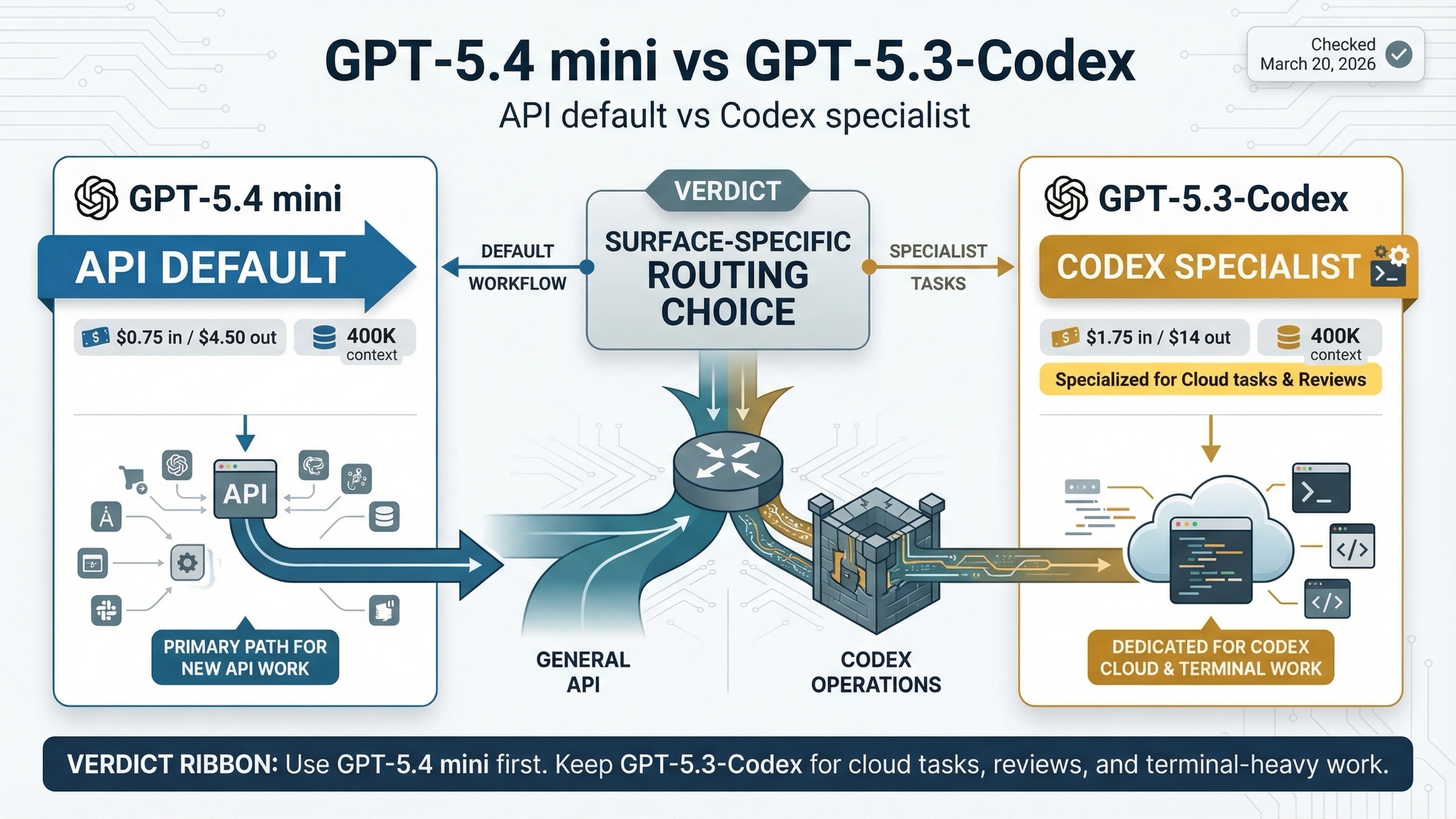
新しい API や subagent work には GPT-5.4 mini を使うべきです。code review、terminal work、より深い coding behavior が small-model の price efficiency より重要な、重い specialist coding を Codex 内で回すなら GPT-5.3-Codex を残してください。
この比較は surface を分けて初めて明確になります。API では GPT-5.4 mini が多くの高ボリューム coding workflow における cheaper newer default です。一方 Codex-style environment では、GPT-5.3-Codex がまだ stronger specialist coding posture を持っています。
要点まとめ
最短で言うと、新しい API coding や subagent は GPT-5.4 mini、Codex の cloud tasks・reviews・terminal-heavy coding は GPT-5.3-Codex です。
| モデル | 向いている用途 | 選ぶ主な理由 | 選ばない主な理由 |
|---|---|---|---|
| GPT-5.4 mini | 新しい API coding worker、安価な subagent、スクリーンショットを使う worker、Codex のローカル日常作業 | API で安く、ツール面が広く、現在の推奨 mini ライン | specialist coding ベンチマークでは GPT-5.3-Codex に劣り、Codex cloud tasks と reviews をまだ持たない |
| GPT-5.3-Codex | terminal-heavy coding、Codex cloud tasks、Codex code reviews、深い coding loop | SWE-Bench Pro と Terminal-Bench の profile が強く、Codex product slot が広い | API でかなり高価で、small-model default ではなくなった |
判断ルールを短くすると次のとおりです。
- 新しい API coding workflow を作るなら、まず GPT-5.4 mini を試す。
- Codex で cloud tasks や GitHub code reviews を使うなら、GPT-5.3-Codex を残す。
- terminal-heavy な engineering loop では GPT-5.3-Codex がまだ有力。
- ChatGPT 上の表示名だけで API / Codex の選択を決めない。
GPT-5.4 mini と GPT-5.3-Codex は何が本当に違うのか
この比較で最もよくある誤解は、GPT-5.4 mini を「GPT-5.3-Codex の安い小型版」と見ることです。実際にはそう単純ではありません。
現在の official model pages では、両者にはかなり近い top-level spec があります。
- 400K context window
- 128K max output
- knowledge cutoff は 2025-08-31
