
Claude Code Agent Teams transforma la experiencia de Claude Code de un solo hilo en un sistema multi-agente coordinado donde instancias independientes de Claude se comunican, comparten tareas y trabajan en paralelo sobre tu código fuente. Lanzado como función experimental en febrero de 2026, los equipos de agentes representan un cambio fundamental en la forma en que los desarrolladores interactúan con los asistentes de programación con IA — pasando de una conversación a la vez a orquestar escuadrones completos de desarrollo. Esta guía te lleva a través de todo lo que necesitas para construir equipos de agentes efectivos, desde la configuración inicial hasta patrones listos para producción.
Resumen rápido
Los Agent Teams permiten crear múltiples sesiones de Claude Code que trabajan juntas en un proyecto compartido. Una sesión actúa como líder del equipo que coordina el trabajo, mientras que los compañeros de equipo ejecutan tareas de forma independiente en sus propias ventanas de contexto. A diferencia de los subagentes (que se ejecutan dentro de una sola sesión y solo pueden reportar a su agente padre), los compañeros pueden enviarse mensajes entre sí directamente, compartir descubrimientos durante la ejecución y coordinarse sin que el líder actúe como intermediario. Actívalos configurando CLAUDE_CODE_EXPERIMENTAL_AGENT_TEAMS=true en tu entorno o en settings.json, y necesitas Claude Code v2.1.32 o posterior. Anthropic demostró el poder de este enfoque al usar 16 agentes en paralelo para construir un compilador C de 100.000 líneas capaz de compilar el kernel de Linux — con un costo aproximado de $20.000 a lo largo de 2.000 sesiones (según el blog de ingeniería de Anthropic, febrero de 2026).
¿Qué son los Claude Code Agent Teams? (Y en qué se diferencian de los subagentes)
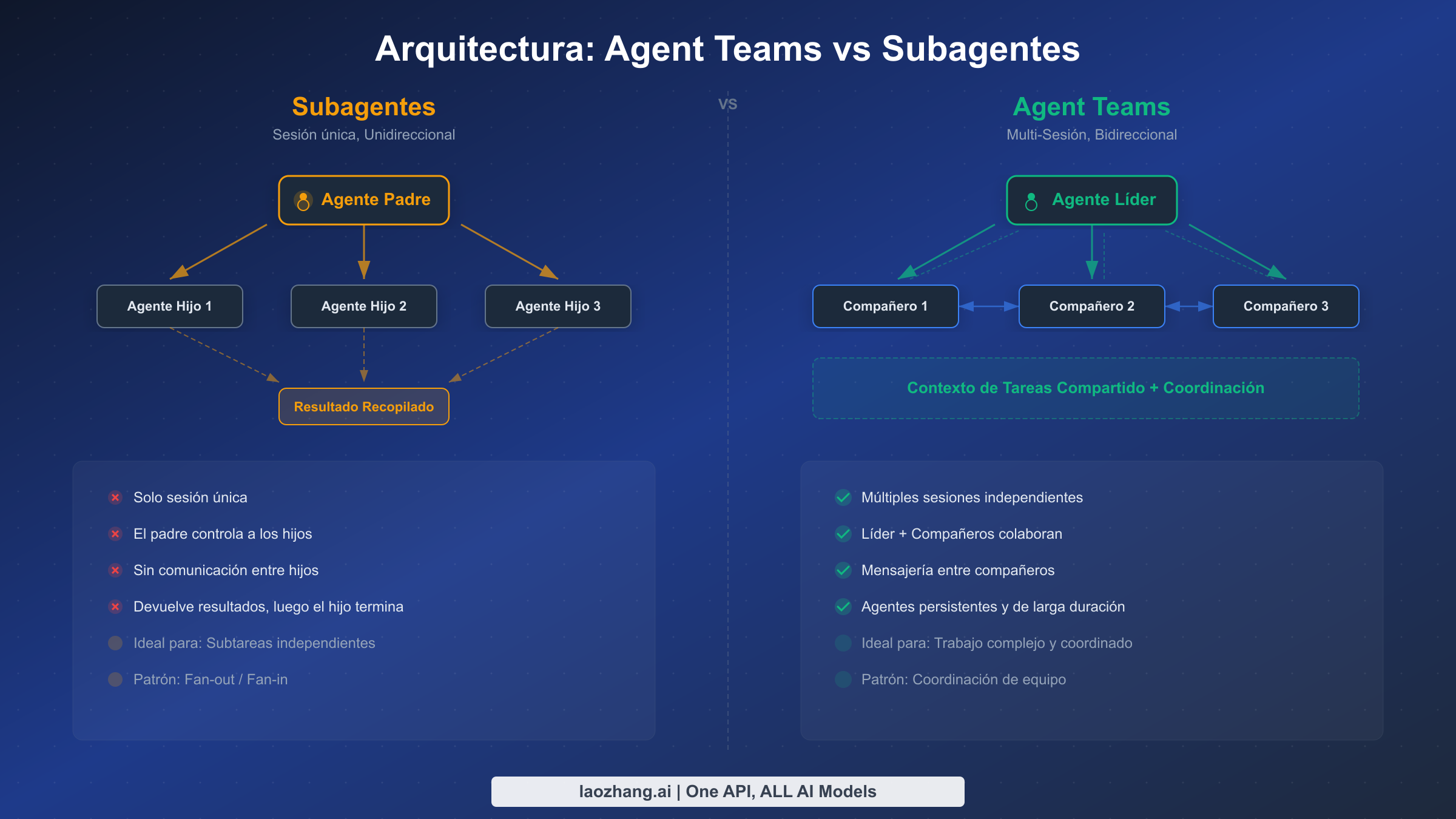
Antes de que existieran los equipos de agentes, Claude Code ofrecía subagentes como la forma principal de paralelizar trabajo. Los subagentes se ejecutan dentro del contexto de una sola sesión, realizan una tarea delimitada y devuelven los resultados al agente padre. Son útiles para mantener la exploración separada de la conversación principal — por ejemplo, buscar un patrón en el código mientras el agente principal continúa razonando sobre la arquitectura. Sin embargo, los subagentes tienen una limitación fundamental: no pueden comunicarse entre sí. Si el agente A descubre algo relevante para el trabajo del agente B, esa información debe pasar a través del agente padre, creando un cuello de botella que limita los tipos de coordinación posibles.
