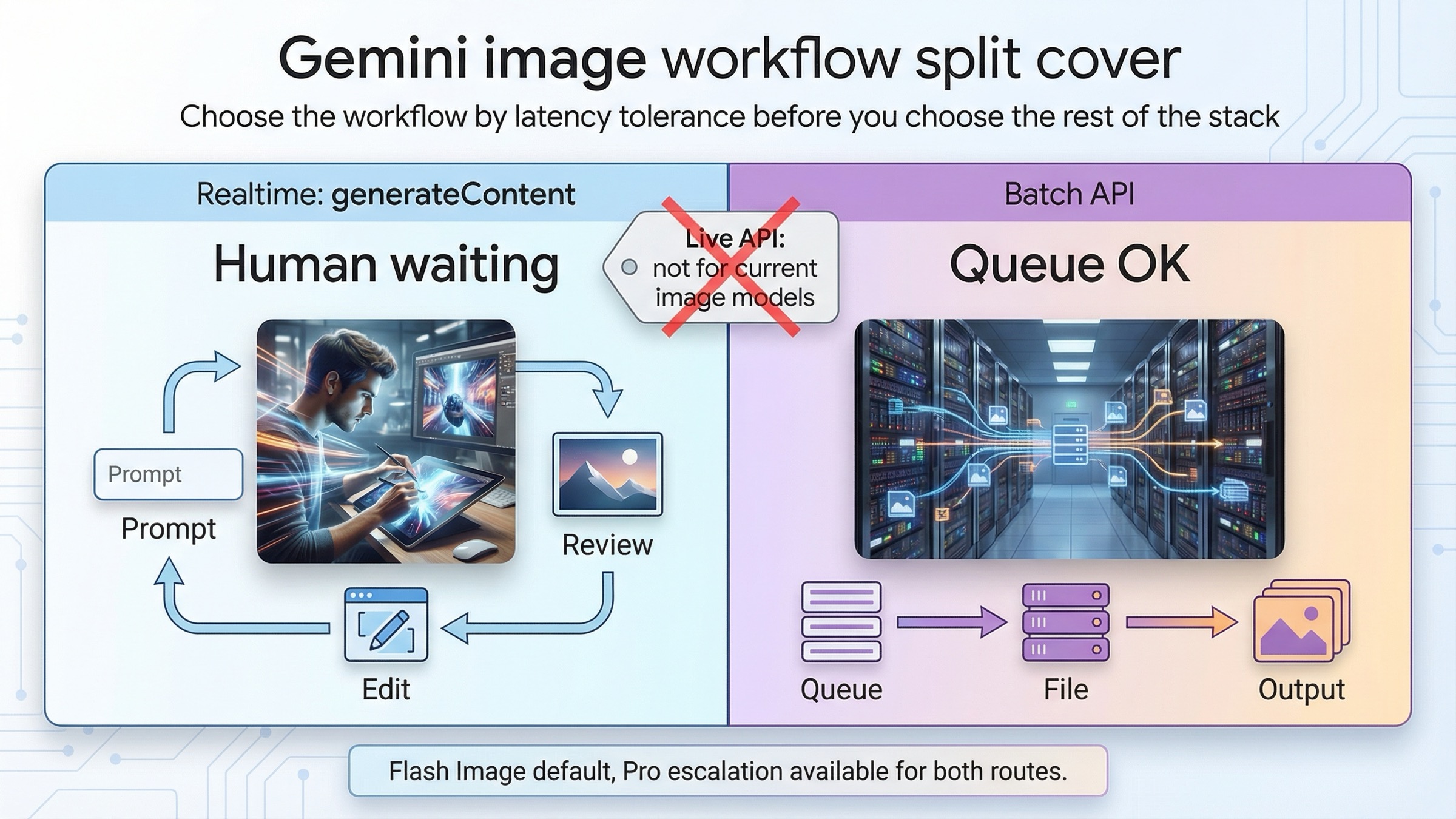
A 23 de marzo de 2026, la mejor regla por defecto para Gemini image generation es muy simple: si una persona está esperando el resultado, usa generateContent síncrono; si el trabajo es voluminoso, barato y no urgente, usa Batch API. Conviene empezar por esa división antes de mirar precios o SDKs, porque el verdadero problema de este tema no es qué API existe, sino qué tipo de workflow estás intentando construir.
