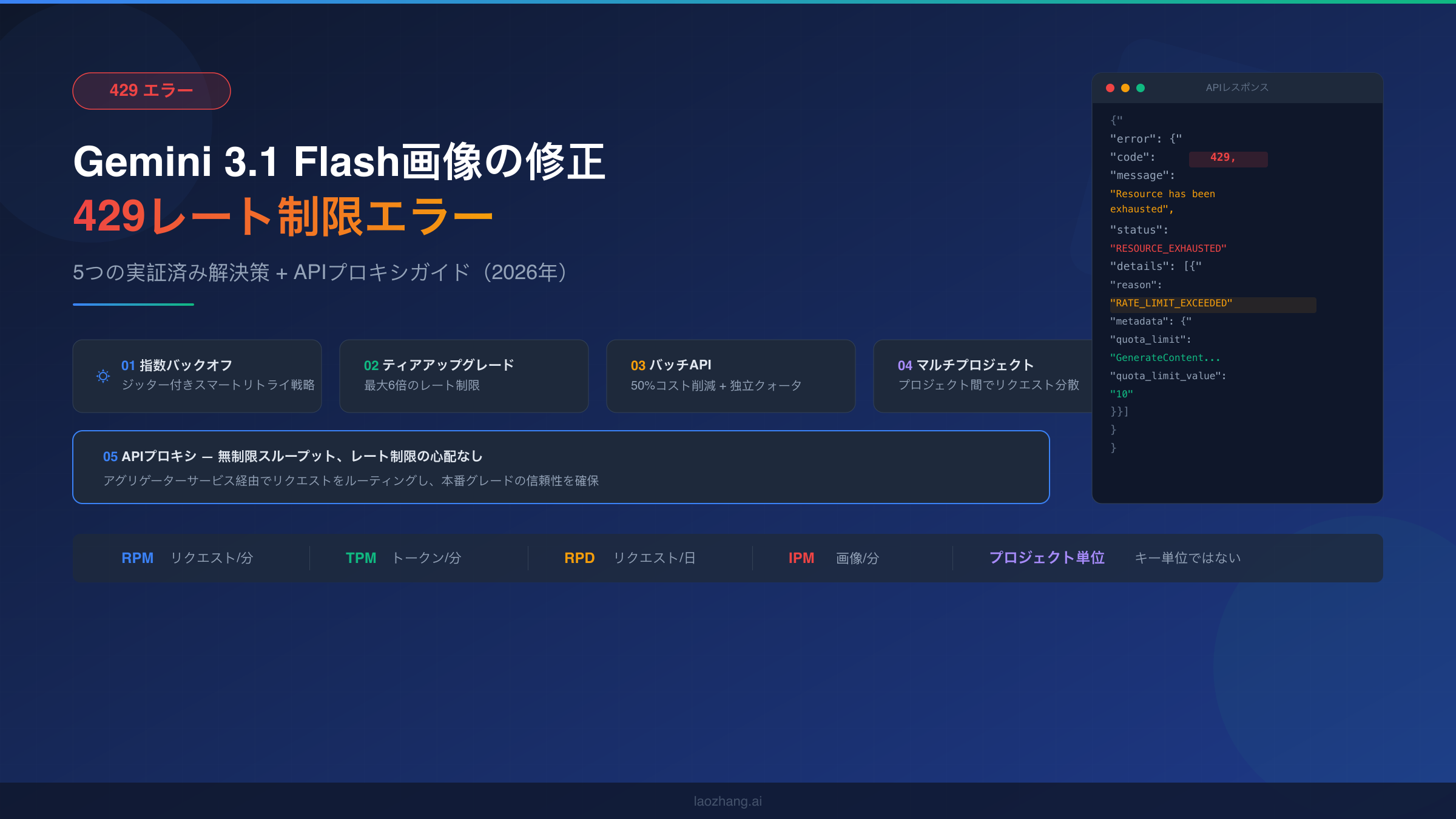
Gemini 3.1 Flashで画像生成中に恐ろしい429 RESOURCE_EXHAUSTEDエラーに遭遇していませんか。Gemini 3.1 Flash画像の429レート制限エラーは、RPM(リクエスト/分)、RPD(リクエスト/日)、TPM(トークン/分)、IPM(画像/分)の4つのレート制限次元のいずれかを超過したことを意味します。ジッター付き指数バックオフの実装、最大6倍のレート制限を得るための課金ティアアップグレード、50%のコスト削減と独立クォータを持つBatch APIの利用、複数プロジェクトへのリクエスト分散、または無制限スループットのためのAPIプロキシ経由のルーティングで即座に解決できます。本ガイドでは、どの制限に到達したかを正確に診断し、ユースケースに最適な解決策を選択する方法を詳しく説明します。
Gemini 3.1 Flash画像429エラーを理解する
Gemini 3.1 Flash画像APIの呼び出しが429ステータスコードを返す場合、レスポンスボディには多くの開発者が見落としがちな重要な診断情報が含まれています。解決策に飛びつく前に、エラーの構造を理解することで、汎用的な修正を適用するのではなく、正確なボトルネックをターゲットにすることができます。429エラーは、プロジェクトが特定の次元の割り当てられたクォータを消費したことをGoogleが伝える方法であり、どこを見ればよいかを知っていれば、レスポンスが実際にどの次元かを教えてくれます。
Gemini 3.1 Flash Image Previewモデルでレート制限に到達した場合の実際のエラーレスポンスは以下のようになります:
json{ "error": { "code": 429, "message": "Resource has been exhausted (e.g. check quota).", "status": "RESOURCE_EXHAUSTED", "details": [ { "@type": "type.googleapis.com/google.rpc.ErrorInfo", "reason": "RATE_LIMIT_EXCEEDED", "metadata": { "quota_limit": "GenerateContentRequestsPerMinutePerProjectPerRegion", "quota_limit_value": "10", "consumer": "projects/your-project-id", "quota_metric": "generativelanguage.googleapis.com/generate_content_requests" } } ] } }