Los Agent Teams resuelven esto dando a cada compañero de equipo su propia sesión completa de Claude Code con contexto independiente, acceso a herramientas y la capacidad de enviar mensajes a cualquier otro compañero o al líder. Esta diferencia arquitectónica desbloquea patrones que son imposibles con subagentes: un agente de frontend puede informar a un agente de backend sobre un cambio en el contrato de API directamente, un agente de pruebas puede alertar al autor del código sobre una prueba fallida sin esperar a que el líder transmita el mensaje, y múltiples agentes pueden converger en una comprensión compartida de un problema mediante discusión directa.
La siguiente tabla aclara cuándo usar cada enfoque, porque elegir el incorrecto lleva a complejidad innecesaria (equipos de agentes para una búsqueda simple) o cuellos de botella de coordinación (subagentes para cambios transversales):
| Dimensión | Subagentes | Agent Teams |
|---|---|---|
| Sesiones | Se ejecutan dentro de la sesión del padre | Cada uno obtiene su propia sesión completa |
| Comunicación | Unidireccional: hijo → padre únicamente | Bidireccional: cualquiera → cualquiera |
| Contexto | Comparten la ventana de contexto del padre | Ventanas de contexto independientes |
| Coordinación | El padre actúa como intermediario | Mensajería directa entre pares |
| Ideal para | Tareas enfocadas y aisladas | Proyectos complejos con múltiples partes |
| Configuración | Integrado, sin configuración necesaria | Requiere flag experimental |
| Costo | Menor (sobrecarga de una sola sesión) | Mayor (sobrecarga de múltiples sesiones) |
Piensa en los subagentes como contratar un consultor especialista que te reporta, mientras que los equipos de agentes son como reunir un escuadrón de proyecto donde todos pueden hablar con todos. Si ya estás familiarizado con las capacidades de Claude Code y quieres entender dónde encajan los equipos de agentes en el conjunto más amplio de herramientas, nuestra guía de instalación de Claude Code cubre la configuración básica.
Cómo funcionan los Agent Teams internamente
La arquitectura de los equipos de agentes consta de tres componentes principales: una sesión de líder de equipo, una o más sesiones de compañeros, y una capa de coordinación compartida construida sobre archivos de tareas y mensajería entre agentes.
El líder del equipo es tu sesión principal de Claude Code — la donde escribes tu prompt inicial describiendo lo que quieres que el equipo logre. Cuando Claude determina que la tarea se beneficiaría del trabajo en paralelo, utiliza la herramienta Teammate para generar procesos adicionales de Claude Code. Cada proceso generado se ejecuta como una sesión independiente de Claude Code con su propia ventana de contexto, permisos de herramientas e historial de conversación. El líder asigna tareas iniciales a cada compañero y monitorea el progreso a través del sistema de tareas compartido.
Los compañeros de equipo son instancias completamente autónomas de Claude Code que reciben un prompt inicial del líder y luego trabajan de forma independiente. Pueden leer y escribir archivos, ejecutar comandos, buscar en el código fuente y usar todas las herramientas estándar de Claude Code. De manera crucial, también pueden enviar mensajes al líder y a otros compañeros usando la herramienta SendMessage, lo que permite el tipo de coordinación en tiempo real que distingue a los equipos de agentes de la simple ejecución en paralelo.
La capa de coordinación consiste en dos mecanismos que trabajan juntos. Primero, una lista de tareas compartida almacenada en disco que todos los miembros del equipo pueden leer y actualizar. Las tareas tienen estados (pendiente, en progreso, completada), pueden bloquear otras tareas e incluyen metadatos sobre quién está trabajando en qué. Cuando un compañero termina una tarea, las tareas posteriores que estaban bloqueadas automáticamente quedan disponibles para que otros compañeros las reclamen. Segundo, la API SendMessage proporciona comunicación directa entre agentes para situaciones que requieren más matices que un cambio de estado de tarea — compartir descubrimientos, solicitar aclaraciones o proponer cambios en el enfoque.
Esta arquitectura significa que los equipos de agentes producen una ráfaga de actividad paralela cuando se generan, convergen gradualmente a medida que las tareas se completan y los compañeros comunican sus hallazgos, y finalmente colapsan de vuelta a la sesión del líder, que sintetiza los resultados y te los presenta. Todo el proceso es visible en tu terminal: puedes observar los mensajes fluir entre agentes, ver cómo se actualizan los estados de las tareas e intervenir si el equipo se desvía del camino.
Comprender el ciclo de vida de una sesión de equipo de agentes te ayuda a anticipar costos y tiempos. Durante la fase de generación (típicamente 10-30 segundos), el líder crea las sesiones de los compañeros y asigna las tareas iniciales. En la fase de ejecución en paralelo (la mayor parte de la sesión, desde minutos hasta horas), los compañeros trabajan de forma independiente con mensajes ocasionales entre agentes. La fase de convergencia comienza cuando los primeros compañeros completan sus tareas y empiezan a ayudar con el trabajo restante o a revisar la producción de otros. Finalmente, la fase de síntesis ve al líder recopilando todos los resultados, resolviendo cualquier conflicto y presentando una respuesta unificada. Cada fase tiene diferentes características de consumo de tokens — la generación es barata, la ejecución en paralelo es la más costosa, y la síntesis depende de cuánta reconciliación necesite realizar el líder.
Vale la pena mencionar que cada sesión de compañero hereda los permisos y el acceso a herramientas de la sesión del líder, pero no el historial de conversación. Los compañeros comienzan con un contexto limpio que contiene solo la descripción de su tarea asignada y cualquier contexto inicial que el líder proporcione. Esto significa que los compañeros no saben lo que discutiste con el líder antes de crear el equipo, lo cual en realidad es una ventaja — obliga al líder a proporcionar instrucciones explícitas y autocontenidas en lugar de depender del contexto implícito de conversaciones anteriores. Si un compañero necesita información del historial de conversación, el líder debe incluirla en la descripción de la tarea o enviarla mediante un mensaje.
