
La respuesta corta a 19 de marzo de 2026 es esta: si priorizas coste bajo, velocidad y tareas de alto volumen, Gemini 3.1 Flash-Lite es el mejor carril para empezar; si priorizas estado Stable, Search grounding gratuito y un comportamiento más predecible en producción, Gemini 2.5 Flash sigue siendo la opción por defecto más segura. La pregunta útil aquí no es "qué modelo es más nuevo", sino "si debo reemplazar 2.5 Flash en todas partes o solo mover ciertos flujos".
La confusión viene del nombre. Mucha gente asume que un modelo llamado Flash-Lite necesariamente está por debajo de un Flash antiguo en todos los ejes. Las páginas oficiales de Google dicen algo más matizado. En pricing, 3.1 Flash-Lite es más barato que 2.5 Flash. En DeepMind también aparece por delante en velocidad y en varias filas de benchmark. Pero en ese mismo conjunto oficial, 2.5 Flash sigue reteniendo el estado Stable / GA, el Search grounding gratuito y la ventaja en FACTS y MRCR v2 a 1M. No es una historia de "lo nuevo aplasta a lo viejo"; es una decisión de enrutamiento.
Resumen rápido
La forma práctica de leer esta keyword es: usa Gemini 3.1 Flash-Lite primero en traducción, clasificación, extracción estructurada y capas de routing; conserva Gemini 2.5 Flash como base cuando dependas de grounding, de menor riesgo operativo o de rendimiento cerca del contexto de 1M tokens.
La foto oficial al 19 de marzo de 2026 es esta:
| Área | Gemini 3.1 Flash-Lite | Gemini 2.5 Flash | Qué implica |
|---|---|---|---|
| Estado actual | Preview | Stable / GA | 3.1 es más nuevo, pero 2.5 es más defendible como default productivo |
| Model ID | gemini-3.1-flash-lite-preview | gemini-2.5-flash | La migración debe ser explícita, no un reemplazo ciego |
| Precio input estándar | Gratis, luego $0.25 / 1M | Gratis, luego $0.30 / 1M | 3.1 es más barato en input |
| Precio output estándar | Gratis, luego $1.50 / 1M | Gratis, luego $2.50 / 1M | 3.1 abarata mucho más la salida |
| Ventana de contexto | 1,048,576 tokens | 1,048,576 tokens | El tamaño de contexto no resuelve la decisión |
| Salida máxima | 65,536 tokens | 65,536 tokens | El techo de salida también es igual |
| Grounding gratis | Sin Search grounding gratis | Search grounding gratis hasta 500 RPD | 2.5 es más cómodo para asistentes grounded |
| Comparativa de velocidad | 363 tokens/s | 249 tokens/s | 3.1 es más rápido |
| Caveat importante | Mejor en GPQA, MMMU-Pro, LiveCodeBench, 128k MRCR | Mejor en FACTS y 1M MRCR | 3.1 no gana absolutamente todo |
Estas cifras salen de pricing, Gemini 3.1 Flash-Lite page, Gemini 2.5 Flash page, release notes y la comparativa oficial de DeepMind en flash-lite.
La recomendación operativa es simple:
- Mueve primero a 3.1 Flash-Lite las cargas donde velocidad y precio te den beneficio inmediato.
- Mantén 2.5 Flash como base para grounded assistants, rutas sensibles a riesgo y tareas de contexto largo.
- Si puedes enrutar por tipo de trabajo, usa ambos.
Por qué esta comparativa es más rara de lo que parece
Parece rara porque no es la comparación ordenada que esperarías por naming. La comparación "simétrica" sería Gemini 3.1 Flash-Lite vs Gemini 2.5 Flash-Lite. Pero los equipos reales no eligen por estética de catálogo. Comparan lo que ya tienen en producción con lo que podría sustituirlo.
Por eso el baseline relevante aquí es Gemini 2.5 Flash. Ha sido la opción low-latency reasoning madura dentro del Gemini API público. La página oficial de 2.5 Flash sigue listándolo en Stable, y su model card mantiene el estado de general availability.
Gemini 3.1 Flash-Lite llega con otro encuadre. Según los release notes, se lanzó el 3 de marzo de 2026 como el primer Flash-Lite de la serie Gemini 3. Su model page lo empuja para translation, transcription, simple document processing, high-volume structured extraction y model routing. Es decir, Google no lo vende como juguete barato, sino como un carril de producción rápido y económico.
La lectura correcta es:
- Gemini 2.5 Flash es el caballo de batalla estable.
- Gemini 3.1 Flash-Lite es el retador Preview más rápido y más barato.
- La decisión real es de routing, no de prestigio.
