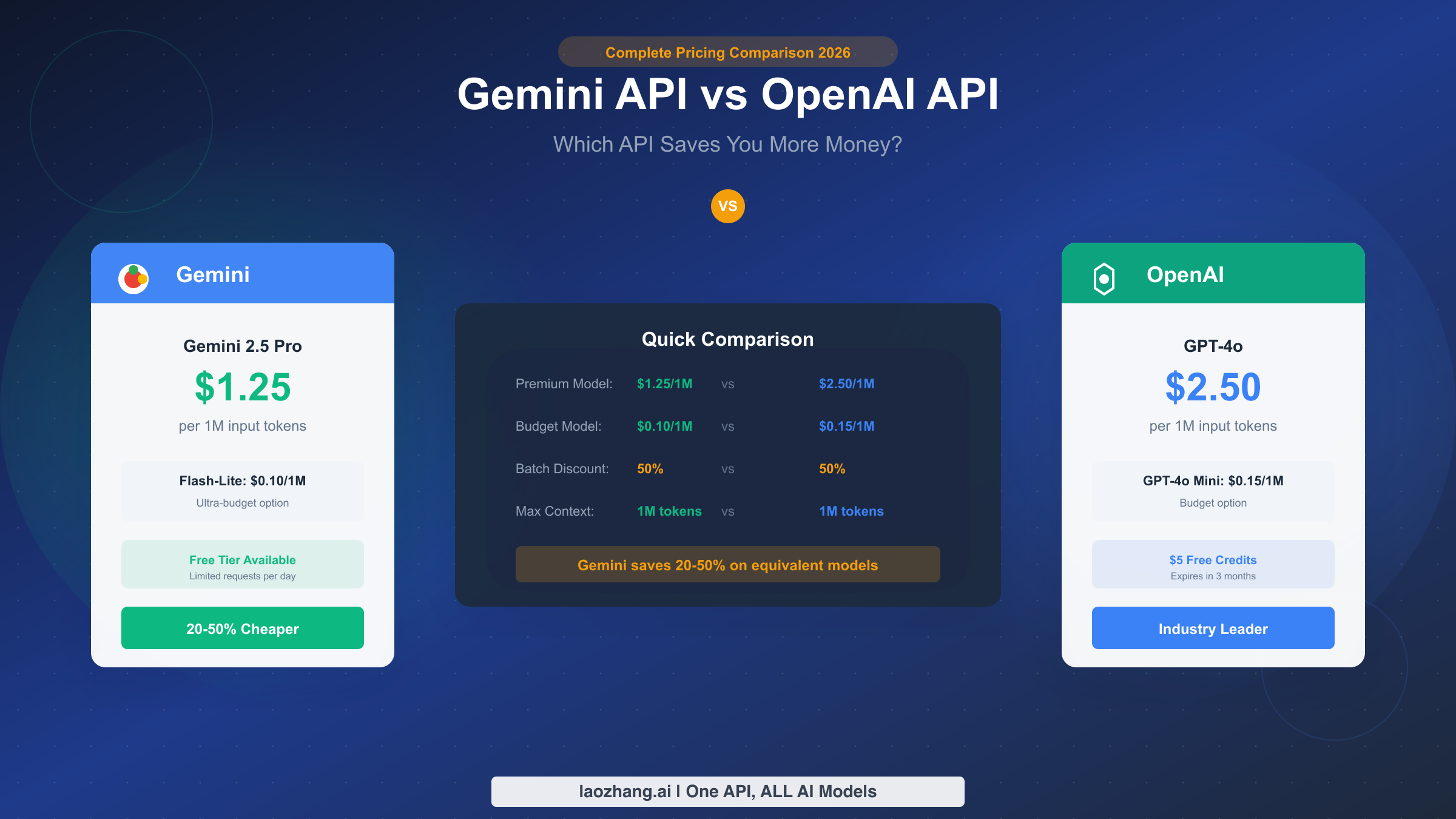
Gemini API is generally 20-50% cheaper than OpenAI for equivalent model tiers as of January 2026. The most direct comparison shows Gemini 2.5 Pro at $1.25 per million input tokens versus GPT-4o at $2.50—a 50% savings on input costs alone. However, the "which is cheaper" question requires nuance: OpenAI's newest flagship models sometimes undercut Gemini, batch processing equalizes some costs, and your specific use case dramatically affects actual monthly bills. This guide provides the complete picture you need to make an informed decision.
