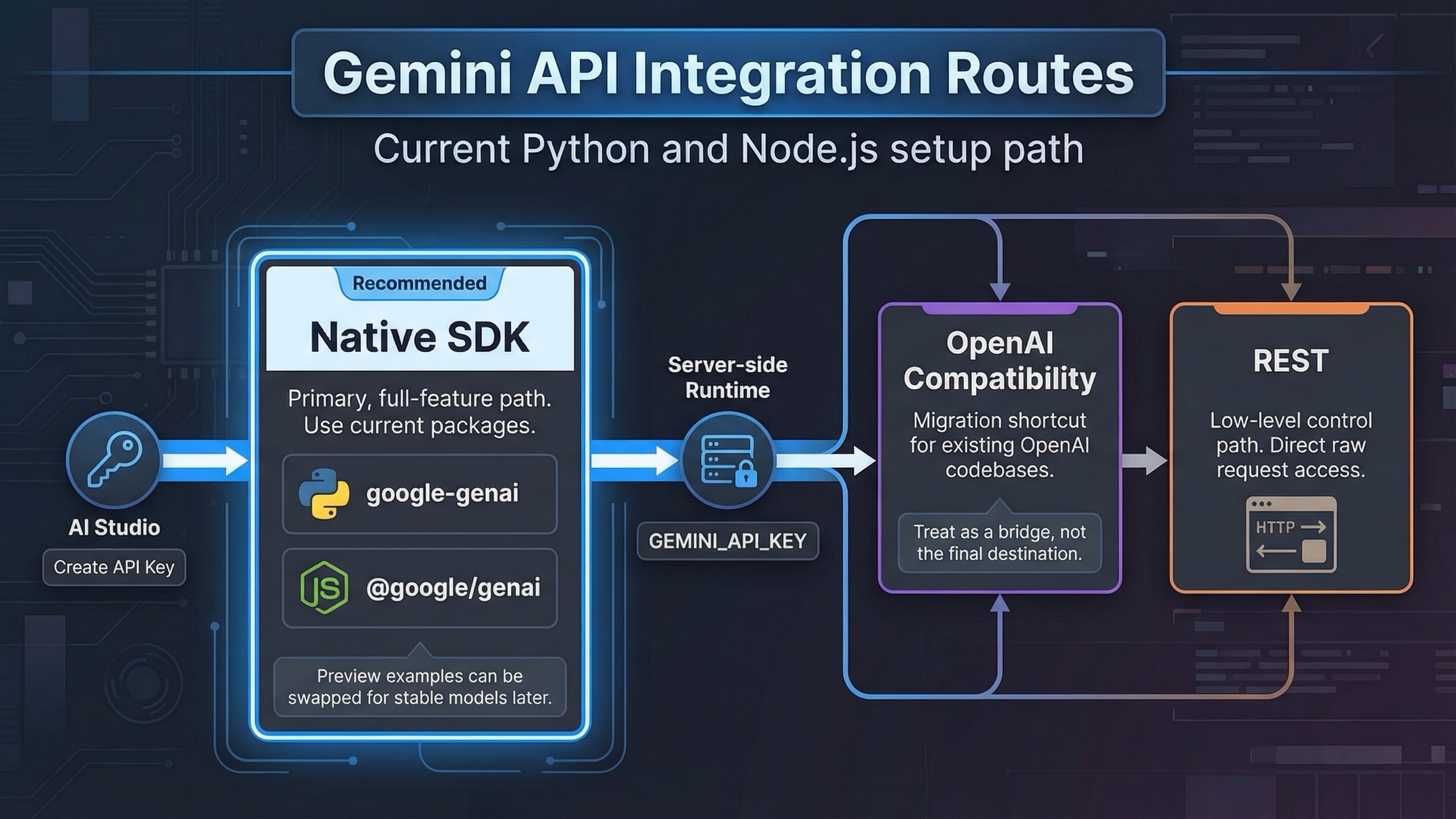
Если вы запускаете новую интеграцию Gemini API сегодня, начните с нативного Google GenAI SDK, держите GEMINI_API_KEY на сервере и сначала добейтесь одного рабочего запроса, а уже потом добавляйте streaming, tools и files. OpenAI-совместимость имеет смысл выносить вперед только тогда, когда у вас уже есть кодовая база с OpenAI-формой клиента и нужен быстрый миграционный мост. Это самый надежный дефолт, потому что текущие quickstart, migration guide и example repo Google уже опираются на google-genai для Python и @google/genai для JavaScript.
