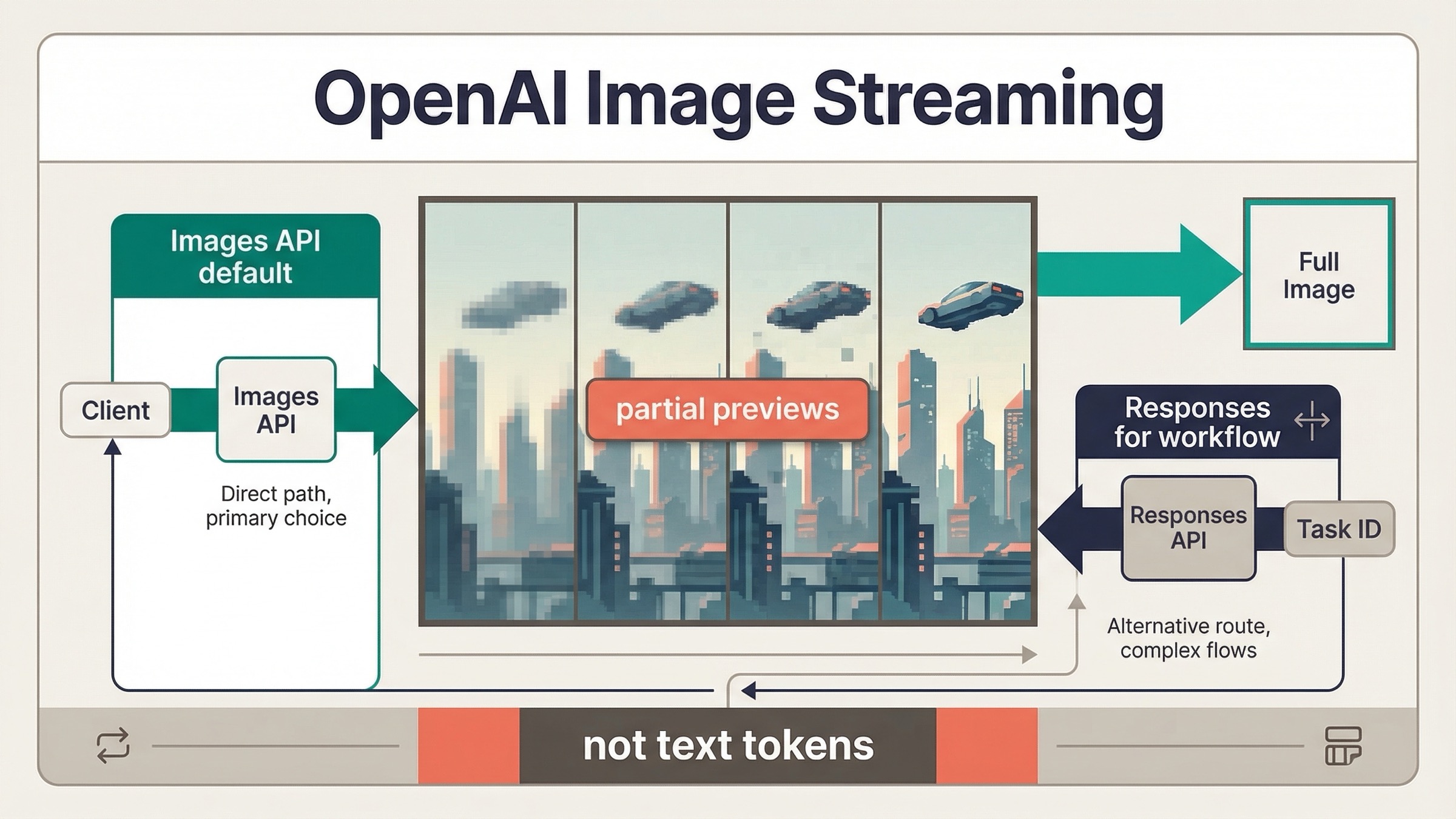
2026 年 3 月 23 日時点で、OpenAI image generation は streaming をサポートしています。 ただし、今 OpenAI が document しているのは text-style token streaming ではありません。実際に返ってくるのは、最終画像の生成中に届く partial-image previews です。この違いは UI の約束の仕方と、最初にどの API surface を選ぶべきかに直結します。
もし作っているものが direct image feature なら、今の safest default はかなり明快です。まず Images API を使い、client.images.generate() から partial previews を流す。 画像生成がより大きな assistant や multimodal workflow の中の 1 tool にすぎないなら、そこで初めて Responses API と hosted image_generation tool を使います。多くの弱いページはこの 2 つを曖昧に混ぜているため、keyword が必要以上に難しく見えています。
もう 1 つこの topic がややこしい理由は、OpenAI の公式ページが streaming を同じレイヤーで説明していないことです。現在の image generation guide は、Responses API と Images API の両方で streaming を document しています。一方で、現在の GPT Image 1.5 model page は feature table にまだ Streaming: Not supported と表示しています。見る順番を間違えると docs が矛盾して見えるので、この記事ではそのズレを先に解消します。
要点まとめ
- OpenAI image generation は現在 streaming をサポートしている が、流れてくるのは partial-image previews であり text tokens ではない。
- 画像生成そのものが feature なら Images API から始める。
- 画像生成が larger workflow の 1 tool なら Responses API を使う。
- event name は surface ごとに違う。Images API では
image_generation.partial_image、Responses API ではresponse.image_generation_call.partial_image。 partial_imagesを指定しても、要求した preview 数が必ず全部返るとは限らない。現在の guide では0から3まで設定でき、generation が速いと少ない preview で終わる可能性がある。
まず押さえるべきこと: 今の OpenAI image streaming が意味するもの
この keyword を誤解しやすい最大の理由は、text generation の mental model をそのまま持ち込んでしまうことです。開発者が「OpenAI image generation は streaming できますか」と聞くとき、実際にはたいてい次の 2 つを確かめています。
- 最終画像ができる前に progressive visual feedback を見せられるか
- image model は text model のように token-sized chunks を連続で返すのか
