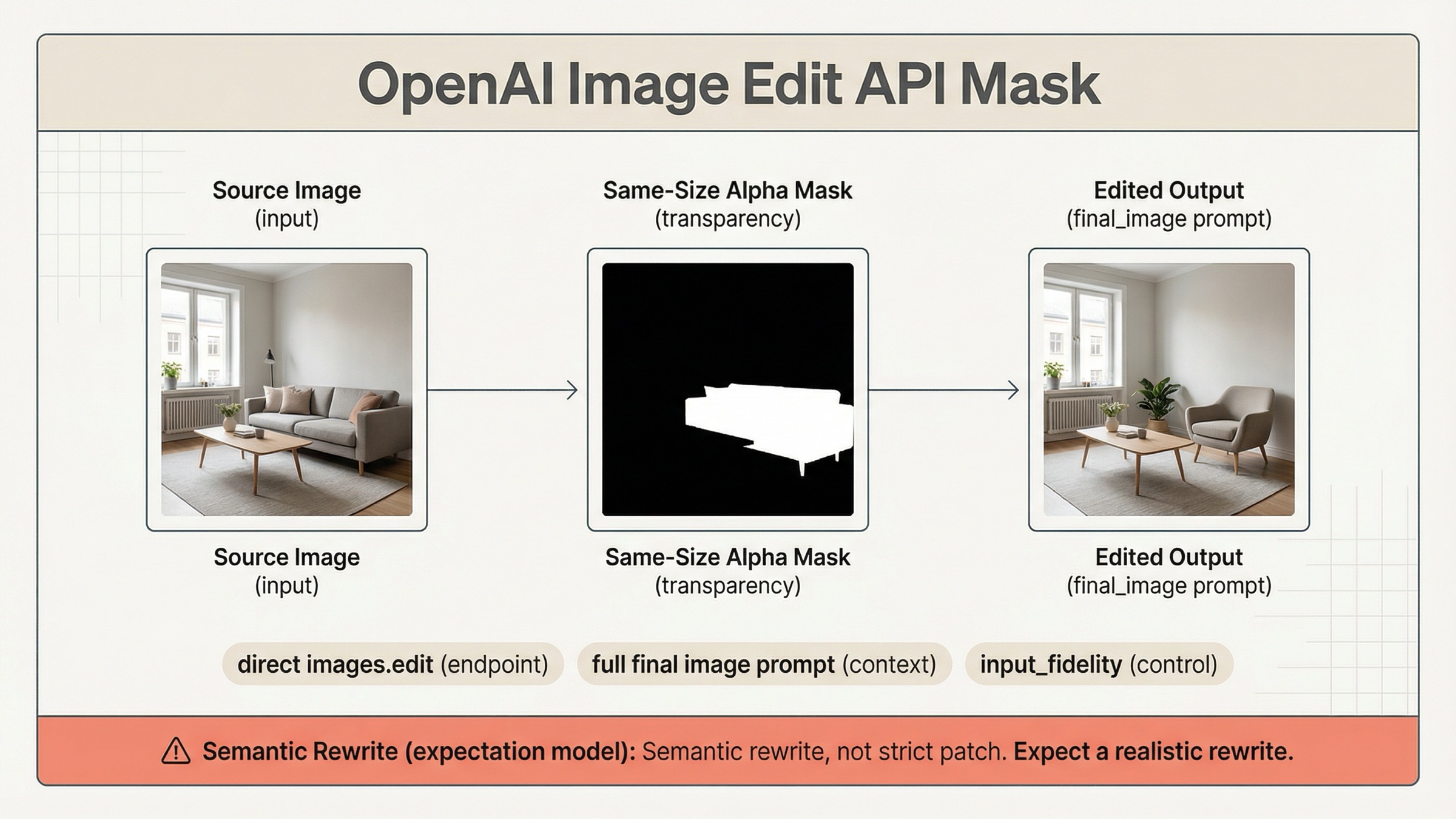
2026年3月29日時点で、OpenAI の mask edits をいちばん安全に始める current default は、gpt-image-1.5 で direct images.edit() を使い、same-size alpha mask を送り、prompt を「最終的な画像全体」の説明として書くことです。 ここを先に固めるだけで、Responses に早く移りすぎたり、昔の inpainting と同じ期待でハマったりする失敗をかなり減らせます。
この query がまだ分かりにくいのは、答えが一箇所にまとまっていないからです。image generation guide は mask の mechanical requirements を説明し、input fidelity は preservation side を補い、Responses の image tool options は action=auto|generate|edit の話を別ページで持っています。一枚だけ読むと、route の判断に必要なピースが足りません。
しかも OpenAI 自身がすでに書いている通り、GPT Image の mask は prompt-based guidance であって、strict local patch を保証するものではありません。 ここを見落とすと、「mask は valid なのに whole-image rewrite っぽく見える」という complaint をずっと prompt bug だと思い続けてしまいます。
要点まとめ
- one-shot の mask edits なら、まず direct
client.images.edit()かPOST /v1/images/editsを使う。 - mask を疑う前に、same format、same dimensions、
50 MB未満、real alpha channel という条件を満たしているか確認する。 - prompt は空いた部分の説明ではなく、最終的な画像全体を説明する。
- face、logo、product details の preservation が重要なときだけ
input_fidelity="high"を加える。 - mental model は deterministic patch ではなく、constrained semantic rewrite に寄せて考える。
いちばん安全な OpenAI mask-first route から始める
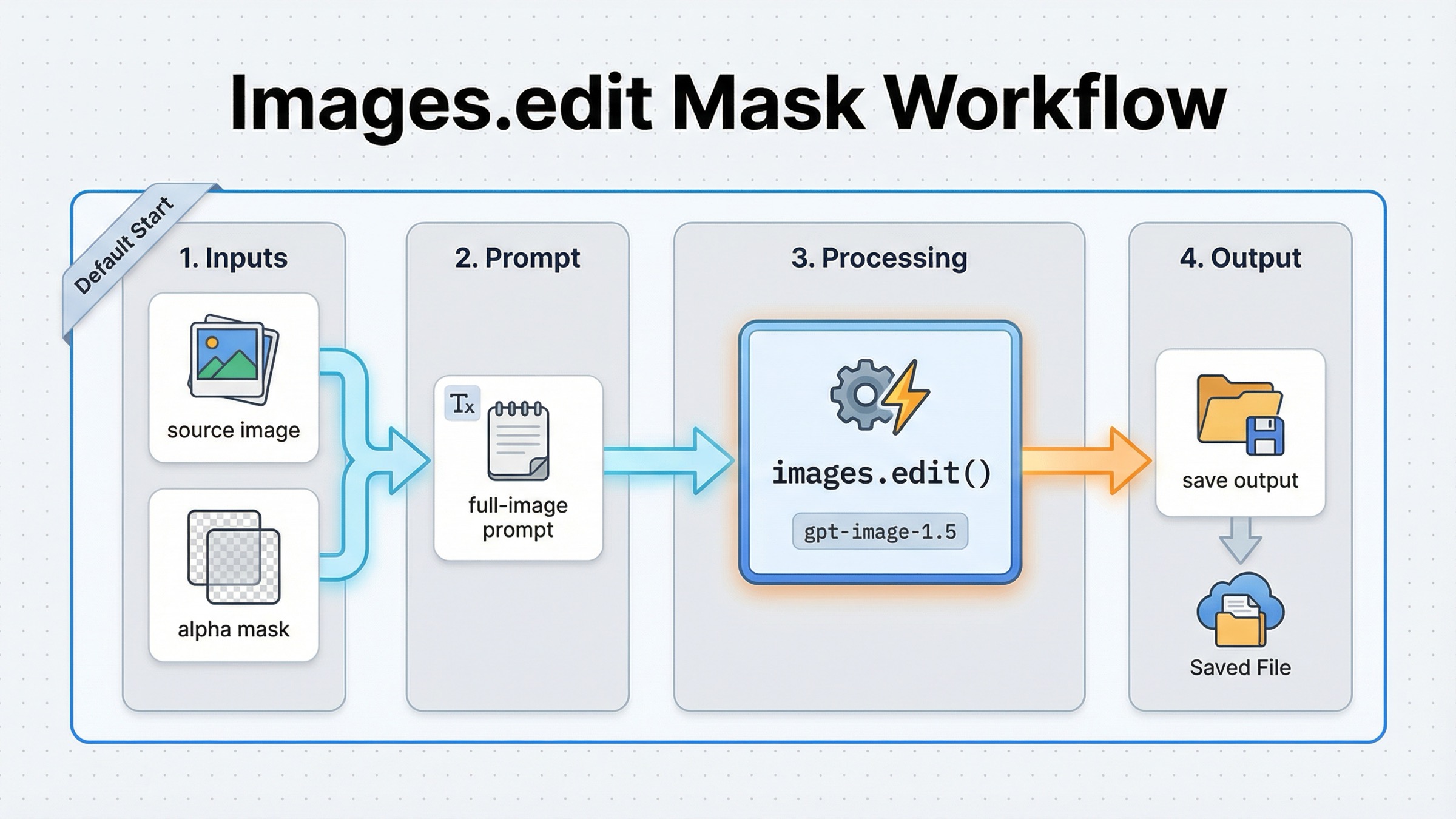
あなたの job が「この画像のこの領域を編集したい」で終わるなら、最初から conversation wrapper を持ち込む理由はほとんどありません。current OpenAI docs がいちばん素直に勧めている route は、base image、mask、final-image prompt、base64 output という direct な Images API path です。
JavaScript の current shape はこうです。