Практическая ценность этого гайда в том, что он помогает правильно пройти первый день интеграции. Сначала зафиксируйте правильный SDK, секретную границу и первый успешный запрос; затем по порядку добавляйте streaming, structured output, function calling, Files API и проверку billing plus rate limits. Такой маршрут полезнее очередного hello world, потому что позволяет не уйти сразу в старый пакет, старую форму клиента или неправильную production-схему.
Официальные примеры Google и сейчас часто используют preview-идентификаторы моделей, прежде всего gemini-3-flash-preview, поэтому в примерах ниже они тоже сохранены. Но production-правило шире. Если для вашей нагрузки существует стабильная модель, Google прямо рекомендует предпочитать стабильный model ID. На практике это значит, что вы можете быстро запустить примеры как есть, а потом переключиться, например, на gemini-2.5-flash, если вам важнее меньшая турбулентность, чем доступ к самому свежему preview-поверхностному слою.
Краткое содержание
- Для новых интеграций используйте
google-genaiв Python и@google/genaiв JavaScript. Это текущие официальные пакеты, и migration guide Google рекомендует уходить со старых Gemini-библиотек. - Создайте ключ в Google AI Studio, храните его в
GEMINI_API_KEYи вызывайте Gemini только с серверной поверхности: backend, worker, API route, server action. - Сначала добейтесь одного успешного нативного запроса. Затем добавьте streaming. После этого уже подключайте structured output, function calling или Files API под реальную задачу.
- Используйте OpenAI compatibility, когда вам нужно быстро адаптировать существующий OpenAI-ориентированный код. Но не делайте ее долгосрочным дефолтом, если вам нужны Gemini-native возможности вроде Files API или более плотной работы с tools.
- Когда общий размер запроса превышает 100 MB, а для PDF 50 MB, переходите на Files API. По официальной документации файлы хранятся 48 часов, лимит проекта составляет 20 GB, а одного файла 2 GB.
- Не откладывайте billing и quota до первой аварии. На странице billing Google пишет, что ошибки 400 и 500 не тарифицируются, но все равно расходуют quota. А страница rate limits подчеркивает, что реальные лимиты зависят от usage tier и проверяются в AI Studio.
| Маршрут | Для кого подходит | Почему работает | Главный компромисс |
|---|---|---|---|
| Нативный Google GenAI SDK | Новые Python и Node.js приложения | Актуальные пакеты, актуальная документация, прямой доступ к streaming, structured output, files и tools | Нужно принять нативную форму клиента Gemini, а не жить только внутри OpenAI-абстракции |
| Совместимость OpenAI | Уже существующие OpenAI-подобные кодовые базы | Самый быстрый путь миграции: меняются base URL, API key и model name | Ниже потолок по функциям и больше трения на Gemini-специфических возможностях |
| Чистый REST | Нишевые языки, жесткий контроль зависимостей, отладка низкого уровня | Максимум контроля над запросами и отсутствие веса SDK | Больше boilerplate, ручной сериализации и ручной обработки сложных режимов |
Если вам сейчас не хватает именно ценового контекста, следующая полезная статья в локализованной сетке это гайд по ценам Gemini API за токены. Если вы уже уткнулись в 400, 403, 429 или 500, логичнее сразу идти в гайд по ошибкам Gemini API.