OpenAI の current answer は 1 つ目には yes、2 つ目には no です。現在の image generation guide は、Responses API と Image API の両方が streaming image generation を support すると書いたうえで、その内容を partial images として説明しています。さらに partial_images は 0 から 3 まで指定できるが、最終画像の完成が速い場合は requested count より少ない preview しか返らないことがある、とも明記しています。
つまり、正しい product expectation は「tiny render increments が最後まで流れてくる」ではありません。正しい期待値は「generation の途中で少数の preview images を受け取り、final image path に自然に引き継げる」です。これは UX として十分有用です。とくに image generation をブラックボックスに見せたくないプロダクトには効きます。ただし、many developers が streaming という言葉から想像するものより契約は狭い、という理解が必要です。
この理解が route choice に直結します。prompt、数枚の preview、そして final image だけが必要なら、Images API の方が mental model を汚しません。conversation state や tool orchestration が必要で、画像生成が broader agent workflow の一部なら Responses API が自然です。current docs は両方を support しています。問題は、どちらも同じくらい良い初手だと思い込むことです。
Images API vs Responses API: 正しい streaming surface を選ぶ
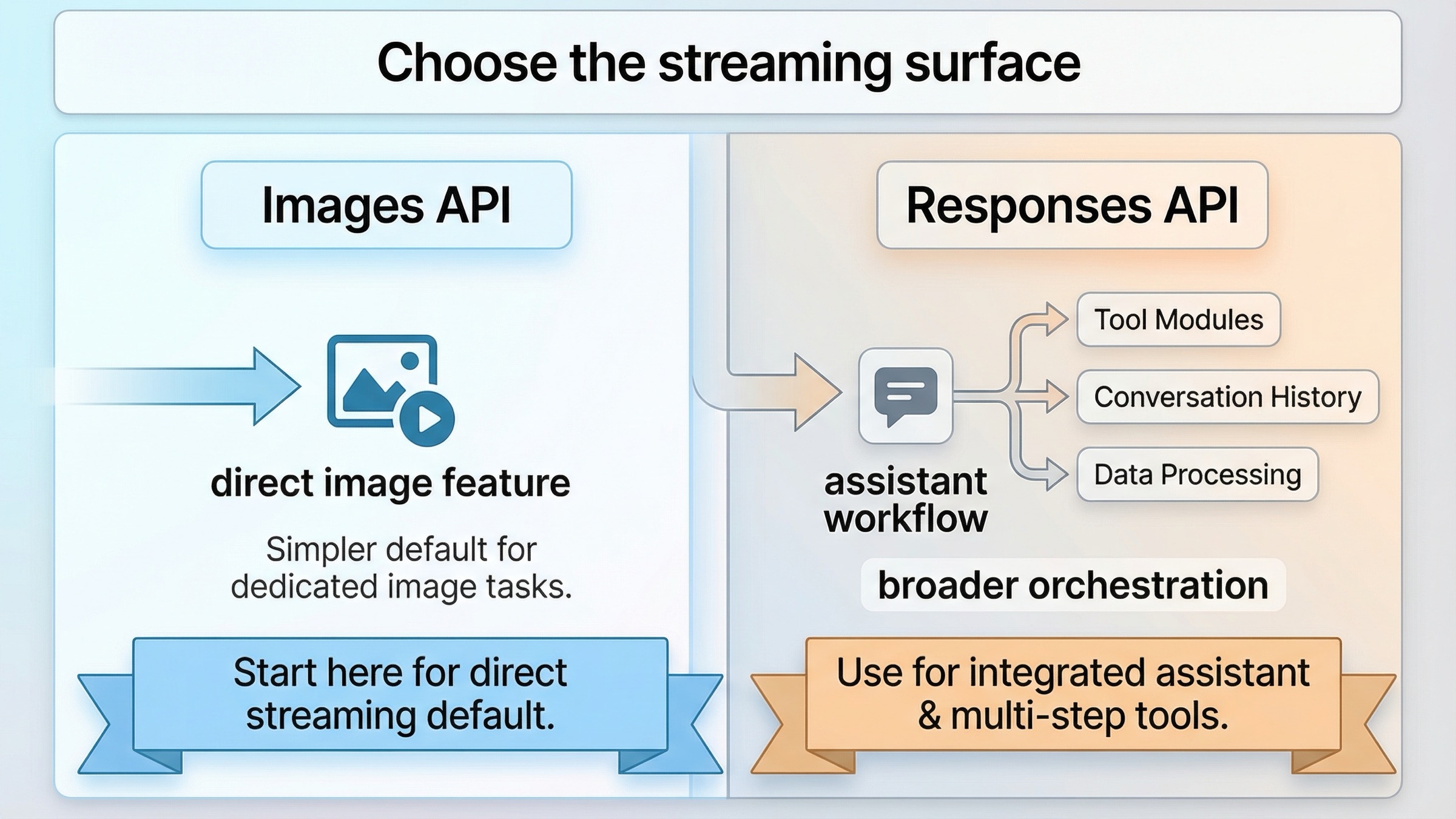
この keyword は、「どちらが新しい endpoint か」を問うのをやめて、「今作っている product に合う surface はどちらか」を考えるとかなり整理されます。
| 状況 | 先に選ぶべき default | 理由 |
|---|---|---|
| direct image feature で preview と final image が欲しい | Images API | request shape が素直で、image-only path の event loop が最も単純 |
| 画像生成が broader assistant / multimodal flow の一部 | Responses API | image generation を大きな reasoning / conversation workflow の tool として扱える |
| 自分の account で streaming が動くか最速で確かめたい | Images API | moving parts が少なく、top-level orchestration をまだ考えなくていい |
| mainline model に prompt revision や他 tool との調整をさせたい | Responses API | image が唯一の output でないなら hosted image_generation tool が自然 |
| docs confusion を最初に切り分けたい | まず Images API、その後必要なら Responses | event handling や orchestration を疑う前に route uncertainty を 1 層消せる |