Hay otra aclaración que debería aparecer desde el primer párrafo. En la generación de imágenes actual de Gemini, "tiempo real" no significa Live API. En las páginas oficiales de gemini-3.1-flash-image-preview y gemini-3-pro-image-preview, Google indica hoy que Batch API sí está soportada y Live API no está soportada. Al mismo tiempo, la guía oficial de image generation enseña ejemplos normales de generateContent síncrono y edición multi-turn. En la práctica, la rama realtime de este tema es request-response con iteración rápida, no una sesión live de salida de imagen.
Ese matiz importa porque la documentación está bien, pero muy repartida. Una página explica Batch API, otra explica generación de imágenes, otra da el pricing y otra lista las capacidades de los modelos. Si las lees por separado puedes conocer los hechos y aun así elegir mal el workflow. Lo que falta es una capa de síntesis operativa: una regla de decisión, una tabla de costes, una lectura clara del rol de cada modelo y una lista de errores frecuentes.
Resumen rápido
Si solo necesitas la respuesta corta, usa esta tabla.
| Pregunta | Mejor respuesta actual | Por qué |
|---|---|---|
| Una persona espera la imagen o la edición ahora | generateContent síncrono | La documentación actual de imágenes de Google está pensada para iterar prompt, ver el resultado y corregir rápido |
| El trabajo es grande, repetitivo y no urgente | Batch API | La documentación de Batch API habla de 50% del coste estándar y 24 horas de turnaround objetivo |
| Por "realtime" entiendes una sesión live de imágenes | Ese no es el modelo mental correcto | Las páginas actuales de los modelos de imagen dicen que Live API no está soportada |
| Modelo por defecto para empezar | gemini-3.1-flash-image-preview | Es la línea actual de mayor eficiencia y el reemplazo oficial de gemini-2.5-flash-image |
| Cuándo tiene sentido subir a Pro | Cuando la calidad del texto, del layout o del activo final ya es costosa de fallar | gemini-3-pro-image-preview encaja mejor en imágenes con texto, diagramas y assets más delicados |
| Ruta oficial más barata | gemini-2.5-flash-image | Sigue siendo la más barata, pero Google la apaga el 2 de octubre de 2026 |
El error más común es elegir Batch API solo porque es más barata. El descuento es real, pero solo gana cuando la latencia no rompe el propio flujo de trabajo. Si todavía estás afinando prompts, haciendo review humano o construyendo una herramienta para usuarios, lo normal es que el camino síncrono siga siendo el mejor.
