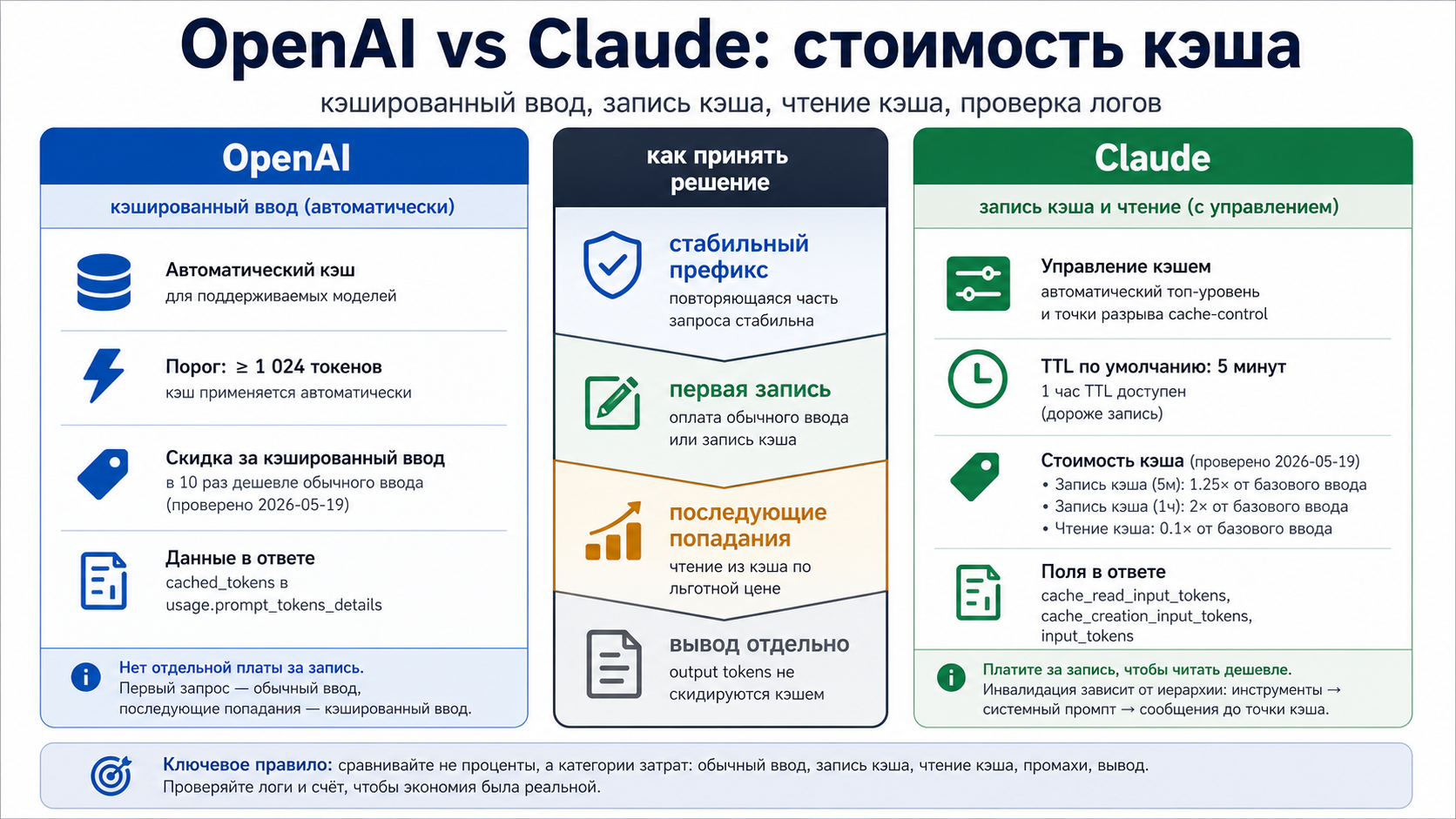
Prompt caching кажется простой скидкой, пока вы не открываете реальный счёт. OpenAI и Claude оба уменьшают стоимость повторяемой части запроса, но делают это через разные строки тарификации. На дату проверки 2026-05-19 стандартные строки OpenAI для GPT-5.5, GPT-5.4 и GPT-5.4 mini показывают cached input примерно как одну десятую от обычного input, без отдельной платы за запись кэша. У Claude чтение из кэша тоже стоит 0.1x от базового input, но создание кэша оплачивается отдельно: 5-минутная запись стоит 1.25x, а 1-часовая запись стоит 2x от базового input.
