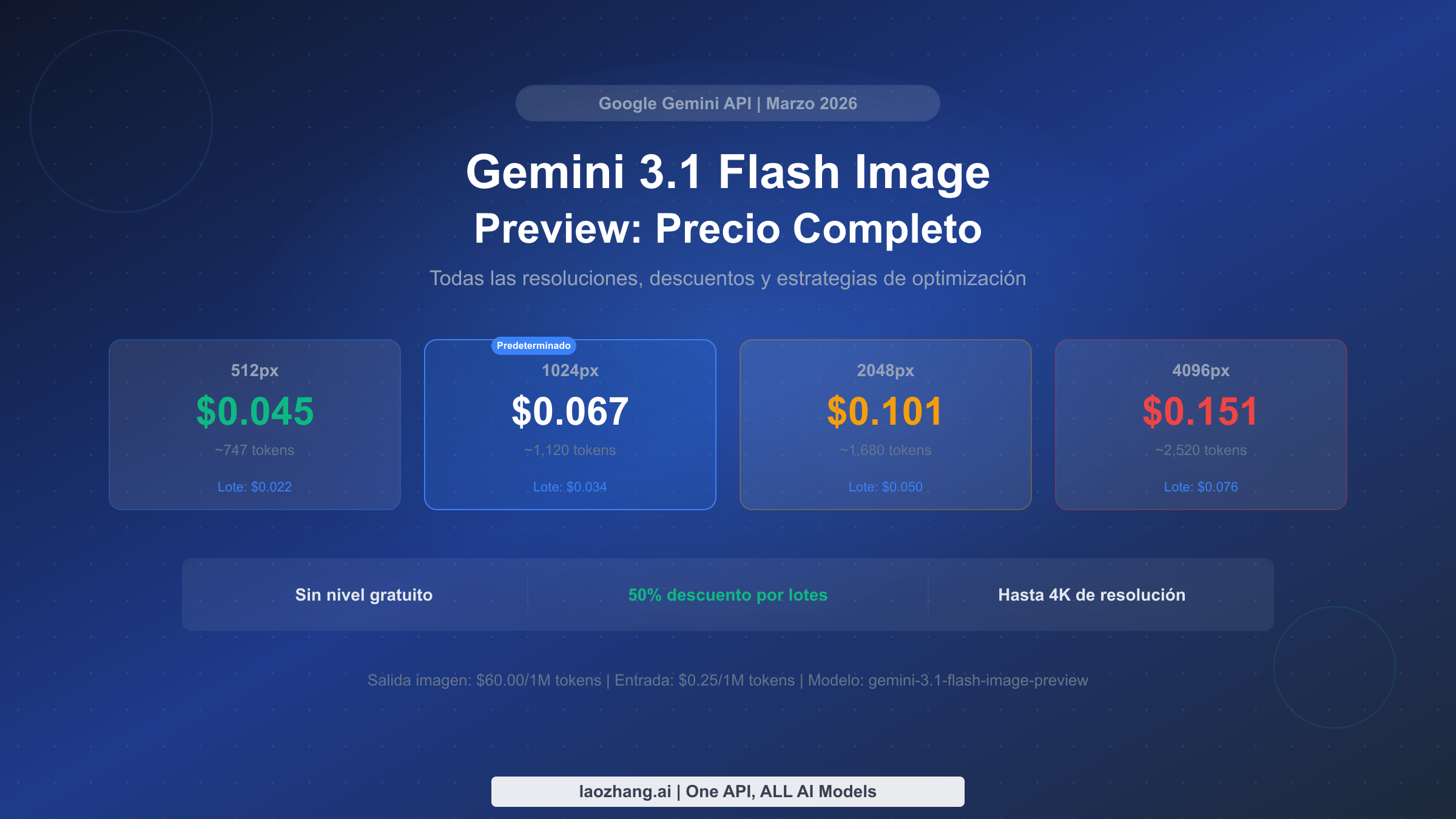
Gemini 3.1 Flash Image Preview cuesta entre $0.045 y $0.151 por imagen generada según la resolución, calculado a partir de la tarifa de Google de $60 por millón de tokens de imagen de salida. La imagen predeterminada de 1024px cuesta $0.067 cada una, y el procesamiento por lotes reduce ese precio a $0.034, un descuento fijo del 50%. No existe un nivel gratuito para este modelo a fecha de marzo de 2026, y una discrepancia de precios entre Google AI Studio y la documentación de la API permanece oficialmente sin resolver. Esta guía desglosa cada costo en cada resolución, compara los precios con 10 modelos competidores y proporciona estrategias prácticas para reducir sus gastos de generación de imágenes hasta en un 67%.
Resumen rápido
- Precios estándar: $0.045 (512px) a $0.151 (4K) por imagen, con 1024px a $0.067
- Modo por lotes: 50% de descuento en todo — 1024px baja a $0.034
- Sin nivel gratuito: A diferencia de otros modelos Gemini, la generación de imágenes siempre tiene costo
- Discrepancia de precios: AI Studio muestra tarifas de entrada/salida de texto 2x más altas que la documentación de la API — el precio de salida de imagen ($60/1M tokens) es consistente
- Mejor valor: Modo por lotes + resolución 1024px = $0.034/imagen; proveedores externos bajan a ~$0.030
- Comparado con alternativas: 60% más barato que GPT Image 1 High ($0.167), similar a DALL-E 3 Standard ($0.040)
¿Qué es Gemini 3.1 Flash Image Preview (y por qué importa el precio)?
