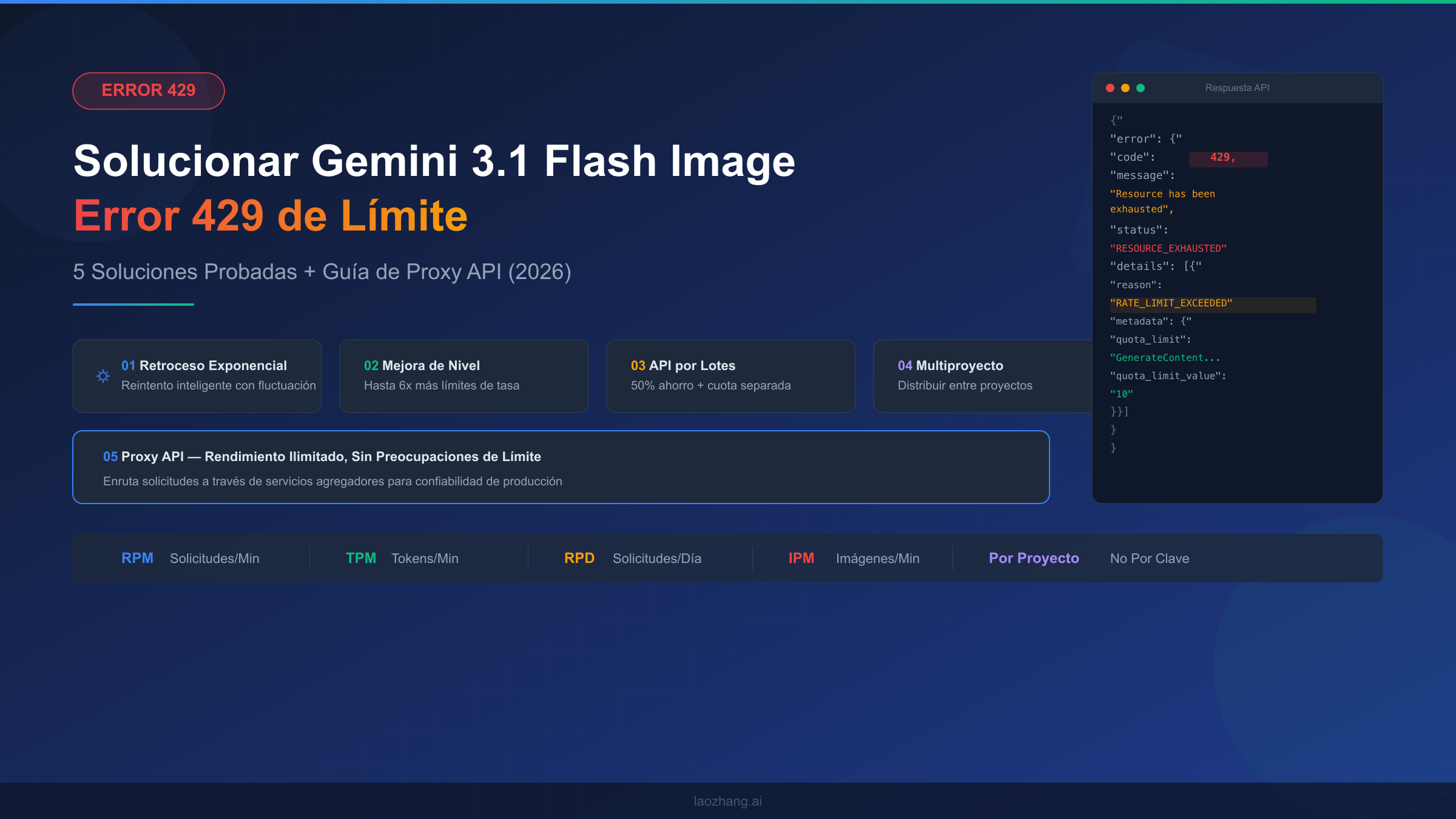
Al encontrarte con el temido error 429 RESOURCE_EXHAUSTED mientras generas imágenes con Gemini 3.1 Flash, debes saber que el error 429 de límite de tasa de Gemini 3.1 Flash Image significa que has excedido una de las cuatro dimensiones de límite de tasa: RPM (solicitudes por minuto), RPD (solicitudes por día), TPM (tokens por minuto) o IPM (imágenes por minuto). Puedes solucionarlo inmediatamente implementando retroceso exponencial con fluctuación aleatoria, mejorando tu nivel de facturación para obtener límites hasta 6 veces mayores, utilizando la API por Lotes para un 50% de ahorro en costos con cuotas separadas, distribuyendo solicitudes entre múltiples proyectos, o enrutando a través de un proxy API para rendimiento ilimitado. Esta guía te lleva paso a paso por el diagnóstico exacto de cuál límite alcanzaste y la elección de la solución correcta para tu caso de uso.
Entendiendo el Error 429 de Gemini 3.1 Flash Image

Cuando tu llamada a la API de Gemini 3.1 Flash Image devuelve un código de estado 429, el cuerpo de la respuesta contiene información diagnóstica crítica que la mayoría de los desarrolladores pasan por alto. Antes de saltar a las soluciones, comprender la estructura del error te ayuda a identificar el cuello de botella exacto en lugar de aplicar correcciones genéricas que pueden no abordar tu situación específica. El error 429 es la forma que tiene Google de indicarte que tu proyecto ha consumido su cuota asignada para una dimensión específica, y la respuesta realmente te dice cuál si sabes dónde buscar.