Поэтому главный вопрос не «где скидка больше», а «как именно мой повторяемый префикс попадёт в счёт». Если у вас стабильный system prompt, набор tools, политика продукта, большой справочник, кодовая база или длинный few-shot блок, OpenAI удобнее как автоматический путь с меньшим числом движущихся частей. Claude сильнее там, где нужно явно задать границы кэша, прогреть длинный контекст и контролировать TTL. В обоих случаях экономию нельзя считать реальной, пока в логах не видно usage.prompt_tokens_details.cached_tokens для OpenAI или cache_read_input_tokens, cache_creation_input_tokens и input_tokens для Claude.
| Рабочая ситуация | С чего начать | Почему | Что проверить в логах |
|---|---|---|---|
| Длинный стабильный префикс повторяется в каждой сессии | OpenAI | автоматический кэш и нет отдельной write-премии | cached_tokens > 0 |
| Нужно управлять cache breakpoint и TTL | Claude | явные границы и предсказуемое окно повторного использования | cache_creation_input_tokens, cache_read_input_tokens |
| Запросы повторяются один-два раза | ни один провайдер не гарантирует выгоду | write, miss и output могут съесть экономию | hit rate, TTL, output share |
| В начале запроса постоянно меняются поля | сначала исправить layout | динамический префикс разрушает попадания | prefix hash и версия prompt |
| Есть Batch, long context, cloud marketplace или enterprise pricing | считать отдельно | базовая таблица цен не покрывает все модификаторы | актуальная страница цен |
Короткий вывод: сравнивайте строки счёта, а не процент
Для повторяемого длинного префикса OpenAI чаще выигрывает простотой. В поддерживаемых современных моделях кэширование работает автоматически, запрос должен быть достаточно длинным, а стабильная часть должна совпадать в начале. Первый miss оплачивается как обычный input; последующие попадания идут по cached input price. Для API-продукта с одинаковым system prompt и разными пользовательскими вопросами это снижает операционные риски: сначала ставите логирование, затем постепенно чистите префикс.
Claude лучше выглядит, когда кэш является частью архитектуры. Вы можете явно отделить tools, system и messages, выбрать cache breakpoint, прогреть длинный контекст и решить, нужен ли 5-минутный или 1-часовой TTL. Но за этот контроль платят заранее. Если чтений мало, если TTL истекает между запросами или если ранние блоки запроса постоянно меняются, запись кэша будет повторяться слишком часто и обещанная экономия не появится.
Русскоязычная выдача по этой теме часто смешивает несколько разных тезисов: «токены в 10 раз дешевле», «OpenAI даёт 50%», «Claude экономит 90%», «кэш снижает latency». Все эти фразы могут быть частично правдивыми в своём контексте, но опасны для бюджета. 50% относится к старым строкам и старым публикациям, 90% относится к чтению или cached input, latency не равна счёту, а output tokens вообще не получают скидку prompt cache.
