
Используйте GPT-5.4, когда результат зависит от более сильного reasoning, меньшего числа retries или значительно большего context window в 1.05M**. Используйте GPT-5.4 mini, когда нужен более дешевый, быстрый и high-volume default для coding, computer use и agent workflows.**
Это не migration story 'старое против нового'. Обе модели - текущие представители семейства GPT-5.4. Вопрос в том, сколько flagship headroom реально нужно вашему workflow и окупает ли себя этот дополнительный запас.
Краткое содержание
Если нужен один практический вывод, он такой:
- GPT-5.4 — для более сложной, длинной и дорогой по ошибке работы
- GPT-5.4 mini — для более дешёвого и более массового production-маршрута
| Категория | GPT-5.4 | GPT-5.4 mini | Практический вывод |
|---|---|---|---|
| Дата запуска | 5 марта 2026 | 17 марта 2026 | Обе модели свежие и актуальные |
| Текущая роль | Основной флагманский default | Маршрут для high-volume coding и agents | Это split по роли, а не по статусу |
| Input цена | $2.50 / 1M | $0.75 / 1M | GPT-5.4 примерно в 3.3 раза дороже |
| Cached input | $0.25 / 1M | $0.075 / 1M | Mini лучше для повторяющегося контекста |
| Output цена | $15.00 / 1M | $4.50 / 1M | Разница по цене существенная |
| Context window | 1,050,000 | 400,000 | GPT-5.4 заметно сильнее на long-context задачах |
| Knowledge cutoff | 31 августа 2025 | 31 августа 2025 | Это не история про свежесть знаний |
| Tool stack | Широкий Responses API tool surface | Тот же широкий tool surface | Mini не является tool-light моделью |
| Публичные top-tier caps | 15,000 RPM / 40,000,000 TPM | 30,000 RPM / 180,000,000 TPM | Mini заметно лучше подходит для масштаба |
Самое важное здесь не то, какая модель «лучше вообще», а то, что вы пытаетесь оптимизировать: качество и headroom или стоимость и throughput.
Настоящий раскол: флагманская headroom против дешёвого масштаба
Ошибка большинства быстрых обзоров в том, что они сравнивают эти модели так, будто одна просто заменяет другую по всем параметрам. На практике это не так.
GPT-5.4 имеет смысл там, где:
- длинный контекст реально нужен