jsimport fs from "fs"; import OpenAI, { toFile } from "openai"; const client = new OpenAI(); const result = await client.images.edit({ model: "gpt-image-1.5", image: await toFile(fs.createReadStream("sunlit_lounge.png"), null, { type: "image/png", }), mask: await toFile(fs.createReadStream("mask.png"), null, { type: "image/png", }), prompt: "A sunlit indoor lounge area with a pool containing a flamingo. Preserve the room, lighting, reflections, and camera angle.", input_fidelity: "high", size: "1024x1024", quality: "medium", }); const imageBase64 = result.data[0].b64_json; const imageBytes = Buffer.from(imageBase64, "base64"); fs.writeFileSync("lounge.png", imageBytes);
Python でも route は同じです。
pythonfrom openai import OpenAI import base64 client = OpenAI() result = client.images.edit( model="gpt-image-1.5", image=open("sunlit_lounge.png", "rb"), mask=open("mask.png", "rb"), prompt=( "A sunlit indoor lounge area with a pool containing a flamingo. " "Preserve the room, lighting, reflections, and camera angle." ), input_fidelity="high", size="1024x1024", quality="medium", ) image_base64 = result.data[0].b64_json image_bytes = base64.b64decode(image_base64) with open("lounge.png", "wb") as f: f.write(image_bytes)
raw HTTP で見るなら、current multipart path はこうです。
bashcurl -s -X POST "https://api.openai.com/v1/images/edits" \ -H "Authorization: Bearer $OPENAI_API_KEY" \ -F "model=gpt-image-1.5" \ -F "mask=@mask.png" \ -F "image[]=@sunlit_lounge.png" \ -F 'prompt=A sunlit indoor lounge area with a pool containing a flamingo'
この route が強いのは、failure surface が小さいからです。問題が account access なのか、mask validity なのか、prompt scope なのか、output handling なのかをすぐ切り分けられます。最初の成功条件を simple に保つことが、この query では本当に大事です。