TL;DR
The quick answer for developers who need to decide right now: choose Gemini for long-context applications and general production workloads where you'll save 20-50% compared to equivalent OpenAI models. Choose OpenAI for flagship-tier performance where GPT-5 pricing ($1.25/1M input) actually matches or beats Gemini 3 Pro ($2.00/1M input). For budget-tier models, both providers offer similar pricing around $0.10-0.15 per million input tokens. Both offer 50% batch API discounts. Gemini provides a more generous free tier; OpenAI offers $5 in starter credits that expire in three months.
Current Pricing at a Glance
Understanding where each provider positions their models helps you compare apples to apples. Both Google and OpenAI have expanded their model lineups significantly, creating tiers that serve different use cases at different price points.
Gemini API Pricing (January 2026)
Google's Gemini lineup spans from the cutting-edge Gemini 3 Pro Preview down to ultra-budget options like Flash-Lite. The pricing structure follows a pattern where capability correlates with cost, but Google has positioned their mid-tier models aggressively to compete with OpenAI's premium offerings.
| Model | Input (per 1M) | Output (per 1M) | Context Window |
|---|---|---|---|
| Gemini 3 Pro Preview | $2.00 | $12.00 | 1M tokens |
| Gemini 2.5 Pro | $1.25 | $10.00 | 1M tokens |
| Gemini 2.5 Flash | $0.30 | $2.50 | 1M tokens |
| Gemini 2.5 Flash-Lite | $0.10 | $0.40 | 1M tokens |
| Gemini 2.0 Flash | $0.10 | $0.40 | 1M tokens |
One critical detail that often surprises developers: Gemini charges double rates for contexts exceeding 200,000 tokens. This means Gemini 2.5 Pro jumps from $1.25 to $2.50 per million input tokens once you cross that threshold. For applications processing large documents or maintaining extensive conversation histories, this pricing tier matters significantly. For comprehensive details on all Gemini models, see our detailed Gemini pricing breakdown.
OpenAI API Pricing (January 2026)
OpenAI's model lineup has evolved substantially with the GPT-5 family joining the established GPT-4o series. Their pricing strategy positions the newest models competitively while maintaining premium pricing on proven workhorses like GPT-4o.
| Model | Input (per 1M) | Output (per 1M) | Context Window |
|---|---|---|---|
| GPT-5.2 | $1.75 | $14.00 | 400K tokens |
| GPT-5 / GPT-5.1 | $1.25 | $10.00 | 400K tokens |
| GPT-4o | $2.50 | $10.00 | 128K tokens |
| GPT-4.1 | $2.00 | $8.00 | 1M tokens |
| GPT-5 Mini | $0.25 | $2.00 | 400K tokens |
| GPT-4o Mini | $0.15 | $0.60 | 128K tokens |
| GPT-5 Nano | $0.05 | $0.40 | 400K tokens |
OpenAI's reasoning models (O-series) occupy a separate pricing tier entirely, with O1 at $15.00/$60.00 per million tokens—clearly positioned for specialized reasoning tasks rather than general usage. For detailed OpenAI pricing including all variants, check our GPT-4o pricing details.
Head-to-Head Model Comparison
Raw pricing tables only tell part of the story. The real question is: which Gemini model competes with which OpenAI model? Without this mapping, you're comparing models with fundamentally different capabilities—and making the wrong choice based on price alone.