- сложная многошаговая работа ломается от слабых промежуточных решений
- стоимость ошибки выше, чем стоимость дополнительных токенов
GPT-5.4 mini имеет смысл там, где:
- запросов много
- workers или subagents работают параллельно
- нужна современная tool-surface модель, но не хочется платить как за флагман каждый раз
Именно поэтому правильный вопрос не «какая сильнее?». Правильный вопрос — кому отдать premium-ветку, а кому production-ветку.
Какие бенчмарки реально двигают решение
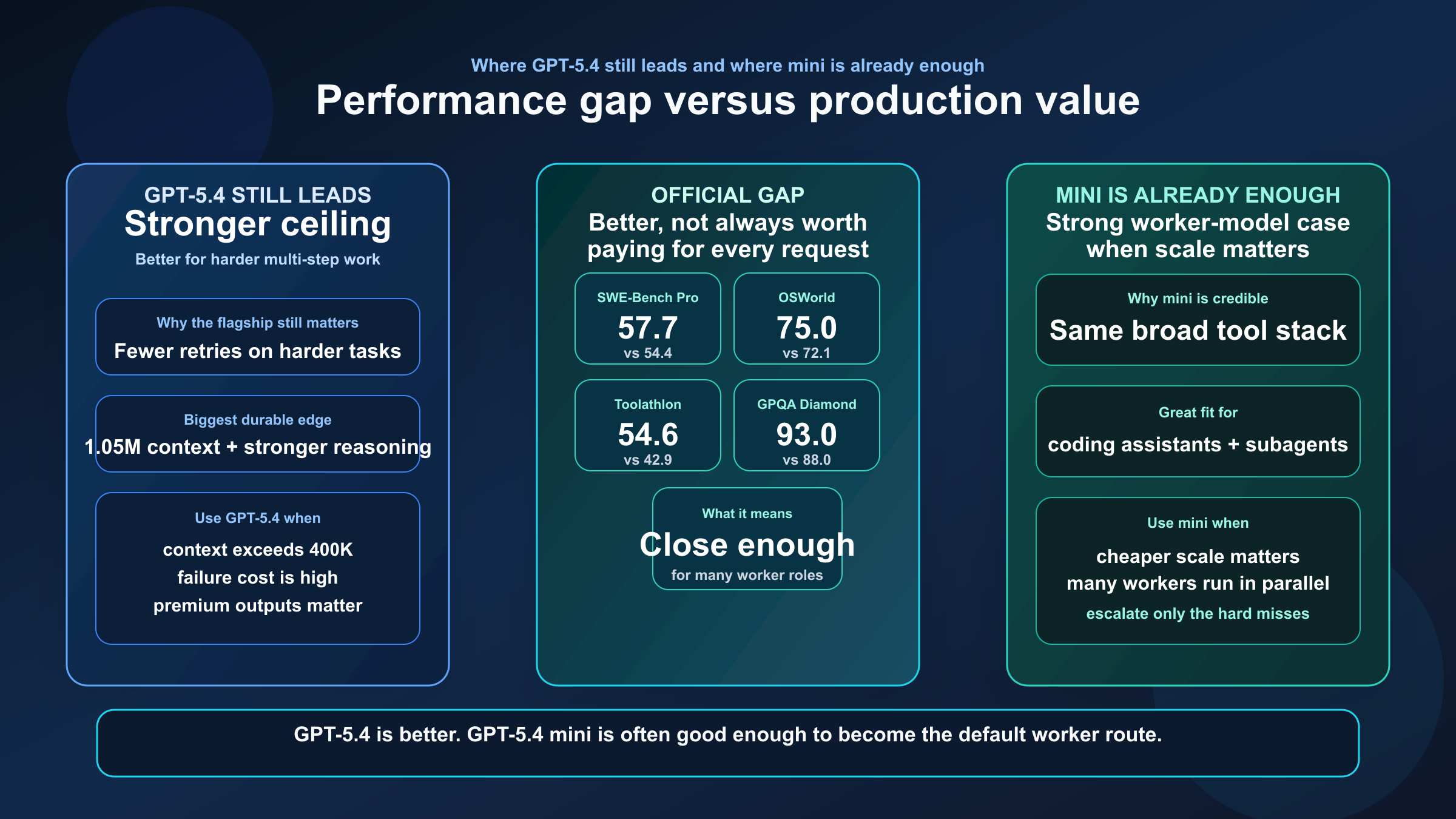
В официальном посте OpenAI о GPT-5.4 mini и nano есть наиболее полезная для этого сравнения таблица:
| Бенчмарк | GPT-5.4 | GPT-5.4 mini | Что это значит |
|---|---|---|---|
| SWE-Bench Pro | 57.7% | 54.4% | GPT-5.4 лучше, но mini остаётся очень близко |
| Terminal-Bench 2.0 | 75.1% | 60.0% | На длинных tool-heavy цепочках разрыв уже заметнее |
| Toolathlon | 54.6% | 42.9% | Флагман лучше держит сложные multi-tool сценарии |
| GPQA Diamond | 93.0% | 88.0% | У GPT-5.4 больше reasoning headroom |
| OSWorld-Verified | 75.0% | 72.1% | Для computer use mini уже достаточно сильна во многих production-сценариях |
Самое важное в этой таблице — не то, что GPT-5.4 выигрывает почти везде. Важно, что GPT-5.4 mini проигрывает не настолько сильно, чтобы автоматически выпадать из production-ветки.
Отсюда следуют три полезных вывода.
Первый: GPT-5.4 — действительно лучший вариант для более тяжёлой работы, но GPT-5.4 mini уже достаточно сильна, чтобы обслуживать большой слой coding- и agent-нагрузки.
Второй: разница особенно важна там, где workflow зависит от длинной многошаговой устойчивости, а не только от одного ответа. Именно поэтому GPT-5.4 удобнее ставить на более дорогие по ошибке ветки.
Третий: mini нельзя воспринимать как «урезанную low-end модель». В текущей линейке это уже полноценный production workhorse.
Практически это означает, что смотреть нужно не на абстрактную разницу в процентах, а на цену промаха в конкретной ветке workflow. Если ошибка ломает planner, оркестратор или длинную tool-heavy цепочку, запас GPT-5.4 окупается гораздо быстрее, чем кажется по одной строке pricing.
