
Если Claude API вернул HTTP 500, а в теле ответа указан error.type: "api_error", начинайте не с ротации ключа, не с переписывания prompt и не с переключения провайдера. Считайте, что запрос дошёл до серверной стороны Claude и упал внутри сервиса. Первое действие: сохраните request_id из тела ответа или request-id из заголовка, зафиксируйте время, модель, endpoint, владельца авторизации, SDK или gateway, base URL, сетевой путь и форму запроса.
На 19 мая 2026 года Claude Status показывал, что системы работают штатно, но в истории были видны недавно закрытые инциденты с повышенной долей ошибок. Это датированная проверка, а не вечное доказательство. Зелёный статус не гарантирует, что именно ваша модель, организация, регион, gateway, прокси или нагрузка здоровы; он только сужает первую гипотезу.
Перед изменениями используйте эту таблицу. Она нужна, чтобы один 500 не превратился в десять переменных одновременно.
| Симптом | Первое действие | Как проверить | Когда остановиться |
|---|---|---|---|
HTTP 500 и api_error | Сохранить request_id, статус, модель, endpoint, route и timestamp | Тот же путь восстанавливается или повторяет ту же ветку | Остановиться после малого retry-бюджета; не запускать бесконечный цикл |
529 overloaded_error | Снизить давление: меньше concurrency, больше backoff, меньше автоматических повторов | Ошибка уходит после снижения нагрузки или меняет ветку | Не диагностировать это как JSON, key или prompt проблему |
429 rate_limit_error | Проверить лимиты, usage, token volume, batch size и pacing | Запросы проходят после изменения темпа | Не лечить rate limit ожиданием публичного инцидента |
504 timeout_error или длинная операция | Уменьшить запрос, включить streaming, разбить задачу или изменить timeout | Малый или streaming-запрос проходит на том же аккаунте | Не называть это чистым 500 без возвращённого ответа |
| DNS, proxy, TLS, SDK timeout без API-ответа | Проверить сеть, proxy, firewall, VPN, base URL, SDK timeout | Малый known-good request доходит до API | Не применять правила retry для api_error к сбою соединения |
| Повторные чистые 500 тем же путём | Собрать пакет: request IDs, status timestamp, retry timeline, route и redacted payload shape | Владелец платформы может связать события в логах | Не отправлять API key, auth header, полный prompt, PII или raw-файлы |
Главное правило: как только ветка подтверждена, перестаньте менять всё подряд. Если сначала поменять модель, затем ключ, затем proxy, затем prompt, а потом ошибка исчезнет, у вас не останется доказательства, что именно помогло.
Что на самом деле означает чистый 500 api_error
В документации Anthropic HTTP 500 относится к ветке api_error. Это не общий ярлык для всех неудач. Это возвращённый сервером внутренний сбой, при котором ответ может содержать error.type, error.message и request_id; также полезен заголовок request-id. Поэтому первая операционная привычка — сохранить идентификаторы до сна, retry или правки конфигурации.
Чистый 500 не доказывает, что ваш код идеален. Он говорит только, что текущий ответ относится к внутренней серверной ветке. Причиной может быть короткий сбой сервиса, модельный путь, зависимость внутри платформы, обёртка gateway или проблема на конкретном маршруте. Для инженера важнее другое: воспроизводится ли тот же путь, совпадает ли время с публичным статусом, меняется ли результат при единственном контролируемом изменении.
Не начинайте с API key. Неверный ключ, нет доступа, неправильный workspace или billing чаще проявляются как authentication, permission или другой 4xx-класс. Не начинайте и с переписывания prompt. Неверная схема запроса обычно должна дать validation-ветку. Prompt, payload size, tool use и вложения могут быть важны, но они идут после сохранения request_id и базовой ветки.
Отдельно смотрите на Claude Code. Терминал может показать raw 5xx response body, и пользователь увидит почти тот же текст, что при прямом API. Это делает Claude Code поверхностью, где видна API-ветка, но не превращает локальную CLI-среду в единственную причину. Запишите версию Claude Code, команду, raw body, auth-состояние и возможность повторить задачу через Workbench или прямой API.