Precios, capa gratuita y grounding a 19 de marzo de 2026

La mayoría de páginas posicionadas aciertan solo a medias: saben que 3.1 Flash-Lite es más barato que 2.5 Flash, pero no convierten eso en una decisión productiva completa.
En la pricing page, a 19 de marzo de 2026:
- Gemini 3.1 Flash-Lite Preview: uso estándar gratis, luego
\$0.25input y\$1.50output por 1M tokens - Gemini 2.5 Flash: uso estándar gratis, luego
\$0.30input y\$2.50output por 1M tokens
Eso significa:
- input aproximadamente 17% más barato
- output 40% más barato
Para muchos flujos reales, la diferencia de output pesa más que la de input. Resúmenes, clasificación con justificación, respuestas de soporte, extracción JSON y otras tareas con salida relativamente larga crecen más por el lado de output. En ese contexto, la ventaja de 3.1 Flash-Lite es material.
Batch mantiene el mismo sentido:
- 3.1 Flash-Lite Batch:
\$0.125input /\$0.75output - 2.5 Flash Batch:
\$0.15input /\$1.25output
Pero la misma página de precios también muestra por qué 2.5 Flash no ha sido desplazado. La diferencia crítica está en grounding:
- Gemini 2.5 Flash mantiene Search grounding gratis hasta 500 RPD
- Gemini 3.1 Flash-Lite Preview no tiene Search grounding gratis en free tier y pasa a una lógica de 5,000 prompts por mes antes de cobrar
Si tu aplicación depende de la herramienta integrada de búsqueda de Google, 2.5 Flash sigue siendo más fácil de justificar como default. Si grounding no es central, el menor coste de 3.1 Flash-Lite gana mucho peso.
En español ya existe Gemini API free quota 2026 para profundizar en la parte de nivel gratuito. También tienes Gemini API error troubleshooting guide para la parte operativa. En cambio, algunos detalles finos sobre thinking controls y límites por tier siguen estando mejor cubiertos en inglés, y los marco más abajo como fallback explícito.
Hay otra lectura útil aquí que muchas páginas de ranking pasan por alto: más barato no siempre significa mejor coste total del sistema. Si tu aplicación depende de grounding integrado, de una política de rollback simple o de un default fácil de defender ante clientes internos, el ahorro por token de 3.1 Flash-Lite no es el único coste que importa. La fricción operacional también cuenta, y en ese eje 2.5 Flash todavía compra tranquilidad.
Benchmarks: dónde gana 3.1 Flash-Lite y dónde 2.5 Flash aún importa

La fuente oficial más útil aquí es la página de DeepMind, donde Gemini 3.1 Flash-Lite High se compara con Gemini 2.5 Flash Dynamic.
Las filas importantes son estas:
| Métrica | Gemini 3.1 Flash-Lite | Gemini 2.5 Flash | Lectura |
|---|---|---|---|
| Output speed | 363 tokens/s | 249 tokens/s | 3.1 Flash-Lite |
| Humanity's Last Exam | 16.0% | 11.0% | 3.1 Flash-Lite |
| GPQA Diamond | 86.9% | 82.8% | 3.1 Flash-Lite |
| MMMU-Pro | 76.8% | 66.7% | 3.1 Flash-Lite |
| LiveCodeBench | 72.0% | 62.6% | 3.1 Flash-Lite |
| MRCR v2 at 128k | 60.1% | 54.3% | 3.1 Flash-Lite |
| FACTS | 40.6% | 50.4% | Gemini 2.5 Flash |
| MRCR v2 at 1M | 12.3% | 21.0% | Gemini 2.5 Flash |
La historia honesta es más matizada que "el modelo nuevo gana en todo".
Razones para mover tráfico a 3.1:
- es más rápido
- es más barato
- sale mejor parado en varias señales públicas de reasoning, coding y multimodalidad
Razones para no borrar 2.5 demasiado pronto:
- FACTS sigue favoreciendo a 2.5, y eso importa si te importa grounding factual
- MRCR a 1M sigue favoreciendo a 2.5, y eso importa si realmente trabajas con documentos muy largos
Por eso no conviene reemplazar 2.5 Flash en todas partes el primer día. Si tu producto vive de respuestas grounded o de recuperación fiable en contexto muy largo, 2.5 sigue teniendo un papel defendible.
El launch post oficial remarca 2.5x más velocidad hasta el primer token y 45% más output speed frente a 2.5 Flash. Son cifras que explican el ruido en la SERP, pero no eliminan las caveats del resto de páginas oficiales.
Riesgo Preview, límites y lo que todavía compras con Stable
Las victorias en benchmark son solo la mitad de la decisión. La otra mitad es el lifecycle status.