Gemini 3.1 Flash Image Preview de Google, con nombre en código interno Nano Banana 2 (Gemini 3.1 Flash Image Preview), representa un cambio significativo en la forma en que Google aborda la generación de imágenes con inteligencia artificial. En lugar de ofrecer la creación de imágenes a través de un modelo separado como Imagen 4, este modelo integra la generación nativa de imágenes directamente en la arquitectura conversacional de Gemini. El identificador del modelo es gemini-3.1-flash-image-preview, y se lanzó en febrero de 2026 con soporte para resoluciones desde 512 píxeles hasta 4096 píxeles y relaciones de aspecto que van desde 1:1 hasta 8:1.
Comprender la estructura de precios importa mucho más de lo que podrías pensar inicialmente, porque el modelo de facturación basado en tokens crea una curva de costos que no es evidente a primera vista. A diferencia de las API de generación de imágenes con tarifa plana como DALL-E 3, donde cada imagen cuesta exactamente lo mismo independientemente de la resolución, Gemini cobra según la cantidad de tokens de salida consumidos durante la generación. Una imagen 4K cuesta aproximadamente 3.4 veces más que una imagen de 512px, y elegir la resolución incorrecta para tu caso de uso puede inflar tu factura mensual en miles de dólares a escala. El modelo se encuentra actualmente en estado "Preview", lo que significa que Google podría ajustar los precios, las capacidades o la disponibilidad sin los períodos de aviso de depreciación típicos que se aplican a los modelos generalmente disponibles.
La cuestión del precio es especialmente relevante porque este modelo no tiene absolutamente ningún nivel gratuito. Los desarrolladores familiarizados con las generosas cuotas gratuitas de Google en otros modelos Gemini — incluido el acceso gratuito a Gemini 2.0 Flash para generación de texto — a menudo asumen que pueden experimentar con la generación de imágenes sin costo alguno. No pueden hacerlo. Cada imagen generada a través del endpoint de Gemini 3.1 Flash Image Preview genera un cargo, lo que hace que la estimación precisa de costos sea esencial antes de comprometerse con este modelo en cualquier pipeline de producción.
Lo que hace que el análisis de precios sea particularmente interesante es cómo la estructura de costos de este modelo se compara con sus capacidades. Gemini 3.1 Flash Image Preview no es simplemente un generador de imágenes — es un modelo multimodal completo que puede comprender texto, analizar imágenes y crear nuevos elementos visuales dentro de un solo hilo de conversación. Esto significa que una sola llamada a la API puede combinar razonamiento de texto con generación de imágenes, reemplazando potencialmente lo que de otro modo requeriría dos llamadas separadas a la API a diferentes modelos. Cuando se tiene en cuenta el costo de ejecutar un modelo de texto más un generador de imágenes dedicado por separado, la prima efectiva por imagen del enfoque integrado de Gemini se reduce considerablemente, especialmente para aplicaciones que necesitan generación contextual de imágenes en lugar de prompts independientes.
El desglose completo de precios (incluida la discrepancia oculta)
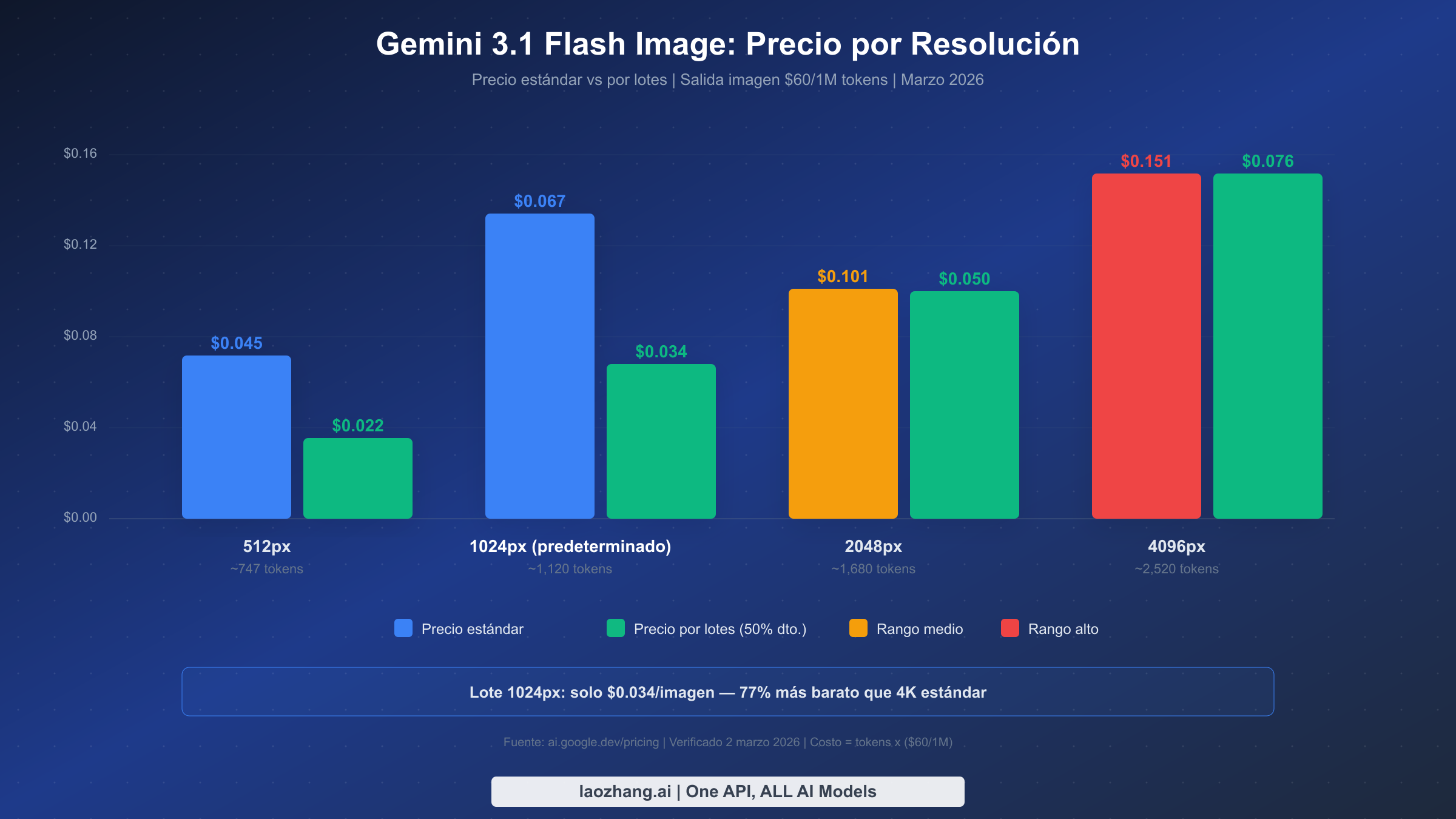