Configuración de tu primer Agent Team (paso a paso)
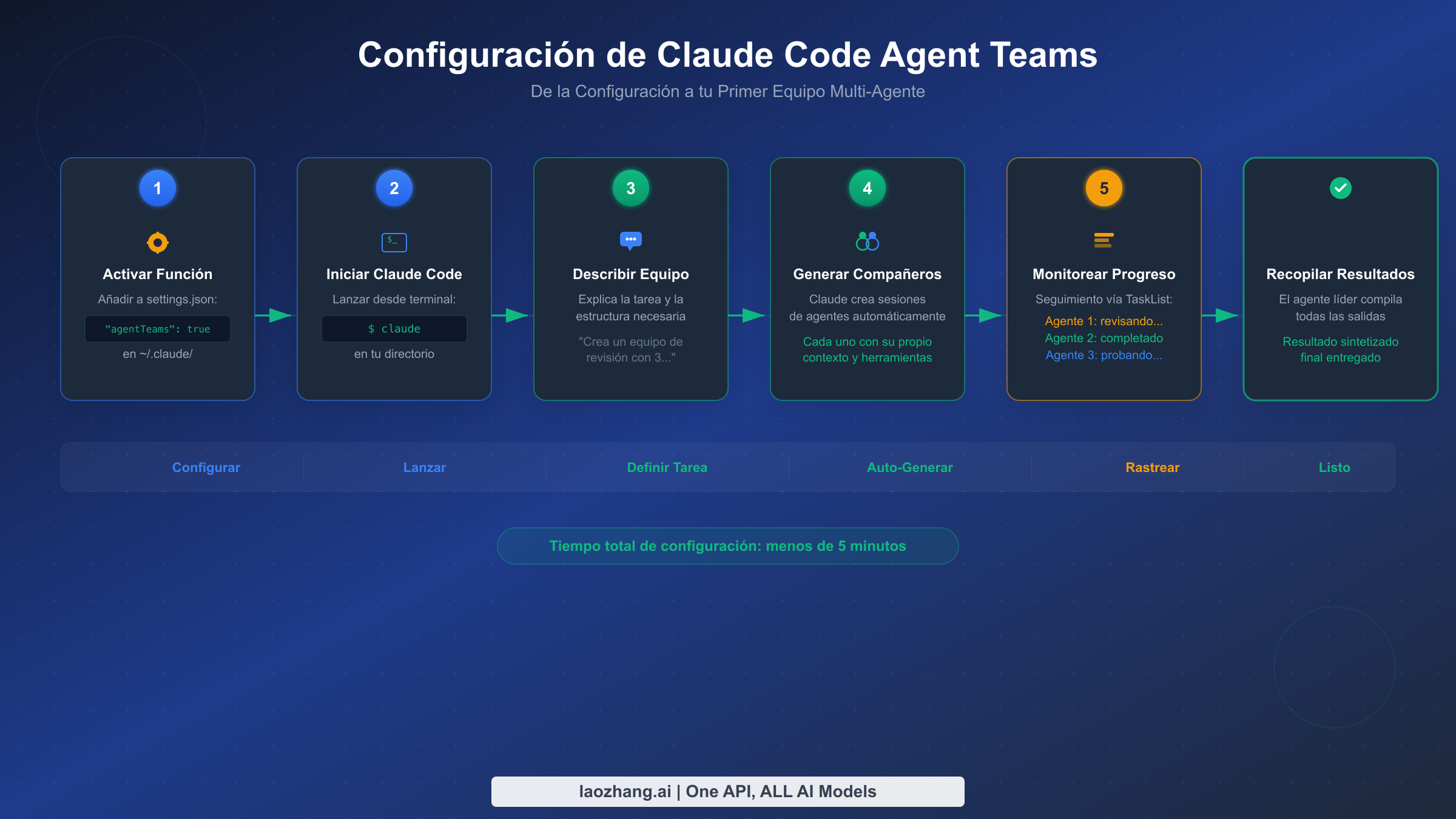
Poner en marcha los equipos de agentes requiere activar el flag de la función experimental y comprender algunas opciones de configuración que afectan el comportamiento del equipo. El proceso de configuración toma menos de cinco minutos, pero las decisiones de configuración que tomes aquí influyen en la efectividad con la que operan tus equipos.
Paso 1: Verifica tu versión de Claude Code. Los equipos de agentes requieren v2.1.32 o posterior. Comprueba tu versión ejecutando claude --version en tu terminal. Si necesitas actualizar, ejecuta npm install -g @anthropic-ai/claude-code@latest o usa el gestor de paquetes apropiado para tu método de instalación.
Paso 2: Activa el flag experimental. Tienes tres opciones para activar los equipos de agentes, y la elección depende de si quieres la función disponible globalmente o por proyecto:
json// Opción A: Configuración a nivel de proyecto (.claude/settings.json) { "env": { "CLAUDE_CODE_EXPERIMENTAL_AGENT_TEAMS": "true" } } // Opción B: Configuración a nivel de usuario (~/.claude/settings.json) { "env": { "CLAUDE_CODE_EXPERIMENTAL_AGENT_TEAMS": "true" } } // Opción C: Variable de entorno (nivel de sesión) // export CLAUDE_CODE_EXPERIMENTAL_AGENT_TEAMS=true
La configuración a nivel de proyecto es la recomendada para equipos porque asegura que todos los que trabajan en el mismo repositorio tengan los equipos de agentes activados sin necesidad de modificar su configuración personal. La configuración persiste entre sesiones y se registra en el control de versiones junto con tu proyecto.
Paso 3: Inicia Claude Code y describe tu tarea de equipo. Lanza Claude Code en el directorio de tu proyecto y dale un prompt que sugiera naturalmente trabajo en paralelo. La clave es describir el resultado que deseas y los flujos de trabajo distintos involucrados, en lugar de microgestionar cómo Claude debe estructurar el equipo. Por ejemplo, en vez de decir "crea tres agentes," di algo como: "Revisa este pull request buscando problemas de seguridad, problemas de rendimiento y brechas en la cobertura de pruebas. Cada área debe examinarse de forma independiente y los hallazgos compilarse en un único informe."
Claude analizará tu prompt, determinará cuántos compañeros serían efectivos, los generará con instrucciones enfocadas y configurará la estructura de coordinación de tareas. Verás mensajes en tu terminal a medida que los compañeros se crean y comienzan a trabajar.
