
По состоянию на февраль 2026 года ландшафт ИИ кардинально изменился: три фронтирные модели вышли в течение одной недели. Claude Opus 4.6 лидирует на SWE-bench с результатом 79,4% и предлагает глубочайшие возможности рассуждения по цене $5/MTok на входе (Anthropic, проверено 12 февраля 2026 г.). GPT-5.3 Codex доминирует на Terminal-Bench 2.0 с показателем 77,3% и обеспечивает самый быстрый опыт кодирования по цене примерно $1,75/MTok (OpenAI, проверено 12 февраля 2026 г.). А GLM-5 — новичок с открытым исходным кодом от Zhipu AI — демонстрирует конкурентоспособный результат 77,8% на SWE-bench всего за $0,11/MTok при полной лицензии MIT. Это первое комплексное сравнение трёх моделей, и оно поможет вам принять конкретное решение вместо привычного «у каждой свои преимущества».
Краткое содержание
Быстрый вердикт целиком зависит от ваших приоритетов. Если вам нужны сильнейшие возможности рассуждения и автономные агентные функции для сложных корпоративных процессов — Claude Opus 4.6 является очевидным лидером, несмотря на премиальную цену. Если в приоритете скорость при работе с терминальными задачами кодирования и самая зрелая экосистема для разработчиков — GPT-5.3 Codex обеспечивает лучший баланс производительности и стоимости. А если бюджет — определяющий фактор, или вам необходим полный суверенитет данных через self-hosting, GLM-5 полностью меняет расклад: цена в 45 раз ниже, чем у Opus, при конкурентоспособных результатах бенчмарков.
| Категория | Победитель | Почему |
|---|---|---|
| Общее рассуждение | Opus 4.6 | GPQA 77,3%, MMLU Pro 85,1% |
| Скорость в терминале/кодировании | GPT-5.3 Codex | Terminal-Bench 77,3%, на 25% быстрее |
| Экономическая эффективность | GLM-5 | ~$0.11/MTok на входе, лицензия MIT |
| Контекстное окно | Opus 4.6 | 1M tokens (бета) |
| Открытый исходный код | GLM-5 | Единственный open-source вариант |
| Агентные возможности | Opus 4.6 | Agent Teams, глубокая автономия |
Прямое сравнение: бенчмарки, которые действительно важны
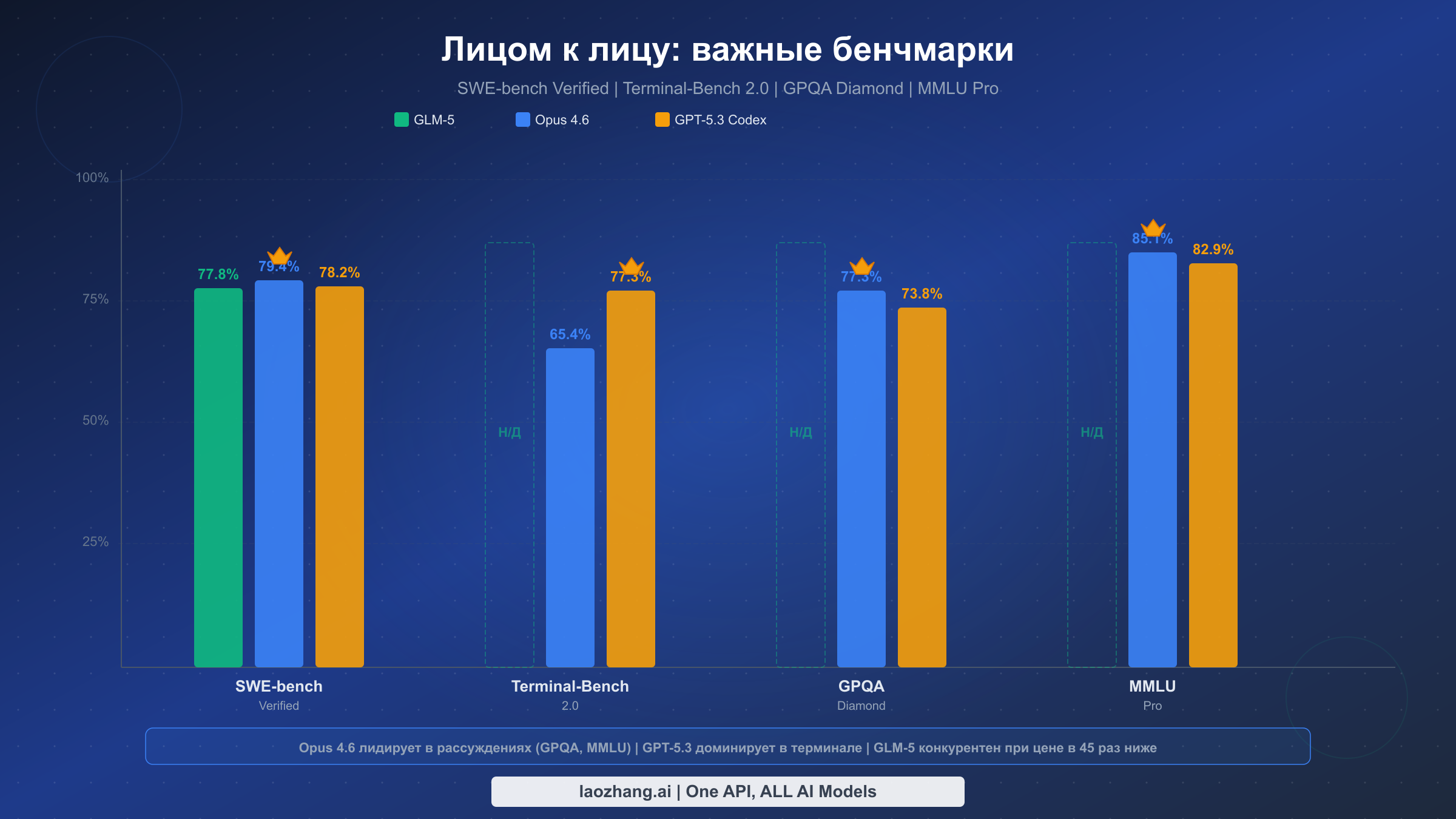
Картина бенчмарков в феврале 2026 года рассказывает увлекательную историю о конвергенции на вершине. Если посмотреть на SWE-bench Verified — самый авторитетный бенчмарк для кодирования, — разброс между тремя моделями удивительно мал: Opus 4.6 набирает 79,4%, GPT-5.3 — 78,2%, а GLM-5 — 77,8%. Разрыв в 1,6 процентного пункта между первым и третьим местом был бы немыслим ещё полгода назад, особенно учитывая, что GLM-5 обучалась исключительно на чипах Huawei Ascend, без какого-либо американского кремния. Эта конвергенция свидетельствует о важном сдвиге, который аналитики Interconnects.ai назвали «пост-бенчмарковой эрой»: сырые числа значат меньше, чем реальный опыт использования моделей в продакшене.