もう一つ current な point として、/v1/images/edits は multipart-only ではありません。JSON で image_url や file_id を使う path もあり、assets を先にアップロードしていても direct Images API を保てます。つまり「files are already uploaded だから Responses へ」という理由は以前より弱くなっています。
API が本当に受け取れる mask を先に作る
この keyword で最もよくある wasted effort は、mask が invalid なのに prompt を調整し続けることです。current mask requirements は短いですが、どれも hard requirement です。
- base image と mask は同じ format
- base image と mask は同じ pixel dimensions
- payload は**
50 MB未満** - mask にはalpha channel が必要
ここで一番見落とされやすいのが alpha です。見た目が黒白でも、実際には opaque な bitmap というケースはまだ多いです。OpenAI が black-and-white image から alpha を付ける例をわざわざ載せているのは、その混乱が今でも続いているからです。
ただし、mechanical validity と strict behavior は別です。ドキュメントは transparent area が replace region だと説明しながら、GPT Image masking は prompt-based で exact shape を完全には追わないことも書いています。つまり、valid mask であることと、strict local patch のように振る舞うことは同じではありません。
production での preflight はこの順番が安全です。
- export 前に base image と mask を同じ最終サイズに揃える
- mask は RGBA PNG として保存する
- changed region が本当に透明になっているか確認する
- mask はできるだけ narrow に保つ
さらに multi-image edit では current docs のもう一つの rule も重要です。mask が効くのは first input image です。first image は base scene として扱い、後ろの images は supplemental references と考えたほうが齟齬が少なくなります。
Prompt は「穴」ではなく final image 全体を書く
この query でいちばん価値が高い sentence は、current docs の「describe the full new image, not only the erased area」です。ここを外すと、mask が正しくても result は不安定になります。
GPT Image は単に hole を埋めるのではなく、新しい coherent final image を作ります。だから prompt には少なくとも次の三つが必要です。
- 何を変えるか
- 何を保つか