Paso 4: Monitorea el progreso. Mientras el equipo trabaja, puedes observar la lista de tareas compartida y los mensajes entre agentes en la salida de tu terminal. El agente líder verifica periódicamente a los compañeros y puede reasignar tareas si un compañero termina antes o encuentra bloqueadores. Si necesitas dirigir al equipo, puedes enviar un mensaje al agente líder, que transmitirá las instrucciones relevantes a los compañeros afectados.
Paso 5: Recopila y revisa los resultados. Cuando todas las tareas están completas, el agente líder sintetiza los hallazgos de todos los compañeros y presenta una respuesta unificada. Los compañeros se cierran automáticamente mediante el protocolo de cierre SendMessage: el líder envía un shutdown_request, cada compañero confirma con un shutdown_response y las sesiones se cierran limpiamente.
Si encuentras problemas durante la configuración, los más comunes son incompatibilidad de versión (actualiza Claude Code), flag de función faltante (verifica las tres posibles ubicaciones de configuración) y errores de permisos (asegúrate de que tu clave API o suscripción tenga cuota suficiente para múltiples sesiones concurrentes). Para usuarios de API específicamente, ten en cuenta que cada compañero consume su propia asignación de tokens, lo que puede acelerar significativamente el consumo de límites de velocidad.
Otra consideración práctica son los recursos de tu sistema. Cada compañero se ejecuta como un proceso Node.js separado, por lo que generar un equipo grande en una máquina con RAM limitada puede causar problemas de rendimiento. Para la mayoría de las máquinas de desarrollo, de tres a cinco compañeros simultáneos funcionan cómodamente. Si necesitas equipos más grandes (diez o más), considera ejecutarlos en una máquina con al menos 16 GB de RAM y monitorea el uso de memoria de los procesos. El ancho de banda de red raramente es un cuello de botella ya que la comunicación entre compañeros ocurre a través de operaciones del sistema de archivos local y llamadas API, pero la latencia hacia la API de Anthropic puede afectar la velocidad con que los compañeros responden a los mensajes.
Para equipos que usan Claude Code con el nivel gratuito, los equipos de agentes son accesibles pero la cuota de uso limitada se consumirá mucho más rápido con múltiples sesiones concurrentes. Considera actualizar a Pro o Max antes de depender de los equipos de agentes para trabajo sustancial, o usa acceso API con una asignación de nivel suficiente para evitar interrupciones frustrantes a mitad de una sesión de equipo.
Patrones de arquitectura de equipo para proyectos reales
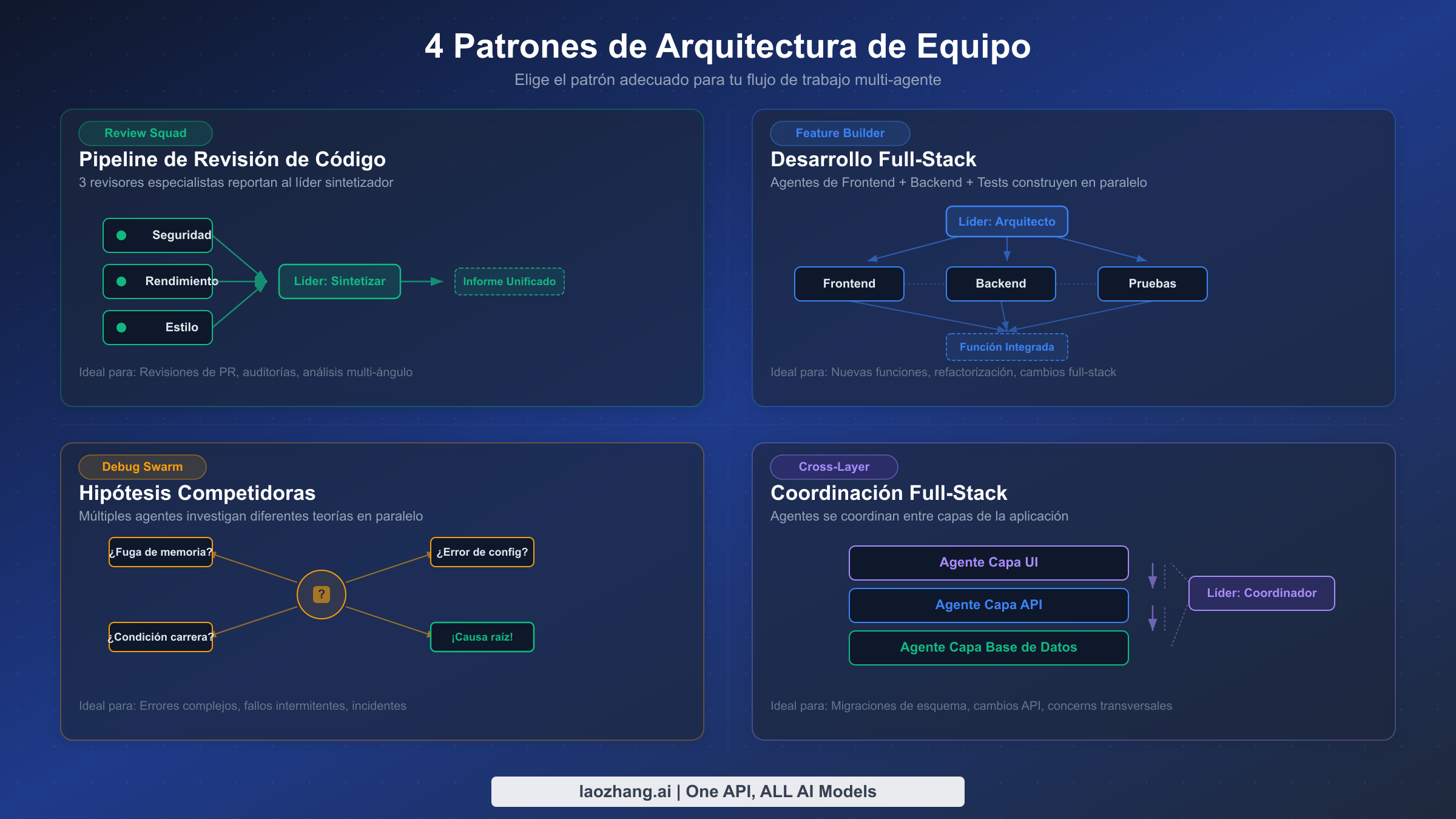
La diferencia entre un equipo de agentes productivo y un caos de sesiones paralelas de Claude se reduce a cómo estructuras las responsabilidades y los patrones de comunicación del equipo. Cuatro patrones de arquitectura han surgido de la experiencia de la comunidad y las propias pruebas de Anthropic como consistentemente efectivos para diferentes tipos de trabajo.