La rate-limits page oficial deja tres mensajes fáciles de pasar por alto:
- los límites aplican por proyecto, no por API key
- los preview models suelen tener límites más restrictivos
- los límites publicados no están garantizados y la capacidad real puede variar
Ese es el sentido operativo de Preview. No significa "no lo uses", pero sí "no lo trates como baseline inmóvil".
La misma página también muestra un punto favorable para 3.1 Flash-Lite. En la tabla pública de Batch API Tier 1:
- Gemini 3.1 Flash-Lite Preview: 10,000,000 enqueued batch tokens
- Gemini 2.5 Flash: 3,000,000 enqueued batch tokens
Si manejas colas asíncronas grandes, ahí hay una señal real de throughput. Aun así, la propia página recuerda que la capacidad puede variar.
Stable todavía compra tres cosas:
- Menos churn de lifecycle
- Historia de grounding gratis más clara
- Más facilidad para justificar el default en caso de incidente
Si quieres profundizar en el ajuste de thinking, hoy el recurso más útil en este repo sigue siendo el fallback en inglés Gemini API thinking-level guide. Lo mismo aplica al desglose fino por tier en Gemini API rate-limits-per-tier guide.
Qué modelo usar según la carga de trabajo
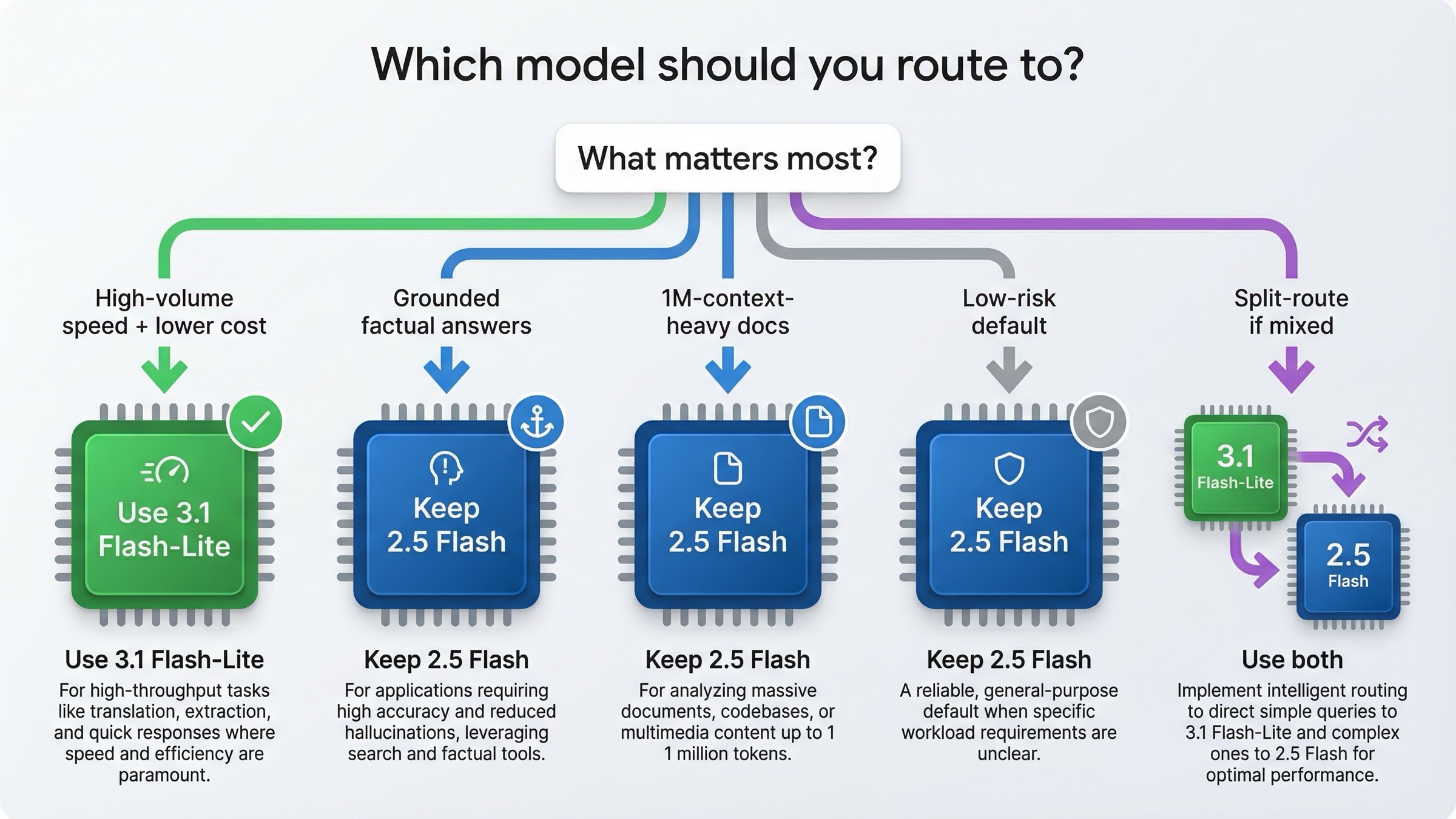
Si conviertes la comparativa en política de enrutamiento, la decisión se aclara enseguida.
