
По состоянию на март 2026 года цены Gemini API для текстовых моделей находятся примерно в диапазоне от 0,10 доллара за 1 млн входных токенов до 2,00 долларов, а для выходных токенов от 0,40 доллара до 12,00 долларов за 1 млн. Самая дешевая стабильная текстовая модель сейчас по-прежнему Gemini 2.5 Flash-Lite. Если вам важно оставаться именно на линейке Gemini 3, то бюджетный вариант сегодня это Gemini 3.1 Flash-Lite Preview. А Gemini 3.1 Pro Preview остается премиальной текстовой моделью, где цена резко вырастает, если промпт превышает 200K токенов.
Эту страницу полезно читать как быстрый бюджетный калькулятор принятия решений. Сначала нужно понять, какую модель закладывать в смету, в какой момент порог 200K токенов меняет экономику и какие доплаты сильнее всего искажают итоговый счет. Поэтому материал намеренно держится только линии Gemini Developer API и отдельно разбирает Batch, caching, grounding, audio и long-context пороги — именно они чаще всего меняют реальную стоимость сильнее, чем базовая строка input/output.
Краткое содержание
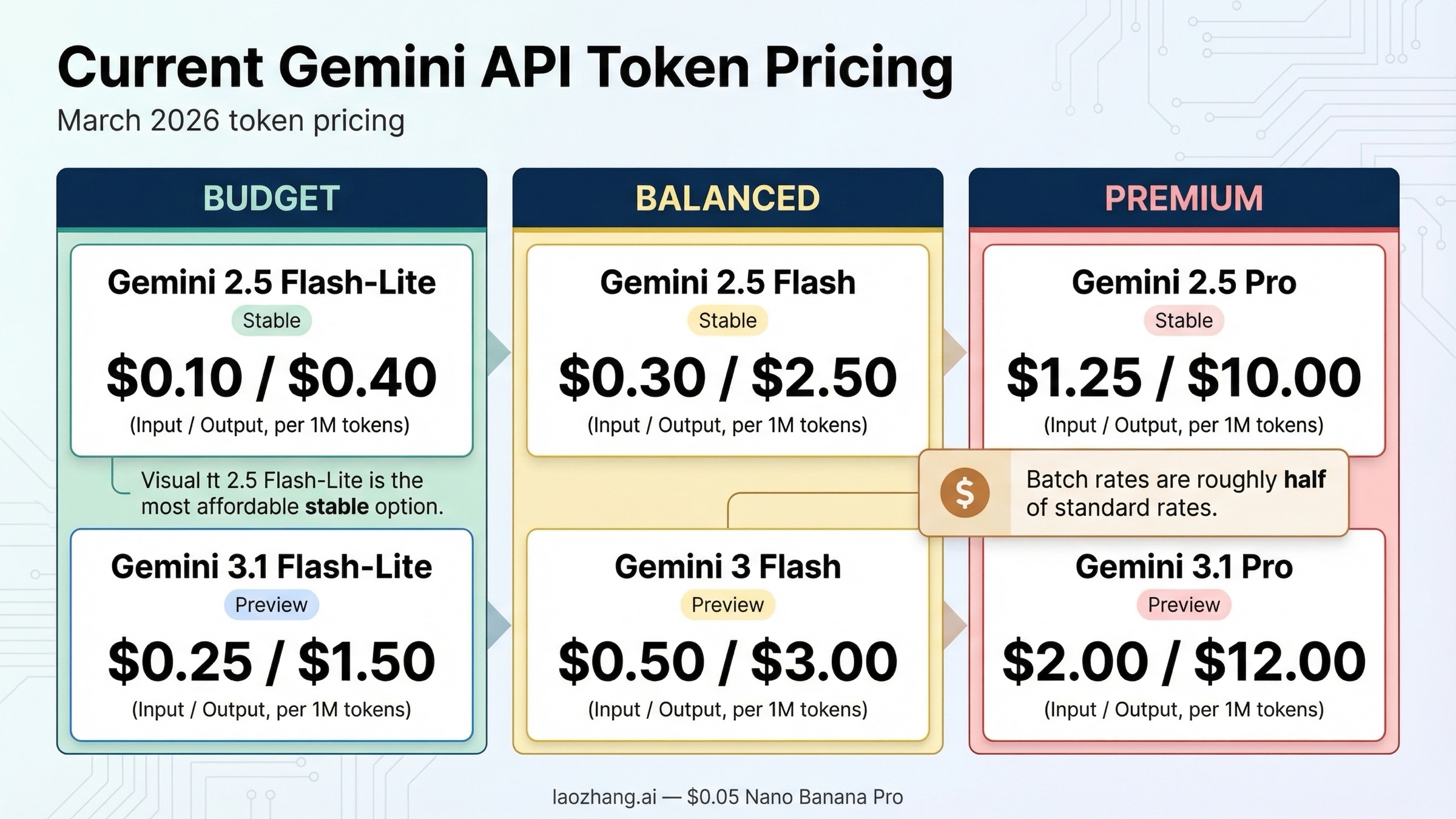
- Самая дешевая стабильная текстовая модель: Gemini 2.5 Flash-Lite, 0,10 доллара за 1 млн входных токенов и 0,40 доллара за 1 млн выходных.
