
Короткий ответ: Claude 529 overloaded_error в большинстве случаев означает, что Anthropic временно перегружен или один из апстрим-сервисов на вашем пути обработки запроса сейчас насыщен. Поэтому первым делом стоит не переписывать prompt и не менять API key, а открыть актуальную страницу статуса Claude и посмотреть недавние инциденты. Если вы вызываете API напрямую, вторым шагом будет retry с backoff. Если вы работаете через Claude chat или Claude Code, нужно еще убедиться, что перед вами не предупреждение о лимите плана или о временной перегрузке чата.
Этот нюанс в 2026 году важнее, чем раньше. В release notes Anthropic сказано, что с 11 августа 2025 года часть сценариев с резким всплеском трафика, которые раньше возвращали 529 overloaded_error, теперь возвращают 429 rate_limit_error. Поэтому современная статья про 529 должна не просто советовать “подождать и попробовать снова”, а помогать быстро определить класс проблемы.
И это не абстрактная теория. Публичный status feed Anthropic открыл инцидент “Elevated errors across surfaces” 19 марта 2026 года в 00:28 UTC, а claude.ai, platform.claude.com, Claude API и Claude Code были отмечены как partial outage. К последней перепроверке для этой статьи в 01:21 UTC инцидент уже перешел в состояние monitoring, а Anthropic уточнил, что пользователи сталкивались с повышенным числом ошибок аутентификации в промежутке 23:59-00:30 UTC. Именно в такой момент поисковый запрос про 529 требует четкой схемы диагностики, а не общих советов.
Краткое содержание
Claude 529 overloaded_error обычно является сигналом перегрузки со стороны Anthropic, а не доказательством того, что ваш запрос составлен неверно. Начните с status.claude.com и feed недавних инцидентов. На момент последней проверки этой статьи, 19 марта 2026 года, summary Anthropic все еще показывал Minor Service Outage, а инцидент “Elevated errors across surfaces” уже был переведен из investigating в monitoring после окна повышенных ошибок аутентификации 23:59-00:30 UTC. Если в ваш момент проверки платформа выглядит здоровой, переходите к retry с jitter и к снижению burst-нагрузки. Если реальная ошибка — 429, переключайтесь на сценарий rate limiting. Если в Claude chat вы видите сообщение вида “Due to unexpected capacity constraints...”, официальная документация Anthropic прямо говорит, что это не полноценный outage и такое состояние может вообще не отображаться на status page.
| Сигнал | Что обычно означает | Где встречается | Первое действие |
|---|---|---|---|
529 overloaded_error | Anthropic или апстрим-сервис временно перегружены | API, Workbench, Claude Code, интеграции через Anthropic | Проверить статус, retry с backoff, сохранить request ID |
429 rate_limit_error | Ваша организация уперлась в RPM, ITPM, OTPM или acceleration limits | API и инструменты поверх API | Уважать retry-after, снизить burst-трафик, посмотреть /en/posts/claude-api-quota-tiers-limits |
| “Due to unexpected capacity constraints...” | Высокая нагрузка именно на Claude chat | claude.ai | Подождать несколько минут; это не то же самое, что outage |
| “5-hour limit reached” | Вы израсходовали окно использования плана | Claude chat / подписочный поток Claude Code | Дождаться reset или изучить /ru/posts/claude-code-rate-limit |
Что на самом деле означает Claude 529 Overloaded Error
Когда Anthropic возвращает 529 overloaded_error, это обычно означает, что сервис не может стабильно обработать ваш запрос прямо сейчас из-за ограничения текущей емкости. Это совершенно другой класс проблем, чем неверный request body, просроченный ключ или отсутствие прав. На практике 529 часто появляется тогда, когда сама платформа переживает плохой час, конкретный модельный backend перегружен или цепочка наподобие Claude Code / Workbench упирается в напряженный backend.
Именно поэтому поиск по этой ошибке всегда очень нервный. Люди попадают на 529 в разгар работы и вводят точную строку ошибки, потому что им нужно быстро понять: “Это проблема у меня или у Anthropic?”. Большинство страниц в выдаче дают только эмоциональное подтверждение: “да, у других тоже такое было”. Но этого недостаточно для решения.
