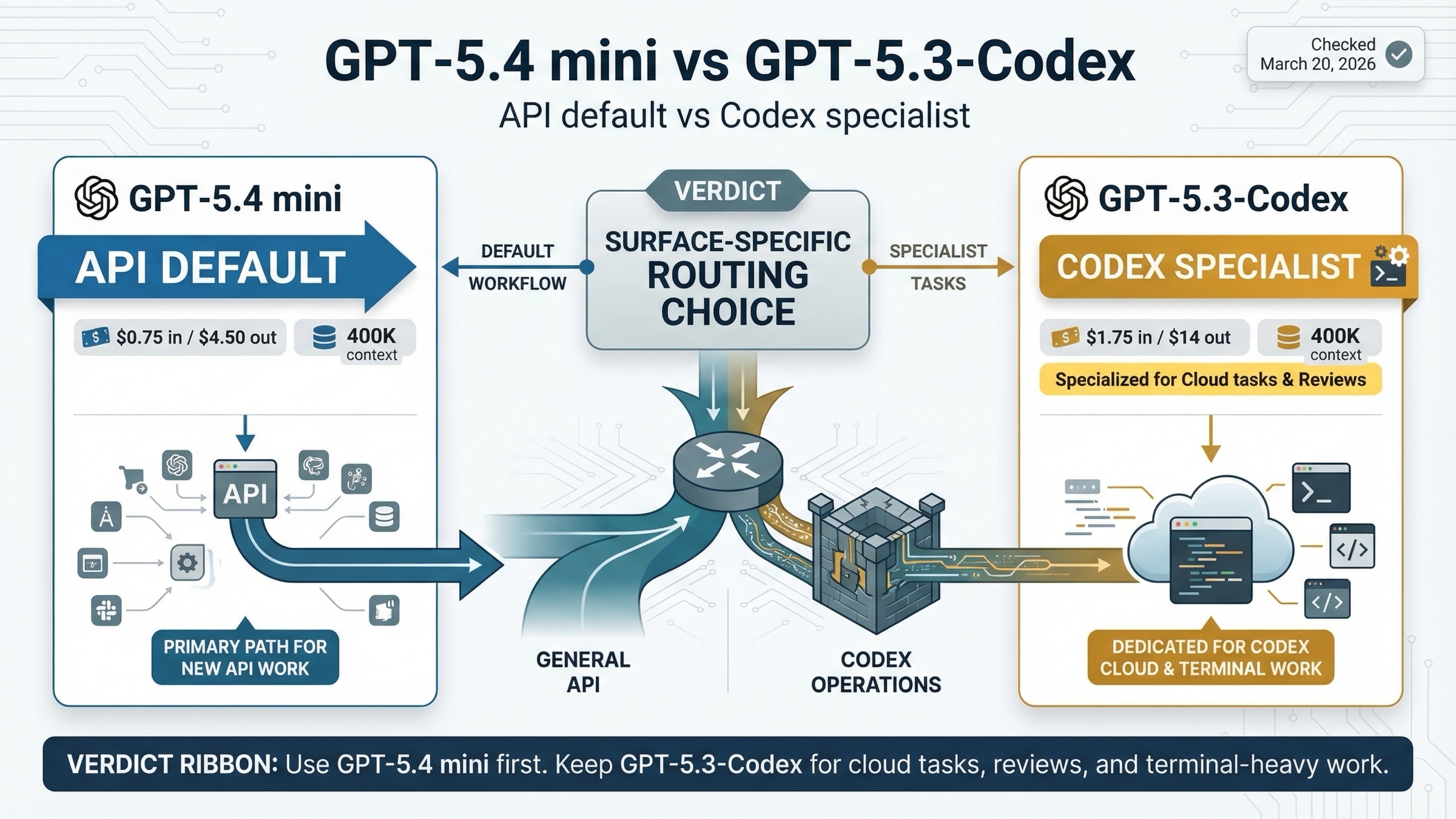
Usa GPT-5.4 mini para trabajo nuevo en API y subagents. Mantén GPT-5.3-Codex para coding especialista mas pesado dentro de Codex cuando code review, terminal y comportamiento de programacion mas profundo importen mas que la eficiencia de precio de un small model.