Как сделать первый запрос к Gemini API правильно
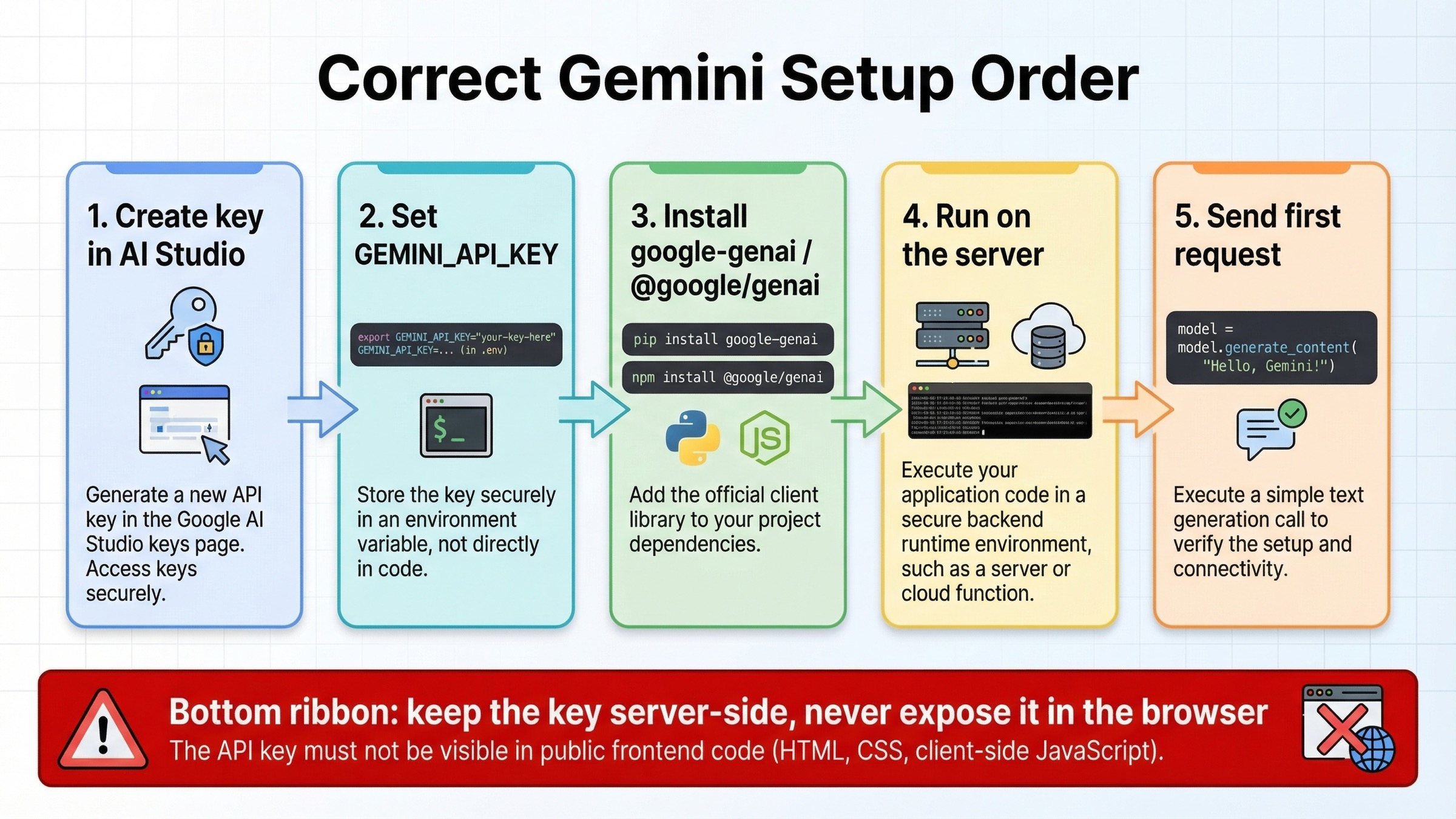
Правильная точка входа находится не в IDE, а в AI Studio. Текущая документация Google объясняет, что ключи Gemini API создаются и управляются через Google AI Studio, а сам ключ привязан к Google Cloud project. Для нового пользователя это удобно, потому что AI Studio часто автоматически создает дефолтный проект и ключ. Но именно из-за этого многие слишком поздно задумываются о собственности проекта, биллинге и разделении окружений между тестом и production.
Первая важная привычка здесь не синтаксическая, а операционная: держите GEMINI_API_KEY на сервере. Для backend-сервиса это обычная переменная окружения. Для веб-приложения это server route, API route, edge backend или отдельный worker. Не передавайте постоянный ключ в браузер и не считайте безопасным паттерн “пусть пользователь сам вставит ключ на фронтенде”. Для production-интеграции это почти всегда плохой старт.