- text / image input 対応
このため、カードだけ流し読みすると似たモデルに見えます。ですが選定を決めるのは spec card ではなく product role です。
OpenAI の Using GPT-5.4 guide では、gpt-5.4-mini が high-volume coding、computer use、agent workflows の推奨小型モデルとして置かれています。つまり現在の mini default です。
一方、GPT-5.3-Codex model page は、このモデルを the most capable agentic coding model to date と説明し、Codex or similar environments に最適化された specialist として位置付けています。
実務上は、次のように覚えるのが一番分かりやすいです。
| 問い | 向いているモデル |
|---|---|
| 現在の API default を small model で組みたい | GPT-5.4 mini |
| より深い specialist coding lane が必要 | GPT-5.3-Codex |
| Codex cloud tasks / reviews が必要 | GPT-5.3-Codex |
| 安いローカル routine work や subagent を回したい | GPT-5.4 mini |
つまり、これは「一方が他方を完全に置き換える話」ではなく、API の default lane と Codex の specialist lane をどう分けるかの話です。
実務で効くベンチマーク差分

OpenAI は両モデルを同一表で直接比較していませんが、それぞれの launch post だけで十分に実務的な差は見えます。
2026年3月17日の公式 GPT-5.4 mini and nano による GPT-5.4 mini の値は:
- 54.4% SWE-Bench Pro
- 60.0% Terminal-Bench 2.0
- 72.1% OSWorld-Verified
2026年2月5日の公式 GPT-5.3-Codex による GPT-5.3-Codex の値は:
- 56.8% SWE-Bench Pro
- 77.3% Terminal-Bench 2.0
- 64.7% OSWorld-Verified
並べると見えてくるパターンはかなり明確です。
| ベンチマーク | GPT-5.4 mini | GPT-5.3-Codex | 実務での読み方 |
|---|---|---|---|
| SWE-Bench Pro | 54.4% | 56.8% | GPT-5.3-Codex のほうが specialist coding profile は強い |
| Terminal-Bench 2.0 | 60.0% | 77.3% | terminal-heavy engineering では GPT-5.3-Codex がかなり強い |
| OSWorld-Verified | 72.1% | 64.7% | screenshot-grounded、computer-use-like work は GPT-5.4 mini が強い |
重要なのは、「どちらが何行勝ったか」ではなく、どの種類の仕事で勝っているか です。
