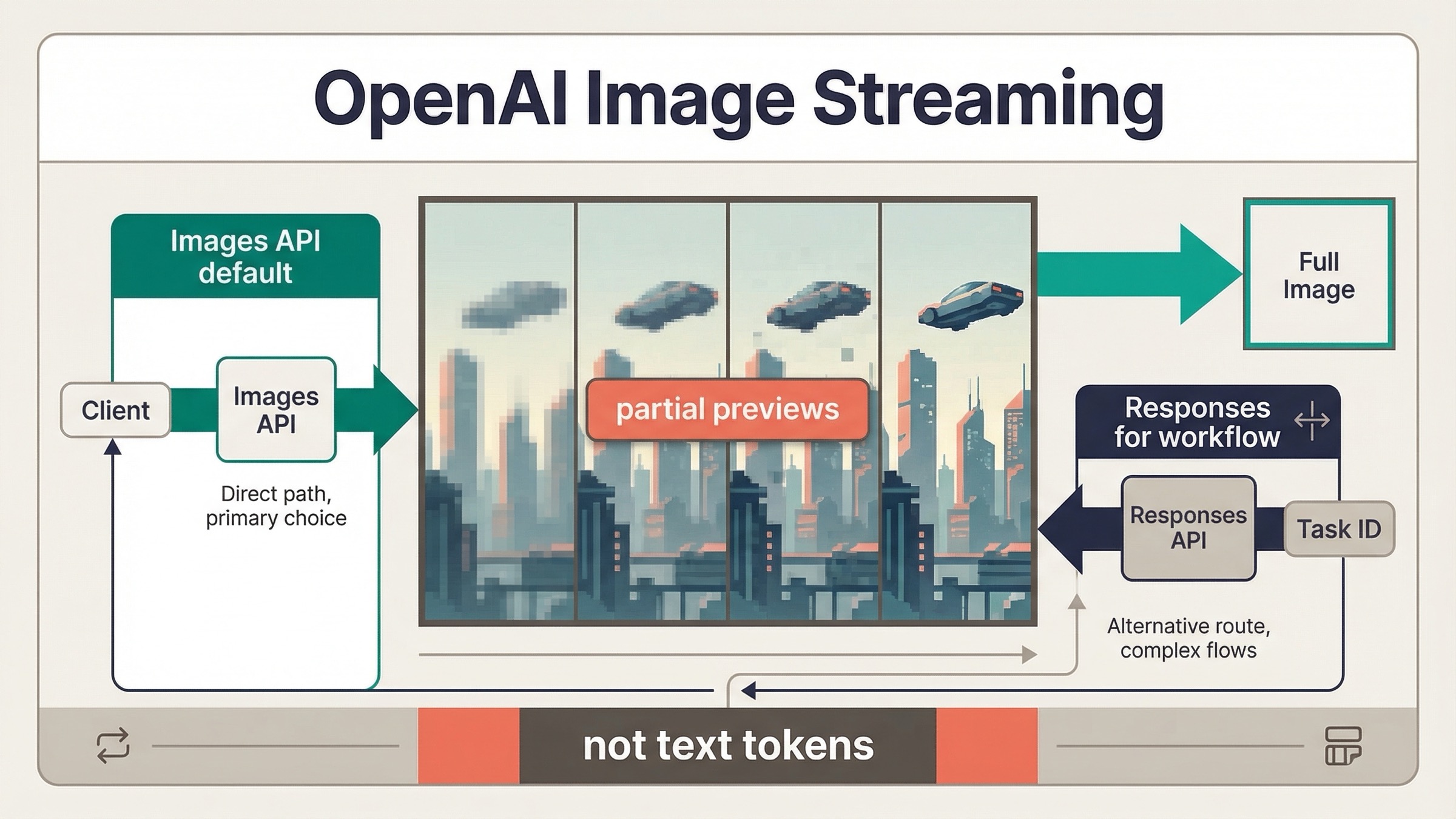
A 23 de marzo de 2026, OpenAI image generation sí soporta streaming, pero el comportamiento actual no se parece al token streaming de texto. Lo que OpenAI documenta hoy son partial-image previews que llegan mientras la imagen final todavía se está generando. Esa diferencia importa porque cambia tanto lo que tu UI puede prometer como la superficie de API que deberías conectar primero.