Сначала выберите ветку ошибки
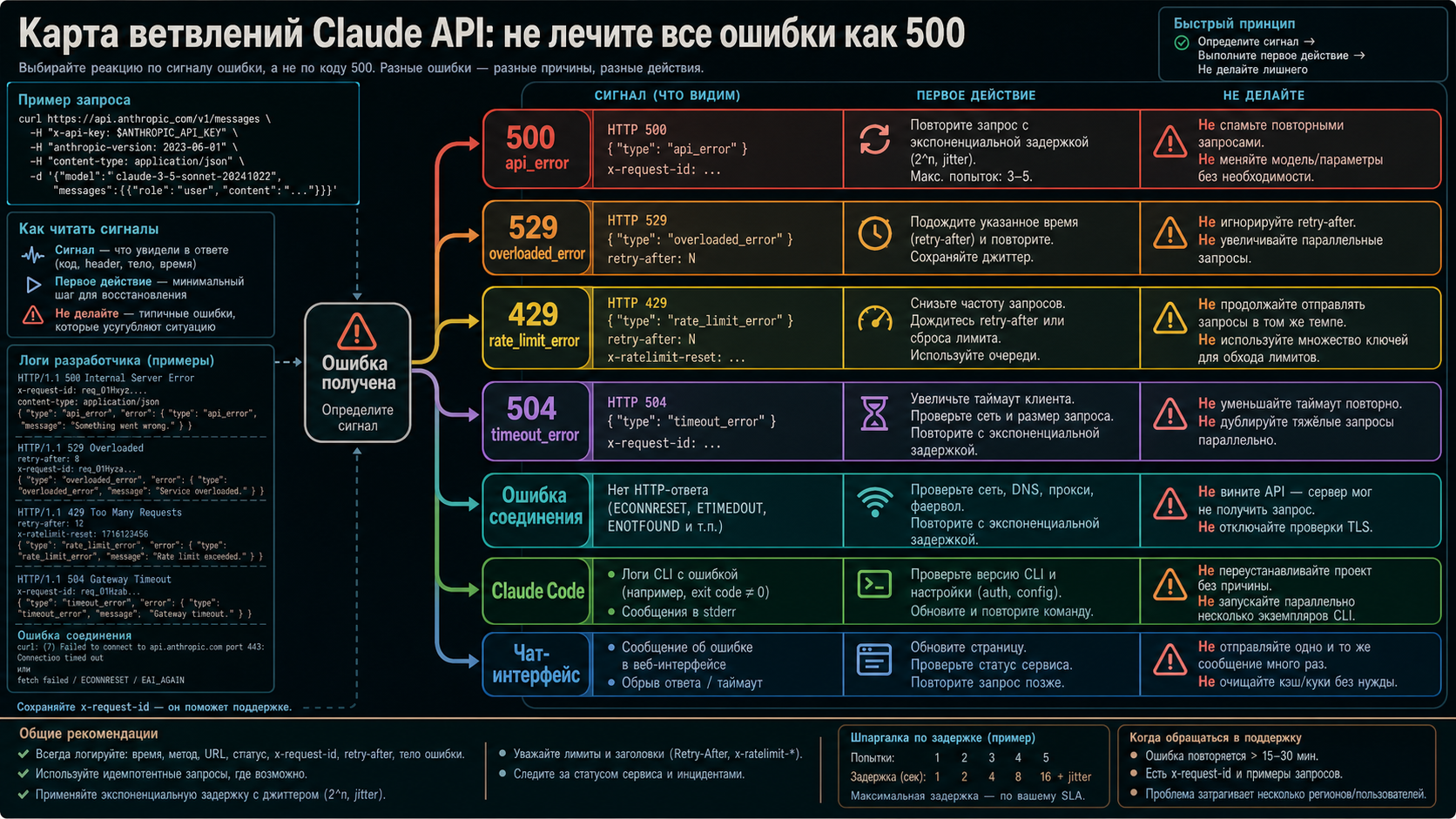
Самая дорогая ошибка в инциденте — применить правильный совет к неправильной ветке. 500 api_error, 529 overloaded_error, 429 rate_limit_error, 504 timeout_error, ошибка соединения и сбой в Claude Code могут прервать один и тот же рабочий процесс, но требуют разных действий.