- 最終的な scene がどう見えるべきか
弱い prompt:
textPut a flamingo in the pool.
より強い prompt:
textA sunlit indoor lounge area with a pool containing a flamingo. Preserve the pink room walls, the pool tile pattern, the reflections, the furniture, and the camera angle. Do not redesign the rest of the room.
label や logo のような preservation-heavy job なら、constraint はもっと具体的に書く必要があります。
textReplace only the blank label area on the bottle with a clean gold logo. Preserve the bottle shape, cap, glass reflections, lighting, shadows, background, and camera framing. Do not change any other packaging detail.
この考え方は GPT Image 1.5 prompting guide の方が third-party tutorials よりうまく言語化しています。要点は「一回で全部載せる」ことではなく、「change list と preserve list を明示し、次の turn では single-change iteration を行う」ことです。
output がすでに近いなら、次の prompt は短くていいです。「keep everything the same, but enlarge the logo slightly」のように one-variable correction にしたほうが drift を抑えやすくなります。
いつ input_fidelity=high が本当に効くのか
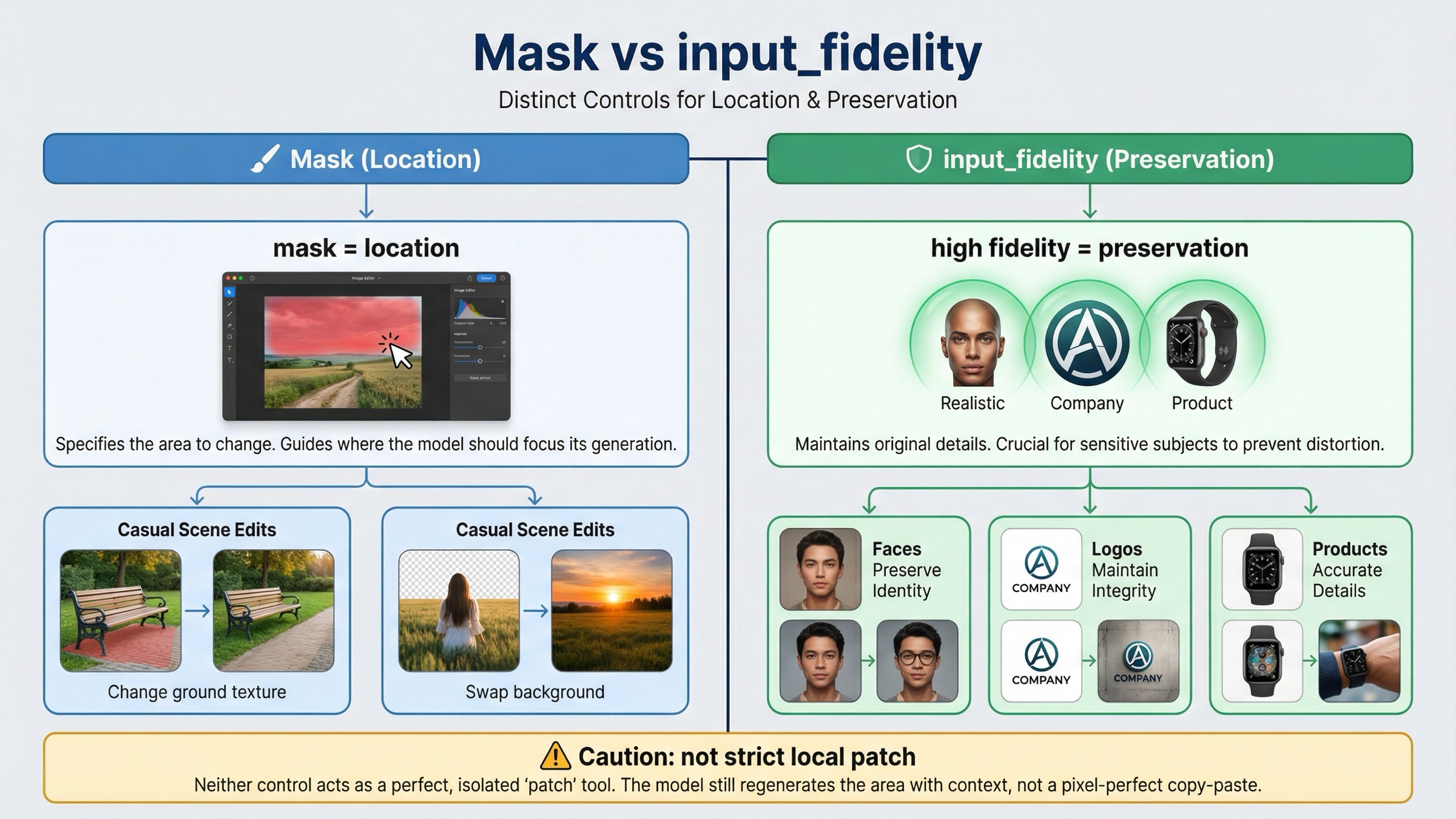
Mask と input_fidelity は役割が違います。Mask は location、input_fidelity は preservation strength です。この split を分けて理解できるかどうかで、debugging の速さがかなり変わります。
current input fidelity section は、faces や logos の preservation に high が有効だと明示しています。gpt-image-1 と gpt-image-1-mini では first input image がより強く preserve され、gpt-image-1.5 では最初の 5 枚までが higher fidelity の対象です。default は low です。
使い分けは次の表で十分です。
| Situation | mask だけで足りることが多いか | input_fidelity="high" を足すべきか | 理由 |
|---|---|---|---|
| casual scene の simple object replacement | 多くは yes | 通常は no | location の問題が大きく、high preservation のコストに見合わない |