Tres ejemplos rápidos:
- una herramienta de producto donde el usuario espera la siguiente imagen: síncrono
- un equipo creativo ajustando prompts con feedback en el mismo día: síncrono primero, batch después
- una tarea nocturna que genera miles de variantes a partir de prompts ya aprobados: batch
Si lo siguiente que necesitas es código y no routing, te conviene ejemplos de código para Gemini image generation. Si lo siguiente es el coste, pricing de Gemini image generation API entra más a fondo. Si tu problema real es edición y no enrutamiento, la página útil es edición de imagen a imagen en Gemini.
La división real: generateContent síncrono frente a Batch API
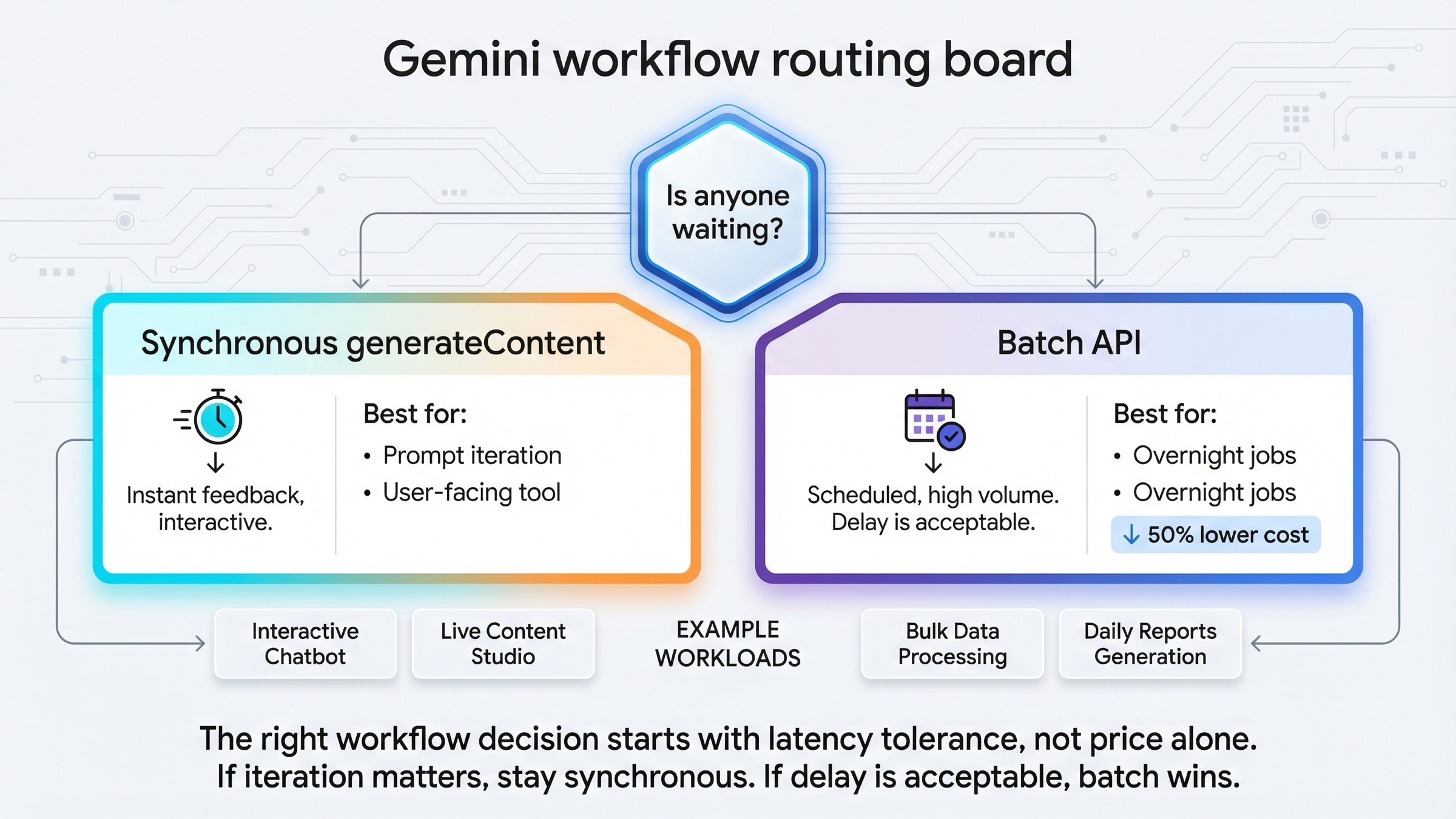
Mucha gente llega a este tema formulando una pregunta técnica, pero escondiendo una pregunta operativa dentro de ella. Preguntan "¿batch o realtime?" y en realidad quieren decir "¿este trabajo debe seguir en un bucle interactivo o ya puedo mandarlo a una cola?".
Por eso la primera pregunta útil no es sobre modelos, precios o tokens. Es esta:
¿Alguien está esperando el resultado?
Si la respuesta es sí, quédate en el camino síncrono. Eso suele cubrir:
- exploración de prompts
- herramientas orientadas al usuario
- bucles de revisión humana
- edición iterativa
- retry rápido tras un primer resultado flojo
Si la respuesta es no, Batch API gana atractivo. Eso suele cubrir:
- generación nocturna
- pipelines de assets basados en cola
- trabajos grandes de catálogo o variantes
- procesos de enriquecimiento no urgentes
- backfills y repeticiones de prompts ya estables
La documentación actual de Batch API deja el trade-off bastante claro: es una superficie asíncrona, pensada para mucho volumen, con 50% del coste estándar y un turnaround objetivo de 24 horas. Eso es excelente para colas y trabajos grandes, pero es una mala elección si la siguiente acción del sistema o de una persona depende del resultado inmediato.
Lo contrario también es cierto. La generación síncrona no es solo para pruebas pequeñas. Es la mejor opción siempre que el valor venga de iterar rápido. La actual guía de image generation está construida justo así: prompt, imagen, edición, siguiente turno. Un buen workflow de imagen suele mejorar con una corrección estrecha y rápida, no con una cola que te devuelve mañana que el prompt de hoy no era bueno.
