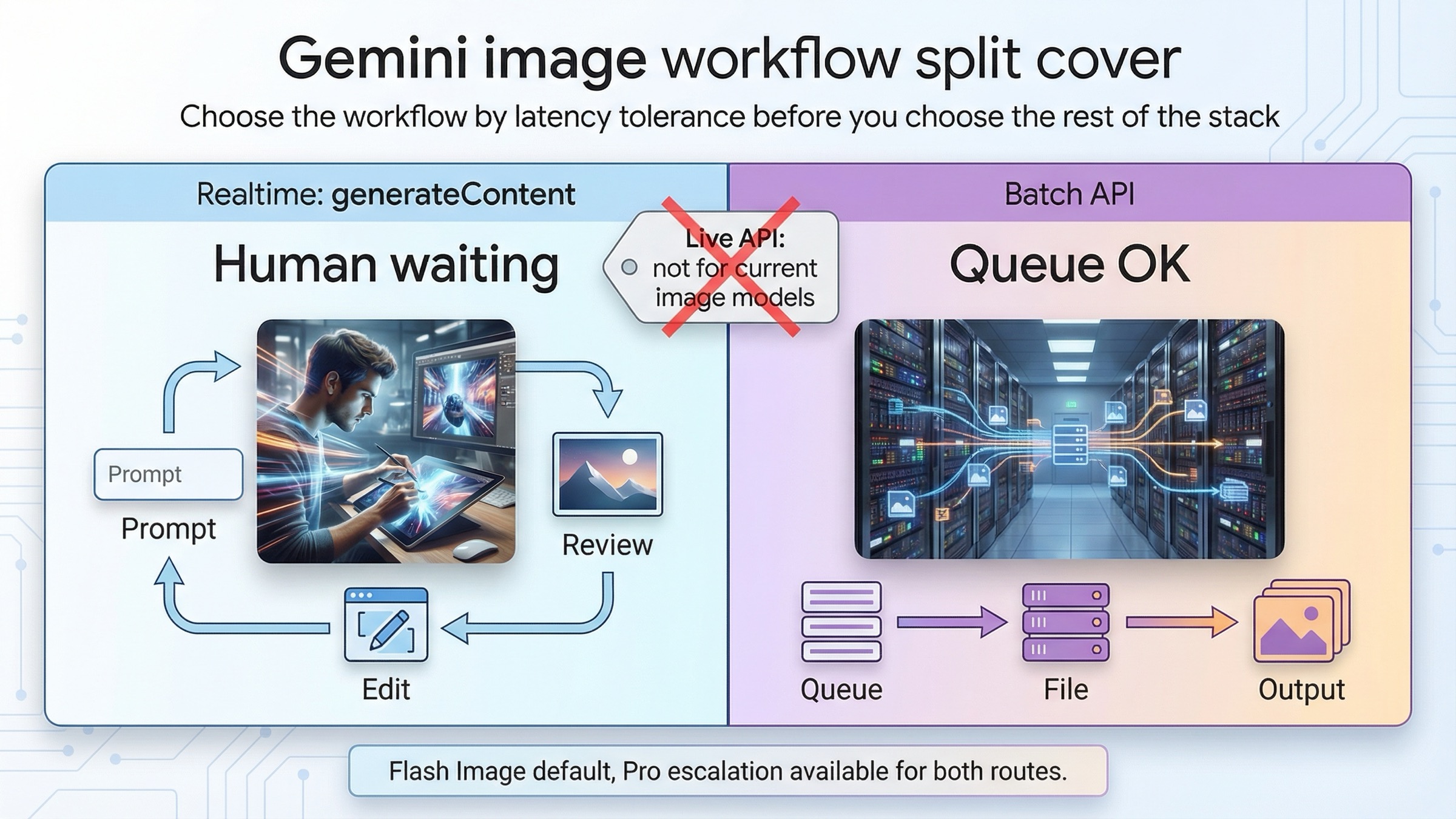
2026年3月23日時点で、Gemini画像生成の判断基準はかなり明快です。人が次の画像を今すぐ待っているなら同期generateContent、大量で急がない処理ならBatch APIです。 価格から入るより、まずこの分岐から入った方が失敗しません。いま必要なのが対話的な反復なのか、キューに積める安い大量処理なのかを先に決めれば、モデル選びやコスト計算はその後で整理できます。
最初にもう一つだけ誤解を外しておくべきです。現在のGemini画像モデルにおいて、リアルタイムはLive APIを意味しません。gemini-3.1-flash-image-preview と gemini-3-pro-image-preview のモデルページでは、どちらも Batch APIは対応、Live APIは非対応 と示されています。一方で、現在の画像生成ドキュメントは通常の同期generateContentとmulti-turn編集を中心に説明しています。つまり、このテーマでいうリアルタイムとはライブ画像ストリームではなく、通常のrequest-response型の画像生成と編集です。
この点が重要なのは、公式情報が間違っているからではなく、散らばっているからです。Batch APIの説明ページ、画像生成ガイド、pricingページ、モデル能力ページを別々に読むと、個々の事実は分かっても、実際のworkflow判断がぶれやすいです。必要なのは、事実の寄せ集めではなく、どう使い分けるかを一枚で理解できる実務的な整理です。
要点まとめ
まずは短い答えだけ見たいなら、この表で十分です。
| 質問 | 現時点の最適解 | 理由 |
|---|---|---|
| 人が画像や編集結果を待っている | 同期generateContent | 現在の公式image guideは、プロンプト調整とmulti-turn編集を同期前提で説明している |
| 量が多く、急がず、コストを下げたい | Batch API | Batch APIドキュメントでは 標準価格の50% と 24時間の目標ターンアラウンド が示されている |
| リアルタイムをLive APIのことだと思っている | その理解は現在の画像モデルには合わない | 現行の画像モデルページでは Live API非対応 |
| まず使うべき画像モデルは何か | gemini-3.1-flash-image-preview | 現在の高効率な標準レーンで、gemini-2.5-flash-image の置き換え先でもある |