実務ルールは単純です。画像生成そのものが feature なら direct route から始める。 Images API を使い、partial previews が届くことを確認し、それから product に本当に必要な場合だけ Responses layer を加える。画像生成が several tools のうちの 1 つなら、初めから Responses に乗せる方が筋が通っています。
現在の images and vision guide もこの split を支持しています。この guide は Image API と Responses API の両方で images の生成や編集ができると書き、Responses example では gpt-4.1-mini のような mainline model に hosted image_generation tool を付けています。これは、OpenAI が Responses path を「mainline model が orchestrate し、image generation はその内側の tool である」と捉えていることの強いヒントです。
いちばん速く動かすなら Images API から始める
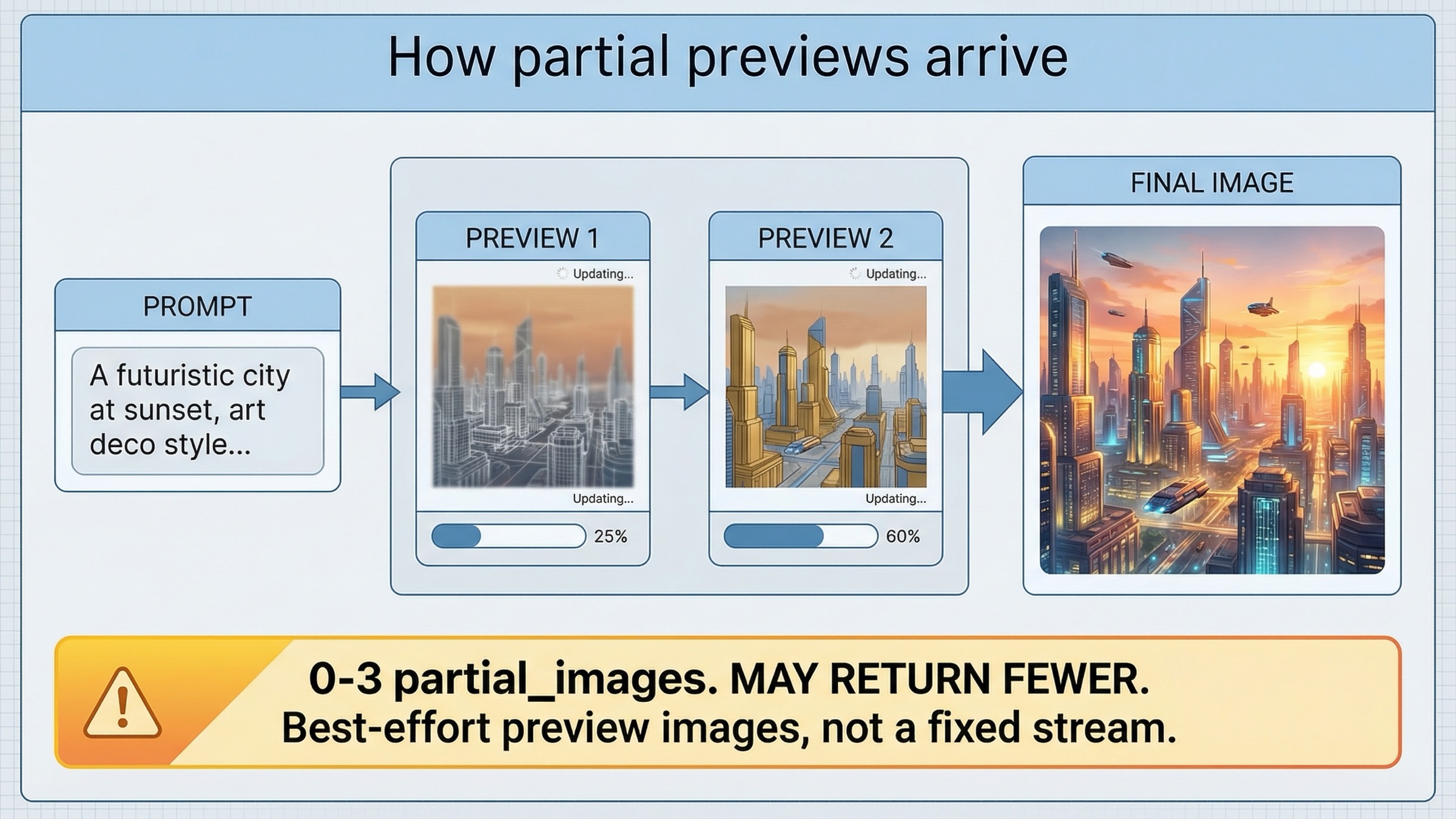
もし目的が streaming path を最速で証明することなら、Images API は今も最良の出発点です。current guide は gpt-image-1.5、stream: true、partial_images: 2 という direct pattern を示しています。私ならまずこの route を通します。
JavaScript では次のようになります。
jsimport fs from "fs"; import OpenAI from "openai"; const client = new OpenAI({ apiKey: process.env.OPENAI_API_KEY, }); const stream = await client.images.generate({ model: "gpt-image-1.5", prompt: "Create a clean editorial illustration of a camera drone hovering over a bright city skyline at sunrise", stream: true, partial_images: 2, }); for await (const event of stream) { if (event.type === "image_generation.partial_image") { const index = event.partial_image_index; const imageBytes = Buffer.from(event.b64_json, "base64"); fs.writeFileSync(`preview-${index}.png`, imageBytes); } }
Python もほぼ同じです。
pythonfrom openai import OpenAI import base64 client = OpenAI() stream = client.images.generate( model="gpt-image-1.5", prompt="Create a clean editorial illustration of a camera drone hovering over a bright city skyline at sunrise", stream=True, partial_images=2, ) for event in stream: if event.type == "image_generation.partial_image": index = event.partial_image_index image_bytes = base64.b64decode(event.b64_json) with open(f"preview-{index}.png", "wb") as f: f.write(image_bytes)