Patrón 1: El Review Squad. Este patrón asigna el mismo artefacto a múltiples revisores, cada uno examinándolo a través de una lente diferente. Una configuración típica genera tres compañeros — uno enfocado en vulnerabilidades de seguridad, uno en cuellos de botella de rendimiento y uno en estilo de código y mantenibilidad. El líder recopila todas las revisiones y produce un informe unificado que prioriza los hallazgos por severidad. Este patrón funciona excepcionalmente bien para revisiones de pull requests, evaluaciones de arquitectura y auditorías de documentación porque los revisores no necesitan coordinarse entre sí — examinan el mismo contenido de forma independiente y el líder se encarga de la síntesis. El costo en tokens es relativamente bajo porque cada revisor lee los mismos archivos sin generar grandes cambios de código.
Patrón 2: El Feature Builder. Al construir una nueva función que abarca múltiples capas del stack, el patrón Feature Builder asigna un compañero a cada capa: frontend, backend, base de datos y pruebas. El líder define las interfaces entre capas por adelantado (contratos de API, esquemas de datos) y luego deja que cada compañero implemente su porción de forma independiente. Aquí es donde la mensajería entre agentes se vuelve crítica — cuando el compañero de backend descubre que el contrato de API necesita ajustarse, envía un mensaje al compañero de frontend directamente en lugar de pasar por el líder. El patrón Feature Builder es más efectivo cuando los límites de la función son claros y las interfaces entre componentes pueden definirse antes de que comience el trabajo.
Patrón 3: El Debug Swarm. La depuración de problemas complejos frecuentemente se beneficia de explorar múltiples hipótesis simultáneamente. El Debug Swarm genera varios compañeros, cada uno persiguiendo una teoría diferente sobre la causa raíz. Uno podría investigar cambios recientes en el código, otro examina patrones de logs, y un tercero revisa diferencias de configuración entre entornos. A medida que los compañeros descartan hipótesis o descubren evidencia de apoyo, comparten hallazgos entre sí. El enjambre converge naturalmente a medida que la evidencia se acumula, y el líder sintetiza el diagnóstico una vez que emerge una imagen clara. Este patrón es particularmente valioso cuando se trata de fallos intermitentes, condiciones de carrera o problemas que abarcan múltiples servicios.
Patrón 4: Coordinación Cross-Layer. El patrón más sofisticado maneja tareas donde los cambios en un área se propagan en cascada a varias otras — por ejemplo, renombrar un modelo de datos central que aparece en la capa API, migraciones de base de datos, componentes de frontend y fixtures de prueba. El líder planifica la secuencia de cambios, asigna cada capa a un compañero, y los compañeros coordinan los cambios específicos a través de mensajería directa. Este patrón requiere la mayor cantidad de comunicación entre agentes y se beneficia de dependencias claras entre tareas: la migración de base de datos debe completarse antes de los cambios en la API, que deben completarse antes de las actualizaciones del frontend.
Un ejemplo del mundo real ilustra cómo estos patrones funcionan en la práctica. En un caso documentado, un desarrollador le indicó a Claude: "Usa un equipo de agentes para hacer QA contra mi blog en localhost:4321." El líder generó cinco compañeros basados en Sonnet, cada uno asignado a una perspectiva diferente de QA: respuestas de páginas principales, renderizado de publicaciones del blog, navegación y enlaces, RSS/sitemap/SEO y accesibilidad. Los compañeros trabajaron de forma independiente — el agente de respuesta de páginas verificó 16 páginas por códigos de estado HTTP 200, el verificador de enlaces validó 146 URLs internas, y el agente de accesibilidad descubrió problemas como un booleano convertido a string en un atributo de clase HTML y etiquetas ARIA faltantes en un selector de tema. El líder sintetizó todos los hallazgos en un informe priorizado de 10 problemas (4 mayores, 2 medianos, 4 menores) — trabajo que habría tomado considerablemente más tiempo a un solo agente para completar secuencialmente.
Una función poderosa pero frecuentemente pasada por alto es la puerta de aprobación de plan. Al generar un compañero, puedes requerir que envíe un plan de implementación para aprobación antes de realizar cualquier cambio. El compañero trabaja en modo de plan de solo lectura — puede leer archivos y analizar el código fuente pero no puede modificar nada hasta que el líder (o tú) apruebe su plan. Si el plan es rechazado, el compañero recibe retroalimentación y revisa su enfoque. Esto es invaluable para cambios de alto riesgo donde quieres un punto de control humano antes de que el código sea modificado, mientras sigues beneficiándote del análisis en paralelo que los equipos de agentes proporcionan.
Elegir entre estos patrones depende de dos factores: cuánto interactúan los flujos de trabajo (baja interacción favorece al Review Squad, alta interacción favorece al Cross-Layer) y si estás creando código nuevo o modificando código existente (código nuevo favorece al Feature Builder, código existente favorece al Debug Swarm o Cross-Layer). Para la mayoría de los proyectos, comienza con el patrón Review Squad para familiarizarte con los equipos de agentes antes de intentar los patrones que requieren más coordinación.
Profundización en comunicación y gestión de tareas
La efectividad de los equipos de agentes depende en gran medida de lo bien que los compañeros se comunican y de cómo se estructuran las tareas. Comprender las primitivas de comunicación disponibles para los compañeros te ayuda a diseñar prompts que lleven a mejores patrones de coordinación.
SendMessage es la herramienta principal de comunicación. Soporta varios tipos de mensajes que sirven para diferentes propósitos de coordinación. Los mensajes estándar entregan texto de un agente a otro — el remitente especifica un destinatario (por nombre o rol del equipo) y el contenido del mensaje. Los mensajes de broadcast van a todos los compañeros simultáneamente, útiles cuando el líder necesita anunciar un cambio de dirección o compartir un descubrimiento relevante para todos. Las solicitudes y respuestas de cierre forman un protocolo de terminación elegante que asegura que ningún compañero sea interrumpido a mitad de tarea.