Si estás construyendo una direct image feature, el default más seguro ahora mismo es simple: empieza con Images API y transmite partial previews desde client.images.generate(). Si la generación de imágenes es solo una herramienta dentro de un assistant o multimodal workflow más amplio, entonces tiene sentido usar Responses API con el hosted image_generation tool. Muchas páginas flojas siguen mezclando esas dos rutas, y por eso este keyword continúa pareciendo más confuso de lo que debería.
La otra razón por la que este tema sigue enredado es que las páginas oficiales de OpenAI no describen streaming desde el mismo nivel. El image generation guide actual documenta streaming tanto en Responses API como en Images API. Al mismo tiempo, la página actual de GPT Image 1.5 todavía muestra Streaming: Not supported en la tabla de features del model card. Si abres esas páginas en el orden equivocado, parece que la documentación se contradice. Este artículo existe justo para resolver esa fricción antes de que pierdas tiempo depurando la capa equivocada.
Resumen rápido
- Sí, OpenAI image generation ahora hace streaming, pero lo que fluye son partial-image previews, no text tokens.
- Usa Images API primero si la generación de imágenes es la feature principal.
- Usa Responses API solo cuando la generación de imágenes sea una herramienta dentro de un assistant o multimodal flow más grande.
- Los event names cambian según la superficie:
image_generation.partial_imageen Images API yresponse.image_generation_call.partial_imageen Responses API. - No des por hecho que siempre recibirás todos los previews que pediste. El guide actual dice que
partial_imagespuede ir de0a3y que las generaciones rápidas pueden devolver menos previews de los solicitados.
Lo primero que hay que entender: qué significa hoy OpenAI image streaming
La forma más fácil de equivocarse con este keyword es importar la mental model de text generation. Cuando un developer pregunta si OpenAI image generation "hace streaming", normalmente está intentando confirmar una de estas dos cosas:
- si puede mostrar feedback visual progresivo antes de que termine la imagen final
- si el image model se comporta como un text model que va emitiendo chunks pequeños hasta completar la respuesta
La respuesta actual de OpenAI es sí a la primera y no a la segunda. El image generation guide vigente dice que tanto Responses API como Image API soportan streaming image generation y define ese soporte alrededor de partial images, no de tokens de texto. El mismo guide aclara que partial_images puede fijarse entre 0 y 3, y advierte que podrías recibir menos previews de los que pediste si la imagen final termina demasiado rápido.
Eso significa que la expectativa correcta no es "voy a recibir un flujo estable de microincrementos hasta el último píxel". La expectativa correcta es "puedo pedir un pequeño conjunto de preview images mientras la generación sigue corriendo y luego pasar a mi flujo normal de imagen final". Eso sigue siendo muy útil para UX, sobre todo si quieres que la generación de imágenes se sienta menos opaca, pero el contrato es más estrecho de lo que muchos developers asumen cuando oyen la palabra streaming.
Por eso la primera decisión de implementación importa tanto. Si tu producto solo necesita un prompt, unas pocas preview frames y una imagen final, la ruta directa con Images API mantiene el modelo mental limpio. Si tu producto necesita conversation state, tool orchestration o image generation como una etapa dentro de un workflow más grande, entonces Responses API sí encaja mejor. La documentación actual soporta ambas. El error es tratarlas como si fueran puntos de partida igual de buenos para cualquier proyecto.
