
先に結論です。 Claude 529 overloaded_error は、たいてい Anthropic が一時的に過負荷状態にあるか、リクエスト経路の上流サービスが飽和していることを意味します。だから最初にやるべきことは prompt を書き換えることでも API key を回すことでもなく、Claude の live status と recent incidents を確認することです。API 利用なら次に backoff 付き retry、Claude chat や Claude Code なら plan limit や chat 側 capacity warning と取り違えていないかも確認する必要があります。
この違いは 2026 年では特に重要です。Anthropic の release notes によると、2025 年 8 月 11 日以降、以前は 529 overloaded_error になっていた一部の急激な usage spike が、今は 429 rate_limit_error として返るようになりました。つまり、今の 529 ガイドは「少し待って再試行」で終わってはいけません。まず、どの種類の失敗なのかを切り分ける必要があります。
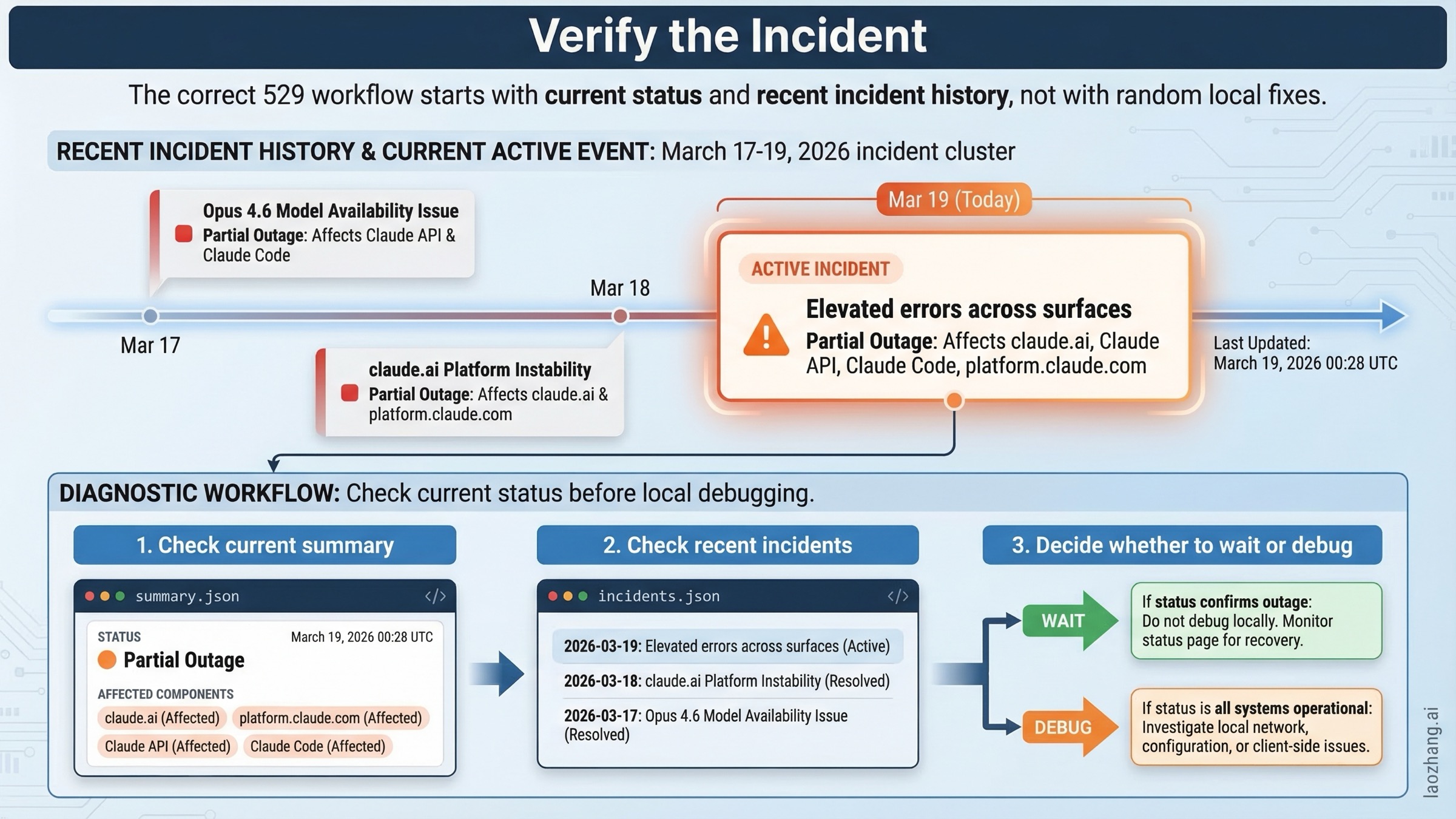
しかもこれは理論だけの話ではありません。Anthropic の public status feed は 2026 年 3 月 19 日 00:28 UTC に “Elevated errors across surfaces” という incident を開き、claude.ai、platform.claude.com、Claude API、Claude Code を partial outage として表示しました。さらにこの記事の最終確認時点である 01:21 UTC には、その incident はすでに monitoring に移っており、Anthropic は 23:59-00:30 UTC のあいだに認証エラーが増えたと説明していました。こういう場面で検索ユーザーに必要なのは、抽象的な説明よりも診断フローです。
要点まとめ
Claude 529 overloaded_error は、ふつう Anthropic 側の overload signal であり、あなたの request format が間違っている証拠ではありません。まず status.claude.com と incidents feed を見てください。この記事の最終確認時点である 2026 年 3 月 19 日には、Anthropic の summary はまだ Minor Service Outage を示していましたが、“Elevated errors across surfaces” はすでに investigating から monitoring に移り、23:59-00:30 UTC の認証エラー区間として説明されていました。あなたが確認したタイミングで platform が healthy なら、jitter 付き retry と concurrency の抑制に進みます。もし実際のエラーが 429 なら rate limiting の問題として扱ってください。Claude chat に “Due to unexpected capacity constraints...” が出ている場合、Anthropic の公式サポート文書ではそれは formal outage ではなく、status page にも出ない可能性があると説明されています。
| シグナル | 何を意味することが多いか | 出やすい場所 | 最初のアクション |
|---|---|---|---|
529 overloaded_error | Anthropic または upstream service の一時的な過負荷 | API、Workbench、Claude Code、Anthropic を使う統合先 | status を確認し、backoff 付き retry、request ID を保存 |
429 rate_limit_error | 組織レベルで RPM / ITPM / OTPM / acceleration limit に到達 | API と API ベースのツール | retry-after を尊重し、burst を下げる。詳細は /en/posts/claude-api-quota-tiers-limits |
