
結論から言うと、ほとんどの開発者にとって標準モデルは GPT-5.4 です。 OpenAI は 2026年3月5日 に GPT-5.4 を公開し、GPT-5.3-Codex の先端的なコーディング能力を取り込みつつ、より広い用途を担う主力推論モデルとして位置付けました。つまり、コード生成だけでなく、長いコンテキスト、検索、ツール利用、パッチ適用、複数ステップのエージェント型作業を一つのモデルで回したいなら GPT-5.4 のほうが安全です。
ただし、それで GPT-5.3-Codex が不要になるわけではありません。GPT-5.3-Codex は 2026年2月5日 に公開され、今でも二つの明確な利点を保っています。ひとつは 入力トークン単価が安いこと、もうひとつは Terminal-Bench 2.0 で GPT-5.4 を上回っていることです。日常の作業がシェル、CLI、CI、ファイル操作、短中距離の修正に偏っているなら、GPT-5.3-Codex はまだ十分に意味のある専門ルートです。
この記事は 2026年3月19日 に確認した OpenAI の公式リリース、API モデルページ、価格ページをもとに書いています。コミュニティの障害報告は一時的な運用上の手がかりとして扱い、長期的な製品方針の証拠とは混同しません。ここで答えるべき本当の問いは、今日どちらを標準ルートにすべきかです。
要点まとめ
一文で言えば、標準は GPT-5.4、例外として GPT-5.3-Codex を残すのが最も実務的です。
| 項目 | GPT-5.4 | GPT-5.3-Codex | 実務的な見方 |
|---|---|---|---|
| リリース日 | 2026年3月5日 | 2026年2月5日 | GPT-5.4 のほうが新しく標準寄り |
| 製品の役割 | reasoning と coding をまとめた mainline model | coding 特化モデル | GPT-5.4 は広く、Codex は狭い |
| Input 価格 | $2.50 / 1M | $1.75 / 1M | GPT-5.3-Codex は入力コストで有利 |
| Output 価格 | $15 / 1M | $14 / 1M | 出力側の差は小さい |
| Cached input | $0.25 / 1M | $0.175 / 1M | 繰り返しコンテキストは Codex が安い |
| コンテキスト | 1,050,000 | 400,000 | GPT-5.4 は repo-scale で強い |
| Max output | 128,000 | 128,000 | ここは同等 |
| ツール面 | search、hosted shell、apply patch、MCP、computer use など | coding 中心の位置付け | GPT-5.4 が one-model default に向く |
| 明確な強み | GDPval、SWE-Bench Pro、OSWorld、Toolathlon、BrowseComp | Terminal-Bench 2.0 | 全体は GPT-5.4、狭い CLI は Codex |
| 向いている人 | 標準ルート、長文脈、mixed workflow | terminal-first、コスト重視 | 実務では両方持つのが最適なことも多い |
大事なのは、GPT-5.4 が「GPT-5.3-Codex の上位互換」と単純化できない点です。確かに default recommendation は GPT-5.4 に移りましたが、workflow の形によっては GPT-5.3-Codex を残したほうが合理的です。
GPT-5.4 で何が変わったのか

一番大きく変わったのは product positioning です。OpenAI の GPT-5.4 紹介ページ では、GPT-5.4 が GPT-5.3-Codex の frontier coding capabilities を取り込んだ最初の mainline reasoning model だと説明されています。この表現は単なる宣伝文句ではなく、OpenAI が今後の default route を GPT-5.4 に置きたいことを示しています。
一方で GPT-5.3-Codex の紹介ページ は coding-first の立ち位置を強調しています。速度、agentic coding、実際の software engineering task、Codex らしい使用感が中心です。だからこそ GPT-5.4 が出たあとでも、Codex には「terminal-heavy なときはまだこちらのほうが合う」という支持が残っています。