Если свести вместе официальные материалы Anthropic, картина становится гораздо полезнее. Help Center разделяет service incidents, capacity constraints в Claude chat и usage-limit messages. Документация API отдельно объясняет rate limits, service tiers и retry-поведение SDK. Если читать эти источники вместе, получается такой рабочий вывод:
529обычно указывает на service overload или временное насыщение upstream.429указывает на rate limiting и burst/acceleration-поведение.- Предупреждения про capacity относятся к потребительскому интерфейсу Claude chat.
- Сообщения про 5-часовой лимит относятся к квоте вашего плана.
Главное здесь не терминология, а правильная классификация. Ошибетесь с классом проблемы — начнете чинить не то.
529 vs 429 vs capacity constraints vs лимиты использования

Люди чаще всего теряют время не из-за сложности самой ошибки, а из-за того, что у Anthropic есть несколько разных состояний “сейчас продолжать нельзя”, и они относятся к разным слоям системы.
В официальной статье Anthropic про ошибки Claude прямо сказано, что chat-side capacity constraints — это временные состояния высокой нагрузки, и что они не отображаются на status page, потому что рассматриваются как нормальная load management, а не как формальный технический инцидент. Одно это уже объясняет массу путаницы: пользователь видит проблему, открывает status page, видит “зеленый” статус и начинает подозревать свой браузер, аккаунт или локальную сеть.
На стороне API логика другая. В документации по rate limits сказано, что лимиты действуют на уровне организации и применяются также на более коротких интервалах, а не только как “среднее в минуту”. Release notes добавляют критически важную деталь: с 11 августа 2025 года часть сценариев резкого роста нагрузки возвращает 429, где раньше появлялся 529.
Поэтому старые советы из сообществ о том, что 529 и 429 — это почти одно и то же, сегодня уже частично устарели.
| Состояние | Слой | Типичная причина | Чего делать не стоит |
|---|---|---|---|
529 overloaded_error | Сервис Anthropic / upstream capacity | Временная перегрузка, активный инцидент, напряженный backend | Не спешить менять ключи и переписывать заведомо корректный код |
429 rate_limit_error | Поведение API вашей организации | Tier limit, давление по RPM/TPM, acceleration limit | Не трактовать это как outage платформы |
| Capacity-constraint banner | Продуктовый слой Claude chat | Высокий спрос в чате | Не думать, что status page обязательно должен стать красным |
| Сообщение про 5-hour limit | Квота плана | Окно использования исчерпано | Не продолжать искать проблему в login или network settings |
Если вы используете Claude Code, полезно помнить еще одну вещь: симптом виден в инструменте, но bottleneck может быть все равно общим компонентом Anthropic. Развернутая версия этой темы — в /ru/posts/claude-code-rate-limit.
