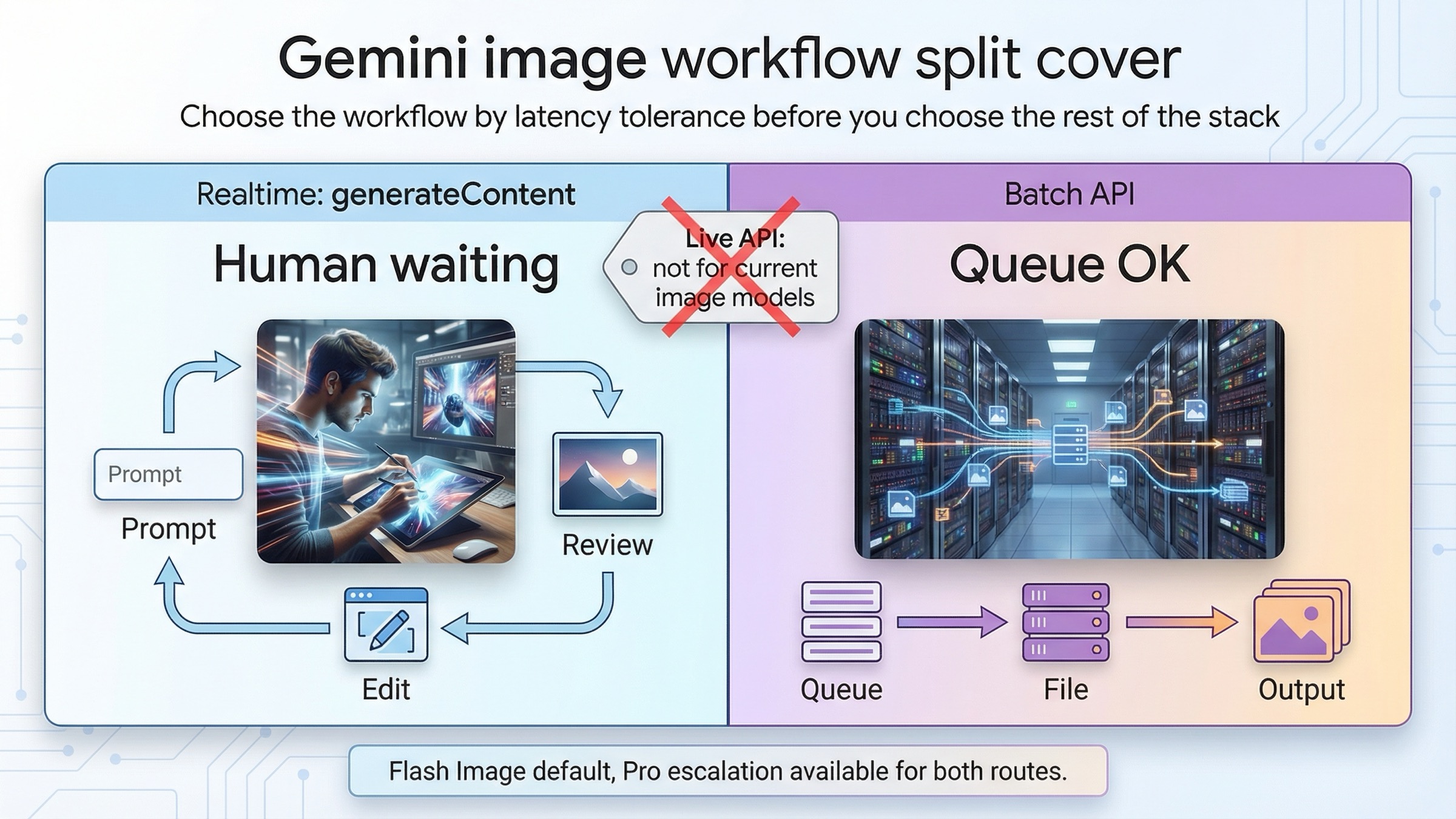
По состоянию на 23 марта 2026 года лучший default для Gemini image generation очень простой: если кто-то ждет картинку сейчас, выбирайте синхронный generateContent; если работа массовая, не срочная и допускает отложенную выдачу, выбирайте Batch API. Этот вопрос лучше начинать не с цены, а с latency tolerance. Как только вы честно отвечаете, ждет ли кто-то следующий результат прямо сейчас, остальная архитектура становится заметно яснее.