La comparativa solo se aclara cuando separas superficies. En API, GPT-5.4 mini es el default mas barato y mas nuevo para muchos workflows de coding de alto volumen. En entornos tipo Codex, GPT-5.3-Codex sigue teniendo una postura mas fuerte como especialista.
Resumen rápido
La regla corta es esta: para nuevos flujos de API y subagentes empieza por GPT-5.4 mini; para Codex cloud tasks, reviews y coding muy orientado a terminal mantén GPT-5.3-Codex.
| Modelo | Mejor para | Motivo principal para elegirlo | Motivo principal para no elegirlo |
|---|---|---|---|
| GPT-5.4 mini | Nuevos workers de API, subagentes baratos, workers con capturas, trabajo local frecuente en Codex | Mucho más barato en API, más herramientas y posición actual de modelo mini recomendado | Peor perfil en benchmarks specialist de coding y sin cloud tasks ni code reviews en Codex |
| GPT-5.3-Codex | Terminal-heavy coding, Codex cloud tasks, Codex reviews, loops de coding más profundos | Mejor perfil en SWE-Bench Pro y sobre todo en Terminal-Bench, además de mayor cobertura funcional dentro de Codex | Coste de API mucho mayor y ya no es el default pequeño recomendado |
Regla práctica en cuatro líneas:
- Si construyes un nuevo flujo de programación sobre OpenAI API, prueba primero GPT-5.4 mini.
- Si dependes de cloud tasks o GitHub code reviews en Codex, conserva GPT-5.3-Codex.
- Si tu trabajo es claramente terminal-first, GPT-5.3-Codex sigue teniendo mejor caso.
- No decidas usando solo las etiquetas del selector de ChatGPT si tu problema real es API o Codex.
Qué cambia de verdad entre GPT-5.4 mini y GPT-5.3-Codex
El error más común es pensar que GPT-5.4 mini es simplemente una versión más pequeña y más barata del mismo trabajo que hacía GPT-5.3-Codex. No es exactamente eso.
Según las páginas oficiales actuales, ambos modelos comparten varios datos de primer nivel:
- 400K context window
- 128K max output
- knowledge cutoff del 31 de agosto de 2025
- soporte para entrada de texto e imagen
Si solo lees esas fichas, parecen mucho más parecidos de lo que realmente son. Pero la decisión no se define por esas cifras estáticas, sino por el papel de producto.
La guía actual Using GPT-5.4 recomienda gpt-5.4-mini para high-volume coding, computer use y agent workflows. Ese es hoy su rol por defecto dentro de la línea pequeña.
En cambio, la página de GPT-5.3-Codex sigue describiéndolo como the most capable agentic coding model to date y lo ata de forma explícita a Codex o entornos similares. Es una posición más estrecha y más specialist.
La manera más útil de pensarlo es esta:
| Pregunta | Mejor encaje |
|---|---|
| Necesitas el default actual para coding y subagentes en API | GPT-5.4 mini |
| Necesitas el carril specialist de coding | GPT-5.3-Codex |
| Necesitas cloud tasks o reviews en Codex | GPT-5.3-Codex |
| Necesitas trabajo barato, local o de subagente | GPT-5.4 mini |
Por eso esta comparación no se resuelve con una sola etiqueta de “ganador”. Lo correcto cambia según si estás tomando una decisión de routing en API o una decisión de producto dentro de Codex.
Benchmarks que sí cambian la decisión

OpenAI no publica una tabla oficial única enfrentando a ambos en el mismo grid, pero los launch posts de cada uno bastan para ver la separación práctica.
