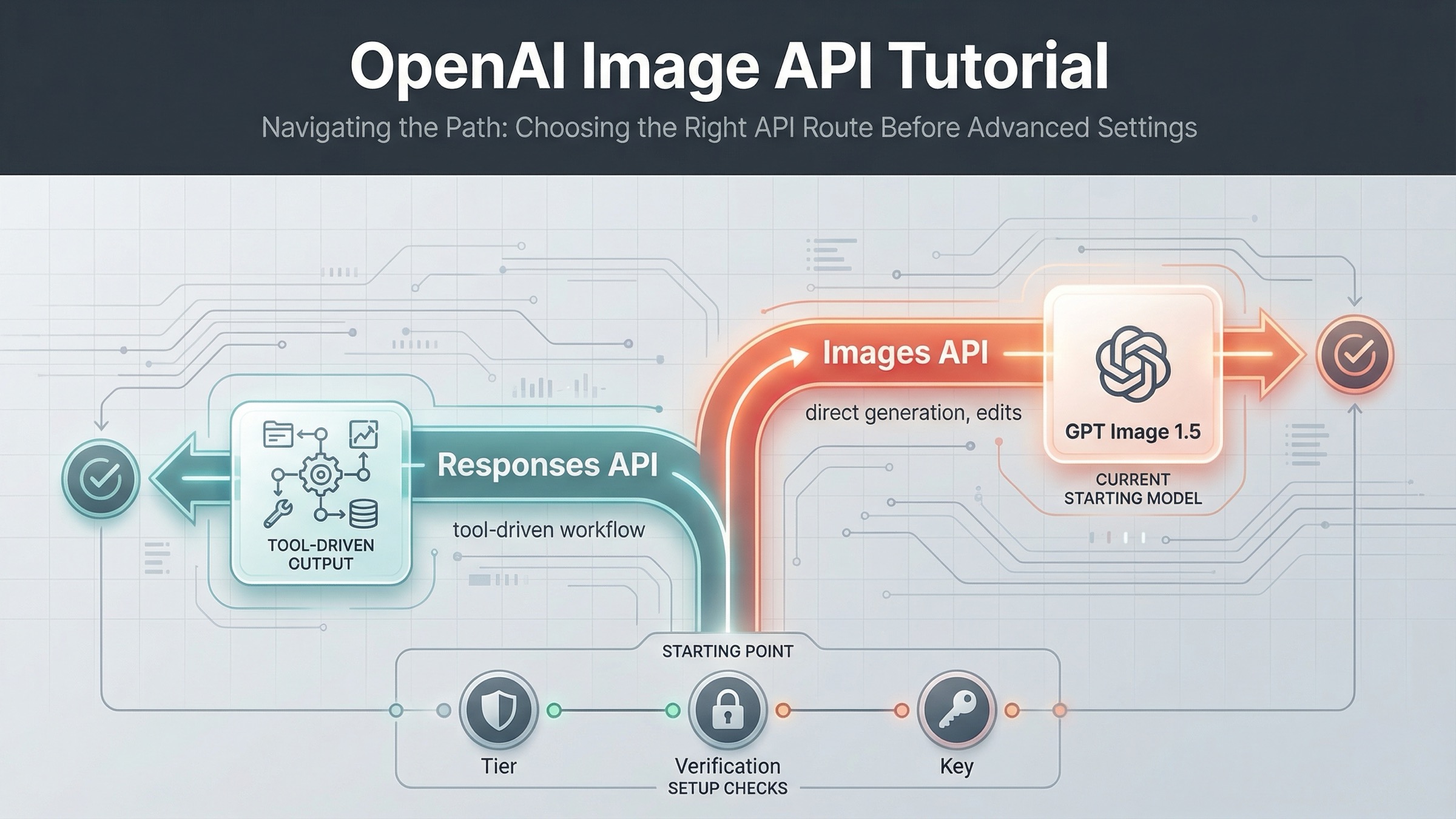
今 OpenAI の画像生成を実装するなら、最初に使うべき既定ルートは Responses ではなく、直接の Images API です。単発の画像生成は POST /v1/images/generations、既存画像を編集するなら POST /v1/images/edits、そして画像生成が大きなマルチモーダルまたは agent ワークフローの一部になったときだけ Responses の image_generation tool に移るのが安全です。
この区別が重要なのは、OpenAI の現在のドキュメントが答えを複数のページに分散させているからです。image generation guide は Images API と Responses API の分担を説明し、Images API reference が生のパスを示し、image_generation tool guide が Responses 内での画像生成を説明します。しかも 2026年3月23日 時点で、公式の Images and vision には最新画像生成モデルが gpt-image-1 と残っており、現在のモデルカタログとズレています。
だからこのキーワードで本当に必要なのは「URL を1本教えること」ではありません。必要なのは、自分が今やっている仕事を、どの API surface から始めるべきかを決めることです。まず 1 枚の画像を確実に返せるか確認したいなら、直接 Images API から始めるべきです。会話状態、他の tool、推論モデルと一緒に画像生成を扱う必要が出てきたら、その時点で Responses に切り替えれば十分です。
現在のOpenAI画像endpointを1枚の表で整理する
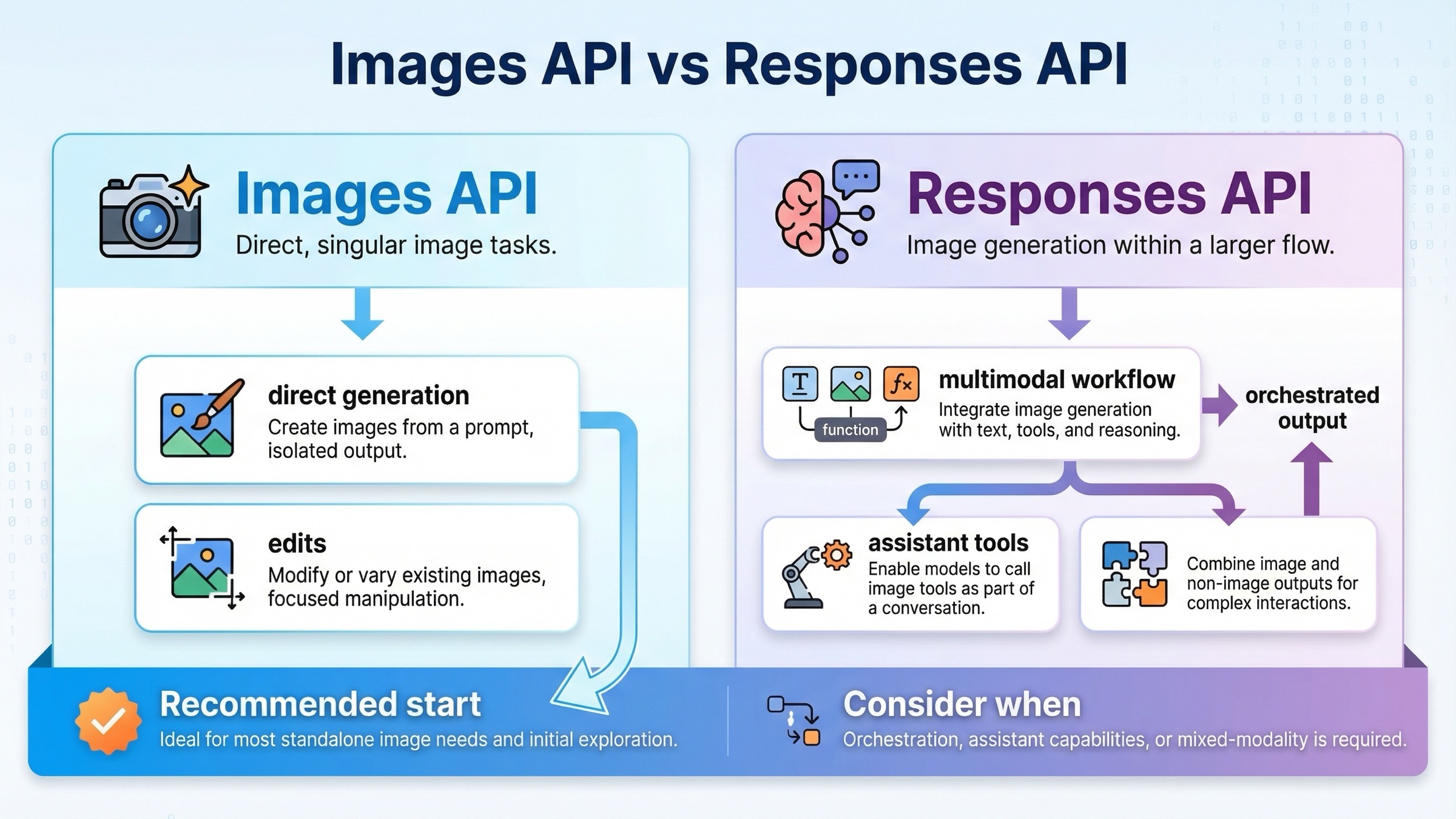
OpenAI の現在の画像スタックは、直接画像を扱う仕事 と tool を伴うマルチモーダル編成 を分けて考えると一気に分かりやすくなります。
| 仕事 | 現在の最適ルート | 生のパスまたは SDK 呼び出し | model に入れるもの | 先に使うべき場面 | ありがちな誤り |
|---|---|---|---|---|---|
| 1回のリクエストで画像を生成する | Images API | POST /v1/images/generations または client.images.generate() | gpt-image-1.5 | 最短で動く経路を取りたい | 新しそうだからといって最初から Responses に行く |