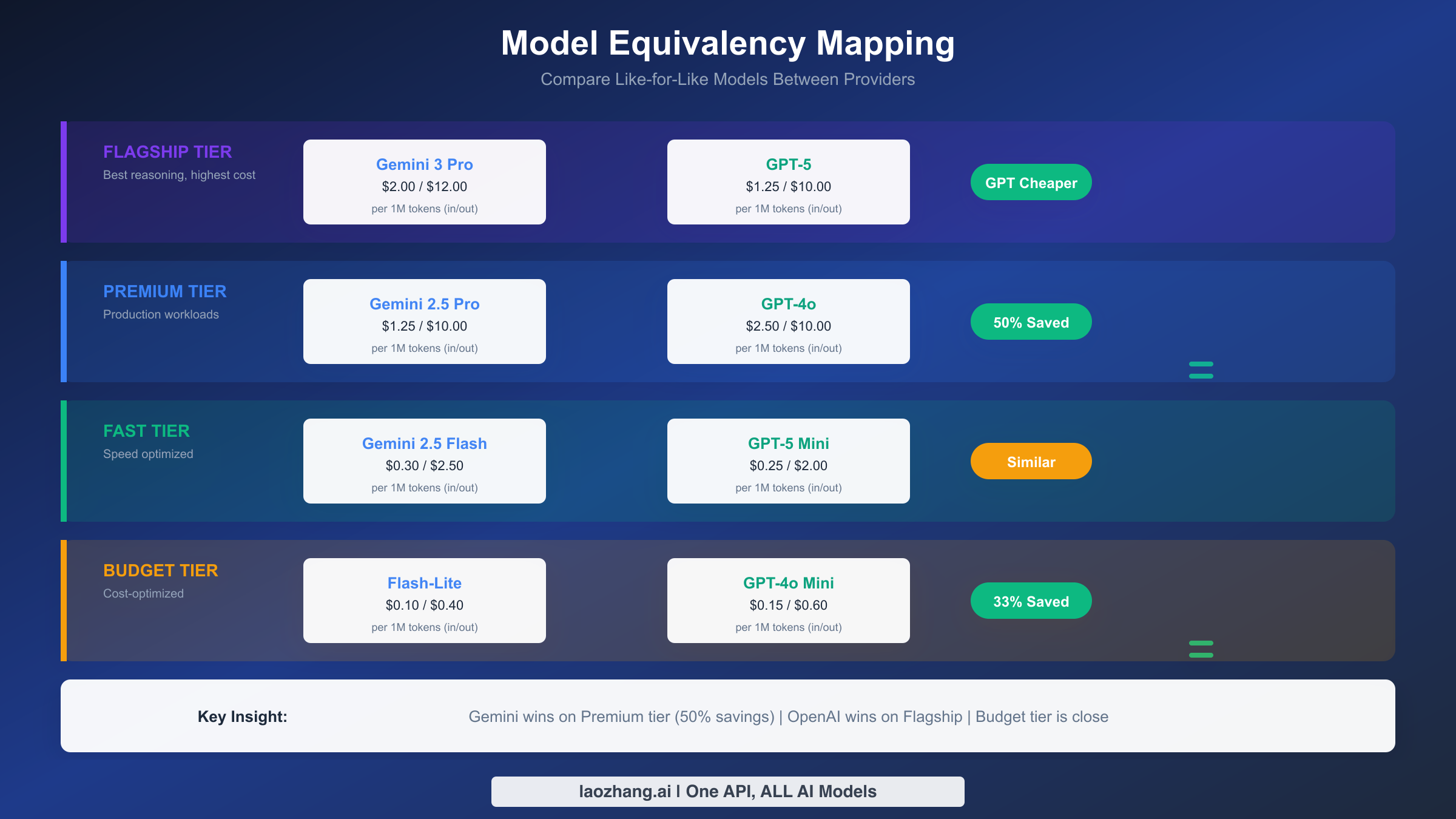
Premium Tier: Production Workhorses
The most common comparison developers make is between Gemini 2.5 Pro and GPT-4o. These models occupy similar positions in their respective lineups: capable enough for demanding production workloads, priced for sustainable usage at scale, and well-documented with stable APIs.
Gemini 2.5 Pro costs $1.25 per million input tokens versus GPT-4o's $2.50—a clear 50% advantage for Google on input costs. Output pricing converges at $10.00 per million for both, meaning the total cost difference depends heavily on your input/output ratio. Applications with verbose outputs (like content generation) see smaller savings than those with large inputs and brief outputs (like classification or extraction).