La tarificación de Gemini 3.1 Flash Image Preview opera sobre el sistema estándar de facturación basada en tokens de Google, pero la tarifa de tokens de imagen de salida se sitúa dramáticamente por encima de las tarifas de salida de texto. Según la documentación oficial de la API de Google verificada el 2 de marzo de 2026, el modelo cobra $0.25 por millón de tokens de entrada, $1.50 por millón de tokens de salida de texto y $60.00 por millón de tokens de imagen de salida. Esa tarifa de $60/1M para tokens de imagen es lo que determina el costo por imagen, ya que cada imagen generada consume entre 747 y 2,520 tokens dependiendo de la resolución solicitada.
Para una visión más profunda de cómo estas tarifas encajan en la estructura de precios más amplia de Google, consulta nuestra guía completa de precios de la API de Gemini que cubre todos los modelos Gemini incluyendo endpoints de texto, visión y audio.
Costos estándar por imagen
El costo práctico por imagen depende enteramente de la resolución. La documentación de Google especifica cantidades exactas de tokens para cada tamaño de salida, haciendo que el cálculo sea sencillo al multiplicar la cantidad de tokens por la tarifa de $60/1M.
| Resolución | Tokens de salida | Costo por imagen | Costo mensual (1K/día) |
|---|---|---|---|
| 512px | ~747 | $0.045 | $1,350 |
| 1024px (predeterminado) | ~1,120 | $0.067 | $2,010 |
| 2048px | ~1,680 | $0.101 | $3,030 |
| 4096px | ~2,520 | $0.151 | $4,530 |
Estas cifras revelan una relación casi lineal entre resolución y costo: duplicar las dimensiones en píxeles aumenta el precio aproximadamente entre un 50% y un 67%. La resolución predeterminada de 1024px representa el punto óptimo para la mayoría de las aplicaciones web, equilibrando la calidad visual con el costo a $0.067 por imagen.
Modo por lotes: 50% de descuento en todo
Google ofrece una API de procesamiento por lotes que aplica un descuento fijo del 50% a todos los costos de tokens, incluidos los tokens de imagen de salida. La contrapartida es la latencia: las solicitudes por lotes se procesan dentro de una ventana de 24 horas en lugar de devolver resultados en tiempo real. Para aplicaciones donde los resultados inmediatos no son críticos — generación de activos de marketing, creación de imágenes de catálogo, pipelines de contenido para redes sociales — el modo por lotes ofrece ahorros sustanciales.
| Resolución | Estándar | Modo por lotes | Ahorro por imagen |
|---|---|---|---|
| 512px | $0.045 | $0.022 | $0.023 |
| 1024px | $0.067 | $0.034 | $0.033 |
| 2048px | $0.101 | $0.050 | $0.051 |
| 4096px | $0.151 | $0.076 | $0.075 |
A escala, los ahorros del modo por lotes se vuelven enormes. Una empresa que genera 1,000 imágenes por día a resolución de 1024px ahorraría aproximadamente $990 por mes al cambiar del procesamiento estándar al procesamiento por lotes, sin absolutamente ninguna diferencia en la calidad de salida.
La discrepancia de precios que necesitas conocer
Existe una inconsistencia documentada de precios entre dos fuentes oficiales de Google que permanece sin resolver a fecha de marzo de 2026. Google AI Studio muestra precios de tokens de entrada a $0.50 por millón y salida de texto a $3.00 por millón, mientras que la documentación de la API muestra $0.25 y $1.50 respectivamente — exactamente la mitad de los precios de AI Studio. La tarifa de tokens de imagen de salida de $60 por millón permanece consistente en ambas fuentes, por lo que los costos por imagen listados anteriormente no se ven afectados por esta discrepancia.
