2026年3月22日時点で、Gemini画像生成コードの safest default は native Gemini API と gemini-3.1-flash-image-preview です。 最初から text-heavy なグラフィックや高価値のアセットを作ると決まっているのでなければ、まずはこのルートから始めるのが最も安全です。
この結論が重要なのは、いまの Gemini の image stack が検索結果だけだとかなり読み違えやすいからです。Gemini アプリの説明ページもあれば、AI Studio の話もあり、raw API docs もあり、さらに古い 2.5 系のチュートリアルもまだ多く残っています。開発者にとっての正しい first step はもっと狭くて実務的です。まず current model を選ぶ。次に working native request を一つ走らせる。画像を実際に保存する。編集、Pro、Batch を考えるのはその後です。
もう一つ、最初に置いておくべき caveat があります。Gemini Apps、AI Studio、Gemini API はつながっていますが、free と paid の境界を一つのルールで説明できるわけではありません。Google の billing ページ には新規アカウントは Free tier から始まるとありますが、Google が 2026年2月26日 に出した Nano Banana 2 の開発者向け記事 では、このモデルを AI Studio で使うには paid API key が必要だと明記されています。この違いを見落とすと、コード以前の前提でつまずきやすくなります。
要点まとめ
- 新しい image-generation code では、generic compatibility layer より native Gemini API を起点にした方が分かりやすいです。
imageSize、aspectRatio、multi-turn editing、より広い image feature も native route の方が見えやすいからです。 - まずは
gemini-3.1-flash-image-previewから始めるのが自然です。画像内テキストの品質、infographic の精度、premium output の価値が差額を上回るときだけgemini-3-pro-image-previewに上げます。 - 最初の request は地味で構いません。まず一枚を生成して保存し、その後で editing、grounding、Batch や複雑な prompt pipeline を足してください。
- Gemini 3 の image models では
imageSizeとaspectRatioの明示が重要です。現在の docs では512、1K、2K、4Kと広い aspect ratio が公開されています。 - 価格、paid key、shutdown date、rate limits は live fact として扱うべきです。
gemini-2.5-flash-imageはまだ cheapest line ですが、deprecations ページ は 2026年10月2日 を shutdown date としています。
| ルート | 向いている用途 | 最初に使うモデル | いまこの経路が適切な理由 | 主な caveat |
|---|---|---|---|---|
| JavaScript / Node.js native SDK | Next.js API routes、server-side app、worker | gemini-3.1-flash-image-preview | imageSize、aspectRatio、inline image data を扱いやすい current path | API key は server-side に置く |
| Python native SDK | batch tooling、編集フロー、script、内部自動化 | gemini-3.1-flash-image-preview | 画像の反復や local file input を扱いやすい | script のまま production hardening を忘れやすい |