この route が良い理由は 3 つあります。
1 つ目は、最小の route を証明できることです。current image model を明示し、少数の previews を要求し、image-specific event を 1 つだけ listen する。質問が「streaming は動くか」である限り、これ以上 clean な first test はありません。
2 つ目は、debug tree がかなりきれいになることです。preview が届かなければ、account access、model choice、event handling をまず疑えます。より大きな Responses workflow のどこかが原因ではないか、と無駄に広く疑わなくて済みます。現在の GPT Image 1.5 page はまだ Free not supported と書いており、image 用 rate limits は Tier 1 の 100,000 TPM / 5 IPM から始まるので、SDK sample を疑う前に access assumptions を外す価値があります。
3 つ目は、UI expectation を最初から正しく置けることです。guide は 0 から 3 の partial images を request できる一方、generation が速ければ requested count より少なくなることもあると明示しています。つまりこれは guaranteed frame contract ではなく preview signal です。product がその semantics を正直に扱えるなら、Images API route だけで十分なことが多いです。
より広い direct-generation guide が必要なら、次に OpenAI Image API チュートリアル を読むのが自然です。streaming 固有の疑問が解けたあとなら、そちらの方が direct generation と edits の全体像を掴みやすいです。
Responses API を選ぶべき場面
Responses path 自体が間違いなのではありません。多くの場合、この keyword に対する 最初の default としては重すぎる だけです。
OpenAI の current image generation guide にある streamed Responses example は次の形です。
jsimport fs from "fs"; import OpenAI from "openai"; const client = new OpenAI({ apiKey: process.env.OPENAI_API_KEY, }); const stream = await client.responses.create({ model: "gpt-5", input: "Create a transparent sticker-style icon of a paper airplane for a travel app", stream: true, tools: [{ type: "image_generation", partial_images: 2 }], }); for await (const event of stream) { if (event.type === "response.image_generation_call.partial_image") { const index = event.partial_image_index; const imageBytes = Buffer.from(event.partial_image_b64, "base64"); fs.writeFileSync(`preview-${index}.png`, imageBytes); } }