Но если ветка дешёво восстанавливается, легко повторяется и не тянет за собой дорогую ручную проверку, то mini часто оказывается выгоднее даже с учётом дополнительных ретраев. Поэтому реальный выбор здесь почти всегда упирается в архитектуру системы, а не в вопрос "какая модель красивее выглядит в таблице".
Если вы хотите сравнить mini ещё и с более старой бюджетной веткой OpenAI, посмотрите GPT-5.4 mini vs GPT-5 mini.
Цена, контекст и публичные limits: где разница ощущается сильнее всего

Текущая страница GPT-5.4 указывает:
- $2.50 за 1M input tokens
- $0.25 за 1M cached input tokens
- $15.00 за 1M output tokens
- context window 1,050,000
Текущая страница GPT-5.4 mini указывает:
- $0.75 за 1M input tokens
- $0.075 за 1M cached input tokens
- $4.50 за 1M output tokens
- context window 400,000
То есть по всем основным ценовым строкам GPT-5.4 примерно в 3.3 раза дороже mini. Это серьёзный разрыв. Для high-volume production он быстро становится главным аргументом.
Но у GPT-5.4 есть и реальное преимущество: 1.05M контекста. Если ваш workflow держит большие репозитории, длинные документы, большие наборы спецификаций и долгие сессии, этот запас реально снижает давление на compaction и обрезку контекста.
Есть и важный caveat, который многие слабые обзоры пропускают. Текущая страница GPT-5.4 также пишет, что для запросов выше 272K input tokens вся сессия считается по схеме 2x input и 1.5x output. То есть огромный контекст — это premium-возможность, а не бесплатный бонус.
Ещё одна вещь, которую часто недооценивают: текущие публичные top-tier caps у GPT-5.4 mini заметно выше. Именно это делает её очень сильным вариантом для workers, subagents и высокообъёмной production-нагрузки.
И наконец, важное уточнение: обе модели сейчас имеют одинаковый knowledge cutoff — 31 августа 2025. Поэтому здесь не нужно придумывать историю про «mini слишком устарела». Реальные различия — в цене, контексте, throughput и качестве на сложной работе.
Есть полезное правило для команды: считать не цену токена, а цену завершённой задачи. Если mini в среднем требует немного больше повторов, но позволяет дешевле прогонять большие очереди background-работы, то она всё равно выигрывает как default-маршрут для масштаба.
И наоборот, если вы каждый раз грузите огромный контекст, долго держите сессию и требуете устойчивости на нескольких шагах подряд, GPT-5.4 начинает выглядеть не как дорогая прихоть, а как страховка от более дорогих операционных сбоев. Это особенно заметно в repo-analysis, agent orchestration и customer-facing ветках.
Инструменты: mini — это не урезанная tool-модель
Это один из самых важных пунктов для практического выбора.
По текущим model pages и GPT-5.4, и GPT-5.4 mini поддерживают широкий Responses API tool surface:
- web search
- file search
- image generation
- code interpreter
- hosted shell
- apply patch
- skills
- computer use
- MCP
- tool search
Поэтому сравнение нельзя сводить к схеме «GPT-5.4 умеет работать с инструментами, а mini — нет». Правильнее так:
- GPT-5.4 даёт более высокий потолок качества на тяжёлых задачах
- GPT-5.4 mini даёт очень похожую продуктовую поверхность, но гораздо лучшее экономическое положение
Именно из-за этой близости surface выбор приходится делать не по названию модели, а по экономике и реальной цене ошибок.
Это и есть причина, почему простая покупка "модели по престижу" обычно работает хуже, чем явное routing-правило. Когда surface почти совпадает, главный вопрос смещается с доступности инструмента на то, где именно вам нужен больший запас рассуждения и устойчивости.
Когда стоит платить за GPT-5.4
GPT-5.4 оправдана там, где качество выигрывает у цены.
Это обычно такие сценарии:
- анализ больших кодовых баз и длинных контекстов
- planner-ветка или оркестратор в агентной системе
- сложные технические задачи с дорогой ошибкой
- customer-facing или business-critical outputs
- всё, что часто разваливается, если модель слишком слаба на промежуточных шагах
Хорошее практическое правило: если ошибка mini приводит к дорогому повтору, ручной проверке или сломанной цепочке, то GPT-5.4 часто оказывается дешевле в общем operational sense, даже если у неё дороже токены.