Images API vs Responses API: elige la superficie correcta para streaming
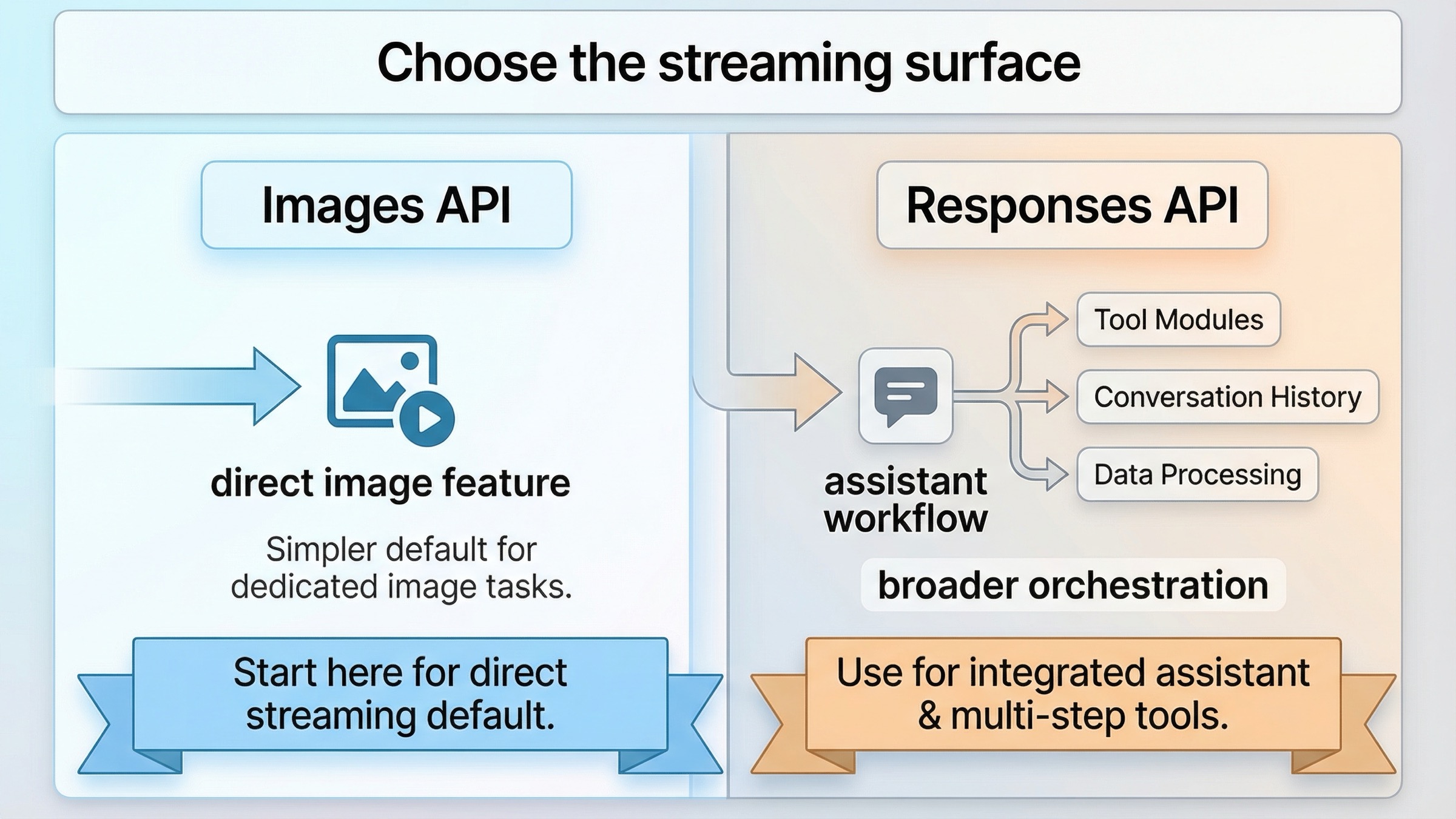
Este keyword se vuelve mucho más sencillo cuando dejas de preguntar "qué endpoint es más nuevo" y empiezas a preguntar "qué superficie encaja con el producto que estoy enviando hoy".