| Proへ上げるべき場面はいつか | 文字、レイアウト、失敗コストが高いとき | gemini-3-pro-image-preview は文字入りビジュアルや高品質な成果物で強い |
| いちばん安い公式レーンは何か | gemini-2.5-flash-image | ただし 2026年10月2日 に終了予定のlegacyライン |
このテーマでいちばん多いミスは、安いからという理由だけでBatch APIを選ぶことです。割引自体は本物ですが、遅れて返ってくることがworkflowの価値を壊すなら意味がありません。プロンプトをまだ探っている段階、レビュー待ちがある段階、ユーザー向けUIの段階では、同期の方がほぼ確実に強いです。
3つだけ具体例を挙げるとこうなります。
- ユーザーが次の画像を待つプロダクト機能: 同期
- 同じ日にプロンプトを調整しながら進める社内クリエイティブ作業: まず同期、安定後にbatch
- 夜間に何千件も回すテンプレート生成: batch
コード寄りの話を見たいならGemini画像生成のコード例へ進む方が早いです。価格を掘りたいならGemini画像生成APIの価格ガイドが向いています。編集中心ならGeminiのimage-to-image編集の方が近いページです。
本当の分岐は同期generateContentとBatch API
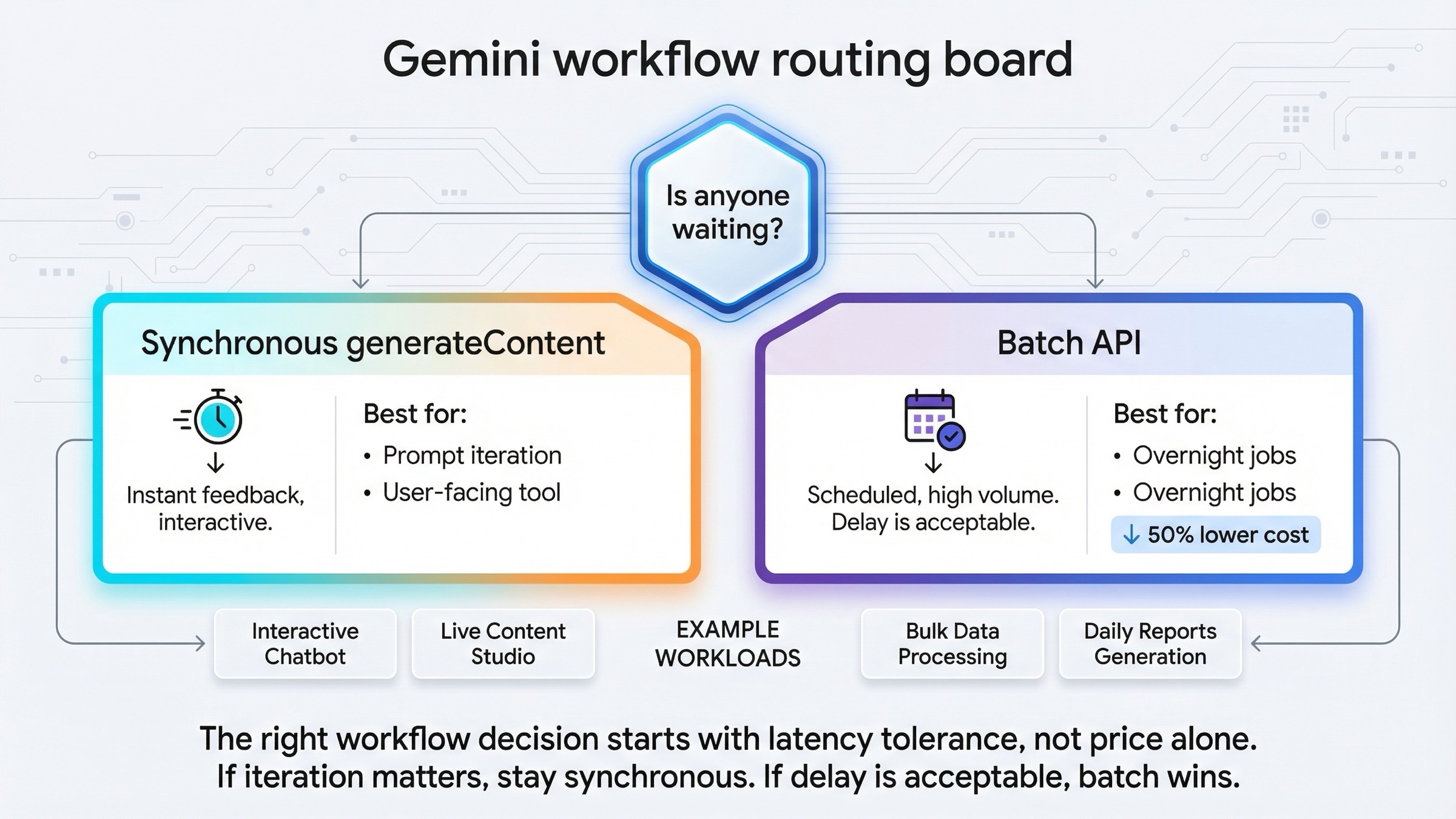
このクエリに来る人の多くは、技術的な質問をしているようで、実際には運用上の質問をしています。「batchかrealtimeか」と言いながら、本当に知りたいのは「この仕事は対話的なループで進めるべきか、それとも安全にキューへ渡せるか」です。
だから最初に聞くべきことは、価格でもモデル名でもありません。次の一問です。
いま結果を待っている人がいるか。
答えがYesなら同期を選ぶべきです。たとえば次のような仕事です。
- prompt探索
- ユーザー向け画像ツール
- 人間のレビューを含むループ
- 段階的な画像編集
- 最初の出力が弱かったときの即時リトライ
答えがNoならBatch APIが有力になります。たとえば次のような仕事です。
- 夜間の一括生成
- queue-drivenなasset pipeline
- 大量の商品バリエーション生成
- 急がないバックフィル
- すでに固まったpromptテンプレートの反復実行
Batch APIドキュメントでは、このトレードオフがかなり明快です。大量リクエスト向けの非同期surfaceであり、標準価格の50%、目標ターンアラウンド24時間 です。安く回せるのは大きな価値ですが、次の人間やシステムの動きが即時出力に依存しているなら、その安さは役に立ちません。