Del post oficial del 17 de marzo de 2026 GPT-5.4 mini y nano, GPT-5.4 mini figura con:
- 54.4% SWE-Bench Pro
- 60.0% Terminal-Bench 2.0
- 72.1% OSWorld-Verified
Del post oficial del 5 de febrero de 2026 GPT-5.3-Codex, GPT-5.3-Codex figura con:
- 56.8% SWE-Bench Pro
- 77.3% Terminal-Bench 2.0
- 64.7% OSWorld-Verified
Puestos lado a lado, el patrón es bastante claro:
| Benchmark | GPT-5.4 mini | GPT-5.3-Codex | Qué significa |
|---|---|---|---|
| SWE-Bench Pro | 54.4% | 56.8% | GPT-5.3-Codex conserva el perfil specialist de coding |
| Terminal-Bench 2.0 | 60.0% | 77.3% | GPT-5.3-Codex es claramente mejor en ingeniería orientada a terminal |
| OSWorld-Verified | 72.1% | 64.7% | GPT-5.4 mini encaja mejor en trabajos con pantallas y computer use |
Lo importante aquí no es “quién gana más filas”, sino qué tipo de trabajo gana.
Si tu trabajo real se parece a shell loops, depuración local de repositorios, herramientas de build, scripts y automatización por CLI, la ventaja de GPT-5.3-Codex no es cosmética. El hueco en Terminal-Bench es demasiado grande como para tratarlo como redondeo.
Si tu flujo se parece más a interpretación de capturas, uso amplio de herramientas, workers baratos dentro de un orquestador o tareas híbridas entre coding y computer use, GPT-5.4 mini empieza a verse más fuerte. Su ventaja en OSWorld apunta exactamente a ese tipo de alineación.
En otras palabras:
- GPT-5.3-Codex gana el carril specialist de coding
- GPT-5.4 mini gana el carril mini moderno, barato y más afinado a computer use
Si estás dudando entre estos small models y un flagship más amplio, la comparativa relacionada es GPT-5.4 vs GPT-5.3-Codex.
Precio en API, herramientas y límites
El precio es el punto donde la recomendación a favor de GPT-5.4 mini deja de ser sutil y se vuelve muy práctica.
Según las páginas oficiales verificadas el 20 de marzo de 2026:
| Especificación | GPT-5.4 mini | GPT-5.3-Codex |
|---|---|---|
| Precio de entrada | $0.75 / 1M tokens | $1.75 / 1M tokens |
| Entrada cacheada | $0.075 / 1M tokens | $0.175 / 1M tokens |
| Precio de salida | $4.50 / 1M tokens | $14.00 / 1M tokens |
| Context window | 400K | 400K |
| Max output | 128K | 128K |
| Knowledge cutoff | 31 ago 2025 | 31 ago 2025 |
Esto contradice la intuición de muchos usuarios. GPT-5.3-Codex no es la opción barata en API; al contrario, GPT-5.4 mini es muchísimo más económico:
- menos de la mitad en entrada
- menos de la mitad en cache
- menos de un tercio en salida
Si estás haciendo routing puro en API, cuesta justificar que GPT-5.3-Codex sea tu primera prueba por defecto.
La superficie de herramientas también inclina la balanza hacia GPT-5.4 mini. En la página actual de GPT-5.4 mini aparecen:
- web search
- file search
- image generation
- code interpreter
- hosted shell
- apply patch
- skills
- computer use
- MCP
- tool search
La página de GPT-5.3-Codex es mucho más estrecha y enfatiza structured outputs, function calling y la especialización en entornos estilo Codex.