Terminal-Bench 2.0 — бенчмарк, специально разработанный для измерения реальных терминальных и командно-строковых задач кодирования, — выявляет более драматичное разделение. GPT-5.3 Codex набирает здесь 77,3%, на целых 11,9 процентного пункта обгоняя Opus 4.6 с его 65,4%. Этот разрыв значителен, потому что Terminal-Bench измеряет именно ту работу, которой большинство разработчиков занимается ежедневно: выполнение команд, отладка скриптов, управление файлами и оркестрация многоэтапных терминальных операций. К сожалению, у GLM-5 пока нет официального результата Terminal-Bench, что понятно, учитывая дату выпуска — 11 февраля. Исходя из сильных результатов на SWE-bench, ранние тесты предполагают, что модель окажется в диапазоне 60-70%, но это ещё предстоит подтвердить.
Для оценки чистой способности к рассуждению GPQA Diamond и MMLU Pro рисуют ясную картину. Opus 4.6 лидирует на GPQA Diamond с результатом 77,3% по сравнению с 73,8% у GPT-5.3 — преимущество в 3,5 пункта, отражающее неизменный акцент Anthropic на глубоком аналитическом рассуждении. На MMLU Pro разрыв ещё больше: 85,1% у Opus против 82,9% у GPT-5.3. Эти бенчмарки измеряют уровень научного рассуждения докторского уровня и широту знаний, необходимых для сложных корпоративных задач, юридического анализа и исследовательских приложений. Для GLM-5 пока не опубликованы результаты этих конкретных бенчмарков, хотя её показатель BrowseComp в 75,9 свидетельствует о сильных общих способностях к рассуждению.
Важно понимать, что бенчмарки всё хуже передают полную картину. Как отмечалось в сравнении моделей предыдущего поколения, разрыв между результатами бенчмарков и реальным опытом использования продолжает расти. Модель, которая набирает на 2% меньше на SWE-bench, на практике может ощущаться быстрее, отзывчивее или лучше понимать именно вашу кодовую базу. Результаты бенчмарков — это отправная точка, но разделы ниже о практике кодирования, ценообразовании и экосистеме дополнят картину.
Также стоит представить полную таблицу бенчмарков в одном месте для быстрого сравнения. Здесь собраны все проверенные данные из различных источников:
| Бенчмарк | Claude Opus 4.6 | GPT-5.3 Codex | GLM-5 | Что измеряет |
|---|---|---|---|---|
| SWE-bench Verified | 79,4% | 78,2% | 77,8% | Реальные задачи разработки ПО |
| Terminal-Bench 2.0 | 65,4% | 77,3% | N/A | Терминальные задачи кодирования |
| GPQA Diamond | 77,3% | 73,8% | N/A | Научное рассуждение уровня PhD |
| MMLU Pro | 85,1% | 82,9% | N/A | Широта знаний и рассуждение |
| BrowseComp | N/A | N/A | 75,9 | Понимание веб-контента |
| Макс. выход | 128K tokens | Неизвестно | 131K tokens | Длина одного ответа |
| Контекстное окно | 1M (бета) | 256K-400K | 200K | Объём входных данных |
Закономерность, которую показывает эта таблица, очевидна: Opus 4.6 лидирует в бенчмарках, требующих глубокого рассуждения; GPT-5.3 доминирует в скоростных задачах кодирования; а GLM-5 уверенно держится в задачах разработки ПО, при этом выделяясь в областях, важных для бюджетных развёртываний. Отсутствие данных GLM-5 по Terminal-Bench и GPQA заметно и, как ожидается, будет восполнено в ближайшие недели, когда независимые оценщики завершат тестирование этой недавно выпущенной модели.