Если вы сравниваете GPT-5.4 не с mini, а с предыдущим flagship-слоем, полезно дополнительно посмотреть GPT-5.4 vs GPT-5.2.
Когда GPT-5.4 mini — более умный default
GPT-5.4 mini выигрывает там, где bottleneck — это масштаб, а не максимальная single-request quality.
Лучшие сценарии для mini:
- subagent workers
- coding assistants с большим объёмом запросов
- screenshot-heavy computer use loops
- фоновые пайплайны, review и triage
- production-нагрузка, где важно не платить флагманскую цену за каждую задачу
Именно поэтому для многих команд лучшая схема выглядит так:
- GPT-5.4 для planner, escalation и более сложных веток
- GPT-5.4 mini для workers
Это намного лучше соответствует текущему позиционированию OpenAI, чем попытка выбрать один-единственный default на все случаи.
API и Codex против ChatGPT-поверхности
С API и Codex всё относительно чисто:
- GPT-5.4 — main default
- GPT-5.4 mini — smaller / faster / cheaper branch
С ChatGPT всё менее симметрично. В текущих release notes ChatGPT указано, что по состоянию на 18 марта 2026 года GPT-5.4 mini начала появляться как Thinking-путь для Free и Go, а для многих платных пользователей — как fallback для GPT-5.4 Thinking. При этом mini не показывается как обычная selectable модель в picker.
Это важно, потому что многие пользователи пытаются выводить API-решение из того, что они видят в ChatGPT. Так делать не стоит. Это разные поверхности и разные правила.
Практическая схема маршрутизации для команды
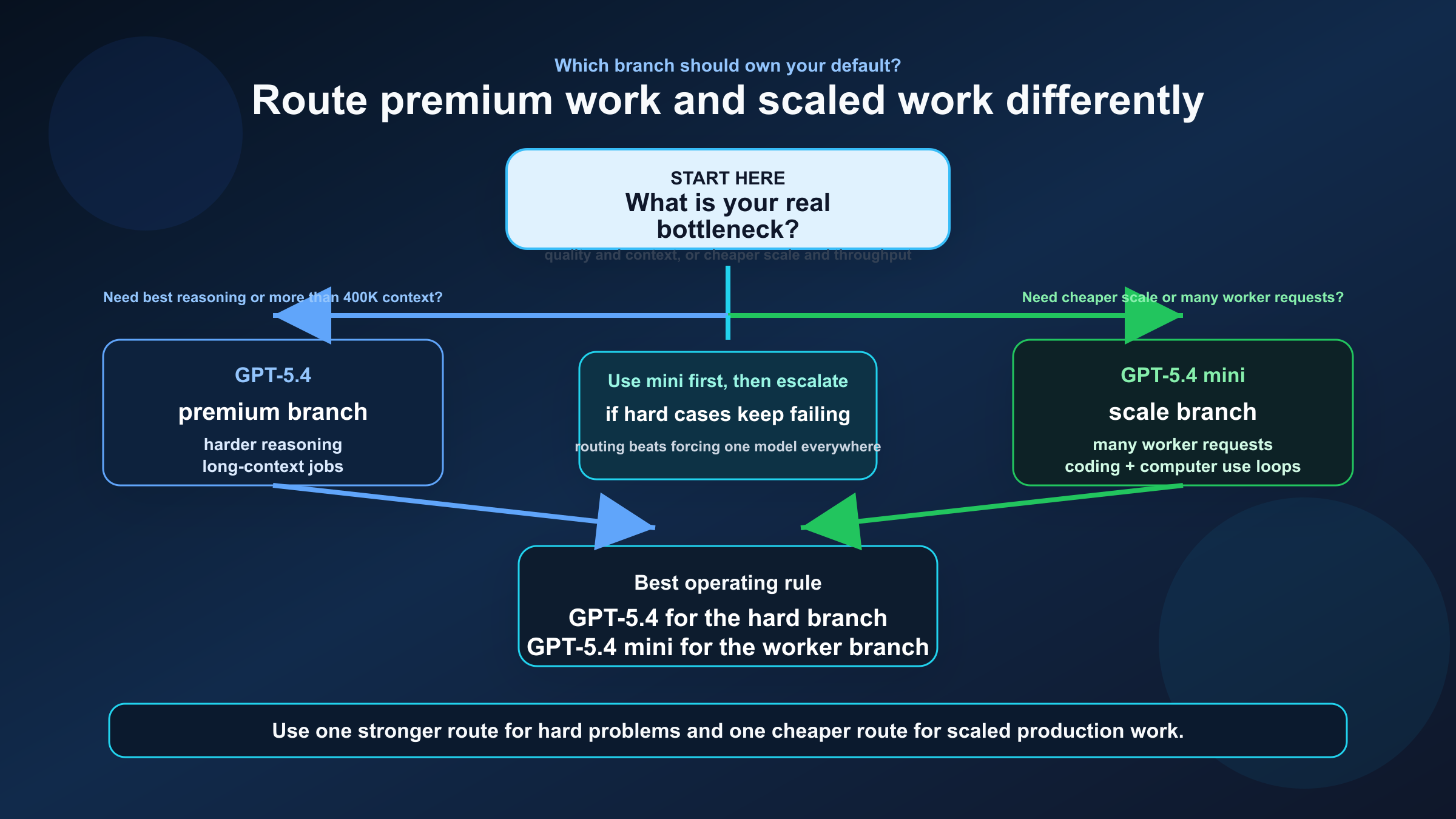
Если вам нужна одна рабочая политика, берите эту:
| Нагрузка | Default модель | Почему | Когда переключать |
|---|---|---|---|
| Long-context repo analysis | GPT-5.4 | Больше контекст и лучше quality headroom | Переключайте на mini только если задача уверенно помещается в 400K и бюджет критичен |
| Planner / orchestration branch | GPT-5.4 | Лучше для сложных многошаговых решений | Только если planner очень лёгкий и cost-sensitive |
| Worker / subagent branch | GPT-5.4 mini | Лучше economics и throughput | Эскалируйте в GPT-5.4 на тяжёлых кейсах |
| Coding assistant at scale | GPT-5.4 mini | Сильна и при этом существенно дешевле | Для сложных веток review и repair поднимайте до GPT-5.4 |