| 既存の画像を編集する | Images API | POST /v1/images/edits または client.images.edit() | gpt-image-1.5 | 入力画像がすでにある | edit だから Responses が必要だと思い込む |
| 画像生成がより大きな assistant/agent の一部 | Responses API + image_generation tool | client.responses.create() | gpt-5 などの上位モデル | 画像が workflow の一部にすぎない | gpt-image-1.5 を Responses の最上位 model に入れる |
この表がいちばん実用的なのは、OpenAI の現行ドキュメントの分け方にそのまま沿っているからです。image generation guide は主に2本のルートがあると説明し、単発の画像 なら Image API を推します。Responses の tool guide はその逆で、画像生成がもっと大きな推論フローに入るケース向けです。
実務上のルールは単純です。明確な理由がない限り、まずは直接 Images API から始める。 そのほうが最初のリクエストも、チーム内の再現も、デバッグの切り分けもはるかに簡単です。
モデル名の選び方自体がまだ曖昧なら、先に同言語の OpenAI Image Generation API Models を見てください。このページは deliberately 狭く、surface の選び方だけに集中します。
単発生成なら POST /v1/images/generations から始める
大半の新規統合にとって、この endpoint は最初の確認に最適です。現在の Images API reference は POST /images/generations を生の生成 endpoint として示しており、実際の呼び出しでは https://api.openai.com/v1/images/generations を使うことになります。モデル選択については、GPT Image 1.5 のモデルページ が現在の画像モデルの起点として最も信頼できます。
最初のリクエストは、あえて退屈にしておくべきです。1つの prompt、正方形サイズ、現在の画像モデル。これだけで API key、project、model access、payload shape が正常かどうかが分かります。最初から透明背景、多画像編集、Responses、出力形式まで一気に詰め込むより、はるかに問題の位置を特定しやすいです。
最小の cURL 例はこうです。