Есть и вторая путаница, которую лучше снять в самом начале. Для текущих Gemini image models слово "realtime" не означает Live API. На страницах моделей gemini-3.1-flash-image-preview и gemini-3-pro-image-preview у Google сейчас указано, что Batch API поддерживается, а Live API не поддерживается. При этом текущая документация по image generation строит все практические примеры вокруг обычных синхронных запросов generateContent. Значит, в рамках этой темы realtime route сегодня означает не live-image session, а обычный request-response workflow с быстрыми prompt-итерациями и редактированием.
Именно здесь многие страницы в SERP все еще не помогают. Одна official page объясняет Batch API, другая объясняет image generation, третья дает pricing, четвертая перечисляет model capabilities. По отдельности факты понятны, но из них не всегда складывается верное workflow решение. Поэтому полезный ответ должен сводить все в одну практическую схему: когда оставаться на synchronous path, когда включать batch, какую модель считать default и каких архитектурных ошибок не делать.
Краткое содержание
Если вам нужен короткий ответ, ориентируйтесь на эту таблицу.
| Вопрос | Лучший текущий ответ | Почему |
|---|---|---|
| Человек ждет результат генерации или редактирования | Синхронный generateContent | Именно так устроены текущие official image workflows Google: prompt, результат, правка, следующий ход |
| Задача большая, не срочная и чувствительна к стоимости | Batch API | В документации Batch API Google пишет о 50% standard cost и 24-часовом target turnaround |
| Под realtime вы имеете в виду live image session | Это неверная модель мышления для текущих Gemini image models | На текущих model pages для image line написано, что Live API is not supported |
| Какую image model брать по умолчанию | gemini-3.1-flash-image-preview | Это текущая эффективная default-линия и официальный путь замены gemini-2.5-flash-image |
| Когда есть смысл идти в Pro | Когда текст, layout и цена ошибки уже дорогие | gemini-3-pro-image-preview лучше подходит для text-heavy visuals, polished assets и более дорогих output jobs |
| Самая дешевая native Gemini image lane | gemini-2.5-flash-image | Но это legacy-линия, и Google уже поставил ей shutdown date 2 октября 2026 года |
Практическая ошибка здесь почти всегда одна и та же: люди выбирают Batch API просто потому, что он дешевле. Но низкая цена выигрывает только тогда, когда задержка не ломает сам workflow. Если prompt еще нестабилен, нужен review loop, строится user-facing tool или команда делает быструю creative iteration, synchronous path почти всегда полезнее.
В трех быстрых сценариях решение выглядит так:
- product tool, где пользователь ждет следующую картинку сейчас: synchronous
- внутренняя creative loop с правками в течение дня: synchronous сначала, batch только после стабилизации prompt
- overnight job на тысячи вариантов по уже утвержденному шаблону: batch
Если вам важнее код, а не routing logic, дальше пригодится примеры кода для генерации изображений в Gemini. Если главный вопрос про стоимость, откройте pricing по Gemini image generation API. Если реальная задача уже не про routing, а про edit behavior, полезнее страница редактирование изображений в Gemini.
