
Выбор между GPT 5.2 Codex и Claude Opus 4.5 стал одним из ключевых решений для разработчиков в 2026 году. Обе модели представляют вершину развития генеративного ИИ для программирования, но каждая имеет свои сильные стороны. По данным официальных бенчмарков, Claude Opus 4.5 лидирует в реальных задачах кодирования с результатом 80.9% на SWE-bench Verified, в то время как GPT 5.2 Codex демонстрирует превосходство в математическом рассуждении с идеальными 100% на AIME 2025. В этом руководстве мы разберём все ключевые различия, чтобы вы могли сделать осознанный выбор.
Краткое содержание
Для тех, кто торопится, вот основные выводы нашего сравнения:
- Claude Opus 4.5 лидирует в практическом кодировании (SWE-bench: 80.9%), терминальных операциях (59.3%) и безопасности (99.78% отказов вредоносных запросов)
- GPT 5.2 Codex доминирует в математике (AIME 2025: 100%), абстрактном мышлении (ARC-AGI-2: 52.9%) и работе со сложными логическими задачами
- По стоимости GPT 5.2 дешевле на входе ($1.75/1M токенов vs $5/1M), но Claude более токен-эффективен
- Для снижения затрат до 84% можно использовать API-агрегаторы
- Выбирайте Claude для повседневного кодинга и рефакторинга
- Выбирайте GPT для сложных алгоритмических задач и математических расчётов
Сравнение бенчмарков
Понимание реальных возможностей каждой модели начинается с анализа бенчмарков. Оба производителя — OpenAI и Anthropic — проводят тестирование на стандартизированных наборах данных, что позволяет провести объективное сравнение.
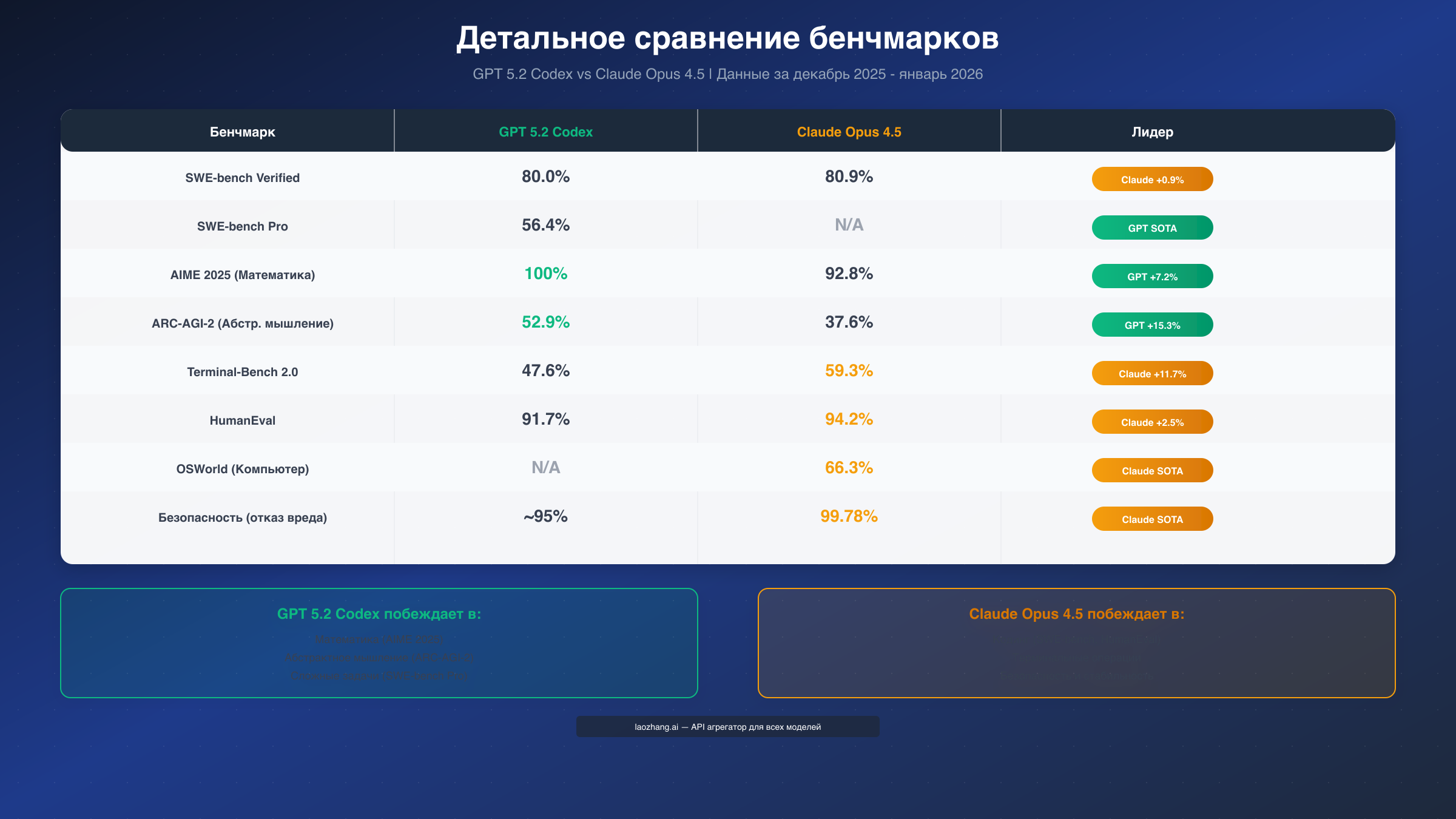
SWE-bench Verified остаётся золотым стандартом для оценки способностей ИИ решать реальные задачи программирования. Этот бенчмарк содержит 500 реальных issue из популярных GitHub-репозиториев, и модель должна не просто написать код, а исправить конкретную проблему в существующей кодовой базе. Claude Opus 4.5 достиг результата 80.9%, став первой моделью, преодолевшей порог в 80%. GPT 5.2 Codex показывает 80.0% — разница в 0.9 процентных пункта находится в пределах статистической погрешности, но символически важна.