Кодирование и агентные возможности: сравнение
Когда речь заходит о реальной работе с кодом, три модели используют принципиально разные подходы, выходящие далеко за рамки того, что могут передать результаты SWE-bench. Claude Opus 4.6 представил Agent Teams — функцию, позволяющую модели создавать и координировать несколько подагентов, работающих параллельно над разными частями кодовой базы. На практике это означает, что Opus может рефакторить модуль и одновременно писать для него тесты и обновлять документацию — всё это координируется через центрального агента-планировщика. Такой подход превосходен при масштабном рефакторинге и сложных реализациях функциональности, где критически важно понимание полного контекста кодовой базы. Контекстное окно в 1M tokens в бета-версии дополнительно усиливает это преимущество, позволяя Opus удерживать целые кодовые базы в памяти при анализе.
GPT-5.3 Codex идёт другим путём благодаря интеграции с Codex CLI, оптимизированной для интерактивной разработки в терминале. Если Opus блистает в автономных, длительных задачах, то GPT-5.3 превосходит в быстром интерактивном кодировании: генерация функций, итеративная доработка реализаций и отладка в реальном времени. Ускорение на 25% по сравнению с предшественником GPT-5.2 сразу заметно на практике, создавая ощущение подлинной отзывчивости, снимающей трение в процессе кодирования. Доминирование на Terminal-Bench с результатом 77,3% напрямую транслируется в превосходный опыт работы непосредственно в терминале: запуск скриптов, управление инфраструктурой через командную строку.
GLM-5 привносит нечто совершенно иное как модель с открытым исходным кодом. Её архитектура MoE с 745B параметрами и 256 экспертами (лишь 44B активны в любой момент времени) позволяет достигать конкурентоспособной производительности при значительно более эффективном использовании ресурсов. Для задач кодирования результат GLM-5 в 77,8% на SWE-bench уверенно помещает её в одну лигу с закрытыми гигантами. Но истинное преимущество GLM-5 для программирования заключается в возможности кастомизации: поскольку у вас есть полный доступ к весам модели по лицензии MIT, вы можете дообучить её на вашей проприетарной кодовой базе, ваших конкретных стандартах кодирования и вашем технологическом стеке. Этого не могут предложить ни Opus, ни GPT-5.3, и для команд с большими специализированными кодовыми базами этот потенциал кастомизации может перевесить преимущество в сырых бенчмарках.
Разницу в контекстных окнах стоит рассмотреть в практическом плане. Бета-контекст Opus 4.6 в 1M tokens означает возможность загрузки примерно 750 000 слов или около 15 000 строк кода в одном запросе. Диапазон GPT-5.3 в 256K-400K позволяет комфортно обработать 5 000-8 000 строк. Контекстное окно GLM-5 в 200K вмещает около 4 000 строк. Для большинства повседневных задач кодирования даже 200K более чем достаточно, но когда нужно анализировать целые микросервисные архитектуры или проводить межрепозиторный рефакторинг, массивное контекстное окно Opus становится подлинным преимуществом.
Различия в агентной архитектуре заслуживают более глубокого рассмотрения, поскольку представляют фундаментально разные философии взаимодействия ИИ с кодовыми базами. Подход Agent Teams в Opus 4.6 рассматривает кодирование как задачу коллективного управления проектом: модель планирует, делегирует и координирует — во многом как опытный разработчик, руководящий командой. Это означает, что Opus преуспевает в задачах, требующих стратегического мышления об архитектуре кода, понимания сквозной функциональности и поддержания согласованности при масштабных изменениях. Напротив, подход Codex в GPT-5.3 трактует кодирование как задачу быстрой итерации: дайте модели задание, получите быстрый результат, быстро доработайте. Эта философия отлично работает при спринтах разработки, когда вы точно знаете, что хотите построить, и нужно двигаться быстро.
Агентные возможности GLM-5 ещё развиваются, но open-source природа модели означает, что сообщество может создавать собственные агентные фреймворки поверх базовой модели. Уже появились ранние проекты, объединяющие GLM-5 с открытыми инструментами оркестрации, такими как LangGraph и CrewAI, создавая кастомные агентные системы, не уступающие встроенным возможностям закрытых моделей. Ключевое преимущество здесь — гибкость: в то время как Opus и GPT-5.3 предлагают вам свои видения агентного кодирования, GLM-5 позволяет построить именно ту агентную архитектуру, которая соответствует вашему рабочему процессу и структуре команды.