Сначала проверьте статус: как подтвердить реальный инцидент Anthropic
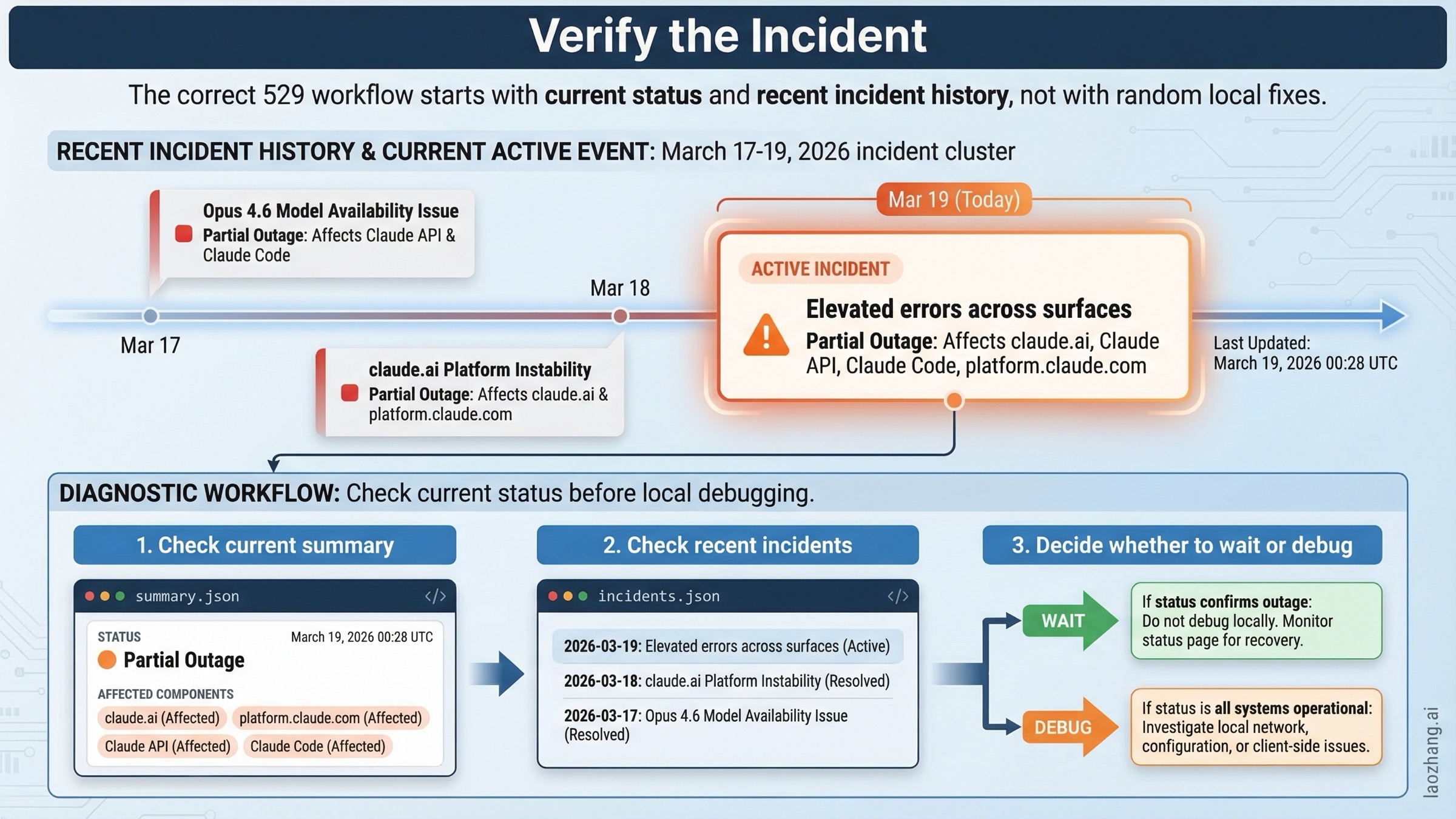
Для этого запроса самая полезная первая реакция — не определение, а workflow проверки статуса.
Начинайте с status.claude.com. Если нужна детализация, открывайте machine-readable endpoints:
https://status.claude.com/api/v2/summary.jsonhttps://status.claude.com/api/v2/incidents.json
Именно они удобны тем, что дают состояние по компонентам:
claude.aiplatform.claude.comClaude APIClaude Code
При повторной проверке 19 марта 2026 года summary endpoint не был зеленым. Он показывал Minor Service Outage и отмечал claude.ai, platform.claude.com, Claude API и Claude Code как partial outage. В обновлении от 01:21 UTC тот же инцидент “Elevated errors across surfaces” перевели в monitoring и уточнили, что всплеск ошибок аутентификации длился с 23:59 до 00:30 UTC. Incidents feed показывал, почему важна не только текущая секунда, но и ближайшая история: между 17 и 19 марта 2026 года у Claude прошло сразу несколько связанных инцидентов, включая:
- 17 марта 2026: elevated errors в Claude Opus 4.6
- 18 марта 2026: elevated errors в Claude Opus 4.6
- 18 марта 2026: increased errors в Opus 4.6
- 18 марта 2026: elevated errors в Claude.ai, при этом затронут был и Claude Code
- 19 марта 2026: “Elevated errors across surfaces” открылся в 00:28 UTC и перешел в monitoring в 01:21 UTC
Именно поэтому общее “подождите 30 секунд и повторите” недостаточно. Иногда этого хватит. Иногда вы находитесь прямо внутри реального outage window и зря подозреваете собственную интеграцию.