この path が向いているのは、image が唯一の output ではないケースです。たとえば次のような場面です。
- text と image を両方返す multimodal assistant
- いつ image generation を呼ぶか mainline model に判断させたい workflow
- image tool の前に prompt revision や他 tool coordination を mainline model にやらせたい system
current guide はこの追加レイヤーも明示しています。Responses API では、mainline model が image generation call の prompt を見直すことがあり、完了後には revised_prompt を確認できます。つまり、surrounding workflow こそが product value である場合には、Responses path は確かに自然です。
ただし 1 つ避けるべき罠があります。final output が image だからといって、top-level model に gpt-image-1.5 を入れる場所だと考えないことです。current docs は Responses image generation を、gpt-4.1 や gpt-5 のような mainline model と hosted image_generation tool の組み合わせとして説明しています。ここを取り違えると、streaming problem ではなく route problem を延々と追うことになります。
なので正しい recommendation は、「Responses の方が modern だから全部それでよい」ではありません。orchestration が feature なら Responses、image generation 自体が feature なら Images API。この 1 行で十分です。
なぜ docs が矛盾して見えるのか
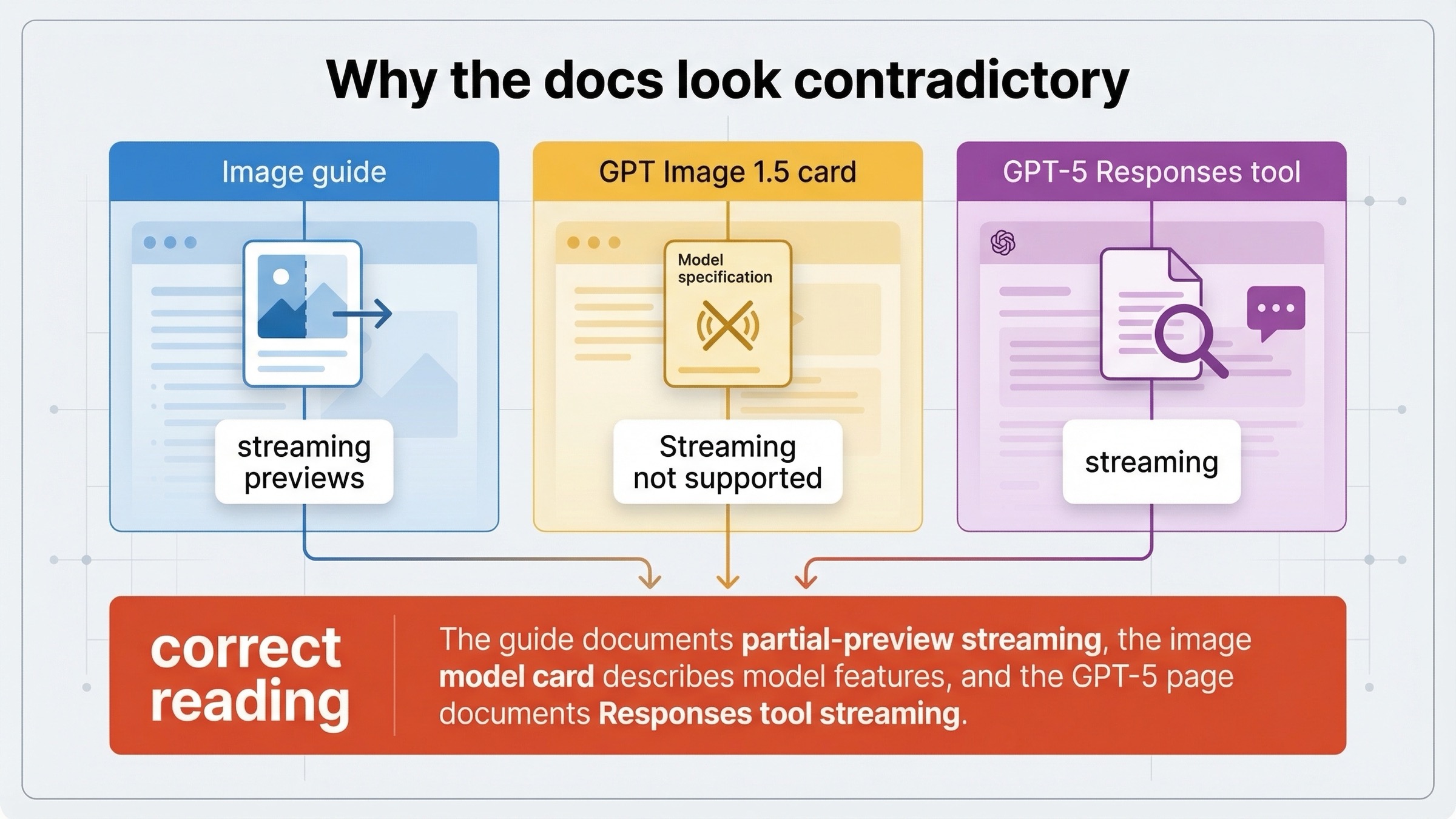
この部分こそ、いまの ranking pages がまだ十分に説明できていないところです。
現在の image generation guide は、Responses API と Image API の両方が streaming image generation を support すると書き、両 surface の concrete event loop を示したうえで、その意味を partial-image previews として定義しています。
一方で、現在の GPT Image 1.5 model page は feature table にまだ Streaming: Not supported と残しています。
さらに現在の GPT-5 model page は streaming is supported と記載し、image_generation tool が Responses API で supported だと示しています。
この 3 つを矛盾なく読むなら、整理はこうです。
- image guide は API surface behavior としての partial-preview streaming を説明している