| raw REST / cURL | 低レベルのデバッグ、payload 確認、SDK がない言語 | gemini-3.1-flash-image-preview | request / response の実際の shape を一番見やすい | boilerplate が長く、decode も手動 |
| premium で text-heavy な出力 | poster、diagram、infographic、高価値 asset | gemini-3-pro-image-preview | 品質差が business result を変えるときに意味がある | 価格差が大きい |
app、AI Studio、API の違いから整理したいなら、先に Gemini画像生成チュートリアル を読む方が自然です。次の疑問が syntax より pricing なら Gemini image generation API の価格ガイド が近いです。編集が主目的なら Gemini image-to-image editing guide の方が適しています。
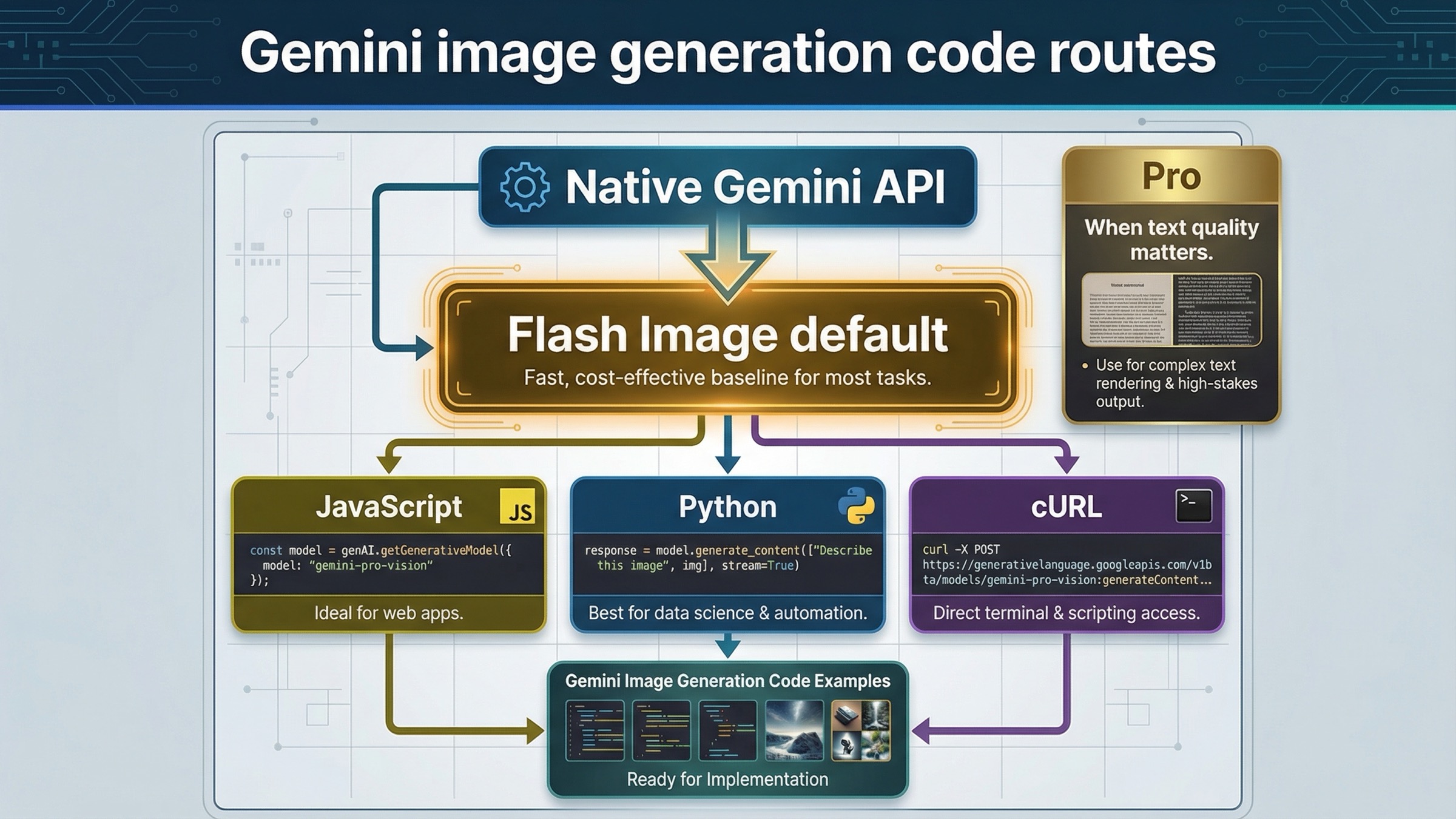
まず選ぶべきGemini画像生成のコード経路
このテーマで最も高くつく失敗は、prompt の細かさではなく、最初に wrong surface から入ってしまうことです。Gemini app で画像を作った経験や、AI Studio でブラウザ上の generate を見た後だと、API もその延長で簡単に使えるように感じがちです。けれど API は app-side の前提をそのまま引き継いでくれるわけではありません。model ID、billing、response handling、quota の理解は依然として自分で持つ必要があります。
大半の新しい実装にとって、正しい first source はやはり Gemini API image generation and editing docs です。ここで Google は Gemini 3.1 Flash Image Preview を current default として示し、実際のコードを変える feature として responseModalities、aspectRatio、imageSize、multi-turn editing を説明しています。だからこのページでも OpenAI compatibility ではなく native Gemini route を中心にしています。compatibility layer は migration のためには便利ですが、いまの image feature set を理解する入口としては最適ではありません。
もちろん、すべての Gemini image model が同じ扱いになるわけではありません。現在の pricing ページ はその違いをかなり明確にしています。gemini-3.1-flash-image-preview は fast default lane、gemini-3-pro-image-preview は premium lane、gemini-2.5-flash-image はまだ使えるが legacy cost lane です。ただし deprecations ページ は 2.5 image line に 2026年10月2日 の shutdown date を付けています。つまり新しい tutorial において "いちばん安い" と "いちばん教えるべき" はもはや同義ではありません。
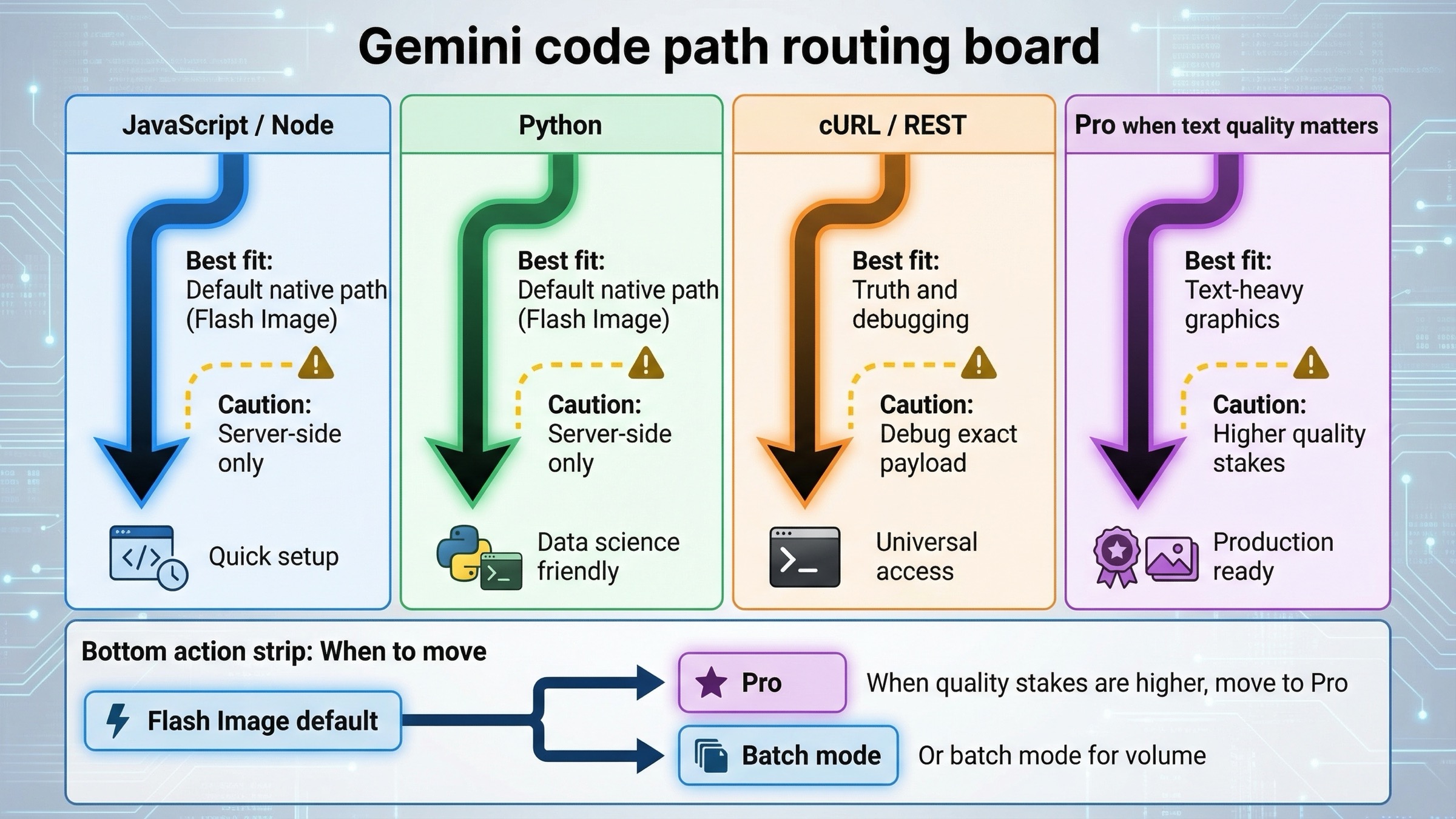
実務上のルールはかなり単純です。新規 workflow なら Flash Image から始める。poster、diagram、infographic のように文字品質や完成度が重要な仕事なら Pro を候補に入れる。2.5 image line を使うなら、それは future-proof default ではなく、legacy cost route を意図的に選んでいると明言する。この順番を最初に整えるだけで、後ろの実装判断がかなり楽になります。
AI Studio を testing surface として使うのは問題ありません。ただし AI Studio をそのまま production contract と見なすのは危険です。Nano Banana 2 の開発者記事が paid API key requirement を書いている以上、実際の architecture、logging、quota planning は API route を中心に考えるべきです。