Словарь тарификации
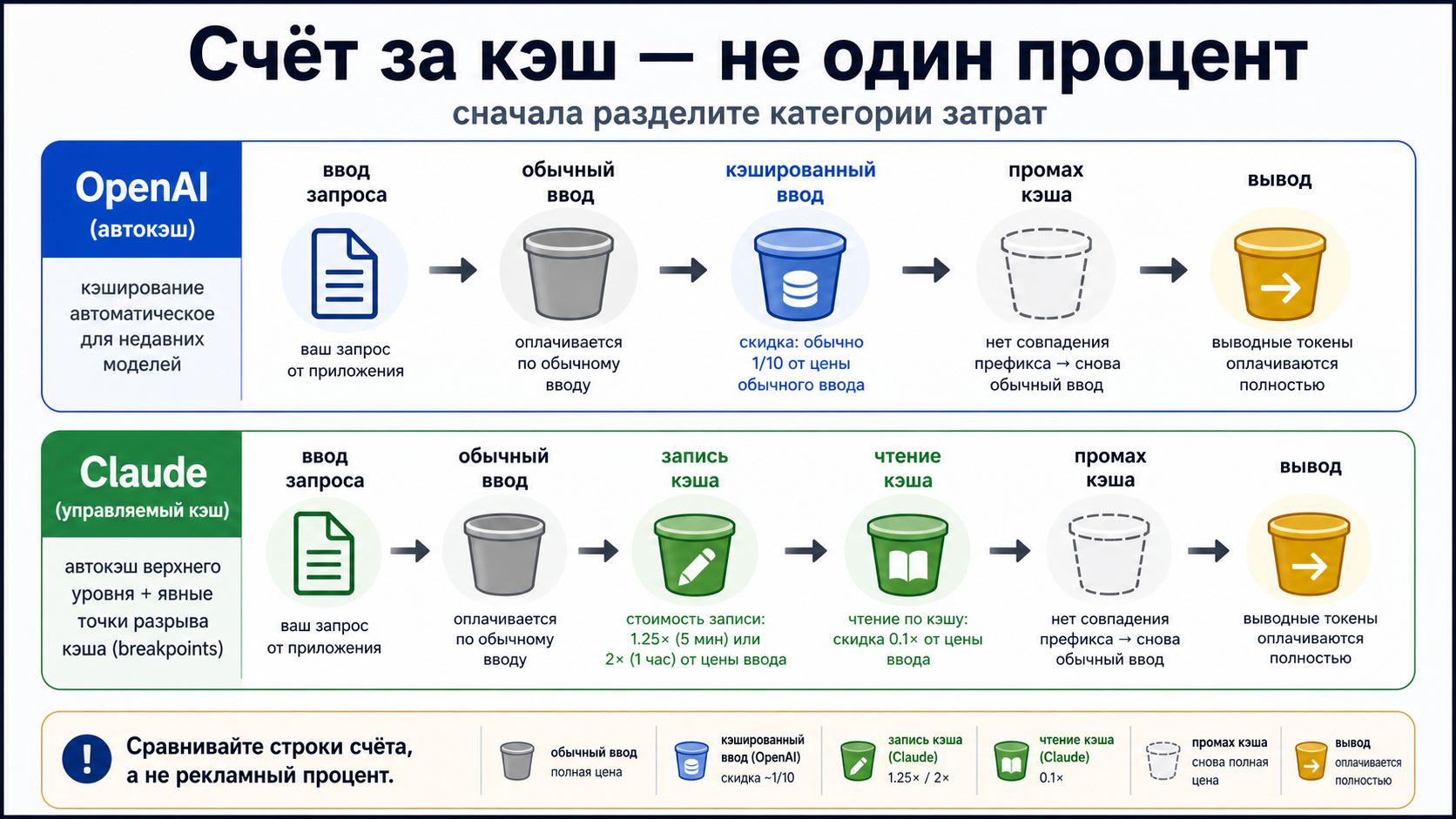
OpenAI использует привычную для счёта строку cached input. Если повторяемый префикс подходит под условия и совпадает, эта часть input оплачивается по более низкой строке. Отдельной строки «cache write» в текущей стандартной модели расчёта нет: первый запрос просто является обычным input, затем повторяемая часть может стать cached input.
Claude показывает больше бухгалтерии. Запись кэша — это отдельная стоимость создания или обновления кэшированного блока. Чтение кэша — отдельная дешёвая строка, когда последующий запрос действительно использует сохранённый блок. Новый input и output всё равно остаются в счёте. Поэтому Claude нельзя сравнивать с OpenAI одним числом: сначала нужно решить, сколько раз вы читаете один и тот же блок после записи.
| Категория | OpenAI | Claude | Практический смысл |
|---|---|---|---|
| Обычный input | miss, новый ввод, неподходящая часть запроса | новый ввод и miss | всегда может присутствовать |
| Запись кэша | отдельной premium-строки нет | 1.25x для 5 минут, 2x для 1 часа | первая стоимость Claude |
| Чтение кэша | cached input row | 0.1x от базового input | появляется только при hit |
| Промах кэша | возврат к обычному input | обычный input или новая запись | причина расхождения с прогнозом |
| Output | оплачивается отдельно | оплачивается отдельно | длинный ответ снижает видимую экономию |
Текущие цены как дата-снимок
Цены ниже не являются вечным справочником. Они нужны, чтобы понять механику расчёта на 2026-05-19. У OpenAI стандартный короткий контекст GPT-5.5 показывал $5 input, $0.50 cached input и $30 output за 1M tokens. GPT-5.4 показывал $2.50, $0.25 и $15. GPT-5.4 mini показывал $0.75, $0.075 и $4.50. Важный вывод: cached input в этих строках равен одной десятой от input, а write premium отдельно не указана.