Así es como se ve la respuesta de error real cuando alcanzas un límite de tasa con el modelo Gemini 3.1 Flash Image Preview:
json{ "error": { "code": 429, "message": "Resource has been exhausted (e.g. check quota).", "status": "RESOURCE_EXHAUSTED", "details": [ { "@type": "type.googleapis.com/google.rpc.ErrorInfo", "reason": "RATE_LIMIT_EXCEEDED", "metadata": { "quota_limit": "GenerateContentRequestsPerMinutePerProjectPerRegion", "quota_limit_value": "10", "consumer": "projects/your-project-id", "quota_metric": "generativelanguage.googleapis.com/generate_content_requests" } } ] } }
El campo metadata.quota_limit es la clave para diagnosticar tu problema. Te indica exactamente cuál de las cuatro dimensiones de límite de tasa has agotado. La API de Gemini de Google aplica límites de tasa en cuatro dimensiones distintas, y cada una opera de forma independiente — lo que significa que podrías estar dentro de tu cuota de RPM pero excediendo tu asignación diaria de RPD. Comprender estas cuatro dimensiones es esencial porque la solución para una violación de RPM es fundamentalmente diferente a la de una violación de RPD.
Las cuatro dimensiones de límite de tasa para Gemini 3.1 Flash Image Preview funcionan de la siguiente manera. RPM (Solicitudes Por Minuto) cuenta cuántas llamadas API realizas dentro de una ventana móvil de 60 segundos, y este es el límite más común que los desarrolladores alcanzan durante operaciones en ráfaga. TPM (Tokens Por Minuto) rastrea el total de tokens de entrada consumidos dentro de la misma ventana móvil, lo cual importa para la generación de imágenes porque los prompts con descripciones detalladas consumen significativamente más tokens que las consultas de texto simples. RPD (Solicitudes Por Día) impone un tope diario estricto que se reinicia a medianoche hora del Pacífico — esto es particularmente restrictivo en el nivel gratuito, donde Google recortó las cuotas un 92% en diciembre de 2025. Finalmente, IPM (Imágenes Por Minuto) es una dimensión única para modelos generadores de imágenes como Gemini 3.1 Flash Image Preview, y frecuentemente es el cuello de botella oculto que los desarrolladores no detectan porque están acostumbrados a pensar solo en RPM y TPM por su experiencia con modelos de solo texto.
Un dato crítico que muchos desarrolladores desconocen: los límites de tasa en la API de Gemini se aplican por proyecto, no por clave API. Esto significa que crear múltiples claves API dentro del mismo proyecto de Google Cloud no proporciona absolutamente ningún beneficio para los límites de tasa. Si tienes tres claves en un proyecto, las tres comparten el mismo fondo de cuota. Esta distinción se vuelve importante cuando discutamos la estrategia de distribución multiproyecto en la Solución 4.
También vale la pena señalar la diferencia entre un error 429 y un error 503, ya que ambos pueden interrumpir tu pipeline de generación de imágenes. Un 429 significa que has consumido tu cuota asignada y necesitas esperar o aumentar tus límites. Un 503 (Servicio No Disponible) indica un problema temporal del lado del servidor de Google — en ese caso, un simple reintento después de una breve espera generalmente es suficiente. Las estrategias de corrección difieren significativamente, así que verificar el código de estado antes de aplicar una solución es importante.
Diagnóstico Rápido — ¿Qué Límite de Tasa Alcanzaste?
Antes de aplicar cualquier corrección, necesitas determinar exactamente qué dimensión de límite de tasa has agotado. Implementar ciegamente retroceso exponencial cuando en realidad has alcanzado tu tope diario de RPD significa que tus reintentos seguirán fallando durante horas hasta medianoche hora del Pacífico. Este enfoque diagnóstico te ahorra tiempo evitando la solución incorrecta, y toma menos de un minuto identificar la causa raíz.
Comienza examinando el campo quota_limit en tu respuesta de error. El valor se mapea directamente a una de las cuatro dimensiones, y cada una tiene un identificador de cadena distinto que Google usa internamente. Cuando ves GenerateContentRequestsPerMinutePerProjectPerRegion, has alcanzado tu límite de RPM — esto típicamente se resuelve en 60 segundos si simplemente haces una pausa. Si el campo muestra GenerateContentTokensPerMinutePerProjectPerRegion, tu TPM está agotado, lo que significa que tus prompts están consumiendo demasiados tokens demasiado rápido. El valor GenerateContentRequestsPerDayPerProjectPerRegion indica una violación de RPD, que es la más frustrante porque no se reiniciará hasta medianoche hora del Pacífico. Y si encuentras GenerateContentImagesPerMinutePerProjectPerRegion, has alcanzado el tope de IPM específicamente para la salida de imágenes — un límite que solo aplica a variantes de modelos generadores de imágenes.
Si tu respuesta de error no incluye el objeto metadata detallado (lo cual ocurre con algunas versiones anteriores del SDK), puedes usar un enfoque de eliminación. Verifica la frecuencia de tus solicitudes en los últimos 60 segundos — si has estado haciendo llamadas rápidas consecutivas, RPM o IPM probablemente sea el culpable. Si has estado ejecutando un trabajo por lotes durante todo el día, verifica tu conteo total de solicitudes diarias contra la asignación de RPD de tu nivel. Puedes verificar tu nivel actual y sus límites asociados visitando la página de cuotas de Google AI Studio, que muestra tu uso en tiempo real y la capacidad restante para cada dimensión.
El siguiente proceso de decisión te ayuda a identificar rápidamente el problema y saltar directamente a la solución más relevante:
- ¿El error apareció durante llamadas API rápidas consecutivas (en segundos)? → Probablemente RPM o IPM. Aplica la Solución 1 (retroceso exponencial) para alivio inmediato, luego considera la Solución 2 (mejora de nivel) para una corrección permanente.
- ¿El error apareció después de uso sostenido durante el día? → Probablemente RPD. Espera hasta medianoche PT, o aplica la Solución 2 (mejora de nivel) para aumentar tu asignación diaria.
- ¿El error apareció con prompts muy largos o detallados? → Probablemente TPM. Simplifica tus prompts o aplica la Solución 1 para distribuir las solicitudes en el tiempo.
- ¿Estás en el nivel gratuito y alcanzaste los límites rápidamente? → Muy probablemente RPD (el RPD del nivel gratuito fue recortado un 92% en diciembre de 2025). La Solución 2 (habilitar facturación para Nivel 1) es la corrección permanente más rápida.