| face 付近の edit | case by case | 多くは yes | identity drift の代償が大きい |
| logo を clothing / packaging / signage に載せる | rare | yes | mask は位置しか教えず、logo の preservation は別問題 |
| branded product hero shot | rare | yes | geometry、reflections、recognizability の維持が重要 |
| strict local patch を期待する | no | high でも十分ではない | fidelity は助けになるが deterministic surgery にはならない |
つまり、「mask は正しいのに face や logo が drift する」は preservation problem です。high は image input token cost を押し上げるので blanket default にする必要はありませんが、drift のコストが高い workflow では prompt をいじるより先に検討する価値があります。
より広い routing judgment が必要なら OpenAI image generation API models も役立ちますが、この query では mask = 位置、fidelity = 保持圧力 と覚えておけば十分です。
なぜ masked edit は予想以上に広く書き換えるのか
OpenAI docs はこの点でかなり正直です。mask section は transparent region を replace area と説明しつつ、GPT Image masking は exact shape を完全には追わないと明記しています。これを practical rule に直すと、current masked edit は constrained semantic rewrite であって、strict layer patch ではない ということです。
コミュニティでは 2025年4月27日 ごろから、valid mask でも scene が広く書き換わる complaint が続いています。ここで大事なのは、「API が壊れている」と早合点しないことです。多くの場合、期待している behavior のほうが current model の edit behavior より厳しすぎます。
overreach の主な原因は次の四つです。
- prompt が inserted object だけを説明し、残りの scene を underspecify している
- face、logo、packaging などの high-salience details に対して
input_fidelity="high"を使っていない - masked area が広く、周辺 context の再解釈が必要になっている
- 期待が old-style inpainting に寄りすぎている
fix は「mask をやめる」ことではありません。期待を current model に合わせ、workflow を調整することです。
- 可能なら edit scope を狭める
- preserve list を prompt に明示する
- preservation-sensitive な job だけ high fidelity を使う