Есть и дополнительный operational caveat. В репозитории anthropics/claude-code есть Issue #1838, где описан случай июня 2025 года: пользователи уже видели overloaded_error, а dashboard еще не успел адекватно отразить сбой. Не стоит из этого делать вывод, что status page бесполезна, но как практическое предупреждение это полезно: в первые минуты инцидента reports from users могут появиться раньше, чем все компоненты сменят статус.
Надежный порядок действий выглядит так:
- Смотрите summary.
- Смотрите incidents.
- Понимаете, ломается ли одна поверхность, одна модель или весь workflow.
- Если публичный статус еще зеленый, но внешние сигналы уже накапливаются, re-try делать надо осторожно и без разрушительных изменений в коде.
Если у вас production-нагрузка, лучше завести мониторинг по JSON feed, а не опираться только на веб-панель.
Что делать в первые 10 минут
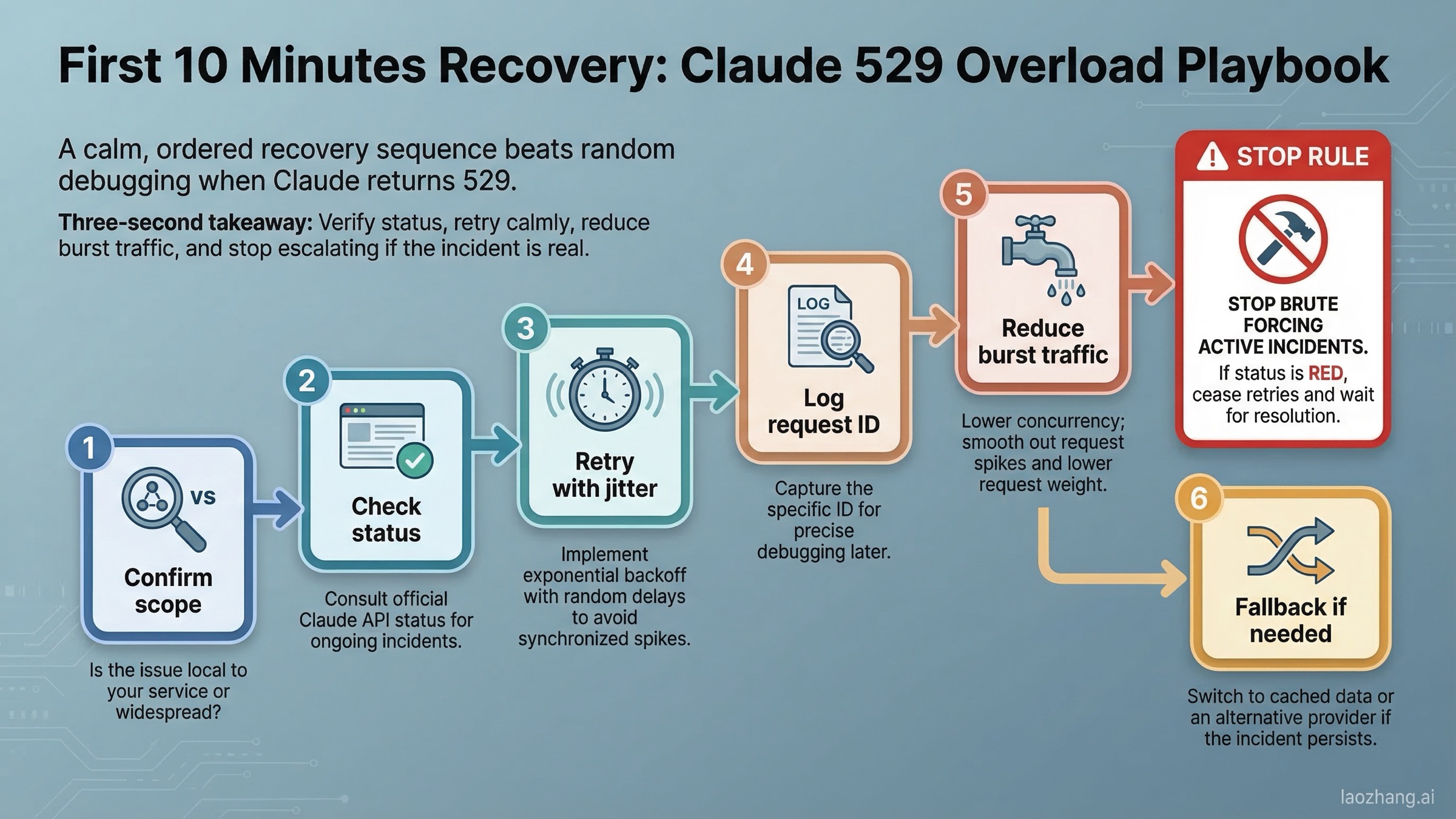
Если вы видите 529 в API, Workbench или Claude Code, полезен именно такой порядок.