Используйте ветку 500 api_error, когда у вас есть возвращённый HTTP-ответ от Claude и тело явно показывает внутреннюю серверную ошибку. Здесь доказательства — status, request ID, model, endpoint и route. Первое восстановление — статус плюс ограниченный retry, а не расчёт лимитов.
Используйте 529 overloaded_error, если ответ говорит о перегрузке. Это ветка давления на сервис: уменьшайте concurrency, добавляйте backoff, избегайте retry storm. Если фактическая ошибка стала 529, применяйте отдельную логику для Claude 529 Overloaded Error, где основной вопрос — ёмкость и нагрузка.
Используйте 429 rate_limit_error, когда ограничен аккаунт, организация или темп вызовов. В этой ветке нужны usage, pacing, batch design и политика лимитов. Для общей темы лимитов уместнее материал про Claude API rate limits, а не попытка объяснить 429 через внутренний серверный сбой.
Используйте 504 timeout_error, когда работа не завершается вовремя. Длинный контекст, большой output, tool chain или отсутствие streaming могут требовать другого режима выполнения. Если сервис не вернул 500, а клиент просто дождался timeout, это не та же ветка.
Используйте сетевую ветку, когда API-ответа нет. DNS, TLS, corporate proxy, VPN, firewall, неправильный base URL или SDK timeout могут оборвать запрос до Claude. В этом случае небольшой known-good request и второй сетевой путь полезнее, чем многократный retry тяжёлого payload.
Запустите ограниченный цикл восстановления
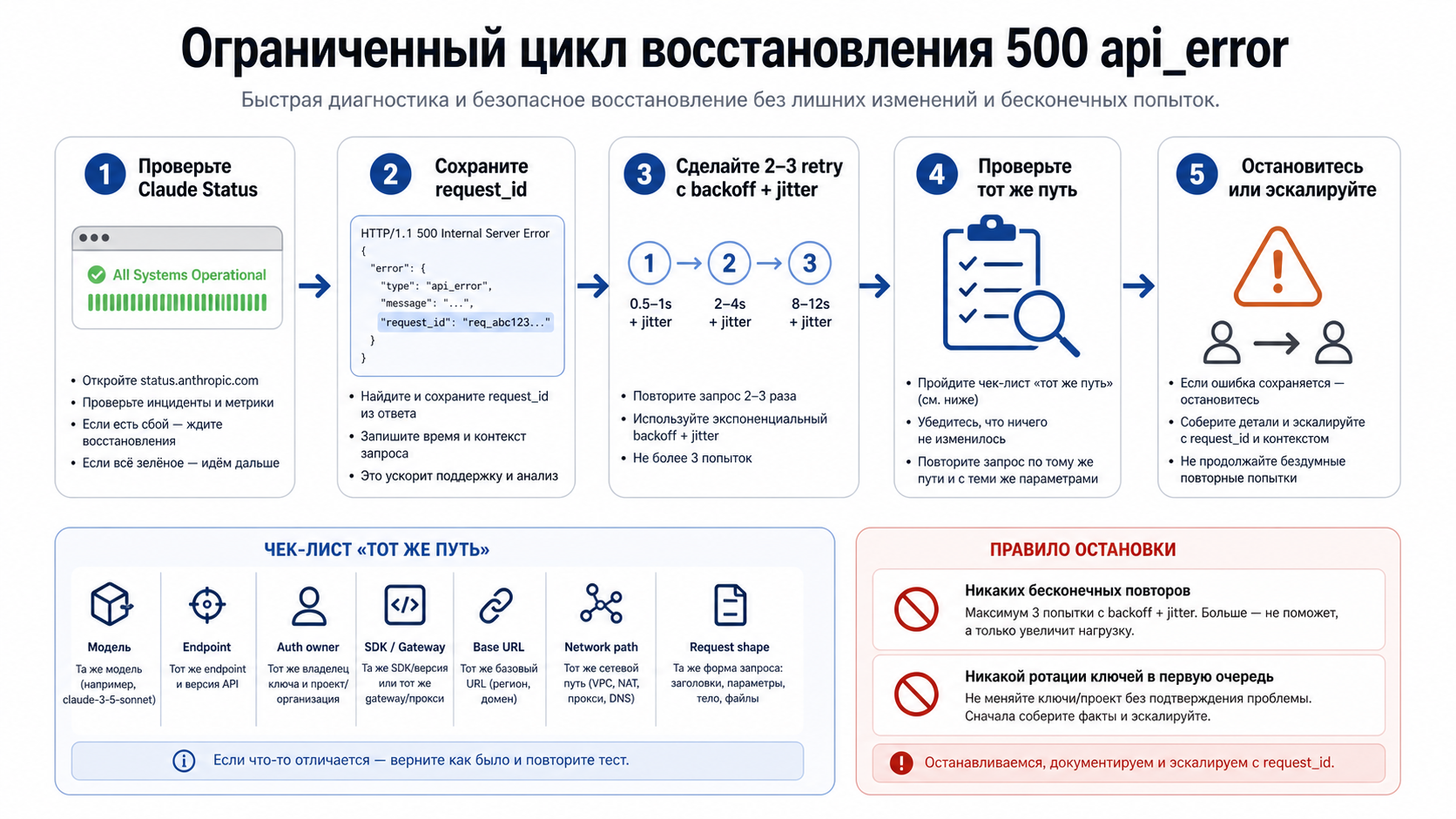
Цикл должен быть коротким: status, evidence, bounded retry, same path, stop or escalate. Он специально устроен так, чтобы вы не потеряли доказательства и не усилили проблему.