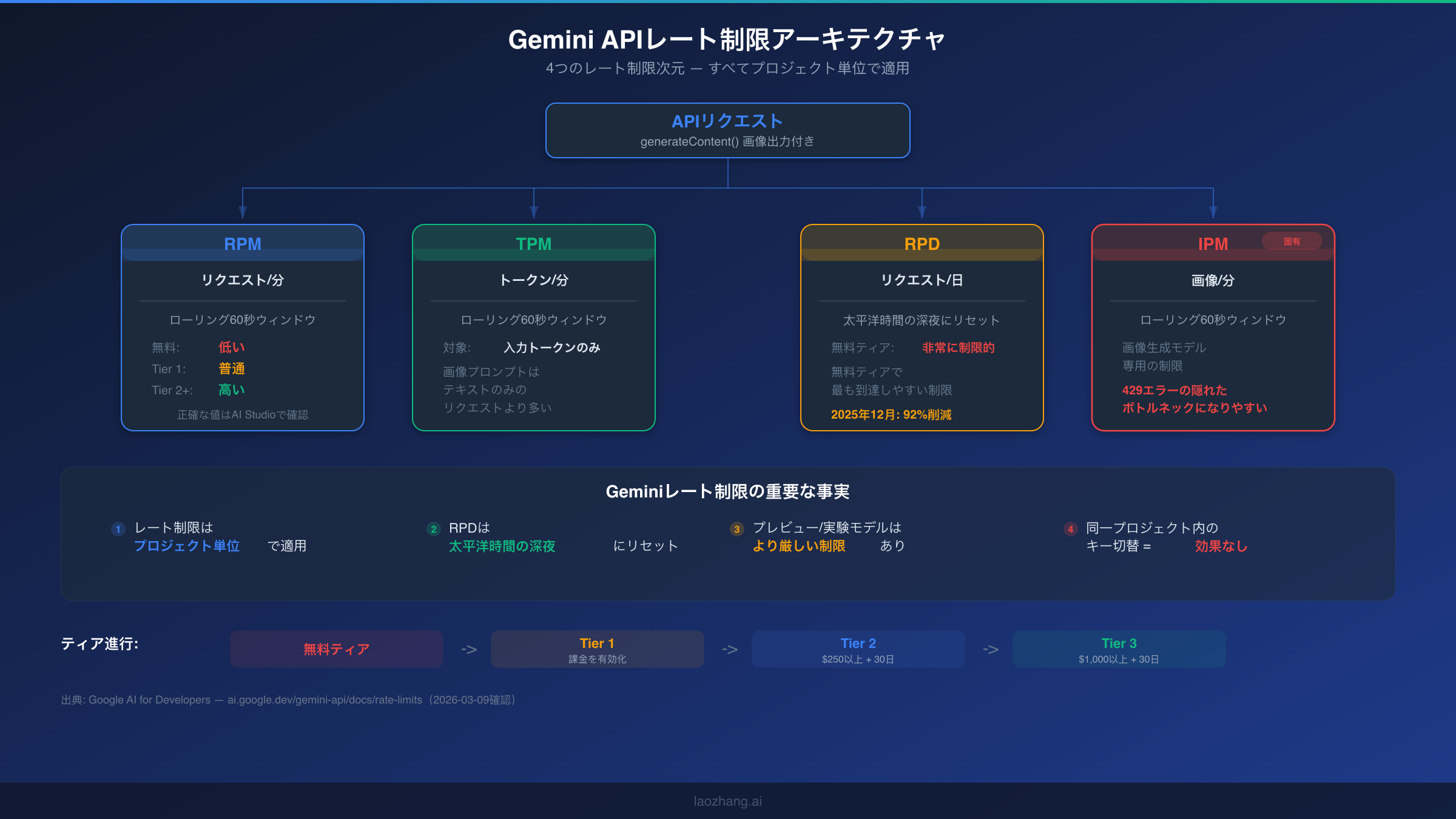
metadata.quota_limitフィールドが問題を診断する鍵です。このフィールドは、4つのレート制限次元のうち、どれを使い果たしたかを正確に教えてくれます。GoogleのGemini APIは4つの異なる次元でレート制限を適用しており、各次元は独立して動作します。つまり、RPMクォータには十分余裕があっても、日次のRPD割り当てを超過している可能性があります。RPM違反の修正はRPD違反の修正とは根本的に異なるため、これら4つの次元を理解することが不可欠です。
Gemini 3.1 Flash Image Previewの4つのレート制限次元は以下のように機能します。RPM(リクエスト/分)は、ローリング60秒ウィンドウ内にどれだけのAPI呼び出しを行ったかをカウントし、バースト操作中に開発者が最も頻繁に到達する制限です。TPM(トークン/分)は、同じローリングウィンドウ内で消費された総入力トークンを追跡します。画像生成では、詳細な説明を含む画像プロンプトが単純なテキストクエリよりも大幅に多くのトークンを消費するため、これが重要になります。RPD(リクエスト/日)は太平洋時間の深夜にリセットされる厳格な日次上限を課します。特に無料ティアでは、Googleが2025年12月にクォータを92%削減したため、非常に制限的です。最後に、IPM(画像/分)はGemini 3.1 Flash Image Previewのような画像生成モデルに固有の次元であり、テキスト専用モデルの経験からRPMとTPMのみを考慮することに慣れている開発者が見落としがちな隠れたボトルネックです。
多くの開発者が気づいていない重要な事実があります:Gemini APIのレート制限はAPIキーごとではなく、プロジェクトごとに適用されます。つまり、同じGoogle Cloudプロジェクト内に複数のAPIキーを作成しても、レート制限の面ではまったくメリットがありません。1つのプロジェクトに3つのキーがある場合、3つとも同じクォータプールを共有します。この区別は、解決策4のマルチプロジェクト分散戦略を議論する際に重要になります。
また、429エラーと503エラーの違いにも注意が必要です。両方とも画像生成パイプラインを中断する可能性があります。429はクォータを消費し、待つか制限を増やす必要があることを意味します。503(サービス利用不可)はGoogle側の一時的なサーバー側の問題を示します。その場合、短い遅延後の単純なリトライで通常は十分です。修正戦略は大きく異なるため、解決策を適用する前にステータスコードを確認することが重要です。
クイック診断 — どのレート制限に到達したか?