Главное разделение: синхронный generateContent против Batch API
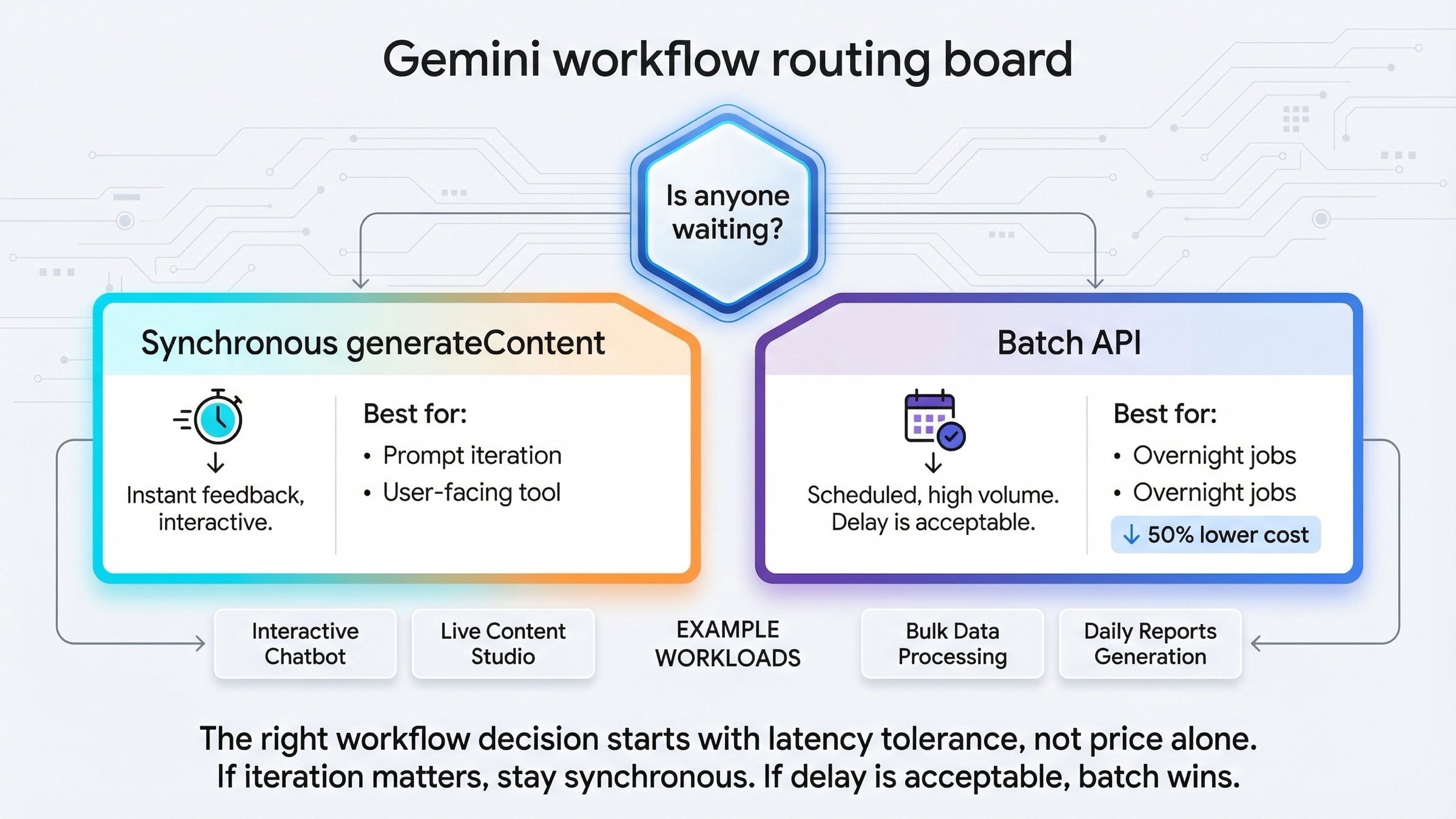
Люди обычно приходят по этому keyword с техническим вопросом, внутри которого спрятан операционный вопрос. Формально они спрашивают: "Batch или realtime?" По сути же они спрашивают: "Эта работа должна оставаться в интерактивном цикле или ее уже можно безопасно отдать в очередь?"
Поэтому первый полезный вопрос здесь не про цену, модель или SDK. Он звучит так:
Кто-то ждет следующий результат прямо сейчас?
Если да, оставайтесь на synchronous path. Это обычно покрывает:
- prompt exploration
- user-facing image tools
- human review loops
- iterative editing
- быстрые retry после слабого первого результата
Если нет, Batch API становится сильным вариантом. Это обычно означает:
- overnight generation
- queue-driven asset pipelines
- массовые catalog или variant jobs
- backfill и enrichment work
- повторяемую генерацию по уже утвержденным prompt templates
Текущая документация по Batch API формулирует trade-off очень прямо: этот API рассчитан на большой объем запросов, работает асинхронно, дает 50% от standard cost, а целевое окно выполнения составляет 24 часа. Иногда job завершается раньше, но это все равно queue surface, а не interactive SLA. Если следующая action в вашем продукте зависит от немедленного output, batch почти наверняка не та дорога.
Обратное тоже верно. Синхронная image generation нужна не только для игрушечных тестов. Она лучше подходит любому workflow, где ценность приходит через быстрый цикл "один prompt, один результат, одна правка, следующий ход". И официальный гайд по image generation именно так и устроен: generation, editing и multi-turn refinement находятся на synchronous path, потому что learning loop там сильнее всего.