У Claude модельная таблица устроена иначе. Opus 4.7, 4.6 и 4.5 показывали $5 input, $6.25 за 5-минутную запись, $10 за 1-часовую запись, $0.50 за чтение и $25 output. Sonnet 4.6 и 4.5 показывали $3, $3.75, $6, $0.30 и $15. Haiku 4.5 показывал $1, $1.25, $2, $0.10 и $5. Эти числа делают видно, почему одно и то же «90% дешевле при hit» не означает одинаковую стоимость первых запросов.
Перед внедрением цену нужно перепроверять. Pro-строки OpenAI могут не иметь той же cached input строки, cloud marketplace может менять правила, long-context pricing может отличаться, а enterprise/scale условия могут быть отдельным договором. Если бюджет важен, сохраняйте дату проверки прямо рядом с таблицей расчёта.
Пример повторяемого префикса
Представим 100k tokens стабильного префикса и 10 запросов подряд. Для GPT-5.4 обычный input стоит $2.50 за 1M tokens, cached input — $0.25. Первый запрос с таким префиксом без hit будет стоить около $0.25 только за эту повторяемую часть. Затем 9 попаданий по 100k cached input будут стоить примерно $0.025 каждое, всего $0.225. Итого повторяемый input за 10 запросов — около $0.475, без нового input и output.
Для Claude Sonnet 4.6 с 5-минутным кэшем базовый input — $3 за 1M, запись — $3.75, чтение — $0.30. Первый 100k prefix write стоит примерно $0.375. Девять чтений стоят примерно $0.03 каждое, всего $0.27. Итого около $0.645, опять же без нового input и output. Если нужен 1-часовой TTL, первая запись дороже, но окно повторного использования длиннее. Этот расчёт не выбирает победителя; он показывает, где находится первая стоимость и где начинается экономия.

Layout промпта важнее обещанной скидки
Кэширование работает не потому, что два запроса «похожи по смыслу». Оно работает, когда повторяемая часть запроса совпадает так, как ожидает провайдер. В OpenAI стабильные части лучше держать в начале: system prompt, tools, политики, схемы, справочники, few-shot примеры. Время, user id, случайный trace id, свежие результаты поиска и другие динамические данные должны идти после стабильного блока. prompt_cache_key может помочь маршрутизации для частых префиксов, но он не заменяет чистый layout и проверку cached_tokens.
У Claude дисциплина ещё строже. Кэш строится относительно порядка tools, system и messages до cache breakpoint. Если ранний блок меняется, последующий кэш становится менее полезным. Поэтому для Claude полезно думать слоями: сначала неизменные tools, затем стабильный system, затем большой контекст, затем изменяемый пользовательский ввод. Ошибка в раннем слое превращает дешёвое чтение в новую запись или обычный input.
Что логировать перед тем, как верить экономии
Для OpenAI минимальный сигнал — usage.prompt_tokens_details.cached_tokens. Ноль в этом поле означает, что вы не должны считать cached input в этой конкретной просьбе. Рядом нужно сохранить model, endpoint, request_id, total input, output, prefix hash, версию system prompt и, если используется, prompt_cache_key. Так вы сможете отличить проблему цены от проблемы совпадения префикса.
Для Claude одной цифры мало. cache_creation_input_tokens показывает стоимость создания или обновления кэша. cache_read_input_tokens показывает чтение существующего кэша. input_tokens показывает свежую часть запроса. Если вы смотрите только total input, то не поймёте, была ли просьба hit, write, miss или смесь нескольких состояний.

Рабочая таблица логов должна включать provider, model, endpoint, prefix_hash, cache policy, cache read, cache creation, normal input, output tokens, request latency, retry count и invoice period. Через день такого логирования обычно уже видно, стоит ли перестраивать prompt layout ради кэша или экономия слишком мала.
Модификаторы цены и лимиты
Base price — только начало. Batch может снизить цену, но меняет latency и workflow. Scale Tier или enterprise pricing могут иметь собственную экономику. Data residency и cloud marketplace могут изменить итоговую стоимость. Long context rows могут отличаться от short context rows. Claude 1-hour TTL дороже при записи, но лучше для длинного окна. OpenAI extended retention нужно проверять по поддерживаемым моделям.