La regla limpia, por tanto, es esta:
- trabajo interactivo, con humanos en el loop o con cara al producto: síncrono
- trabajo en cola, masivo, sensible al coste o no urgente: batch
Ese enfoque evita un error de arquitectura muy habitual. Muchos equipos saben que a la larga necesitarán una cola y, por eso, empiezan con la cola demasiado pronto. Pero necesitar una cola más tarde no significa que el workflow deba nacer allí. Lo más estable suele ser probar prompt, modelo y manejo de respuesta por vía síncrona, y solo después decidir si la petición ya merece una ruta batch.
Qué modelo de imagen de Gemini conviene usar detrás de cada workflow
La decisión de workflow y la decisión de modelo están relacionadas, pero no son lo mismo. Batch no es un modelo. Tiempo real no es un modelo. Puedes ejecutar el mismo modelo de imagen detrás de decisiones operativas distintas.
Para la mayoría de trabajos nuevos, el modelo por defecto sigue siendo gemini-3.1-flash-image-preview. Google lo posiciona como la línea actual de mayor eficiencia y, en la página de deprecations, aparece como la ruta de sustitución de gemini-2.5-flash-image.
| Modelo | Estado a 23 de marzo de 2026 | Batch API | Live API | Señal de precio actual | Mejor uso |
|---|---|---|---|---|---|
gemini-3.1-flash-image-preview | Preview actual por defecto | Sí | No | $0.067 por imagen 1K, $0.034 en batch | La mayoría de workflows nuevos, tanto interactivos como en cola |
gemini-3-pro-image-preview | Ruta premium actual | Sí | No | $0.134 por 1K o 2K, $0.067 en batch | Imágenes con texto, diagramas y assets de alto valor |
gemini-2.5-flash-image | Línea legacy aún disponible | Sí | No | $0.039 estándar y $0.0195 en batch | Ruta oficial más barata si aceptas el riesgo de lifecycle |
De aquí salen tres conclusiones.
La primera: los modelos actuales de imagen de Gemini soportan Batch API pero no soportan Live API. No merece la pena forzar esta discusión hacia una arquitectura live-image porque no es la superficie oficial de esta línea de modelos.
La segunda: gemini-3.1-flash-image-preview es la respuesta por defecto mientras no tengas una razón cara para salir de ella. Es suficientemente rápida, suficientemente actual y suficientemente flexible para casi todos los usos iniciales.
La tercera: la ruta más barata no es la misma que la ruta mejor por defecto. gemini-2.5-flash-image sigue siendo más barata, pero Google ya le asigna una fecha de cierre: 2 de octubre de 2026. Si empiezas algo nuevo sobre esa línea, deberías hacerlo conscientemente como movimiento económico a corto plazo, no como default neutral. Si quieres contexto más amplio sobre la familia de modelos, mira Nano Banana 2, Pro o Imagen 4.
El mejor workflow en tiempo real para prompting, revisión y edición
Si una persona espera el resultado, el mejor workflow sigue siendo el generateContent síncrono de toda la vida. Eso vale para un backend, para una herramienta interna y para un flujo conversacional dentro de un producto.
La razón no es solo la velocidad. Es la calidad de la iteración.
La generación de imágenes útil con Gemini suele tener este ritmo:
- enviar un prompt claro
- inspeccionar la primera imagen
- corregir una cosa concreta
- lanzar el siguiente turno
Esto es especialmente cierto en edición. La documentación actual de imágenes presenta el trabajo con Gemini como algo conversacional y multi-turn, y ese sigue siendo el mejor modelo mental. El segundo paso depende de lo que la primera imagen hizo bien o mal. Batch no sirve para eso porque aprendes demasiado tarde.
Este es el tipo de request síncrona con el que conviene arrancar:
javascriptimport { GoogleGenAI } from "@google/genai"; import * as fs from "node:fs"; const ai = new GoogleGenAI({ apiKey: process.env.GEMINI_API_KEY }); const response = await ai.models.generateContent({ model: "gemini-3.1-flash-image-preview", contents: "Create a clean 16:9 product hero image of a matte black coffee grinder on a soft gray background with premium ecommerce lighting.", config: { responseModalities: ["IMAGE"], imageConfig: { aspectRatio: "16:9", imageSize: "2K" } } }); for (const part of response.candidates[0].content.parts) { if (part.inlineData) { fs.writeFileSync("coffee-grinder.png", Buffer.from(part.inlineData.data, "base64")); } }
Ese primer request debería ser aburrido a propósito. La meta no es demostrar que Gemini puede hacer magia; la meta es probar que el modelo, el tamaño y el manejo de la respuesta funcionan en tu entorno. Una vez que eso es estable, entonces ya tiene sentido pasar a edición, refinamiento y prompts más exigentes.