もし日々の仕事が shell 操作、repo-local debugging、CLI 自動化、build/test loop に近いなら、GPT-5.3-Codex の優位は小さな差ではありません。特に Terminal-Bench の gap は、terminal-first の人にとって無視しにくいレベルです。
逆に、ワークフローがスクリーンショット解釈、広めの tool use、orchestrator 配下の安価な subagent、computer-use に近い処理を含むなら、GPT-5.4 mini のほうが自然です。OSWorld の優位は、その方向に GPT-5.4 line がチューニングされていることを示しています。
要するに、ベンチマークの結論はこうです。
- GPT-5.3-Codex は深い coding specialist lane を取る
- GPT-5.4 mini は安くて新しい mini lane と computer-use fit を取る
もし small models の比較ではなく、いっそ flagship を見るべきか迷っているなら、関連する GPT-5.4 vs GPT-5.3-Codex も参考になります。
API 価格、ツール対応、レート制限
API 観点では、価格差が recommendation をかなり実務的なものにします。
2026年3月20日時点で確認した official pages では:
| 項目 | GPT-5.4 mini | GPT-5.3-Codex |
|---|---|---|
| Input price | $0.75 / 1M tokens | $1.75 / 1M tokens |
| Cached input | $0.075 / 1M tokens | $0.175 / 1M tokens |
| Output price | $4.50 / 1M tokens | $14.00 / 1M tokens |
| Context window | 400K | 400K |
| Max output | 128K | 128K |
| Knowledge cutoff | 2025-08-31 | 2025-08-31 |
つまり GPT-5.3-Codex は API で budget option ではありません。むしろ GPT-5.4 mini のほうが明確に安い です。
- input は半分以下
- cached input も半分以下
- output は 3 分の 1 未満
純粋に API routing を考えるだけなら、GPT-5.3-Codex を first test にする理由はかなり弱くなります。
ツール面も GPT-5.4 mini 側が広いです。現在の GPT-5.4 mini page では次がサポートされています。
- web search
- file search
- image generation
- code interpreter
- hosted shell
- apply patch
- skills
- computer use
- MCP
- tool search
対して GPT-5.3-Codex page は、structured outputs や function calling を含む一方で、GPT-5.4 mini のような広い current Responses tool matrix を前面には出していません。