bashcurl https://api.openai.com/v1/images/generations \ -H "Authorization: Bearer $OPENAI_API_KEY" \ -H "Content-Type: application/json" \ -d '{ "model": "gpt-image-1.5", "prompt": "Create a clean editorial illustration of a robot camera operator in a bright studio", "size": "1024x1024", "quality": "medium" }'
JavaScript の SDK でも対応はほぼそのままです。
jsimport OpenAI from "openai"; const client = new OpenAI({ apiKey: process.env.OPENAI_API_KEY }); const result = await client.images.generate({ model: "gpt-image-1.5", prompt: "Create a clean editorial illustration of a robot camera operator in a bright studio", size: "1024x1024", quality: "medium", });
ここで弱い記事が飛ばしがちな大事な点が1つあります。Images API reference によれば、GPT Image 系はデフォルトで b64_json を返します。つまり最初の「成功」は、HTTP 200 が返ることではなく、その戻り値を decode して保存できることまで含めて確認すべきです。だからこそ、最初の一歩は直接 endpoint のほうが向いています。リクエストから利用可能な画像までの最小ループが一番見えやすいからです。
コード例をもっと幅広く見たいなら、同言語の OpenAI image generation API example に進めば十分です。この endpoint 記事の役目は、あくまで「どの surface から始めるか」を先に固定することです。
入力画像があるなら POST /v1/images/edits を使う
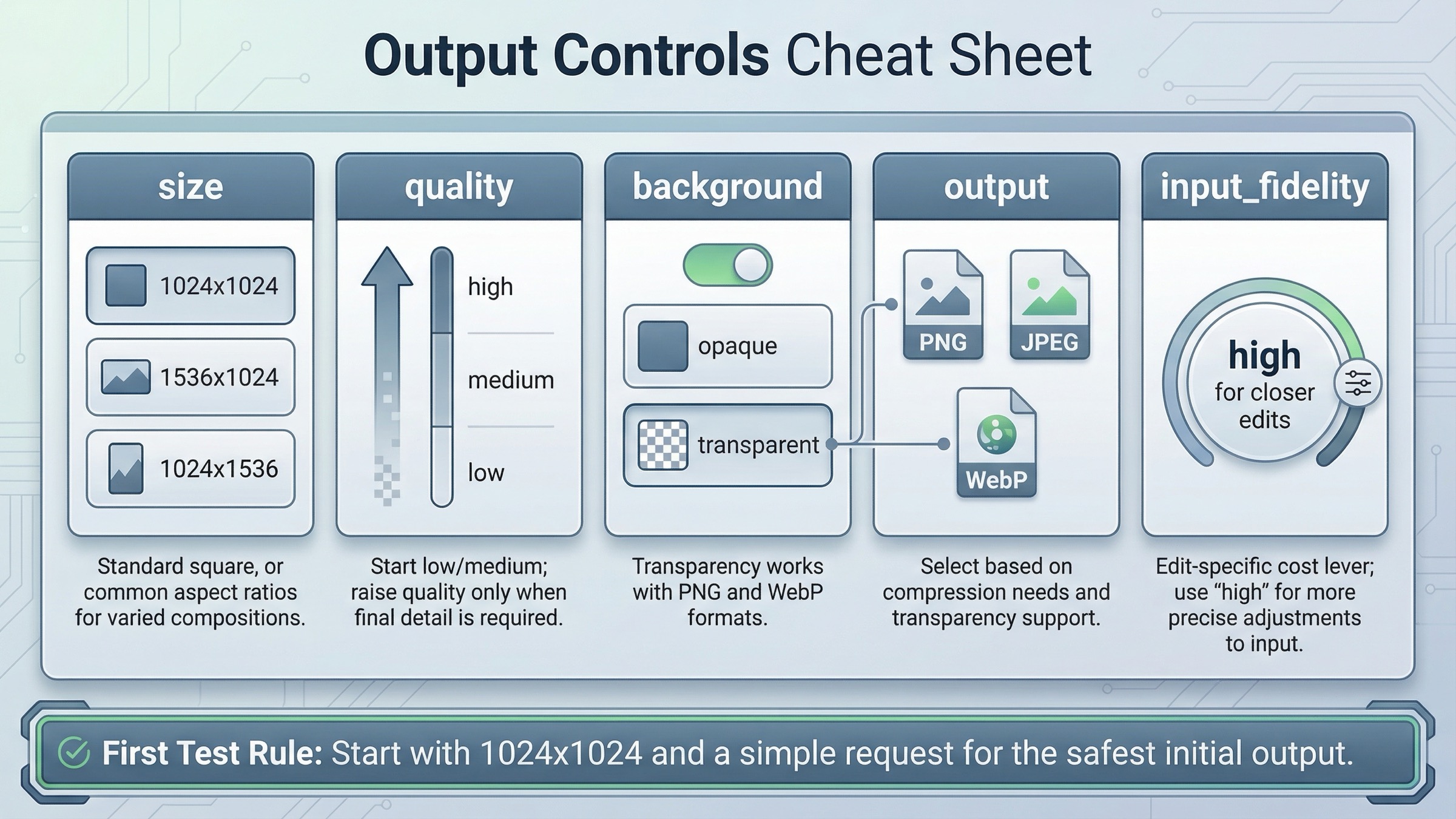
“image generation endpoint” を探している人でも、実際に必要なのが純粋な生成ではなく、手元の画像を修正することは少なくありません。その場合でも、現在の最適ルートは直接 Images APIのままです。単に生成 branch から edit branch に移るだけです。