También puedes verificar tu nivel actual programáticamente revisando el estado de facturación de Google Cloud. Los usuarios del nivel gratuito tienen los límites más restrictivos en las cuatro dimensiones. Mejorar al Nivel 1 simplemente requiere habilitar una cuenta de facturación en tu proyecto — el aumento del límite de tasa típicamente surte efecto en minutos. Para un desglose detallado de límites de tasa por nivel, consulta nuestra guía dedicada que mapea cuotas exactas para cada variante de modelo.
Hay otra técnica de diagnóstico que vale la pena mencionar para desarrolladores que quieren monitorear su consumo de cuota de forma proactiva en lugar de reactiva. La Consola de Google Cloud proporciona una página de Cuotas y Límites del Sistema donde puedes ver gráficos de uso en tiempo real para cada dimensión de límite de tasa. Navega a la sección IAM y Administración de tu proyecto, luego selecciona Cuotas. Filtra por "generativelanguage.googleapis.com" para ver todas las cuotas de la API de Gemini. Estos gráficos muestran tus patrones de uso a lo largo del tiempo, facilitando detectar si estás constantemente rozando un límite particular o solo experimentando picos ocasionales. También es posible configurar alertas de cuota — puedes configurar notificaciones al 50%, 80% y 90% de uso, dándote advertencia temprana antes de que tu aplicación comience a recibir errores 429. Este monitoreo proactivo es especialmente valioso para sistemas en producción donde los errores de límite de tasa impactan directamente la experiencia del usuario.
Solución 1 — Retroceso Exponencial con Lógica de Reintento Inteligente
El retroceso exponencial es la primera línea de defensa contra errores 429 y debería implementarse en cada aplicación de producción que llame a la API de Gemini, independientemente de qué otras soluciones apliques. El concepto es sencillo: cuando recibes una respuesta 429, esperas una cantidad de tiempo creciente antes de reintentar. Pero una implementación ingenua que simplemente duplica el tiempo de espera puede crear problemas de estampida cuando múltiples instancias reintentan simultáneamente. Agregar fluctuación aleatoria a tus intervalos de retroceso distribuye los intentos de reintento de manera más uniforme y reduce significativamente la probabilidad de colisiones repetidas en el límite de la tasa.
Implementación en Python
La implementación en Python a continuación usa el SDK google-generativeai con un wrapper de reintento personalizado que maneja diferentes tipos de límites de tasa de forma inteligente. Para límites basados en RPM, usa retrasos iniciales más cortos ya que la ventana se reinicia cada 60 segundos. Para límites de RPD, la estrategia cambia a retrasos mucho más largos o lanza una excepción para señalar que reintentar es inútil hasta el reinicio diario.
pythonimport time import random import google.generativeai as genai genai.configure(api_key="YOUR_API_KEY") def generate_image_with_retry(prompt, max_retries=5, base_delay=1.0): """Generate image with exponential backoff and jitter.""" model = genai.GenerativeModel("gemini-3.1-flash-image-preview") for attempt in range(max_retries): try: response = model.generate_content( prompt, generation_config={"response_mime_type": "image/png"} ) return response except Exception as e: error_str = str(e) if "429" not in error_str and "RESOURCE_EXHAUSTED" not in error_str: raise # Non-rate-limit error, don't retry if "PerDay" in error_str: print("Daily limit reached. Retrying won't help until midnight PT.") raise # Exponential backoff with full jitter delay = base_delay * (2 ** attempt) + random.uniform(0, 1) delay = min(delay, 60) # Cap at 60 seconds print(f"Rate limited. Retry {attempt + 1}/{max_retries} in {delay:.1f}s") time.sleep(delay) raise Exception("Max retries exceeded")
Implementación en Node.js
Para aplicaciones Node.js, la implementación sigue el mismo patrón pero usa sintaxis async/await y el paquete @google/generative-ai. El cálculo de fluctuación usa Math.random() para agregar aleatoriedad al intervalo de retraso, previniendo reintentos sincronizados entre múltiples instancias del servidor.
javascriptconst { GoogleGenerativeAI } = require("@google/generative-ai"); const genAI = new GoogleGenerativeAI("YOUR_API_KEY"); async function generateImageWithRetry(prompt, maxRetries = 5, baseDelay = 1000) { const model = genAI.getGenerativeModel({ model: "gemini-3.1-flash-image-preview" }); for (let attempt = 0; attempt < maxRetries; attempt++) { try { const result = await model.generateContent({ contents: [{ parts: [{ text: prompt }] }], generationConfig: { responseMimeType: "image/png" } }); return result; } catch (error) { const msg = error.message || ""; if (!msg.includes("429") && !msg.includes("RESOURCE_EXHAUSTED")) throw error; if (msg.includes("PerDay")) { throw new Error("Daily limit reached. Wait until midnight PT."); } const delay = Math.min(baseDelay * Math.pow(2, attempt) + Math.random() * 1000, 60000); console.log(`Rate limited. Retry ${attempt + 1}/${maxRetries} in ${(delay/1000).toFixed(1)}s`); await new Promise(resolve => setTimeout(resolve, delay)); } } throw new Error("Max retries exceeded"); }
Hay algunos matices para hacer que el retroceso exponencial funcione bien en producción. Primero, siempre establece un tope máximo de retraso (60 segundos es razonable para límites de RPM) para prevenir esperas excesivamente largas durante la limitación de tasa sostenida. Segundo, considera implementar un patrón de disyuntor encima de la lógica de reintento: si recibes cinco errores 429 consecutivos, detén temporalmente todas las solicitudes durante un período de enfriamiento en lugar de continuar martillando la API. Esto no solo es más respetuoso con la infraestructura de Google sino que también permite que tu cuota se recupere más rápido. Tercero, registra cada encuentro con 429 con los detalles completos del error incluyendo el campo quota_limit — estos datos son invaluables para comprender tus patrones de uso y decidir cuándo mejorar tu nivel o cambiar a una solución más escalable.