Сначала откройте Claude Status и запишите время проверки. Активный инцидент меняет поведение: меньше давления, ожидание, защита пользовательского опыта и понятное сообщение о degraded state. Зелёная страница не закрывает ваш кейс; она просто делает доказательство того же пути более важным.
Затем сохраните identifiers. Для прямого API это request_id из тела и request-id из заголовка. Для SDK — exception class, status, error.type, model, endpoint, base URL, SDK version, gateway name, attempt number и ваш correlation ID. Для Claude Code сохраните raw body, команду и версию CLI.
После этого retry только с малым бюджетом. Если SDK уже сделал одну или две попытки, внешний цикл может неожиданно умножить нагрузку. Начните с двух или трёх попыток уровня приложения, добавьте exponential backoff и jitter, ограничьте общее время и прекратите повторять, если та же чистая 500 возвращается снова.
Проверка того же пути должна быть строгой. Тот же путь означает ту же модель, endpoint, auth owner, SDK или gateway, base URL, network egress, ключевые headers без секретов и ту же форму запроса. Если вы одновременно меняете provider, модель и payload, успешный ответ не объясняет исходный сбой.
Последний шаг — выбор между stop и escalation. Разовый успех в идемпотентном workflow можно залогировать и продолжить мониторинг. Повторяющаяся чистая 500 тем же путём после малого бюджета должна перейти в evidence packet, а не в новый круг случайных правок.
Сделайте retry безопасным до повторения работы
Retry безопасен только тогда, когда безопасно повторять саму работу. Read-only summarization, classification или analysis обычно перезапускаются проще. Платежи, записи в базу, отправка сообщений, ticket updates, tool calls и создание файлов требуют idempotency-защиты.