| Situación | Mejor default | Por qué |
|---|---|---|
| Estás construyendo una direct image feature y quieres previews más la imagen final | Images API | La forma de la request es más limpia, eliges el image model de manera explícita y el event loop es el más simple para image-only work |
| Necesitas image generation dentro de un assistant o multimodal flow más amplio | Responses API | La imagen pasa a ser una herramienta dentro de un workflow mayor de reasoning o conversación |
| Quieres la prueba más rápida de que streaming funciona en tu cuenta | Images API | Hay menos moving parts, menos decisiones de ruta y todavía no necesitas pensar en tool orchestration de nivel superior |
| Necesitas que el mainline model revise prompts o coordine otras tools alrededor del output de imagen | Responses API | El hosted image_generation tool encaja mejor cuando la imagen no es el único output |
| Estás depurando por primera vez la confusión de docs | Primero Images API, luego Responses si hace falta | Elimina una capa completa de incertidumbre antes de que tengas que depurar event handling u orchestration |
La regla práctica es directa. Si la generación de imágenes es la feature, empieza por la ruta directa. Usa Images API, confirma que llegan los partial previews y añade la capa de Responses solo si el producto realmente la necesita. Si la generación de imágenes es una herramienta entre varias, entonces sí tiene sentido empezar con Responses, porque ahí el workflow alrededor ya es el punto.
El images and vision guide actual respalda esa separación. Dice que los developers pueden generar o editar imágenes usando Image API o Responses API, y su ejemplo de Responses utiliza un mainline model como gpt-4.1-mini junto con el hosted image_generation tool. Esa es una pista fuerte de cómo OpenAI espera que funcione esa ruta: el mainline model orquesta y la generación de imágenes es una herramienta dentro del flujo mayor.
La ruta más rápida que sí funciona: empezar por Images API
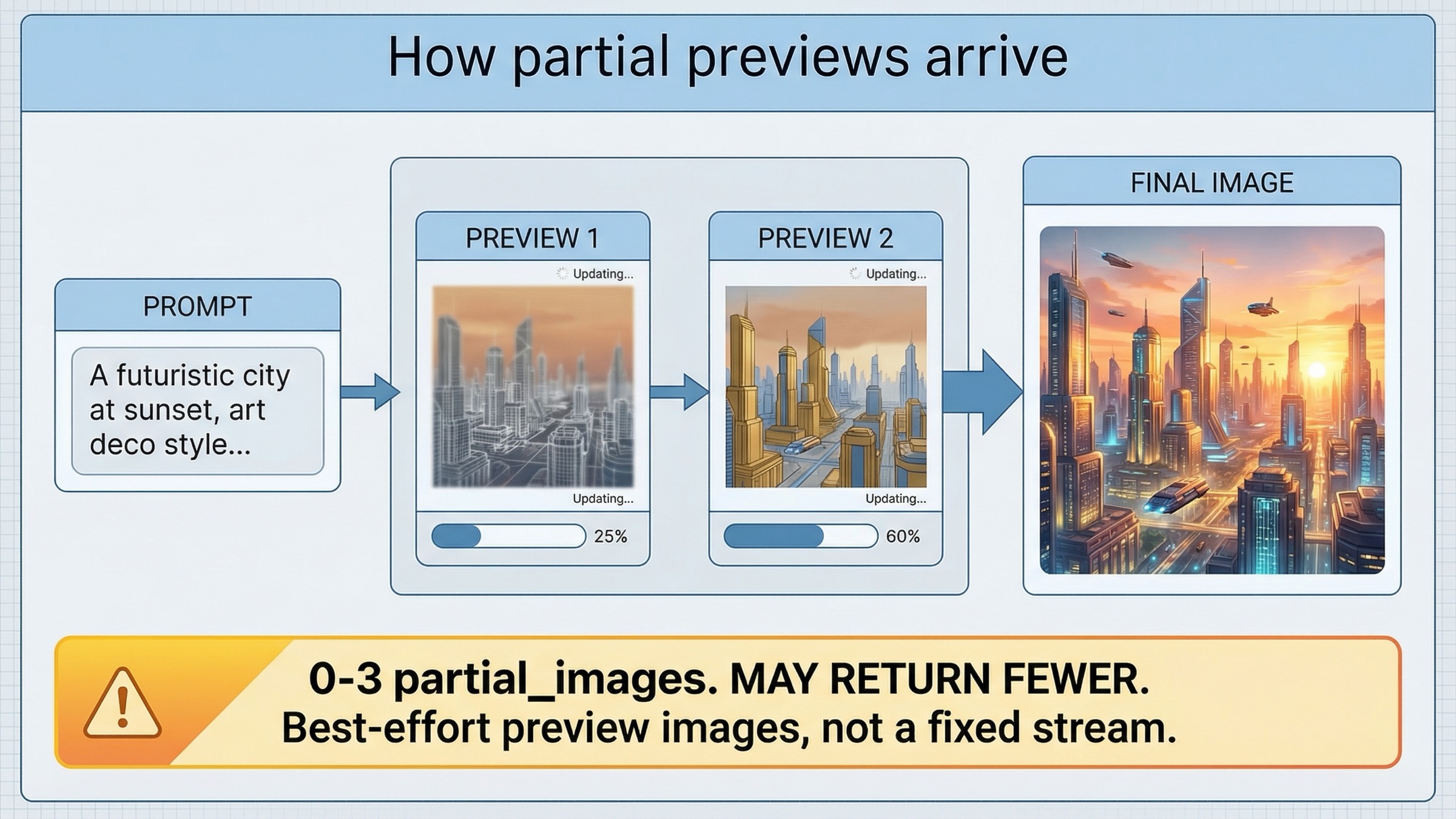
Si tu objetivo es demostrar rápido que el path de streaming existe de verdad, Images API sigue siendo el mejor punto de partida. El guide actual muestra el patrón directo con gpt-image-1.5, stream: true y partial_images: 2. Esa es la ruta que yo le daría a un developer que quiere el camino más honesto hacia un primer éxito.
