
OpenAI and Claude both make repeated prompt prefixes cheaper, but the bill moves through different line items. As of May 19, 2026, OpenAI's current GPT-5.5/GPT-5.4 standard rows price cached input at one tenth of normal input and do not add a separate cache-write premium. Claude's cache reads are also one tenth of base input, but the first cache creation costs 1.25x for the 5-minute cache or 2x for a 1-hour cache.
Use OpenAI when your stable prefix repeats and you want automatic caching with simpler accounting. Use Claude when explicit cache boundaries, prewarming, and TTL control matter enough to justify the write cost. Do not budget either provider on cache savings until your logs show OpenAI usage.prompt_tokens_details.cached_tokens or Claude cache_read_input_tokens and cache_creation_input_tokens; output tokens and cache misses still bill outside the cached-input discount.
Quick verdict: which cache billing model is cheaper?
The practical answer is workload-based. OpenAI is usually easier to model when you have a long, stable prefix that repeats often: the first request is ordinary input, later matched prefixes use the model's cached-input price, and there is no separate line item for creating the cache. Claude is more explicit: you pay a cache write price when the cache is created, then cache reads are much cheaper than base input. That extra write bucket is not a problem for high-reuse workloads, but it matters for low-hit or short-lived traffic.
| Decision point | OpenAI prompt caching | Claude prompt caching | What it means for your bill |
|---|---|---|---|
| Activation | Automatic on eligible recent models | Automatic top-level cache control or explicit cache_control breakpoints | OpenAI is lower-friction; Claude gives more boundary control |
| First request | Ordinary input tokens | Cache write tokens, 1.25x for 5-minute TTL or 2x for 1-hour TTL | Claude's first cached request can cost more than normal input |
| Later matching requests | Cached input price for matched prefix | Cache read price, 0.1x base input | Both can make repeated input much cheaper |
| TTL and retention | Provider-managed in-memory retention, with extended retention available on supported models | Explicit 5-minute default or 1-hour TTL choice | Claude makes TTL a pricing decision |
| Usage proof | usage.prompt_tokens_details.cached_tokens | cache_read_input_tokens, cache_creation_input_tokens, and input_tokens | Logging fields are provider-specific |
| Best fit | Stable repeated prefixes with simple accounting | Long documents, agents, or tool-heavy prompts that need explicit boundaries | Hit rate and prefix stability decide the winner |
The table is intentionally input-side only. Prompt caching does not discount output tokens, and it does not rescue prompts whose stable prefix keeps changing. If your application generates long answers, output cost may dominate the total bill even when prompt caching works perfectly.
The billing vocabulary is different
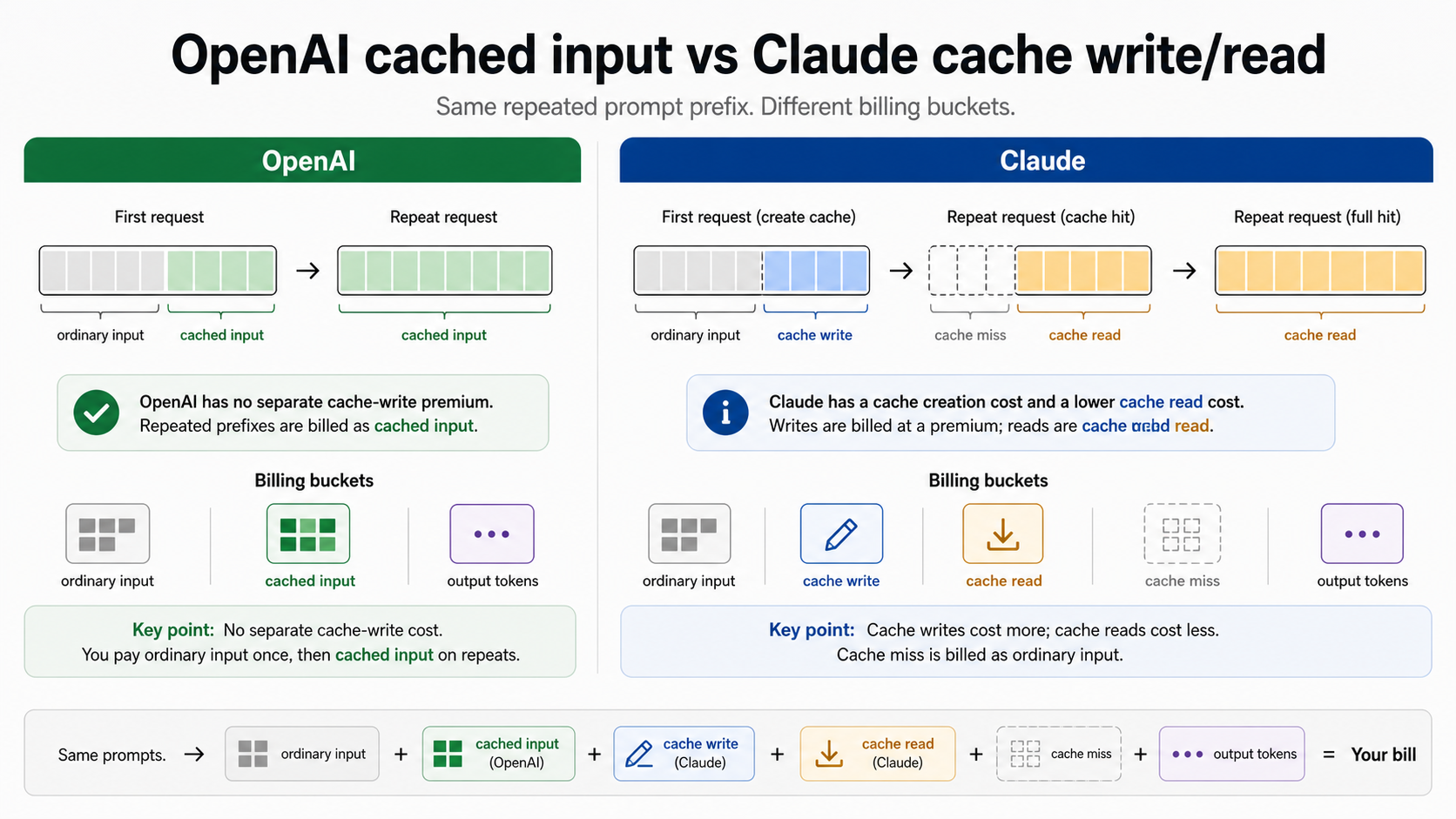
