
Choose Gemini 3 Flash if you need stronger coding, agentic, multimodal, and search-heavy performance and can absorb preview risk plus a higher token bill. Keep Gemini 2.5 Flash if lower cost, GA stability, and a simpler current default matter more while you plan a migration.
The useful frame is migration timing. Gemini 3 Flash is the forward lane Google is pushing, but Gemini 2.5 Flash is still cheaper and still rational until the June 17, 2026 shutdown window gets close enough that migration risk outweighs the savings.
TL;DR
If you only need the decision, here it is:
- Choose Gemini 3 Flash first for coding agents, multimodal reasoning, tool-heavy workflows, and products where better quality matters more than squeezing every cent out of the token bill.
- Choose Gemini 2.5 Flash first for cost-sensitive high-volume text workloads, conservative production defaults, and low-cost grounded prototypes where stable status still matters.
- Do not wait too long to plan the migration. Google already names Gemini 3 Flash as the replacement for Gemini 2.5 Flash, and the current shutdown date for 2.5 Flash is June 17, 2026.
The current official comparison looks like this:
| Area | Gemini 3 Flash | Gemini 2.5 Flash | What it means |
|---|---|---|---|
| Current status | Preview | Stable / GA | 3 Flash is the forward path, 2.5 Flash is the steadier current default |
| Model ID | gemini-3-flash-preview | gemini-2.5-flash | If you pin model IDs, migration is explicit |
| Release date | December 17, 2025 | June 17, 2025 | 3 Flash is the newer generation |
| Shutdown / lifecycle | No shutdown date announced | Shutdown date: June 17, 2026 | Staying on 2.5 Flash is a time-bounded decision |
| Recommended replacement | N/A | gemini-3-flash-preview | Google has already told users where to go next |
| Standard price | $0.50 in / $3.00 out | $0.30 in / $2.50 out | 3 Flash is meaningfully more expensive |
| Batch price | $0.25 in / $1.50 out | $0.15 in / $1.25 out | 2.5 Flash stays cheaper in batch too |
| Context / output | 1,048,576 / 65,536 | 1,048,576 / 65,536 | Headline token limits are not the real differentiator |
| Grounding | Paid-tier monthly allowances for Search and Maps | Free Search grounding up to 500 RPD and free Maps grounding up to 500 RPD | 2.5 Flash is easier for low-cost grounded apps |
| Thinking control | thinking_level | thinking_budget | Migration changes how you tune latency and reasoning |
| Computer Use | Supported | Not listed as supported on the Gemini API page | 3 Flash clearly opens more agentic workflows |
| Best fit | Higher-capability Flash lane | Cheaper stable Flash lane | Pick based on workload, not just the newer date |
Those rows come from the official pricing page, Gemini 3 Flash page, Gemini 2.5 Flash page, release notes, deprecations page, and the current Vertex AI Gemini 3 Flash documentation.
Why This Choice Is Harder Than Google's Launch Story Makes It Look
Google's public story around Gemini 3 Flash is straightforward. The official launch post and the official DeepMind page present Gemini 3 Flash as the model that brings frontier-level reasoning into the Flash speed and cost lane. That story is real. The official DeepMind benchmark table is not subtle: Gemini 3 Flash beats Gemini 2.5 Flash on GPQA, MMMU-Pro, ScreenSpot-Pro, LiveCodeBench Pro, SWE-bench Verified, FACTS, SimpleQA Verified, and several agentic benchmarks.
If you care about coding, tool use, multimodal reasoning, or interface-heavy workflows, that improvement is not cosmetic. On the official DeepMind table, Gemini 3 Flash reaches:
- 90.4% on GPQA Diamond versus 82.8% for Gemini 2.5 Flash
- 81.2% on MMMU-Pro versus 66.7%
- 78.0% on SWE-bench Verified versus 60.4%
- 61.9% on FACTS versus 50.4%
- 57.4% on MCP Atlas versus 8.8%
Those are large jumps, not rounding noise. They explain why Google is already routing users toward Gemini 3 Flash and why the release notes switched the gemini-flash-latest alias to gemini-3-flash-preview on January 21, 2026.
But the launch story is still incomplete if you are making an API decision instead of reading a benchmark headline. Gemini 3 Flash is not a free upgrade. It is a better but more expensive preview model. Gemini 2.5 Flash is still a cheaper stable GA model with a friendlier free-grounding story. That means the practical question is not "Is 3 Flash stronger?" It clearly is. The practical question is "Where is that extra strength actually worth paying for right now?"
There is also an important surface split that page one often blurs together. In the consumer Gemini app, Google already made Gemini 3 Flash the default. In the API, you still have to think about price, rollout risk, prompt behavior, and exact model IDs. The app decision tells you Google's strategic direction. It does not automatically prove that your API workload should migrate everywhere on the same day.