逆も同じです。同期生成は小さなテスト用の手段ではありません。価値が速い反復から生まれる仕事なら、同期が本筋です。現在の画像生成ドキュメントがgeneration、editing、multi-turn refinementを同期例で示しているのもそのためです。画像仕事では「一つのprompt、一つの結果、一つの修正、次のターン」という流れがいちばん学習効率が高いことが多いからです。
要するに、ルールはこうです。
- 対話的で、人がループにいて、プロダクトの体験に直結する仕事は同期
- キューに積めて、量が多く、急がず、単価最適化を狙う仕事はbatch
この発想にすると、よくある設計ミスも防げます。最終的にキューが必要になると分かっているからといって、最初からキューで始める必要はありません。多くの場合、まず同期でpromptと出力処理を固め、その後で安定したrequestだけをbatchへ逃がす方が速くて安全です。
どのGemini画像モデルを各workflowの裏に置くべきか
workflow choiceとmodel choiceは関連していますが、同じ問いではありません。Batchはモデルではなく、realtimeもモデルではありません。同じ画像モデルを、同期でもbatchでも使えます。
いま新しく始める仕事の多くでは、まず gemini-3.1-flash-image-preview を標準回答として置くのが妥当です。Googleはこれを高効率な画像レーンとして位置づけており、deprecationsページでも gemini-2.5-flash-image の置き換え先として扱っています。
| モデル | 2026年3月23日時点の位置づけ | Batch API | Live API | 価格シグナル | 向いている用途 |
|---|---|---|---|---|---|
gemini-3.1-flash-image-preview | 現在の標準preview | 対応 | 非対応 | $0.067 / 1K image、batchで $0.034 | 新規の大半のinteractive workflowとqueue workflow |
gemini-3-pro-image-preview | 現在のpremium preview | 対応 | 非対応 | $0.134 / 1Kまたは2K、batchで $0.067 | 文字の多い画像、diagram、仕上がり重視のasset |
gemini-2.5-flash-image | まだ使えるlegacyライン | 対応 | 非対応 | $0.039 standard、$0.0195 batch | いまの公式最安レーンが必要な場合 |