JavaScript 例: いま最短で使える Node / サーバーサイドの経路
Next.js、Node.js、あるいは backend service で JavaScript を使っているなら、現在いちばん素直な path は @google/genai です。client はサーバー側に置き、GEMINI_API_KEY を環境変数から読み、返ってきた inlineData をファイルや object storage に保存します。
この例が良いのは、後で壊れやすい moving parts を最初から通せるからです。現在の package name、現在の model name、explicit image controls、そして response parsing。この段階で full pipeline を組む必要はありません。一枚返ること、保存できること、サイズと比率が意図通りであることを確かめれば十分です。
javascriptimport { GoogleGenAI } from "@google/genai"; import fs from "node:fs"; const ai = new GoogleGenAI({ apiKey: process.env.GEMINI_API_KEY }); const prompt = ` Create a clean 16:9 product hero image of a matte black travel mug on a light concrete surface. Use soft studio lighting, crisp texture, and calm negative space on the right for marketing copy. `; const response = await ai.models.generateContent({ model: "gemini-3.1-flash-image-preview", contents: prompt, config: { responseModalities: ["IMAGE"], imageConfig: { aspectRatio: "16:9", imageSize: "2K", }, }, }); for (const part of response.candidates[0].content.parts) { if (part.inlineData) { const buffer = Buffer.from(part.inlineData.data, "base64"); fs.writeFileSync("travel-mug-hero.png", buffer); } }
ここで覚えておきたいポイントは四つです。第一に model は gemini-3.1-flash-image-preview であり、古い 2.5 系サンプルではありません。第二に responseModalities: ["IMAGE"] は、caption や explanation が不要なときに画像だけを返してもらうための指定です。docs では default が text + image になっていますが、最初の "save the file" には image-only が向いています。第三に useful な control は imageConfig にあります。出力 shape が大事なら、そこを曖昧にしない方がいい。第四にこの client は server-side に置くべきです。短い sample だからといって permanent API key を frontend に置いてはいけません。
これが動いたあとに考えるべき次の JavaScript decision は、pure image output で十分か、text-plus-image response が欲しいかです。backend worker なら image-only が素直ですし、creator tool なら Gemini の説明や次の改善案も一緒に返した方が UX が良いことがあります。native Gemini image flow の良さは、ここを conversation として扱える点にもあります。