rate limits でも GPT-5.4 mini は不利ではありません。
| Tier | GPT-5.4 mini TPM | GPT-5.3-Codex TPM |
|---|---|---|
| Tier 1 | 500,000 | 500,000 |
| Tier 2 | 2,000,000 | 1,000,000 |
| Tier 3 | 4,000,000 | 2,000,000 |
| Tier 4 | 10,000,000 | 4,000,000 |
| Tier 5 | 180,000,000 | 40,000,000 |
なので API 側だけを見るなら、結論はかなりシンプルです。specialist coding edge が価格差と tool gap を上回るとはっきり言える場合を除き、まず GPT-5.4 mini を default にする のが妥当です。
mini 系の別比較も必要なら、GPT-5.4 mini vs GPT-5 mini もあわせて見ると整理しやすいです。
Codex に入ると結論が変わる理由
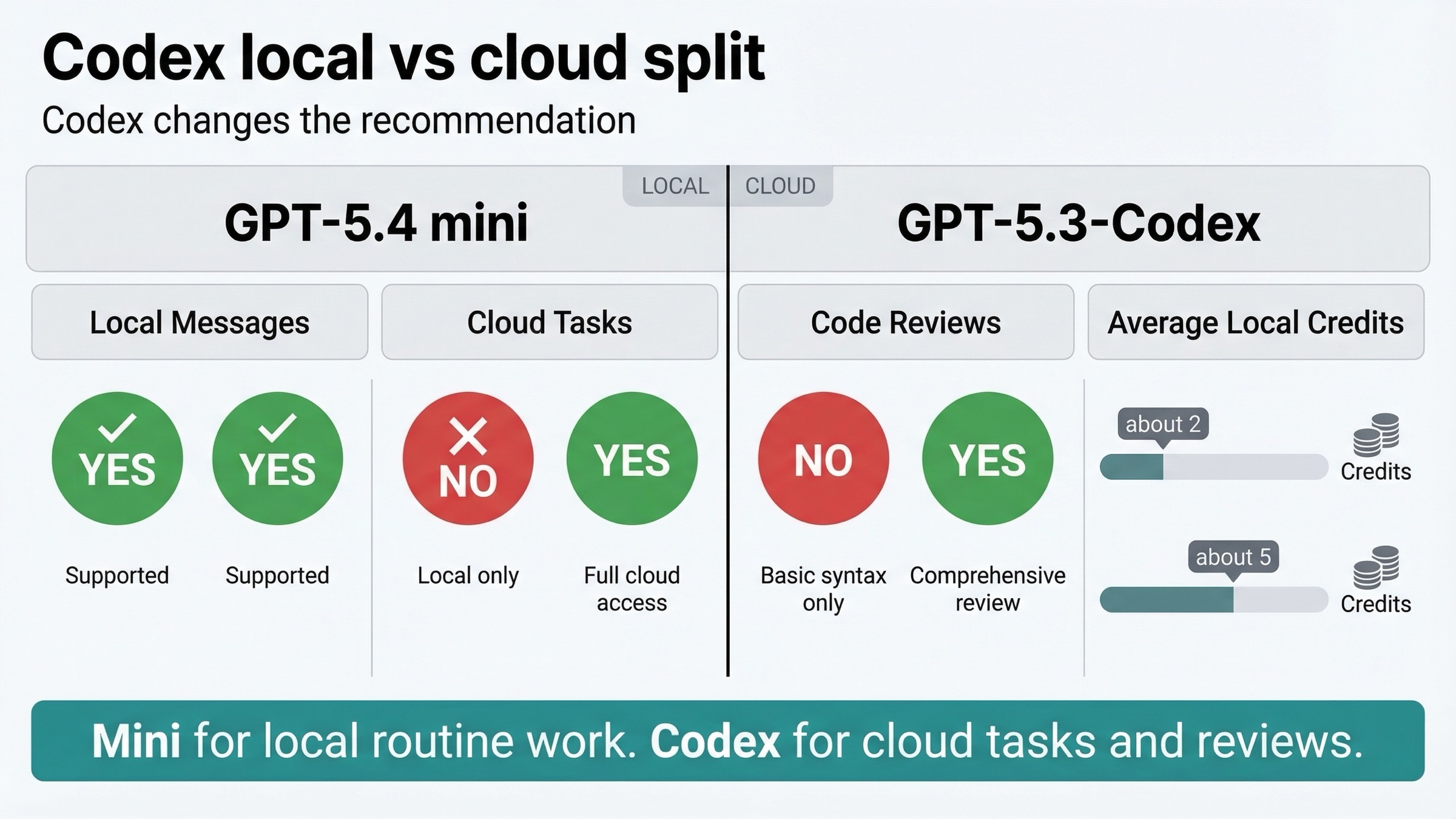
この比較で本当に重要なのはここです。
Codex の中では、GPT-5.4 mini は GPT-5.3-Codex の完全な代替ではありません。
現在の Codex pricing page では:
- GPT-5.4 mini は 最大 3.3x 高い local-message limits
- GPT-5.4 mini の平均ローカルタスクは約 2 credits
- GPT-5.3-Codex の平均ローカルタスクは約 5 credits
このため GPT-5.4 mini は次の用途に非常に向いています。
- Codex の routine local work
- 小さくて安い日常編集
- file read / file edit の高頻度作業
- local quota を長持ちさせたい supporting work
ただし同じページには重要な caveat があります。
| Codex capability | GPT-5.4 mini | GPT-5.3-Codex |
|---|---|---|
| Local messages | Yes | Yes |
| Cloud tasks | No | Yes |
| Code reviews | No | Yes |
つまり Codex では recommendation が二分されます。
- ローカル routine work は GPT-5.4 mini
- cloud tasks と reviews は GPT-5.3-Codex
この product split を見落として「GPT-5.4 mini が安いから全部置き換える」と考えると、実際の運用ではすぐ破綻します。
2026年3月の Reddit などで見えた混乱の多くは、plan や surface ごとの availability 変動に対する反応でした。ですが、それは durable product fact を変えません。現時点で GPT-5.4 mini と GPT-5.3-Codex は Codex 内で違う仕事をしている のです。
どの workflow でどちらを使うべきか
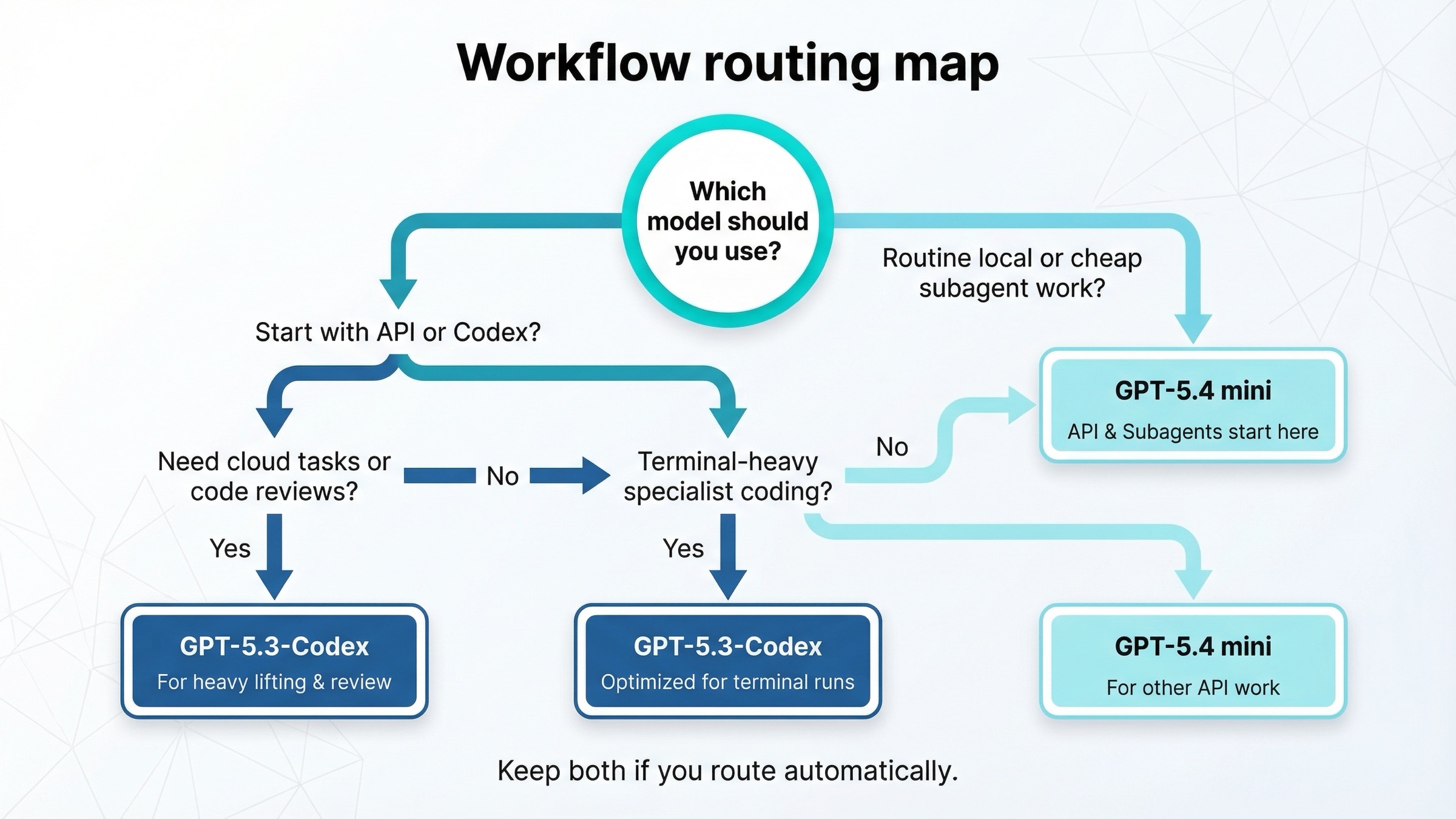