この表から重要なのは3点です。
1つ目は、現在のGemini画像モデルはBatch APIには対応しているがLive APIには対応していない ことです。つまり、このテーマをlive-session前提で考える必要はありません。
2つ目は、gemini-3.1-flash-image-preview が今のdefault answerだということ です。速さ、現行性、柔軟性のバランスがよく、同期でもbatchでも最初に置きやすいです。
3つ目は、最安と最適デフォルトは別の答えだということ です。gemini-2.5-flash-image は確かに安いですが、Googleは 2026年10月2日 の終了日も明示しています。新規構築でこのモデルを選ぶなら、それは中長期の標準解ではなく、意図的なlegacy節約策として選ぶべきです。モデル全体の立ち位置を比較したいなら、Nano Banana 2、Pro、Imagen 4の比較の方が向いています。
プロンプト調整と編集で最適なリアルタイムworkflow
人が結果を待っているなら、最適なworkflowはやはり同期generateContentです。backendでも、社内ツールでも、チャット型のproduct UIでも、この答えは変わりません。
理由は単純な速度だけではありません。反復の質です。
良いGemini画像生成は、たいてい次の短いサイクルで良くなります。
- 明確なpromptを送る
- 最初の画像を見る
- 一点だけ修正する
- 次のターンを送る
特にeditingではこれが顕著です。現在のimage generation docsはGemini画像作業を会話型・multi-turnで説明していますが、その理解は今でも正しいです。2回目の指示は、1回目の画像が何を外したかによって決まるからです。Batchではそこにたどり着くまでが遅すぎます。
新しいworkflowで最初に使うリクエストは、むしろ地味であるべきです。
javascriptimport { GoogleGenAI } from "@google/genai"; import * as fs from "node:fs"; const ai = new GoogleGenAI({ apiKey: process.env.GEMINI_API_KEY }); const response = await ai.models.generateContent({ model: "gemini-3.1-flash-image-preview", contents: "Create a clean 16:9 product hero image of a matte black coffee