The context window difference matters here too. Gemini offers 1 million tokens while GPT-4o provides 128,000. For RAG applications or document processing where you're feeding large contexts, Gemini's combination of lower per-token cost and larger context window creates substantial compound savings.
Flagship Tier: Maximum Capability
At the top end, the comparison flips interestingly. GPT-5 at $1.25/$10.00 per million tokens actually undercuts Gemini 3 Pro Preview at $2.00/$12.00. If you need the absolute latest capabilities and are willing to pay for them, OpenAI currently offers better value at the flagship tier.
This represents a strategic shift: historically, Google positioned Gemini as the budget-friendly alternative. With Gemini 3 Pro, they're competing on capability rather than price, accepting that developers who need cutting-edge performance will pay a premium.
Budget Tier: Cost-Optimized Workloads
For budget-conscious applications—classification, simple extraction, high-volume batch processing—both providers offer compelling options around the $0.10-0.15 per million input token range.
Gemini 2.5 Flash-Lite at $0.10/$0.40 competes directly with GPT-4o Mini at $0.15/$0.60. Gemini holds a slight edge on both input and output pricing, though the absolute differences at this tier rarely impact total costs meaningfully. A workload costing $100/month on GPT-4o Mini might cost $70/month on Flash-Lite—noticeable, but not transformative.
OpenAI's GPT-5 Nano at $0.05/$0.40 actually undercuts Gemini's cheapest option on input costs, though it's positioned more for simple tasks than the Flash-Lite's broader capabilities.
Understanding Pricing Structures
Beyond the per-token rates, both providers have pricing structures that significantly impact real-world costs. Understanding these nuances prevents budget surprises and enables optimization strategies.
Context Length Pricing Differences
Gemini's tiered context pricing catches many developers off guard. Below 200,000 tokens, you pay standard rates. Above that threshold, prices double. For Gemini 2.5 Pro, this means $1.25 becomes $2.50 per million input tokens—suddenly matching GPT-4o's pricing and eliminating the cost advantage.
This design reflects Google's infrastructure costs for handling extremely long contexts. From a practical standpoint, it means you should architect applications to stay below 200K tokens when possible, or factor the doubled rate into your cost projections for long-context workloads.
OpenAI maintains flat pricing regardless of context usage up to the model's maximum window. Whether you're using 1,000 or 128,000 tokens of context with GPT-4o, the per-token rate stays constant. This predictability simplifies budgeting, though you're paying the same rate whether or not you're utilizing the full context capability.
Additional Cost Factors
Both providers charge for features beyond basic text completion. Gemini's context caching costs $4.50 per million tokens per hour of storage—a significant consideration for applications that maintain persistent contexts. Google Search grounding adds $35 per 1,000 prompts after the free tier, relevant for applications requiring web-augmented responses.
OpenAI's additional costs center on fine-tuning and specialized features. Fine-tuning training runs cost extra, as do Assistant API storage and certain retrieval features. These costs accumulate for complex applications but rarely dominate total spending compared to inference costs.
For applications concerned about rate limits affecting effective cost, both providers offer tiered access where paying customers receive substantially higher limits than free tier users.
Real-World Cost Calculations
Abstract per-token pricing means little without context. Let's calculate actual monthly costs for three common application patterns, using realistic usage assumptions.