運用ルールとしては、次の表が最も使いやすいです。
| Workflow | GPT-5.4 mini | GPT-5.3-Codex | 理由 |
|---|---|---|---|
| 新しい API coding worker | Yes | Rarely | 安く、広い tool support を持ち、current default に近い |
| 大きな planner 配下の cheap subagent | Yes | Rarely | OpenAI がまさに mini の役割として説明している |
| screenshot-heavy / computer-use-like worker | Yes | Sometimes | OSWorld と tool posture が強い |
| terminal-heavy engineering | Sometimes | Yes | Terminal-Bench の差が大きい |
| Codex の local routine work | Yes | Sometimes | local quota と credit efficiency が良い |
| Codex cloud tasks | No | Yes | 現在の product slot が GPT-5.3-Codex |
| Codex GitHub code reviews | No | Yes | 現在の product slot が GPT-5.3-Codex |
| 深い specialist coding loop | Sometimes | Yes | 依然として specialist choice |
典型的な API チームなら、答えはかなり簡単です。まず GPT-5.4 mini を default にして、terminal-heavy か specialist coding だけ GPT-5.3-Codex にルーティングする のが良いでしょう。
典型的な Codex ヘビーユーザーなら、実際には 両方持つ のが最も自然です。
- GPT-5.4 mini を cheap local work に使う
- GPT-5.3-Codex を cloud tasks、reviews、難しい coding lane に使う
新しいから全部 5.4 mini、specialist だから全部 Codex、という二者択一より、このほうがはるかに健全です。
それでも GPT-5.3-Codex を残すべきケース
多くの比較記事は「GPT-5.4 mini は新しい。だからそれを使えばいい」で終わります。短くは済みますが、実務には足りません。
GPT-5.3-Codex が今でも意味を持つのは主に四つのケースです。
第一に、terminal-heavy work。shell operations、repo-local debugging、CLI 中心の開発では、GPT-5.3-Codex の benchmark profile がまだ最も説得力があります。
第二に、Codex cloud workflows。これが最も明快です。cloud tasks が必要なら、GPT-5.3-Codex を残すしかありません。
第三に、Codex code reviews。GitHub review flow が重要なチームでは、この一点だけで残す理由になります。
第四に、fallback routing。一つの永久勝者を探すのではなく、