Ni siquiera los rate limits rescatan a GPT-5.3-Codex como default evidente en API. Los límites públicos actuales muestran:
| Tier | GPT-5.4 mini TPM | GPT-5.3-Codex TPM |
|---|---|---|
| Tier 1 | 500,000 | 500,000 |
| Tier 2 | 2,000,000 | 1,000,000 |
| Tier 3 | 4,000,000 | 2,000,000 |
| Tier 4 | 10,000,000 | 4,000,000 |
| Tier 5 | 180,000,000 | 40,000,000 |
Así que, si tu pregunta es “qué small model debería probar primero un equipo nuevo de API”, la respuesta es bastante directa: empieza por GPT-5.4 mini salvo que tengas muy claro que tu carga cae en el carril specialist y terminal-heavy donde GPT-5.3-Codex compensa el sobrecoste.
Si además quieres ver cómo se posiciona frente a la línea mini anterior, puedes seguir con GPT-5.4 mini vs GPT-5 mini.
Por qué Codex cambia la recomendación
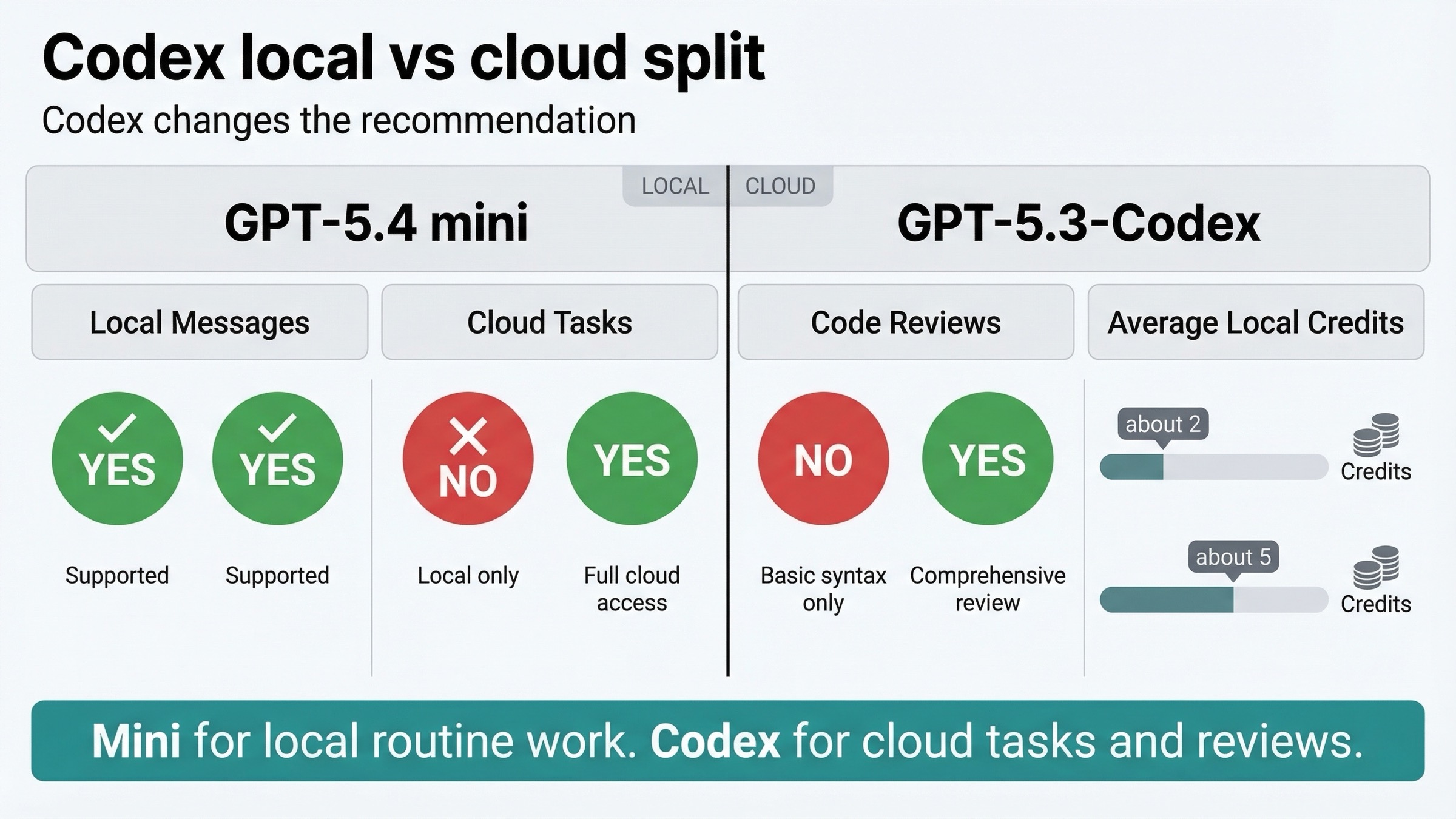
Aquí está la parte que más se pierde en las comparativas actuales.