現在の OpenAI API モデル一覧 も同じ方向を示します。複雑な reasoning、coding、agentic tasks は GPT-5.4 から始めるよう案内し、GPT-5.3-Codex は coding-specialized option として残しています。これが重要なのは、ローンチ当日の勢いではなく、今この瞬間の product surface を反映しているからです。
さらに、2026年3月5日 の GPT-5.4 リリースページ は、表面ごとの違いもかなり具体的に書いています。GPT-5.4 Thinking はその日から ChatGPT Plus、Team、Pro にロールアウトされ、GPT-5.4 Pro は Pro と Enterprise に提供され、Codex の GPT-5.4 には 実験的な 1M コンテキスト対応 が入っています。同じページでは、Codex で標準の 272K コンテキスト を超えるリクエストは 通常の 2 倍の使用量 として扱われるとも明記されています。つまり、default recommendation はすでに GPT-5.4 に移った一方で、surface ごとの体感差が残るのも不自然ではありません。
したがって、正しい読み方はこうです。GPT-5.4 は GPT-5.3-Codex を default recommendation の位置から置き換えたが、すべての workflow で同じように置き換えたわけではない。 長文脈、ツール、検索、パッチ適用、複数ステップ reasoning が混ざるなら GPT-5.4。terminal-first で narrow なら GPT-5.3-Codex がまだ生きています。
SERP で混乱しやすいのは、ChatGPT の model picker、Codex surface、API catalog を同じものとして語る議論が多いからです。これらは関連していますが、更新速度も不具合の出方も同じではありません。比較記事はこの三つを分けて扱う必要があります。
ベンチマークを実務にどう読み替えるか
表の数字だけ見ても、実際にどちらを標準にするかは決まりません。重要なのは、どの数字がどんな workflow に効くかです。
| ベンチマーク | GPT-5.4 | GPT-5.3-Codex | 実務での意味 |
|---|---|---|---|
| GDPval | 83.0% | 70.9% | GPT-5.4 は曖昧で混合的なタスクに強い |
| SWE-Bench Pro | 57.7% | 56.8% | 難度の高い software engineering で GPT-5.4 がわずかに優位 |
| OSWorld-Verified | 75.0% | 74.0% | system 操作寄りのタスクでも GPT-5.4 が少し強い |
| Toolathlon | 54.6% | 51.9% | ツールを使う workflow では GPT-5.4 が有利 |
| BrowseComp | 82.7% | 77.3% | 調査、閲覧、根拠集めを含む仕事に GPT-5.4 が向く |
| Terminal-Bench 2.0 | 75.1% | 77.3% | CLI-heavy 作業では GPT-5.3-Codex が残る |
ここで見落としてはいけないのは、GPT-5.3-Codex が勝っている一項目が軽いニッチではないことです。Terminal-Bench は shell script、file ops、環境調整、terminal debugging のような実務にかなり近いベンチです。terminal が主戦場の人にとっては、この差は数字以上に重要です。
その一方で、日常業務が「コードを書く」だけで終わらないなら GPT-5.4 の優位が効いてきます。大きなコードベースの理解、仕様の整理、複数ツールの併用、根拠を伴う検索、長い文脈の維持といった場面では GPT-5.4 の総合点の高さがそのまま default value になります。
実務の判断に落とし込むなら次の二つです。
- 作業の大半が shell-first なら GPT-5.3-Codex を残す価値がある。
- 作業が mixed-task なら GPT-5.4 を標準にするほうが失敗しにくい。