Aunque el retroceso exponencial es esencial, es importante comprender sus limitaciones. Maneja bien los picos temporales de RPM, pero no puede resolver problemas estructurales como exceder consistentemente el límite diario de tu nivel o necesitar rendimiento sostenido por encima de tu tasa asignada. Piensa en él como una red de seguridad, no como una estrategia de escalamiento. Si te encuentras dependiendo de reintentos para más del 10-15% de tus solicitudes, es hora de considerar las soluciones más fundamentales que siguen.
Solución 2 — Mejora Tu Nivel de API para Límites Más Altos
Mejorar tu nivel de facturación de Google Cloud es la forma más directa de aumentar permanentemente tus límites de tasa en las cuatro dimensiones. El sistema de niveles de Google está diseñado para desbloquear progresivamente cuotas más altas a medida que demuestras uso legítimo a través de umbrales de gasto y antigüedad de la cuenta. Para muchos desarrolladores, simplemente habilitar la facturación (pasar de Gratuito a Nivel 1) proporciona un aumento inmediato y dramático en la capacidad disponible, frecuentemente resolviendo errores 429 sin ningún cambio de código.
El sistema de niveles funciona de la siguiente manera (verificado en la documentación de Google AI for Developers, 2026-03-09): el nivel Gratuito está disponible para usuarios en países y regiones elegibles, con los límites más restrictivos que fueron reducidos aún más en diciembre de 2025. El Nivel 1 requiere vincular una cuenta de facturación pagada a tu proyecto de Google Cloud, y la mejora típicamente surte efecto en minutos. El Nivel 2 requiere un gasto total superior a $250 y al menos 30 días desde tu primer pago. El Nivel 3 requiere superar $1,000 en gasto total con el mismo mínimo de 30 días. Cada nivel trae límites sustancialmente más altos en RPM, TPM, RPD e IPM — con el Nivel 1 solo frecuentemente proporcionando un aumento de 3-6x sobre el nivel gratuito.
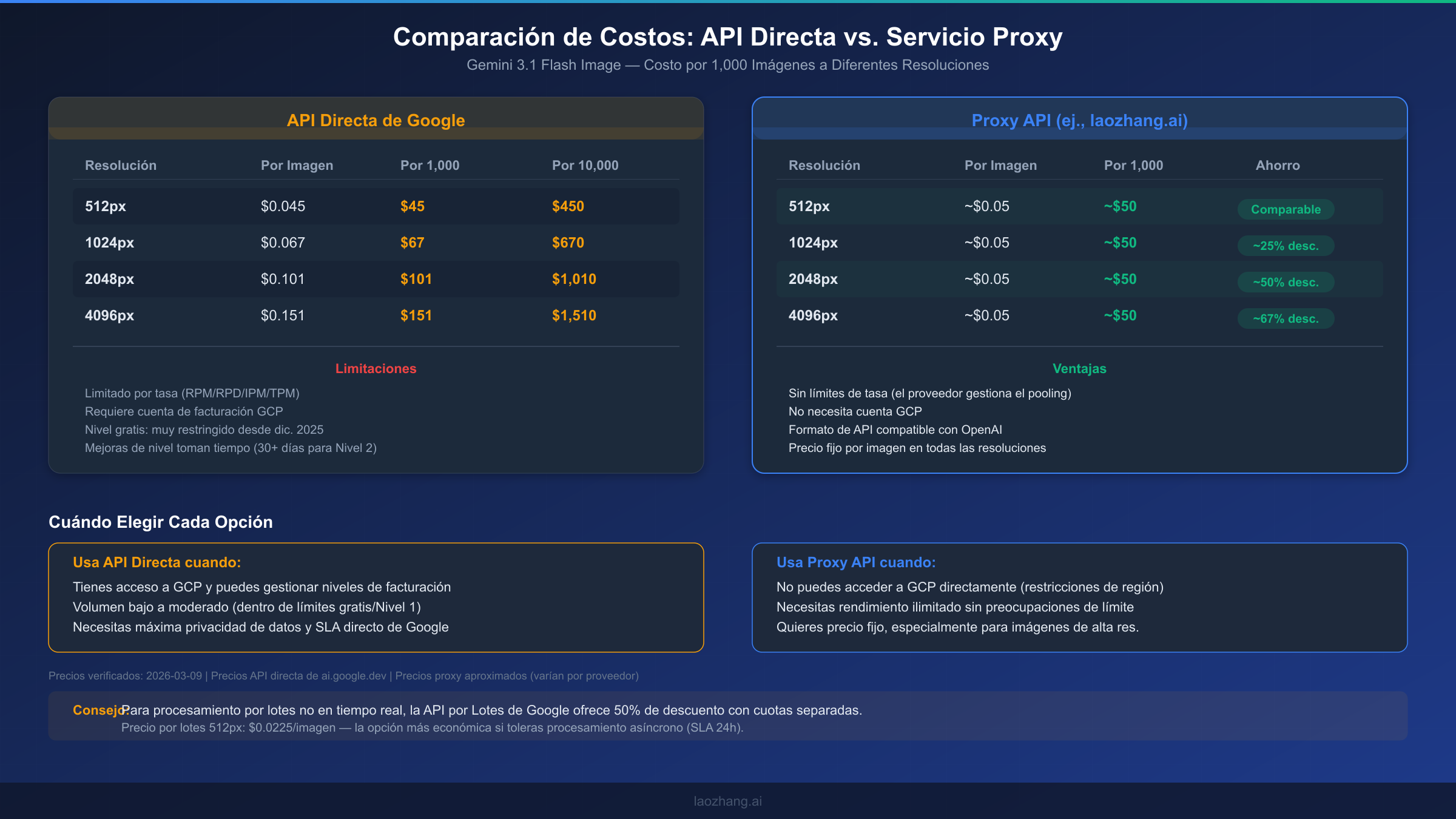
La consideración de costos para mejorar de nivel depende mucho de tu patrón de uso. Si estás generando menos de cien imágenes por día, el nivel gratuito puede técnicamente ser suficiente fuera de los períodos de ráfaga, pero constantemente lucharás contra los límites de RPD. Habilitar la facturación no significa que gastarás dinero inmediatamente — solo pagas por lo que uses por encima de la cuota gratuita. El precio de generación de imágenes de Gemini depende de la resolución: $0.045 por imagen a 512px, $0.067 a 1024px, $0.101 a 2048px y $0.151 a 4096px (Google AI for Developers, 2026-03-09 verificado). Para una aplicación en producción generando 500 imágenes por día a resolución de 1024px, el costo diario sería aproximadamente $33.50 — una inversión razonable considerando las ganancias en confiabilidad.
