
先给结论: Claude 529 overloaded_error 大多数情况下表示 Anthropic 当前临时过载,或者你的请求上游服务已经饱和。最合理的第一步不是改 prompt,也不是立刻换 key,而是先看 Claude 的实时状态页和最近事故记录。如果你走的是 API,第二步才是带退避的重试;如果你用的是 Claude 聊天或 Claude Code,还要先排除你看到的其实是套餐额度或聊天侧容量提示。
这个区别在 2026 年比以前更重要。Anthropic 的官方 release notes 明确写到,到了 2025 年 8 月 11 日,一些原本会返回 529 overloaded_error 的“突发流量”场景,已经改成返回 429 rate_limit_error。所以现在一篇靠谱的 529 指南,不能只说“等一会再试”,而是要先告诉你:你到底撞上的是哪一类问题。
而且这不是纸上谈兵。Anthropic 的公共状态流在 2026 年 3 月 19 日 00:28 UTC 打开了 “Elevated errors across surfaces” 事故,claude.ai、platform.claude.com、Claude API 和 Claude Code 都被标成了 partial outage。而在本文最后一次复查的 01:21 UTC,这个事故已经进入 monitoring,Anthropic 还补充说明用户在 23:59-00:30 UTC 之间经历了跨表面的认证错误。这个时间线正说明:搜索 529 的用户真正需要的是诊断流程,而不是空泛的“多试几次”。
要点速览
Claude 529 overloaded_error 通常是 Anthropic 侧过载信号,不等于你的请求格式写错。先看 status.claude.com 和最近的 incidents feed。本文最后一次复查时,2026 年 3 月 19 日的 summary 仍显示 Minor Service Outage,而 “Elevated errors across surfaces” 已经从 investigating 进入 monitoring,对应的是 23:59-00:30 UTC 之间的跨表面认证错误。如果你检查时平台是健康的,再考虑退避重试和降低并发;如果你实际碰到的是 429,那就按限流问题处理;如果你看到的是 Claude 聊天里的 “Due to unexpected capacity constraints...” 提示,Anthropic 的帮助文档明确说这不是正式 outage,也可能不会显示在状态页上。
| 信号 | 通常代表什么 | 常见出现位置 | 第一动作 |
|---|---|---|---|
529 overloaded_error | Anthropic 或上游服务临时过载 | API、Workbench、Claude Code、接入 Anthropic 的第三方链路 | 先查状态,再做退避重试,并记录 request ID |
429 rate_limit_error | 你的组织触发了 RPM、ITPM、OTPM 或 acceleration limit | API 及依赖 API 的工具 | 尊重 retry-after,降低突发流量,查看 rate limits |
| “Due to unexpected capacity constraints...” | Claude 聊天端处于高负载 | claude.ai | 等几分钟再刷新;官方说明这不是正式 outage |