Текущая официальная установка выглядит так:
bashpip install -U google-genai npm install @google/genai
Потом задайте ключ:
bashexport GEMINI_API_KEY="your_real_key_here"
После этого первая проверка должна быть нарочно скучной. Не начинайте с function calling, grounding или multimodal-файлов. Цель первого запроса только одна: убедиться, что ключ, окружение, runtime и сетевая дорожка работают правильно.
pythonfrom google import genai client = genai.Client() response = client.models.generate_content( model="gemini-3-flash-preview", contents="Explain the purpose of an API integration tutorial in one sentence." ) print(response.text)
javascriptimport { GoogleGenAI } from "@google/genai"; const ai = new GoogleGenAI({}); const response = await ai.models.generateContent({ model: "gemini-3-flash-preview", contents: "Explain the purpose of an API integration tutorial in one sentence.", }); console.log(response.text);
Ключевая вещь здесь не сам prompt, а форма клиента. Новый Google GenAI SDK централизует models, chats, files и другие сервисы в одном клиенте. Именно поэтому старые статьи сегодня часто сбивают с толку: они учат не просто старым пакетам, а уже неактуальной структуре клиента. Чем раньше вы стандартизируете новый shape, тем меньше потом миграционной грязи.
Примеры интеграции на Python, которые не устарели в 2026 году
Python по-прежнему остается самым прямым путем, если вам нужны и короткие базовые примеры, и удобные продвинутые helpers. Следующий действительно полезный шаг после обычного generate_content это streaming. В текущем text-generation guide Google для этого показан generate_content_stream, и для production это первый апгрейд, который реально меняет ощущение от продукта.
pythonfrom google import genai client = genai.Client() stream = client.models.generate_content_stream( model="gemini-3-flash-preview", contents="Write three short tips for migrating from a legacy LLM SDK." ) for chunk in stream: print(chunk.text, end="")
Streaming важен не только для чат-приложений. Он помогает CLI, внутренним инструментам, серверным рендерингам и любому интерфейсу, где важно снизить воспринимаемую задержку. Сильный туториал по интеграции должен толкать читателя именно туда: от “модель ответила” к “продукт начал вести себя быстрее и аккуратнее”.
Второй Python-паттерн, который быстро окупается, это structured output. Официальный guide по structured outputs показывает, что Gemini может следовать JSON Schema, а Python SDK поддерживает и прямую работу через Pydantic. Это важно, потому что реальные интеграции часто строятся не вокруг “написать абзац”, а вокруг “вернуть структуру, которую дальше обработает другой сервис”.
pythonfrom google import genai from google.genai import types from pydantic import BaseModel class IntegrationTicket(BaseModel): language: str task: str priority: str client = genai.Client() response = client.models.generate_content( model="gemini-3-flash-preview", contents="Python app, needs JSON output, shipping next week.", config=types.GenerateContentConfig( response_mime_type="application/json", response_schema=IntegrationTicket, ), ) print(response.text)
Такой подход гораздо надежнее, чем просто попросить модель “ответить в JSON” и надеяться, что формат не съедет. Как только схема передается прямо в запрос, prompt перестает тратить энергию на дисциплину форматирования и начинает работать на смысл. Это один из самых практичных переходов от demo-режима к интеграции, которая кормит downstream-системы.
Отдельный плюс Python-маршрута это function calling. Google объясняет, что Python SDK может взять реальную функцию с type hints и docstring, превратить ее в tool declaration, вызвать и вернуть финальный ответ. Для внутренних инструментов, быстрых agent-потоков и мелких сервисных автоматизаций это ускоряет разработку очень заметно.
pythonfrom google import genai from google.genai import types def get_current_temperature(location: str) -> dict: """Gets the current temperature for a given location.""" return {"temperature": 25, "unit": "Celsius"} client = genai.Client() response = client.models.generate_content( model="gemini-3-flash-preview", contents="What's the temperature in Boston?", config=types.GenerateContentConfig(tools=[get_current_temperature]), ) print(response.text)
Но использовать эту удобную прослойку стоит осознанно. Она особенно хороша, когда Python сам является execution center. Если же вам нужна строгая мультисервисная оркестрация, единая audit-поверхность или межъязыковой tool layer, слишком “магическая” автоматизация может быть уже не лучшим долговременным выбором.
Примеры интеграции на JavaScript и Node.js
В Node.js форма клиента примерно та же, что и в Python, но практический риск другой. JavaScript-команды часто строят веб-продукты и слишком рано смешивают секреты, клиент SDK и фронтенд-логику. В результате проблема выглядит как “интеграция Gemini”, хотя на самом деле это ошибка границы исполнения. Сам пакет @google/genai тут ни при чем. Ключевой вопрос в том, где запускается код: в Node-процессе, server action, API route, edge backend или worker.