Hay dos hábitos que mejoran mucho la vía síncrona:
- describir la escena en vez de lanzar una lista de keywords
- proteger de forma explícita lo que no debe cambiar en edición
La vieja guía de prompts de Google sigue acertando en eso: Gemini responde mejor cuando explicas qué debe cambiar y qué debe quedarse fijo. Esa es otra razón para que el trabajo interactivo empiece en modo síncrono: la mejora más rápida suele venir de una instrucción estrecha de seguimiento, no de un primer prompt gigante.
Además, el camino síncrono mantiene la imagen dentro del loop de revisión. Puedes ver el error exacto, conservar contexto y pedir una corrección focalizada. Para tools de ecommerce, generadores de anuncios, flujos de diseño internos y ediciones con muchas vueltas, eso suele ser claramente superior a una arquitectura batch-first.
Si primero pruebas en AI Studio, está bien. Solo no confundas esa superficie de prueba con el contrato de producción. En la publicación de Google del 26 de febrero de 2026 sobre Nano Banana 2 se deja claro que en AI Studio hace falta paid API key para este modelo. AI Studio sirve para aprender más rápido, pero el workflow real se define después en tu integración.
El mejor workflow batch para colas y generación nocturna
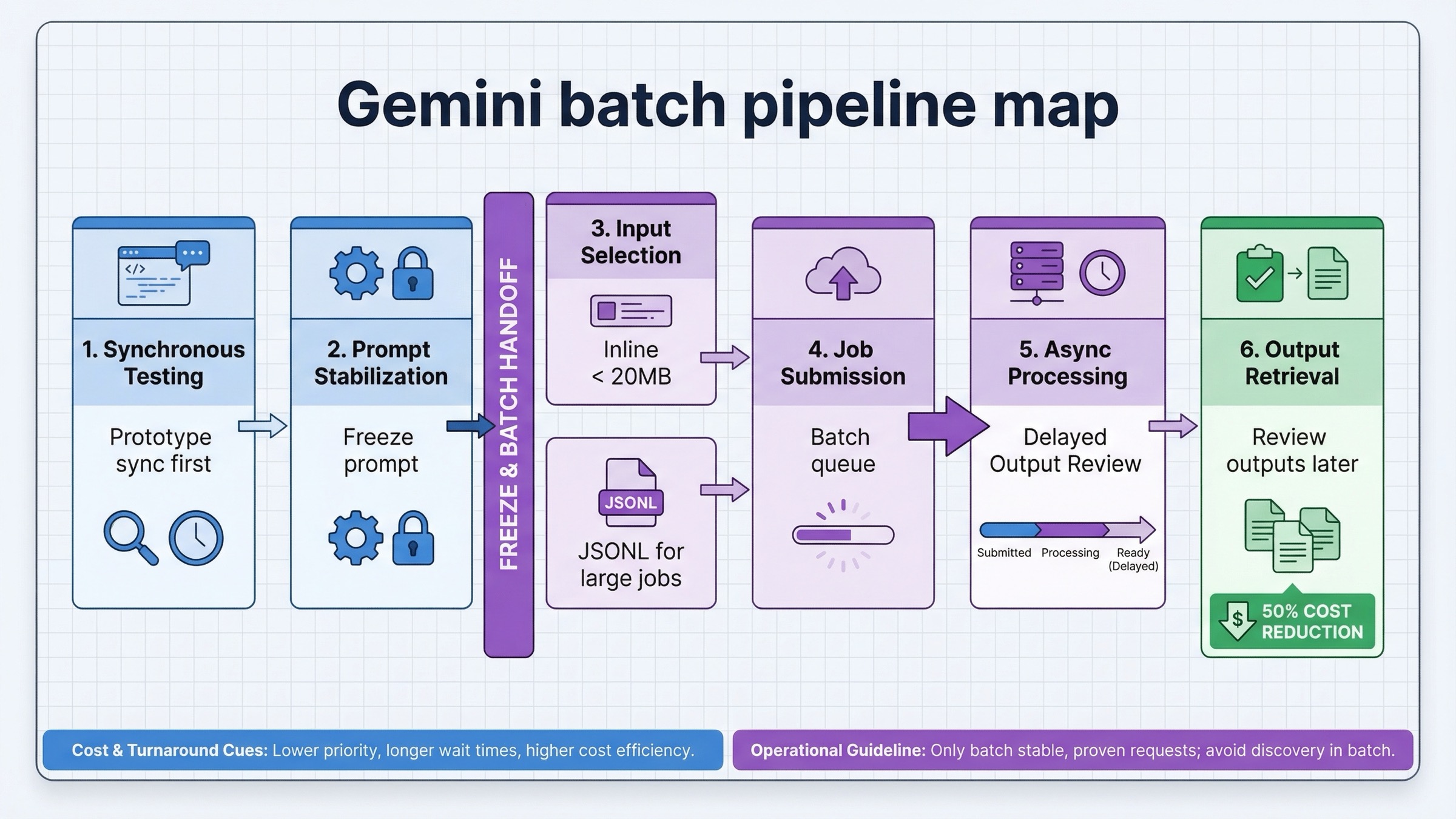
Batch API es la respuesta correcta cuando el trabajo es real, grande y no urgente. En la práctica, eso suele significar una combinación de tres cosas:
- importa mucho el coste total
- importa la capacidad de cola
- quieres separar intake de requests y entrega final de outputs
Aquí Batch API es mejor que un simple sistema de retries alrededor de requests síncronas. Google explica que puedes usar inline requests para trabajos pequeños y archivos JSONL para trabajos grandes. En generación de imágenes, el camino basado en archivo suele ser el que mejor aguanta un entorno productivo porque hace más fácil repetir, auditar y rehacer jobs.
La forma de un buen workflow batch suele ser:
- cerrar el prompt y los parámetros por la vía síncrona
- congelar el formato de request
- serializar jobs en JSONL o pequeños grupos inline
- mandar a batch solo cuando esperar ya no mejora el resultado