| “5-hour limit reached” | 你当前套餐窗口额度用完 | Claude 聊天 / Claude Code 订阅流程 | 等待重置、降低使用量,或查看 /zh/posts/claude-code-rate-limit |
Claude 529 Overloaded Error 到底是什么意思
当 Anthropic 返回 529 overloaded_error 时,最常见的含义是:服务此刻无法稳定处理你的请求,因为当前容量受限。这和请求格式错误、API key 过期、权限不足不是一回事。现实里,很多开发者会在平台高峰、某个模型后端压力过大,或者 Claude Code / Workbench 依赖的后端链路吃紧时看到 529。
这也解释了为什么围绕这个错误的搜索意图非常焦虑。大多数人是在工作中途被打断,于是直接搜报错原文,想尽快判断一件事:“这是我自己的问题,还是 Anthropic 自己挂了?” 但现有很多搜索结果只提供“有人也遇到了”的情绪确认,却没有给出真正可执行的判断框架。
把 Anthropic 的几类官方资料放在一起看,诊断就会清楚很多。帮助中心把 服务事故、Claude 聊天容量约束 和 使用额度提示 分成了不同类别;API 文档又分别解释了 rate limits、service tiers 和 SDK 重试机制。综合这些信息,最实用的理解是:
529通常指向服务过载或上游临时饱和。429指向限流,包括短时突发或 acceleration 行为。- 聊天侧容量提示属于 Claude 消费端体验问题。
- 五小时额度提示属于套餐配额问题。
你真正要做的不是背定义,而是先把问题归类。因为只要归类错了,后面的修复动作就会全部跑偏。
还有一点很重要:529 主要是可用性问题,而不是语义问题。如果 Anthropic 当前过载,那么把一个本来就合法的请求改写一下,通常并不能真正解决根因。真正更有效的思路仍然是先判断平台健康状态。
529、429、容量提示和使用额度的区别

用户在这个主题上最容易浪费时间的原因,是 Anthropic 有多种“现在不能继续”的状态,但这些状态根本不属于同一层。
Anthropic 关于 Claude error messages 的官方文章明确提到,聊天侧的 capacity constraints 是高负载下的临时现象,而且不会出现在状态页上,因为官方把它视为正常负载管理,而不是正式技术事故。这一句话就解释了为什么很多人会困惑:明明 Claude 聊天坏了,状态页却还是绿的,于是用户反而去怀疑浏览器、账号或网络。
API 侧则完全不同。Anthropic 的 rate limits 文档 说明,限制是在组织级别生效的,而且还会按更短时间片执行,不只是“按分钟算平均值”。这意味着即使你分钟级平均值不高,短时爆发也仍然可能失败。再加上 release notes 里的关键更新:2025 年 8 月 11 日,Anthropic 说部分突增使用量场景现在会返回 429,而不是过去更常见的 529。
所以如果你还在参考旧社区帖子里那种“529 和 429 差不多”的说法,最好把它当成过时建议。它在 2024 年或 2025 年前半段或许还算勉强有用,但对 2026 年的诊断已经不够精确了。
最实用的比较是下面这张表:
| 条件 | 所在层 | 典型原因 | 最不该做的事 |
|---|---|---|---|