| “Due to unexpected capacity constraints...” | Claude chat 側の高負荷 | claude.ai | 数分待って更新。outage と同一ではない |
| “5-hour limit reached” | プランの利用枠が切れた | Claude chat / Claude Code の subscription flow | reset を待つか /ja/posts/claude-code-rate-limit を確認 |
Claude 529 Overloaded Error の本当の意味
Anthropic が 529 overloaded_error を返すとき、それは多くの場合「今は容量的に安定して処理できない」という意味です。これは malformed request、expired key、permission error とは別の話です。実際には、platform 全体が重い時間帯、特定モデルの backend が混んでいる時間、あるいは Claude Code / Workbench の裏側が詰まっているときに 529 を見かけやすくなります。
このクエリの検索意図が強く不安寄りなのはそのためです。作業の途中で 529 が出ると、ユーザーはまず「自分のせいなのか、Anthropic 側なのか」を知りたくなります。ところが page one の多くは “他の人も起きている” という reassurance で止まってしまい、次に何をすべきかまで落とし込めていません。
Anthropic の help center、API docs、release notes をまとめて読むと、実用上の分類はかなり明快です。
529は service overload か temporary upstream saturation を指すことが多い429は rate limiting を指す- chat capacity warning は Claude chat の利用体験側の問題
- 5-hour limit は plan quota の問題
重要なのは定義を覚えることではなく、どのクラスかを先に見誤らないことです。
529 と 429、capacity constraints、usage limit の違い

ユーザーがこのテーマで時間を浪費しやすい最大の理由は、Anthropic には複数の「今は使えません」状態があるのに、それらが同じ層に属していないからです。
Anthropic の公式記事 understanding Claude error messages では、chat-side の capacity constraints は一時的な高負荷状態であり、status page には表示されない と説明されています。つまり、Claude chat が重いのに status page が緑でも、それだけでローカル原因とは限りません。
一方で API 側は別です。rate limits docs では、組織単位の制限がより短い時間粒度でも enforcement されると説明されています。さらに release notes の 2025 年 8 月 11 日の変更で、一部の sudden usage spike は 529 ではなく 429 を返すようになりました。
そのため、古いコミュニティ投稿にある「529 と 429 はほぼ同じ」という理解は、2026 年の診断では精度不足です。
| 条件 | レイヤー | 典型原因 | やってはいけないこと |
|---|---|---|---|
529 overloaded_error | Anthropic service / upstream capacity | 一時的な overload、live incident、backend の混雑 | 正しいコードや key をすぐ疑う |
429 rate_limit_error | 組織の API usage behavior | tier limit、RPM/TPM 圧力、burst | platform outage と決めつける |
| capacity-constraint banner | Claude chat product layer | chat の高負荷 | status page が赤くないからといって否定する |
| 5-hour limit message | plan quota | 利用枠の消化 | login や network 設定を延々と触る |