Before comparing percentages, split the bill into buckets. OpenAI calls the discounted repeated prompt prefix cached input. The OpenAI prompt caching guide says eligible prompts of at least 1024 tokens can be cached automatically when the beginning of the prompt matches earlier requests. The response usage object reports the hit through usage.prompt_tokens_details.cached_tokens.
Claude separates the same idea into cache creation and cache read buckets. The Anthropic prompt caching guide documents cache writes, cache reads, default 5-minute TTL, optional 1-hour TTL, and the usage fields cache_creation_input_tokens and cache_read_input_tokens. That split is why a Claude cost model needs at least two input-side numbers: what you pay to create or refresh the cache, and what you pay when later requests read from it.
This difference also changes how you talk about discounts. "OpenAI prompt caching is 50% off" was a useful headline for the 2024 GPT-4o and o1-era launch, but it is not a safe universal rule for current model rows. In the current OpenAI pricing table, GPT-5.5 standard input is $5.00 per 1M tokens and cached input is $0.50; GPT-5.4 standard input is $2.50 and cached input is $0.25; GPT-5.4 mini input is $0.75 and cached input is $0.075. Those are one-tenth cached-input rows, not a blanket 50% statement.
Claude's percentage is easier to state but still easy to misuse. Cache reads are 0.1x base input, but cache writes are not free: 5-minute writes are 1.25x base input, and 1-hour writes are 2x base input. If you cache once and read many times, the write premium fades. If you cache once and never hit it again, caching made the request more expensive.
Current price rows to anchor the comparison
Use these rows as a dated starting point, not as evergreen truth. Model names and pricing change often, so refresh the provider pages before locking a budget.
| Provider and model row | Normal input per 1M | Cache creation or cached input per 1M | Cache read per 1M | Output per 1M |
|---|---|---|---|---|
| OpenAI GPT-5.5 standard | $5.00 | $0.50 cached input | same cached-input row | $30.00 |
| OpenAI GPT-5.4 standard | $2.50 | $0.25 cached input | same cached-input row | $15.00 |
| OpenAI GPT-5.4 mini | $0.75 | $0.075 cached input | same cached-input row | $4.50 |
| Claude Opus 4.7 / 4.6 / 4.5 | $5.00 | $6.25 5-minute write; $10.00 1-hour write | $0.50 | $25.00 |
| Claude Sonnet 4.6 / 4.5 | $3.00 | $3.75 5-minute write; $6.00 1-hour write | $0.30 | $15.00 |
| Claude Haiku 4.5 | $1.00 | $1.25 5-minute write; $2.00 1-hour write | $0.10 | $5.00 |
Two details matter more than the headline. First, OpenAI's current pro rows can differ from standard rows. In the checked pricing table, GPT-5.5-pro and GPT-5.4-pro did not show cached-input pricing. Second, Claude's write and read columns are visible as separate rows because TTL choice changes the first cached request. For broader provider-cost context, use the Gemini API vs OpenAI vs Claude cost guide; the cache-billing decision should stay anchored to the repeated-prefix accounting model.