- Самая дешевая модель в линейке Gemini 3: Gemini 3.1 Flash-Lite Preview, 0,25 доллара за 1 млн входных токенов и 1,50 доллара за 1 млн выходных.
- Текущий премиальный вариант: Gemini 3.1 Pro Preview, 2,00 / 12,00 доллара за 1 млн токенов до 200K и 4,00 / 18,00 доллара выше этого порога.
- Наиболее практичный дефолт для многих production-задач: Gemini 2.5 Flash. Она заметно дешевле Pro, но ощутимо сильнее Flash-Lite в рабочих сценариях.
- Самый быстрый способ снизить расходы: режим Batch. Для основных текстовых моделей он обычно примерно вдвое дешевле стандартного режима.
- Главная ошибка в оценке бюджета: смотреть только на цену input/output и забывать про порог 200K, аудио-ввод, context caching, стоимость хранения кеша и grounding.
Таблица цен Gemini API за токены на март 2026
Официальная страница Gemini Developer API pricing остается главным источником правды, но для быстрого сравнения она не всегда удобна. Ниже собраны именно те текстовые модели, которые разработчики чаще всего сравнивают между собой сегодня.
| Модель | Стандартная цена input | Стандартная цена output | Batch input | Batch output | Комментарий |
|---|---|---|---|---|---|
| Gemini 3.1 Pro Preview | 2,00 доллара за 1 млн до 200K, 4,00 доллара выше 200K | 12,00 доллара до 200K, 18,00 доллара выше 200K | 1,00 доллара до 200K, 2,00 выше 200K | 6,00 доллара до 200K, 9,00 выше 200K | Только paid, текущий премиальный текстовый путь |
| Gemini 3 Flash Preview | 0,50 доллара за text / image / video, 1,00 доллара за audio | 3,00 доллара | 0,25 доллара за text / image / video, 0,50 за audio | 1,50 доллара | Быстрая линия Gemini 3, доступен free tier |
| Gemini 3.1 Flash-Lite Preview | 0,25 доллара за text / image / video, 0,50 за audio | 1,50 доллара | 0,125 доллара за text / image / video, 0,25 за audio | 0,75 доллара | Самый дешевый текстовый путь внутри Gemini 3 |
| Gemini 2.5 Pro | 1,25 доллара до 200K, 2,50 доллара выше 200K | 10,00 доллара до 200K, 15,00 доллара выше 200K | 0,625 доллара до 200K, 1,25 выше 200K | 5,00 доллара до 200K, 7,50 выше 200K | Более доступная сильная альтернатива 3.1 Pro |
| Gemini 2.5 Flash | 0,30 доллара за text / image / video, 1,00 за audio | 2,50 доллара | 0,15 доллара за text / image / video, 0,50 за audio | 1,25 доллара | Сбалансированный стабильный вариант |
| Gemini 2.5 Flash-Lite | 0,10 доллара за text / image / video, 0,30 за audio | 0,40 доллара | 0,05 доллара за text / image / video, 0,15 за audio | 0,20 доллара | Самая дешевая стабильная линия |
Из этой таблицы нужно вынести две вещи.