En JavaScript:
jsimport fs from "fs"; import OpenAI from "openai"; const client = new OpenAI({ apiKey: process.env.OPENAI_API_KEY, }); const stream = await client.images.generate({ model: "gpt-image-1.5", prompt: "Create a clean editorial illustration of a camera drone hovering over a bright city skyline at sunrise", stream: true, partial_images: 2, }); for await (const event of stream) { if (event.type === "image_generation.partial_image") { const index = event.partial_image_index; const imageBytes = Buffer.from(event.b64_json, "base64"); fs.writeFileSync(`preview-${index}.png`, imageBytes); } }
En Python:
pythonfrom openai import OpenAI import base64 client = OpenAI() stream = client.images.generate( model="gpt-image-1.5", prompt="Create a clean editorial illustration of a camera drone hovering over a bright city skyline at sunrise", stream=True, partial_images=2, ) for event in stream: if event.type == "image_generation.partial_image": index = event.partial_image_index image_bytes = base64.b64decode(event.b64_json) with open(f"preview-{index}.png", "wb") as f: f.write(image_bytes)
Esta es la prueba correcta por tres razones.
La primera es que demuestra la ruta más simple posible. Estás eligiendo de forma explícita el current image model, pides un número pequeño de previews y escuchas un único event type específico de imágenes. Eso es exactamente lo que quieres cuando la pregunta es "funciona el streaming para mi feature de imagen" y no "cómo orquesto un agent entero".
La segunda es que te deja un árbol de depuración mucho más limpio. Si no llega ningún preview, puedes revisar account access, model choice o event handling sin preguntarte si el problema vive en un Responses workflow más amplio. La página actual de GPT Image 1.5 todavía marca Free not supported, y las rate limits para image use arrancan en Tier 1 con 100,000 TPM y 5 IPM, así que conviene despejar supuestos de acceso antes de culpar al SDK.
La tercera es que fija la expectativa correcta en la UI. El guide dice que puedes pedir entre 0 y 3 partial images, pero también aclara que podrías no recibir todos los que solicitaste si la imagen final se genera rápido. Eso es una señal de progreso, no un contrato de frames garantizados. Si tu producto puede manejar esa semántica con honestidad, la ruta directa con Images API suele bastar.