Шаг 1: подтвердите масштаб проблемы. Если одновременно плохо работают и Claude chat, и API, вероятность platform-side incident резко выше. Если сбоит только одна интеграция, upstream-проблема все еще возможна, но стоит проверить и свою сторону.
Шаг 2: retry с jitter, а не panic retry. Transient overload — один из немногих случаев, когда повтор действительно оправдан, но агрессивное забрасывание запроса только ухудшает ситуацию. Используйте exponential backoff с небольшим случайным разбросом. Текущая документация Python SDK Anthropic говорит, что SDK по умолчанию автоматически делает 2 retry для connection errors, 408, 409, 429 и >=500.
Шаг 3: сохраняйте request ID. В SDK для этого и существует _request_id. Для support и дебага это намного полезнее, чем расплывчатое “примерно в обед что-то упало”.
Шаг 4: уменьшайте burst-нагрузку. В документации по rate limits прямо сказано, что enforcement идет и на коротких интервалах, а API использует token-bucket. Даже если текущий симптом — 529, снижение резких всплесков по-прежнему разумно.
Шаг 5: убедитесь, что это не 429. Если exception или body ответа явно говорят RateLimitError, нужно немедленно переключаться на сценарий rate limiting. Тогда правильнее читать /en/posts/claude-api-429-solution.
Шаг 6: уменьшите вес запроса. Если текущий workflow отправляет огромные контекстные окна, длинные tool outputs или тяжелые вложения, временно облегчите его.
Шаг 7: меняйте timing, а не только код. Если модельное семейство явно переживает плохой час, перенести некритичную задачу на 10-20 минут часто умнее, чем сжигать попытки.
Минимальный Python-паттерн может выглядеть так:
pythonimport time import random from anthropic import Anthropic, APIStatusError, RateLimitError client = Anthropic(max_retries=2) def call_with_jitter(messages, max_attempts=5): for attempt in range(max_attempts): try: return client.messages.create( model="claude-sonnet-4-6", max_tokens=1024, messages=messages, ) except RateLimitError: # 429: это rate limiting, а не generic overload raise except APIStatusError as e: if e.status_code == 529: delay = min(2 ** attempt, 20) + random.uniform(0, 1) time.sleep(delay) continue raise raise RuntimeError("Claude remained overloaded after retries")
Смысл этой схемы не в том, чтобы “додавить” сервис. Смысл — в graceful degradation и своевременной остановке, если evidence уже показывает продолжающийся инцидент.
Что делать пользователям Claude chat и Claude Code
Многие, кто ищет эту ошибку, вообще не делают raw API calls. Они работают внутри claude.ai, Claude Code, Workbench, Cursor, MCP-цепочки или другого инструмента, который в итоге все равно идет в Anthropic. Это меняет последовательность диагностики.