529 overloaded_error | Anthropic 服务 / 上游容量 | 临时过载、实时事故、后端模型拥堵 | 不要第一时间换 key 或重写本来就正常的代码 |
429 rate_limit_error | 你的组织 API 使用行为 | tier 上限、RPM/TPM 压力、acceleration limit | 不要把它当平台 outage |
| 聊天容量提示 | Claude 聊天产品层 | 系统高峰、聊天基础设施繁忙 | 不要以为状态页一定会变红 |
| 五小时额度提示 | 套餐配额层 | 你的 Pro/Max 窗口额度耗尽 | 不要继续折腾网络和登录设置 |
如果你主要用 Claude Code,还有一个额外分叉:表面上是工具层报错,但真正的瓶颈可能依然来自 Anthropic 的底层组件。所以订阅配额问题和 API 问题最好分开看;更完整的拆解可以继续读 /zh/posts/claude-code-rate-limit。
先查状态:如何确认是不是 Anthropic 真实事故
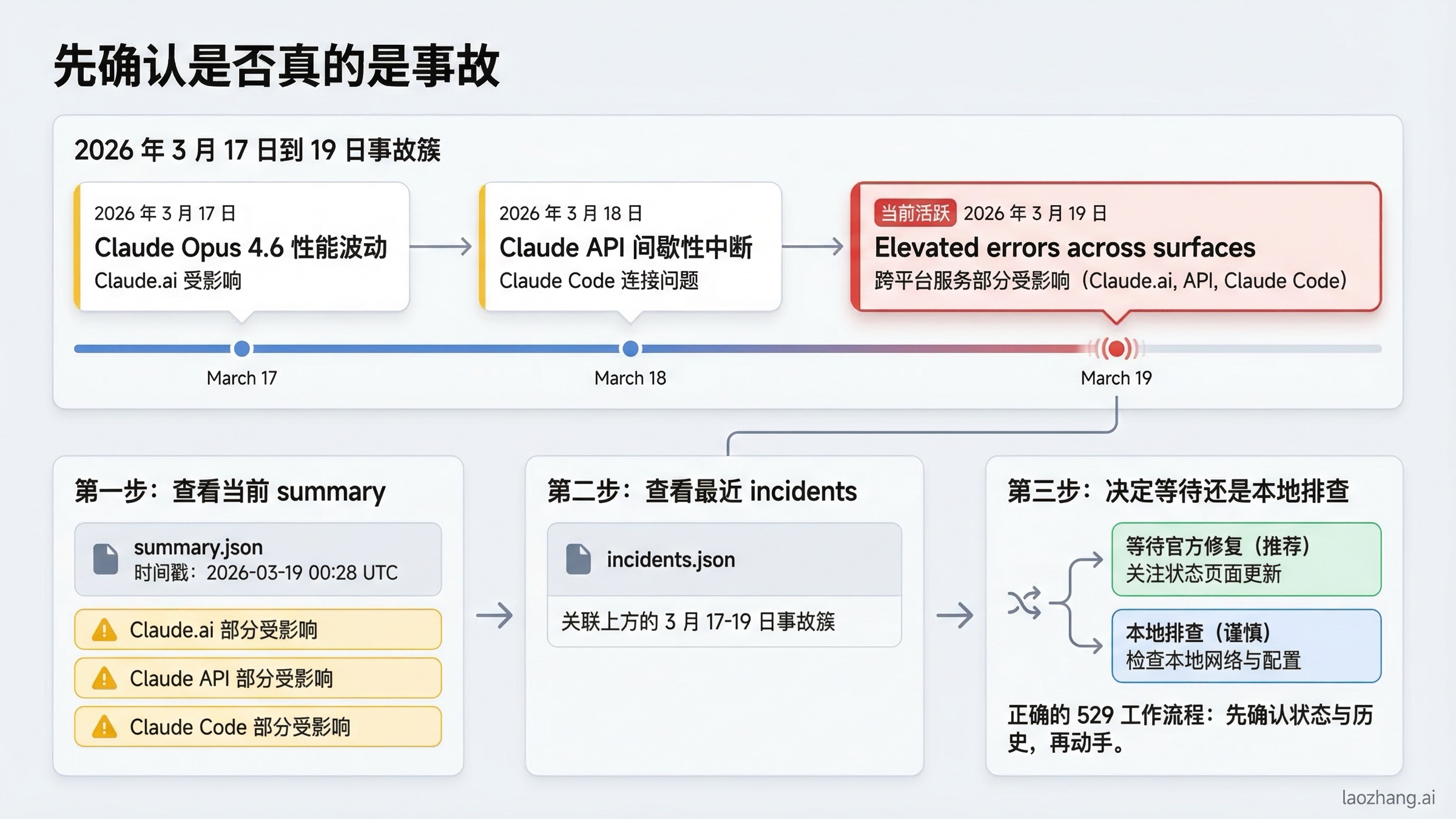
对这个关键词来说,最有价值的答案其实不是定义,而是一套状态检查流程。
第一步先打开 status.claude.com。如果你想看得更细,再直接查机器可读接口:
https://status.claude.com/api/v2/summary.jsonhttps://status.claude.com/api/v2/incidents.json
这两个接口有价值,是因为它们会给出组件级状态,包括:
claude.aiplatform.claude.comClaude API (api.anthropic.com)Claude Code
我在 2026 年 3 月 19 日重新检查时,summary endpoint 并不是一片绿色。它显示的是 Minor Service Outage,并把 claude.ai、platform.claude.com、Claude API 和 Claude Code 都标成了 partial outage。同一天 01:21 UTC 的后续更新又把 “Elevated errors across surfaces” 从 investigating 调整为 monitoring,并说明用户在 23:59-00:30 UTC 间遭遇了跨表面的认证错误。incidents feed 也解释了为什么“最近几天的历史”同样重要:Anthropic 在 2026 年 3 月 17 日到 19 日之间连续出现了多次相关事故,包括:
- 2026 年 3 月 17 日: Claude Opus 4.6 elevated errors
- 2026 年 3 月 18 日: Claude Opus 4.6 elevated errors
- 2026 年 3 月 18 日: Opus 4.6 increased errors
- 2026 年 3 月 18 日: Claude.ai elevated errors,Claude Code 也受到影响
- 2026 年 3 月 19 日: “Elevated errors across surfaces” 在 00:28 UTC 打开,并在 01:21 UTC 进入 monitoring
这就是为什么“等 30 秒重试”这种建议不够。它有时当然有效,但有时你正好站在一个真实 outage 窗口里,再怎么怀疑自己的代码也没意义。