Более сложный SWE-bench Pro включает задачи повышенной сложности на четырёх языках программирования. Здесь GPT 5.2 Codex устанавливает новый рекорд с результатом 56.4%, значительно опережая предыдущие модели. Anthropic не публикует результаты Claude на этом бенчмарке, что может указывать либо на недостаточную производительность, либо на стратегическое решение не конкурировать в этой категории.
Terminal-Bench 2.0 оценивает способность модели работать в терминальных средах — выполнять команды, навигировать по файловой системе и автоматизировать задачи. Claude Opus 4.5 демонстрирует явное преимущество с 59.3% против 47.6% у GPT 5.2. Эта разница в 11.7 процентных пунктов — самая большая среди всех основных бенчмарков и критически важна для разработчиков, работающих с DevOps и автоматизацией.
| Бенчмарк | GPT 5.2 Codex | Claude Opus 4.5 | Лидер |
|---|---|---|---|
| SWE-bench Verified | 80.0% | 80.9% | Claude +0.9% |
| SWE-bench Pro | 56.4% | N/A | GPT (SOTA) |
| Terminal-Bench 2.0 | 47.6% | 59.3% | Claude +11.7% |
| HumanEval | 91.7% | 94.2% | Claude +2.5% |
| OSWorld | N/A | 66.3% | Claude (SOTA) |
Для понимания практической значимости этих цифр важно учитывать контекст. Согласно тестированию на реальном проекте с 50K+ строк кода, опубликованному на DEV Community (https://dev.to/tensorlake/claude-opus-45-vs-gpt-52-high-vs-gemini-3-pro-production-coding-test-25of ), Claude Opus 4.5 показал наиболее стабильные результаты, выполняя задачи за 7-8 минут со стоимостью $0.94-$1.78 за задачу. GPT 5.2 требовал 20-26 минут на аналогичные задачи, но демонстрировал более высокое качество архитектурных решений.
Возможности кодирования
Способность модели писать качественный код — это не только про бенчмарки, но и про практический опыт использования. Разработчики, активно использующие обе модели, отмечают существенные различия в подходах к генерации кода.