Отсюда и главное правило статьи:
- interactive, human-in-the-loop и product-facing работа: synchronous
- queued, bulk, cost-sensitive и не срочная работа: batch
Это правило помогает избежать одной очень частой инженерной ошибки. Команды знают, что позже им все равно понадобится очередь, и поэтому пытаются начать сразу с нее. Но то, что queue surface понадобится потом, не означает, что workflow должен рождаться в queue. Почти всегда быстрее сначала доказать prompt, response handling и model behavior на synchronous path, а уже потом решать, заслуживает ли стабильный request отдельной batch-ветки.
Какую Gemini image model ставить за каждым workflow
Выбор workflow и выбор модели связаны, но это не одно и то же. Batch не является model. Realtime не является model. Один и тот же image model family может стоять как за synchronous path, так и за batch path.
Для большинства новых задач базовым ответом должен оставаться gemini-3.1-flash-image-preview. Google позиционирует его как текущую high-efficiency image lane, а на странице deprecations указывает его как replacement path для gemini-2.5-flash-image.
| Модель | Статус на 23 марта 2026 | Batch API | Live API | Текущий price signal | Лучший fit |
|---|---|---|---|---|---|
gemini-3.1-flash-image-preview | Текущий preview default | Поддерживается | Не поддерживается | $0.067 за 1K image, $0.034 в batch | Большинство новых interactive и queued workflows |
gemini-3-pro-image-preview | Текущая premium preview lane | Поддерживается | Не поддерживается | $0.134 за 1K или 2K, $0.067 в batch | Text-heavy visuals, diagrams, polished assets |
gemini-2.5-flash-image | Legacy-линия, но еще доступна | Поддерживается | Не поддерживается | $0.039 standard и $0.0195 batch | Самая дешевая official native lane, если lifecycle риск приемлем |
Из этой таблицы важны три вывода.
Во-первых, текущие Gemini image models поддерживают Batch API, но не поддерживают Live API. Значит, не нужно проектировать эту тему так, будто правильный ответ скрыт в live-session architecture. Для текущей image line такой путь официально не поддерживается.
Во-вторых, gemini-3.1-flash-image-preview остается правильным default answer, пока у вас нет дорогой причины от него уйти. Он достаточно быстрый, достаточно актуальный и достаточно гибкий и для synchronous prompting, и для batch repetition.
В-третьих, самая дешевая линия и лучшая default-линия не совпадают. gemini-2.5-flash-image действительно дешевле, но Google уже указывает ей shutdown date 2 октября 2026 года. Поэтому выбирать ее для нового проекта стоит только осознанно, как временную экономию на legacy lane, а не как новый нейтральный default. Если вам нужен более широкий контекст по model family, откройте Nano Banana 2, Pro или Imagen 4: что выбрать.
Лучший realtime workflow для prompt-итераций, review и редактирования
Если человек ждет результат прямо сейчас, лучшим workflow остается обычный синхронный generateContent. Это верно и для backend service, и для внутреннего image tool, и для product UI, и для conversational editing flow.
Причина не только в скорости. Причина в качестве итерации.
Хорошая Gemini image work очень часто выглядит как короткий цикл:
- отправить ясный prompt
- посмотреть первый результат
- сузить одну инструкцию
- отправить следующий ход
Особенно это верно для editing. Текущая documentation по image generation показывает Gemini image work как conversational и multi-turn. Именно такая mental model и полезна для product workflows: вторая инструкция почти всегда зависит от того, что первая картинка сделала правильно или неправильно. Batch для этого плох именно потому, что обратная связь приходит слишком поздно.
Ниже тот тип синхронного вызова, от которого разумно стартовать почти любой новый workflow:
javascriptimport { GoogleGenAI } from "@google/genai"; import * as fs from "node:fs"; const ai = new GoogleGenAI({ apiKey: process.env.GEMINI_API_KEY }); const response = await ai.models.generateContent({ model: "gemini-3.1-flash-image-preview", contents: "Create a clean 16:9 product hero image of a matte black coffee grinder on a soft gray background with premium ecommerce lighting.", config: { responseModalities: ["IMAGE"], imageConfig: { aspectRatio: "16:9", imageSize: "2K" } } }); for (const part of response.candidates[0].content.parts) { if (part.inlineData) { fs.writeFileSync("coffee-grinder.png", Buffer.from(part.inlineData.data, "base64")); } }
Первый запрос стоит делать специально скучным. Его задача не в том, чтобы доказать, что Gemini умеет все. Его задача в том, чтобы подтвердить, что у вас работают model selection, response handling и image output. Когда этот baseline стабилен, уже потом можно уходить в editing, follow-up turns и более дорогие prompts.