Реальная стоимость: анализ цен и ценности

Ценообразование — это та область, где трёхстороннее сравнение становится по-настоящему интересным и где большинство существующих обзоров ограничиваются перечислением цен за токены, не анализируя, что эти цены означают для реальных нагрузок. Начнём с проверенных цифр: Claude Opus 4.6 стоит $5,00 за миллион входных токенов и $25,00 за миллион выходных токенов для запросов до 200K контекста, а при превышении 200K цены повышаются до $10,00/$37,50 (claude.com/pricing, проверено 12 февраля 2026 г.). GPT-5.3 Codex не указан отдельно на странице цен OpenAI, но исходя из цены GPT-5.2 в $1,75/$14,00 за миллион токенов (openai.com/api/pricing, проверено 12 февраля 2026 г.) и подтверждения из нескольких источников, оценочная цена GPT-5.3 составляет примерно $1,75/$14,00. GLM-5 стоит приблизительно $0,11 за миллион входных токенов согласно ценовой структуре Zhipu AI (glm5.net и сторонние источники).
Чтобы понять, что эти цены означают на практике, рассмотрим три типичные задачи разработки с ИИ. Для ревью 100 строк кода (примерно 2 000 токенов на входе, 1 000 на выходе) GLM-5 стоит около $0,0002, GPT-5.3 — около $0,018, а Opus 4.6 — приблизительно $0,035. Для анализа документа на 10 000 слов (примерно 15 000 токенов на входе, 3 000 на выходе) затраты масштабируются до ~$0,002 для GLM-5, $0,068 для GPT-5.3 и $0,150 для Opus. А для непрерывной часовой агентной сессии с обработкой около 600 000 входных и 200 000 выходных токенов вы заплатите примерно $0,09 с GLM-5, $1,05 с GPT-5.3 и $8,00 с Opus 4.6.
Эти различия драматически нарастают при масштабировании. Стартап, выполняющий 10 000 API-вызовов в день, потратит примерно $2 в день с GLM-5, $180 в день с GPT-5.3 или $350 в день с Opus. За месяц это $60 против $5 400 против $10 500. Для бюджетных команд ценообразование GLM-5 фактически снимает ограничение стоимости API как фактор. Для разработчиков, желающих экспериментировать со всеми тремя моделями без управления несколькими API-ключами, агрегаторные платформы вроде laozhang.ai предлагают единый доступ с упрощённой оплатой и унифицированными API-интерфейсами.
Кэширование также заслуживает внимания для нагрузок с повторяющимся контекстом. Opus 4.6 предлагает кэширование промптов, способное существенно снизить стоимость входных данных для приложений, использующих одни и те же системные промпты или справочные документы. GPT-5.3 аналогично предоставляет механизмы кэширования. Open-source природа GLM-5 означает, что при self-hosted развёртывании можно реализовать собственные стратегии кэширования на уровне инфраструктуры, потенциально снижая эффективные затраты ещё ниже и без того низкой цены API. Более подробный разбор тарифных планов Anthropic и скидок за кэширование можно найти в детальном обзоре цен Claude Opus.
Есть важный ценовой нюанс, который большинство сравнительных статей полностью упускают: разница между стоимостью входных и выходных токенов. Хотя входные цены привлекают больше всего внимания, именно на выходных токенах накапливаются реальные затраты для генеративных задач. Opus 4.6 берёт $25/MTok за выходные токены — это в пять раз больше входной цены. GPT-5.3 берёт примерно $14/MTok за выход — в восемь раз больше входной цены. Для задач, генерирующих существенный объём выходных данных — написание целых функций, создание документации или генерация тестовых наборов — разница в ценах на выход может значительно сместить расчёт стоимости. Задача, генерирующая 10 000 выходных токенов, обойдётся в $0,25 с Opus против $0,14 с GPT-5.3 — разрыв куда меньше, чем предполагают одни лишь входные цены. Для Opus, в частности, запросы, превышающие 200K токенов контекста, облагаются ещё более высокими ценами $10/$37,50 за миллион входных/выходных токенов, что фактически удваивает стоимость для приложений с большим контекстом.
| Сценарий затрат | GLM-5 | GPT-5.3 | Opus 4.6 |
|---|---|---|---|
| Ревью 100 строк кода | ~$0.0002 | ~$0.018 | ~$0.035 |
| Анализ документа 10K слов | ~$0.002 | ~$0.068 | ~$0.150 |
| Часовая агентная сессия | ~$0.09 | ~$1.05 | ~$8.00 |
| 10K вызовов/день (за месяц) | ~$60 | ~$5,400 | ~$10,500 |
| Self-hosted (за месяц) | Только оборудование | N/A | N/A |
Open-source козырь: почему GLM-5 меняет правила игры
Выпуск GLM-5 с полной лицензией MIT представляет собой подлинную точку перелома в ландшафте ИИ-моделей. В отличие от предыдущих open-source моделей, которые часто сопровождались ограничительными условиями использования или отставанием в производительности, делавшим их непрактичными для серьёзной промышленной эксплуатации, GLM-5 демонстрирует результаты на SWE-bench в пределах 1,6 процентного пункта от Opus 4.6, при этом являясь абсолютно бесплатной для использования, модификации и коммерческого развёртывания. Лицензия MIT — самая либеральная из доступных: никаких ограничений на использование модели, никаких требований по разделению доходов, никаких лимитов на коммерческое развёртывание. Впервые open-source модель достигла такого сочетания конкурентоспособной производительности и неограниченного лицензирования.