Базовый JavaScript-запрос должен выглядеть так:
javascriptimport { GoogleGenAI } from "@google/genai"; const ai = new GoogleGenAI({}); const response = await ai.models.generateContent({ model: "gemini-3-flash-preview", contents: "Give me a one-line summary of why current SDK names matter.", }); console.log(response.text);
Следующий шаг снова streaming:
javascriptimport { GoogleGenAI } from "@google/genai"; const ai = new GoogleGenAI({}); const stream = await ai.models.generateContentStream({ model: "gemini-3-flash-preview", contents: "List three practical steps for hardening an API integration.", }); for await (const chunk of stream) { process.stdout.write(chunk.text ?? ""); }
Именно здесь Node начинает ощущаться особенно сильным для web-backend сценариев. Вы можете держать ключ на сервере и в то же время отдавать клиенту потоковый ответ через SSE или streamed HTTP response. Это повышает UX без компромисса по безопасности. Если у вас Next.js, Express или любой другой backend c incremental delivery, такой маршрут почти всегда правильнее, чем отправлять пользователю только финальный монолитный ответ.
JavaScript также поддерживает structured output и function calling, но ergonomics здесь намеренно более явные. В официальных примерах Google для structured output используется Zod, а для tools конфигурации вроде functionCallingConfig. Для TypeScript-команд это не недостаток, а скорее плюс: запросы и схемы проще вписать в существующую типовую дисциплину и сервисные контракты.
Еще одна ранняя production-привычка, которую стоит закрепить в JS-стеке, это счетчик токенов. Официальный token guide рекомендует использовать count-tokens методы и usage metadata вместо грубой оценки по символам. В JavaScript-продуктах prompts обычно разрастаются незаметно: к ним добавляются system instructions, пользовательский контекст, RAG-фрагменты, tool logs. Чем раньше вы начинаете это измерять, тем меньше вероятность, что первая неприятность придет не из модели, а из счета или лимитов.