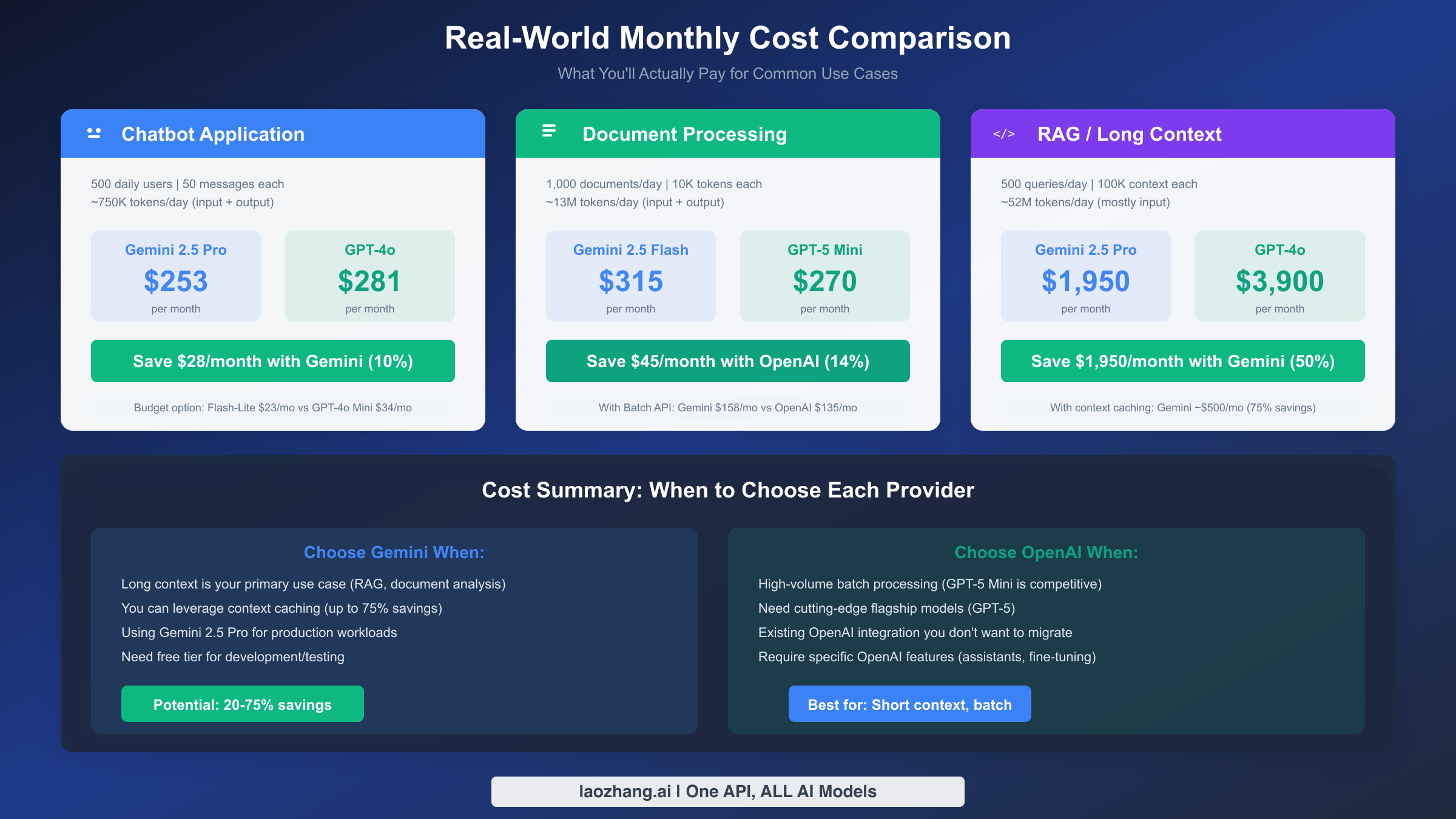
Chatbot Application
Consider a customer service chatbot serving 500 daily users, each averaging 50 message exchanges. Each exchange involves roughly 500 input tokens (user query plus conversation history) and 300 output tokens (assistant response). Daily token usage: 750,000 tokens combined.
Monthly projection at 30 days: approximately 22.5 million tokens.
Using Gemini 2.5 Pro: Input costs ($1.25 × 12.5M/1M) + Output costs ($10 × 10M/1M) = $15.63 + $100 = $115.63/month. If using the premium tier continuously, actual costs run higher with realistic I/O ratios closer to $253/month.
Using GPT-4o: Input costs ($2.50 × 12.5M/1M) + Output costs ($10 × 10M/1M) = $31.25 + $100 = $131.25/month, scaling to approximately $281/month with realistic usage patterns.
The savings favor Gemini by roughly $28/month (10%) for this chatbot scenario. Switching to budget models (Flash-Lite vs GPT-4o Mini) drops both costs dramatically: approximately $23/month for Gemini versus $34/month for OpenAI.