Dentro de Codex, GPT-5.4 mini no reemplaza por completo a GPT-5.3-Codex.
La página actual de Codex pricing indica que:
- GPT-5.4 mini ofrece hasta 3.3x más límite de mensajes locales
- una tarea local media en GPT-5.4 mini consume unas 2 credits
- una tarea local media en GPT-5.3-Codex consume unas 5 credits
Eso vuelve a GPT-5.4 mini muy atractivo para:
- trabajo local rutinario en Codex
- lecturas y ediciones rápidas
- tareas de soporte frecuentes
- flujos donde importa estirar al máximo la cuota local
Pero la misma página deja claro el caveat decisivo:
| Capacidad de Codex | GPT-5.4 mini | GPT-5.3-Codex |
|---|---|---|
| Local messages | Yes | Yes |
| Cloud tasks | No | Yes |
| Code reviews | No | Yes |
Ese es el dato de producto más importante de toda la comparativa.
Si tu flujo de Codex depende de cloud tasks o GitHub code reviews, GPT-5.4 mini no es un sustituto completo hoy.
La recomendación correcta en Codex, por tanto, se divide en dos:
- trabajo local rutinario: GPT-5.4 mini
- cloud tasks y code reviews: GPT-5.3-Codex
Eso también explica buena parte de la confusión de marzo de 2026 en Reddit y otros foros. Muchos hilos reflejan cambios de disponibilidad o de interfaz entre superficies, pero no alteran este hecho más durable: GPT-5.4 mini y GPT-5.3-Codex hoy cubren trabajos distintos dentro de Codex.