Claude Opus 4.5 известен своим «инженерным» подходом к написанию кода. Модель генерирует хорошо документированные решения с чёткой структурой, что делает её особенно полезной для обучения и ревью кода. По данным тестирования, Opus 4.5 показывает 22 ошибки управления потоком на миллион строк кода (MLOC) — лучший результат среди современных моделей. Кроме того, Claude лидирует в многоязычном программировании, показывая лучшие результаты в 7 из 8 тестируемых языков на SWE-bench Multilingual.
Особую силу Claude демонстрирует в работе с терминалом и компьютером. OSWorld — бенчмарк, оценивающий способность ИИ управлять десктопным интерфейсом — показывает результат 66.3% для Claude Opus 4.5. Это делает модель идеальным выбором для автоматизации задач, требующих взаимодействия с различными приложениями.
GPT 5.2 Codex занимает нишу «продакшн-готового» генератора кода. Согласно исследованию Sonar (https://www.sonarsource.com/blog/new-data-on-code-quality-gpt-5-2-high-opus-4-5-gemini-3-and-more/ ), модель демонстрирует минимальную плотность ошибок при работе с конкурентным кодом и сложными асинхронными паттернами. Контекстное окно в 400K токенов позволяет работать с крупными кодовыми базами без потери контекста.
Ключевое преимущество GPT 5.2 Codex — его способность находить проблемы. Разработчики на Hacker News отмечают, что «Codex невероятно хорош в поиске багов и мелких несоответствий... где Claude Code хорош в "сыром кодинге", Codex/GPT5.x непревзойдён в тщательном, методичном поиске проблем».
Для понимания API-доступа полезно знать, что оба производителя предлагают различные варианты подключения. Если вас интересуют уровни API OpenAI, мы подготовили отдельное руководство с подробностями о лимитах и ценах на разных уровнях.
Практическая рекомендация: Используйте Claude для написания нового кода и рефакторинга, где важна читаемость и документация. Переключайтесь на GPT для отладки, оптимизации и работы с legacy-кодом, где критичен поиск скрытых проблем.
Математика и рассуждения
Если ваша работа связана с алгоритмами, научными вычислениями или сложными логическими задачами, выбор между моделями становится более очевидным.
GPT 5.2 демонстрирует впечатляющие результаты в математических бенчмарках. Модель достигает 100% на AIME 2025 (American Invitational Mathematics Examination) без использования внешних инструментов — это означает идеальное решение всех олимпиадных задач по математике. Claude Opus 4.5 показывает 92.8% на том же тесте, что также является отличным результатом, но уступает GPT.
Ещё более показательным является ARC-AGI-2 — бенчмарк абстрактного рассуждения, разработанный для оценки способности к обобщению и переносу знаний. GPT 5.2 набирает 52.9-54.2%, почти вдвое превосходя Claude Opus 4.5 с его 37.6%. Этот разрыв указывает на фундаментальные различия в архитектуре моделей и их способности к абстрактному мышлению.
GPQA Diamond — бенчмарк задач уровня аспирантуры по физике, химии и биологии — показывает результат 93.2% для GPT 5.2 Pro, что практически совпадает с 93.8% у Gemini 3 Deep Think. Это свидетельствует о том, что GPT 5.2 является одним из лучших инструментов для научных исследований и академической работы.
| Категория | GPT 5.2 | Claude Opus 4.5 | Разница |
|---|---|---|---|
| AIME 2025 (математика) | 100% | 92.8% | GPT +7.2% |
| ARC-AGI-2 (абстракция) | 52.9% | 37.6% | GPT +15.3% |
| GPQA Diamond (наука) | 93.2% | ~88% | GPT +5% |
При этом важно понимать контекст этих результатов. Режим «Thinking» в GPT 5.2 использует до 57K токенов на рассуждение, что существенно увеличивает стоимость сложных задач. Claude Opus 4.5 предлагает аналогичный режим с настраиваемым «effort» параметром, позволяющим балансировать между качеством и стоимостью.