- recoger outputs después y manejar los retries por separado
Ese orden importa. Muchos equipos intentan descubrir prompts dentro de batch porque el coste por imagen baja. A nivel unitario parece buena idea; a nivel workflow casi nunca lo es. Descubrir el prompt correcto es un trabajo interactivo. Repetir un prompt ya estable es un trabajo batch.
Cuando la request ya está probada, el diferencial de precio se vuelve importante. Con los list prices actuales del 23 de marzo de 2026, 10 000 imágenes 1K con gemini-3.1-flash-image-preview cuestan alrededor de $670 en estándar y alrededor de $340 en batch. En gemini-3-pro-image-preview, esas mismas 10 000 imágenes suben a unos $1 340 estándar y unos $670 en batch. Por eso la rama batch importa tanto en jobs de catálogo, generación programada, variantes aprobadas o workflows de localización.
También hay que entender que Batch API no es solo una función de pricing. Es otra superficie operativa. La página de rate limits habla de 100 concurrent batch requests, 2GB de límite de input file, 20GB de file storage y control de capacidad por enqueued tokens según modelo. Eso significa que la presión operativa de batch puede aparecer incluso si tu tráfico síncrono va bien.
La forma concreta de la request también importa. Google indica que los inline requests son adecuados cuando el payload total está por debajo de 20MB, y que los trabajos más grandes deberían pasar a un archivo JSONL subido previamente. En la práctica, esa es la ruta que suele sobrevivir mejor a producción.
json{"key":"shoe-0001","request":{"contents":[{"parts":[{"text":"Create a clean white-background ecommerce image of a running shoe in side profile."}]}],"generation_config":{"response_modalities":["IMAGE"]}}} {"key":"shoe-0002","request":{"contents":[{"parts":[{"text":"Create a clean white-background ecommerce image of a black leather loafer in side profile."}]}],"generation_config":{"response_modalities":["IMAGE"]}}}
El ejemplo es deliberadamente sencillo. Un buen archivo batch no está para ser elegante, sino para ser reproducible. Para cuando una request llega a JSONL, prompt y parámetros deberían estar ya validados por la ruta síncrona.