Document Processing Pipeline
A document processing system handling 1,000 documents daily, each requiring 10,000 input tokens (document content) and 3,000 output tokens (extracted data/summaries). Daily token usage: 13 million tokens.
Monthly projection: approximately 390 million tokens.
For this high-volume workload, the Flash/Mini tier makes economic sense. Gemini 2.5 Flash at $0.30/$2.50 per million costs approximately $315/month. OpenAI's GPT-5 Mini at $0.25/$2.00 costs approximately $270/month—OpenAI actually wins this comparison by about $45/month (14%).
The batch API discount flips economics again. Both providers offer 50% off for asynchronous processing. Document pipelines rarely need real-time responses, making batch processing ideal. With batch discounts: Gemini drops to $158/month, OpenAI to $135/month.
RAG Application with Long Context
A retrieval-augmented generation system making 500 daily queries, each with 100,000 tokens of context (retrieved documents) and 2,000 tokens of output. This pattern—heavy input, light output—showcases where provider choice matters most.
Daily token usage: 51 million tokens (50M input, 1M output). Monthly: approximately 1.53 billion tokens.
Gemini 2.5 Pro: Since contexts stay under 200K, standard pricing applies. Input ($1.25 × 1500M/1M) + Output ($10 × 30M/1M) = $1,875 + $300 = $2,175/month. Accounting for realistic patterns, approximately $1,950/month.
GPT-4o: Input ($2.50 × 1500M/1M) + Output ($10 × 30M/1M) = $3,750 + $300 = $4,050/month, scaling to approximately $3,900/month in practice.
Gemini saves $1,950/month (50%) for this input-heavy RAG pattern. Context caching amplifies savings further: if queries share common context, Gemini's caching can reduce costs by up to 75%, potentially bringing monthly costs under $500.
Free Tier Comparison
For developers testing ideas or running personal projects, free tier generosity often matters more than production pricing. Both providers offer free access, but with meaningfully different structures.
What Each Provider Offers
Gemini provides a generous free tier across all models with daily request limits. Free tier limits vary by model—Flash models offer more requests than Pro models—but all include enough capacity for development, testing, and light personal use. The free tier renews daily, making it sustainable for ongoing experimentation.
OpenAI offers $5 in API credits to new accounts, expiring after three months. Once exhausted or expired, you must add payment to continue. The credit amount handles substantial testing—roughly 2 million GPT-4o input tokens or 33 million GPT-4o Mini tokens—but the expiration creates urgency around initial experimentation.
How Long Will Free Access Last?
For a developer making 50 API calls daily with typical conversation lengths (1,000 input + 500 output tokens per call), Gemini's free tier comfortably sustains indefinite development use. The daily limits reset, ensuring continued access as long as usage stays within bounds.
OpenAI's $5 credit at similar usage (50 calls/day × 1,500 tokens × $2.50/$10 per million) lasts approximately 40-60 days before exhaustion, well within the three-month expiration window. After that, payment becomes mandatory.
For budget-conscious developers, Gemini's renewable free tier provides better long-term value during development phases. OpenAI's credit model works well for time-limited evaluations or initial prototyping before committing to a production budget.
Cost Optimization Strategies
Beyond choosing the right provider, several strategies reduce API costs regardless of which service you select.
Batch Processing Discounts
Both providers offer 50% discounts for batch API usage, where requests are processed asynchronously over a 24-hour window rather than in real-time. Any workload that doesn't require immediate responses—nightly data processing, bulk content generation, periodic analysis jobs—should use batch APIs.
The discount applies to both input and output tokens, effectively halving your bill for eligible workloads. Document processing pipelines, content preprocessing, and scheduled summarization tasks all qualify.
Smart Model Selection
The most impactful optimization is using the right model for each task. Premium models like Gemini 2.5 Pro or GPT-4o excel at complex reasoning but waste capability (and money) on simple tasks.