Практический совет: Для математически интенсивных задач — оптимизационных алгоритмов, научных вычислений, криптографии — GPT 5.2 является объективно лучшим выбором. Claude лучше подходит для задач, где требуется понимание контекста и работа с естественным языком в сочетании с кодом.
Цены и оптимизация затрат
Стоимость использования ИИ-моделей — критический фактор для индивидуальных разработчиков и небольших команд. Официальные цены обоих производителей существенно различаются, но итоговая стоимость зависит от многих факторов.
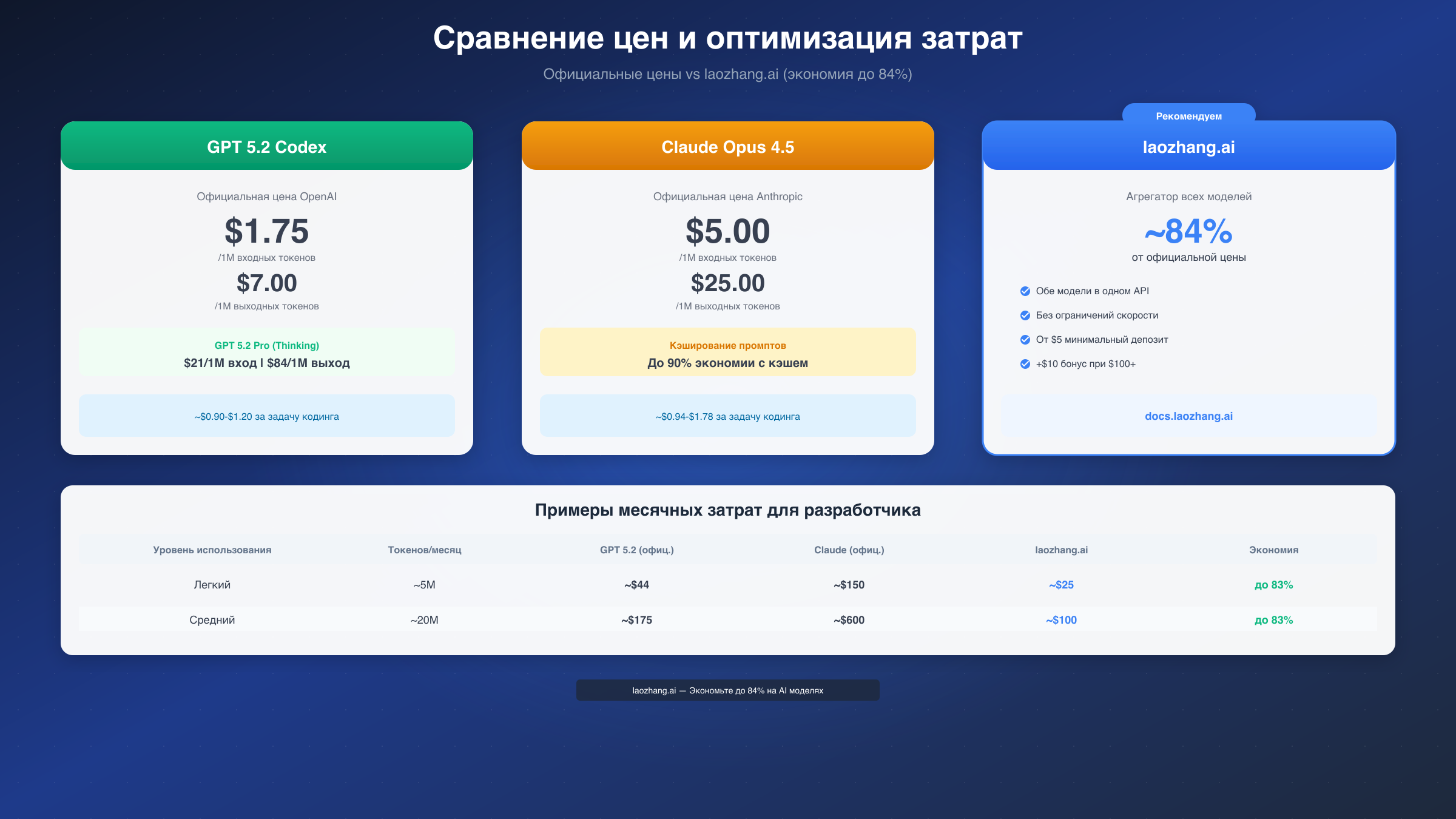
GPT 5.2 Codex предлагает базовую цену $1.75 за миллион входных токенов и $7.00 за миллион выходных. Это делает его одним из наиболее доступных frontier-моделей на рынке. Однако версия GPT 5.2 Pro с режимом Thinking стоит $21 за вход и $84 за выход, что значительно увеличивает затраты при решении сложных задач.