Во-первых, актуальная линейка Google не устроена как простая лестница, где все новое автоматически и лучше, и выгоднее. Если вам нужен минимальный стабильный текстовый cost, выигрывает Gemini 2.5 Flash-Lite. Если вам нужно остаться именно на Gemini 3, тогда бюджетная ветка сейчас это Gemini 3.1 Flash-Lite Preview. Многие сторонние статьи сводят все к одной общей строке "Gemini 3 pricing", и этим только мешают принять правильное решение.
Во-вторых, в результатах поиска до сих пор часто встречается Gemini 3 Pro Preview. Но это уже устаревшая ссылка. На официальной странице моделей Google прямо предупреждает, что Gemini 3 Pro Preview был отключен 9 марта 2026 года, и рекомендует переходить на Gemini 3.1 Pro Preview. Если статья по-прежнему сравнивает Gemini 3 Pro Preview как живую модель, остальные ее цифры тоже стоит перепроверить.
Какую модель Gemini стоит закладывать в бюджет
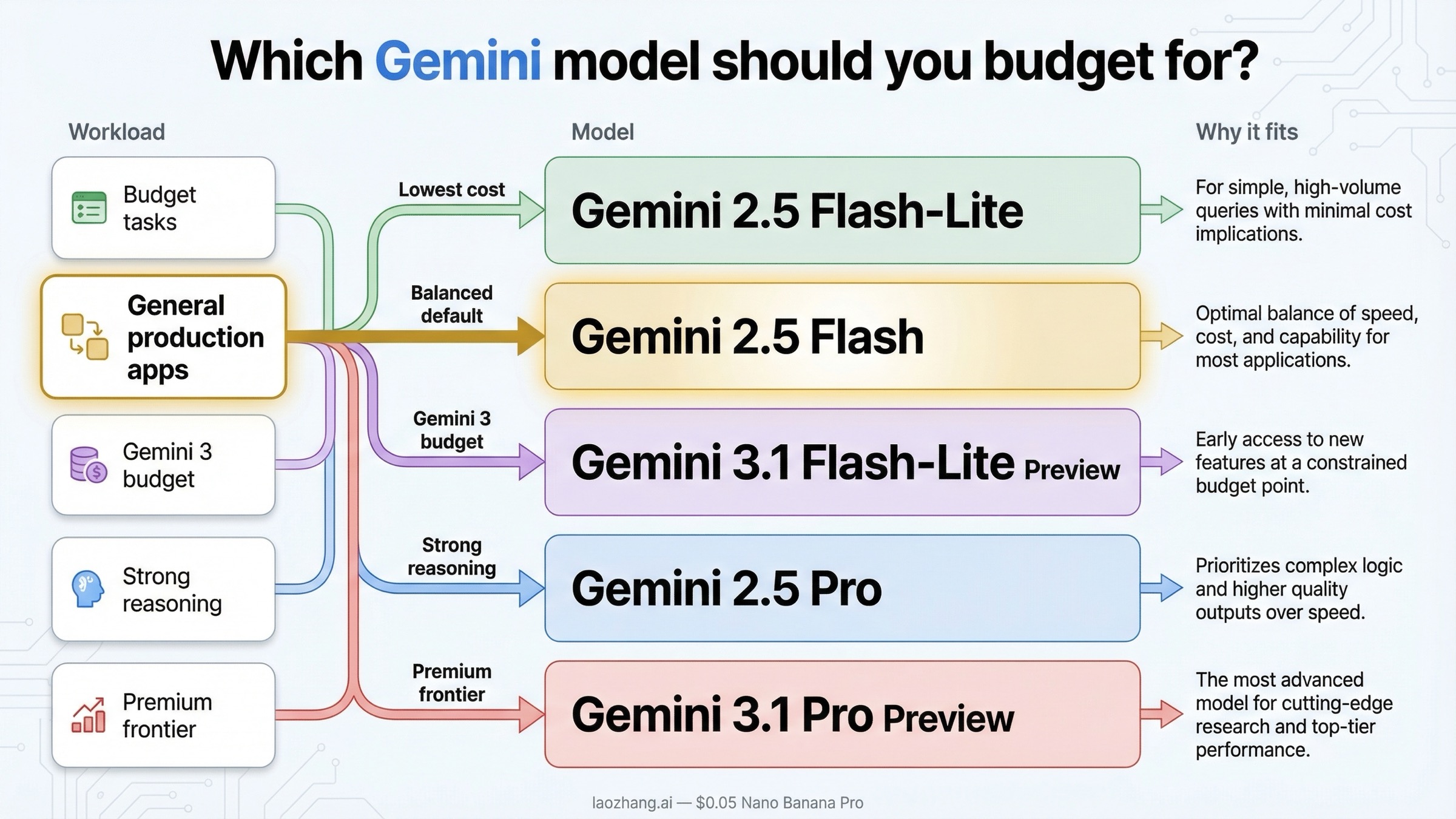
Полезный вопрос здесь не "какая модель самая мощная", а "какая модельная линия лучше подходит под мой тип нагрузки". Если смотреть только на новизну модели, бюджет обычно получается неточным.