修正を適用する前に、どのレート制限次元を使い果たしたかを正確に特定する必要があります。実際にはRPDの日次上限に到達しているのに、闇雲に指数バックオフを実装すると、太平洋時間の深夜まで何時間もリトライが失敗し続けることになります。この診断アプローチにより、間違った解決策に時間を無駄にすることを防ぎ、根本原因の特定には1分もかかりません。
エラーレスポンスのquota_limitフィールドを調べることから始めましょう。値は4つの次元のいずれかに直接マッピングされ、それぞれにGoogleが内部的に使用する固有の文字列識別子があります。GenerateContentRequestsPerMinutePerProjectPerRegionが表示された場合、RPM制限に到達しています。単純に一時停止すれば、通常60秒以内に解消されます。GenerateContentTokensPerMinutePerProjectPerRegionが表示された場合、TPMが消費されており、プロンプトがトークンを早く消費しすぎていることを意味します。GenerateContentRequestsPerDayPerProjectPerRegionの値はRPD違反を示し、太平洋時間の深夜まで日次カウンターがリセットされないため最もフラストレーションがたまります。そしてGenerateContentImagesPerMinutePerProjectPerRegionに遭遇した場合、画像出力専用のIPM上限に到達しています。これは画像生成モデルバリアントにのみ適用される制限です。
エラーレスポンスに詳細なmetadataオブジェクトが含まれていない場合(一部の古いSDKバージョンで発生)、消去法アプローチを使用できます。過去60秒間のリクエスト頻度を確認してください。連続的に呼び出しを行っている場合、RPMまたはIPMが原因の可能性が高いです。一日中バッチジョブを実行している場合、総日次リクエスト数をティアのRPD割り当てと照合してください。Google AI Studioのクォータページにアクセスすることで、現在のティアと関連する制限を確認できます。各次元のリアルタイム使用量と残り容量が表示されます。
以下の判断プロセスにより、問題を素早く絞り込み、最も関連する解決策に直接ジャンプできます:
- 連続的なAPI呼び出し中(数秒以内)にエラーが発生? → RPMまたはIPMの可能性が高いです。解決策1(指数バックオフ)で即座に緩和し、解決策2(ティアアップグレード)で恒久的な修正を検討してください。
- 一日中の継続使用後にエラーが発生? → RPDの可能性が高いです。太平洋時間の深夜まで待つか、解決策2(ティアアップグレード)で日次割り当てを増やしてください。
- 非常に長いまたは詳細なプロンプトでエラーが発生? → TPMの可能性が高いです。プロンプトを簡素化するか、解決策1でリクエストを時間的に分散させてください。
- 無料ティアですぐに制限に到達? → RPDの可能性が最も高いです(無料ティアのRPDは2025年12月に92%削減されました)。解決策2(課金を有効にしてTier 1へ)が最も速い恒久的な修正です。
Google Cloudの課金ステータスを確認することで、現在のティアをプログラム的にチェックすることもできます。無料ティアのユーザーは、4つのすべての次元で最も制限的なリミットを持っています。Tier 1へのアップグレードは、プロジェクトで課金アカウントを有効にするだけで済み、レート制限の増加は通常数分以内に反映されます。ティア別の詳細なレート制限の内訳については、各モデルバリアントの正確なクォータを示した専用ガイドをご確認ください。
さらに、事後的ではなく積極的にクォータ消費を監視したい開発者には、もう1つの診断テクニックがあります。Google Cloud Consoleには「割り当てとシステム制限」ページがあり、各レート制限次元のリアルタイム使用量グラフを表示できます。プロジェクトの「IAMと管理」セクションに移動し、「割り当て」を選択します。「generativelanguage.googleapis.com」でフィルタリングすると、すべてのGemini APIクォータが表示されます。これらのグラフは使用パターンを時系列で表示するため、特定の制限に常にぶつかっているのか、単に時折スパイクが発生しているだけなのかを簡単に把握できます。クォータアラートの設定も可能です。50%、80%、90%の使用量しきい値で通知を設定でき、アプリケーションが429エラーを受信し始める前の早期警告が得られます。この積極的な監視は、レート制限エラーがユーザーエクスペリエンスに直接影響する本番システムで特に価値があります。
解決策1 — スマートリトライロジック付き指数バックオフ
指数バックオフは429エラーに対する最初の防御線であり、他にどのような解決策を適用するかに関わらず、Gemini APIを呼び出すすべての本番アプリケーションに実装すべきものです。コンセプトはシンプルです:429レスポンスを受信したら、リトライする前に増加する時間だけ待ちます。しかし、単純に待ち時間を倍増させるナイーブな実装は、複数のインスタンスが同時にリトライした場合にサンダリングハード問題を引き起こす可能性があります。バックオフ間隔にランダムジッターを追加することで、リトライの試行がより均等に分散され、レート制限の境界で繰り返し衝突する可能性が大幅に減少します。
Python実装
以下のPython実装は、google-generativeai SDKとカスタムリトライラッパーを使用し、異なるレート制限タイプをインテリジェントに処理します。RPMベースの制限にはウィンドウが60秒ごとにリセットされるため短い初期遅延を使用し、RPD制限には大幅に長い遅延に切り替えるか、日次リセットまでリトライしても無駄であることを通知する例外を発生させます。