На synchronous path особенно полезны две привычки:
- описывать сцену, а не бросать набор keywords
- явно фиксировать, что должно остаться неизменным при editing
Старый, но все еще полезный гайд Google по prompt-writing по-прежнему прав именно в этом: Gemini работает лучше, когда вы не только описываете, что хотите изменить, но и объясняете, что нельзя трогать. Поэтому interactive work почти всегда должна рождаться на synchronous path. Самый быстрый способ улучшить output здесь обычно один: узкая follow-up correction, а не гигантский стартовый prompt.
Есть и еще одно practical advantage. В синхронном workflow сама картинка остается в review loop. Вы видите точный failure mode, сохраняете контекст и просите модель исправить одну конкретную вещь. Для merch tools, ad generators, internal design ops и edit-heavy product flows это почти всегда сильнее, чем batch-first pipeline, который лишь сообщает вам завтра, что prompt был слаб уже сегодня.
Если сначала вы тестируете все в AI Studio, это нормально. Но не путайте testing surface с production contract. В developer post Google о Nano Banana 2 от 26 февраля 2026 года прямо сказано, что для текущей модели в AI Studio нужен paid API key. Значит, AI Studio полезна как place to learn, но не заменяет реальное workflow решение для production.
Лучший batch workflow для очередей и overnight generation
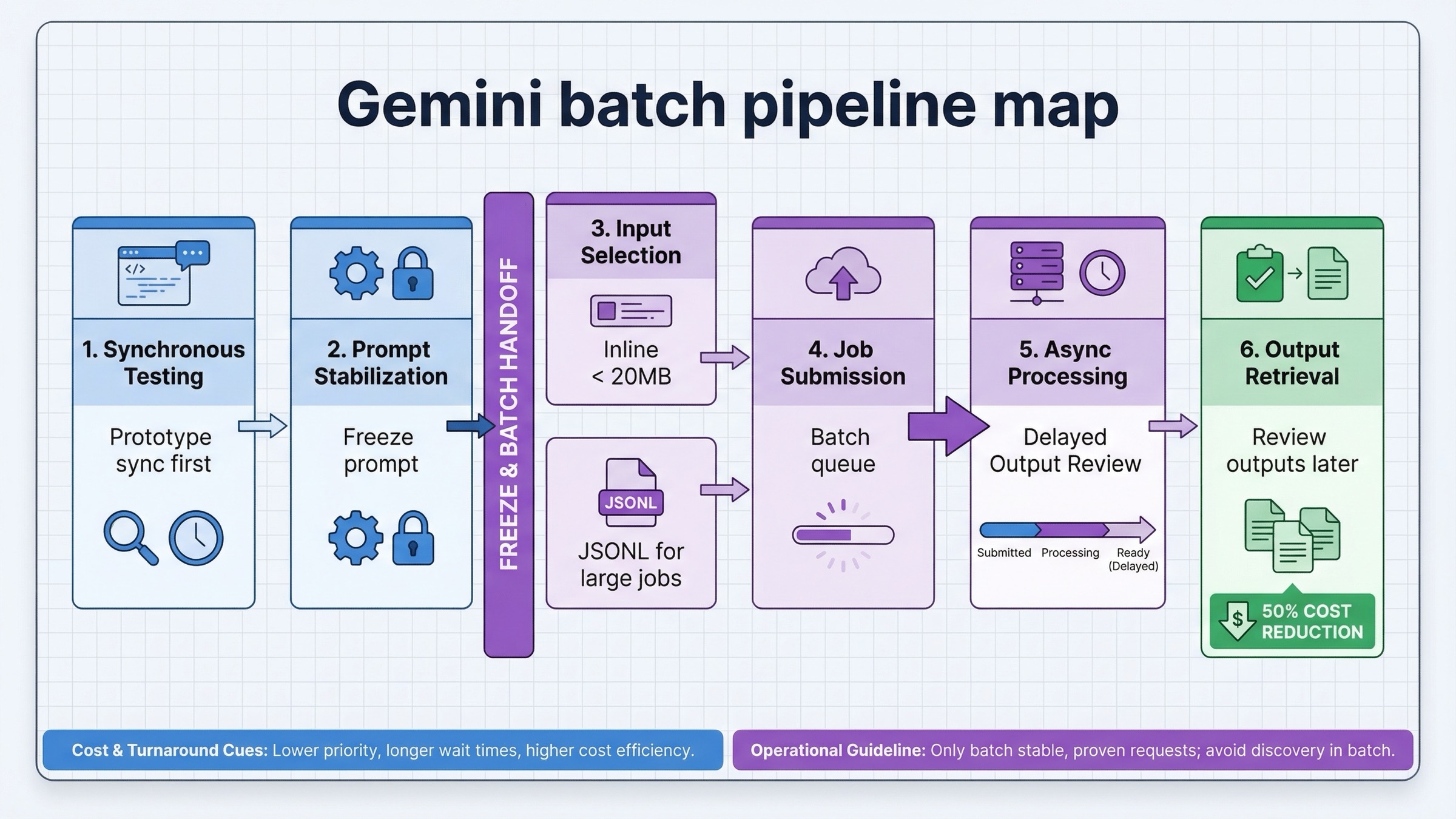
Batch API правильнее всего работает там, где задача одновременно реальна, массова и не срочна. На практике это почти всегда означает одну из трех вещей:
- вам важна суммарная стоимость
- вам нужна throughput-очередь
- вам нужно развести прием запросов и выдачу результатов по разным этапам системы
Именно здесь Batch API становится лучше, чем простые retry вокруг synchronous requests. В official docs Google пишет, что для небольших jobs можно использовать inline requests, а для больших работ переходить на JSONL input files. Для image generation это особенно логично: request payload быстро становится тяжелым, а file-based path легче повторять и воспроизводить.
У хорошего batch workflow обычно такая форма:
- сначала отладить prompt и параметры на synchronous path
- заморозить request format
- сериализовать jobs в JSONL или небольшие inline groups
- отправлять batch только тогда, когда ожидание уже не улучшает качество