Разделяйте модельный сбой и бизнес-побочный эффект. Если запись в базу уже сделана до вызова Claude, повторный запуск не должен создать второй объект. Если tool может отправить письмо, webhook или покупку, не перезапускайте всю цепочку только из-за финального 500. Сохраняйте job ID, делайте deduplication, маркируйте replay и показывайте пользователю честный промежуточный статус.
Политика retry должна быть видна в логах. Укажите maximum attempts, initial delay, backoff shape и maximum elapsed time. Без этих чисел фраза “добавьте backoff” превращается в произвольный код в каждом сервисе.
Минимальная форма обработчика выглядит так:
tsasync function callClaudeWith500Budget(runClaude: () => Promise<unknown>) { const maxAttempts = 3; const baseDelayMs = 800; for (let attempt = 1; attempt <= maxAttempts; attempt += 1) { try { return await runClaude(); } catch (error: any) { const status = error?.status || error?.statusCode; const type = error?.error?.type || error?.type; if (status !== 500 || type !== "api_error") { throw error; } recordClaude500Evidence({ attempt, requestId: error?.request_id || error?.headers?.["request-id"], status, type, }); if (attempt === maxAttempts) { throw error; } const jitter = Math.floor(Math.random() * 400); await sleep(baseDelayMs * 2 ** (attempt - 1) + jitter); } } }
Важен не конкретный delay. Важно, что handler не считает все ошибки retryable, сохраняет request evidence до ожидания и останавливается после ограниченного бюджета.
Разделите прямой API, Claude Code и gateway
В русскоязычной практике эта ошибка часто приходит через разные поверхности: прямой Anthropic API, Claude Code, Workbench, внутренний gateway, прокси компании или сторонний routing layer. Для пользователя всё выглядит как “Claude сломался”, но владельцы пути разные.
В прямом API Anthropic возвращает сервисный ответ, а ваша команда отвечает за request construction, retry policy, idempotency и logging. В Claude Code терминал может показать raw 5xx, но локальный auth, версия CLI, tool execution, MCP servers и shell-среда добавляют собственные слои. В gateway-пути появляются base URL, provider selection, auth handoff, trace ID и возможный retry до Anthropic.
Поэтому проверка того же пути включает владельца маршрута. Если прямой API падает с чистым 500, а тот же payload проходит через gateway, это полезное наблюдение, но не полный диагноз. Оно говорит, что два пути дали разные результаты. Сохраните Anthropic request ID, gateway trace ID, timestamp, region и base URL отдельно.
Переключение провайдера может быть правильной стратегией доступности, но не должно быть первым диагностическим шагом. Сначала зафиксируйте исходный сбой. Затем уже решайте, нужен ли fallback для бизнеса. Иначе вы потеряете линию расследования и не поймёте, что восстановилось: Claude, маршрут или запрос.
Подготовьте пакет для эскалации

Хорошая эскалация помогает владельцу платформы связать событие в логах и не раскрывает секреты. Не отправляйте API keys, bearer tokens, auth headers, полный приватный prompt, PII, raw-файлы клиентов или коммерческие данные. Отправляйте metadata, redacted shape и identifiers.
Минимальный пакет:
| Поле | Зачем оно нужно |
|---|---|
| Время проверки статуса | Показывает, был ли публичный инцидент или зелёное окно |
request_id или request-id | Позволяет найти конкретный ответ |
HTTP status и error.type | Подтверждает ветку 500 api_error |
| Model и endpoint | Отделяет модельный путь от аккаунта или gateway |
SDK, gateway, base URL, region | Показывает, какой слой мог обернуть запрос |
| Retry timeline | Доказывает, что ошибка повторялась после ограниченного backoff |
| Same-path reproduction | Указывает, что переменные не менялись одновременно |
| Redacted payload shape | Даёт размер, streaming/tool mode и класс вложений без секретов |
| Impact и frequency | Помогает отличить шум от production degradation |
Для Claude Code добавьте версию, команду, raw 5xx body, auth symptoms, MCP/tool context и результат того же задания через Workbench или прямой API. Для gateway добавьте внутренний trace ID и любой Anthropic request ID, который gateway пробросил наружу.