Claude Opus 4.5 имеет официальную цену $5 за миллион входных и $25 за миллион выходных токенов — примерно в 2.8 раза дороже базового GPT 5.2. Однако Anthropic предлагает существенные скидки: до 90% экономии с кэшированием промптов и 50% при пакетной обработке.
Интересный момент заключается в токен-эффективности. Согласно независимым тестам, Claude Opus 4.5 генерирует тот же результат примерно на 76% меньшим количеством токенов. Это означает, что фактическая стоимость выполнения задачи может быть сопоставимой, несмотря на разницу в номинальных ценах.
| Метрика | GPT 5.2 Codex | Claude Opus 4.5 |
|---|---|---|
| Вход (1M токенов) | $1.75 | $5.00 |
| Выход (1M токенов) | $7.00 | $25.00 |
| Стоимость задачи | $0.90-$1.20 | $0.94-$1.78 |
| Экономия с кэшем | - | до 90% |
Для существенного снижения затрат можно использовать API-агрегаторы. Платформа laozhang.ai предлагает доступ к обеим моделям по ценам примерно на 84% ниже официальных. Минимальный депозит составляет $5 (около 35 рублей), а при пополнении на $100 вы получаете бонус $10. Все модели доступны через единый API без ограничений скорости, что удобно для интенсивного использования.
Если вас интересует бесплатный доступ к API, рекомендуем ознакомиться с нашим руководством по бесплатному неограниченному API ChatGPT, где описаны легальные способы получения бесплатных кредитов.
Рекомендация по выбору тарифа: Для индивидуальных разработчиков с умеренным использованием (до 5M токенов/месяц) API-агрегаторы позволят сэкономить ~$100-120 ежемесячно по сравнению с официальными ценами. Для команд с интенсивным использованием экономия может достигать нескольких тысяч долларов.
Безопасность и производительность
В enterprise-среде безопасность и надёжность модели зачастую важнее сырой производительности. Оба производителя уделяют серьёзное внимание этим аспектам, но с разными акцентами.
Claude Opus 4.5 устанавливает новый стандарт безопасности. Модель достигает 99.78% уровня безопасных ответов на одиночные вредоносные запросы на всех тестируемых языках — это лучший результат среди всех существующих моделей. В агентных сценариях, где риски выше из-за цепочек действий, Claude отказывает 88.39% вредоносных запросов по сравнению с 66.96% у предыдущей версии Claude Opus 4.1.
Anthropic использует подход Constitutional AI, обучая модель следовать набору принципов, а не просто избегать определённых слов или тем. Это обеспечивает более устойчивую защиту от jailbreak-атак и делает модель предсказуемой в корпоративных сценариях.
GPT 5.2 Codex выделяется расширенными возможностями кибербезопасности. Модель достигает 79% успеха на сценариях Network Attack Simulation и 80% на Vulnerability Research and Exploitation. OpenAI позиционирует это как преимущество для defensive security — команд, занимающихся защитой инфраструктуры. При этом компания признаёт двойственность этих возможностей и внедряет специальные ограничения для предотвращения злоупотреблений.
Контекстное окно у моделей различается: GPT 5.2 поддерживает до 400K токенов, что достаточно для работы с крупными кодовыми базами. Claude Opus 4.5 предлагает меньшее окно, но компенсирует это более эффективной компрессией контекста.
С точки зрения времени отклика, GPT 5.2 Codex в стандартном режиме работает быстрее (7-8 минут на сложную задачу против 20-26 минут в режиме Thinking). Claude Opus 4.5 показывает среднее время около 8 минут с более стабильным качеством результатов.