JavaScript は overengineer しやすい場所でもあります。最初の request に grounding や chat state、複雑な orchestration は要りません。first image、then editing、then storage、then retries、then quotas。この順番の方が、結果として速いです。
Python 例: 編集と反復にいちばん向く現在の経路
Python は Gemini image generation を学ぶうえで特に相性が良い環境です。official docs が読みやすく、SDK も compact で、editing の考え方も script として素直に書けます。そのため batch tooling、内部運用、画像編集の自動化に向いています。
Python の強みは、生成から編集に移るときも mental model が崩れないことです。Gemini の docs では image generation と image editing が同じ generate_content の流れで説明されます。input が変わるだけで call pattern 自体は大きく変わりません。これは実際の visual workflow とかなり相性が良いです。
pythonfrom google import genai from google.genai import types from PIL import Image client = genai.Client() base_image = Image.open("living-room.png") prompt = """ Using the provided image of a living room, change only the blue sofa to a vintage brown leather chesterfield sofa. Keep the pillows, lighting, coffee table, and room layout unchanged. """ response = client.models.generate_content( model="gemini-3.1-flash-image-preview", contents=[prompt, base_image], config=types.GenerateContentConfig( response_modalities=["TEXT", "IMAGE"], image_config=types.ImageConfig( aspect_ratio="4:3", image_size="2K", ), ), ) for part in response.parts: if part.text is not None: print(part.text) elif part.inline_data is not None: image = part.as_image() image.save("living-room-edit.png")
この sample を支えているのは二つの判断です。一つ目は prompt discipline。局所編集をしたいなら、変えてはいけない部分をはっきり書く必要があります。Gemini は指示追従が強いですが、layout や lighting を維持してほしいなら、それを明示した方が安定します。二つ目は base image が contents の中に text prompt と並んで入っていることです。current Gemini image editing は "別モード" に切り替える感覚ではなく、context を与えて controlled change を依頼する感覚で考える方が合っています。
ここから multi-turn workflow の価値も大きくなります。image generation docs も conversational editing を推しています。実際、良い production prompt は必ずしも longest prompt ではありません。最初の指示、最初の結果、そして必要な差分だけを求める follow-up。この方が速くて安定しやすい。80% 合っている画像を捨てて、毎回ゼロからやり直す必要はありません。