Images API reference は POST /images/edits を編集 endpoint として示し、主 image generation guide も GPT Image 1.5 の edit 例を同じ surface 上で案内しています。これは重要です。なぜなら、画像編集は still Images API の正式な仕事 であり、edit だからといって自動的に Responses に寄せる必要はないからです。
SDK の最小形はこうです。
jsimport fs from "fs"; import OpenAI from "openai"; const client = new OpenAI({ apiKey: process.env.OPENAI_API_KEY }); const result = await client.images.edit({ model: "gpt-image-1.5", image: [fs.createReadStream("product-shot.png")], prompt: "Keep the product shape, but place it on a clean studio shelf with warm lighting", input_fidelity: "high", });
input_fidelity: "high" を endpoint 記事でも触れるべき理由は、直接 edit ルートが「簡易版」ではないことを示せるからです。これは OpenAI が今まさに提供している編集の本線です。ここを離れる理由があるとすれば、それは画像タスクが難しいからではなく、workflow 自体がより大きくなったからです。
多くの弱いチュートリアルは、画像タスクが少し複雑になるだけで何でも Responses へ寄せてしまいます。そのせいで習得コストが不必要に高くなります。仕事が still “この画像を変える” である限り、直接 Images API のほうが request shape もデバッグも分かりやすいことが多いです。
mask、input_fidelity、preservation、多画像 compositing まで深く知りたいなら、同言語の OpenAI image editing API を見れば十分です。このページで固定したいのは、編集は Images API の第一級ユースケースであり、それ自体は Responses へ移る理由ではないということです。
画像生成が大きなフローの一部になったときだけ Responses に移る