Экономические последствия self-hosting GLM-5 существенны для организаций со значительными ИИ-нагрузками. Хотя начальные инвестиции в оборудование для запуска модели с 745B параметрами нетривиальны, архитектура MoE означает, что для каждого отдельного вызова инференса активны лишь 44B параметров. Это кардинально снижает аппаратные требования по сравнению с тем, что может предполагать общее количество параметров. Организации, уже эксплуатирующие GPU-кластеры для обучения или инференса, потенциально могут добавить GLM-5 в существующую инфраструктуру, полностью исключив затраты на токены. Для компании, тратящей $10 000 в месяц на вызовы API Opus 4.6, точка безубыточности при инвестициях в оборудование для self-hosting может быть достигнута в течение месяцев, а не лет.
Пожалуй, стратегически наиболее значимым аспектом GLM-5 является её обучающее оборудование. Zhipu AI создала эту модель исключительно на чипах Huawei Ascend, продемонстрировав, что конкурентоспособные фронтирные модели могут обучаться без какой-либо американской полупроводниковой технологии. Это имеет непосредственные практические последствия для организаций, работающих в условиях экспортных ограничений, компаний с мандатами на диверсификацию цепочек поставок или бизнесов, стремящихся обеспечить независимость своей ИИ-инфраструктуры от чипового производства одной страны. Геополитическая независимость обучающей инфраструктуры GLM-5 — это уникальное ценностное предложение, которое ни Opus, ни GPT-5.3 не могут предложить, вне зависимости от их преимуществ в производительности.
Open-source природа GLM-5 также открывает возможности, недоступные закрытым моделям. Команды могут дообучать модель на доменно-специфичных данных, интегрировать её непосредственно в проприетарные пайплайны, запускать в изолированных (air-gapped) средах и проводить аудит весов модели для соответствия регуляторным требованиям. Для таких отраслей, как здравоохранение, финансы и государственный сектор, где резидентность данных и прозрачность модели — обязательные требования, GLM-5 может быть единственным жизнеспособным вариантом среди трёх, независимо от результатов бенчмарков.
При этом важно трезво оценивать ограничения open-source преимущества GLM-5. Запуск модели с 745B параметрами, даже при эффективности MoE, требует серьёзной инфраструктуры. Хотя 44B активных параметров при инференсе вполне посильны для современных GPU-кластеров, полные веса модели всё равно нужно загрузить в память для работы маршрутизации экспертов. Организации без существующей GPU-инфраструктуры столкнутся со значительными начальными затратами на оборудование, окупаемость которых может занять месяцы. Оптимальная ситуация для self-hosting GLM-5 — это организации, уже обрабатывающие крупномасштабные ИИ-нагрузки и способные включить GLM-5 в существующий вычислительный бюджет. Для небольших команд цена API в $0,11/MTok и так настолько низка, что self-hosting может не оправдать операционной сложности.
Состав обучающих данных GLM-5 тоже заслуживает упоминания. Zhipu AI сообщает об обучении на 28,5 триллионах токенов, и модель демонстрирует сильные возможности как в английском, так и в китайском языке. Однако баланс между англоязычными и китаеязычными обучающими данными публично не раскрыт, и некоторые ранние пользователи отмечали несколько лучшую производительность GLM-5 на задачах на китайском языке по сравнению с английским, хотя разница для большинства случаев использования минимальна. Для нагрузок с преобладанием английского языка независимое бенчмаркирование в ближайшие недели поможет прояснить, является ли это реальной проблемой или артефактом условий раннего тестирования.
За пределами бенчмарков: чего цифры не расскажут

Мы вступили в то, что аналитики называют «пост-бенчмарковой эрой» — период, когда значимые различия между фронтирными моделями всё больше определяются их экосистемами, опытом разработчиков и возможностями интеграции, а не сырыми показателями производительности. Когда три модели набирают с разницей в 2 процентных пункта на SWE-bench, факторы, реально определяющие, какую модель стоит использовать, становятся куда более тонкими, чем простое сравнение бенчмарков.