Python はこうした follow-up の自動化とも相性が良いです。asset pipeline、moderation hook、post-processing にもつなぎやすい。ただし、ここには典型的な落とし穴もあります。notebook や単発 script で proof of concept は通ったのに、retry、logging、usage 観測を付けずに production に流れてしまうことです。user-facing app になるなら、その "地味な部分" も早めに入れた方が安全です。
cURL と raw REST の例: 低レベルのデバッグや言語非依存の統合が必要なとき
SDK が見えにくい、あるいは runtime が Python / Node ではないなら、raw REST は今でも最も頼れる truth source です。cURL は full app を作るには不便ですが、Gemini API が期待する request shape を最も直接的に見せてくれます。model choice、payload serialization、proxy layer、AI Studio と自前コードの差分を確認するときに特に有効です。
bashcurl -s -X POST \ "https://generativelanguage.googleapis.com/v1beta/models/gemini-3.1-flash-image-preview:generateContent" \ -H "x-goog-api-key: $GEMINI_API_KEY" \ -H "Content-Type: application/json" \ -d '{ "contents": [{ "parts": [ { "text": "Create a 16:9 studio photo of a white sneaker on a soft gray background with crisp side lighting and premium ecommerce styling." } ] }], "generationConfig": { "responseModalities": ["IMAGE"], "imageConfig": { "aspectRatio": "16:9", "imageSize": "2K" } } }'
この cURL sample を持っておく価値は、単に shell で試せることではありません。もし cURL では通るのに SDK では失敗するなら、問題は client version、wrapper、response parsing のどこかにあります。逆に cURL でも失敗するなら、API contract、billing、rate limits、あるいは model choice に寄って考えるべきだと分かります。ここが切り分けの大きな助けになります。
SDK のない言語や low-dependency environment にとっても、raw REST は良い starting point です。最終的に Go や Rust、PHP、自社 platform layer に包むとしても、wire 上で何が起きているかを先に理解しておく価値は大きいです。generateContent、contents、generationConfig、responseModalities、imageConfig を明示的に見ることで、あとから internal wrapper を作るときの精度も上がります。
欠点はもちろんあります。response decode を自分でやる必要があり、parts や chats、file inputs の便利さは SDK の方が上です。だから cURL は default comfort path ではなく、debugging tool / truth source として考える方が自然です。
コードが実際に変わる編集・マルチターン・高解像度オプション
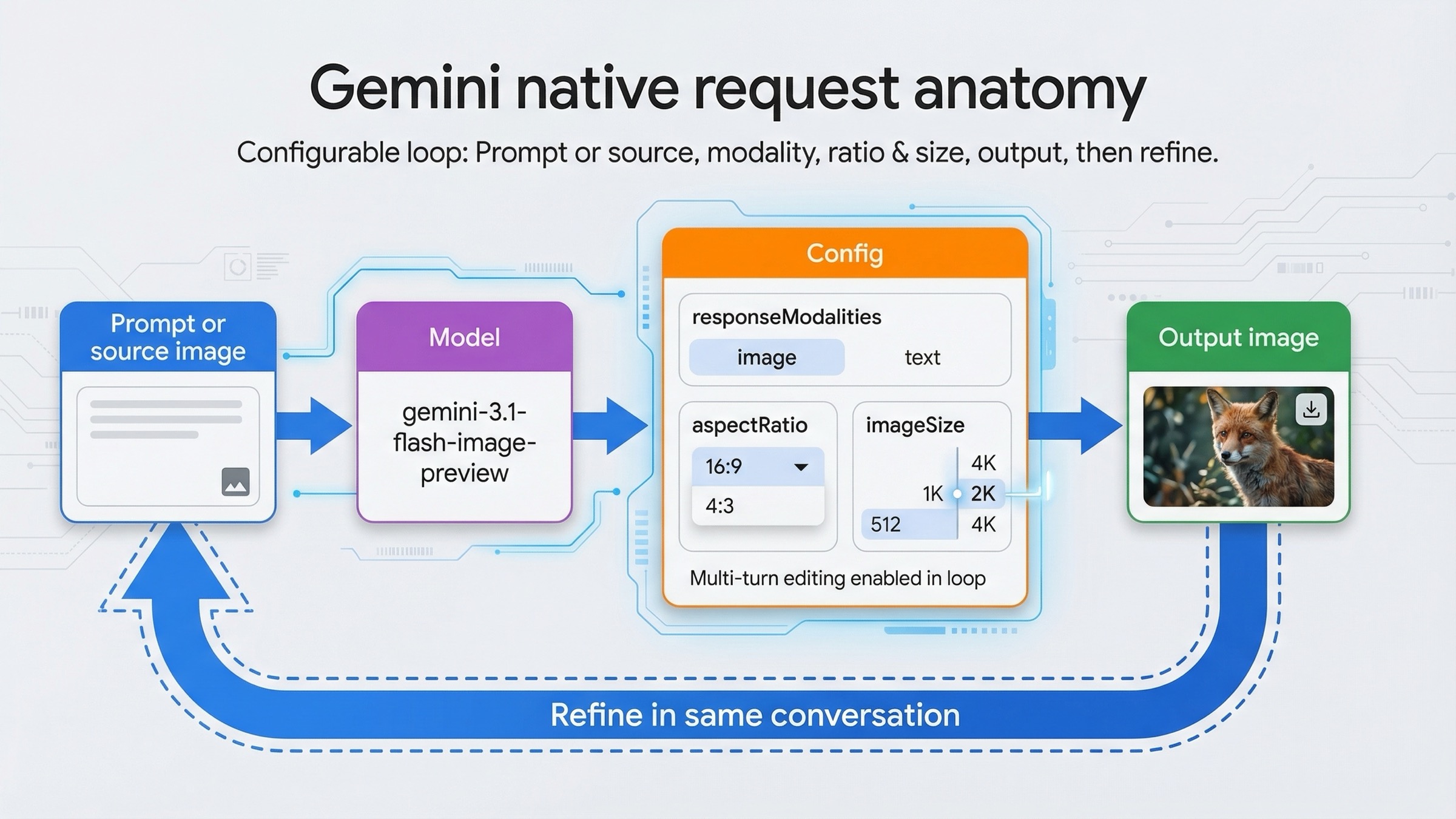
Gemini-native image generation が shallow tutorial と差をつけるのはこの部分です。text-to-image の一回呼び出しだけで終わるページはまだ多いですが、実際の product value はその先にあります。controlled edits、reference image、higher resolutions、そして前の良い結果を活かした iterative refinement が必要になるからです。