Miembros de la comunidad en el Foro de Desarrolladores de Google AI informaron de esta inconsistencia a principios de 2026 sin recibir una respuesta oficial de Google. Basándonos en nuestro análisis y la referencia cruzada con datos de facturación reales compartidos en comunidades de desarrolladores, los precios de la documentación de la API ($0.25/$1.50) parecen reflejar las tarifas de facturación reales. Sin embargo, si estás construyendo proyecciones de costos para un caso de negocio, recomendamos utilizar los precios más altos de AI Studio como tu estimación conservadora hasta que Google aclare oficialmente la discrepancia. El impacto práctico es limitado para la generación de imágenes, ya que el componente de costo dominante — tokens de imagen de salida a $60/1M — es idéntico en ambas fuentes.
Costo por imagen en cada resolución (512px a 4K)
Elegir la resolución correcta es la forma más rápida de optimizar tus costos de generación de imágenes con Gemini sin sacrificar la calidad para tu caso de uso específico. La resolución que selecciones debe coincidir con el contexto de visualización previsto, no establecerse por defecto en la máxima calidad disponible. Una imagen 4K mostrada como una miniatura de 200 píxeles desperdicia más de tres veces el costo sin ninguna mejora de calidad perceptible.
Mapeo de resolución a caso de uso
Las cuatro resoluciones disponibles sirven para contextos de producción distintos. Comprender qué resolución coincide con tus requisitos reales previene el error común de sobrespecificar las dimensiones de salida, que es la causa principal de facturas de generación de imágenes inesperadamente altas entre los desarrolladores que despliegan las capacidades de imagen de Gemini a escala.
512px ($0.045/imagen) sirve para generación de miniaturas, imágenes de vista previa, creación de avatares pequeños y cualquier contexto donde el tamaño de visualización final esté por debajo de 500 píxeles. A esta resolución, Gemini genera imágenes que son perfectamente adecuadas para fotos de perfil de redes sociales, miniaturas de listados de productos en plataformas de comercio electrónico y elementos de ilustración pequeños en publicaciones de blog. La calidad visual es sorprendentemente buena para este rango de precio, y los 747 tokens de salida significan tiempos de generación más rápidos además de costos más bajos.
1024px ($0.067/imagen) es la resolución predeterminada y la opción ideal para la gran mayoría de aplicaciones web. Publicaciones estándar de redes sociales, imágenes principales de blog, gráficos para boletines por correo electrónico y elementos visuales de marketing general se muestran de manera óptima a esta resolución. La relación calidad-costo a 1024px es la mejor de las cuatro opciones, lo cual es presumiblemente la razón por la que Google la seleccionó como predeterminada. A menos que tengas una razón específica para ir más alto o más bajo, esta resolución debería ser tu opción estándar.
2048px ($0.101/imagen) entra en el territorio de producción con calidad de impresión. Folletos de marketing, fotografía de productos en alta resolución para galerías con capacidad de zoom, diapositivas de presentación mostradas en pantallas grandes y activos de publicidad digital destinados a pantallas retina se benefician del detalle adicional que proporciona la resolución 2K. La prima de precio del 50% sobre 1024px se justifica solo cuando la salida se mostrará realmente a su resolución nativa o cerca de ella.
4096px ($0.151/imagen) está diseñada para salida de gran formato: impresiones de pósters, gráficos para vallas publicitarias, pantallas digitales de gran formato y generación de imágenes con calidad de archivo. A $0.151 por imagen, esta resolución cuesta 3.4 veces más que la opción base de 512px. Los casos de uso que genuinamente requieren salida 4K son relativamente limitados, y los desarrolladores deberían evaluar cuidadosamente si su aplicación realmente necesita este nivel de detalle antes de seleccionarlo como predeterminado.
Presupuesto mensual por resolución y volumen
Planificar tu presupuesto requiere mapear tu volumen esperado contra la resolución requerida. La tabla a continuación proporciona estimaciones de costos mensuales a volúmenes de producción comunes para ayudarte a prever los gastos con precisión.
| Volumen diario | 512px | 1024px | 2048px | 4096px |
|---|---|---|---|---|
| 100 imágenes | $135 | $201 | $303 | $453 |
| 500 imágenes | $675 | $1,005 | $1,515 | $2,265 |
| 1,000 imágenes | $1,350 | $2,010 | $3,030 | $4,530 |
| 5,000 imágenes | $6,750 | $10,050 | $15,150 | $22,650 |
| 10,000 imágenes | $13,500 | $20,100 | $30,300 | $45,300 |
Estas cifras asumen precios estándar (sin lotes) y meses de 30 días. Aplicar el descuento del 50% del modo por lotes reduciría a la mitad cada número en esta tabla, haciendo que la producción de alto volumen sea significativamente más viable para aplicaciones sensibles al costo.
La relación entre volumen y costo revela un importante efecto umbral. A volúmenes bajos de 100 imágenes por día, la diferencia entre 512px y 1024px es solo $66 por mes — apenas perceptible en la mayoría de los presupuestos de proyectos. Pero a volúmenes de escala empresarial de 10,000 imágenes por día, esa misma elección de resolución crea una brecha mensual de $6,600 que puede determinar la viabilidad financiera de todo un pipeline de generación de imágenes. Esta es la razón por la que la selección de resolución merece una atención cuidadosa durante la fase de arquitectura de cualquier proyecto, no como una consideración posterior durante la optimización de costos. Los equipos que establecen por defecto la máxima resolución disponible durante el desarrollo y luego intentan reducir costos después, a menudo descubren que sus prompts, el procesamiento posterior y las expectativas de calidad se han calibrado todos para la resolución más alta, haciendo que el cambio sea más costoso que acertar desde el principio.