- позже собирать outputs и отдельно разбирать retry policy
Этот порядок очень важен. Частая ошибка состоит в том, что команды начинают discovering prompt inside batch, потому что там дешевле. На unit economics это выглядит заманчиво, но operationally это почти всегда проигрыш. Prompt discovery по самой своей природе интерактивна. Batch нужен для стабильного повторения, а не для learning loop.
Когда request уже стабилен, разница в цене становится большой достаточно быстро. На текущих list prices на 23 марта 2026 года 10 000 изображений 1K через gemini-3.1-flash-image-preview дают примерно $670 standard cost и примерно $340 batch cost. Та же задача на gemini-3-pro-image-preview дает примерно $1 340 standard и около $670 batch. Поэтому batch branch действительно важна для catalog refresh, localization runs, scheduled asset generation и других approved-template workflows.
Но Batch API стоит понимать не только как pricing feature. Это отдельная operational surface. На странице rate limits Google пишет о 100 concurrent batch requests, 2GB input file size limit, 20GB file storage и separate enqueued-token accounting per model. То есть batch pressure существует отдельно от обычного synchronous traffic. Можно оставаться в обычных квотах и все равно упереться в batch-specific limits.
Имеет значение и форма запроса. Google указывает, что inline requests подходят, пока общий payload остается меньше 20MB, а дальше лучше переходить к uploaded JSONL file. Для production image workflows чаще всего именно JSONL path оказывается устойчивее: сама batch creation request остается небольшой, а replay и auditing становятся проще.
json{"key":"shoe-0001","request":{"contents":[{"parts":[{"text":"Create a clean white-background ecommerce image of a running shoe in side profile."}]}],"generation_config":{"response_modalities":["IMAGE"]}}} {"key":"shoe-0002","request":{"contents":[{"parts":[{"text":"Create a clean white-background ecommerce image of a black leather loafer in side profile."}]}],"generation_config":{"response_modalities":["IMAGE"]}}}
Этот пример специально простой. У хорошего batch file задача не в красоте, а в воспроизводимости. К моменту, когда запрос попадает в JSONL, и prompt, и generation settings уже должны быть доказаны на synchronous path.