もし Codex 系モデルを他社 flagship と比べた位置づけも知りたいなら、英語版の GPT-5.3 Codex vs Claude Opus 4.6 も参考になります。
価格、コンテキスト、ツール面の差

ベンチマークの次に重要なのは、どれだけ払うか、その支払いで何を得るかです。
| 項目 | GPT-5.4 | GPT-5.3-Codex | 重要な理由 |
|---|---|---|---|
| Input | $2.50 / 1M | $1.75 / 1M | prompt-heavy なら Codex のほうが安い |
| Cached input | $0.25 / 1M | $0.175 / 1M | 同じコンテキストを繰り返すと Codex が有利 |
| Output | $15 / 1M | $14 / 1M | ここだけで選ぶ差ではない |
| Context window | 1,050,000 | 400,000 | GPT-5.4 は大きい repo や長いセッションに強い |
| 長文脈の注意点 | 272K input 超で 2x input と 1.5x output | 同種の公開 multiplier なし | 大きいコンテキストは便利だが無料ではない |
| Tools | search、file search、image generation、code interpreter、hosted shell、apply patch、skills、MCP、computer use、tool search | coding-oriented positioning | GPT-5.4 は broader default として扱いやすい |
料金の話で一番大きいのは output ではなく input です。大量のコード、長い prompt、繰り返しのコンテキストを毎日送るなら、GPT-5.3-Codex の価格差は無視できません。逆に、1セッションの中で検索やツール利用、長文脈 reasoning まで含むなら、GPT-5.4 の追加コストはかなり説明しやすくなります。
コンテキストの差も単に「大きいほうが勝ち」ではありません。1.05M の上限は repo-scale の理解や長い会話では本当に便利ですが、272K input を超えるとセッション単価が上がります。つまり GPT-5.4 は「必要なときに大きく使える default」であって、何でも大きな prompt を投げるための free pass ではありません。
そして default choice を一番変えるのは tool surface です。今の coding work は、編集だけでなく、検索、パッチ、ファイル操作、外部情報の確認まで含みます。こうした mixed workflow を一つのモデルで受けたいなら GPT-5.4 のほうが自然です。GPT-5.3-Codex はそこでも使えますが、最初に置くモデルとしては狭くなっています。
ワークフロー別にどちらを選ぶべきか
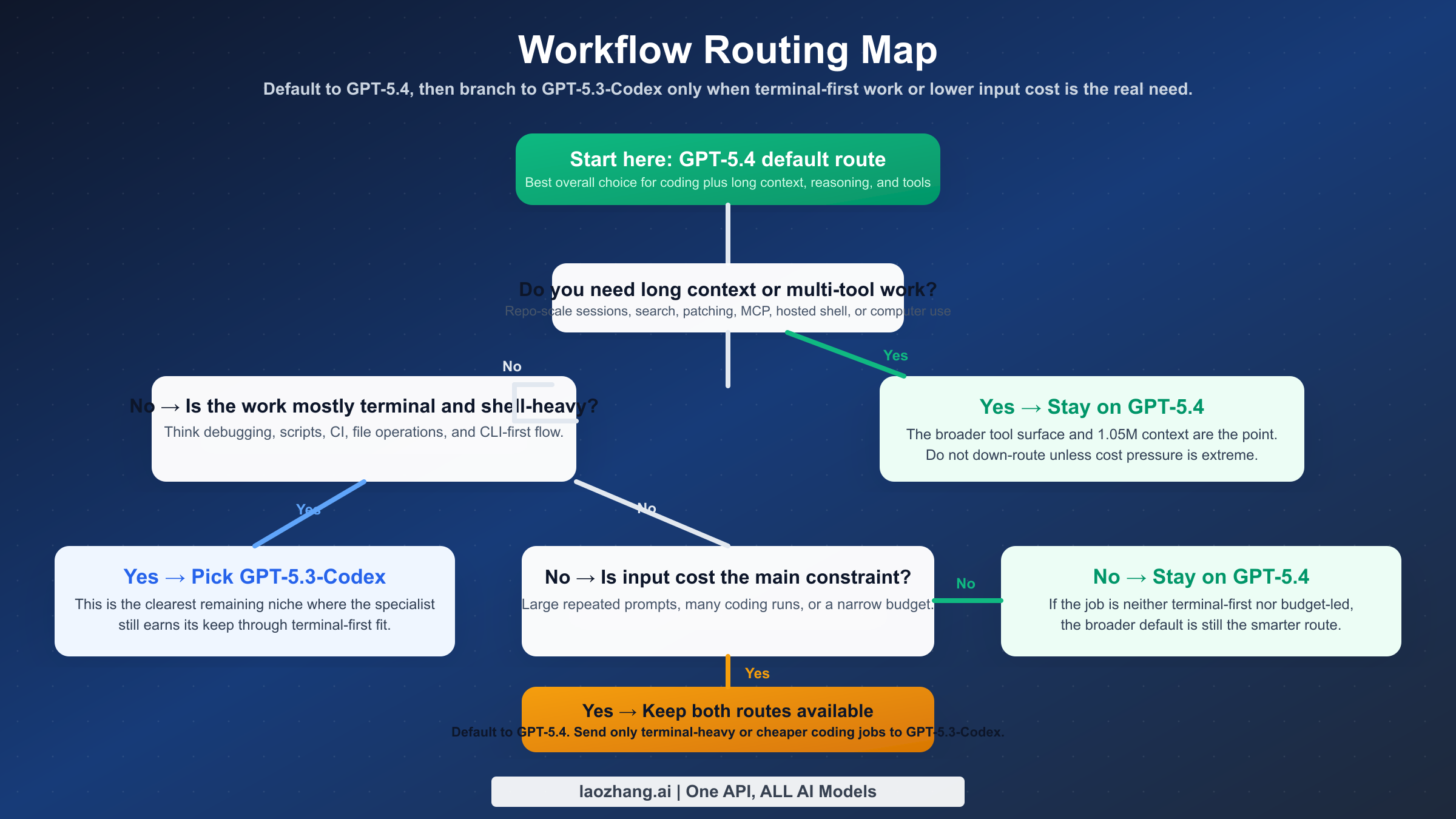
結局のところ、この比較で知りたいのは「どちらが強いか」ではなく「自分はどちらを default にすべきか」です。
| ワークフロー | GPT-5.4 を選ぶ | GPT-5.3-Codex を選ぶ | 理由 |
|---|---|---|---|
| チームの標準モデル | はい | いいえ | GPT-5.4 のほうが broader default に向く |
| terminal-first な engineering | 条件付き | はい | Codex は CLI-heavy にまだ強い |
| 長い repo 分析 | はい | まれ | 1.05M context の差が大きい |
| multi-tool agentic workflow | はい | まれ | GPT-5.4 は tool surface が広い |
| 入力コストを強く気にする coding | 条件付き | はい | input 単価差が効く |
| コード以外も混ざる仕事 | はい | いいえ | GPT-5.4 は one-model default に近い |
個人開発者や小規模チームなら、まず GPT-5.4 を標準にするのが無難です。モデルを事前に細かく振り分けなくても、長文脈、ツール、検索を含む仕事にそのまま対応しやすいからです。