pythonimport time import random import google.generativeai as genai genai.configure(api_key="YOUR_API_KEY") def generate_image_with_retry(prompt, max_retries=5, base_delay=1.0): """Generate image with exponential backoff and jitter.""" model = genai.GenerativeModel("gemini-3.1-flash-image-preview") for attempt in range(max_retries): try: response = model.generate_content( prompt, generation_config={"response_mime_type": "image/png"} ) return response except Exception as e: error_str = str(e) if "429" not in error_str and "RESOURCE_EXHAUSTED" not in error_str: raise # Non-rate-limit error, don't retry if "PerDay" in error_str: print("Daily limit reached. Retrying won't help until midnight PT.") raise # Exponential backoff with full jitter delay = base_delay * (2 ** attempt) + random.uniform(0, 1) delay = min(delay, 60) # Cap at 60 seconds print(f"Rate limited. Retry {attempt + 1}/{max_retries} in {delay:.1f}s") time.sleep(delay) raise Exception("Max retries exceeded")
Node.js実装
Node.jsアプリケーションでは、同じパターンに従いますが、async/await構文と@google/generative-aiパッケージを使用します。ジッター計算にMath.random()を使用して遅延間隔にランダム性を追加し、複数のサーバーインスタンス間での同期リトライを防止します。
javascriptconst { GoogleGenerativeAI } = require("@google/generative-ai"); const genAI = new GoogleGenerativeAI("YOUR_API_KEY"); async function generateImageWithRetry(prompt, maxRetries = 5, baseDelay = 1000) { const model = genAI.getGenerativeModel({ model: "gemini-3.1-flash-image-preview" }); for (let attempt = 0; attempt < maxRetries; attempt++) { try { const result = await model.generateContent({ contents: [{ parts: [{ text: prompt }] }], generationConfig: { responseMimeType: "image/png" } }); return result; } catch (error) { const msg = error.message || ""; if (!msg.includes("429") && !msg.includes("RESOURCE_EXHAUSTED")) throw error; if (msg.includes("PerDay")) { throw new Error("Daily limit reached. Wait until midnight PT."); } const delay = Math.min(baseDelay * Math.pow(2, attempt) + Math.random() * 1000, 60000); console.log(`Rate limited. Retry ${attempt + 1}/${maxRetries} in ${(delay/1000).toFixed(1)}s`); await new Promise(resolve => setTimeout(resolve, delay)); } } throw new Error("Max retries exceeded"); }
指数バックオフを本番環境で効果的に機能させるためのいくつかの注意点があります。まず、最大遅延上限を常に設定してください(RPM制限には60秒が妥当です)。持続的なレート制限中に過度に長い待機を防ぐためです。次に、リトライロジックの上にサーキットブレーカーパターンの実装を検討してください。5回連続で429エラーを受信した場合、APIを叩き続けるのではなく、すべてのリクエストを一時的に停止してクールダウン期間を設けます。これはGoogleのインフラストラクチャに対してより配慮があるだけでなく、クォータの回復も速くなります。第三に、すべての429遭遇をquota_limitフィールドを含む完全なエラー詳細とともにログに記録してください。このデータは、使用パターンを理解し、ティアのアップグレードやよりスケーラブルなソリューションへの切り替え時期を判断する上で非常に貴重です。
指数バックオフは不可欠ですが、その限界を理解することも重要です。一時的なRPMスパイクにはうまく対処できますが、ティアの日次制限を恒常的に超過したり、割り当てられたレート以上の持続的なスループットが必要な場合など、構造的な問題を解決することはできません。これはセーフティネットであり、スケーリング戦略ではないと考えてください。リクエストの10〜15%以上でリトライに依存していることに気づいた場合、以降のより根本的な解決策を検討する時です。
解決策2 — 高い制限のためのAPIティアアップグレード
Google Cloudの課金ティアをアップグレードすることは、4つのすべての次元でレート制限を恒久的に増やす最も簡単な方法です。Googleのティアシステムは、支出しきい値とアカウントの年齢を通じて正当な使用を証明するにつれて、段階的により高いクォータをアンロックするように設計されています。多くの開発者にとって、単に課金を有効にする(無料からTier 1への移行)だけで、利用可能な容量が即座に劇的に増加し、コード変更なしに429エラーを解消できることが多いです。