Для большинства команд из этого следует более сильный hybrid pattern:
- используйте synchronous
generateContentдля prompt design, first-pass approval и editing - переводите в Batch API только стабильную, повторяемую работу
- резервируйте batch для задач, где окно в 24 часа приемлемо по бизнес-логике
Такой hybrid workflow обычно сильнее pure batch-first architecture, потому что он разделяет человеческую итерацию и дешевое массовое повторение вместо того, чтобы смешивать их.
Нужна и еще одна оговорка. Official docs обещают target turnaround 24 hours, но не обещают строгий SLA. В начале 2026 года в community threads были жалобы на jobs, которые висели в processing заметно дольше. Это не отменяет official documentation, но напоминает главное: batch надо понимать как queue tool, а не как interactive contract.
Когда Pro меняет ответ, даже если workflow не меняется
После pricing tables очень легко начать думать, будто вся тема сводится к Flash против batch. Но это неверно. Иногда workflow остается тем же, а меняется именно модель.
Здесь и становится полезным gemini-3-pro-image-preview.
Pro выглядит рационально, когда цена слабого результата уже заметно выше, чем цена самой модели. Типичные случаи такие:
- diagrams и infographics с реальным текстом
- polished campaign assets
- client-facing visuals с высокой ценой ошибки
- factual visuals, где важны layout и label accuracy
- premium outputs, где важнее снизить число неудачных первых draft
Заметьте, что сам workflow choice в этом списке не изменился. Если результат все еще нужен человеку прямо сейчас, работа все равно остается синхронной. Если это по-прежнему большой не срочный export run, batch все еще может быть правильной operational surface. Вопрос модели и вопрос workflow не надо смешивать.
Это дает четыре практических маршрута вместо двух:
- Flash + synchronous для большинства интерактивных задач
- Flash + batch для repeatable cost-sensitive generation
- Pro + synchronous для premium iterative work
- Pro + batch для не срочных high-stakes bulk jobs
Самый полезный критерий здесь не "какая модель лучше абстрактно", а "какова цена ошибки для бизнеса". Если asset low-risk и массовый, Flash почти всегда выигрывает. Если работа text-heavy, design-sensitive и дорога в переделке, Pro становится разумным уже даже при том же самом workflow.
Как проверить, что вы выбрали неправильный workflow
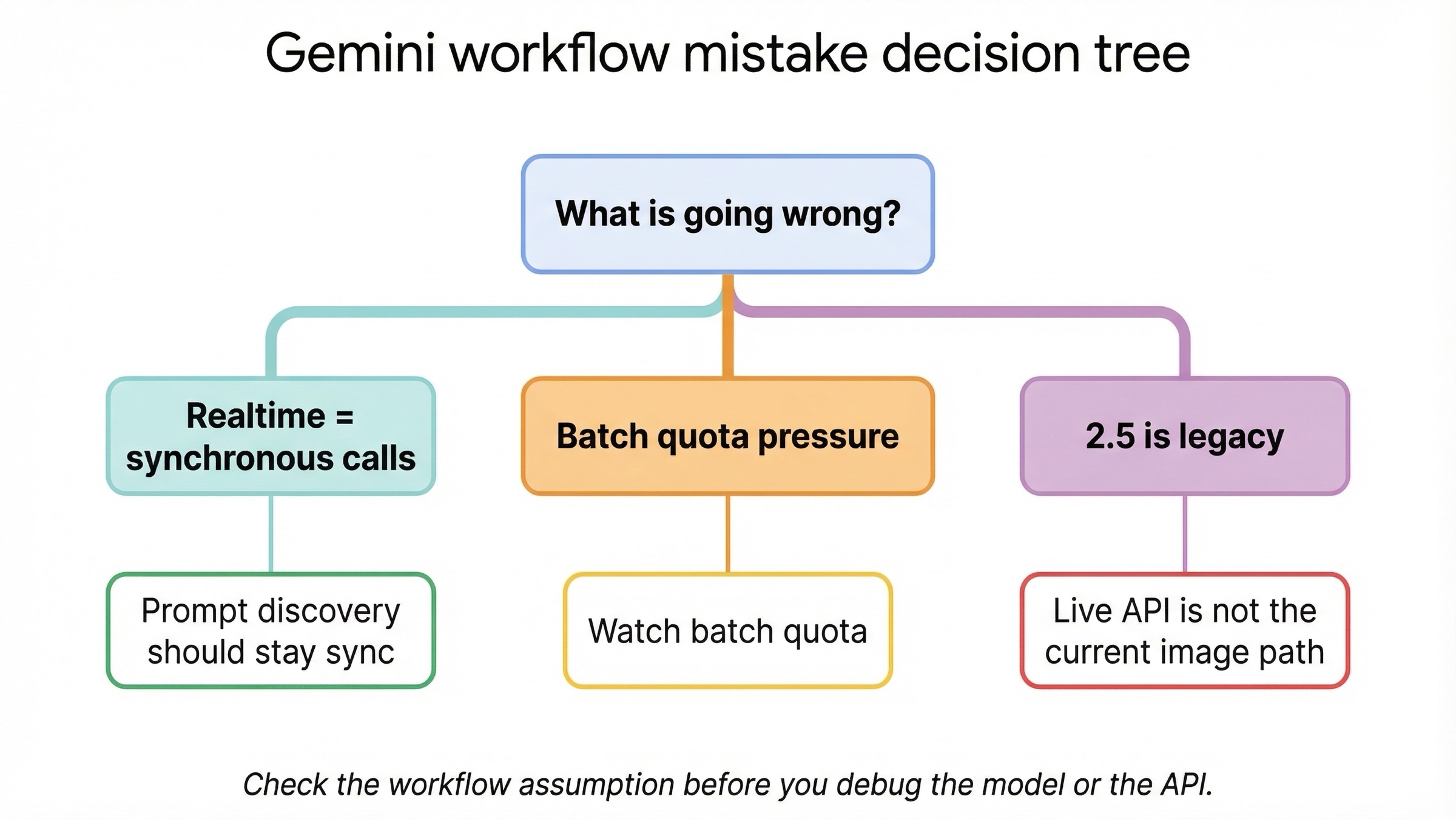
Большинство проблем в этой теме рождается не из плохого API, а из неправильного workflow decision.