Para muchos equipos, eso lleva a un patrón híbrido mejor:
- usa
generateContentsíncrono para diseñar prompts, aprobar primeras imágenes y editar - mueve a Batch API solo el trabajo repetitivo y estable
- reserva batch para jobs donde aceptar 24 horas de ventana sea razonable
Ese patrón híbrido suele ser mejor que una arquitectura batch-first pura, porque separa la parte del workflow que necesita juicio humano de la parte que se beneficia del descuento por volumen.
Hay una última advertencia. La documentación oficial habla de 24 horas objetivo, no de un SLA estricto. En algunos hilos de la comunidad a inicios de 2026 hubo quejas sobre jobs atascados durante bastante más tiempo. Eso no invalida la documentación, pero sí recuerda la idea central: batch es una herramienta de cola, no un contrato interactivo.
Cuándo Pro cambia la respuesta aunque el workflow no cambie
Después de mirar pricing tables es fácil caer en la idea de que todo se reduce a Flash frente a batch. Pero no es así. A veces el workflow sigue igual y lo que cambia es el modelo.
Ahí es donde gemini-3-pro-image-preview resulta útil.
Pro se vuelve racional cuando el coste de un mal resultado ya es mayor que el coste adicional del modelo. Los casos típicos son:
- diagramas e infografías con texto real
- assets de campaña o producto más pulidos
- visuales para clientes donde el fallo sale caro
- imágenes factuales donde importan labels y layout
- outputs premium donde quieres menos borradores fallidos
Fíjate en lo que no cambia en esa lista: la decisión de workflow. Si una persona sigue esperando el resultado, el trabajo sigue siendo síncrono. Si sigue siendo una exportación grande y no urgente, batch puede seguir siendo la superficie correcta. La decisión de modelo y la decisión de workflow son capas distintas.
Eso da cuatro rutas prácticas:
- Flash + síncrono para la mayoría del trabajo interactivo
- Flash + batch para generación masiva y sensible al coste
- Pro + síncrono para trabajo premium con iteración
- Pro + batch para jobs voluminosos de alto valor pero no urgentes
La forma útil de decidir no es preguntar qué modelo "gana" en abstracto, sino cuánto cuesta equivocarse. Si el asset es de bajo riesgo y gran volumen, Flash suele ser suficiente. Si el trabajo es text-heavy, delicado de layout o caro de rehacer, Pro pasa a ser razonable aunque no cambie el workflow.
Cómo detectar que elegiste mal el workflow
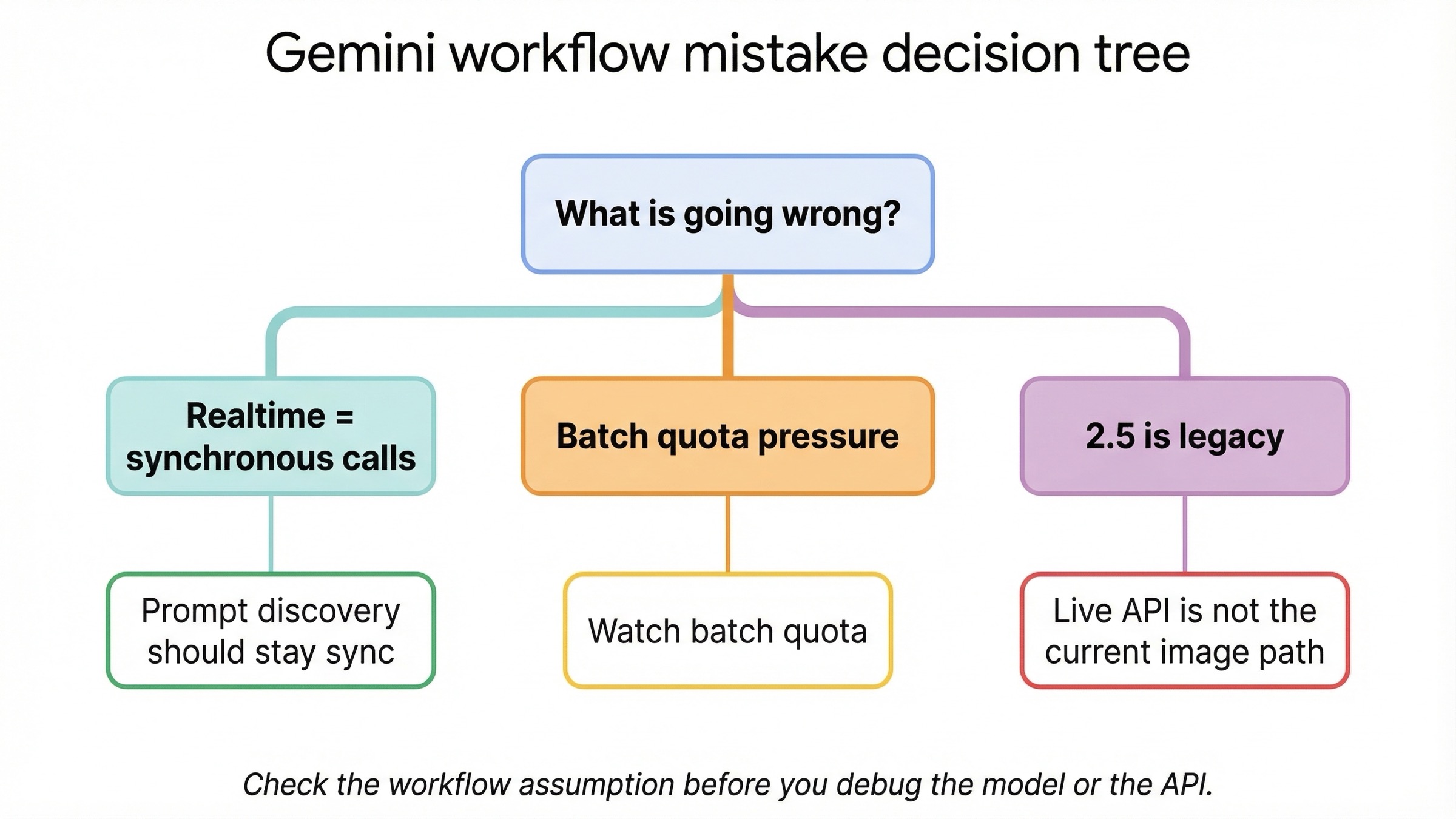
La mayoría de los fallos en este tema son errores de workflow, no errores puros de API.