- truly local reliability が必要なら crop / segmentation を先に入れる
product requirement が「ここ以外は絶対に変えるな」なら、それは prompt tuning だけの問題ではなく、workflow design の問題です。ここを早く見抜けるかどうかが、この topic の本質です。
Images API vs Responses for mask-heavy workflow
Responses は useful ですが、多くの mask-first workflow では早すぎます。current image generation guide と tool options を合わせて読むと、gpt-image-1.5 や chatgpt-image-latest を Responses で使う場合、action を auto / generate / edit から選べて、OpenAI は default の auto を推奨しています。
このヒントから、route split はかなり明快になります。
- single edit request で完結するなら direct Images API
- multi-turn context や broader assistant chain の一部なら Responses
- stored files を再利用したいだけなら JSON
/v1/images/editsでも足りることがある
つまり、「assets are already uploaded」だけでは Responses へ移る理由になりにくくなりました。より大きい orchestration が product 上必要かどうかが本当の判断軸です。
より広い surface comparison が必要なら OpenAI Image API チュートリアル を読む価値があります。でも exact mask query に対する答えはやはり、最短の direct route から始める です。
Troubleshooting: mask がまだ壊れる、あるいは広く効きすぎる理由
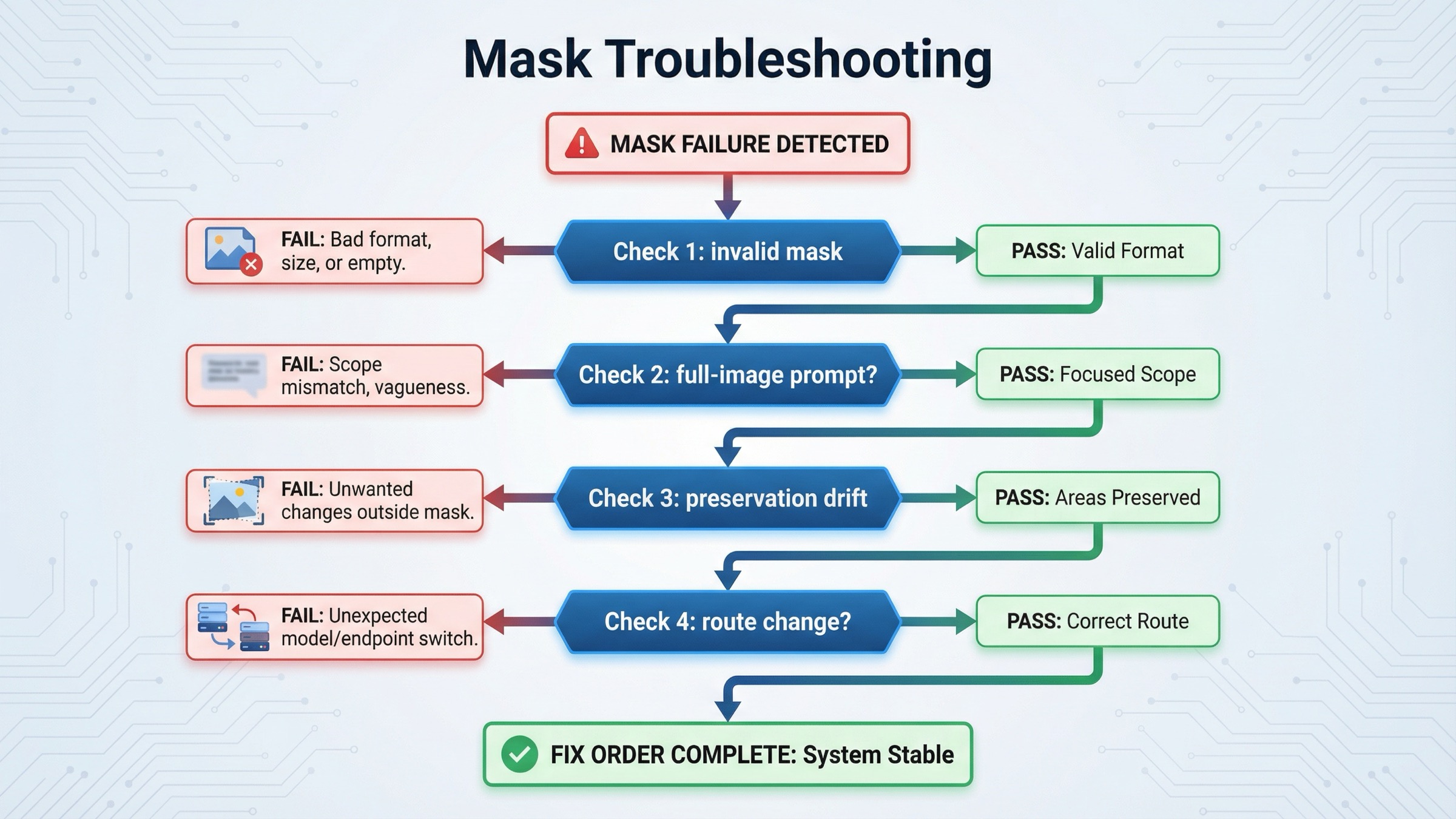
いちばん時間を無駄にしない diagnosis order は次の通りです。
-
API が mask を拒否する、あるいは無視しているように見える。
まず format、dimensions、payload size、alpha を確認する。ここが通っていない段階で prompt を触っても意味がありません。 -
編集位置はだいたい合っているが、scene 全体も変わる。
prompt が change だけを述べて preserved scene を弱くしか説明していない可能性が高いです。full final-image description に書き換え、preserve list を追加します。 -
変更が mask を越えて spill する。
GPT Image では珍しくありません。mask を狭め、1 回の変更量を減らし、preserve wording を具体化します。 -
face、logo、branded product が still drift する。
これは location ではなく preservation の問題です。input_fidelity="high"を使い、must-keep details を prompt に明記します。 -