Para mejorar tu nivel, navega a Google AI Studio o la Consola de Google Cloud y habilita la facturación en tu proyecto. El proceso es sencillo: crea una cuenta de facturación si no tienes una, vincúlala a tu proyecto API, y la mejora de nivel se propaga en aproximadamente 10 minutos. Para alcanzar el Nivel 2 y superiores, el requisito principal es el gasto acumulativo, que ocurre naturalmente a medida que usas la API. No hay un proceso de solicitud o aprobación separado — solo uso consistente que cruza los umbrales de gasto.
Una nota de planificación importante: el período de espera de 30 días para el Nivel 2 y el Nivel 3 significa que no puedes acelerar la ruta de mejora. Si anticipas necesitar límites más altos en el futuro cercano, la mejor estrategia es habilitar la facturación temprano (incluso si tu uso actual es mínimo) para que el reloj comience a correr. De esta manera, cuando tu aplicación escale y necesites los límites del Nivel 2, ya habrás satisfecho el requisito de tiempo.
Aquí tienes un análisis práctico de costo-beneficio para diferentes escenarios de uso que te ayudará a decidir qué nivel tiene sentido. Si estás generando alrededor de 100 imágenes por día a resolución de 1024px, el costo diario en el Nivel 1 sería aproximadamente $6.70, o alrededor de $200 por mes. A 1,000 imágenes por día — un umbral común para aplicaciones SaaS en producción — estás viendo aproximadamente $67 por día o $2,000 por mes, lo cual te coloca bien encaminado hacia la elegibilidad del Nivel 2 dentro del primer mes. Para operaciones de alto volumen generando 10,000+ imágenes diarias, los costos alcanzan $670 por día a resolución de 1024px, pero a esta escala deberías considerar seriamente la API por Lotes (Solución 3) o un proxy API (Solución 5) para reducciones significativas de costos. La idea clave es que el costo por imagen se mantiene constante entre niveles — lo que cambia es solo el techo de rendimiento, no el precio por generación.
Solución 3 — API por Lotes para Generación de Imágenes de Alto Volumen
La API por Lotes es el enfoque oficialmente recomendado por Google para la generación de imágenes de alto volumen, pero permanece sorprendentemente subutilizada porque la mayoría de las guías competidoras la omiten por completo o la mencionan solo de pasada. La API por Lotes proporciona dos ventajas críticas: opera en un sistema de cuotas completamente separado de la API en tiempo real (lo que significa que las solicitudes por lotes no cuentan contra tus límites de RPM/RPD/IPM), y ofrece un descuento del 50% en todos los costos de generación. La compensación es que las solicitudes por lotes se procesan de forma asíncrona con un SLA de 24 horas, por lo que esta solución es ideal para flujos de trabajo donde no necesitas las imágenes devueltas instantáneamente.
La cuota de la API por Lotes se mide en tokens en cola en lugar de solicitudes por minuto, y los límites son generosos incluso en niveles inferiores. Los proyectos del Nivel 1 pueden encolar hasta 1,000,000 de tokens de solicitudes por lotes, el Nivel 2 desbloquea 250,000,000 de tokens en cola, y el Nivel 3 proporciona 750,000,000 (página de límites de tasa de Google AI for Developers, 2026-03-09 verificado). Para darte contexto, un prompt típico de generación de imágenes de 50-100 palabras usa aproximadamente 70-130 tokens, lo que significa que una cola por lotes del Nivel 1 puede contener aproximadamente 7,700-14,300 solicitudes de generación de imágenes simultáneamente.
Implementación por Lotes en Python
Aquí tienes un ejemplo funcional completo que crea un trabajo por lotes, consulta el estado de finalización y recupera las imágenes generadas:
pythonimport google.generativeai as genai import time genai.configure(api_key="YOUR_API_KEY") batch_requests = [] prompts = [ "A serene mountain landscape at sunset, photorealistic", "A futuristic city skyline with flying vehicles", "An underwater coral reef teeming with colorful fish" ] for i, prompt in enumerate(prompts): batch_requests.append({ "custom_id": f"img-{i}", "method": "POST", "url": "/v1beta/models/gemini-3.1-flash-image-preview:generateContent", "body": { "contents": [{"parts": [{"text": prompt}]}], "generationConfig": {"responseMimeType": "image/png"} } }) # Step 2: Submit batch job # Note: Use the REST API or batch-specific SDK methods # The exact SDK interface may vary — check current documentation import requests, json headers = {"Content-Type": "application/json"} api_url = "https://generativelanguage.googleapis.com/v1beta/batchJobs" response = requests.post( f"{api_url}?key=YOUR_API_KEY", headers=headers, json={"requests": batch_requests} ) job = response.json() job_name = job.get("name") print(f"Batch job created: {job_name}") # Step 3: Poll for completion while True: status_resp = requests.get(f"{api_url}/{job_name}?key=YOUR_API_KEY") status = status_resp.json() state = status.get("state", "UNKNOWN") print(f"Job state: {state}") if state in ("SUCCEEDED", "FAILED", "CANCELLED"): break time.sleep(30) # Check every 30 seconds # Step 4: Retrieve results if state == "SUCCEEDED": results = requests.get(f"{api_url}/{job_name}/results?key=YOUR_API_KEY") for result in results.json().get("responses", []): custom_id = result["custom_id"] # Process each generated image print(f"Image {custom_id} generated successfully")
Hay varias consideraciones prácticas al trabajar con la API por Lotes. El SLA de 24 horas es un máximo — en la práctica, la mayoría de los trabajos por lotes se completan significativamente más rápido, frecuentemente en 1-4 horas dependiendo de la profundidad de la cola y el tamaño del trabajo. Deberías diseñar tu aplicación para consultar el estado del trabajo a intervalos razonables (cada 30-60 segundos) en lugar de implementar una espera bloqueante. El manejo de errores en modo por lotes difiere de las llamadas en tiempo real: las solicitudes individuales dentro de un lote pueden fallar independientemente, así que tu código de procesamiento de resultados necesita verificar el estado de cada respuesta e implementar lógica de reintento para los elementos fallidos. También ten en cuenta que el límite de tokens en cola cuenta todos los trabajos en cola (aún no completados), así que deberías evitar enviar más trabajo del que puedes procesar en un plazo razonable.