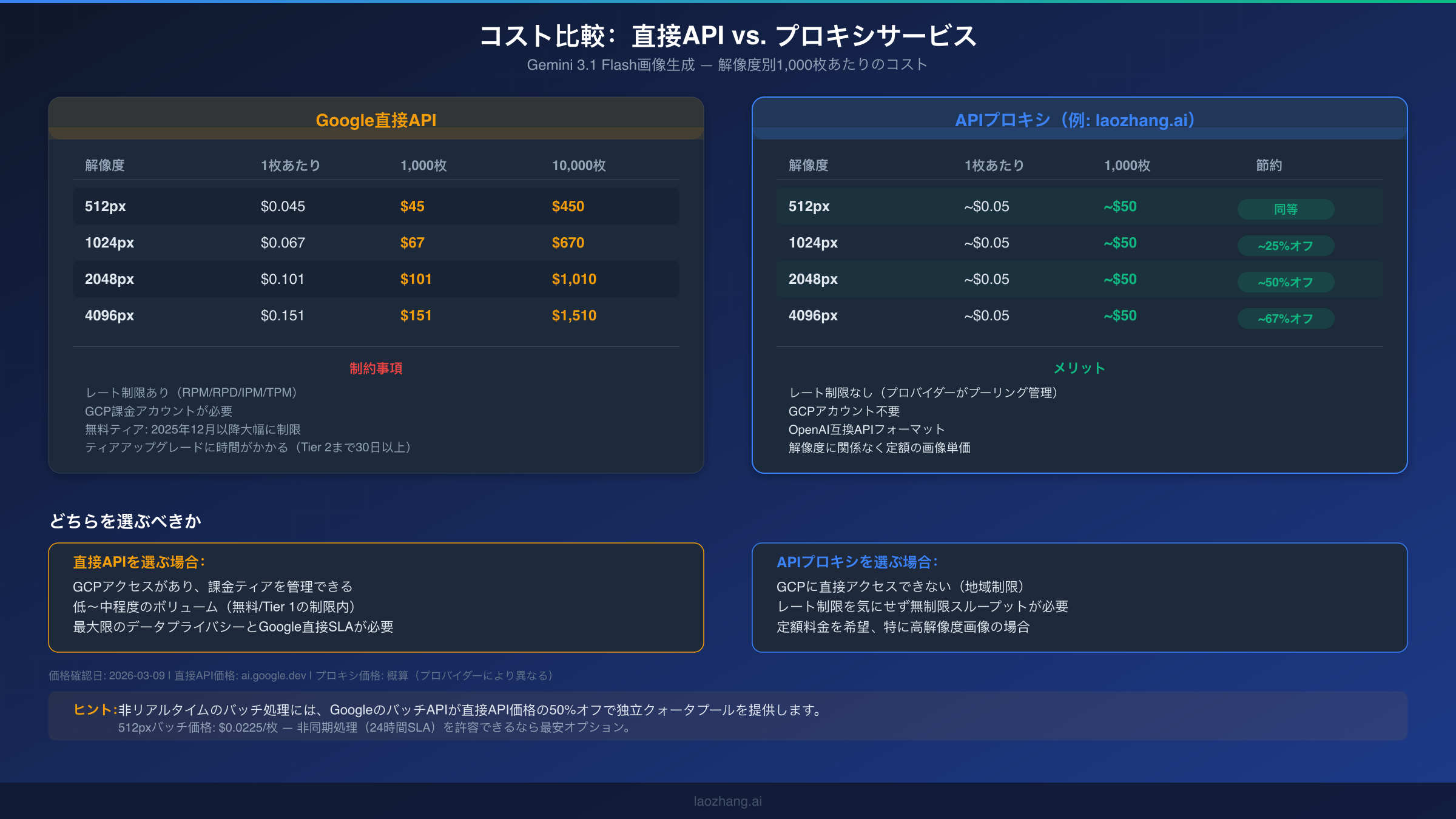
ティアシステムは以下のように機能します(Google AI for Developersドキュメントから確認、2026-03-09):無料ティアは対象の国と地域のユーザーに利用可能で、2025年12月にさらに削減された最も制限的なリミットを持ちます。Tier 1はGoogle Cloudプロジェクトに有料課金アカウントをリンクする必要があり、アップグレードは通常数分以内に反映されます。Tier 2は総支出が250ドルを超え、最初の支払いから少なくとも30日が経過している必要があります。Tier 3は総支出が1,000ドルを超え、同じ30日間の最低期間が必要です。各ティアは、RPM、TPM、RPD、IPM全体で大幅に高い制限をもたらし、Tier 1だけで無料ティアの3〜6倍の増加を提供することが多いです。
ティアアップグレードのコスト面は、使用パターンに大きく依存します。1日100枚未満の画像を生成している場合、バースト期間外では技術的に無料ティアで十分かもしれませんが、RPD制限に常に悩まされることになります。課金を有効にしても、すぐにお金がかかるわけではありません。無料クォータを超えた使用分のみが課金されます。Gemini画像生成の料金は解像度に依存します:512pxで1画像あたり$0.045、1024pxで$0.067、2048pxで$0.101、4096pxで$0.151です(Google AI for Developers、2026-03-09確認)。1024px解像度で1日500枚の画像を生成する本番アプリケーションの場合、日次コストは約$33.50となり、信頼性向上を考慮すれば妥当な投資です。
ティアをアップグレードするには、Google AI StudioまたはGoogle Cloud Consoleに移動し、プロジェクトで課金を有効にします。プロセスは簡単です:まだ持っていなければ課金アカウントを作成し、APIプロジェクトにリンクすると、ティアアップグレードは約10分以内に反映されます。Tier 2以上への到達には、自然にAPIを使用することで発生する累積支出が主な要件です。別途の申請や承認プロセスはなく、支出しきい値を超える一貫した使用のみです。
1つの重要な計画上の注意点があります:Tier 2とTier 3の30日間の待機期間は、アップグレードパスを急ぐことができないことを意味します。近い将来より高い制限が必要になることが予想される場合、最良の戦略は早期に課金を有効にする(現在の使用量が最小限でも)ことで、カウントダウンを開始することです。そうすれば、アプリケーションがスケールアップしてTier 2の制限が必要になった時、すでに時間要件を満たしています。
以下は、さまざまな使用シナリオにおける実用的なコスト便益分析です。1024px解像度で1日約100枚の画像を生成している場合、Tier 1での日次コストは約$6.70、月間約$200です。1日1,000枚の場合(本番SaaSアプリケーションの一般的なしきい値)、1日約$67または月間$2,000となり、最初の月以内にTier 2の資格を得る支出レベルに達します。1日10,000枚以上の大量生成では、1024px解像度で日次コストが$670に達しますが、このスケールではBatch API(解決策3)やAPIプロキシ(解決策5)を使用して意味のあるコスト削減を強く検討すべきです。重要な洞察として、画像あたりのコストはティア間で一定です。変わるのはスループットの上限のみであり、生成あたりの価格ではありません。
解決策3 — 大量画像生成のためのBatch API
Batch APIは大量画像生成に対するGoogleの公式推奨アプローチですが、多くの競合ガイドが完全にスキップするか、触れる程度にしか言及しないため、驚くほど十分に活用されていません。Batch APIには2つの重要な利点があります:リアルタイムAPIとは完全に別のクォータシステムで動作する(バッチリクエストはRPM/RPD/IPM制限にカウントされない)ことと、すべての生成コストが50%割引になることです。トレードオフとして、バッチリクエストは24時間のSLAで非同期処理されるため、画像を即座に返す必要のないワークフローに最適です。
Batch APIのクォータはリクエスト/分ではなくキューに入れたトークンで測定され、低ティアでも制限は十分に高いです。Tier 1プロジェクトは最大1,000,000トークン分のバッチリクエストをキューに入れることができ、Tier 2では250,000,000、Tier 3では750,000,000となります(Google AI for Developersレート制限ページ、2026-03-09確認)。参考として、50〜100ワードの一般的な画像生成プロンプトは約70〜130トークンを使用するため、Tier 1のバッチキューには約7,700〜14,300の画像生成リクエストを同時に保持できます。
Pythonバッチ実装
以下は、バッチジョブの作成、完了のポーリング、生成された画像の取得を行う完全な動作例です:
pythonimport google.generativeai as genai import time genai.configure(api_key="YOUR_API_KEY") batch_requests = [] prompts = [ "A serene mountain landscape at sunset, photorealistic", "A futuristic city skyline with flying vehicles", "An underwater coral reef teeming with colorful fish" ] for i, prompt in enumerate(prompts): batch_requests.append({ "custom_id": f"img-{i}", "method": "POST", "url": "/v1beta/models/gemini-3.1-flash-image-preview:generateContent", "body": { "contents": [{"parts": [{"text": prompt}]}], "generationConfig": {"responseMimeType": "image/png"} } }) # Step 