Si después de esta duda de streaming quieres un manual más amplio para direct generation y edits, lo natural es seguir con nuestro tutorial de OpenAI Image API. Para esa pregunta general, sigue siendo la mejor página de arranque.
Cuándo Responses API sí es la mejor ruta
La ruta de Responses no es incorrecta. Lo que pasa es que normalmente no es el primer default correcto para este keyword salvo que tu workflow la necesite de verdad.
El image generation guide actual muestra la generación de imágenes en streaming con Responses más o menos así:
jsimport fs from "fs"; import OpenAI from "openai"; const client = new OpenAI({ apiKey: process.env.OPENAI_API_KEY, }); const stream = await client.responses.create({ model: "gpt-5", input: "Create a transparent sticker-style icon of a paper airplane for a travel app", stream: true, tools: [{ type: "image_generation", partial_images: 2 }], }); for await (const event of stream) { if (event.type === "response.image_generation_call.partial_image") { const index = event.partial_image_index; const imageBytes = Buffer.from(event.partial_image_b64, "base64"); fs.writeFileSync(`preview-${index}.png`, imageBytes); } }
Ese path merece la pena cuando la imagen no es lo único que importa. Buenos ejemplos serían:
- un multimodal assistant que a veces devuelve texto y otras veces imágenes
- un workflow en el que el mainline model decide cuándo activar image generation
- un sistema en el que conviene que el mainline model revise el prompt o coordine otras tools antes de llamar al image tool
El guide actual deja ver esa capa extra de forma directa. En Responses API, el mainline model puede revisar el prompt que se usa en la llamada de image generation y después puedes inspeccionar el campo revised_prompt en la llamada completada. Eso es útil cuando el valor del producto está en el workflow alrededor y no solo en la sencillez de la ruta.
Pero aquí sigue habiendo una trampa habitual: no trates Responses como si fuera la superficie donde debes poner gpt-image-1.5 en el campo model solo porque el output final sea una imagen. La documentación actual plantea la generación de imágenes en Responses alrededor de un mainline model como gpt-4.1 o gpt-5 más el hosted image_generation tool. Si fuerzas la mental model equivocada sobre esa surface, acabarás depurando un route problem como si fuera un streaming problem.