Лимиты тоже разные. OpenAI указывает, что cached tokens всё равно учитываются в TPM, поэтому меньшая цена input не означает автоматический рост пропускной способности. У Claude документация описывает отдельные эффекты кэша на rate limit в некоторых режимах. Для production-системы рядом с cost model должна быть capacity model: requests per minute, input tokens, cache read tokens, output tokens, retries и errors.
Когда выбирать OpenAI
OpenAI разумнее первым тестировать, когда префикс стабилен, достаточно длинен и вам не нужно управлять несколькими cache segments. Это похоже на хороший путь для customer support bot, product policy assistant, batch analysis с одинаковой схемой, agent workflow с фиксированным набором tools или сервиса, где система уже отправляет один и тот же большой system prompt.
Но OpenAI не должен становиться магической скидкой. Если запрос короче порога, если модель не поддерживает нужный режим, если первые токены отличаются, если output огромный или если трафик распределён так, что hit rate низкий, итоговая экономия будет скромной. Сначала доказательство в usage field, потом прогноз годового бюджета.
Когда выбирать Claude
Claude подходит, когда контроль важнее простоты. Явные breakpoints полезны в agent workflow, где есть большой набор tools, стабильный system layer, длинная codebase summary и несколько типов пользовательских сообщений. Prewarming может быть полезен, если вы заранее знаете, что один и тот же контекст будет использоваться в серии шагов.
Цена за этот контроль — больше дисциплины. Нужно считать write отдельно, выбирать TTL, отслеживать invalidation hierarchy и не смешивать динамические данные с ранними блоками. Если команда не готова логировать cache_creation_input_tokens и cache_read_input_tokens, Claude будет казаться дешевле в теории, чем в счёте.
Практический чеклист внедрения
- Зафиксируйте стабильный prefix и перенесите динамические поля ниже.
- Считайте hash для версии prefix и сохраняйте его в каждом запросе.
- Для OpenAI проверяйте
cached_tokens, для Claude — creation/read/input fields. - Сравнивайте первый запрос и последующие hits в одном тесте.
- Считайте output tokens отдельно.
- При смене model, endpoint, TTL или price row пересчитывайте таблицу.
- Сверяйте estimated cost с invoice, а не только с локальным расчётом.
Если вам нужен общий контекст цен между OpenAI, Claude и Gemini, полезно читать обзор стоимости API-провайдеров. Эта статья уже уже: она объясняет только prompt caching billing и не заменяет выбор модели по качеству, latency или tool use.
Часто задаваемые вопросы
OpenAI prompt caching всё ещё даёт скидку 50%?
Не как универсальное правило. 50% часто встречается в старых материалах про GPT-4o/o1-era pricing. На дату проверки 2026-05-19 стандартные строки GPT-5.5, GPT-5.4 и GPT-5.4 mini показывали cached input как одну десятую от input. Всегда смотрите текущую price table.
Почему у Claude есть write cost?
Потому что Claude явно тарифицирует создание кэшированного блока. Первый запрос или обновление кэша может быть дороже обычного input, зато последующие чтения дешевле. Это делает контроль прозрачным, но требует расчёта окупаемости.
Output tokens получают скидку?
Нет. Prompt caching влияет на повторяемую входную часть запроса. Output tokens остаются отдельной строкой. Если ответы длинные, общая экономия в процентах будет ниже, чем скидка на input.
Можно ли полагаться на похожие prompts?
Нет. Нужен стабильный prefix, а не смысловая похожесть. Маленькое изменение в начале запроса может превратить hit в miss. Поэтому prefix hash и versioning важны.
Что значит cached_tokens = 0?
Для OpenAI это означает, что в данном ответе не было кэшированных input tokens. Причина может быть в длине, модели, layout, routing или изменении prefix. Сначала исправьте запрос, затем считайте экономию.
Claude automatic caching заменяет explicit cache control?
Не полностью. Текущая документация описывает автоматический верхнеуровневый вариант и явные breakpoints. Для сложных workloads explicit design всё ещё полезен, потому что вы решаете, какой слой должен пережить несколько запросов.
Нужно ли менять провайдера ради prompt caching?
Только если логи показывают длинный стабильный prefix, высокий hit rate, достаточное число повторов и контролируемый output cost. Иначе лучше сначала улучшить layout и наблюдаемость, а решение о провайдере принимать по фактической стоимости.