La decisión de diseño importante que tomó Anthropic es que SendMessage es el único canal de comunicación directa. No hay memoria compartida, no hay portapapeles compartido y no hay capacidad para que un compañero lea el historial de conversación de otro. Esta restricción es deliberada — obliga a que la comunicación sea explícita y estructurada, previniendo el tipo de acoplamiento implícito que haría impredecible el comportamiento del equipo. Cuando el compañero A necesita información del compañero B, debe solicitarla a través de un mensaje, y el compañero B debe responder con el contexto relevante. Esto hace que el flujo de información sea auditable y depurable.
La gestión de tareas proporciona la columna vertebral estructural para la coordinación. Las tareas se crean con TaskCreate, se actualizan con TaskUpdate y se consultan con TaskList y TaskGet. Cada tarea tiene un asunto, descripción, estado, propietario y enlaces de dependencia opcionales. El sistema de dependencias es particularmente poderoso: puedes especificar que la tarea B está bloqueada por la tarea A, y cuando la tarea A se completa, la tarea B automáticamente queda disponible para que un compañero la reclame.
Aquí hay un ejemplo de cómo un líder podría estructurar las tareas para un equipo Feature Builder:
pythonTaskCreate(subject="Definir contrato API para perfiles de usuario", description="...") TaskCreate(subject="Implementar endpoints de API del backend", description="...", addBlockedBy=["task-1"]) # Bloqueada hasta que se defina el contrato API TaskCreate(subject="Construir componentes de perfil del frontend", description="...", addBlockedBy=["task-1"]) # También bloqueada hasta el contrato API TaskCreate(subject="Escribir pruebas de integración", description="...", addBlockedBy=["task-2", "task-3"]) # Bloqueada hasta ambas implementaciones
Esta estructura de dependencias asegura que ningún compañero comience a implementar antes de que se defina el contrato, y las pruebas solo comienzan después de que tanto el frontend como el backend estén completos. Los compañeros reclaman automáticamente la siguiente tarea disponible no bloqueada cuando terminan la actual, lo que significa que el equipo se balancea automáticamente sin que el líder necesite intervenir.
Un error común es sobrecomplicar el grafo de dependencias de tareas. Las dependencias deben reflejar requisitos genuinos de secuenciación — la tarea B verdaderamente no puede comenzar hasta que la tarea A termine — en lugar de expresar preferencias sobre el orden de ejecución. Especificar demasiadas dependencias reduce el paralelismo porque los compañeros pasan más tiempo esperando que las tareas bloqueadas se desbloqueen. Por el contrario, especificar pocas dependencias lleva a conflictos cuando dos compañeros modifican código superpuesto simultáneamente. El punto óptimo es crear dependencias solo donde existe una dependencia a nivel de datos o archivos, y usar definiciones de alcance de tarea amplias que den a los compañeros propiedad clara sobre los archivos.
Para equipos que procesan grandes bases de código, monitorear el volumen de comunicación entre agentes proporciona una señal útil de salud. Si los agentes están enviando más de unos pocos mensajes por tarea, generalmente indica que la descomposición de tareas fue demasiado granular y los agentes están gastando tokens excesivos coordinando en lugar de produciendo. El patrón ideal muestra una breve ráfaga de mensajes después de la generación (agentes confirmando que entienden sus tareas), mensajes ocasionales durante la ejecución (compartiendo descubrimientos o solicitando aclaraciones) y una ronda final de mensajes durante la síntesis. Para desarrolladores que construyen aplicaciones que usan las capacidades API de Claude Code, la guía de integración MCP explica cómo extender los equipos de agentes con herramientas personalizadas a través del Model Context Protocol.
Análisis de costos — ¿Cuánto cuestan realmente los Agent Teams?
Comprender los costos de los equipos de agentes es esencial para tomar decisiones informadas sobre cuándo la ejecución en paralelo vale la inversión frente a cuándo una sola sesión de Claude Code sería suficiente. El modelo de costos para los equipos de agentes es sencillo en teoría pero tiene matices que afectan significativamente el gasto en el mundo real.
La fórmula básica es: costo total = número de compañeros x tokens promedio por compañero x precio por token. Cada compañero es una sesión independiente que consume tokens por leer archivos, pensar, generar salida y comunicarse con otros compañeros. La sesión del líder también consume tokens por la sobrecarga de coordinación. A diferencia del uso basado en suscripción donde tienes un presupuesto mensual fijo, los equipos de agentes basados en API facturan estrictamente por token, haciendo que el costo sea directamente proporcional a la cantidad de trabajo realizado.
El experimento del compilador C de Anthropic proporciona el benchmark de costos más concreto disponible. Usando 16 agentes Opus 4.6 en paralelo a lo largo de aproximadamente 2.000 sesiones de Claude Code, el equipo produjo un compilador C basado en Rust de 100.000 líneas capaz de compilar el kernel de Linux en arquitecturas x86, ARM y RISC-V. El costo total fue de aproximadamente $20.000 en uso de API (verificado del blog de ingeniería de Anthropic, febrero de 2026). Eso equivale a aproximadamente $0,20 por línea de código producido, o $10 por sesión en promedio. Este es un escenario de alto nivel usando el modelo más costoso (Opus) para una tarea extremadamente compleja — la mayoría de los flujos de trabajo de desarrolladores costarán significativamente menos.
La elección del modelo afecta dramáticamente el costo. Usar Sonnet 4.6 en lugar de Opus 4.6 reduce los costos por token en un 40% (Sonnet a $3/$15 por MTok versus Opus a $5/$25, verificado en claude.com/pricing, marzo de 2026). Para muchas tareas de equipos de agentes — revisión de código, generación de documentación, escritura de pruebas — Sonnet ofrece una calidad comparable a Opus mientras reduce sustancialmente los costos. Una estrategia práctica es usar Opus para el agente líder (que necesita el razonamiento más fuerte para la coordinación) y Sonnet para los compañeros (que ejecutan tareas más enfocadas y bien definidas).
Las estrategias de optimización de costos que reducen el gasto en equipos de agentes sin sacrificar calidad incluyen limitar el tamaño del equipo al número mínimo de compañeros que puedan paralelizar significativamente el trabajo (de tres a cinco suele ser óptimo), establecer límites claros de alcance para cada compañero para prevenir exploración redundante, usar dependencias de tareas para evitar consumo innecesario de tokens en trabajo bloqueado, y monitorear el uso de tokens a través de los dashboards en tiempo real de la Consola de Claude.