Por eso la recomendación correcta no es "Responses es más moderno, úsalo en todo". La recomendación correcta es "Responses es mejor cuando la feature es la orchestration; Images API es mejor cuando la feature es la image generation".
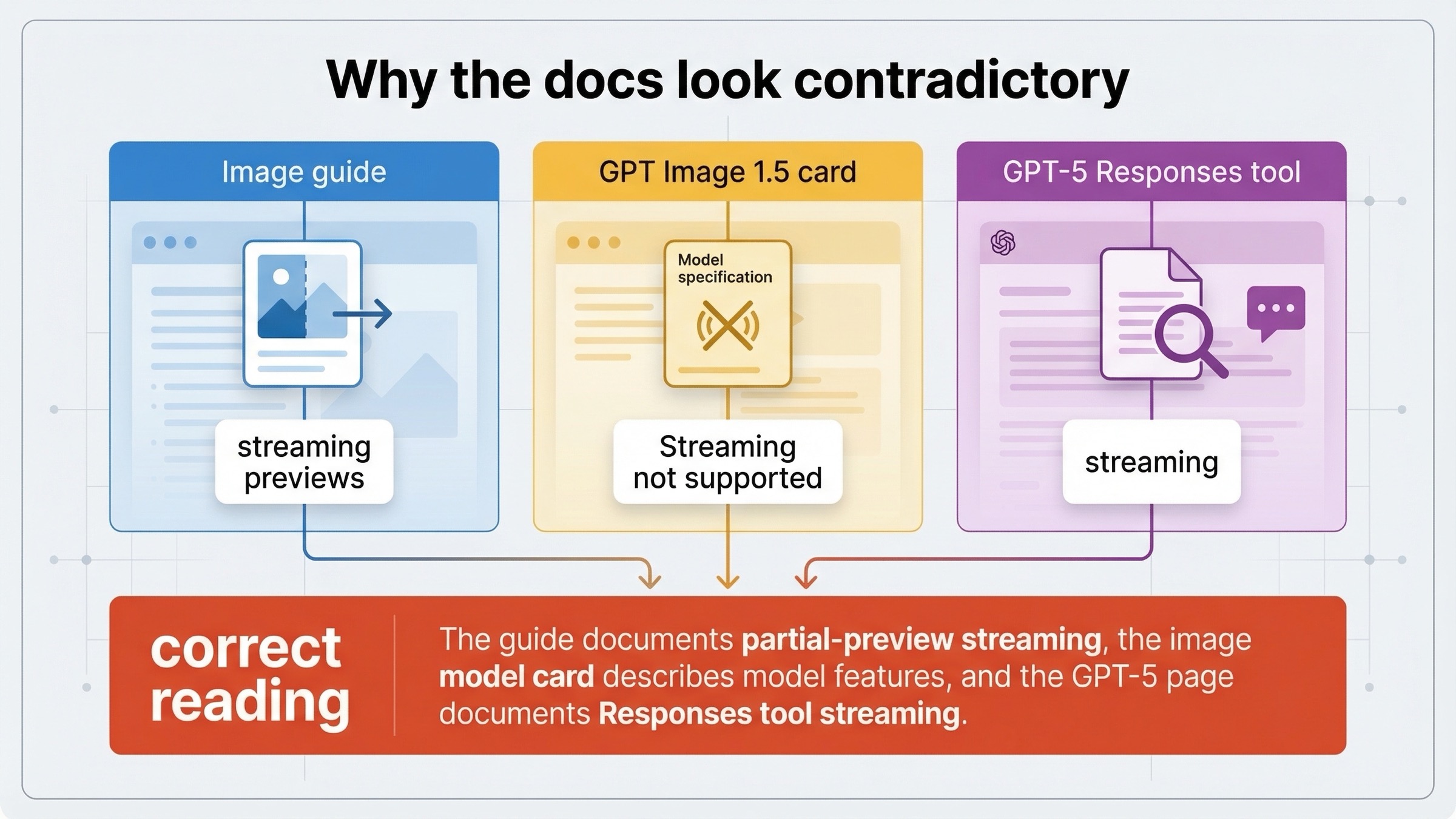
Por qué la documentación parece contradictoria
Esta es la parte que muchas páginas que ya rankean siguen evitando, y es la razón principal por la que este keyword existe.
El image generation guide actual dice que tanto Responses API como Image API soportan streaming image generation. Luego enseña event loops concretos para ambas superficies y define esa capacidad alrededor de partial-image previews.
La página de GPT Image 1.5, sin embargo, todavía muestra Streaming: Not supported en su tabla de features.
Y la página de GPT-5 actual indica que streaming is supported y que el tool image_generation está soportado en Responses API.
La forma limpia de reconciliar esas páginas es esta:
- el image guide documenta el comportamiento en la surface de API para la entrega de partial-image previews en streaming
- la página de GPT-5 documenta el comportamiento del mainline model y el soporte de tools dentro de Responses
- el model card de GPT Image no está prometiendo un streaming genérico al estilo texto desde el modelo de imagen en sí
Esa interpretación coincide con los ejemplos que OpenAI publica de verdad. Si tu pregunta es "¿mi aplicación puede recibir preview images mientras la generación sigue en marcha?", la respuesta es sí. Si tu pregunta es "¿el image model se comporta como un text model que va soltando token chunks?", la respuesta es no, eso no es lo que describe el current image guide.
Esto también explica por qué los tutorials viejos siguen sonando distintos. En el launch post del modelo de imagen para API, fechado el 23 de abril de 2025, OpenAI lanzó gpt-image-1 primero en Images API y dijo que el soporte en Responses estaba "coming soon". Si aprendiste el stack en esa época, es normal que todavía arrastres una mental model Images-first y una idea más estrecha de lo que puede significar streaming. Las docs actuales ya avanzaron, pero el wording antiguo no desapareció de todas las superficies a la vez.