grinder on a soft gray background with premium ecommerce lighting.", config: { responseModalities: ["IMAGE"], imageConfig: { aspectRatio: "16:9", imageSize: "2K" } } }); for (const part of response.candidates[0].content.parts) { if (part.inlineData) { fs.writeFileSync("coffee-grinder.png", Buffer.from(part.inlineData.data, "base64")); } }
最初の一発で見栄えの良い作品を狙う必要はありません。やるべきことは、モデル指定、画像サイズ、response handlingが期待通り動くことを確認することです。そこが安定してからeditingやfollow-upへ進めば十分です。
同期ルートで効く習慣は2つあります。
- 単語を並べるより、場面を描写する
- 編集では「変えてよい部分」と「固定したい部分」を両方書く
Googleの古いprompt guideもこの点では今でも有効です。Geminiは、何を変えるかだけでなく、何を守るべきかを明示した方が安定します。だからinteractiveな画像仕事は、まず同期ルートで始めるのが合理的です。
AI Studioで先に試すのは問題ありません。ただし、そこをproduction contractと混同しないことです。Googleの 2026年2月26日 のNano Banana 2のdeveloper postでは、AI Studioでこのモデルを使うには paid API keyが必要 だと明記されています。AI Studioは学習には役立ちますが、最終的なworkflow設計そのものではありません。
キュー処理や夜間生成で最適なBatch workflow
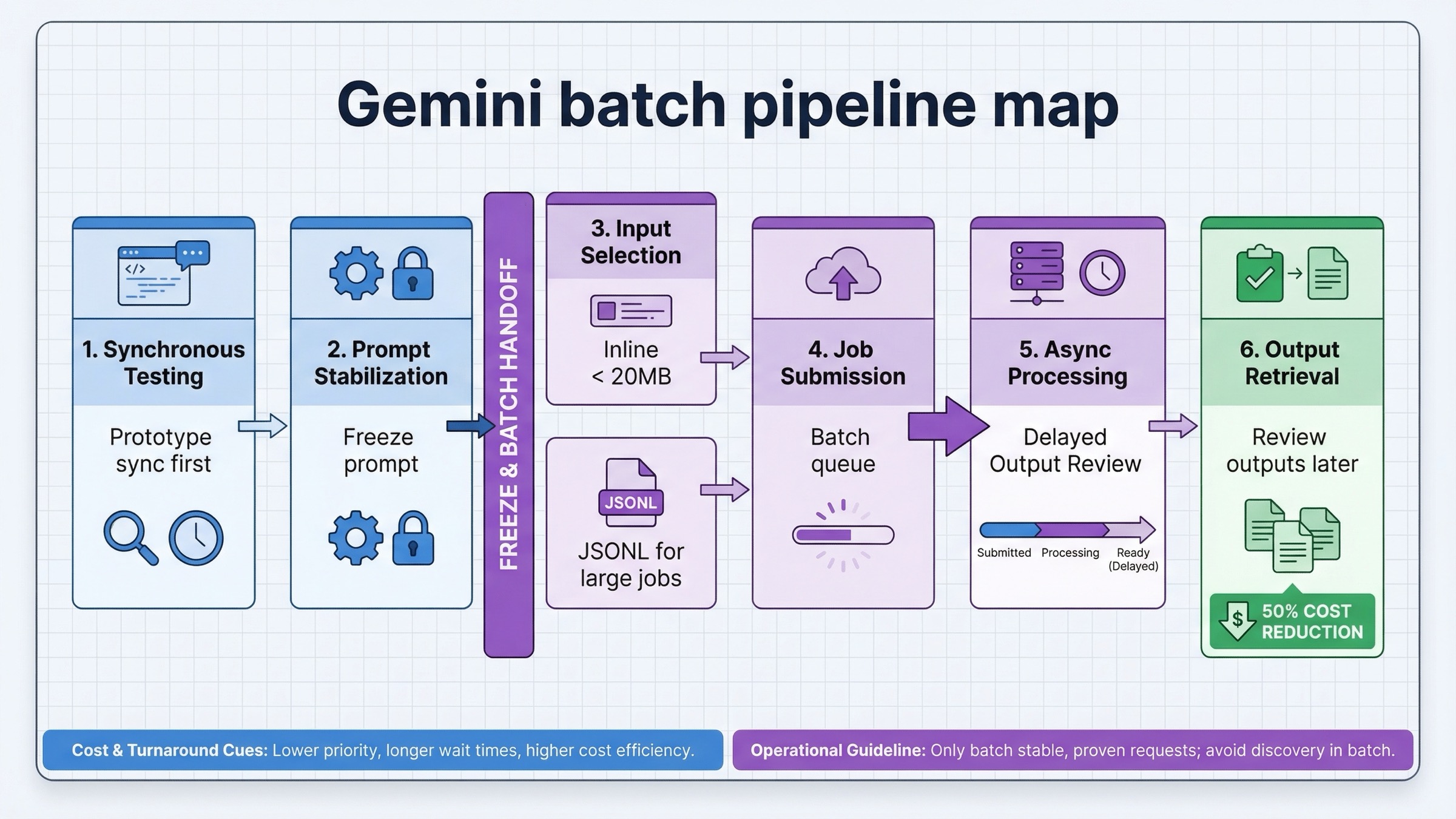
Batch APIが強いのは、仕事が本物で、量が多く、しかも急がないときです。実務ではだいたい次のどれかに当たります。
- 総コストを下げたい
- 一定のスループットでキューを流したい
- request受付と結果配布を分けたい
Googleの説明では、小さな仕事にはinline requests、大きな仕事にはJSONL file inputが推奨されています。画像生成では特に、fileベースの方が長い目で見て扱いやすいです。再実行、監査、差し替えがしやすいからです。