Claude Code ユーザーなら、subscription limit と API-side issue の違いも押さえておくと役に立ちます。詳しくは /ja/posts/claude-code-rate-limit を参照してください。
まず status を見る: Anthropic の real incident を確認する方法
この検索で最初に役立つのは定義ではなく status workflow です。
まず status.claude.com を見てください。必要なら次の machine-readable feed も直接確認します。
https://status.claude.com/api/v2/summary.jsonhttps://status.claude.com/api/v2/incidents.json
これらの endpoint が便利なのは、claude.ai、platform.claude.com、Claude API、Claude Code といった component 別の情報を出せるからです。
2026 年 3 月 19 日に再確認した時点では、summary endpoint は完全な green ではなく Minor Service Outage を表示しており、主要 component は partial outage でした。さらに 01:21 UTC の更新では、“Elevated errors across surfaces” は monitoring に変わり、23:59-00:30 UTC の認証エラーが原因帯として示されていました。incidents feed を見ると、2026 年 3 月 17 日から 19 日のあいだに複数の関連インシデントが続いていました。たとえば:
- 2026 年 3 月 17 日: Claude Opus 4.6 の elevated errors
- 2026 年 3 月 18 日: Claude Opus 4.6 の elevated errors
- 2026 年 3 月 18 日: Opus 4.6 の increased errors
- 2026 年 3 月 18 日: Claude.ai の elevated errors(Claude Code にも影響)
- 2026 年 3 月 19 日: “Elevated errors across surfaces” が 00:28 UTC に始まり、01:21 UTC に monitoring へ移行
この事実があるので、「30 秒待って retry」という advice だけでは足りません。短い incident ならそれで復帰することもありますが、real outage window の中にいるなら、無駄にローカル診断を深掘りするだけです。
実務上の注意点もあります。anthropics/claude-code の Issue #1838 では、ユーザーが overloaded_error を見ているのに dashboard の反映が遅れていたケースが報告されています。status page は重要ですが、事故の最初の数分で絶対視しすぎないほうがいい、という程度の理解がちょうどいいです。
おすすめの順番は次の通りです。
- summary を見る
- incidents を見る
- 1 surface だけなのか、1 model family だけなのか、workflow 全体なのかを切り分ける
- status がまだ green でも外部報告が増えているなら、破壊的な変更は避けつつ保守的に retry する
production で使うなら dashboard UI だけでなく JSON feed を monitoring に入れるべきです。
最初の 10 分でやるべきこと
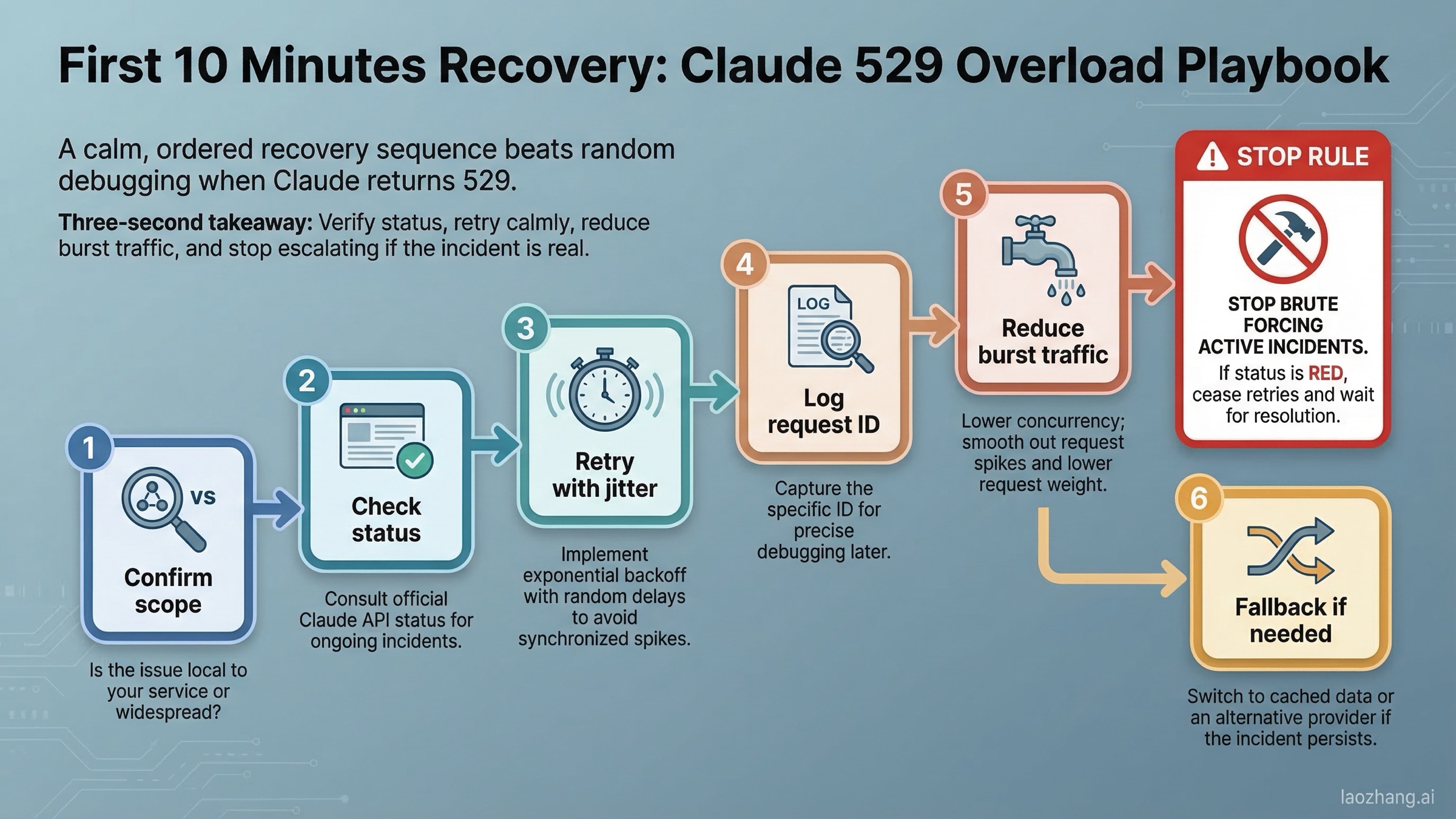
API、Workbench、Claude Code で 529 が出たら、次の順番が実用的です。
1. まず広域障害か局所問題かを確認する。 Claude chat と API の両方が怪しいなら platform-side incident の可能性が高くなります。1 つの integration path だけなら upstream か local chain の確認も必要です。
2. retry は jitter 付きで、感情的に連打しない。 transient overload は retry が合理的な数少ないケースですが、叩き続けると悪化します。指数 backoff に小さな random jitter を加えてください。Anthropic の Python SDK docs では、connection errors、408、409、429、>=500 に対して 2 回の自動 retry がデフォルトだと説明されています。