Cómo se compara Gemini 3.1 Flash con cada alternativa

El mercado de generación de imágenes con IA en 2026 ofrece más opciones que nunca, con precios que van desde $0.011 por imagen en el extremo inferior hasta $0.167 en el extremo superior. Posicionar Gemini 3.1 Flash Image Preview dentro de este panorama requiere considerar no solo el costo bruto, sino también la calidad, las capacidades y los requisitos de integración.
Comparación completa de 10 modelos
| Modelo | Proveedor | Costo/imagen | Mensual (1K/día) | Nivel de calidad | Ventaja clave |
|---|---|---|---|---|---|
| GPT Image 1 Low | OpenAI | $0.011 | $330 | Bajo | Opción más barata |
| Imagen 4 Fast | $0.020 | $600 | Bueno | Rápido y económico | |
| laozhang.ai (Flash Image) | Externo | $0.030 | $900 | Alto | Mismo modelo, menor precio |
| GPT Image 1 Mini High | OpenAI | $0.036 | $1,080 | Alto | Buena relación calidad/costo |
| DALL-E 3 Standard | OpenAI | $0.040 | $1,200 | Alto | Calidad establecida |
| Imagen 4 Standard | $0.040 | $1,200 | Alto | Mejor dedicado de Google | |
| Imagen 4 Ultra | $0.060 | $1,800 | Muy alto | Calidad premium | |
| Gemini 3.1 Flash Image | $0.067 | $2,010 | Muy alto | Multimodal nativo | |
| DALL-E 3 HD | OpenAI | $0.080 | $2,400 | Muy alto | Salida HD |
| GPT Image 1 High | OpenAI | $0.167 | $5,010 | Máximo | Mejor calidad disponible |
Varios patrones emergen de esta comparación exhaustiva. Gemini 3.1 Flash Image Preview se sitúa en la parte media-alta del espectro de precios, costando un 60% menos que GPT Image 1 High mientras ofrece una calidad visual comparable. Sin embargo, cuesta un 67% más que DALL-E 3 Standard y más de tres veces el precio de Imagen 4 Fast del propio portafolio de Google.
El diferenciador crítico de Gemini 3.1 Flash Image no es el costo bruto — es la arquitectura multimodal nativa. A diferencia de los modelos dedicados de generación de imágenes, Gemini 3.1 Flash Image puede generar imágenes como parte de un flujo conversacional, comprender el contexto de mensajes anteriores, editar imágenes existentes mediante instrucciones en lenguaje natural y mezclar sin problemas la generación de texto e imágenes dentro de una sola llamada a la API. Esta ventaja arquitectónica lo convierte en la opción ideal para aplicaciones donde la generación de imágenes necesita ser contextualmente consciente en lugar de operar como un endpoint independiente.
¿Cuándo es Gemini 3.1 Flash Image la elección correcta?
Gemini 3.1 Flash Image justifica su prima sobre alternativas más simples en varios escenarios específicos. La generación conversacional de imágenes donde el contexto importa — como flujos de trabajo de diseño iterativo, respuesta visual a preguntas o sesiones creativas de múltiples turnos — aprovecha las capacidades multimodales nativas del modelo de maneras que los generadores de imágenes independientes no pueden igualar. Las aplicaciones que requieren tanto análisis de texto como generación de imágenes en un solo pipeline se benefician de la complejidad reducida de usar un modelo en lugar de encadenar dos API separadas. La combinación de comprensión de texto y generación de imágenes también permite características únicas como generar imágenes basadas en el análisis de documentos o crear elementos visuales que referencian con precisión información de un contexto de texto proporcionado.
Para la generación pura de imágenes sin requisitos contextuales, sin embargo, Imagen 4 Standard a $0.040 o DALL-E 3 Standard a $0.040 ofrecen mejor eficiencia de costos. La decisión depende en última instancia de si tu aplicación necesita las capacidades multimodales que justifican el costo adicional por imagen.
Análisis de la relación precio vs calidad
La tabla de comparación revela tres niveles de precios distintos que corresponden aproximadamente a los niveles de calidad y capacidad. El nivel económico por debajo de $0.040 por imagen incluye GPT Image 1 Low, Imagen 4 Fast y acceso a través de proveedores externos — estas opciones priorizan el ahorro de costos y son adecuadas para generación de borradores, pruebas internas y aplicaciones de alto volumen donde la calidad individual de cada imagen es menos crítica que el rendimiento. El nivel intermedio desde $0.040 hasta $0.080 incluye DALL-E 3, Imagen 4 Standard y Ultra, y Gemini 3.1 Flash Image, ofreciendo el mejor equilibrio de calidad, capacidades y costo para contenido web de producción. El nivel premium por encima de $0.080 por imagen, ocupado por DALL-E 3 HD y GPT Image 1 High, ofrece la máxima calidad visual pero a costos que limitan el despliegue práctico a aplicaciones de bajo volumen y alto valor, como materiales de marketing premium y trabajo creativo profesional.
La mayoría de las aplicaciones de producción encuentran su modelo óptimo en el nivel intermedio. Dentro de esa franja, la elección entre Gemini 3.1 Flash Image a $0.067 y DALL-E 3 Standard a $0.040 se reduce a si necesitas las capacidades de contexto conversacional de Gemini. Para la generación directa de texto a imagen donde cada prompt es autosuficiente, DALL-E 3 ofrece una ventaja de costo del 40%. Para flujos de trabajo que involucran refinamiento iterativo, edición de imágenes a través de conversación o generación que necesita referenciar contexto previo, la arquitectura de Gemini proporciona un valor único que justifica la prima.