Если главная цель это максимально низкая цена, то Gemini 2.5 Flash-Lite по-прежнему самый прямой ответ. Эта модель хорошо подходит для классификации, извлечения, легкой маршрутизации, перевода, высокообъемной обработки текста и других задач, где важнее throughput и низкая стоимость, чем максимально глубокое рассуждение. Во многих сценариях именно эта модель дает лучший экономический результат.
Если нужен более безопасный production-default, то Gemini 2.5 Flash остается самым практичным стартовым вариантом. Она дороже Flash-Lite, но разница все еще далека от Pro-линий. Для внутренних помощников, FAQ-ботов, поиска по документам, support automation и легких agent workflows этого уровня зачастую вполне достаточно. Именно поэтому 2.5 Flash и сегодня выглядит как самая здравая "сбалансированная" рекомендация.
Если команде важно быть именно на Gemini 3, но не хочется сразу платить за Pro, тогда логичный маршрут это Gemini 3.1 Flash-Lite Preview. Она не дешевле 2.5 Flash-Lite, но зато дает вход в текущее поколение Gemini 3. Такой выбор имеет смысл, если вам важна совместимость с новым модельным семейством и вы готовы мириться с рисками preview-статуса.
Если задача по-настоящему heavy reasoning, тогда приходится выбирать между Gemini 2.5 Pro и Gemini 3.1 Pro Preview. Gemini 2.5 Pro заметно дешевле, а Gemini 3.1 Pro Preview это уже премиальная ставка. Для кода, сложного анализа, длинной синтетики и planning-heavy задач цена 3.1 Pro имеет смысл только тогда, когда вы реально получаете за нее прирост качества, который важен для бизнеса.
Именно этого многим широким pricing-guides не хватает: они перечисляют характеристики, но не формулируют саму практическую развилку. В марте 2026 она выглядит так:
- минимальная цена: Gemini 2.5 Flash-Lite
- стабильный сбалансированный default: Gemini 2.5 Flash
- самый дешевый путь внутри Gemini 3: Gemini 3.1 Flash-Lite Preview
- сильное reasoning без максимальной цены: Gemini 2.5 Pro
- премиальный фронтирный путь: Gemini 3.1 Pro Preview
Если вы пока только тестируете продукт, не путайте бесплатный опыт в AI Studio с финальной production-стоимостью. В billing FAQ Google прямо объясняет, что AI Studio остается бесплатным до тех пор, пока вы не подключаете paid API key к платным функциям. То есть "я попробовал это бесплатно" и "это так же будет стоить в продакшене" — это разные вещи.