2: Submit batch job # Note: Use the REST API or batch-specific SDK methods # The exact SDK interface may vary — check current documentation import requests, json headers = {"Content-Type": "application/json"} api_url = "https://generativelanguage.googleapis.com/v1beta/batchJobs" response = requests.post( f"{api_url}?key=YOUR_API_KEY", headers=headers, json={"requests": batch_requests} ) job = response.json() job_name = job.get("name") print(f"Batch job created: {job_name}") # Step 3: Poll for completion while True: status_resp = requests.get(f"{api_url}/{job_name}?key=YOUR_API_KEY") status = status_resp.json() state = status.get("state", "UNKNOWN") print(f"Job state: {state}") if state in ("SUCCEEDED", "FAILED", "CANCELLED"): break time.sleep(30) # Check every 30 seconds # Step 4: Retrieve results if state == "SUCCEEDED": results = requests.get(f"{api_url}/{job_name}/results?key=YOUR_API_KEY") for result in results.json().get("responses", []): custom_id = result["custom_id"] # Process each generated image print(f"Image {custom_id} generated successfully")
Batch APIで作業する際のいくつかの実用的な考慮事項があります。24時間のSLAは最大値であり、実際にはほとんどのバッチジョブはキューの深さとジョブサイズに応じて、通常1〜4時間以内に大幅に速く完了します。アプリケーションは、ブロッキング待機を実装するのではなく、妥当な間隔(30〜60秒ごと)でジョブステータスをポーリングするように設計すべきです。バッチモードのエラー処理はリアルタイム呼び出しとは異なります:バッチ内の個々のリクエストは独立して失敗する可能性があるため、結果処理コードは各レスポンスのステータスを確認し、失敗した項目のリトライロジックを実装する必要があります。また、バッチキューのトークン制限は、すべてのキューに入った(まだ完了していない)ジョブをカウントするため、妥当な時間枠内で処理できる以上の作業を送信することは避けるべきです。
Batch APIが最も活躍するシナリオには、ECサイトの商品画像生成(一晩で数百の商品説明を処理)、コンテンツマーケティングパイプライン(SNSビジュアルの大量生成)、機械学習トレーニング用のデータセット作成があります。サブ秒のレスポンスではなく、数分から数時間の遅延を許容できるワークフローは、コスト削減と、429エラーを引き起こすリアルタイムレート制限の影響を受けないという両方の点から、Batch APIの利用を強く検討すべきです。コスト最適化のより広い視点については、Gemini画像レート制限の解決策ガイドをご参照ください。
解決策4 — マルチプロジェクトリクエスト分散
Gemini APIのレート制限はAPIキーごとではなくプロジェクトごとに適用されるため、複数のGoogle Cloudプロジェクトにリクエストを分散させることで、利用可能な総クォータを効果的に増倍させることができます。このアプローチは技術的に簡単です:N個のプロジェクトを作成し、それぞれにAPIキーを生成し、アプリケーションコードにラウンドロビンまたはロードバランシングの分散戦略を実装します。3つのプロジェクトで、ティアアップグレードや追加費用なしにRPM、RPD、IPM、TPMの制限を効果的に3倍にできます。
実装には、APIキーのプール(プロジェクトごとに1つ)を維持し、各リクエストで循環させる必要があります。以下は、分散と個々のプロジェクトが制限に到達した場合のフォールバックの両方を処理する本番環境対応の実装です:
pythonimport itertools import random class MultiProjectClient: def __init__(self, api_keys: list[str]): self.api_keys = api_keys self.key_cycle = itertools.cycle(api_keys) self.failed_keys = set() def generate_image(self, prompt, max_attempts=None): max_attempts = max_attempts or len(self.api_keys) * 2 for attempt in range(max_attempts): key = next(self.key_cycle) if key in self.failed_keys: continue try: genai.configure(api_key=key) model = genai.GenerativeModel("gemini-3.1-flash-image-preview") response = model.generate_content( prompt, generation_config={"response_mime_type": "image/png"} ) return response except