A repeated-prefix cost example
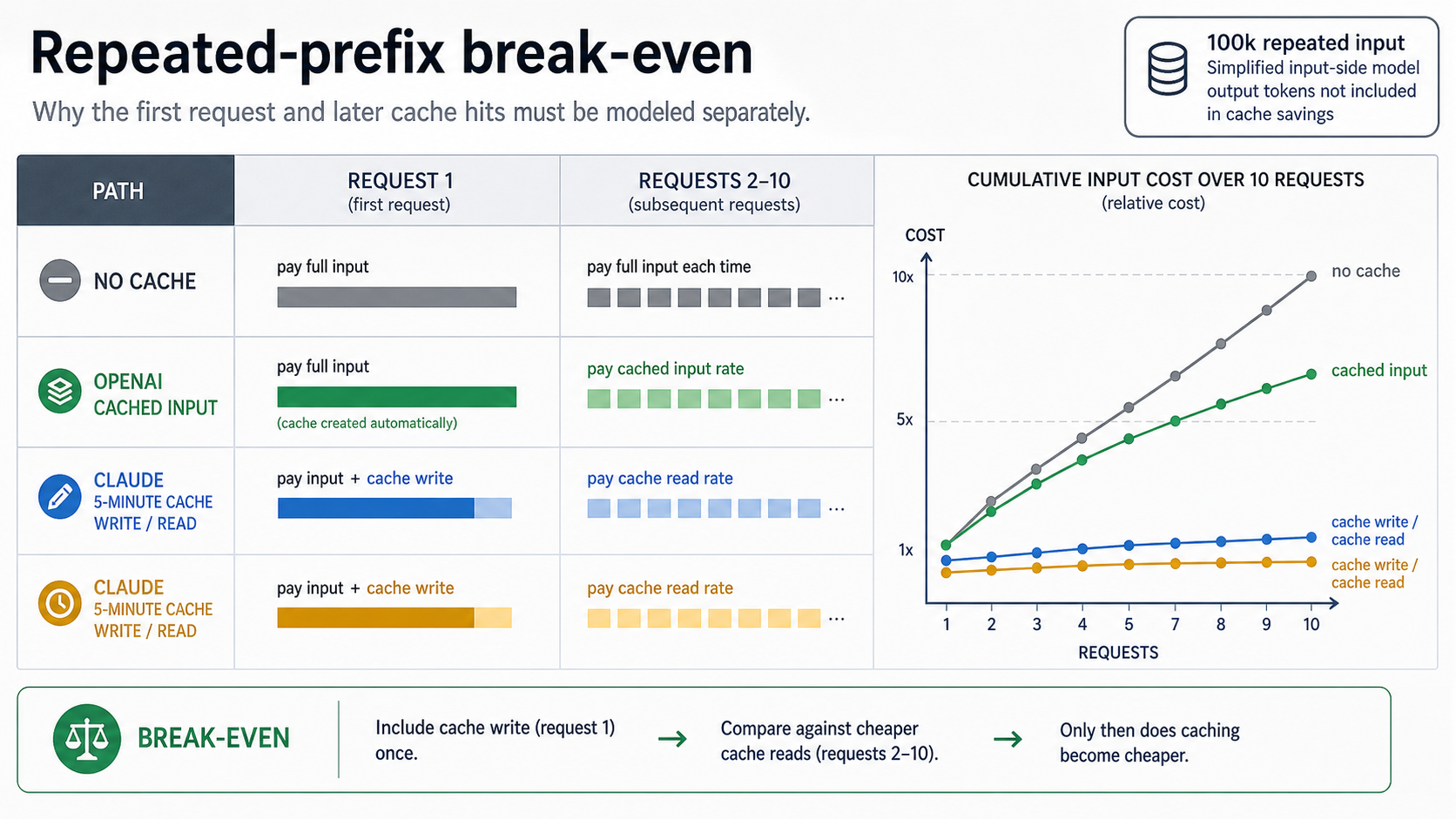
Use one input-side scenario to see the shape. Suppose you have a 100,000-token stable prefix: a system prompt, tool schema, policy pack, or retrieved document set. You send ten requests with that same prefix. Output tokens are excluded below because prompt caching does not discount them.