5 estrategias de optimización de costos que realmente funcionan

Reducir tus costos de generación de imágenes con Gemini no requiere sacrificar calidad ni cambiar a alternativas inferiores. Estas cinco estrategias se pueden combinar para lograr hasta un 67% de reducción de costos respecto a la tarifa estándar de 1024px de $0.067 por imagen, llevando tu costo efectivo a aproximadamente $0.022 por imagen.
Estrategia 1: Usar el modo por lotes para tareas no urgentes. La optimización de mayor impacto es transferir las cargas de trabajo elegibles a la API de procesamiento por lotes de Google, que ofrece un descuento fijo del 50% en todos los costos de tokens. Las solicitudes por lotes se procesan dentro de una ventana de 24 horas, lo que lo hace inadecuado para aplicaciones de cara al usuario en tiempo real, pero perfecto para procesamiento en segundo plano, generación de pipelines de contenido y creación masiva de activos. Un equipo que genera 1,000 imágenes de marketing diariamente a resolución de 1024px ahorra $990 por mes al enrutar esas solicitudes a través del endpoint por lotes en lugar de la API estándar. La API por lotes soporta los mismos parámetros de modelo, resoluciones y configuraciones de calidad que el endpoint estándar — la única diferencia es la latencia.
Estrategia 2: Ajustar la resolución a tus necesidades reales. La mayoría de las imágenes mostradas en la web no necesitan resolución de 2048px o 4096px. Auditar tus contextos de visualización reales y ajustar la resolución al requisito es la segunda palanca de costo más efectiva. Cambiar de 2048px a 1024px para contenido web ahorra un 33% por imagen ($0.101 baja a $0.067), y la diferencia de calidad es invisible cuando las imágenes se muestran a dimensiones web típicas. Si estás generando imágenes a 2K porque "más alto es mejor" sin un caso de uso específico de gran formato, estás gastando $1,020 más por mes de lo necesario a un volumen de 1,000 imágenes por día.
Estrategia 3: Considerar proveedores de API externos. Las plataformas de agregación de terceros ofrecen acceso al mismo modelo Gemini 3.1 Flash Image Preview a precios significativamente reducidos. Proveedores como laozhang.ai ofrecen el mismo modelo a través de un endpoint de API compatible con OpenAI a aproximadamente $0.030 por imagen — un descuento del 55% respecto a la tarifa oficial de Google de $0.067. Estas plataformas funcionan agregando el acceso a la API a través de múltiples cuentas y transfiriendo los descuentos por volumen a los usuarios. Las contrapartidas incluyen posibles diferencias de latencia y la dependencia de un intermediario externo, pero para aplicaciones sensibles al costo que generan miles de imágenes diariamente, los ahorros de más de $1,110 por mes a un volumen de 1,000 imágenes/día hacen que esto merezca una consideración seria. Para quienes exploran alternativas de nivel gratuito para la generación de imágenes con Gemini, los proveedores externos con créditos gratuitos al registrarse ofrecen lo más parecido disponible, ya que el modelo oficial no tiene nivel gratuito.
Estrategia 4: Implementar caché de prompts para plantillas repetidas. Al generar múltiples imágenes con estructuras de prompt similares — fotografía de productos con estilo consistente, plantillas de redes sociales de marca o variaciones por lotes sobre un tema — la función de caché de prompts de Google puede reducir los costos de tokens de entrada entre un 30% y un 60%. Aunque los tokens de entrada son una fracción pequeña del costo total de generación de imágenes (la tarifa de $60/1M de tokens de imagen de salida domina), el almacenamiento en caché de prompts se acumula en volúmenes altos, especialmente cuando tus prompts incluyen instrucciones detalladas del sistema o referencias de estilo que se repiten en las solicitudes.
Estrategia 5: Negociar descuentos por volumen para uso empresarial. Las organizaciones que generan más de 100,000 imágenes por mes deberían contactar al equipo de ventas de Google Cloud para obtener precios empresariales personalizados. Google ofrece descuentos por compromiso de uso y negociaciones de tarifas personalizadas en niveles de alto volumen, aunque estos acuerdos no se publican en la página de precios. Según informes de la industria, los acuerdos empresariales pueden reducir los costos por imagen entre un 15% y un 25% adicional sobre cualquier descuento por lotes, aunque los términos específicos varían según el nivel de compromiso y la duración del contrato.
Potencial de ahorro combinado
Combinar las estrategias 1, 2 y 3 puede reducir tu costo efectivo de $0.067 por imagen estándar de 1024px a aproximadamente $0.022 — una reducción del 67%. El escenario de máximo ahorro utiliza procesamiento por lotes a través de un proveedor externo a resolución de 1024px, lo cual varios equipos de producción han reportado lograr en discusiones de comunidades de desarrolladores a principios de 2026.
Cómo acceder a Gemini 3.1 Flash Image a precios más bajos
Acceder a Gemini 3.1 Flash Image Preview a precios inferiores a la tarifa oficial de Google es posible a través de plataformas de agregación de API externas que proporcionan el mismo modelo mediante endpoints alternativos. Estas plataformas ofrecen acceso legítimo agrupando cuotas de API y negociando términos por volumen, y luego transfiriendo esos ahorros a desarrolladores individuales y equipos pequeños que no calificarían para precios empresariales por su cuenta.