В большинстве реальных систем самая чистая схема — не «одна модель для всего», а одна более сильная ветка для сложной работы и одна более дешёвая ветка для масштабируемой работы.
На практике удобно формализовать это как политику эскалации. Всё, что требует длинного контекста, сложного plan-and-execute и дорогой проверки, сразу уходит в GPT-5.4. Всё, что относится к дешёвым workers, фоновой обработке, triage и массовому coding assistance, остаётся на GPT-5.4 mini.
Так команда перестаёт спорить о модели на уровне вкуса и начинает оперировать понятными критериями: сложность ветки, стоимость ошибки, размер контекста и ожидаемый объём. Для production это почти всегда полезнее, чем пытаться выбрать один-единственный default для всего трафика.
FAQ
Достаточно ли GPT-5.4 mini для серьёзных coding agents?
Во многих случаях да. По официальной таблице она уже близка к GPT-5.4 на SWE-Bench Pro и OSWorld-Verified, а стоит существенно дешевле и лучше подходит для high-volume использования.
Есть ли у GPT-5.4 mini заметно меньше инструментов?
По текущим model pages — нет. И GPT-5.4, и GPT-5.4 mini указывают одинаково широкий tool surface. Разница в ceiling, context и economics, а не в самой поверхности продукта.
Стоит ли GPT-5.4 своих денег?
Да, если большая контекстная голова и более сильный reasoning реально меняют исход задачи. Нет, если ваш workload в основном про дешёвую массовую обработку, и mini уже справляется достаточно хорошо.
Является ли 1.05M context главным аргументом за GPT-5.4?
Это один из самых сильных аргументов, но не единственный. Не менее важно, что GPT-5.4 держит более высокий потолок на тяжёлой tool-heavy работе.
Что выбрать для Codex-style subagents?
Для многих subagent-ролей — GPT-5.4 mini. Для более сложного planner или escalation branch — GPT-5.4.
Нужно ли сразу переводить весь трафик на GPT-5.4 mini ради экономии?
Не стоит делать это вслепую. Сначала лучше выделить ветки, где цена ошибки действительно низкая, и перевести именно их. Тогда экономия будет заметной, а риск деградации — управляемым.
Если нужен один итог в рабочем формате, то он такой: GPT-5.4 отвечает за сложную и более дорогую по ошибке ветку, а GPT-5.4 mini — за дешёвую и масштабируемую production-ветку.
Именно так эта пара моделей и читается на практике: не как битва за один глобальный default, а как разделение ролей внутри одной рабочей системы.