Responses の価値は「新しい」ことではなく、より大きな workflow に向いていることです。もしあなたの製品が、指示を読み、別の tool を呼び、会話状態を保ちながら、その一部として画像を生成する必要があるなら、image_generation tool は直接 endpoint より自然な抽象になります。
このとき最も起きやすい誤りは、gpt-image-1.5 を Responses の最上位 model に入れることです。現在の image_generation tool guide は明確で、GPT Image モデルは tool の裏側で使われるものの、最上位 model の値としては有効ではありません。
つまり shape はこうなります。
jsimport OpenAI from "openai"; const client = new OpenAI({ apiKey: process.env.OPENAI_API_KEY }); const response = await client.responses.create({ model: "gpt-5", input: "Generate a transparent sticker-style icon of a paper airplane for a travel app", tools: [{ type: "image_generation", background: "transparent", quality: "high" }], });
このルートは正しいですが、解いている問題は直接 Images API と別です。向いているのは次のようなケースです。
- 1つのリクエストが文章と画像の両方を返す可能性がある
- 画像生成が複数 tool の一つである
- モデル自身に「いつ画像を作るか」を判断させたい
逆に、今の悩みが「どの endpoint から始めるべきか」だけなら、Responses は層を増やしすぎます。上位モデル、tool invocation、tool output parsing、より間接的なデバッグが増えるからです。
だから原則は「Responses は新しいから優先」ではありません。オーケストレーション自体が本当の課題になったときだけ Responses が正解になる、ということです。
この先でより広い導入ルートまで整理したいなら、同言語の OpenAI Image API tutorial を続けて読むのが自然です。
ドキュメントのズレとアクセス確認が、正しいendpointを“間違い”に見せる
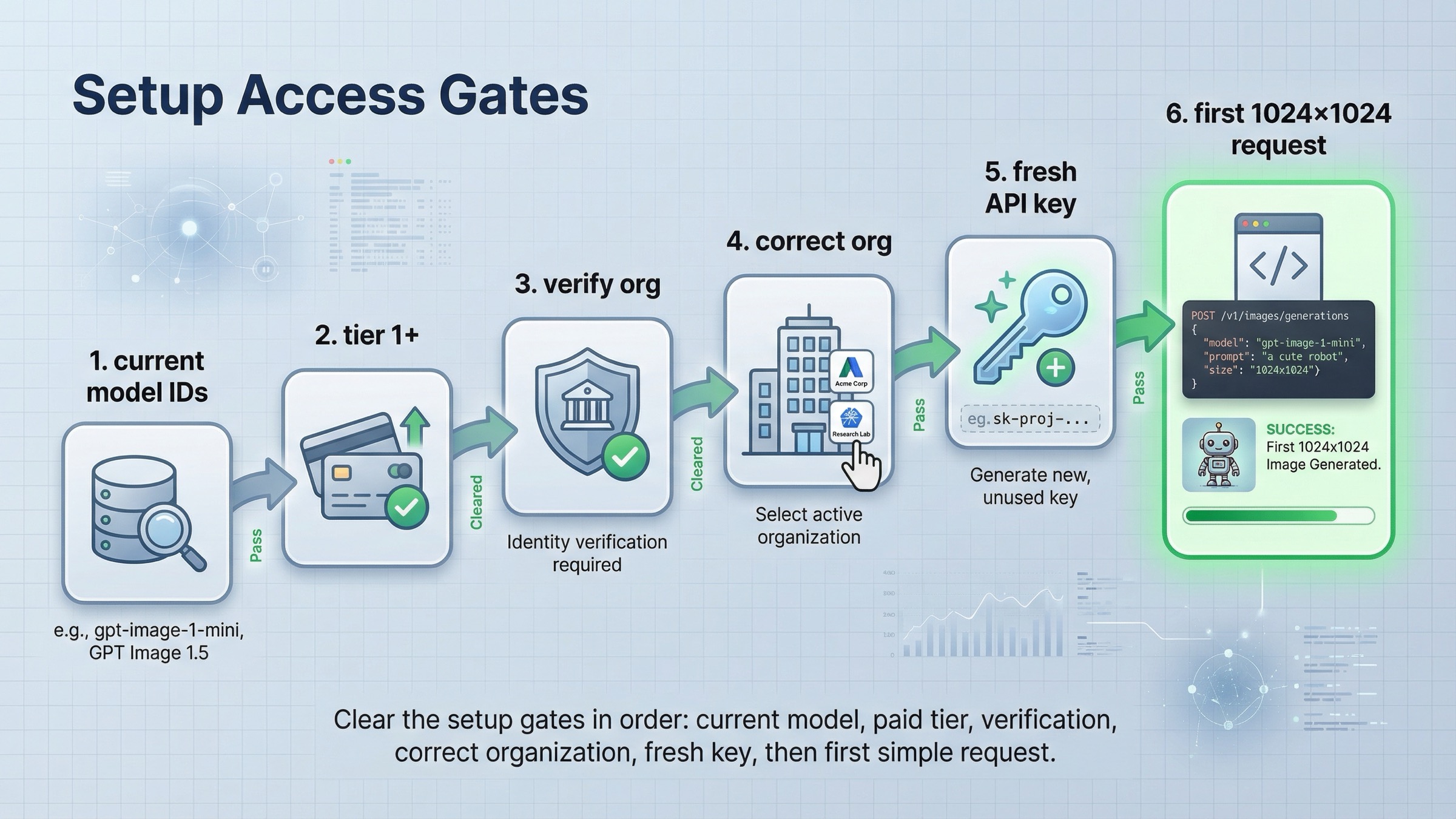