3. request ID を残す。 _request_id を記録しておくと support や後追い分析がかなり楽になります。
4. burst を下げる。 rate limits docs にある通り、より短い interval でも enforcement はあり、API は token-bucket で動いています。529 を見ている時でも、急激な concurrency spike を抑えるのは有効です。
5. 本当に 429 ではないか確認する。 error body や SDK exception が RateLimitError なら、問題は overload ではなく rate limiting です。その場合は /en/posts/claude-api-429-solution の方が近いです。
6. request weight を一時的に下げる。 巨大な context window、大量の tool output、重い添付があるなら、一時的に軽くしてください。
7. code だけでなく timing も変える。 ある model family が悪い時間帯なら、10〜20 分待つ方が、不要な retry を積むより賢いことが多いです。
pythonimport time import random from anthropic import Anthropic, APIStatusError, RateLimitError client = Anthropic(max_retries=2) def call_with_jitter(messages, max_attempts=5): for attempt in range(max_attempts): try: return client.messages.create( model="claude-sonnet-4-6", max_tokens=1024, messages=messages, ) except RateLimitError: # 429: generic overload ではなく rate limiting として扱う raise except APIStatusError as e: if e.status_code == 529: delay = min(2 ** attempt, 20) + random.uniform(0, 1) time.sleep(delay) continue raise raise RuntimeError("Claude remained overloaded after retries")
大切なのは brute force ではなく graceful degradation です。
Claude chat / Claude Code ユーザーが確認すべきこと
このキーワードで来る人の多くは raw API を叩いているわけではありません。claude.ai、Claude Code、Workbench、Cursor、MCP chain など、最終的に Anthropic に到達するツールの中で詰まっています。だから troubleshooting sequence も少し変わります。
Claude chat では、Anthropic の help docs が capacity warning は temporary だと説明しています。もし見えているのが chat-side warning なら、数分待って refresh するのが基本で、延々と browser settings を疑うべきではありません。5-hour limit はそれとは別で、plan budget を使い切っただけです。
Claude Code では、login trouble、history の不整合、より広い outage の兆候がないかも見てください。実際に 2026 年 3 月 18 日の incident update では、Claude.ai 側の障害が Claude Code の login/logout にも影響したと記録されています。つまり、Claude Code だけが悪そうに見えても、実際には wider Anthropic incident かもしれません。