Errores de implementación que hacen perder tiempo
Los fallos más comunes en este tema no son problemas profundos de algoritmo. Son errores de ruta, de nombres y de expectativas.
1. Usar el event name equivocado para la surface elegida
En Images API directo, el guide actual escucha image_generation.partial_image. En Responses API escucha response.image_generation_call.partial_image. No son intercambiables. Si copias la idea correcta pero el event name equivocado, puede parecer que la ruta está rota cuando el problema real está en el handler.
2. Empezar con Responses cuando el producto es solo una direct image feature
Este es el error arquitectónico más común. Si lo único que necesitas es un prompt, unos pocos preview images y un asset final, Images API te da el first success más limpio. Empezar por Responses añade una capa extra de abstracción antes de demostrar siquiera que el stream más simple funciona.
3. Tratar partial_images como si garantizara frames fijos
El guide actual dice que partial_images puede ir de 0 a 3, pero también aclara que podrías recibir menos previews de los pedidos si la imagen final se genera rápido. Los previews deben tratarse como una UX de progreso best-effort, no como un contrato para entregar un número fijo de frames.
4. Leer el model card y el guide como si describieran la misma capa
No lo hacen. El guide describe la entrega actual de partial-image previews en la surface de API. El model card describe features del image model dentro de una tabla más amplia del catálogo. Si colapsas ambos significados en uno solo, o infravalorarás el soporte actual o exagerarás lo que ese soporte garantiza.
5. Depurar código antes de comprobar los supuestos de acceso
La página actual de GPT Image 1.5 sigue diciendo que Free no está soportado para image use, y el launch post todavía advierte de que algunos developers pueden necesitar organization verification. Si tu primer streamed test no devuelve nada, no asumas que el único sospechoso es el event loop. Comprueba primero si la cuenta y la organización realmente tienen acceso al image model que elegiste.
6. Dejar que las suposiciones de gpt-image-1 manden una implementación de 2026
El anchor actual para trabajo nuevo es gpt-image-1.5, no la mental model original del lanzamiento de gpt-image-1. Si además estás comparando el lineup general de rutas de imágenes de OpenAI, el siguiente paso más útil es nuestra guía de modelos actuales de OpenAI image generation.
FAQ
¿Puedo forzar exactamente dos preview frames?
No. El current image generation guide dice que partial_images puede configurarse de 0 a 3, pero también indica que podrías recibir menos previews de los solicitados si la imagen final se termina rápido. Trata las partial images como señales de preview best-effort, no como un conteo garantizado.
¿Debería resolver esto con Realtime API?
No como respuesta por defecto a este keyword. El current image generation guide documenta los streamed partial-image previews sobre Images API y Responses API. Ese es el path documentado que conviene seguir salvo que OpenAI publique un patrón más explícito para Realtime más adelante.
¿Qué model pongo en la request?
Para la ruta directa de Images API, empieza por gpt-image-1.5. Para la ruta de Responses, sigue el patrón de docs actual y usa un mainline model como gpt-4.1 o gpt-5 en el campo model, añadiendo luego el hosted image_generation tool.
Recomendación final
Si solo te quedas con una regla de esta página, que sea esta: hoy OpenAI image generation streaming significa partial-image preview streaming, y Images API sigue siendo el default más seguro salvo que image generation sea solo una herramienta dentro de un Responses workflow más amplio.
Esa respuesta es más útil que un simple "sí" porque te dice qué construir a continuación. Empieza con una sola request directa en Images API usando gpt-image-1.5. Asegúrate de que tu UI sabe manejar preview images que llegan en modo best-effort. Solo después de eso tiene sentido subir a Responses API, donde la orchestration extra realmente compensa la complejidad adicional.
Si después de resolver la duda sobre streaming quieres el mapa más amplio de rutas, sigue con nuestro tutorial de OpenAI Image API para direct generation y edits, o con nuestra guía de OpenAI image editing API si el siguiente problema son los edits con preservación y no los progressive previews.