La API por Lotes brilla en escenarios como la generación de imágenes de productos para comercio electrónico (procesando cientos de descripciones de productos durante la noche), pipelines de marketing de contenido (generando visuales para redes sociales en masa), y creación de conjuntos de datos para entrenamiento de aprendizaje automático. Cualquier flujo de trabajo donde puedas tolerar un retraso de minutos a horas — en lugar de requerir respuestas en menos de un segundo — debería considerar seriamente la API por Lotes tanto por sus ahorros de costos como por su inmunidad a los límites de tasa en tiempo real que causan errores 429. Para una visión más amplia sobre la optimización de costos, consulta nuestra guía de solución de límites de tasa de imágenes de Gemini.
Solución 4 — Distribución de Solicitudes Multiproyecto
Dado que los límites de tasa de la API de Gemini se aplican por proyecto en lugar de por clave API, puedes efectivamente multiplicar tu cuota total disponible distribuyendo solicitudes entre múltiples proyectos de Google Cloud. Este enfoque es técnicamente sencillo: crea N proyectos, genera una clave API para cada uno, e implementa una estrategia de distribución round-robin o balanceada por carga en el código de tu aplicación. Con tres proyectos, efectivamente triplicas tus límites de RPM, RPD, IPM y TPM sin ninguna mejora de nivel ni gasto adicional por proyecto.
La implementación requiere mantener un grupo de claves API (una por proyecto) y ciclar entre ellas para cada solicitud. Aquí tienes una implementación lista para producción que maneja tanto la distribución como el respaldo cuando proyectos individuales alcanzan sus límites:
pythonimport itertools import random class MultiProjectClient: def __init__(self, api_keys: list[str]): self.api_keys = api_keys self.key_cycle = itertools.cycle(api_keys) self.failed_keys = set() def generate_image(self, prompt, max_attempts=None): max_attempts = max_attempts or len(self.api_keys) * 2 for attempt in range(max_attempts): key = next(self.key_cycle) if key in self.failed_keys: continue try: genai.configure(api_key=key) model = genai.GenerativeModel("gemini-3.1-flash-image-preview") response = model.generate_content( prompt, generation_config={"response_mime_type": "image/png"} ) return response except Exception as e: if "429" in str(e): self.failed_keys.add(key) if len(self.failed_keys) >= len(self.api_keys): self.failed_keys.clear() # Reset and retry raise Exception("All projects rate limited") else: raise raise Exception("Max distribution attempts exceeded") # Usage client = MultiProjectClient([ "API_KEY_PROJECT_1", "API_KEY_PROJECT_2", "API_KEY_PROJECT_3" ]) result = client.generate_image("A beautiful sunset over the ocean")
Una consideración arquitectónica importante: asegúrate de que cada proyecto de Google Cloud tenga habilitada su propia cuenta de facturación (o al menos comparta facturación desde una única cuenta de facturación vinculada a múltiples proyectos). Esto garantiza que cada proyecto califique independientemente para los límites de tasa de su nivel. Puedes gestionar múltiples proyectos a través del selector de proyectos de la Consola de Google Cloud, y no hay un límite práctico sobre cuántos proyectos puede poseer una sola cuenta de Google.
Respecto al cumplimiento de los Términos de Servicio: la documentación de Google establece explícitamente que "los límites de tasa se aplican por proyecto" y proporciona herramientas de gestión de cuotas por proyecto, lo cual reconoce implícitamente que los usuarios pueden operar múltiples proyectos. El enfoque no viola ningún término establecido siempre que cada proyecto sea un proyecto legítimo de Google Cloud con facturación configurada correctamente. Sin embargo, hay consideraciones prácticas a tener en cuenta — necesitas gestionar la facturación en múltiples proyectos, monitorear cuotas por separado y manejar la complejidad adicional en tu pipeline de despliegue. Esta solución funciona mejor para equipos que ya operan en un entorno multiproyecto de Google Cloud.
Solución 5 — Proxy API para Rendimiento Ilimitado
Cuando tu aplicación requiere un rendimiento alto sostenido que excede incluso los límites del Nivel 3, o cuando no puedes acceder a Google Cloud Platform directamente (común para desarrolladores en ciertas regiones), un servicio de proxy API proporciona la solución más completa a los errores 429. Los proxies API funcionan manteniendo grandes grupos de credenciales API en muchos proyectos y niveles, distribuyendo transparentemente tus solicitudes para evitar alcanzar los límites de tasa de cualquier proyecto individual. Desde la perspectiva de tu aplicación, haces llamadas API a un único punto de acceso y nunca ves errores 429 porque el proxy maneja toda la gestión de límites de tasa entre bastidores.
Al evaluar servicios de proxy API para generación de imágenes con Gemini, varios criterios importan. Primero, verifica si el proxy soporta el modelo específico que necesitas — no todos los servicios soportan gemini-3.1-flash-image-preview o sus capacidades de salida de imágenes. Segundo, verifica la estructura de precios: algunos proxies cobran por solicitud, otros por token, y algunos usan una tarifa plana por imagen. Tercero, evalúa la compatibilidad de la API — los mejores proxies ofrecen un formato de API compatible con OpenAI, lo que significa que puedes cambiar modificando solo la URL base y la clave API en tu código existente sin reescribir ninguna lógica. Finalmente, considera las garantías de confiabilidad como SLAs de tiempo de actividad, latencia geográfica y capacidad de respuesta del soporte.