Что на самом деле входит в ваш счет Gemini
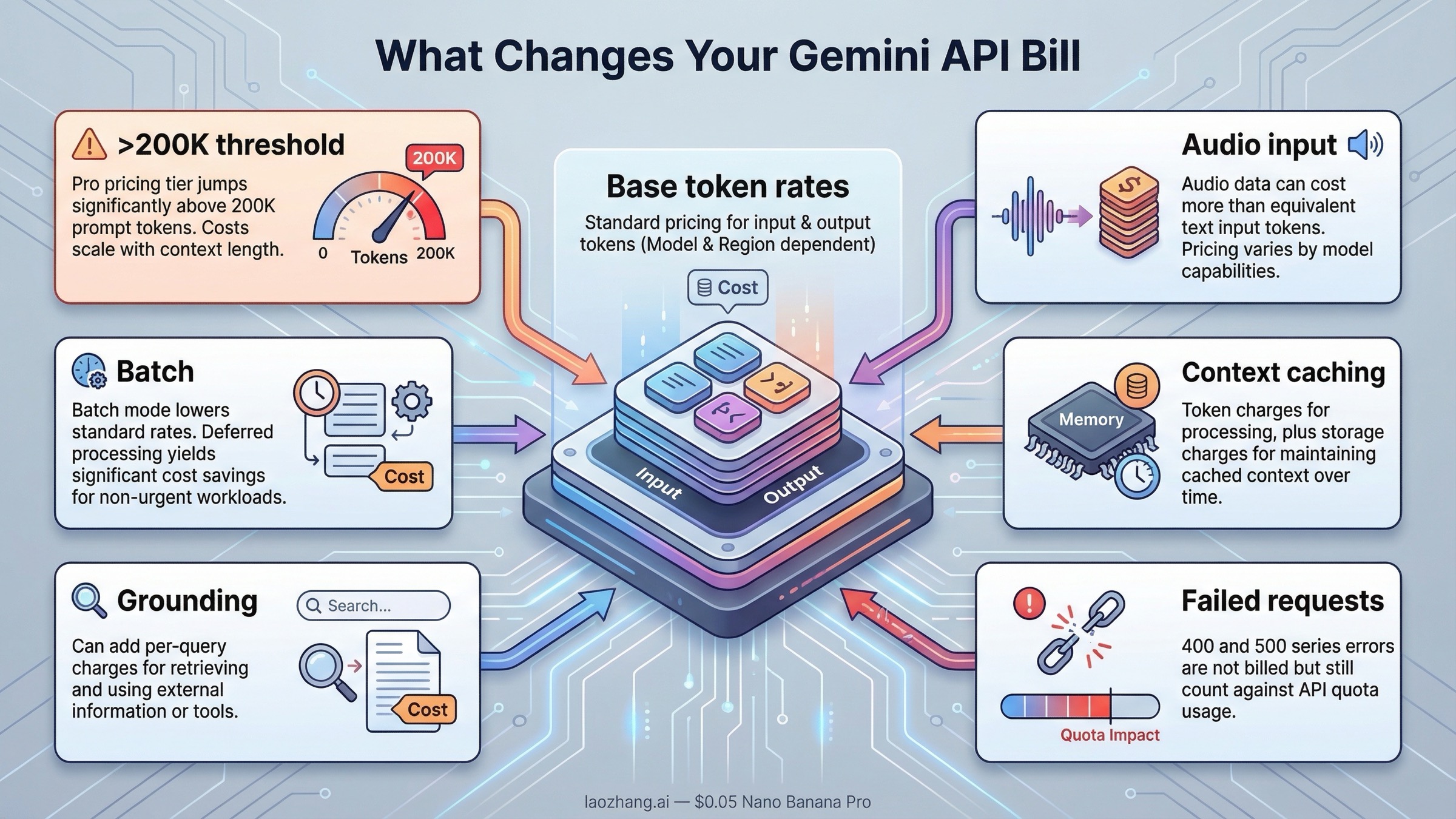
Многие статьи о ценах Gemini останавливаются на таблице тарифов, но самая полезная часть начинается дальше. На billing-странице Google пишет, что расчет идет по количеству входных токенов, количеству выходных токенов, количеству cached tokens и времени хранения кеша. Иными словами, вы платите не только за то, что отправили, и не только за то, что получили в ответ.
Важно и то, как вообще считать токены. По официальному гайду по токенам, один токен для Gemini примерно соответствует 4 символам, а 100 токенов это около 60–80 английских слов. Это не точная бухгалтерская формула, но достаточно хорошая оценка, чтобы понять простую вещь: короткий промпт редко становится дорогим, а вот длинные системные инструкции, большие RAG-вставки, tool traces и повторяющийся контекст — именно там начинается настоящий рост расходов.