Когда стоит использовать совместимость с OpenAI
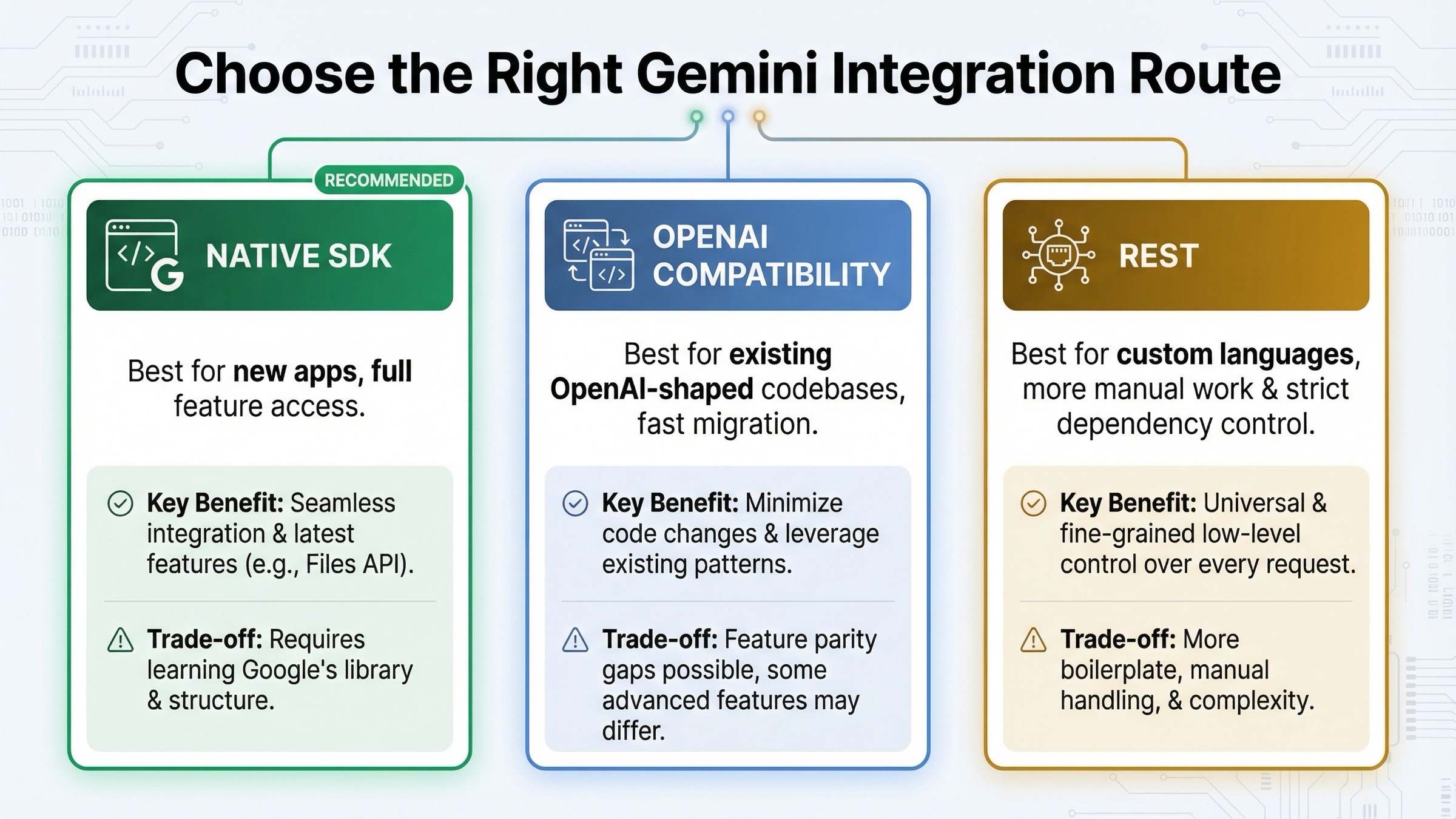
OpenAI-совместимость действительно полезна, но ее часто неправильно понимают. Официальный guide Google показывает, что быстрый путь состоит почти из трех изменений: другой base URL, Gemini API key вместо ключа OpenAI и другой model name. Если у вас уже есть сервисный слой, заточенный под OpenAI messages и привычную клиентскую форму, это часто самый быстрый способ проверить Gemini в реальной нагрузке.
pythonfrom openai import OpenAI client = OpenAI( api_key="YOUR_GEMINI_API_KEY", base_url="https://generativelanguage.googleapis.com/v1beta/openai/", ) response = client.chat.completions.create( model="gemini-3-flash-preview", messages=[{"role": "user", "content": "Explain why compatibility layers are useful."}], ) print(response.choices[0].message.content)
Этот маршрут привлекателен по двум причинам. Во-первых, не нужно немедленно переучивать всю команду на новую форму клиента. Во-вторых, проще строить provider-comparison или bring-your-own-key логику, если инфраструктура уже нормализована вокруг OpenAI-подобных сообщений. Когда ваша цель это скорость проверки или быстрая миграция, совместимость часто является правильным первым ответом.
Но это не означает, что совместимость должна стать вечным базовым слоем. В partner-integration и related guides Google довольно прямо формулирует компромисс: OpenAI compatibility хороша для миграционного мостика, но хуже подходит как долгосрочный дефолт, если вам нужны Gemini-native возможности вроде Files API, нативных tool flows или дальнейшей эволюции SDK. Чем больше ваш workload зависит от этих поверхностей, тем заметнее слой совместимости начинает работать как трансляционный налог.
Практическое правило здесь очень простое. Для новой Gemini-интеграции выбирайте нативный SDK. Для адаптации существующего OpenAI-ориентированного production-кода начинайте с compatibility. Это удерживает архитектуру ближе к реальной задаче, а не к привычке команды.