Exception as e: if "429" in str(e): self.failed_keys.add(key) if len(self.failed_keys) >= len(self.api_keys): self.failed_keys.clear() # Reset and retry raise Exception("All projects rate limited") else: raise raise Exception("Max distribution attempts exceeded") # Usage client = MultiProjectClient([ "API_KEY_PROJECT_1", "API_KEY_PROJECT_2", "API_KEY_PROJECT_3" ]) result = client.generate_image("A beautiful sunset over the ocean")
1つの重要なアーキテクチャ上の考慮事項があります:各Google Cloudプロジェクトにそれぞれ独自の課金アカウントが有効になっていること(または少なくとも複数のプロジェクトにリンクされた単一の課金アカウントから課金を共有すること)を確認してください。これにより、各プロジェクトがそのティアのレート制限に独立して適格となります。複数のプロジェクトはGoogle Cloud Consoleのプロジェクトセレクターを通じて管理でき、1つのGoogleアカウントが所有できるプロジェクト数に実質的な制限はありません。
利用規約のコンプライアンスに関して:Googleのドキュメントには「レート制限はプロジェクトごとに適用される」と明記されており、プロジェクトごとのクォータ管理ツールが提供されていることから、ユーザーが複数のプロジェクトを運用することを暗黙的に認めています。適切な課金が設定された正当なGoogle Cloudプロジェクトである限り、このアプローチはいかなる規約にも違反しません。ただし、実用的な考慮事項を念頭に置く必要があります。複数プロジェクト間の課金管理、個別のクォータ監視、デプロイメントパイプラインの複雑さの増加に対処する必要があります。この解決策は、すでにマルチプロジェクトのGoogle Cloud環境で運用しているチームに最適です。
解決策5 — 無制限スループットのためのAPIプロキシ
アプリケーションがTier 3の制限を超える持続的な高スループットを必要とする場合、またはGoogle Cloud Platformに直接アクセスできない場合(特定の地域の開発者に一般的)、APIプロキシサービスが429エラーに対する最も包括的な解決策を提供します。APIプロキシは、多数のプロジェクトとティアにわたるAPIクレデンシャルの大規模なプールを維持し、単一のプロジェクトのレート制限に到達することを避けるためにリクエストを透過的に分散させます。アプリケーションの観点からは、単一のエンドポイントにAPI呼び出しを行い、プロキシがバックグラウンドですべてのレート制限管理を処理するため、429エラーを見ることはありません。
Gemini画像生成のAPIプロキシサービスを評価する際、いくつかの基準が重要です。まず、プロキシが必要な特定のモデルをサポートしているかを確認してください。すべてのサービスがgemini-3.1-flash-image-previewやその画像出力機能をサポートしているわけではありません。次に、料金体系を確認します:リクエストごと、トークンごと、画像ごとの定額制など、プロキシによって課金方法が異なります。第三に、API互換性を評価します。最良のプロキシはOpenAI互換のAPIフォーマットを提供しており、ロジックを書き直すことなく、既存コードのベースURLとAPIキーを変更するだけで切り替えられます。最後に、稼働時間SLA、地理的レイテンシー、サポートの応答性などの信頼性保証を考慮してください。
プロキシオプションを探している開発者向けに、laozhang.aiのようなサービスでは、解像度に関係なく1画像あたり約$0.05の定額でGemini画像生成を提供しています。これは、Googleの直接価格が$0.101〜$0.151の高解像度で大幅な節約となります。プラットフォームは複数のモデルとプロバイダーを集約し、レート制限を内部的に処理し、GCPアカウントを必要としません。コミットする前に画像生成プレイグラウンドで直接テストできます。
ほとんどのAPIプロキシはOpenAI互換のエンドポイントを公開しているため、統合プロセスは驚くほど簡単です。多くの場合、Google APIへの直接アクセスからプロキシへの切り替えは、コード内の2つの設定値(ベースURLとAPIキー)を変更するだけで済みます。既存のプロンプトフォーマット、エラーハンドリング、レスポンスパースのロジックは通常、変更なしで動作します。以下は、プロキシ統合が直接APIとどのように異なるかを示す最小限の例です:
python# Direct Google API import google.generativeai as genai genai.configure(api_key="GOOGLE_API_KEY") model = genai.GenerativeModel("gemini-3.1-flash-image-preview") # Via API Proxy (OpenAI-compatible format) from openai import OpenAI client = OpenAI( api_key="PROXY_API_KEY", base_url="https://api.laozhang.ai/v1" ) response = client.chat.completions.create( model="gemini-3.1-flash-image-preview", messages=[{"role": "user", "content": "A sunset over mountains"}] )