Кроме того, не все виды input стоят одинаково. На некоторых моделях аудио-ввод дороже текстового. У Pro-линий запросы с промптом выше 200K токенов переходят в более дорогую категорию. Если вы еще и используете caching, grounding или multimodal-input, то "цена за миллион токенов" перестает быть достаточным ориентиром.
Вот краткая таблица факторов, которые сильнее всего меняют итоговый счет:
| Модификатор | Что меняется | Почему это важно |
|---|---|---|
| Запросы Pro выше 200K | Gemini 3.1 Pro Preview растет с 2,00 / 12,00 до 4,00 / 18,00; Gemini 2.5 Pro с 1,25 / 10,00 до 2,50 / 15,00 | Длинный контекст может резко удорожить нагрузку |
| Аудио input | Flash и Flash-Lite часто имеют более высокую цену на audio input | Голосовые сценарии легко недооценить по бюджету |
| Batch режим | Для основных текстовых моделей цена примерно вдвое ниже стандартной | Самый прямой инструмент снижения стоимости для async-задач |
| Context caching | Появляется цена за cached tokens и за время хранения | Кеш помогает экономить, но это не бесплатная память |
| Grounding | Добавляются отдельные per-query расходы | Итоговый счет уже не чисто "token-only" |
| Ошибки 400/500 | Они не тарифицируются, но все равно расходуют quota | Проблемы с устойчивостью бьют по throughput даже без прямого роста биллинга |
Два пункта здесь особенно важны.
Первый — Batch. Если ваша задача не требует ответа в реальном времени, batch-цены почти всегда заслуживают быть базовым сценарием для оценки. Ночные прогоны, отчеты, массовая генерация, оценка данных, большие асинхронные пайплайны — все это обычно имеет смысл считать именно по batch-ставкам, а не по стандартным.
Второй — Context caching. Это одна из самых часто неправильно понимаемых функций Gemini. Да, кеш действительно может снизить повторную стоимость одинакового контекста. Но Google при этом берет деньги за cached tokens и за storage duration. Поэтому caching нужно понимать как инструмент оптимизации, а не как "бесплатную память для промптов". Если контекст действительно переиспользуется, выгода может быть существенной. Если нет, то искусственно добавлять caching в архитектуру бессмысленно. Если вас интересует именно лимитная и quota-часть вопроса, локализованный материал про Gemini API free quota 2026 будет хорошим следующим шагом.
Почему стоимость Gemini может неожиданно вырасти
Есть три повторяющихся причины, из-за которых люди помнят одну цену, а платят в итоге совсем другую.
Первая — порог 200K токенов в prompt у Pro-линий. Как только вы начинаете обрабатывать длинные документы, большие code-context, широкие RAG-подборки или многословную историю диалога, этот порог становится реальной угрозой для бюджета. И именно поэтому часть задач, которые на бумаге кажутся "Pro-случаем", в реальности лучше обслуживать Flash-моделью плюс более аккуратной retrieval-стратегией.
Вторая — иллюзия бесплатного доступа. Пользователи нередко смешивают "мне дали попробовать в AI Studio бесплатно" и "этот же сценарий так же останется бесплатным для API". Но у разных моделей разные правила free-tier, а production-биллинг включается отдельно. Именно здесь многие оценки расходов и оказываются ошибочными.
Третья — связка цен и лимитов. Стоимость — это только половина картины. На странице rate limits Google отдельно подчеркивает, что лимиты применяются на уровень проекта, а не на конкретный API key, и зависят от модели и usage-tier. Как только вы переходите в реальную эксплуатацию, вопрос "какая модель дешевле" начинает пересекаться с вопросом "какая модель выдержит нужный мне throughput". Если у вас уже регулярные 429, сравнение нескольких центов на миллион токенов перестает быть главным.
Иначе говоря, главные колебания бюджета обычно вызывает не микроскопическая разница между похожими строками прайсинга, а выбор модельной линии, длина контекста, режим batch и дисциплина работы с промптом.