Google の current docs もこの点をかなり押しています。単発生成だけでなく multi-turn image editing を勧め、chat の中で infographic を作ってから後続ターンで言語を差し替える例まで出しています。重要なのはサンプルの派手さではなく、mental model の違いです。Gemini image generation は pixels を返すだけの endpoint ではなく、context を保ったまま visual state を育てていく system と捉えた方が実運用に近いです。
javascriptimport { GoogleGenAI } from "@google/genai"; import fs from "node:fs"; const ai = new GoogleGenAI({ apiKey: process.env.GEMINI_API_KEY }); const chat = ai.chats.create({ model: "gemini-3.1-flash-image-preview", config: { responseModalities: ["TEXT", "IMAGE"], }, }); await chat.sendMessage({ message: "Create a vibrant infographic that explains photosynthesis like a colorful kids cookbook.", }); const response = await chat.sendMessage({ message: "Update this infographic to be in Spanish. Do not change any other elements.", config: { responseModalities: ["TEXT", "IMAGE"], imageConfig: { aspectRatio: "16:9", imageSize: "2K", }, }, }); for (const part of response.candidates[0].content.parts) { if (part.inlineData) { fs.writeFileSync( "photosynthesis-es.png", Buffer.from(part.inlineData.data, "base64") ); } }
この段階では imageSize と aspectRatio は trivia ではありません。公式 docs は 512、1K、2K、4K と、16:9、9:16、21:9、4:1、1:4 などの aspect ratio を公開しています。これにより code path 自体が変わります。ecommerce asset、banner、social crop、app-store artwork のように output shape がそのまま downstream cost に響く場面では、native request で明示する意味が大きいです。
Pro lane もここで理解する方が自然です。pricing page と Gemini Apps の help は別の surface から同じことを言っています。Flash Image は fast default、Pro は expensive but higher-stakes lane。poster copy、diagram、infographic labels、premium product art のような仕事なら、code level でも最初から Pro を視野に入れた方が良いケースがあります。
さらに、current pricing page は Google Search grounding と image-based grounding のコストを別立てで示し、docs でも search-grounded visual flow を見せています。つまり premium workflow の一部は "prompt in, image out" だけではなくなっています。ただしこれは day-one requirement ではありません。まずは base request をきちんと通し、その後に必要な product case だけ grounding を追加すべきです。