複数回の iteration と stored asset references が必要。
この段階になってから Responses や JSON/v1/images/editsを検討すれば十分です。 -
本当に pixel-local reliability が必要。
期待値そのものが current model boundary を超えていないかを確認します。超えているなら crop、segmentation、preprocessing が本当の fix です。
この triage order を最初から持っていることが、この page を generic edit tutorials と分ける value です。多くの pages は一部しか説明しませんが、読者が実際に必要なのは一連の判断順序です。
FAQ
transparent な mask area なら、その exact pixels だけが変わるのですか。
いいえ。current docs は transparent region が replace area だと説明しますが、GPT Image masking は prompt-based で exact shape への完全追従は保証していません。strict local surgery ではなく、constrained rewrite と考えるべきです。
mask edits は images.edit() より Responses で始めるべきですか。
default ではありません。one-shot edits は direct Images API が先です。Responses は multi-turn conversation や broader assistant workflow の inside に edit が入るときに使います。
mask が正しいのに logo や face が drift するのはなぜですか。
Mask は location の control であって preservation の control ではないからです。そういう case こそ input_fidelity="high" と explicit preserve instructions を先に試すべきです。
最後の recommendation
current OpenAI mask edits の default route はシンプルです。gpt-image-1.5 の direct Images API で始め、mask の mechanical validity を先に固め、prompt を final image 全体として書き、preservation が重要なときだけ input_fidelity="high" を足す。 これが、より大きい framework から入るよりも多くの real-world failures を解決します。
それでも結果が期待より広く変わるなら、まず mask upload failure を疑うのではなく、product expectation のほうが current GPT Image masking behavior より厳しすぎないかを見直してください。より広い edit route は OpenAI image editing API guide、rollout 前の access / capability checks は OpenAI image generation API verification guide が次の一歩です。