- GPT-5 page は mainline model behavior と Responses 内の tool support を説明している
- GPT Image model card は image model 自体が text のように generic streaming することを約束しているわけではない
この読み方は、OpenAI が実際に公開している examples とも一致します。質問が「generation 中に preview images を受け取れるか」なら答えは yes です。質問が「image model が text model のように token chunks を stream するか」なら答えは no です。current image guide が記述しているのはその意味ではありません。
古い tutorials が別のことを言っているように見えるのも同じ理由です。OpenAI が API image model を launch した 2025 年 4 月 23 日 の post では、gpt-image-1 は Images API にまず出て、Responses support は "coming soon" とされていました。その時代の mental model のままだと、今でも Images-first な理解と狭い streaming 定義を引きずりやすいです。docs は前に進んでいますが、古い wording が自動で消えるわけではありません。
よくある implementation mistakes
この topic の失敗は深い algorithm 問題より、route、naming、expectation のミスで起こります。
1. 選んだ surface と event name がずれている
direct Images API では image_generation.partial_image、Responses API では response.image_generation_call.partial_image を listen します。これらは interchangeable ではありません。surface に合わない event name を使うと、streaming が壊れているように見えても実際には handler のミスです。
2. direct image feature なのに最初から Responses に行く
prompt、数枚の preview、最終 asset だけが必要なら、Images API の方が first success がきれいです。Responses から始めると、最初の success を証明する前に余分な abstraction layer を背負うことになります。
3. partial_images を固定フレーム数の保証だと思う
current guide は partial_images が 0 から 3 まで設定できると言いつつ、generation が速い場合は requested count 未満になることもあると書いています。previews は best-effort progress UX と考えるべきで、guaranteed frame contract ではありません。
4. model card と guide を同じ層の説明として読む
違います。guide は API surface の streamed partial-image delivery を説明しています。model card は broader catalog table の一部として image-model features を説明しています。この 2 つを 1 つに潰すと、今の support を過小評価するか、逆に guarantee を過大評価するかのどちらかになります。
5. access assumptions を確認する前に code を疑う