Пакет должен быть коротким. Лучший формат — timeline: first failure, status check, attempts, same-path reproduction, current impact, recent changes. Длинная история без request IDs хуже короткой таблицы с точными полями.
Production-контроль для повторяющихся 500
Команда, зависящая от Claude, должна иметь политику 500 до инцидента. Первый уровень — structured logging. Логируйте status, error type, request ID, model, endpoint, route, elapsed time, attempt number и собственный correlation ID. Без этих полей после аварии останутся только догадки.
Второй уровень — circuit breaker. Если чистые 500 выросли выше порога, остановите неважные high-volume jobs, уменьшите retry pressure, переведите пользовательский workflow в degraded mode и покажите понятное сообщение. Цель не в том, чтобы отказаться от Claude после одной ошибки, а в том, чтобы не превратить внутренний сбой сервиса в ваш traffic storm.
Третий уровень — idempotent jobs. Очереди, deduplication, replay markers и явное состояние side effects должны быть частью архитектуры. Если модельный вызов — один шаг большого workflow, весь workflow не должен автоматически повторяться без защиты.
Четвёртый уровень — route isolation. Direct API, gateway, Claude Code, Workbench, proxy и browser surface лучше смотреть раздельно. Зелёная линия на одном маршруте не должна скрывать красную линию на другом.
Пятый уровень — владелец реакции. До инцидента решите, кто проверяет Claude Status, кто открывает support ticket, кто снижает concurrency, кто включает fallback и кто сообщает пользователям. Плохой инцидент выглядит так: пять человек меняют пять переменных, а первый request_id никто не сохранил.
Ещё полезно разделять выборку по модели, endpoint, account, region, SDK version и request class. Spike только на tool calls или только на large payload требует другого ответа, чем равномерный рост 500 на всех запросах.
Часто задаваемые вопросы
Ошибка 500 означает, что prompt неверный?
Обычно нет. HTTP 500 с api_error — внутренняя серверная ветка. Неверный JSON, auth, permission или validation обычно дают другие статусы. Сохраните request ID и статусный контекст, затем отдельно смотрите payload size, tool use и schema.
Нужно сразу менять API key?
Нет, если у вас чистый 500 api_error. Key rotation относится к auth, permission или security incident. При 500 она добавляет лишнюю переменную и может уничтожить диагностическую линию.
Сколько раз повторять запрос?
Используйте малый бюджет: часто достаточно двух или трёх попыток уровня приложения с backoff и jitter, с учётом того, что SDK мог уже повторить запрос. Для неидемпотентных workflow бюджет должен быть ещё меньше.
Зелёный Claude Status означает, что проблема у меня?
Нет. Это только публичный status signal на конкретный момент. Он не доказывает здоровье вашей организации, модели, route, gateway, proxy или request shape. Поэтому нужна same-path verification.
500 api_error и 529 overloaded_error — это одно и то же?
Нет. Оба могут ощущаться как provider-side failure, но официальные ветки разные. 500 api_error — internal server branch. 529 overloaded_error — capacity или overload branch, где важнее снизить давление и предотвратить retry storm.
Claude Code показывает ту же ошибку. Что сохранить?
Сохраните raw response body, версию Claude Code, команду, request ID если он есть, auth-состояние, tool/MCP context и результат прямого API или Workbench. Так вы отделите API-ветку от локальной CLI-среды.
Когда эскалировать?
После повторных чистых 500 тем же путём, после малого retry-бюджета или при реальном пользовательском влиянии. Передавайте status timestamp, request IDs, model, endpoint, route, retry timeline, redacted payload shape и impact.
Можно сразу уйти на fallback?
Можно как business-continuity шаг, но после сохранения исходных доказательств. Fallback без request IDs и same-path evidence помогает пережить минуту, но мешает понять причину.