良いbatch workflowはだいたい次の順序になります。
- まず同期でpromptとパラメータを確定する
- request formatを固定する
- jobsをJSONLや小さなinline groupにする
- 待っても品質が上がらない段階でbatchに投げる
- 出力回収とretry判断は後段で行う
ここでのミスは、安いからといってbatchの中でprompt discoveryを始めることです。単価は下がっても、全体の学習速度は落ちます。prompt discoveryは対話的な仕事であり、batchは安定した反復のためのsurfaceです。
価格差は、requestが固まるとかなり大きく見えてきます。2026年3月23日 の価格で、gemini-3.1-flash-image-preview を 10,000 枚の1K画像で回すと、おおよそ $670 が通常価格、$340 がbatch価格です。gemini-3-pro-image-preview なら同じボリュームで $1,340 と $670 程度になります。だからこそ、承認済みテンプレートの大量生成、ローカライズ用の反復処理、scheduled generationではbatchの価値が大きいです。
ただしBatch APIは、単なる割引オプションではありません。運用面でも別surfaceです。rate limitsページでは 100 concurrent batch requests、2GBのinput file limit、20GBのfile storage、そしてモデルごとの enqueued tokens 管理が記載されています。つまり、通常の同期トラフィックが問題なくても、batch側だけ別の圧力に当たることがあります。
さらにrequestの形も重要です。公式にはpayload合計が 20MB 未満ならinline、それを超える大きな仕事はアップロード済みのJSONLが推奨されています。実運用では、後者の方が破綻しにくいことが多いです。
json{"key":"shoe-0001","request":{"contents":[{"parts":[{"text":"Create a clean white-background ecommerce image of a running shoe in side profile."}]}],"generation_config":{"response_modalities":["IMAGE"]}}} {"key":"shoe-0002","request":{"contents":[{"parts":[{"text":"Create a clean white-background ecommerce image of a black leather loafer in side profile."}]}],"generation_config":{"response_modalities":["IMAGE"]}}}