Para desarrolladores que ejecutan equipos de agentes frecuentemente y quieren reducir costos aún más, servicios de enrutamiento de API de terceros como laozhang.ai ofrecen acceso de pago por token a modelos Claude con potencialmente menos sobrecarga que gestionar la progresión de niveles de API directamente con Anthropic. Este enfoque puede ser particularmente rentable para equipos con patrones de uso variables — algunas semanas con uso intensivo de equipos de agentes, otras semanas con actividad mínima — porque evitas pagar por capacidad de suscripción no utilizada.
Otro factor de costo frecuentemente pasado por alto es el almacenamiento en caché de prompts. Cuando múltiples compañeros leen los mismos archivos grandes (lo cual es común en patrones de Review Squad), el almacenamiento en caché reduce significativamente el costo efectivo de tokens. El sistema ITPM de Anthropic consciente de la caché significa que los tokens de entrada en caché no cuentan para tus límites de velocidad y se facturan al 10% del precio base de entrada. Para equipos de agentes que comparten un contexto común de código, el almacenamiento en caché efectivo puede reducir los costos de tokens de entrada entre un 50-80% comparado con implementaciones sin optimizar. La optimización clave es estructurar los prompts de los compañeros de modo que el contexto compartido (como instrucciones del sistema y archivos de referencia comunes) aparezca al principio de cada solicitud, maximizando las tasas de aciertos de caché entre compañeros. Para una comprensión más profunda de cómo la caché interactúa con los límites de velocidad, consulta nuestra guía de límites de velocidad de Claude Code.
| Escenario | Agentes | Modelo | Tokens estimados | Costo estimado |
|---|---|---|---|---|
| Revisión de PR (3 perspectivas) | 3 | Sonnet 4.6 | ~500K total | ~$2-5 |
| Nueva función (3 capas) | 4 | Mixto Opus+Sonnet | ~2M total | ~$15-30 |
| Debug Swarm (4 hipótesis) | 4 | Sonnet 4.6 | ~1M total | ~$5-12 |
| Refactorización grande (cross-layer) | 5 | Mixto | ~3M total | ~$25-50 |
| Compilador C (caso Anthropic) | 16 | Opus 4.6 | ~Miles de millones | ~$20.000 |
Lecciones del experimento del compilador C de Anthropic
El ejemplo más instructivo de equipos de agentes a escala proviene del propio equipo de ingeniería de Anthropic, que usó 16 agentes Opus 4.6 para construir un compilador C desde cero en Rust. Este experimento, documentado en el blog de ingeniería de Anthropic en febrero de 2026, reveló tanto el extraordinario potencial como las limitaciones prácticas del desarrollo multi-agente. Las lecciones clave se aplican directamente a cómo los desarrolladores deberían estructurar sus propios equipos de agentes.
Lección 1: La paralelización funciona mejor con problemas naturalmente descomponibles. El proyecto del compilador C tuvo éxito porque la compilación es inherentemente modular — el análisis sintáctico, la verificación de tipos, la generación de código y la optimización pueden desarrollarse y probarse de forma algo independiente. El equipo descubrió que el mayor paralelismo se lograba cuando había muchas pruebas fallidas distintas, porque cada agente podía tomar una prueba fallida diferente para trabajar sin coordinación. Cuando la suite de pruebas alcanzó una tasa de aprobación del 99% y las fallas restantes estaban interrelacionadas, el paralelismo naturalmente disminuyó ya que los agentes necesitaban coordinarse más cuidadosamente. La conclusión para los desarrolladores es identificar los límites naturalmente paralelos en tu proyecto antes de generar un equipo, en lugar de esperar que Claude descubra la descomposición por sí mismo.
Lección 2: Un oráculo lo facilita todo. Para el desafío de compilación del kernel Linux, el equipo usó GCC como un oráculo de compilador confiable. Construyeron un arnés de pruebas que compilaba aleatoriamente la mayoría de los archivos del kernel con GCC y solo unos pocos archivos con su nuevo compilador, permitiendo que cada agente se enfocara en corregir diferentes errores en diferentes archivos simultáneamente. Este patrón — comparar tu salida contra una referencia confiable — se generaliza más allá de los compiladores. Si estás refactorizando una API, mantén la implementación antigua funcionando junto con la nueva y deja que los agentes verifiquen la equivalencia de comportamiento. Si estás migrando una base de datos, compara los resultados de las consultas entre esquemas antiguos y nuevos. El patrón del oráculo convierte un problema abierto de calidad en un ciclo de verificación cerrado que los agentes pueden ejecutar de forma independiente.
Lección 3: La sobrecarga de comunicación es real pero manejable. Con 16 agentes, el potencial de caos comunicativo es significativo. El equipo de Anthropic descubrió que las dependencias estructuradas de tareas reducían la charla innecesaria entre agentes: en lugar de que los agentes se enviaran mensajes constantemente sobre en qué estaban trabajando, el sistema de tareas proporcionaba visibilidad sobre quién estaba haciendo qué. La mensajería directa se reservaba para descubrimientos genuinos o conflictos — como cuando dos agentes intentaban modificar el mismo archivo. Para tus propios equipos, resiste la tentación de fomentar la comunicación excesiva. La mayoría de las tareas de equipos de agentes se benefician de un enfoque de "divide y vencerás con puntos de control" en lugar de discusión continua.
Lección 4: Los costos de tokens escalan con la exploración, no solo con la producción. Los $20.000 de costo por 100.000 líneas de código podrían parecer altos, pero reflejan la extensa exploración y depuración requerida para construir un compilador que maneje toda la complejidad del código C del mundo real. Cada agente no solo escribió código — leyó código existente, formuló hipótesis sobre errores, probó correcciones, revirtió intentos fallidos e iteró. El costo en tokens de este trabajo exploratorio empequeñece el costo de la producción final. Los equipos que trabajan en tareas más directas (implementación de funciones con especificaciones claras, por ejemplo) verán ratios de costo-producción mucho más bajos.