Для Claude chat официальная документация Anthropic говорит, что capacity-constraint messages бывают во время высокой нагрузки и являются временными. Если вы видите именно chat-side capacity banner, обычно правильнее просто подождать и обновить страницу, а не тратить час на очистку cookies. Та же документация разделяет такие сообщения и 5-hour usage-limit messages: последние означают, что вы исчерпали бюджет текущего окна плана.
Для Claude Code полезно смотреть, сопровождается ли ошибка login-проблемами, исчезающей историей или другими признаками более широкого сбоя. В incident update от 18 марта 2026 года прямо говорилось, что login/logout действия в Claude Code тоже были затронуты. Это важный сигнал: часть “ошибок Claude Code” на деле являются следствием общего инцидента Anthropic, а не локального CLI-багa.
Если ваш Claude Code workflow проходит через MCP server или другой local bridge, проверьте и этот промежуточный слой. Routing-слой может обернуть исходную ошибку и сделать symptom менее очевидным. Для общего контекста пригодится /en/posts/claude-mcp-complete-guide-2025.
Практическое правило простое:
- Если нестабилен весь Anthropic ecosystem, думайте сначала про incident.
- Если ломается только ваш подписочный поток, скорее всего это capacity или plan limit.
- Если ломается только API-автоматизация, сначала отделите 529 от 429.
Как снизить вероятность будущих 529
Полностью убрать provider-side overload нельзя, но можно сильно сократить ущерб для своего workflow.
Первый слой — лучшая форма трафика. Не переходите от нуля к максимуму concurrency мгновенно. Anthropic прямо предупреждает, что burst-нагрузка может упираться в лимиты и деградацию даже при приемлемом среднем уровне.
Второй слой — дисциплина prompt и context. Более легкие запросы проще retry-ить и они реже смешивают overload с timeout или другими побочными эффектами.
Третий слой — cache и reuse. Если приложение заново отправляет один и тот же большой префикс, вы одновременно увеличиваете стоимость и поверхность отказа.
Четвертый слой — tier strategy. В service tiers documentation сказано, что Priority Tier ориентирован на production-нагрузку и помогает минимизировать server overloaded errors в часы пик. Это не иммунитет от outage, но это четкий сигнал, что Standard не стоит воспринимать как production SLA.
Пятый слой — fallback architecture. Если плохой час у одного поставщика полностью парализует ваш бизнес-процесс, это уже не только vendor problem, но и ваш design issue. Ключевая мысль здесь в архитектуре, а не в конкретном бренде: если вашей команде нужна redundancy, вторичный маршрут нужно продумать заранее, а не во время следующего incident window.
Шестой слой — monitoring. Polling incidents feed, логирование request IDs и алерты по повторяющимся ошибкам дают вам реальную operational picture. Reddit и GitHub — хорошие дымовые датчики, но не мониторинг.
Если повторяющиеся “529” на деле скрывают проблемы burst control или организационных лимитов, дальше стоит прочитать /en/posts/claude-api-quota-tiers-limits.
FAQ
Claude 529 overloaded error — это моя вина? Обычно нет. Как правило, это сигнал временной перегрузки на стороне Anthropic или upstream-сервиса. Ваш клиент может усилить симптом слишком агрессивными retry, но сам факт ошибки чаще всего указывает на service pressure.
Сколько обычно длится 529? Фиксированного окна нет. Иногда инцидент проходит за минуты, иногда тянется дольше. Лучший источник — живой incidents feed.
Стоит ли retry делать сразу? Да, но с backoff и jitter. Одна-две спокойные попытки — нормально. Массовый параллельный retry — нет.
529 — это то же самое, что 429? Нет. В 2026 году их лучше воспринимать как разные диагностические ветки. 429 — это rate limiting, 529 — обычно overload.
Почему Claude chat ломается, а status page выглядит нормальной? Потому что официальная документация Anthropic говорит: chat-side capacity constraints не считаются формальным outage и потому могут не появляться на status page.
Какой самый быстрый и безопасный workflow при кодинге? Проверить статус, сохранить текущую работу, retry с backoff и переключиться на fallback endpoint или модель, если инцидент тянется. Для heavy users Claude Code наличие второй рабочей трассы обычно важнее, чем идеальный retry loop.