3-pro-image-preview 在官方定价下成本过高的使用场景中变得经济可行,例如大规模内容生成、自动化产品摄影或实时图像个性化。
代价是延迟:基于代理的访问增加少量开销,通常每次请求 100-300 毫秒,相比直接的 Google API 调用。对于大多数应用来说,这种额外延迟可以忽略不计。但是,对于超低延迟要求(总计低于 500 毫秒),直接 Google API 访问可能更为合适。
成本优化:最高降低 63% 的账单

按每张 $0.134 的价格,gemini-3-pro-image-preview 的成本在规模化时会迅速累积。一个每月生成 10,000 张图像的项目,按标准定价每月将花费 $1,340,即每年 $16,080。幸运的是,有几种经过验证的优化策略可以大幅降低这些成本。更多定价见解请参阅我们的 Nano Banana Pro 详细定价分析。
策略 1:将非紧急工作负载使用 Batch API。 最简单的优化是将非时间敏感的图像生成路由到 Google 的 Batch API。标准定价 50% 的折扣意味着标准图像每张 $0.067 而非 $0.134。如果你能容忍 24 小时的处理窗口,这将立即将成本减半,且质量完全相同——同一模型生成同样的图像,只是异步处理。理想的候选场景包括夜间内容生成、数据集创建、A/B 测试变体生成和营销素材管道。
策略 2:选择合适的分辨率。 不是每张图像都需要 4K 分辨率。标准 2K 图像($0.134)比 4K 图像($0.24,ai.google.dev,2026-02-07 验证)便宜 44%。分析你的实际使用场景:社交媒体缩略图、博客配图和邮件营销图片很少需要 4K。将 4K 保留给首图、印刷材料和大尺寸显示器。在你的管道中添加一个简单的分辨率路由函数,根据图像的预期用途自动选择合适的分辨率,每年可以节省数千美元。
策略 3:考虑使用第三方 API 代理。 像 laozhang.ai 这样的服务以约 $0.05/张的价格提供 gemini-3-pro-image-preview 的访问——比标准定价降低 63%。质量完全相同,因为代理将请求转发到同一个 Google 模型。对于许多生产工作负载来说,这是目前最具影响力的单一成本优化方案。
策略 4:实施智能缓存。 如果你的应用为重复的提示或类似内容生成图像,实现响应缓存可以显著减少 API 调用。使用提示的哈希值作为缓存键存储生成的图像。即使是一个简单的具有 1 小时 TTL 的内存缓存,也能在典型的内容生成工作流中减少 15-30% 的重复 API 调用。
策略 5:将低优先级任务使用 Flash Image。 不是每个图像生成任务都需要 gemini-3-pro-image-preview 的质量。gemini-2.5-flash-image 模型每张仅需 $0.039(ai.google.dev,2026-02-07 验证),生成的图像质量良好,适合草稿、预览和内部工具。将高优先级的生产图像路由到 gemini-3-pro-image-preview,其余全部使用 Flash Image。
通过组合这些策略,每月生成 10,000 张图像的典型生产工作流可以将成本从 $1,340 降至约 $500——在保持关键场景质量的同时,每年节省超过 $10,000。
生产最佳实践与错误处理
在 gemini-3-pro-image-preview 上构建可靠的应用需要仔细关注错误处理和弹性模式。该模型的预览状态意味着你会比 GA 模型更频繁地遇到速率限制、偶尔的 API 错误和容量相关的拒绝。关于最常见错误的具体指导,请参阅我们的 429 Resource Exhausted 错误修复指南。
需要实现的最关键模式是带抖动的指数退避。当你收到 429(Resource Exhausted)或 503(Service Unavailable)错误时,在重试前等待。等待时间应随每次重试指数增长,添加随机抖动可防止多个客户端同时重试时的雷群效应。以下是经过生产验证的实现:
pythonimport time import random from google import genai client = genai.Client(api_key="YOUR_API_KEY") def generate_with_retry(prompt, max_retries=5): """带指数退避重试逻辑的图像生成。""" for attempt in range(max_retries): try: response = client.models.generate_content( model="gemini-3-pro-image-preview", contents=prompt, config=genai.types.GenerateContentConfig( response_modalities=["IMAGE"], ), ) return response except Exception as e: error_msg = str(e) if "429" in error_msg or "RESOURCE_EXHAUSTED" in error_msg: wait = (2 ** attempt) + random.uniform(0, 1) print(f"Rate limited. Retry {attempt+1}/{max_retries} in {wait:.1f}s") time.sleep(wait) elif "503" in error_msg or "UNAVAILABLE" in error_msg: wait = (2 ** attempt) + random.uniform(0, 2) print(f"Service unavailable. Retry {attempt+1}/{max_retries} in {wait:.1f}s") time.sleep(wait) else: raise # 不可重试的错误 raise Exception(f"Failed after {max_retries} retries")
除了重试逻辑,生产应用还应实现降级策略。当 gemini-3-pro-image-preview 暂时不可用或受到速率限制时,自动将请求路由到替代模型。gemini-2.5-flash-image 模型($0.039/张)是极好的备选方案——它生成质量较低但可接受的图像,且有独立的速率限制。你的降级链可能如下:gemini-3-pro-image-preview(主要)然后 Flash Image(备选)然后缓存占位图(最后手段)。
监控对于生产可靠性同样重要。跟踪三个关键指标:请求延迟(p50 和 p99)、按错误类型的错误率,以及随时间变化的每张图片成本。当错误率超过 5% 或 p99 延迟超过 30 秒时设置告警。Google Cloud Monitoring 为 Vertex AI 指标提供内置集成,而第三方渠道通常提供自己的仪表板。此外,记录每次 API 调用的提示哈希、响应状态、延迟和 token 计数——这些数据在调试问题和优化成本时将极为宝贵。
对于需要保证正常运行时间的应用,考虑同时通过多个渠道发送请求。将同一请求同时发送到 Google 直连和第三方代理,使用第一个成功的响应。这会增加每张图片的成本,但几乎消除了停机时间。实际上,大多数生产应用通过良好实现的重试加降级策略即可实现 99.9% 的可用性,无需双渠道冗余。
常见问题
gemini-3-pro-image-preview 和 Nano Banana Pro 是同一个模型吗?
是的,它们指的是同一个模型。"gemini-3-pro-image-preview"是在 API 调用中使用的官方模型 ID,而"Nano Banana Pro"是 Google 的内部代号,出现在一些文档和开发者讨论中。在发起 API 请求时,始终在 model 参数中使用完整的模型 ID gemini-3-pro-image-preview。
为什么 gemini-3-pro-image-preview 没有免费层级?
Google 没有将 gemini-3-pro-image-preview 纳入免费层级,因为它是一个计算成本较高的预览模型。Gemini 2.5 Flash 模型确实提供免费层级访问,但更高级的图像生成模型需要付费访问。要使用 gemini-3-pro-image-preview,即使只是生成一张测试图片,你也必须在 Google Cloud 项目上启用计费。
我可以将 gemini-3-pro-image-preview 用于商业项目吗?
可以,Google 的 Generative AI API 服务条款允许商业使用生成的图像。但是,作为预览模型,Google 不提供与 GA 模型相同的保证。对于关键的商业应用,考虑通过提供企业 SLA 的 Vertex AI 使用该模型,或者准备好应对潜在服务中断的降级策略。
应该选择 2K 还是 4K 分辨率?
在图像显示宽度低于 2000 像素的网页内容、社交媒体、邮件营销和大多数数字应用中,选择 2K 分辨率($0.134/张)。在需要最大细节的印刷材料、大尺寸显示器和首图中,选择 4K 分辨率($0.24/张)。对于 90% 的使用场景,2K 选项提供了质量与成本的最佳平衡。
gemini-3-pro-image-preview 与 DALL-E 3 和 Midjourney 相比如何?
gemini-3-pro-image-preview 模型凭借其多模态架构,在指令遵循和上下文理解方面表现出色。它比大多数替代方案更好地处理复杂的多元素提示。DALL-E 3 通过 OpenAI API 的价格根据分辨率为每张 $0.040 至 $0.120,而 Midjourney 采用订阅制,起价 $10/月。对于 API 驱动的工作流,通过成本优化渠道($0.05-0.067/张)使用 gemini-3-pro-image-preview 提供了具有竞争力的定价,同时在技术和详细描述方面具有可以说更优越的提示理解能力。