Экосистема Anthropic вокруг Opus 4.6 значительно повзрослела: Claude Code обеспечивает глубоко интегрированный опыт в IDE, Agent Teams позволяют реализовать сложные автономные процессы, а бета-версия контекстного окна в 1M открывает сценарии использования, ранее невозможные. Опыт работы с Opus ощущается принципиально иначе по сравнению с двумя другими моделями: она превосходна в понимании сложных многофайловых контекстов, поддержании когерентных продолжительных диалогов и генерации кода, учитывающего более широкие архитектурные последствия. Пользователи стабильно отмечают, что Opus «думает более тщательно» перед ответом, что выражается в меньшем количестве итераций для сложных задач, но более длительном времени первичного отклика. Этот компромисс выгоден пользователям, для которых точность важнее скорости.
Экосистемное преимущество OpenAI с GPT-5.3 Codex заключается в широте интеграций. Codex CLI, интеграция с ChatGPT, обширная экосистема плагинов и массивная поддержка сторонних инструментов создают среду разработки, в которой GPT-5.3 часто оказывается путём наименьшего сопротивления. Ускорение модели на 25% создаёт ощущение подлинной отзывчивости, а терминально-ориентированный подход Codex идеально совпадает с тем, как многие разработчики фактически работают. Сообщество OpenAI — крупнейшее в отрасли, что означает больше руководств, больше ответов на Stack Overflow и больше open-source инструментов, построенных вокруг их API. Для команд, ценящих скорость и широту экосистемы, GPT-5.3 обеспечивает наиболее безпроблемный опыт.
Экосистема GLM-5 — самая молодая из трёх, запущенная буквально несколько дней назад, 11 февраля 2026 года. Однако open-source природа означает, что инструменты от сообщества могут развиваться стремительно, не дожидаясь официальных релизов. Архитектура MoE модели хорошо задокументирована, веса свободно доступны на Hugging Face, а лицензия MIT позволяет любому создавать коммерческие инструменты на её основе. Наибольшую раннюю активность проявило китайское сообщество разработчиков, но open-source природа делает глобальный рост экосистемы неизбежным. Ключевой вопрос для GLM-5 — не будет ли экосистема развиваться, а успеет ли она развиться достаточно быстро, чтобы конкурировать со зрелыми экосистемами Opus и GPT-5.3 для вашего конкретного сценария в рамках актуальных сроков.
Часто упускаемый аспект экосистемного сравнения — качество поддержки и документации. Anthropic предоставляет подробную техническую документацию, отзывчивые DevRel-отношения и растущую базу лучших практик для максимально эффективного использования Opus 4.6, включая конкретные рекомендации по промпт-инженерингу для Agent Teams и оптимальному использованию расширенного контекстного окна. Документация OpenAI — самая обширная в индустрии, подкреплённая крупнейшим сообществом разработчиков, делящихся советами, руководствами и open-source инструментами. Документация GLM-5 на данный момент доступна преимущественно через официальные каналы Zhipu AI, причём англоязычные ресурсы растут, но пока менее развиты, чем у конкурентов. Для команд, нуждающихся в надёжной поддержке и понятных путях обновления, этот фактор зрелости экосистемы может иметь не меньшее значение, чем технические характеристики самих моделей.
История интеграций также значительно различается для трёх моделей. Opus 4.6 предлагает первоклассную интеграцию с VS Code через Claude Code, прямую поддержку в популярных расширениях IDE, а Anthropic SDK поддерживает все основные языки программирования. GPT-5.3 выигрывает от многолетнего развития экосистемы OpenAI: библиотеки доступны для практически любого языка и фреймворка, плюс нативная интеграция в GitHub Copilot и другие инструменты разработчика. GLM-5 использует форматы API, совместимые с OpenAI, что означает: большинство существующих инструментов, разработанных для GPT, работают с минимальными модификациями — умная стратегия, снижающая барьер входа за счёт использования экосистемных инвестиций OpenAI.
Какую модель выбрать? Практическая схема принятия решения
Вместо бесполезного ответа «всё зависит от обстоятельств» предлагаем конкретную матрицу решений, основанную на вашей роли и основном сценарии использования. Найдите свою ситуацию ниже — рекомендация следует непосредственно из неё.
Если вы сольный разработчик или инди-хакер, ориентированный прежде всего на продуктивность кодирования, GPT-5.3 Codex — лучшая стартовая точка. Преимущество в скорости, зрелая интеграция Codex CLI и конкурентоспособная цена $1,75/MTok делают его наиболее практичным ежедневным инструментом. Вы получите самый быстрый цикл обратной связи и широчайшую экосистему инструментов и ресурсов. Переключайтесь на Opus для задач сложного рассуждения или когда нужно целостно проанализировать большую кодовую базу.
Если вы CTO или технический руководитель, принимающий инфраструктурные решения для команды, ответ сильно зависит от бюджета и требований к данным. Для команд со значительными тратами на ИИ (свыше $5 000/месяц) стоит рассмотреть мультимодельную стратегию: используйте Opus 4.6 для сложного планирования, архитектурных ревью и автономных агентных процессов, где качество критично; GPT-5.3 — для повседневной помощи в кодировании, где важна скорость; а GLM-5 — для высокообъёмных, чувствительных к стоимости нагрузок: пакетная обработка, генерация контента или поддержка клиентов. Такой гибридный подход может сократить общие затраты на ИИ на 40-60% по сравнению с эксклюзивным использованием Opus, сохраняя качество там, где оно наиболее важно.