For OpenAI GPT-5.4 standard:
| Step | Input-side calculation | Cost |
|---|---|---|
| Request 1, uncached | 0.1M tokens x $2.50 | $0.25 |
| Requests 2-10, cached input | 9 x 0.1M tokens x $0.25 | $0.225 |
| Cached total | $0.25 + $0.225 | $0.475 |
| No-cache baseline | 10 x 0.1M tokens x $2.50 | $2.50 |
| Input-side savings | $2.50 - $0.475 | $2.025 |
For Claude Sonnet 4.6 with the default 5-minute cache:
| Step | Input-side calculation | Cost |
|---|---|---|
| Cache write | 0.1M tokens x $3.75 | $0.375 |
| Requests 2-10, cache reads | 9 x 0.1M tokens x $0.30 | $0.27 |
| Cached total | $0.375 + $0.27 | $0.645 |
| No-cache baseline | 10 x 0.1M tokens x $3.00 | $3.00 |
| Input-side savings | $3.00 - $0.645 | $2.355 |
The same Claude example with a 1-hour write starts at $0.60 instead of $0.375, so the cached total becomes $0.87 before output. That can still be a good trade if the reuse window really needs the longer TTL, but it makes the break-even point later.
The example does not prove that Claude is always cheaper or OpenAI is always cheaper. GPT-5.4 and Sonnet 4.6 are different models with different output prices, quality profiles, context behavior, and availability. The point is the method: separate first request, later hits, output tokens, and miss risk. Once you do that, your own prefix size and hit count become the decision surface.
How prompt layout creates or destroys hits
A lower cache price only matters after the provider can match the prefix. For OpenAI, the strongest rule is to put static content first and dynamic content last. Stable system instructions, tool schemas, policy text, and long reference context should appear before user-specific messages, timestamps, request IDs, or volatile retrieval fragments. The prompt_cache_key parameter can also help route similar prefixes, but OpenAI warns that very high traffic for the same prefix or key may still spread across machines and reduce hit effectiveness.
Claude's layout rule is more explicit because cache boundaries can be controlled. The prompt caching docs describe a hierarchy of tools, system, and messages. Changes earlier in that hierarchy can invalidate later cache segments. A dynamic tool list is expensive because it can wipe out all downstream cache reuse. A stable tool schema, a stable system prompt, and dynamic user content after the cache boundary are safer.
Common cache-busting mistakes are predictable:
- inserting timestamps, user IDs, or trace IDs before the cached prefix ends
- rebuilding tool schemas in a different order on each request
- mixing static policy text with dynamic retrieved snippets
- changing model rows while comparing bills
- setting Claude's 1-hour TTL when requests actually repeat inside five minutes
- assuming a repeated prompt string always means a provider-side cache hit
The safe prompt architecture is simple: build a deterministic static prefix, keep it in the same order, put per-request material after it, and log whether the provider reports a hit. If you need Claude-specific setup details, use the Claude API prompt caching guide as the implementation companion.
What to log before trusting savings

Do not infer cache savings from repeated prompts alone. Your billing dashboard and response usage fields need to show that cache hits happened.
For OpenAI, store at least:
- model name
- prompt token count
usage.prompt_tokens_details.cached_tokens- output token count
- a deterministic prefix hash from your own application
- whether
prompt_cache_keywas used
For Claude, store at least:
- model name
input_tokenscache_creation_input_tokenscache_read_input_tokens- output token count
- TTL choice
- cache boundary or prefix hash
These fields let you calculate a write/read ratio. If Claude shows high cache_creation_input_tokens and low cache_read_input_tokens, you are paying write premiums without enough reuse. If OpenAI shows low or zero cached tokens despite a large repeated prefix, your prompt is not matching the cache or is below the eligible threshold. The logging layer should also tag workload class, because support chat, code agents, batch document analysis, and RAG flows have different hit patterns.
Pricing modifiers and caveats
Base cache math is only the default path. Several modifiers can change the bill or the operational conclusion.
OpenAI cached tokens still need rate-limit planning. The prompt caching guide states that cached tokens count toward TPM limits, so a high hit rate can lower cost without removing every throughput constraint. OpenAI also has Batch, Scale Tier, priority or flex-style routing, long-context rows, and extended retention behavior that should be checked separately before using a simple cached-input model for production budgeting.