La opción más práctica para los desarrolladores que buscan las formas más económicas de acceder a Gemini Flash Image es a través de proveedores de API compatibles con OpenAI que soportan modelos Gemini. Estos servicios aceptan el mismo formato de solicitud que la API de OpenAI, lo que hace que la integración sea trivialmente simple si ya tienes código basado en OpenAI — típicamente solo requiere un cambio en la URL base y la clave de API, sin modificaciones en tu estructura de prompts o lógica de manejo de respuestas.
laozhang.ai es una de esas plataformas que proporciona acceso a Gemini 3.1 Flash Image Preview a aproximadamente $0.030 por imagen de 1024px, representando un ahorro del 55% sobre los precios directos de Google. La plataforma ofrece un endpoint compatible con OpenAI, sin restricciones de límite de velocidad más allá de las que Google impone a nivel de cuenta, y precios fijos por imagen que eliminan la complejidad de los cálculos de costos basados en tokens. Para equipos que generan grandes volúmenes de imágenes, la diferencia de costo se acumula significativamente: 1,000 imágenes por día a $0.030 versus $0.067 ahorra $1,110 mensuales.
Al evaluar proveedores externos, hay varios factores a considerar más allá del precio bruto. La latencia de respuesta puede variar dependiendo de la infraestructura del proveedor y la proximidad geográfica. Las garantías de tiempo de actividad difieren de los compromisos de SLA directos de Google. Las políticas de procesamiento de datos y privacidad pueden no coincidir con los estándares de nivel empresarial de Google. Para tareas de generación de imágenes no sensibles como activos de marketing, contenido de redes sociales y trabajo creativo general, estas contrapartidas son típicamente aceptables. Para aplicaciones que involucran datos sensibles o que requieren SLA garantizados, la API directa de Google sigue siendo la opción apropiada a pesar del mayor costo.
El proceso de configuración para la mayoría de los proveedores externos sigue un patrón consistente. Te registras para obtener una cuenta, obtienes una clave de API, configuras tu código existente para apuntar a la URL base del proveedor en lugar del endpoint de Google, y mantienes el resto de tu integración sin cambios. La mayoría de los proveedores ofrecen créditos gratuitos iniciales (típicamente $0.50-$1.00) para probar el servicio antes de comprometerse con un plan de pago, lo que proporciona una forma libre de riesgo de verificar la calidad y la latencia para tu caso de uso específico.
Inicio rápido: Genera tu primera imagen
Comenzar con Gemini 3.1 Flash Image Preview requiere una clave de API de Google AI Studio y una llamada sencilla a la API. Los siguientes ejemplos demuestran la solicitud mínima viable para generar una imagen, que puedes extender con parámetros adicionales para control de resolución, guía de estilo y conversaciones de múltiples turnos.
Ejemplo en Python
pythonimport google.generativeai as genai from PIL import Image from io import BytesIO import base64 genai.configure(api_key="YOUR_API_KEY") # Initialize the model model = genai.GenerativeModel("gemini-3.1-flash-image-preview") # Generate an image response = model.generate_content( "Generate a professional product photo of a sleek wireless mouse " "on a clean white background with soft studio lighting" ) # Extract and save the image for part in response.candidates[0].content.parts: if hasattr(part, "inline_data"): image_data = base64.b64decode(part.inline_data.data) image = Image.open(BytesIO(image_data)) image.save("generated_image.png") print(f"Image saved: {image.size[0]}x{image.size[1]}px")
Ejemplo con cURL
bashcurl -X POST \ "https://generativelanguage.googleapis.com/v1beta/models/gemini-3.1-flash-image-preview:generateContent?key=YOUR_API_KEY" \ -H "Content-Type: application/json" \ -d '{ "contents": [{ "parts": [{ "text": "Generate a professional product photo of a sleek wireless mouse on a clean white background" }] }], "generationConfig": { "responseModalities": ["TEXT", "IMAGE"] } }'
Parámetros clave para controlar costos
Tres parámetros impactan directamente el costo por solicitud. El campo responseModalities debe incluir "IMAGE" para activar la generación de imágenes — omitirlo genera respuestas solo de texto a la tarifa mucho menor de $1.50/1M de tokens de salida de texto. La resolución se controla a través de la configuración de generación, donde especificar una resolución más baja reduce directamente la cantidad de tokens de salida y, por lo tanto, el costo. El parámetro candidateCount determina cuántas variaciones de imagen se generan por solicitud, y cada candidato adicional multiplica el costo de tokens de imagen de salida proporcionalmente.
Para un uso de producción eficiente en costos, recomendamos establecer la resolución para que coincida con tus requisitos reales de visualización, generar un candidato por solicitud a menos que necesites específicamente variaciones, e implementar caché de prompts para patrones de generación repetidos basados en plantillas. Estas tres opciones de configuración, combinadas con la API por lotes para cargas de trabajo no urgentes, forman la base de la generación de imágenes con Gemini optimizada en costos.
Vale la pena señalar que el formato de respuesta difiere de las API de generación de imágenes típicas. Gemini devuelve imágenes como datos en línea dentro de las partes de contenido de respuesta, codificados en base64. Cada respuesta puede contener múltiples partes que mezclan datos de texto e imagen, lo que significa que tu lógica de análisis necesita iterar a través de todas las partes y manejar cada tipo de manera apropiada. El SDK de Python abstrae gran parte de esta complejidad, pero si estás trabajando con la API REST directamente a través de cURL o un cliente HTTP personalizado, necesitarás decodificar los datos de imagen en base64 de la respuesta JSON y escribirlos en un archivo. El manejo de errores debería contemplar casos donde el modelo devuelve respuestas solo de texto (lo que puede ocurrir si el prompt no solicita claramente la generación de imágenes o si los filtros de seguridad de contenido se activan), así como respuestas de límite de velocidad durante períodos de alto tráfico.