Если вы работаете в регулируемой отрасли (финансы, здравоохранение, госсектор), где конфиденциальность данных первостепенна, GLM-5 заслуживает серьёзного рассмотрения вне зависимости от сравнения бенчмарков. Возможность self-hosting по лицензии MIT в сочетании с полным доступом к весам модели для аудита и комплаенса отвечает регуляторным требованиям, которые ни Opus, ни GPT-5.3 удовлетворить не могут. Конкурентоспособные результаты бенчмарков означают, что вы не жертвуете значительными возможностями ради соответствия нормативам.
Если вы строите бизнес на китайском рынке или должны обеспечить независимость цепочки поставок от американских технологий, GLM-5 — очевидный выбор. Обучающая инфраструктура на Huawei Ascend, происхождение от китайской компании и свободная доступность делают её единственным вариантом, обеспечивающим полную независимость технологического стека.
| Ваша ситуация | Основной выбор | Дополнительный | Когда переключаться |
|---|---|---|---|
| Сольный разработчик | GPT-5.3 Codex | Opus 4.6 | Сложные архитектурные задачи |
| Стартап (< $2K/мес. на ИИ) | GLM-5 | GPT-5.3 | Нужны скорость + экосистема |
| Средняя команда | GPT-5.3 + Opus | GLM-5 | Массовая пакетная обработка |
| Крупное предприятие | Opus 4.6 | GLM-5 self-hosted | Суверенитет данных |
| Регулируемая отрасль | GLM-5 self-hosted | Opus 4.6 | Когда комплаенс позволяет |
| Бюджет прежде всего | GLM-5 | GPT-5.3 | Практически никогда |
Мультимодельная стратегия заслуживает особого акцента, поскольку представляет наиболее зрелый и экономичный подход для организаций с разнообразными ИИ-потребностями. Вместо привязки к одному провайдеру направляйте разные типы запросов к разным моделям в зависимости от конкретных требований каждой задачи. Используйте Opus 4.6 для самых важных задач рассуждения: анализа контрактов, архитектурного планирования, сложных сессий отладки, где получение правильного ответа с первой попытки оправдывает премиальную стоимость. Направляйте высокообъёмные, чувствительные к задержке задачи кодирования в GPT-5.3 для максимальной продуктивности разработчиков. А затратно-чувствительную пакетную обработку, генерацию контента и внутренние инструменты — в GLM-5, где 45-кратное ценовое преимущество выливается в колоссальную экономию без значимой потери качества. Этот многоуровневый подход может снизить общие затраты на ИИ-инфраструктуру на 40-60% по сравнению с использованием единой премиальной модели для всего, при этом фактически повышая общее качество за счёт соответствия сильных сторон каждой модели задачам, где эти сильные стороны проявляются наиболее ярко.
Для организаций, только начинающих оценку, практичный первый шаг — двухнедельный пилот со всеми тремя моделями на ваших реальных рабочих нагрузках. Подготовьте тестовый набор из 50-100 репрезентативных задач из повседневных операций, прогоните каждую через все три модели и сравните результаты по трём параметрам: качество вывода, задержка и общая стоимость. Такой эмпирический подход даст вам данные, специфичные для вашей организации, которые гораздо ценнее любого универсального сравнения бенчмарков, включая это. Результаты часто удивляют: многие команды обнаруживают, что GLM-5 обрабатывает 70-80% их нагрузок с вполне приемлемым качеством, существенно сокращая объём дорогих API-вызовов, которые приходится направлять к премиальным моделям.
Начало работы: доступ к API и советы по миграции
Начать работу с любой из трёх моделей требует минимальной настройки. Для Claude Opus 4.6 зарегистрируйтесь в Anthropic Console и используйте идентификатор модели claude-opus-4-6. API следует стандартному формату Messages API, и если вы мигрируете с Opus 4.5, переход проходит без разрывов совместимости. Полное руководство по тарифным планам API Anthropic и настройке аутентификации представлено в описании ценовой структуры Claude API.
Для GPT-5.3 Codex доступ осуществляется через стандартный OpenAI API с соответствующим идентификатором модели. Если вы уже используете GPT-5.2, переключение — это изменение одной строки в параметре модели. Codex CLI устанавливается через npm и предоставляет интегрированный терминальный опыт, наглядно демонстрирующий преимущество GPT-5.3 в скорости.