Estás usando "realtime" de forma demasiado amplia. En la línea actual de Gemini image models, tiempo real significa request-response síncrono, no salida de imágenes por Live API. Si no aclaras eso desde el inicio, es fácil diseñar la arquitectura equivocada.
Estás yendo a batch durante el descubrimiento del prompt. El descuento es real, pero no convierte batch en el sitio correcto para aprender qué prompt funciona. Primero descubre el prompt; después, repite a escala.
Estás mezclando una decisión de workflow con una decisión de lifecycle. gemini-2.5-flash-image sigue siendo barata, pero también tiene fecha de apagado: 2 de octubre de 2026. Si la eliges, que sea por economía consciente de corto plazo, no porque un artículo viejo la siga tratando como default neutral.
Estás mirando solo las cuotas normales y no la presión específica de batch. Batch tiene sus propias restricciones, incluyendo capacidad por enqueued tokens. Eso cambia cómo deberías monitorizar el sistema.
Estás tomando AI Studio como historia completa del producto. AI Studio es útil para probar y iterar, pero tu aplicación real vive bajo el contrato del API, las páginas de capacidades del modelo y el pricing que despliegas. Un test cómodo en AI Studio no resuelve por sí solo la elección del workflow.
Estás intentando resolver un problema de modelo con un cambio de superficie. A veces no hace falta pasar de síncrono a batch; hace falta pasar de Flash a Pro porque el trabajo tiene demasiado texto o demasiado riesgo visual.
Si tu siguiente pregunta ya es sobre migración y no sobre routing, la lectura útil es cómo reemplazar Gemini 2.5 Flash Image.
Conclusión
La respuesta más útil a "Gemini image generation batch vs realtime" hoy no es una comparación abstracta entre superficies, sino una regla de enrutamiento bastante sencilla.
Si una persona espera el resultado, quédate en generateContent síncrono. Si el trabajo es grande, no urgente y ya no depende de iteración rápida, usa Batch API. Para la mayoría de implementaciones nuevas, empieza con gemini-3.1-flash-image-preview. Sube a gemini-3-pro-image-preview cuando el texto, el layout o el valor del asset hagan racional esa prima. Y deja gemini-2.5-flash-image solo para casos de economía legacy bien entendida, recordando su cierre el 2 de octubre de 2026.
Ese orden mantiene la decisión limpia: primero eliges el workflow según la tolerancia a la latencia; después eliges el modelo según la dificultad del output y el coste del error.