料金、Batch モード、そして Pro を選ぶべき場面

code examples の記事で pricing を主役にする必要はありませんが、無視もできません。model choice と output size は implementation decision の一部だからです。
Google の pricing page は現在かなり明確です。Gemini 3.1 Flash Image Preview は standard mode で 0.5K が約 $0.045、1K が約 $0.067、2K が約 $0.101、4K が約 $0.151。Gemini 3 Pro Image Preview は 1K / 2K が約 $0.134、4K が約 $0.24。legacy の Gemini 2.5 Flash Image は standard 約 $0.039、Batch 約 $0.0195。これらは単なる pricing row ではなく、どの sample を教えるべきかに直結します。
| モデル | 現在の位置づけ | 公式の price signal | 向いているコード用途 | 注意点 |
|---|---|---|---|---|
gemini-3.1-flash-image-preview | current default lane、2026年2月26日公開 | 0.5K 約 $0.045、1K 約 $0.067、2K 約 $0.101、4K 約 $0.151 | ほとんどの新規 workflow の起点 | preview label なので quota の余裕は限定的 |
gemini-3-pro-image-preview | current premium lane、2025年11月20日公開 | 1K / 2K 約 $0.134、4K 約 $0.24 | text-heavy graphics、infographic、high-value output | Flash Image よりかなり高い |
gemini-2.5-flash-image | legacy low-cost lane、shutdown 予定あり | standard 約 $0.039、Batch 約 $0.0195 | cost-sensitive な legacy flow | 2026年10月2日 に停止予定 |
では Pro が本当に worth it になるのはいつか。失敗した画像のコストが model price 差より高いときです。poster、diagram、infographic、premium brand asset のように text quality や finish が outcome を左右するなら Pro が妥当になります。反対に ideation、variation、cost-sensitive volume generation なら Flash Image が依然として強い default です。
Batch mode は architecture を変える二つ目の判断です。価格ページの economics はかなり分かりやすく、画像枚数が多くて待ち時間を許容できるなら Batch は cost をかなり下げます。とくに 2.5 line と Flash Image line でその差が出やすいです。最初の sample code の形は変わりませんが、prototype から scheduled generation に移るときの推奨が変わります。
ここで 2.5 image line の位置づけも率直に書くべきです。まだ useful で、まだ official で、まだ cheap です。ただし fresh な code-example page がこれを main recommendation にしてしまうのは不正確です。いまの 2.5 は cheap legacy branch であり、visible retirement clock を持つ line です。
トラブルシューティング: Gemini画像生成コード例で起きやすい失敗