この例はわざとシンプルです。batch fileの役割は美しさではなく再現性です。JSONLへ落とし込む時点で、promptと設定はすでに同期側で十分に検証されているべきです。
現実的には、多くのチームにとって一番強いのはハイブリッド運用です。
- prompt設計、初回承認、editingは同期
generateContent - 安定した繰り返し仕事だけBatch APIへ移す
- 24時間ターンアラウンドを許容できる仕事だけbatchにする
この分離の方が、人間の判断が必要な部分と、安く大量に回せる部分をきれいに切り分けられます。
Proに上げるべきなのはworkflowではなくモデルの問題である場合
pricing tableだけ見ると、「FlashかBatchか」という二択に見えがちですが、実際にはそうではありません。workflowは同じままで、変えるべきなのがモデルであるケースがあります。
そこが gemini-3-pro-image-preview の出番です。
Proが合理的になるのは、失敗のコストがモデル差額を上回る場面です。たとえば次のようなケースです。
- 実際の文字が多いdiagramやinfographic
- 品質要求の高い広告素材や商品ビジュアル
- クライアント提出物のように失敗が高い仕事
- layoutやlabel accuracyが重要な可視化
- 仕上がりの一発目の精度を上げたい高価値出力
ここで大事なのは、workflowの答えはそのままでもよいということです。人が待っているならProでも同期、急がない大量出力ならProでもbatchという形がありえます。workflow choiceとmodel choiceは分けて考えた方が整理しやすいです。
実務的には次の4レーンに整理できます。
- Flash + 同期: ほとんどのinteractive画像仕事
- Flash + batch: 大量でコスト重視の安定処理
- Pro + 同期: 高品質が必要な対話的作業
- Pro + batch: 高価値だが急がない大量出力
つまり、先に決めるべきはworkflowで、後から決めるべきは失敗コストに見合うモデルです。
間違ったworkflowを選んでいるときの見分け方
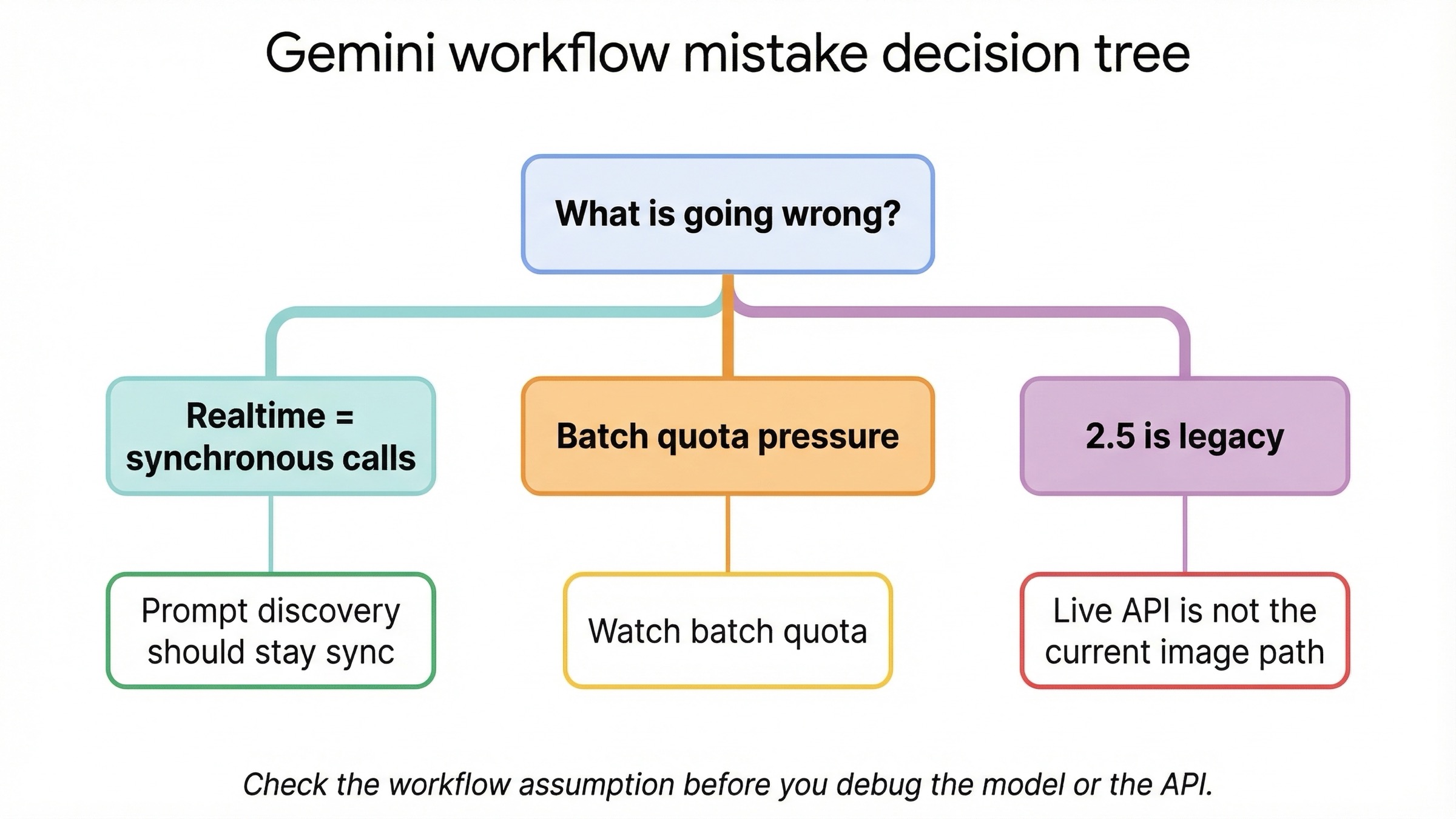
このテーマのトラブルの多くは、APIが壊れているのではなく、workflow選択が間違っていることから始まります。