Что изучать сразу после hello world
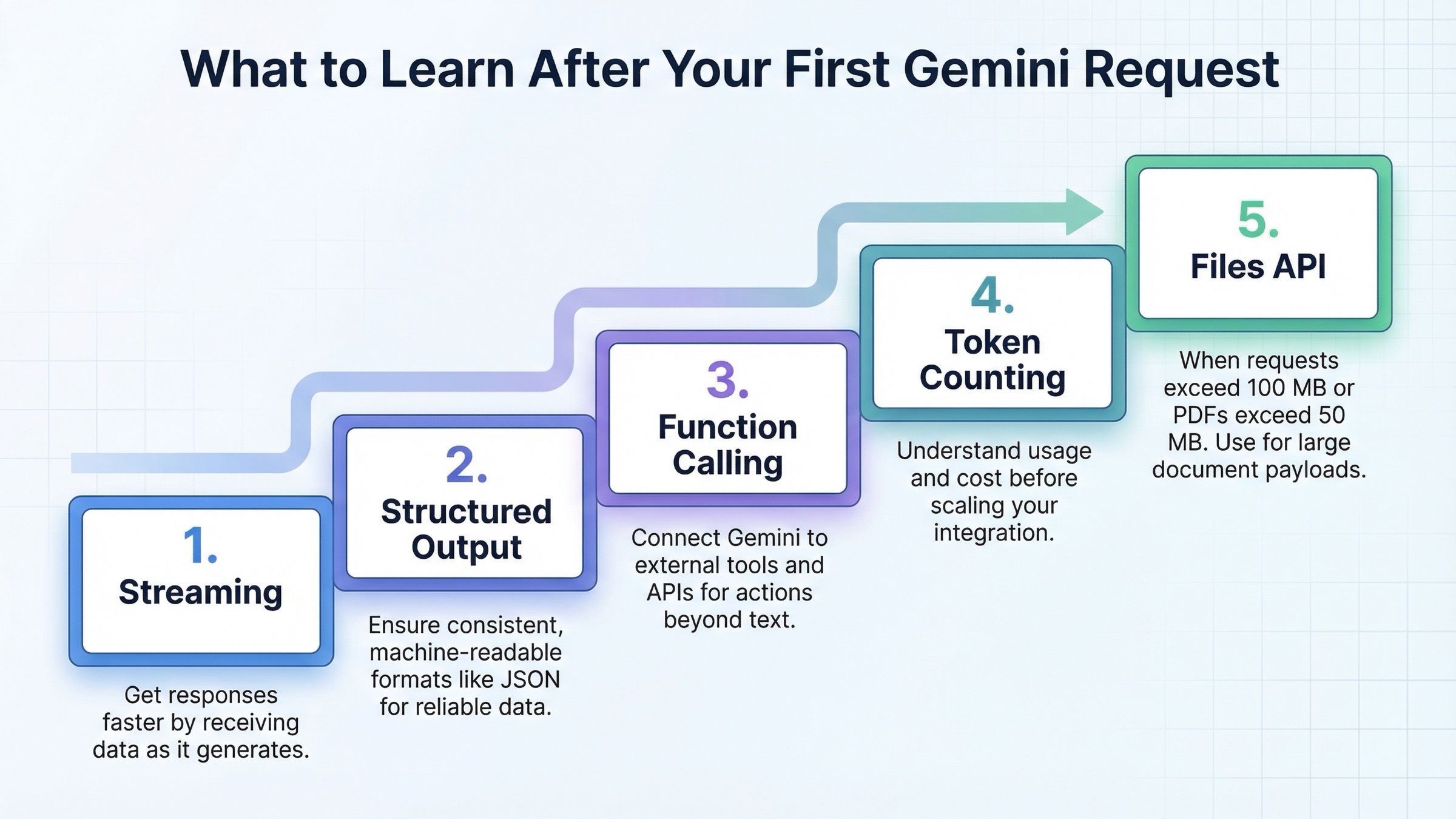
После первого успешного запроса не нужно “изучить все возможности Gemini”. Нужно изучить небольшой набор функций, которые действительно меняют поведение приложения. Обычно правильный порядок такой: streaming, structured output, function calling, token counting и только затем Files API.
Streaming улучшает отзывчивость. Structured output делает downstream-автоматизацию безопаснее. Function calling связывает Gemini с вашим кодом и внешними системами. Token counting дает раннее понимание стоимости и роста контекста. Files API становится обязательным, когда запросы становятся действительно крупными или мультимодальными. В официальном Files guide Google пишет, что переходить на Files API нужно при размере запроса более 100 MB, а для PDF уже после 50 MB. Там же зафиксированы 48 часов хранения, 20 GB на проект и 2 GB на файл. Для production это не “мелкие детали”, а параметры дизайна ingestion и retention.