ここが今の SERP で最も弱い部分です。多くの開発者は endpoint を間違えたと思い込みますが、実際には ドキュメントの鮮度のズレ か アカウントアクセス が問題です。
まず鮮度のズレです。2026年3月23日 時点で、all-model catalog は GPT Image 1.5 を現在の画像ラインとして見せ、GPT Image 1.5 のモデルページ もそれを current flagship として扱っています。ところが公式の Images and vision には still gpt-image-1 が最新と残っています。さらに古い cookbook example も gpt-image-1 を使っています。
これは公式ドキュメントが使えないという意味ではありません。意味するのは、ページごとに解くべき問題が違う ということです。
- 生の path は API reference を見る
- 現在どのモデルが主線か は all-model catalog と GPT Image 1.5 page を見る
- Images API か Responses か は main guide を見る
- Responses を本当に使うときだけ tool guide を見る
次にアクセスです。GPT Image 1.5 のページは Free not supported と示し、公開制限は Tier 1 の 100,000 TPM と 5 IPM から始まります。API model availability は gpt-image-1 と gpt-image-1-mini の利用可否が tier 1 through 5 と organization verification に関係することも書いています。つまり endpoint が正しくても、アカウントが ready でなければ失敗します。
さらに rollout 由来のノイズも検索圏に残っています。OpenAI 自身の GPT Image 1.5 rollout thread では、モデルが見えない、model-not-found が返る、といった報告がありました。こうしたローンチ直後の情報は、古いチュートリアルやキャッシュ断片に残りやすいです。
だから安全なデバッグ順はこうなります。
- まず route が正しいか確認する。Images API 先、Responses は必要になってから
- 次に model default が current か確認する。GPT Image 1.5 を基準にする
- その後で tier、active org、verification を確認する
- 最後に payload や SDK 呼び出しを疑う