realtimeという言葉を広く使いすぎている。 現在のGemini画像モデルでは、realtimeは通常の同期request-responseを指します。Live APIの画像出力ではありません。ここを曖昧にしたまま設計すると、最初から違う枝に入ります。
prompt discoveryの段階でbatchへ行っている。 割引があるからといって、学習フェーズをbatchに乗せるのは逆効果です。まず同期でpromptを固め、その後で大量処理に移すべきです。
workflowの問題とlifecycleの問題を混ぜている。 gemini-2.5-flash-image は安いですが、2026年10月2日 に終了予定です。これを選ぶなら「安いlegacyを短期活用する」という判断であって、新規構築のデフォルトではありません。
通常クォータだけ見て、batch固有の制約を見落としている。 batchには別のenqueued-token pressureがあります。監視もbatch専用の見方が必要です。
AI Studioをプロダクト全体の答えだと思っている。 AI Studioは試行には便利ですが、実アプリはAPI contract、model capabilities、pricingの上で動きます。AI Studioでうまくいったことと、本番workflowが正しいことは同義ではありません。
workflowを変えれば品質問題が解決すると考えている。 本当に必要なのはbatchではなくProモデルであることもあります。特に文字の多い画像や高品質レイアウトでは、この見極めが重要です。
legacyラインの移行判断を深く見たいなら、次はGemini 2.5 Flash Imageの置き換えガイドが近い読み物です。
結論
Gemini画像生成のbatch vs realtimeという問いに対するいちばん実務的な答えは、API比較そのものではなく、ルーティング規則です。
人が結果を待っているなら同期generateContentに残る。仕事が大量で、急がず、反復学習が終わっているならBatch APIへ回す。多くの新規実装では gemini-3.1-flash-image-preview から始める。文字、レイアウト、失敗コストが高いなら gemini-3-pro-image-preview に上げる。gemini-2.5-flash-image は 2026年10月2日 の終了を踏まえたうえで、legacy節約策としてのみ扱う。
順序はこれで十分です。先にlatency toleranceでworkflowを決め、後から失敗コストでモデルを決める。それが一番ぶれません。