这里也有一个值得补充的操作层提醒。anthropics/claude-code 仓库里有个 Issue #1838,记录了 2025 年 6 月 9 日一次用户已经碰到 overloaded_error,但 dashboard 还没及时反映故障的案例。这个案例本身不能被夸大成“状态页不可信”,但它足以说明:状态页很重要,却不是魔法。事故刚开始的几分钟里,社区报告可能先于所有组件正式翻红。
更稳妥的顺序是:
- 先看 summary。
- 再看 incidents。
- 确认问题是只出在单个表面、单个模型,还是整条工作流都在抖。
- 如果状态页暂时还是绿的,但社区反馈已经明显堆起来了,就要保守处理重试,不要因为一次可能错误的“本地诊断”而做破坏性改动。
如果你的系统是生产环境,最好把 incidents feed 接进监控,而不是只靠 dashboard UI。JSON feed 更适合告警,也更适合和自己的日志做时间线对比。
故障排查:前 10 分钟应该怎么做
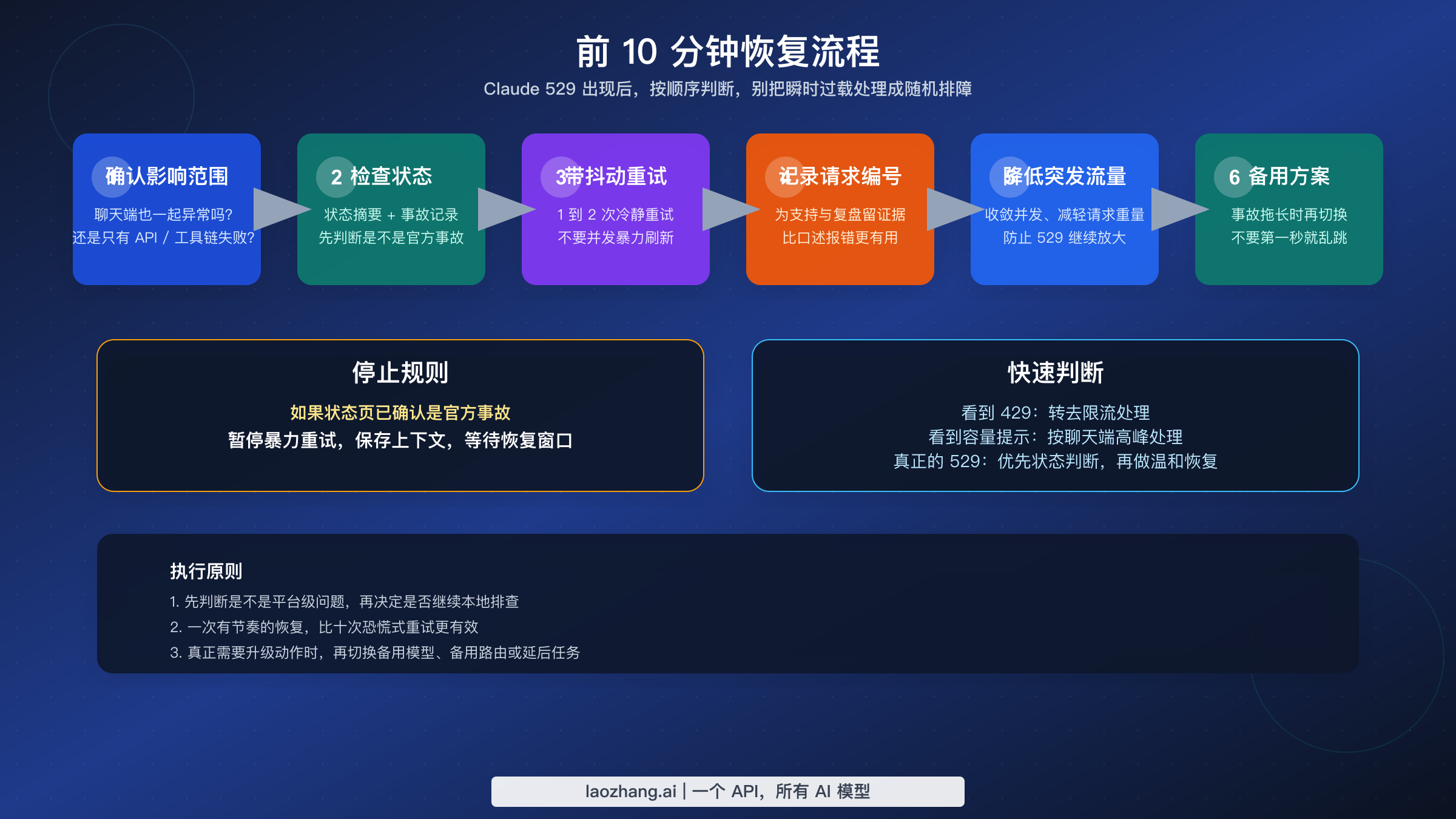
如果你是在 API、Workbench 或 Claude Code 里遇到 529,建议按下面这个顺序处理。
第 1 步:先确认是局部问题还是广泛问题。 如果 Claude 聊天和 API 都有异常,平台侧问题的概率会明显变高;如果只有一条接入路径失败,也可能是上游问题,但你同时也该检查自己的接入链路。
第 2 步:用带 jitter 的重试,不要“情绪化重试”。 过载类错误是少数确实适合重试的场景,但无节制地猛打只会让情况更差。应该用指数退避,再加一点随机抖动。Anthropic 的 Python SDK 文档说明,官方 SDK 默认会自动重试 connection errors、408、409、429 和 >=500 错误各 2 次。所以如果你已经在用官方 SDK,先弄清楚它已经帮你做了什么,再决定是否叠更多重试层。
第 3 步:记录 request ID。 Anthropic SDK 暴露 _request_id 就是为了这个。真要走支持工单时,一个清晰的 request ID 比“中午左右感觉挂了”更有价值。
第 4 步:减少突发流量。 Anthropic 的 rate-limit 文档写得很清楚:短时间片也会执行限流,而且底层是 token-bucket 逻辑。哪怕你当前看到的是 529,降低突发并发仍然是对的,因为 burst 行为可能把你进一步推到 429 路径,或者在服务紧张时让恢复更慢。
第 5 步:确认你看到的到底是不是 429。 如果异常体或 SDK 抛出的明确是 RateLimitError,就要立刻切换思路。那时更有用的是 /en/posts/claude-api-429-solution,而不是继续按“Claude 宕机”去想。
第 6 步:暂时减轻请求负载。 如果你现在的工作流带了非常大的上下文、大量工具输出或过重附件,先把负载降下来。这不代表“重 prompt 会导致所有 529”,但较轻的请求更容易重试,也更不容易叠加出 timeout 或次级限流问题。
第 7 步:必要时改变时机,而不只是改代码。 如果某个模型家族在当前小时明显状态很差,那么把非关键任务延后 10 到 20 分钟,往往比继续榨干重试更划算。目标是尽快恢复有效工作,而不是证明自己的重试循环有多顽强。
一个保守的 Python 处理模式可以写成这样:
pythonimport time import random from anthropic import Anthropic, APIStatusError, RateLimitError client = Anthropic(max_retries=2) def call_with_jitter(messages, max_attempts=5): for attempt in range(max_attempts): try: return client.messages.create( model="claude-sonnet-4-6", max_tokens=1024, messages=messages, ) except RateLimitError: # 429: 按限流处理,不要当成普通过载 raise except APIStatusError as e: if e.status_code == 529: delay = min(2 ** attempt, 20) + random.uniform(0, 1) time.sleep(delay) continue raise raise RuntimeError("Claude remained overloaded after retries")
这段逻辑的重点不是“无限坚持”,而是“优雅降级”。如果 529 连续出现,而且状态页上已经有活动事故,就应该停止继续加压,而不是拿更大流量去硬撞。
Claude 聊天和 Claude Code 用户应该怎么处理
很多搜索这个关键词的人,其实根本不是在直接调用原始 API,而是在 claude.ai、Claude Code、Workbench、Cursor、MCP 链路或者其他最终走到 Anthropic 的工具里工作。这样一来,排查顺序就和纯 API 用户不完全一样。
对于 Claude 聊天,Anthropic 的帮助文档明确说,capacity-constraint 类提示是高峰期下的临时现象。如果你看到的是聊天侧容量提示,通常该做的是等几分钟再刷新,而不是花半小时清浏览器缓存。同一篇文档也强调,五小时使用额度提示又是另一类完全不同的问题,它表示的是当前套餐窗口的预算耗尽。
对于 Claude Code,建议看报错是否伴随登录异常、历史记录异常,或者更大范围的服务波动。因为在 2026 年 3 月 18 日的事故记录里,Claude.ai 那次 incident 更新就明确提到:Claude Code 的登录和登出动作也受到了影响。这说明 Claude Code 出问题时,未必是本地 CLI 坏了,也可能只是它正好暴露了更广的 Anthropic 事故。
如果你的 Claude Code 前面还套了一层 MCP server 或其他本地桥接层,也应该顺手检查它。中间层有时会把原始错误包掉,导致你只看到模糊症状。想更系统地理解中间层行为,可以继续读 /zh/posts/claude-mcp-complete-guide-2025。
这里也解释了为什么很多付费用户对 529 特别恼火。无论你付的是 Pro、Max,还是 API 充值,付费都不等于不会遇到过载。它只代表你按该套餐规则获得访问权;底层服务一旦紧张,配置完全正确的工作流照样可能卡住。
一个更实用的记忆方式是:
- 如果 Anthropic 整个生态都在抖,先按 incident 思路判断。
- 如果只是你的订阅工作流受影响,更像套餐额度或聊天容量问题。
- 如果只是 API 自动化链路出问题,先分清 529 和 429,再去动设置。
如何减少以后再次遇到 529
你无法彻底消灭平台侧过载,但你可以显著减少它对自己的伤害。