もし Claude Code の前に MCP server や local bridge が入っているなら、その layer も確認しましょう。元のエラーが包まれて symptom がぼやけることがあります。関連背景は /en/posts/claude-mcp-complete-guide-2025 が参考になります。
実践的なルールは次の通りです。
- Anthropic 全体が不安定なら incident と考える
- subscription flow だけなら chat capacity か plan limit を疑う
- API automation だけならまず 529 と 429 を分ける
将来の 529 を減らすには
provider-side overload を完全になくすことはできませんが、被害を小さくすることはできます。
第一は traffic shape です。ゼロから最大 concurrency へ一気に上げないこと。Anthropic docs は、burst traffic が average が低くても problems を起こしうると明言しています。
第二は prompt と context の節度 です。軽い request は retry しやすく、timeout など別の問題も重ねにくくなります。
第三は cache と reuse。同じ大きな prefix を毎回送り直す設計は、コストも failure surface も増やします。
第四は tier strategy。Anthropic の service tiers docs によると、Priority Tier は production workload を想定しており、peak time の server overloaded errors を減らす助けになります。outage-proof ではありませんが、Standard を本番 SLA のように扱うべきではない、という合図です。
第五は fallback architecture。1 provider の bad hour でワークフロー全体が止まるなら、それは vendor problem であると同時に設計問題でもあります。重要なのは特定ブランドではなく設計です。redundancy が必要なワークフローなら、次の incident window の前に二次ルートを準備しておくべきです。
第六は monitoring。incidents feed の polling、request ID の保存、model ごとの error spike の追跡は、Reddit や GitHub よりもはるかに役立ちます。
もし recurring 529 が実は rate limit 設計や burst control の問題を隠しているなら、次は /en/posts/claude-api-quota-tiers-limits を読むと整理しやすいです。
FAQ
Claude 529 overloaded_error は自分のせいですか? 通常は違います。多くは Anthropic 側か upstream service の一時的な飽和です。もちろん、過剰な retry で症状を悪化させることはありますが、エラーの存在自体は service pressure を示す場合が多いです。
529 はどれくらい続きますか? 固定時間はありません。数分で戻ることも、もっと長引くこともあります。正しく見るべきなのは live incidents feed です。
すぐ retry すべきですか? はい。ただし backoff と jitter を付けてください。1〜2 回の落ち着いた retry は妥当ですが、parallel retry flood は逆効果です。
529 と 429 は同じですか? いいえ。2026 年時点では別の diagnosis path と考えるべきです。429 は rate limit、529 は通常 overload です。
Claude chat が壊れているのに status page が正常なのはなぜですか? Anthropic の help docs が、chat-side capacity constraints は formal outage ではなく status page にも出ないと説明しているからです。
コーディング中に起きたときの最短安全ルートは? status を確認し、作業を保存し、backoff 付き retry を行い、incident が続くなら fallback model や fallback endpoint に切り替えることです。Claude Code を重く使う人ほど、第二の経路を事前に持っておく価値が大きいです。