Preguntas frecuentes
¿Es gratuito usar Gemini 3.1 Flash Image Preview?
No. A diferencia de la mayoría de otros modelos Gemini que ofrecen generosos niveles gratuitos a través de Google AI Studio, el modelo Gemini 3.1 Flash Image Preview no tiene nivel gratuito. Cada imagen generada incurre en un cargo basado en la cantidad de tokens de salida, comenzando en $0.045 para imágenes de 512px. Google no ha indicado planes para introducir un nivel gratuito para este modelo, aunque el estado "Preview" significa que esto podría cambiar. Para propósitos de prueba, generar una sola imagen de 1024px cuesta $0.067, por lo que experimentar con 10-15 imágenes de prueba cuesta menos de un dólar.
¿Cuánto cuesta generar 1,000 imágenes por día con Gemini?
A la resolución predeterminada de 1024px usando precios estándar (sin lotes), generar 1,000 imágenes por día cuesta aproximadamente $2,010 por mes ($0.067 x 1,000 x 30). Cambiar al modo por lotes reduce esto a $1,020 por mes. Usar un proveedor externo con precios equivalentes al modo por lotes reduce el total a aproximadamente $900 por mes. La resolución que elijas afecta significativamente este número: imágenes de 512px a precios por lotes costarían solo $660 por mes para el mismo volumen.
¿Es la generación de imágenes con Gemini más barata que DALL-E 3 o GPT Image?
Gemini 3.1 Flash Image a $0.067 por imagen de 1024px es más caro que DALL-E 3 Standard ($0.040) y GPT Image 1 Medium ($0.042), pero significativamente más barato que GPT Image 1 High ($0.167) y DALL-E 3 HD ($0.080). Sin embargo, el modo por lotes de Gemini a $0.034 lo hace competitivo con DALL-E 3 Standard, y las capacidades multimodales nativas — comprensión contextual, generación basada en conversación, edición de imágenes mediante lenguaje natural — proporcionan funcionalidad que los generadores de imágenes independientes no pueden igualar a ningún precio.
¿Qué causa la discrepancia de precios entre AI Studio y la documentación de la API?
A fecha de marzo de 2026, Google no ha explicado oficialmente por qué AI Studio muestra precios de tokens de entrada a $0.50/1M y salida de texto a $3.00/1M, mientras que la documentación de la API lista $0.25/1M y $1.50/1M respectivamente. La tarifa de tokens de imagen de salida ($60/1M) es idéntica en ambas fuentes, por lo que los costos por imagen no se ven afectados. Los informes de la comunidad de desarrolladores sugieren que la facturación real sigue las tarifas más bajas de la documentación de la API, pero recomendamos presupuestar con las tarifas más altas de AI Studio hasta que Google publique una aclaración oficial.
¿Puedo usar Gemini 3.1 Flash Image para proyectos comerciales?
Sí, las imágenes generadas a través de la API de Gemini 3.1 Flash Image Preview pueden usarse para propósitos comerciales bajo los términos de servicio estándar de la API de Google. Sin embargo, la designación "Preview" significa que Google se reserva el derecho de modificar o descontinuar el modelo con menos aviso del que reciben los modelos generalmente disponibles. Para aplicaciones de producción de misión crítica, asegúrate de que tu arquitectura pueda recurrir a modelos de generación alternativos si el modelo preview experimenta cambios. Las imágenes generadas no llevan marcas de agua y son propiedad del usuario según los términos actuales de Google, aunque debes revisar los últimos términos de servicio de la API para cualquier actualización específica sobre contenido generado.
¿Cuáles son los límites de velocidad para Gemini 3.1 Flash Image Preview?
Los límites de velocidad varían según el nivel. Las cuentas de Nivel 1 (las predeterminadas para nuevas claves de API) comienzan con límites de solicitudes por minuto más bajos que aumentan gradualmente a medida que crece tu historial de uso. El sistema escalonado de Google significa que el uso de producción de alto volumen requiere tiempo para subir de nivel o un acuerdo directo con el equipo de ventas de Google Cloud. Las solicitudes de API por lotes tienen límites de encolamiento separados, típicamente más altos — el Nivel 1 permite 1 millón de tokens en cola, mientras que el Nivel 3 soporta hasta 750 millones de tokens. Para aplicaciones que requieren un rendimiento consistentemente alto desde el primer día, los proveedores externos a menudo ofrecen límites de velocidad más predecibles sin el período de incremento escalonado, lo cual es otro factor a considerar al elegir tu método de acceso a la API.
¿Cambiarán los precios cuando Gemini 3.1 Flash Image salga de Preview?
Google no ha hecho ningún compromiso público sobre cambios de precios cuando el modelo haga la transición de Preview a Disponibilidad General. Históricamente, Google ha tanto aumentado como disminuido precios durante las transiciones a GA dependiendo del modelo. La tarifa actual de $60 por millón de tokens de imagen de salida podría subir si Google determina que el modelo tiene un precio insuficiente en relación con la demanda, o bajar si la presión competitiva de OpenAI y otros proveedores justifica una reducción de precio. Para efectos de presupuesto, recomendamos usar los precios actuales como línea base mientras se mantiene la flexibilidad para ajustar si las tarifas cambian. Monitorear la página de precios de Google y el blog de desarrolladores para anuncios es la forma más confiable de anticiparse a cualquier cambio.