Claude's cache behavior has its own platform caveats. The first-party Claude API docs are the safest source for cache write and read math, but cloud marketplace routes such as Bedrock, Vertex AI, Microsoft Foundry, or AWS Marketplace may have additional contract details. Anthropic's pricing docs also mention Fast mode, Batch, data residency, and long-context notes. Keep those modifiers outside the simple table until you know which route your traffic actually uses.
Minimum token thresholds also differ by model. OpenAI's current prompt caching guide uses a 1024-token eligibility floor. Anthropic's checked docs listed 1024 for Sonnet 4.6/4.5 and several Opus/Sonnet rows, 2048 for Haiku 3.5, and 4096 for Mythos Preview, Opus 4.7/4.6/4.5, and Haiku 4.5. Treat these as current implementation facts, not copy-paste constants.
Decision rules
The cheapest provider is the one whose cache mechanics match your reuse pattern.
Choose OpenAI first when:
- your stable prefix repeats often and is easy to keep unchanged
- you want automatic caching without adding explicit cache boundary code
- you prefer a model row with a visible cached-input price and no write premium
- you can tolerate provider-managed cache retention rather than explicit TTL pricing
- your logs show meaningful
cached_tokensafter deployment
Choose Claude first when:
- your workload uses long documents, stable tool definitions, or agent context that benefits from explicit cache control
- you need to pre-warm or reason about cache boundaries directly
- the cache read volume is high enough to absorb the write premium
- 5-minute versus 1-hour TTL is a real product decision
- your logs show a healthy read-to-write ratio
Choose neither caching path as a cost lever when:
- the repeated prefix is small
- every request changes the beginning of the prompt
- output tokens dominate the bill
- traffic is too sparse to hit the cache before TTL expiry
- the provider row you use does not expose cached-input or cache-read pricing
The last point is easy to miss. Prompt caching is not a procurement slogan; it is a measurable behavior in a specific model route. If a wrapper, marketplace, or gateway sits between your app and the provider, verify its cache semantics and price rows separately before assuming first-party economics apply.
Implementation checklist
Use this checklist before you turn caching into a budget target.
- Pick the model row first. Do not use a generic OpenAI or Claude discount percentage.
- Measure the stable prefix size. Caching only matters when enough tokens repeat.
- Move dynamic values after the cached prefix. Timestamps, request IDs, and user-specific content should not break the static part.
- For OpenAI, check
cached_tokensin usage and considerprompt_cache_keyfor common prefixes. - For Claude, decide whether automatic top-level cache control is enough or explicit breakpoints are needed.
- Model first write, later reads, and output tokens separately.
- Watch cache writes that never turn into reads.
- Recheck price rows when model names, TTL policies, or platform routes change.
For Claude-specific cache_control examples, the dedicated Claude prompt caching guide should be the next stop. For broader Anthropic model economics, use the Claude API pricing guide.
FAQ
Is OpenAI prompt caching still a 50% discount?
Not as a universal current rule. OpenAI's 2024 launch language described 50% cached-input pricing for GPT-4o and o1-era models. The current checked GPT-5.5 and GPT-5.4 standard rows show cached input at one tenth of normal input. Always read the model row you plan to use.
Does Claude charge for the first cached request?
Yes. Claude separates cache creation from cache reads. The default 5-minute cache write is 1.25x base input, and the 1-hour cache write is 2x base input. Later cache reads are 0.1x base input.
Are output tokens discounted by prompt caching?
No. Prompt caching reduces repeated input-side processing. Generated output tokens still bill at the model's output price, and long answers can dominate the final invoice.
Which provider is cheaper for a long repeated system prompt?
It depends on the model row and reuse count. OpenAI is simpler because the first request is ordinary input and later matched prefixes use cached input. Claude can be very efficient after enough reads, but you need to include the cache write premium and TTL choice.
Does Claude have automatic prompt caching now?
Yes, Claude supports automatic top-level cache control as well as explicit cache_control breakpoints. Explicit control still matters when you need to decide exactly which tools, system content, or messages belong in the cached prefix.
What fields prove prompt caching worked?
For OpenAI, log usage.prompt_tokens_details.cached_tokens. For Claude, log cache_read_input_tokens, cache_creation_input_tokens, and fresh input_tokens. Also record model name, prefix hash, output tokens, and route details so you can reconcile usage with the invoice.
When should I avoid optimizing around prompt caching?
Avoid making prompt caching the main cost lever when prompts are short, the prefix changes on every request, traffic is too sparse for TTL windows, output tokens dominate the bill, or the provider route does not expose a reliable cached-token price.