javascriptimport { GoogleGenAI, createPartFromUri, createUserContent, } from "@google/genai"; const ai = new GoogleGenAI({}); const myfile = await ai.files.upload({ file: "path/to/sample.mp3", config: { mimeType: "audio/mpeg" }, }); const response = await ai.models.generateContent({ model: "gemini-3-flash-preview", contents: createUserContent([ createPartFromUri(myfile.uri, myfile.mimeType), "Describe this audio clip", ]), }); console.log(response.text);
Используйте Files API тогда, когда он действительно нужен. Не загружайте файлы только потому, что API это позволяет. Для маленьких текстовых запросов лучший запрос по-прежнему самый простой. Но и откладывать Files до последнего не стоит. Как только вы входите в большие вложения, жизненный цикл файла и лимиты перестают быть опциональным знанием.
| Возможность | Когда учить | Почему это важно | Официальная опора |
|---|---|---|---|
| Streaming | Сразу после первого успешного запроса | Улучшает воспринимаемую задержку и UX интерактивных приложений | Text generation |
| Structured output | Как только другой сервис начинает зависеть от ответа Gemini | Снижает хрупкость автоматизации и убирает JSON-хакерство из prompt | Structured outputs |
| Function calling | Когда Gemini должен запускать бизнес-логику или инструменты | Делает agent-like сценарии практичными без prompt-spaghetti | Function calling |
| Token counting | До production-трафика и до первых cost-алармов | Позволяет измерять рост контекста и заранее оценивать расходы | Token counting |
| Files API | Когда размер запроса превышает 100 MB, а PDF 50 MB | Делает работу с крупными multimodal-вложениями управляемой | Files API |
Этот порядок важен, потому что слабые туториалы обычно падают в одну из двух крайностей. Либо они останавливаются на простом text prompt и не доводят читателя до production-навыков. Либо пытаются показать все сразу и разрушают чувство приоритета. Полезная середина это один надежный запрос, а затем небольшой набор возможностей, которые меняют реальные эксплуатационные результаты.
Типичные ошибки и troubleshooting при интеграции Gemini
Самая частая ошибка это старт с неправильного туториала. Если вы видите в статье google-generativeai или @google/generative-ai как основной “текущий” путь, остановитесь и сразу сверьтесь с migration guide Google. Старые примеры не всегда полностью бесполезны, но они уже не являются чистой точкой отсчета для интеграции в 2026 году. Самый быстрый способ сократить путаницу это с первого дня стандартизироваться на текущих пакетах и текущей форме клиента.
Вторая типовая ошибка это воспринимать preview model IDs как стабильный контракт. В models guide Google прямо говорит, что preview-модели могут использоваться и в production, но обычно у них выше риск депрекации и жестче лимиты. Это не значит, что preview нужно избегать любой ценой. Это значит, что их нужно использовать осознанно и держать план на pin или swap model IDs. Если вашему продукту не нужен самый свежий preview-only surface, стабильная модель обычно безопаснее.
Третья ошибка касается quota и billing. На billing page Google пишет, что биллинг строится вокруг input tokens, output tokens, cached token count и cached token storage duration. Там же указано, что ошибки 400 и 500 не тарифицируются, но продолжают расходовать quota. Это важно, потому что многие читают “not billed” и ошибочно трактуют это как “почти бесплатно”. Нет. Прямого списания может не быть, но пропускная способность проекта и лимиты продолжают гореть.
Особенно заметно это на 429. Rate-limit docs и обсуждения в сообществе показывают, почему путаница сохраняется: вы можете быть ниже ожидаемого RPM и все равно упереться в enqueued tokens, проектные ограничения, free-tier exhaustion или емкость preview-линии. Поэтому при 429 полезнее не просто усиливать retry с exponential backoff, а сначала понять природу ограничения. Если нужен более детальный разбор по кодам ошибок, переходите к гайду по ошибкам Gemini API.
Последняя распространенная ошибка это переусложнить первую неделю интеграции. Вам не нужны сразу streaming, tools, files, structured output, caches и длинная chat history. Вам нужен один успешный серверный запрос, одна надежная граница секрета и одна следующая функция, которая действительно соответствует продуктовой задаче. Команды, которые держатся этой последовательности, обычно доходят до рабочего endpoint быстрее, чем те, кто пытается “изучить все Gemini” до первой рабочей ручки.
Самое полезное production-правило можно уместить в одну строку: начинайте нативно, держите ключ на сервере, рано считайте токены и добавляйте новые возможности только тогда, когда их требует реальный кейс. Для большинства интеграций это спасает от большего числа проблем, чем любой гигантский сборник сниппетов.