Lección 5: La intervención humana en puntos clave de decisión multiplica la efectividad del equipo. Aunque el compilador C fue construido en gran parte de forma autónoma, el equipo de Anthropic descubrió que la orientación humana ocasional en puntos de decisión arquitectónica — elegir entre enfoques competidores para la generación de código, por ejemplo — evitaba que los agentes gastaran miles de tokens explorando caminos subóptimos. El flujo de trabajo más efectivo no era completamente autónomo sino semi-autónomo: los agentes trabajan de forma independiente en subtareas bien definidas, y los humanos toman las decisiones estratégicas de alto nivel que enmarcan esas subtareas. Este enfoque híbrido respeta las fortalezas de ambas partes — los agentes sobresalen en ejecutar tareas bien definidas en paralelo, mientras que los humanos sobresalen en juicio estratégico y planificación a largo plazo.
Lección 6: El valor de los equipos de agentes se multiplica con la complejidad del proyecto. Para una adición de función simple, una sola sesión de Claude Code es generalmente más rápida y económica que generar un equipo. El punto de equilibrio — donde los equipos de agentes entregan mejores resultados por dólar que el trabajo secuencial — ocurre cuando la tarea involucra flujos de trabajo genuinamente paralelos (diferentes archivos, diferentes preocupaciones) o cuando la tarea se beneficia de múltiples perspectivas (revisión de código, evaluación arquitectónica). El proyecto del compilador C estaba muy por encima del punto de equilibrio porque involucraba miles de casos de prueba independientes que podían depurarse en paralelo. Para la mayoría de los flujos de trabajo de desarrolladores, el punto de equilibrio está alrededor de tres a cinco subtareas verdaderamente independientes — menos que eso, y la sobrecarga de coordinación del equipo supera las ganancias de paralelismo.
Preguntas frecuentes
¿Cuántos compañeros de equipo debería usar para un proyecto típico?
Comienza con tres a cinco compañeros para la mayoría de las tareas. El patrón Review Squad funciona bien con tres revisores especializados, mientras que el patrón Feature Builder típicamente necesita cuatro (uno por capa más pruebas). Ir más allá de cinco compañeros rara vez mejora el rendimiento porque la sobrecarga de coordinación empieza a superar los beneficios del paralelismo. La excepción son las tareas altamente descomponibles como el experimento del compilador de Anthropic, donde 16 agentes fueron efectivos porque cada uno trabajó en casos de prueba genuinamente independientes con necesidad mínima de coordinación.
¿Pueden los equipos de agentes funcionar con la suscripción Pro o Max, o requieren acceso API?
Los equipos de agentes funcionan tanto con planes de suscripción como con acceso directo por API. Al usar una suscripción (Pro a $20/mes o Max a $100-200/mes), cada compañero consume tokens de tu cuota compartida de suscripción, lo que significa que alcanzarás los límites de uso más rápido que con una sola sesión. El acceso API proporciona un control más granular sobre los presupuestos de tokens por compañero y evita el techo de cuota de suscripción, haciéndolo más adecuado para uso intensivo de equipos de agentes. Independientemente del método de acceso, asegúrate de tener cuota suficiente para el número de sesiones paralelas que planeas ejecutar.
¿Qué sucede si dos compañeros intentan editar el mismo archivo simultáneamente?
Claude Code maneja el acceso concurrente a archivos a través de sus mecanismos estándar de bloqueo de archivos y resolución de conflictos. En la práctica, las dependencias de tareas bien estructuradas previenen la mayoría de los conflictos al asegurar que solo un compañero trabaje en un archivo dado a la vez. Si ocurren conflictos, el agente líder típicamente los detecta durante la síntesis y los resuelve dando prioridad a los cambios de un compañero. Puedes minimizar los conflictos estructurando las tareas alrededor de la propiedad de archivos — asignando a cada compañero responsabilidad sobre archivos o directorios distintos en lugar de áreas superpuestas.
¿Hay alguna forma de guardar y reutilizar configuraciones de equipo?
Actualmente, los equipos de agentes no tienen una plantilla integrada o archivo de configuración para estructuras de equipo predefinidas. Sin embargo, puedes lograr configuraciones reutilizables creando instrucciones en CLAUDE.md que describan tus patrones de equipo preferidos, o escribiendo skills personalizados que codifiquen arquitecturas de equipo específicas. La comunidad también ha desarrollado patrones de configuración compartidos a través de gists y repositorios de GitHub. A medida que la función madure más allá del estado experimental, se esperan opciones de configuración más estructuradas.
¿Cómo interactúan los equipos de agentes con las ramas de git y el control de versiones?
Cada compañero opera en el mismo directorio de trabajo y estado de git que el líder. Esto significa que todos los compañeros ven la misma rama, cambios no confirmados y estado de archivos. Para tareas complejas, el líder puede instruir a los compañeros para que trabajen en modo de aislamiento usando git worktrees, lo que da a cada compañero una copia separada del repositorio. Esto previene conflictos de merge durante el trabajo en paralelo pero requiere un paso de reconciliación al final. Para tareas más simples donde los compañeros modifican archivos diferentes, el acceso concurrente directo al directorio de trabajo principal funciona bien.
¿Son los equipos de agentes lo suficientemente estables para flujos de trabajo de producción?
Los equipos de agentes actualmente están etiquetados como experimentales, lo que significa que Anthropic puede cambiar la API, el comportamiento o la disponibilidad sin previo aviso. Para flujos de trabajo de producción, este estado experimental conlleva riesgo — una actualización de Claude Code podría cambiar cómo se coordinan los equipos o introducir cambios incompatibles en el protocolo SendMessage. Dicho esto, muchos desarrolladores utilizan con éxito los equipos de agentes en sus flujos de trabajo diarios para revisión de código, desarrollo de funciones y depuración. La recomendación es usarlos para tareas donde el fallo parcial es aceptable y la intervención manual es factible, en lugar de para pipelines CI/CD completamente automatizados donde la fiabilidad es crítica. Las limitaciones actuales notables incluyen: sin reanudación de sesión (el comando /resume no restaura compañeros), solo un equipo por sesión, sin equipos anidados (los compañeros no pueden generar sus propios equipos) y los compañeros a veces no marcan las tareas como completadas, lo cual puede bloquear tareas dependientes. Se espera que estas limitaciones mejoren a medida que la función evolucione más allá del estado experimental.