APIプロキシがユースケースに適しているかどうかを判断するために、以下の判断フレームワークを検討してください。信頼性の高いGCPアクセスがあり、ボリュームがティアの制限内に収まり、直接的なGoogle SLAによる最大限のデータプライバシーが必要な場合は、Google直接APIを使用してください。GCPアクセスが制限された地域にいる場合、ティアアップグレードで提供できる以上のスループットが必要な場合、GCPプロジェクトを管理せずに簡素化された課金を求める場合、またはプロトタイプ構築中にGCPのセットアップオーバーヘッドを完全に避けたい場合は、APIプロキシを使用してください。さまざまなプロバイダーの最安値Gemini Flash画像APIオプションについては、現在の比較ガイドをご確認ください。
最適な解決策の選択 — 比較表とFAQ
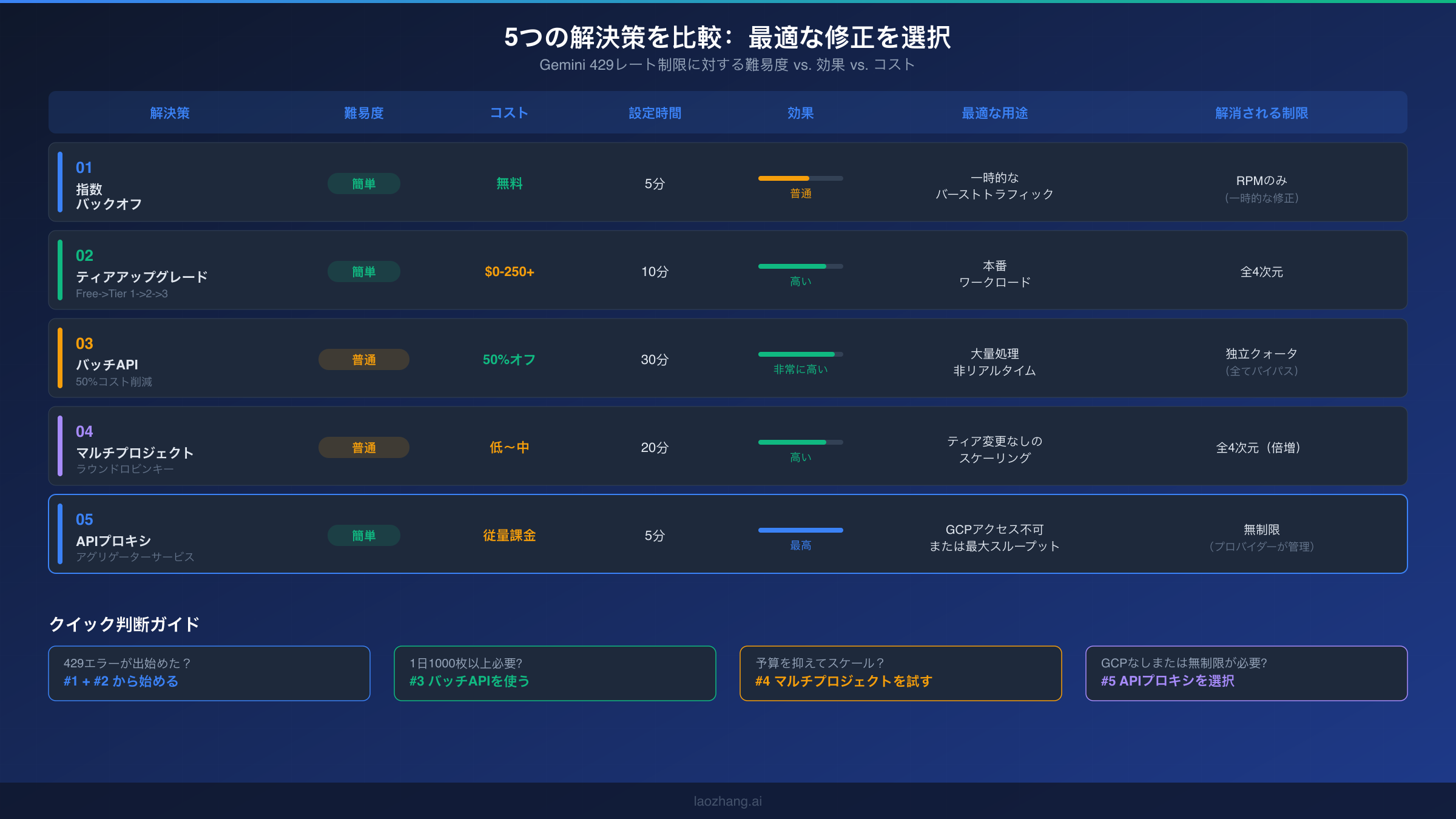
最適な解決策は、状況によって異なります:エラーをどれだけ緊急に修正する必要があるか、予算の制約、技術インフラ、長期的なスループット要件によって変わります。ほとんどの本番デプロイメントでは、複数の解決策を組み合わせることが有益です。たとえば、指数バックオフ(解決策1)をベースラインのセーフティネットとして実装しながら、Tier 1またはTier 2(解決策2)にアップグレードして持続的な容量を確保するといった方法です。
以下は、5つの解決策が最も重要な判断要素でどのように比較されるかの要約です。解決策1と2は、すべてのプロジェクトが実装すべき基盤です。バックオフは回復力のため、ティアアップグレードは容量のためです。解決策3、4、5はスケーリング戦略であり、それぞれ異なる制約に対処します:レイテンシーが重要でない場合のコスト最適化にはBatch API、Googleのエコシステム内での無料スケーリングにはマルチプロジェクト、最大限のシンプルさと無制限スループットにはAPIプロキシです。
無料ティアで429エラーに遭遇し始めたGemini画像生成の初心者開発者にとって、最も速い解決パスは次のとおりです:まず、即座のエラーをグレースフルに処理するために指数バックオフを実装します。次に、プロジェクトで課金を有効にしてTier 1に到達します。これが最もインパクトのある単一の変更であることが多く、4つのすべての次元でクォータが劇的に増加します。これら2つのステップで、大多数の開発および中規模以下の本番ワークロードの429エラーが解消されます。
1日数千枚の画像を生成する大量の本番ワークロードの場合、最適な戦略はレイテンシー要件に依存します。画像を非同期で生成できる場合(ECカタログ、マーケティングコンテンツパイプライン、MLトレーニングデータ)、Batch API(解決策3)が50%割引と独立クォータプールで最高のコスト効率を提供します。リアルタイムの大規模画像生成が必要な場合、ティアアップグレード(解決策2)とマルチプロジェクト分散(解決策4)を組み合わせて、効果的な制限を増倍させてください。レート制限を完全に排除したい場合は、APIプロキシ(解決策5)がすべてのクォータ管理をプロバイダーにオフロードします。
よくある質問
Gemini APIの429レート制限はどのくらい続きますか?
RPM、TPM、IPM制限のウィンドウはローリング60秒です。リクエストの送信を停止すれば、1分以内にクォータが更新されます。RPD制限の場合、太平洋時間の深夜に日次カウンターがリセットされるまで待つ必要があります。レート制限カウンターを手動でリセットする方法はなく、自然なリセットを待つか、ティアアップグレードで制限を増やすかの選択肢しかありません。
Googleからレート制限の免除を受けることはできますか?
GoogleはGemini APIの個別のレート制限免除を提供していません。ティアシステムが制限を増やすための指定されたパスです。Tier 3を超える制限が必要な場合、推奨されるアプローチはGoogle Cloudの営業にエンタープライズ契約について問い合わせることです。カスタムクォータの割り当てが含まれる場合があります。
同じプロジェクトで複数のAPIキーを使用すると効果がありますか?
いいえ。レート制限はAPIキーごとではなく、プロジェクトごとに適用されます。単一のプロジェクト内に追加のキーを作成しても、どの次元でもクォータは増加しません。複数のキーのメリットを得るには、各キーが異なるGoogle Cloudプロジェクトに属している必要があります(解決策4を参照)。
429エラーと503エラーの違いは何ですか?
429エラーは割り当てられたクォータを超過したことを意味し、クォータが更新されるのを待つか制限を増やす必要があります。503エラーはGoogleサービス自体が一時的に利用できないことを意味し、使用量とは無関係です。503エラーには、通常1〜5秒後のシンプルなリトライで十分です。429エラーには、このガイドに記載されたターゲットを絞った解決策が必要です。
Batch APIは常に50%安くなりますか?
GoogleのBatch API料金は、導入以来一貫してリアルタイムAPI価格の50%に設定されています。価格は変更される可能性がありますが、この割引はバッチ処理の使用を促進するためのものであり、Googleのインフラストラクチャにとってより効率的です。コスト予測を行う前に、Geminiの公式料金ページで現在の価格をご確認ください。
レート制限の使用量をリアルタイムで監視するにはどうすればよいですか?
Google Cloud Consoleの「IAMと管理」>「割り当て」でリアルタイムのクォータ監視が提供されています。「generativelanguage.googleapis.com」サービスでフィルタリングすると、使用量グラフ付きのすべてのGemini APIクォータが表示されます。設定可能なしきい値(例:使用量80%)でクォータアラートを設定することもでき、429エラーが本番環境で発生し始める前の早期警告が得られます。プログラム的な監視には、Cloud Monitoring APIを使用してクォータ使用量メトリクスをクエリし、既存のダッシュボードやアラートシステムに統合できます。
無料ティアの制限を支払いなしで増やす方法はありますか?
ありません。無料ティアの制限は固定されており、2025年12月に大幅に削減されました。レート制限を増やす唯一の方法は、プロジェクトで課金を有効にする(Tier 1にアップグレード)か、解決策4で説明したマルチプロジェクト分散アプローチを使用することです。Googleは時折無料ティアのクォータを調整しますが、サービスがスケールアップするにつれて制限が厳しくなる傾向があり、無料ティアは本番ワークロードよりも開発と実験に主に適しています。