| Carga | Primer candidato | Por qué |
|---|---|---|
| Traducción a escala | Gemini 3.1 Flash-Lite | La propia documentación lo posiciona ahí y el perfil precio/velocidad encaja perfecto |
| Extracción estructurada / JSON | Gemini 3.1 Flash-Lite | El output más barato y la menor latencia pesan más que Stable |
| Routing / clasificación | Gemini 3.1 Flash-Lite | La model page cita routing como caso ideal |
| Coding ligero / generación UI | Gemini 3.1 Flash-Lite | Mejor LiveCodeBench y mejor velocidad |
| Asistentes grounded con Search | Gemini 2.5 Flash | Grounding gratis y mejor FACTS lo vuelven más seguro |
| Razonamiento en documentos cerca de 1M | Gemini 2.5 Flash | Sigue ganando la fila de MRCR a 1M |
| Default productivo de bajo riesgo | Gemini 2.5 Flash | Stable / GA sigue importando |
| Sistemas con split routing | Ambos | 2.5 para grounded/long-context, 3.1 para fast high-volume |
Además, los controles de thinking no son idénticos. El model card de 2.5 Flash habla de configurable thinking budgets, mientras que la narrativa oficial de 3.1 Flash-Lite enfatiza reasoning levels. Si tu arquitectura depende de ajustar muy fino el presupuesto de inferencia, esa diferencia importa.
Cómo migrar sin arrepentirte
La mejor estrategia en marzo de 2026 no es "cambiar todo", sino un rollout por etapas.
-
Empieza por rutas de bajo riesgo y alto volumen
Traducción, extracción, clasificación y routing son los lugares donde la mejora de velocidad y coste se convierte más rápido en valor. -
Mantén grounded y long-context en 2.5 Flash
Si dependes de Search grounding o tus evals se apoyan de verdad en la ventana de 1M, no elimines 2.5 Flash demasiado pronto. -
Conserva una vía de fallback
Aunque 3.1 se vea mejor en tablas públicas, no borres la ruta de 2.5 hasta validar tus prompts, latencia y patrones de error.
La regla práctica se puede resumir así:
- si tu cuello de botella es coste o velocidad, empieza por 3.1
- si tu cuello de botella es grounding, long-context o estabilidad, conserva 2.5
- si puedes dividir tráfico, usa ambos
También conviene medir la migración con un criterio algo más serio que "¿bajó el coste por token?". Lo correcto es mirar tres señales a la vez: latencia real, tasa de error en tus prompts y porcentaje de respuestas que luego requieren revisión humana. En bastantes equipos, 3.1 Flash-Lite paga solo en traducción, extracción y routing, mientras que 2.5 Flash sigue siendo mejor negocio cuando el problema principal no es el precio sino la previsibilidad del carril por defecto.
FAQ
¿Gemini 3.1 Flash-Lite es mejor que Gemini 2.5 Flash?
En muchas tareas rápidas y baratas de reasoning, sí. Pero si incluyes Stable, grounding gratis, FACTS y comportamiento en contexto de 1M, Gemini 2.5 Flash sigue pudiendo ser la mejor opción.
¿Gemini 3.1 Flash-Lite es realmente más barato?
Sí, frente a Gemini 2.5 Flash. La pricing page oficial marca \$0.25 input / \$1.50 output para 3.1 Flash-Lite frente a \$0.30 input / \$2.50 output para 2.5 Flash.
¿Por qué no reemplazar 2.5 Flash en todas partes ya mismo?
Porque 3.1 sigue en Preview y la comparativa oficial todavía deja a 2.5 por delante en FACTS y MRCR a 1M. Para rutas grounded o de contexto muy largo, eso no es una nota al pie.
¿Cuál es la postura más defendible ahora mismo?
Enrutar por tipo de trabajo. 3.1 Flash-Lite para carriles rápidos y baratos; 2.5 Flash para grounding, contexto largo y rutas sensibles a estabilidad.