Для enterprise-применения: Claude Opus 4.5 предпочтительнее благодаря лучшим показателям безопасности и предсказуемости поведения. GPT 5.2 Codex подходит для security-команд, где расширенные возможности анализа уязвимостей являются преимуществом.
Какую модель выбрать
После анализа всех аспектов, выбор между моделями сводится к вашим конкретным задачам и приоритетам. Вот практические рекомендации для различных сценариев.
Выбирайте Claude Opus 4.5, если:
Вы занимаетесь повседневной разработкой — написанием новых функций, рефакторингом, code review. Claude демонстрирует лучшие результаты в типичных задачах кодирования и генерирует более читаемый, документированный код. Это особенно важно в командной работе, где код должен быть понятен другим разработчикам.
Ваша работа связана с DevOps и автоматизацией. Преимущество в 11.7% на Terminal-Bench означает практически ощутимую разницу при написании скриптов и работе с командной строкой.
Вам нужен AI-агент для компьютерного управления. OSWorld с результатом 66.3% показывает, что Claude лучше справляется с задачами, требующими взаимодействия с GUI.
Безопасность критична. Показатель 99.78% безопасных ответов делает Claude предпочтительным выбором для enterprise-применений и проектов с высокими требованиями к compliance.
Если вы решили использовать Claude, наше руководство по установке Claude Code поможет быстро начать работу с инструментом для командной строки.
Выбирайте GPT 5.2 Codex, если:
Ваша работа связана с алгоритмами и математикой. Идеальные 100% на AIME 2025 и лидерство в ARC-AGI-2 делают GPT безальтернативным выбором для научных вычислений, оптимизационных задач и криптографии.
Вам нужен глубокий анализ и отладка. Способность GPT методично находить проблемы в коде — его главное конкурентное преимущество в реальных сценариях использования.
Вы работаете со сложными legacy-системами. Контекстное окно в 400K токенов позволяет анализировать крупные кодовые базы без потери контекста.
Бюджет ограничен. При базовой цене $1.75/1M токенов GPT 5.2 Codex остаётся одной из самых доступных frontier-моделей.
Оптимальная стратегия: Для большинства разработчиков лучший результат достигается комбинированным использованием. Используйте Claude для написания нового кода и архитектурных решений, переключайтесь на GPT для отладки, оптимизации и сложных алгоритмических задач. API-агрегаторы упрощают переключение между моделями через единый интерфейс.
FAQ
Какая модель лучше для начинающего разработчика?
Claude Opus 4.5 лучше подходит для обучения благодаря подробным объяснениям и хорошо документированному коду. Модель ведёт себя как «старший инженер», что помогает понять паттерны реализации. GPT 5.2 более лаконичен и ориентирован на продакшн-результат.
Можно ли использовать обе модели через один API?
Да, платформа laozhang.ai предоставляет единый API для доступа к обеим моделям и многим другим. Это позволяет легко переключаться между моделями в зависимости от задачи и экономить до 84% на стоимости по сравнению с официальными ценами. Подробности на docs.laozhang.ai.
Какая модель быстрее генерирует код?
В стандартном режиме GPT 5.2 Codex показывает скорость генерации на 23% выше. Однако Claude Opus 4.5 более стабилен — его результаты требуют меньше доработок, что компенсирует разницу в скорости на практике.
Как часто обновляются модели?
OpenAI выпустила GPT 5.2 Codex 18 декабря 2025 года, спустя 24 дня после релиза Claude Opus 4.5 (24 ноября 2025). Оба производителя планируют регулярные обновления, но конкретные даты не анонсируются. Рекомендуется следить за официальными блогами OpenAI и Anthropic.
Какую модель выбрать для стартапа с ограниченным бюджетом?
Для стартапов рекомендуется начать с GPT 5.2 Codex из-за более низкой базовой стоимости ($1.75 vs $5 за 1M входных токенов). По мере роста можно подключить Claude для специфических задач. Использование laozhang.ai позволит сэкономить до 84% бюджета на AI, что критично для early-stage стартапов.