- mini first を cheap current work に当てる
- Codex second を specialist coding と Codex cloud surfaces に当てる
という二段構えのほうが、現実の routing design としては強いです。
もし Codex 系モデルを他社 specialist coding モデルと比べた感触まで見たいなら、英語版の GPT-5.3 Codex vs Claude Opus 4.6 も参考になります。
FAQ
GPT-5.4 mini は coding 全般で GPT-5.3-Codex より上ですか。
完全にはそうではありません。公式値では GPT-5.3-Codex のほうが SWE-Bench Pro と Terminal-Bench 2.0 で強いです。一方で GPT-5.4 mini は API 価格が安く、現在の推奨 small model であり、computer-use-adjacent work に向いています。
なぜ coding benchmarks では GPT-5.3-Codex が強いのに、default recommendation は GPT-5.4 mini なのですか。
default recommendation は 1 行のベンチマークだけで決まりません。価格、tool support、rate limits、product direction、そして多くの coding system が実際には tool-and-agent system でもある、という運用現実で決まります。
Codex の中で GPT-5.4 mini は GPT-5.3-Codex を置き換えますか。
完全には置き換えません。少なくとも 2026年3月20日時点の Codex pricing page では、GPT-5.4 mini に cloud tasks と code reviews がありません。そこは GPT-5.3-Codex の仕事です。
新しいチームは最初にどちらを試すべきですか。
API なら GPT-5.4 mini を先に試すのが自然です。Codex-heavy なら GPT-5.4 mini を local routine work に、GPT-5.3-Codex を cloud-task / review workflow に当てる二本立てから始めるのが速いです。
最終的なおすすめ
チームに 1 行だけ持ち帰るなら、これで十分です。新しい API coding と subagent work は GPT-5.4 mini を default にし、Codex の cloud tasks、reviews、terminal-heavy engineering は GPT-5.3-Codex を残す。
この結論が単なる「新しい対古い」より強いのは、2026年3月の product reality にそのまま沿っているからです。
- GPT-5.4 mini は API で安く、default として置きやすい
- GPT-5.3-Codex は specialist coding profile をまだ保っている
- Codex の product behavior が、両者を today interchangeable ではなくしている
成熟した選び方は、片方を消すことではなく、両方を正しい lane に戻すことです。