第一层是 更好的流量形状。不要从零瞬间拉到最大并发。Anthropic 官方文档已经提醒过,短时间片限流和 token-bucket 行为会让“平均值看起来还好”的流量也在 burst 时失败。
第二层是 prompt 和上下文纪律。更小、更干净的请求更容易重试,也更不容易在响应时间过长时叠加其他边缘错误。如果某些任务天然会跑很久,在适合的情况下用 streaming,通常比一口气等一个巨大非流式响应更稳。
第三层是 缓存与复用策略。如果你的系统每次都重发同样的大段前缀,既增加成本,也扩大失败面。prompt caching 不能消灭 Anthropic 的过载,但能减少不必要流量,也更容易让你分清楚到底是供应商临时过载,还是自己请求设计太重。
第四层是 tier 策略。Anthropic 的 service tiers 文档 明说了,Priority Tier 是给生产工作流用的,目标之一就是在高峰期减少 server overloaded 类错误。它并不代表你从此 outage 免疫,但它确实意味着:如果你有真实可用性要求,就不要继续把 Standard 当成生产 SLA。
第五层是 fallback 架构。如果一个供应商状态不稳,你的整条业务流程就完全停摆,那已经不只是“供应商问题”,也是你自己的系统设计问题。对需要第二出口的团队来说,relay 或 aggregation 层可以在供应商波动时保留更多可操作空间。关键点在于架构本身,而不是某个具体品牌:如果你的工作流真的需要冗余,就应该在下一次事故窗口到来之前把备用链路设计好。
第六层是 监控。定时抓 incidents feed、记录 request ID、观察某个模型家族的连续错误峰值,并为重复失败做告警,这些才是运营层面的真实抓手。Reddit 和 GitHub 线程适合当烟雾报警器,不适合当你的正式监控系统。
如果你反复觉得自己“老是 529”,但最后发现其实更像限流或 burst 设计问题,可以接着看更完整的 /en/posts/claude-api-quota-tiers-limits。
FAQ
Claude 529 overloaded error 是我自己的问题吗? 通常不是。529 overloaded_error 大多数时候表示 Anthropic 或上游服务临时饱和。当然,如果你的客户端疯狂重试,也会把症状放大,但错误本身通常还是平台压力信号。
529 一般会持续多久? 没有固定时间。有的几分钟恢复,有的会拖更久。真正该看的还是 status.claude.com 的实时 incidents feed,而不是旧论坛里随手给出的估计。
应该马上重试吗? 可以重试,但要用带退避和随机抖动的方式。一两次冷静重试是合理的;并行洪水式重试只会更糟。
529 和 429 是一回事吗? 不是。到 2026 年,最好把两者当成完全不同的诊断路径。429 是限流问题,529 通常是过载问题。Anthropic 在 2025 年 8 月 11 日的 release note,已经给出了最清楚的官方依据。
为什么 Claude 聊天坏了,但状态页看起来正常? 因为 Anthropic 官方帮助文档明确写着:聊天侧 capacity constraints 不算正式 outage,所以不会出现在状态页上。这很让人抓狂,但这就是官方当前的公开规则。
编码时碰到这个问题,最快最安全的流程是什么? 先查状态,保存当前工作,用退避方式重试;如果事故持续,就切到备用模型或备用 endpoint。对重度 Claude Code 用户来说,提前准备第二条工作路径,比事故发生时临时找工具要有效得多。