現在の GPT Image 1.5 page は Free 不可を示したままですし、launch post も organization verification が必要になる場合を示唆しています。最初の streamed test が無反応なら、event loop だけを疑わないでください。まず account と organization が選んだ image model に access できるかを確認すべきです。
6. gpt-image-1 時代の前提で 2026 年の実装を進める
new work の current anchor は gpt-image-1.5 であり、初期の gpt-image-1 launch mental model ではありません。OpenAI image routes 全体も整理したいなら、次は OpenAI image generation API models ガイド を見た方が早いです。
FAQ
preview frames を必ず 2 枚受け取るように強制できますか。
できません。current image generation guide は partial_images を 0 から 3 まで設定できるとしつつ、generation が速い場合は requested count より少ない preview になることがあると明記しています。partial images は best-effort preview signals と考えるべきです。
この話は Realtime API から入るべきですか。
少なくとも現時点では default answer ではありません。current image generation guide が明示している route は、Images API と Responses API 上の streamed partial-image previews です。OpenAI がより明示的な Realtime image-preview pattern を出すまでは、この path を基準にするのが妥当です。
request に入れる model は何ですか。
direct Images API path なら gpt-image-1.5 から始めます。Responses path なら current docs pattern に従い、top-level model に gpt-4.1 や gpt-5 のような mainline model を置き、hosted image_generation tool を付けます。
最後の推奨
このページから 1 つだけ持ち帰るなら、OpenAI image generation の streaming は今のところ partial-image preview streaming を意味し、image generation が単体 feature である限り Images API が safest default である、という点です。
単なる "yes" よりこの答えの方が有用なのは、次にやるべきことまで示すからです。まず gpt-image-1.5 で direct streamed Images API request を 1 本通し、UI が best-effort な preview arrival を正しく扱えるか確認する。その後で、product が本当に必要とするときだけ Responses API に上がる。この順番がいちばん無駄が少ないです。
streaming の疑問が解けたあとに broader route map が必要なら、direct generation と edits の全体像は OpenAI Image API チュートリアル を、preserve-heavy edits が次の課題なら OpenAI image editing API ガイド を続けて読むとよいです。