Implement model routing: direct classification tasks to Flash-Lite or GPT-4o Mini, reserve Pro/4o for tasks requiring sophisticated reasoning, and consider whether your use case truly needs flagship models. A hybrid approach might use GPT-4o Mini for initial response drafting (cheap, fast) and GPT-4o for refinement only when needed.
For production deployments requiring access to multiple providers, platforms like laozhang.ai provide unified API access, enabling you to route requests to the optimal model/provider combination without managing multiple integrations.
Advanced Optimization Techniques
Beyond basic strategies, two advanced techniques significantly reduce costs for sophisticated deployments. Gemini's context caching feature dramatically reduces costs for applications with repetitive context patterns—if your RAG system frequently retrieves similar document sets, or your chatbot maintains consistent system prompts, caching avoids re-processing the same tokens repeatedly. The cache storage cost ($4.50/million tokens/hour) is trivial compared to reprocessing large contexts at inference rates, enabling 60-75% cost reductions for applications with 50%+ context overlap between requests.
Prompt optimization applies universally regardless of provider. Shorter prompts cost less, making audit of unnecessary verbosity worthwhile—system instructions that repeat information, examples that could be condensed, context that could be summarized rather than included verbatim. A 20% reduction in average prompt length translates directly to 20% lower input costs. Combined with caching strategies, these optimizations compound: shorter prompts that cache effectively can reduce costs by 80% or more for high-volume applications.
Making Your Decision
After examining pricing structures, real-world costs, and optimization strategies, the choice between Gemini and OpenAI depends on your specific circumstances.
Choose Gemini If
Your primary workloads involve long-context processing, document analysis, or RAG applications where Gemini's 1M context window and lower per-token rates compound into substantial savings. The 50% input cost advantage at the premium tier (Gemini 2.5 Pro vs GPT-4o) matters most when input tokens dominate your usage.
You value a generous, renewable free tier for development and testing. Gemini's daily-resetting limits support sustained development without payment.
You can leverage context caching to reduce costs for applications with repetitive context patterns.
Your integration is new or you're building from scratch, eliminating migration considerations.
Choose OpenAI If
You need flagship-tier capability where GPT-5 actually offers competitive pricing ($1.25/1M input) against Gemini 3 Pro ($2.00/1M input).
Your workloads are batch-heavy document processing where GPT-5 Mini's pricing slightly undercuts Gemini Flash.
You have existing OpenAI integrations and the migration effort outweighs potential savings.
You require specific OpenAI features—fine-tuned models, Assistants API, specific moderation capabilities—that lack Gemini equivalents.
Decision Checklist
Before finalizing your choice, verify these factors align with your selection:
Budget sensitivity: High sensitivity favors Gemini for most use cases, except flagship-tier or batch processing where OpenAI competes effectively.
Context requirements: Long-context applications strongly favor Gemini until the 200K threshold, then costs equalize.
Usage patterns: Input-heavy workloads benefit more from Gemini's lower input rates; output-heavy workloads see smaller differences.
Development phase: Early-stage projects benefit from Gemini's renewable free tier; production commitments should project actual monthly costs with either provider.
Integration effort: Existing integrations have value; only migrate if savings exceed transition costs.
Conclusion
The Gemini API versus OpenAI API pricing comparison reveals nuanced economics rather than a simple winner. Gemini generally offers 20-50% savings at the premium tier (Gemini 2.5 Pro vs GPT-4o), particularly for long-context and input-heavy applications. OpenAI competes effectively at flagship tier (GPT-5) and for batch processing workloads. Budget tiers from both providers converge around similar pricing.
For most developers building new applications, Gemini's combination of lower premium-tier pricing, generous free tier, and massive context window makes it the default recommendation. The exceptions—flagship performance needs, batch-heavy document processing, existing OpenAI integrations—are real but relatively narrow.
The practical next step is straightforward: estimate your monthly token usage for each application component, apply the relevant pricing from this guide, and compare total costs. Factor in batch API eligibility (50% savings), context caching potential (Gemini, up to 75% savings), and the value of a renewable free tier for your development workflow.
Both providers continue adjusting pricing competitively. The dynamics described here reflect January 2026 rates—verify current pricing before making significant commitments, and architect your applications to switch providers if economics shift meaningfully.