一つ目の失敗は、古い 2.5 系 image tutorial をそのまま current default だと思ってコピーすることです。いまはそうではありません。current docs、pricing、launch materials はいずれも Gemini 3 image line を first recommendation にしています。gemini-2.5-flash-image を使うなら、legacy-cost route を意図的に選んでいると考える方が正確です。
二つ目の失敗は、app、AI Studio、Gemini API の挙動を一つの product contract だと思うことです。Gemini Apps の help page は consumer surface の理解には便利ですし、AI Studio は prompt iteration に便利です。ただし実際の code contract を支配しているのは API です。billing、launch post、docs の読み方を分けないと、paid key や quota の前提でずれやすくなります。
三つ目の失敗は explicit image controls を省くことです。出力 shape が大事なら aspectRatio、サイズが大事なら imageSize を明示します。docs が示す通り、指定しなければ input image size に引きずられたり、square output になったりします。実験では問題なくても、production では弱い default です。
四つ目の失敗は image generation を one-shot endpoint だと思い込むことです。実際の workflow が必要としているのは multi-turn editing であることが多く、良い partial result を残して delta だけを依頼した方が速く、安く、制御しやすいケースが目立ちます。
五つ目の失敗は project-level quota を無視することです。rate limits ページ は limit が project 単位で掛かり、requests per day が Pacific time の深夜に reset すると説明しています。429 confusion が多いのはこのためです。魔法の数字を覚えるより、quota を live project state として確認する方が正しいです。
六つ目の失敗は、いちばん安い row をそのまま最初に教えるべき row だと思うことです。教育の順番としては current default first、cheaper legacy branch second、premium Pro third の方が reader にとって良い判断になります。
七つ目の失敗は SynthID watermark を忘れることです。workflow を壊すとは限りませんが、現実の product characteristic である以上、実装ガイドが明示しない理由はありません。もし本当の悩みが "どの sample を使うか" ではなく "なぜ急に動かなくなったか" なら、次に読むべきは Gemini image generation limit reset と Gemini image API free tier です。
結論
2026年の Gemini image generation code examples で本当に価値があるのは、最も派手な sample ではなく、次の implementation decision を最も明確にしてくれる sample です。
まずは native Gemini API から始めてください。大半の新規 workflow では gemini-3.1-flash-image-preview が default です。JavaScript、Python、cURL のいずれかで一枚を確実に保存し、その後に complexity を足します。output shape が重要になったら aspectRatio と imageSize を明示する。gemini-3-pro-image-preview は text-heavy、infographic-heavy、premium output の価値が差額を超えるときだけ選ぶ。gemini-2.5-flash-image は cheap legacy lane として扱う。この整理だけで、後続の実装はかなり楽になります。