platform、infra、DevOps 系なら判断はもう少し割れます。日々の仕事が shell script、CI、ログ確認、terminal debugging に偏っているなら GPT-5.3-Codex のほうが体感で合う場面が残ります。しかも input コストも低いので route として残しやすいです。
staff engineer、tech lead、アーキテクト寄りの役割なら GPT-5.4 を標準にするメリットが大きいです。なぜなら、そうした役割の仕事はほぼ必ず reasoning、比較、検索、長文脈、複数ステップの synthesis を含むからです。
自動 routing ができる環境なら、最適解は二者択一ではありません。GPT-5.4 を default にして、terminal-heavy または input-sensitive な job だけ GPT-5.3-Codex に送るのが現実的です。
それでも GPT-5.3-Codex を残すべき場面
「GPT-5.4 が Codex を吸収したのだから、Codex という型番はもう不要」と言いたくなる気持ちはわかります。ただ、その見方は engineering workflow の粒度では粗すぎます。
GPT-5.3-Codex を残す意味があるのは少なくとも四つの場面です。第一に terminal-first task。第二に 入力コストが厳しい場面。第三に 狭い coding workflow で、search や computer use を必要としない場合。第四に fallback route としてです。強い coding model を二本持っていること自体が routing の堅牢性になります。
2026年3月のコミュニティ報告で、GPT-5.4 と GPT-5.3-Codex の surface access が不安定になったという話題もありました。これは operational friction としては重要ですが、product direction を覆す証拠ではありません。比較記事ではここを混同しないほうが読者の判断に役立ちます。
したがって今の運用ルールはシンプルです。GPT-5.4 を主ルート、GPT-5.3-Codex を例外ルートにする。
GPT-5.3-Codex から GPT-5.4 へ移行するチェックリスト
Codex をいま default にしているなら、移行は一気に切り替えるより段階的なほうが安全です。
- 長文脈、複雑な reasoning、multi-tool task の default route を GPT-5.4 に切り替える。
- GPT-5.3-Codex は terminal-heavy debugging と安価な coding lane として残す。
- 272K input 超の GPT-5.4 セッションに対してコスト監視を入れる。
- 代表タスクを三つ再評価する。repo-scale の分析、terminal workflow、multi-tool workflow を一つずつ比較する。
- 一時的な access regression に備えた fallback rule を明文化する。
このやり方なら、OpenAI の現在の product direction に追従しつつ、Codex の narrow advantage も失いません。
FAQ
GPT-5.4 は GPT-5.3-Codex より完全に上ですか
いいえ。全体としては上ですが、terminal-heavy workflow と input コストでは GPT-5.3-Codex がまだ意味を持ちます。特に CLI 中心の仕事なら Codex の優位は実務的です。
GPT-5.4 の値上がりは見合いますか
多くの場合は見合います。長文脈、tool surface、mixed-task reasoning を本当に使うなら、追加コストは合理的です。ただし短い coding run と shell work だけなら、差額の意味は小さくなります。
Codex や API では GPT-5.4 が実質的な後継ですか
OpenAI の位置付けとしてははいです。ですが workflow の現場では、GPT-5.3-Codex を narrow specialist として残す余地があります。
最近のアクセス不具合は判断を変えますか
大きくは変えません。障害報告は運用上の注意点にはなりますが、モデル選定の中心にはしないほうが良いです。中心に置くべきなのは、公式のモデル仕様と、あなたの workflow が terminal-first か mixed-task かという違いです。