もし本当の問題が access なら、同言語の OpenAI image generation API verification に進む方が早いです。endpoint を闇雲に変えても、ほとんどの場合ここは直りません。
最終的なおすすめ
2026年3月23日 時点で短く覚えるなら、次の順番で十分です。
- 単発生成 は
POST /v1/images/generations - 入力画像を使う編集 は
POST /v1/images/edits - 画像生成が大きなマルチモーダル処理の一部 なら Responses +
image_generation - 生の path は reference、鮮度は model catalog と GPT Image 1.5 page を基準にする
この順番が現在の page one 平均より優れているのは、公式 facts をただ並べるのではなく、実装上の判断に変換しているからです。多くの上位ページは reference、help、古い例、最新 guide のあいだを読者に自分で縫わせています。より安全なのは、まず surface を選び、最小の直接リクエストを成功させ、それから本当に必要な複雑さだけを積み上げることです。
FAQ
普通の画像編集でも Responses が必要ですか。
いいえ。一般的な edit workflow なら、現在の OpenAI ドキュメントは POST /v1/images/edits と client.images.edit() を正式ルートとして扱っています。Responses が有利なのは、画像編集がより大きな assistant/agent フローの一部になっている場合です。
一部の公式ページに gpt-image-1 とあるなら、まだそれを使うべきですか。
新規導入の既定値としては使わないほうが安全です。2026年3月23日時点では、all-model catalog と GPT Image 1.5 page が GPT Image 1.5 を current line として扱っています。gpt-image-1 は migration や legacy comparison の文脈で残っている、と考えるのが安全です。
endpoint は正しいのに、なぜ still 失敗するのですか。
endpoint routing と account readiness は別問題だからです。GPT Image 1.5 page は Free 非対応を示し、availability guidance も一部アクセスが paid tier と organization verification に結びつくことを示しています。route が正しそうなら、まず access を確認してください。