Para desarrolladores buscando una opción de proxy, servicios como laozhang.ai ofrecen generación de imágenes con Gemini a aproximadamente $0.05 por imagen con una tarifa plana independiente de la resolución — lo cual representa ahorros significativos en resoluciones más altas donde el precio directo de Google varía de $0.101 a $0.151. La plataforma agrega múltiples modelos y proveedores, maneja la limitación de tasa internamente y no requiere una cuenta de GCP. Puedes probarla directamente en el playground de generación de imágenes antes de comprometerte.
El proceso de integración con la mayoría de los proxies API es notablemente simple porque exponen endpoints compatibles con OpenAI. En muchos casos, cambiar del acceso directo a la API de Google a un proxy requiere cambiar solo dos valores de configuración en tu código — la URL base y la clave API. Tu lógica existente de formateo de prompts, manejo de errores y análisis de respuestas típicamente funciona sin modificación. Aquí tienes un ejemplo mínimo mostrando cómo difiere una integración con proxy de la API directa:
python# Direct Google API import google.generativeai as genai genai.configure(api_key="GOOGLE_API_KEY") model = genai.GenerativeModel("gemini-3.1-flash-image-preview") # Via API Proxy (OpenAI-compatible format) from openai import OpenAI client = OpenAI( api_key="PROXY_API_KEY", base_url="https://api.laozhang.ai/v1" ) response = client.chat.completions.create( model="gemini-3.1-flash-image-preview", messages=[{"role": "user", "content": "A sunset over mountains"}] )
Para determinar si un proxy API es adecuado para tu caso de uso, considera este marco de decisión. Usa la API directa de Google cuando tengas acceso confiable a GCP, tu volumen se mantenga dentro de los límites de tu nivel, y necesites máxima privacidad de datos con un SLA directo de Google. Usa un proxy API cuando estés en una región con acceso restringido a GCP, tus necesidades de rendimiento excedan lo que las mejoras de nivel pueden proporcionar, quieras facturación simplificada sin gestionar proyectos de GCP, o estés construyendo un prototipo y quieras evitar la configuración de GCP por completo. Para las opciones más económicas de API de Gemini Flash Image entre diferentes proveedores, nuestra guía comparativa cubre el panorama actual.
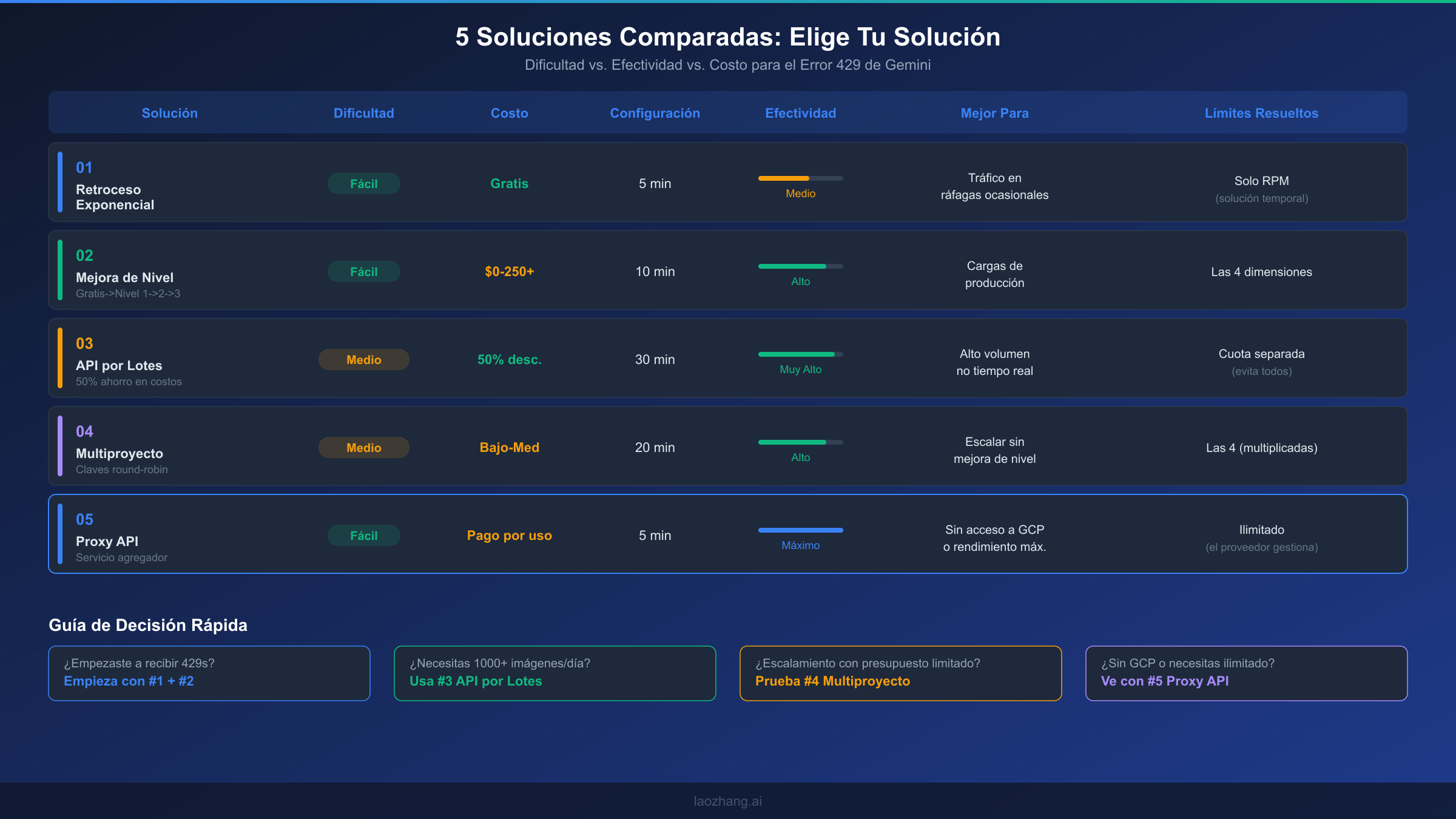
Elige Tu Solución — Comparación + Preguntas Frecuentes
La solución correcta depende de tu situación específica: cuán urgentemente necesitas corregir el error, tus restricciones presupuestarias, tu infraestructura técnica y tus requisitos de rendimiento a largo plazo. La mayoría de los despliegues en producción se benefician de combinar múltiples soluciones — por ejemplo, implementar retroceso exponencial (Solución 1) como red de seguridad base mientras mejoras al Nivel 1 o Nivel 2 (Solución 2) para capacidad sostenida.