Qué modelo usar en cada workflow
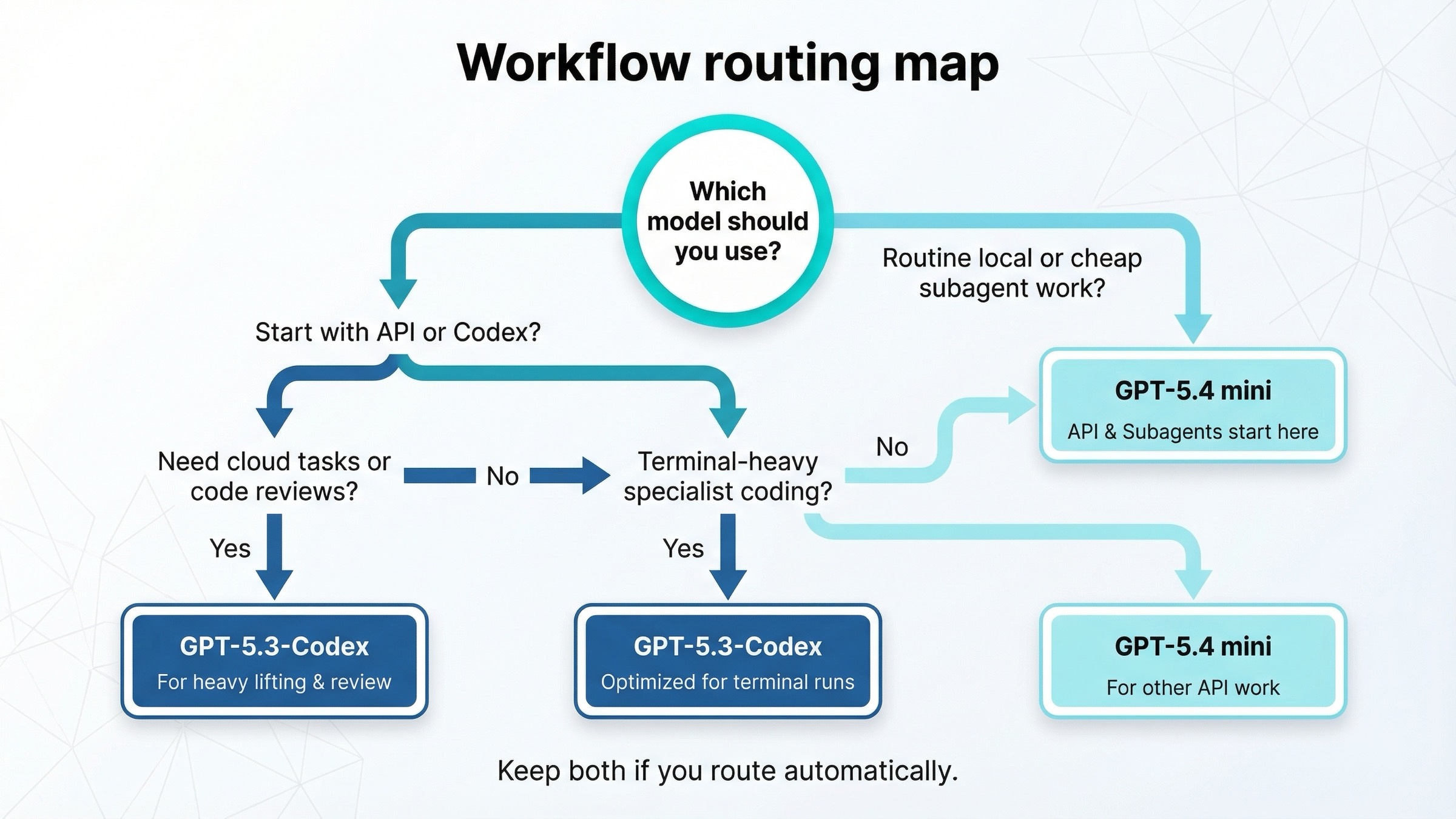
Si quieres convertir el artículo en una regla operativa, esta tabla es la más útil:
| Workflow | GPT-5.4 mini | GPT-5.3-Codex | Por qué |
|---|---|---|---|
| Nuevo worker de coding por defecto en API | Yes | Rarely | Más barato, más actual y con más herramientas |
| Subagentes baratos bajo un planner mayor | Yes | Rarely | Esa es justo la función que OpenAI asigna hoy a mini |
| Worker con capturas o computer-use-like | Yes | Sometimes | Mejor OSWorld y mejor postura de herramientas |
| Ingeniería muy orientada a terminal | Sometimes | Yes | La diferencia en Terminal-Bench sigue siendo muy fuerte |
| Trabajo local rutinario en Codex | Yes | Sometimes | Rinde mejor la cuota local |
| Codex cloud tasks | No | Yes | Esa superficie sigue siendo de GPT-5.3-Codex |
| Codex GitHub code reviews | No | Yes | Esa superficie sigue siendo de GPT-5.3-Codex |
| Un único modelo specialist para coding profundo | Sometimes | Yes | GPT-5.3-Codex sigue siendo la opción specialist |
Para un equipo típico de API, la respuesta es sencilla: usa GPT-5.4 mini como default y enruta a GPT-5.3-Codex solo los casos claramente terminal-heavy o specialist de coding.