Чем отличаются Gemini Developer API, Vertex AI и AI Studio по цене
Этот запрос часто приводит на страницы, которые смешивают сразу несколько поверхностей доступа к Gemini.
Но для разработчика это не одно и то же:
- Gemini Developer API — то, о чем идет речь в этой статье; это прямой ориентир для расчетов по публичному Gemini API.
- Vertex AI — корпоративная поверхность внутри Google Cloud, где те же модели живут в более широком enterprise-контексте.
- AI Studio — интерфейс для экспериментов и тестов, а не финальная модель production-биллинга.
Проблема в том, что многие статьи ради полноты добавляют сюда же Gemini App subscriptions, Workspace add-ons или другие Google-сервисы. В итоге материал становится шире, но не полезнее именно для запроса "Gemini API token pricing".
Практическое правило здесь простое:
- если вы оцениваете прямые вызовы через Gemini Developer API pricing, смотрите именно эту страницу;
- если вы реально строите инфраструктуру внутри Google Cloud, сверяйтесь с Vertex AI pricing;
- если вы пока только экспериментируете в AI Studio, не превращайте это автоматически в оценку production-стоимости.
На март 2026 интересно то, что Vertex AI в целом повторяет основные Gemini price lanes, но при этом сильнее выносит наружу priority и Flex / Batch-подходы. Если сторонняя статья не уточняет, какой именно pricing-surface она цитирует, к ее выводам стоит относиться осторожно.
Примеры месячной стоимости для типовых сценариев
Сами по себе цифры "за 1 млн токенов" полезны только тогда, когда вы можете мысленно подставить в них реальные нагрузки.
Сценарий 1: небольшой support-бот на Gemini 2.5 Flash
Допустим, вы обрабатываете 30 млн входных токенов и 10 млн выходных в месяц:
- input: 30 × 0,30 = 9,00 доллара
- output: 10 × 2,50 = 25,00 доллара
- оценка итоговой месячной цены: 34,00 доллара
Именно поэтому 2.5 Flash остается столь сильным default-choice: достаточно дешево для продакшен-экспериментов, но без сильного падения качества.
Сценарий 2: сервис маршрутизации или извлечения на Gemini 2.5 Flash-Lite
Допустим, у вас 200 млн входных токенов и 40 млн выходных в месяц:
- input: 200 × 0,10 = 20,00 доллара
- output: 40 × 0,40 = 16,00 доллара
- оценка итоговой цены: 36,00 доллара
Этот пример хорошо показывает, почему output-price тоже имеет значение. При больших объемах сжатый и недорогой output у Flash-Lite становится важной частью экономии.
Сценарий 3: premium coding или synthesis на Gemini 3.1 Pro Preview
Предположим, вы тратите 20 млн входных токенов и 4 млн выходных, а каждый prompt остается ниже 200K:
- input: 20 × 2,00 = 40,00 доллара
- output: 4 × 12,00 = 48,00 доллара
- итоговая оценка: 88,00 доллара
Тот же объем на Gemini 2.5 Pro:
- input: 20 × 1,25 = 25,00 доллара
- output: 4 × 10,00 = 40,00 доллара
- итоговая оценка: 65,00 доллара
То есть премия за 3.1 Pro вполне реальна, и ее нельзя считать мелочью.
Сценарий 4: async backfill через Batch
Если взять первый пример и перевести его в batch-режим:
- input: 30 × 0,15 = 4,50 доллара
- output: 10 × 1,25 = 12,50 доллара
- итоговая оценка: 17,00 доллара
Это почти вдвое дешевле. Поэтому первым вопросом в оптимизации расходов должен быть не "какого провайдера менять", а "можно ли перевести этот workflow в async batch".
Если вас пока больше интересует free-tier и как он ведет себя на практике, лучше продолжить чтение со статьи про Gemini API free quota 2026. Но главный вывод этой страницы можно сформулировать коротко:
Запрос "Gemini API token pricing" на самом деле не сводится к вопросу "сколько стоит миллион токенов". Он сводится к вопросу "какую модельную линию мне выбирать и какие модификаторы биллинга изменят реальную цифру". Когда вы отвечаете именно на этот вопрос, прайсинг Gemini перестает казаться хаотичным.