Вы слишком широко используете слово realtime. Для текущих Gemini image models realtime почти всегда означает обычный synchronous request-response flow, а не Live API image output. Если не сделать это уточнение сразу, очень легко потратить часы на неверную architecture branch.
Вы уходите в batch слишком рано. Discount реален, но batch все равно не предназначен для prompt discovery. Сначала найдите рабочий prompt, убедитесь в correct output shape и только потом переносите стабильную версию в очередь.
Вы смешиваете workflow question и lifecycle question. gemini-2.5-flash-image действительно дешевле, но Google уже поставил ему shutdown date 2 октября 2026 года. Если выбираете его, делайте это как сознательный legacy-economics move, а не как default path для нового продукта.
Вы смотрите только на обычные quotas и пропускаете batch-specific pressure. У batch свои ограничения, включая enqueued-token pressure. Именно поэтому monitoring для batch workflows должен быть отдельным, а не копией synchronous dashboards.
Вы слишком доверяете AI Studio как полной product story. AI Studio удобна для testing и prompt iteration, но приложение потом живет по API contract, model capability pages и pricing surface, которые вы реально deployите. Удачный тест в AI Studio не отменяет необходимости правильно выбрать workflow.
Вы хотите решить model problem через workflow switch. Иногда проблема не в том, что нужен batch вместо synchronous, а в том, что нужна Pro-модель вместо Flash. Если prompt стабилен, но output по-прежнему слишком слаб для text-heavy visual, менять стоит модель, а не surface.
Если вам важнее lifecycle и migration story вокруг старой image line, дальше логично читать чем заменить Gemini 2.5 Flash Image.
Вывод
Самый полезный ответ на запрос про Gemini image generation batch vs realtime сегодня звучит не как абстрактное сравнение API surfaces, а как простое routing rule.
Если результата ждет человек, оставайтесь на синхронном generateContent. Если работа большая, не срочная и уже не зависит от prompt-итерации, используйте Batch API. Для большинства новых задач начинайте с gemini-3.1-flash-image-preview. На gemini-3-pro-image-preview переходите тогда, когда текст, layout и цена ошибки делают premium lane рациональной. gemini-2.5-flash-image оставляйте только как сознательный legacy-economics choice, помня о его shutdown date 2 октября 2026 года.
Именно такой порядок делает тему проще: сначала выберите workflow по latency tolerance, потом выберите модель по цене ошибки. Не наоборот.