Para un usuario intensivo de Codex, la mejor respuesta suele ser mantener ambos:
- GPT-5.4 mini para trabajo local barato y frecuente
- GPT-5.3-Codex para cloud tasks, reviews y el carril de coding más duro
Eso funciona mejor que forzar todas las tareas a pasar por un único modelo por ser más nuevo o más specialist.
Cuándo sigue teniendo sentido GPT-5.3-Codex
Muchas páginas lo aplastan todo en una frase: “GPT-5.4 mini es más nuevo, así que úsalo”. Eso hace el artículo más corto, pero también menos correcto.
GPT-5.3-Codex sigue teniendo sentido en al menos cuatro casos.
Primero, terminal-heavy work. Si tu día real se parece a shell operations, depuración local del repo, scripting y bucles CLI, GPT-5.3-Codex sigue teniendo la evidencia más fuerte a favor.
Segundo, workflows cloud en Codex. Esta es la razón más limpia. Si necesitas cloud tasks, necesitas GPT-5.3-Codex.
Tercero, code reviews en Codex. Para equipos que dependen del flujo de review en GitHub, este punto por sí solo ya justifica mantenerlo.
Cuarto, fallback routing. Algunas arquitecturas no deberían pensar en un ganador permanente, sino en una regla mejor:
- mini first para trabajo barato, actual y general
- Codex second para specialist coding o superficies cloud de Codex
Esa es una estrategia de routing más sana que dejar un specialist antiguo como default universal por inercia.
Si además quieres comparar Codex con otro specialist no-OpenAI, la referencia siguiente sería el artículo en inglés GPT-5.3 Codex vs Claude Opus 4.6.
FAQ
¿GPT-5.4 mini es mejor que GPT-5.3-Codex para programar en general?
No en todos los benchmarks. GPT-5.3-Codex sigue siendo más fuerte en SWE-Bench Pro y mucho más fuerte en Terminal-Bench 2.0. Pero GPT-5.4 mini es mucho más barato en API, es el mini recomendado hoy y encaja mejor en tareas cercanas a computer use.
Si GPT-5.3-Codex puntúa mejor en coding, por qué la recomendación por defecto es GPT-5.4 mini?
Porque la recomendación por defecto no sale de una sola fila de benchmark. Sale del cuadro completo: precio, herramientas, límites públicos, dirección de producto y el hecho de que muchos sistemas de coding hoy son también sistemas de tools y agentes.
¿GPT-5.4 mini reemplaza a GPT-5.3-Codex dentro de Codex?
No por completo. Al menos a fecha del 20 de marzo de 2026, la página oficial de Codex pricing sigue mostrando que GPT-5.4 mini no tiene cloud tasks ni code reviews. Ahí GPT-5.3-Codex sigue siendo necesario.
¿Qué debería probar primero un equipo nuevo?
Si trabajas en API, prueba primero GPT-5.4 mini. Si tu trabajo es muy Codex-heavy, lo más eficaz suele ser una configuración de dos carriles: GPT-5.4 mini para trabajo local rutinario y GPT-5.3-Codex para cloud tasks, reviews y coding intensivo de terminal.
Recomendación final
Si necesitas una sola frase para llevarte al equipo, usa esta: GPT-5.4 mini es el default correcto para nuevos flujos de API y subagentes, pero GPT-5.3-Codex sigue siendo el modelo que conviene conservar cuando tu trabajo es terminal-heavy o depende de Codex cloud tasks y reviews.
Ese resumen es mejor que una lectura simplista de “nuevo contra viejo” porque encaja con la realidad de producto de marzo de 2026:
- GPT-5.4 mini es más atractivo y más barato en API
- GPT-5.3-Codex mantiene el perfil specialist de coding
- el comportamiento de Codex hace que hoy no sean modelos intercambiables
La decisión madura aquí no es borrar uno con el otro, sino devolver a cada uno el carril donde de verdad encaja mejor.