GLM-5 предлагает самые гибкие варианты доступа. Вы можете использовать официальный API Zhipu AI через платформу BigModel или скачать полные веса модели с Hugging Face для self-hosting. Модель поддерживает формат API, совместимый с OpenAI, что означает: большая часть существующего кода, написанного для моделей GPT, работает с минимальными модификациями. Self-hosting требует следования руководству по настройке от Zhipu, при этом аппаратные требования зависят от того, разворачиваете ли вы полную модель или квантизированную версию.
pythonfrom openai import OpenAI # For GLM-5 via laozhang.ai unified access client = OpenAI( base_url="https://api.laozhang.ai/v1", api_key="your-api-key" ) response = client.chat.completions.create( model="glm-5", # or "claude-opus-4-6" or "gpt-5.3-codex" messages=[{"role": "user", "content": "Compare these three approaches..."}] )
Для команд, желающих оценить все три модели без управления отдельными API-ключами и платёжными аккаунтами, унифицированные API-платформы предоставляют единую конечную точку с маршрутизацией к любой модели. Этот подход особенно полезен на этапе оценки, когда нужно прогнать одни и те же промпты через все три модели и сравнить результаты перед выбором основного провайдера.
Миграция с предыдущих версий моделей проста для всех трёх провайдеров. Если вы сейчас используете Claude Opus 4.5, обновление до 4.6 требует лишь изменения строки идентификатора модели в API-вызовах без изменений формата запроса или структуры ответа. То же касается перехода с GPT-5.2 на GPT-5.3, который обеспечивает полную обратную совместимость с существующим форматом OpenAI API. Для команд, впервые знакомящихся с GLM-5, формат API, совместимый с OpenAI, означает, что часто достаточно просто изменить базовый URL и имя модели в существующем коде — это делает добавление GLM-5 как дополнительной модели в любую мультимодельную конфигурацию исключительно простым.
Практический аспект, который часто упускают из виду, — ограничения скорости запросов и доступность. Opus 4.6 имеет относительно консервативные лимиты на бесплатном уровне, с более щедрыми лимитами на подписках Claude Pro ($20/месяц) и Claude Max (от $100/месяц) (claude.com/pricing, проверено 12 февраля 2026 г.). OpenAI предоставляет многоуровневые лимиты скорости запросов на основе истории использования API и объёма трат. API GLM-5 через Zhipu AI имеет собственную структуру лимитов, тогда как self-hosted развёртывания ограничены лишь мощностью вашего оборудования, что является ещё одним убедительным аргументом в пользу self-hosting для высоконагруженных приложений.
FAQ
Действительно ли GLM-5 конкурентоспособна на фоне Opus 4.6 и GPT-5.3?
Да, данные бенчмарков это подтверждают. GLM-5 набирает 77,8% на SWE-bench Verified — всего на 1,6 пункта позади лидирующего Opus 4.6 с 79,4% и на 0,4 пункта позади GPT-5.3 с 78,2%. Хотя по некоторым бенчмаркам вроде Terminal-Bench и GPQA Diamond опубликованные результаты отсутствуют, общая производительность уверенно помещает GLM-5 в один уровень с закрытыми лидерами, что примечательно для open-source модели, стоящей в 45 раз дешевле.
Почему наблюдается расхождение в ценах на GPT-5.3 Codex?
По состоянию на 12 февраля 2026 года OpenAI не разместила GPT-5.3 Codex отдельно на своей официальной странице цен. Цифра $1,75/MTok основана на опубликованной цене GPT-5.2 (проверено на openai.com/api/pricing) и подтверждается несколькими независимыми источниками. В некоторых статьях фигурируют более высокие цифры $6/$30, которые могут относиться к другим уровням доступа или более ранним ценовым анонсам. Рекомендуем обращаться непосредственно к странице цен OpenAI для получения актуальной информации.
Может ли GLM-5 заменить Opus 4.6 для корпоративных задач рассуждения?
По опубликованным бенчмаркам рассуждения GLM-5 конкурентоспособна, но, вероятно, уступает Opus 4.6 в задачах, требующих глубокого аналитического рассуждения (GPQA, MMLU Pro). Тем не менее возможность self-hosting и лицензия MIT могут быть важнее маргинальных различий в бенчмарках для предприятий со строгими требованиями к резидентности данных. Ответ зависит от того, что является вашим основным ограничением — возможности или соответствие нормативам.
Какая модель лучше всего подходит для кодирования в 2026 году?
Зависит от типа работы с кодом. Для интерактивного кодирования в терминале GPT-5.3 Codex лидирует с результатом 77,3% на Terminal-Bench. Для автономного многофайлового рефакторинга и архитектурного планирования Agent Teams Opus 4.6 и контекстное окно в 1M дают ему явное преимущество. Для экономичных массовых задач кодирования или сред, требующих self-hosted моделей, GLM-5 предлагает лучшее соотношение цена-качество. Многие разработчики переходят на мультимодельную стратегию, используя разные модели для разных типов задач.
Стоит ли дождаться дополнительных бенчмарков GLM-5 перед внедрением?
Если ваша главная забота — подтверждённые результаты бенчмарков по всем категориям, ожидание более полного тестирования обосновано. Однако существующие результаты SWE-bench 77,8% и BrowseComp 75,9 уже демонстрируют сильные возможности. Если ваша основная мотивация — сокращение затрат или доступ к open-source, причин ждать мало: лицензия MIT и конкурентоспособная базовая производительность — уже установленные факты.