Aquí tienes un resumen de cómo se comparan las cinco soluciones en los factores de decisión más importantes. Las Soluciones 1 y 2 son la base que todo proyecto debería implementar — retroceso para resiliencia y mejoras de nivel para capacidad. Las Soluciones 3, 4 y 5 son estrategias de escalamiento que abordan diferentes restricciones: API por Lotes para optimización de costos cuando la latencia no es crítica, multiproyecto para escalamiento gratuito dentro del ecosistema de Google, y proxy API para máxima simplicidad y rendimiento ilimitado.
Para desarrolladores que recién comienzan con la generación de imágenes de Gemini y están recibiendo errores 429 en el nivel gratuito, la ruta más rápida hacia la resolución es: primero, implementa retroceso exponencial para manejar los errores inmediatos con gracia. Segundo, habilita la facturación en tu proyecto para alcanzar el Nivel 1 — este es frecuentemente el cambio individual de mayor impacto, ya que aumenta dramáticamente tus cuotas en las cuatro dimensiones. Estos dos pasos resuelven los errores 429 para la gran mayoría de las cargas de trabajo de desarrollo y producción de volumen bajo a moderado.
Para cargas de trabajo de producción de alto volumen que generan miles de imágenes diariamente, la estrategia óptima depende de tus requisitos de latencia. Si las imágenes pueden generarse de forma asíncrona (catálogos de comercio electrónico, pipelines de contenido de marketing, datos de entrenamiento de ML), la API por Lotes (Solución 3) proporciona la mejor eficiencia de costos con un 50% de descuento con su propio grupo de cuotas separado. Si necesitas generación de imágenes en tiempo real a escala, combina una mejora de nivel (Solución 2) con distribución multiproyecto (Solución 4) para multiplicar tus límites efectivos. Y si quieres eliminar la limitación de tasa como preocupación por completo, un proxy API (Solución 5) descarga toda la gestión de cuotas al proveedor.
Preguntas Frecuentes
¿Cuánto dura el límite de tasa 429 de la API de Gemini?
Para los límites de RPM, TPM e IPM, la ventana es de 60 segundos móviles — lo que significa que si dejas de enviar solicitudes, tu cuota se renueva en un minuto. Para los límites de RPD, debes esperar hasta medianoche hora del Pacífico para que el contador diario se reinicie. No hay forma de reiniciar manualmente ningún contador de límite de tasa; las únicas opciones son esperar el reinicio natural o aumentar tus límites a través de mejoras de nivel.
¿Puedo obtener una exención de límite de tasa de Google?
Google no ofrece exenciones individuales de límite de tasa para la API de Gemini. El sistema de niveles es la ruta designada para aumentar los límites. Si necesitas límites más allá del Nivel 3, el enfoque recomendado es contactar al equipo de ventas de Google Cloud para un acuerdo empresarial, que puede incluir asignaciones de cuotas personalizadas.
¿Usar múltiples claves API en el mismo proyecto ayuda?
No. Los límites de tasa se aplican por proyecto, no por clave API. Crear claves adicionales dentro de un solo proyecto no aumenta tu cuota en ninguna dimensión. Para beneficiarte de múltiples claves, cada clave debe pertenecer a un proyecto de Google Cloud diferente (ver Solución 4).
¿Cuál es la diferencia entre los errores 429 y 503?
Un error 429 significa que has excedido tu cuota asignada — necesitas esperar a que la cuota se renueve o aumentar tus límites. Un error 503 significa que el servicio de Google mismo está temporalmente no disponible, lo cual no está relacionado con tu uso. Para errores 503, un simple reintento después de 1-5 segundos usualmente funciona. Para errores 429, necesitas las soluciones específicas descritas en esta guía.
¿La API por Lotes siempre será un 50% más barata?
El precio de la API por Lotes de Google se ha establecido consistentemente en el 50% del precio de la API en tiempo real desde su introducción. Aunque los precios pueden cambiar, el descuento incentiva a los desarrolladores a usar procesamiento por lotes, que es más eficiente para la infraestructura de Google. Verifica los precios actuales en la página oficial de precios de Gemini antes de hacer proyecciones de costos.
¿Cómo monitoreo mi uso de límite de tasa en tiempo real?
La Consola de Google Cloud proporciona monitoreo de cuotas en tiempo real bajo IAM y Administración > Cuotas. Filtra por el servicio "generativelanguage.googleapis.com" para ver todas las cuotas de la API de Gemini con gráficos de uso. También puedes configurar alertas de cuota para notificarte en umbrales configurables (por ejemplo, 80% de uso), dándote advertencia temprana antes de que los errores 429 comiencen a aparecer en producción. Para monitoreo programático, la API de Cloud Monitoring te permite consultar métricas de uso de cuotas e integrarlas en tus dashboards o sistemas de alertas existentes.
¿Hay alguna forma de aumentar los límites del nivel gratuito sin pagar?
No. Los límites del nivel gratuito son fijos y fueron significativamente reducidos en diciembre de 2025. La única forma de aumentar tus límites de tasa es habilitar la facturación en tu proyecto (lo que te mejora al Nivel 1) o usar el enfoque de distribución multiproyecto descrito en la Solución 4. Google ocasionalmente ajusta las cuotas del nivel gratuito, pero la tendencia ha sido hacia restricciones más estrictas a medida que el servicio escala, haciendo que el nivel gratuito sea adecuado principalmente para desarrollo y experimentación en lugar de cargas de trabajo de producción.