That is the gap most ranking pages still leave open.
Pricing, Grounding, And Lifecycle On March 20, 2026

Pricing is the first reason this comparison is not automatic.
On the official Gemini Developer API pricing page, current standard pricing is:
- Gemini 3 Flash Preview:
\$0.50input and\$3.00output per 1M tokens - Gemini 2.5 Flash:
\$0.30input and\$2.50output per 1M tokens
For batch usage, the direction stays the same:
- Gemini 3 Flash Preview batch:
\$0.25input and\$1.50output - Gemini 2.5 Flash batch:
\$0.15input and\$1.25output
So Gemini 3 Flash is not the "same price but better" upgrade many readers assume. Relative to Gemini 2.5 Flash, it is about 67% more expensive on input and 20% more expensive on output. That does not kill the case for migrating, but it changes the math. If your workload is millions of lightweight extraction or summarization calls, the price gap is meaningful.
Grounding makes the difference even sharper. The same official pricing page shows:
- Gemini 2.5 Flash includes free Google Search grounding up to 500 RPD and free Google Maps grounding up to 500 RPD on the free tier.
- Gemini 3 Flash Preview does not present the same free-tier grounding path. Instead, it lists paid-tier monthly allowances for Search and Maps before per-query charges apply.
That matters because many teams are not evaluating a benchmark lab task. They are building a grounded assistant or prototype that needs low-friction economics. For that use case, Gemini 2.5 Flash still has a very real convenience advantage.
Then there is lifecycle. This is where the comparison stops being purely economic. The official deprecations page currently says:
gemini-2.5-flashrelease date: June 17, 2025gemini-2.5-flashshutdown date: June 17, 2026- recommended replacement:
gemini-3-flash-preview
The same page lists gemini-3-flash-preview as released on December 17, 2025 with no shutdown date announced. That means you can rationally stay on 2.5 Flash for now, but you can no longer rationally treat it as a permanent default. The clock is visible now.
The cleanest way to think about the economics is this:
- 2.5 Flash wins on price
- 2.5 Flash wins on free grounding convenience
- 3 Flash wins on official future direction
- 3 Flash wins on capability
That is why a staged migration is smarter than either stubbornly refusing to move or blindly swapping everything over at once.
If you need the surrounding cost context across the whole Gemini line, our Gemini API pricing 2026 guide and Gemini 3 Flash API price guide go deeper.
What Gemini 3 Flash Actually Adds Over Gemini 2.5 Flash

The easiest mistake in this comparison is treating Gemini 3 Flash as a slightly better Gemini 2.5 Flash. The official docs show a bigger shift than that.
First, Gemini 3 Flash is clearly Google's stronger agentic Flash lane. The current Gemini 3 Flash API page and the Vertex AI page highlight several workflow-level upgrades:
- Computer Use support
- multimodal function responses
- streaming function-call arguments
- media-resolution control
- thinking-level controls for Gemini 3
That feature stack matters most if your product is not just "send prompt, get text." It matters if you are building coding agents, tool-heavy workflows, search-grounded assistants, or multimodal apps that need strong reasoning under latency pressure.
Second, Google is not merely claiming that 3 Flash is more capable in vague terms. The official DeepMind table shows a strong direct advantage versus Gemini 2.5 Flash on exactly the kinds of benchmarks that map to higher-end product behavior:
- coding and agentic software tasks
- screen understanding
- tool use
- multimodal reasoning
- factuality
- complex chart and document interpretation
That is the strongest reason to move first in coding and agentic workflows. If your current product is already bottlenecked by reasoning quality rather than raw cost, Gemini 3 Flash is the more sensible frontier Flash model.
Third, the migration is not just about price and quality. It changes how you tune the model. Vertex AI's current Gemini 3 Flash documentation says Gemini 3 uses thinking_level, and it explicitly tells users that if they previously used a thinking budget of 0 with Gemini 2.5 Flash, they should set thinking_level to MINIMAL for similar latency and cost. That is a real operational difference. If your prompts and latency budget were built around thinking_budget, you need to test those assumptions again instead of assuming a drop-in swap.
This is where the current SERP still feels shallow. Many pages tell readers Gemini 3 Flash is stronger. Fewer explain the mechanism:
- better agentic tooling support
- stronger reasoning benchmarks
- changed control surface
- a more explicit "future default" signal from Google
If you are choosing for coding agents, interactive tool use, or multimodal workflow automation, that mechanism matters more than a single headline score.
It is also worth translating the benchmark rows into operational language instead of leaving them as leaderboard trivia. Higher ScreenSpot-Pro and MMMU-Pro matter if your workflow reasons over screenshots, UI state, charts, PDFs, or mixed visual context. Higher SWE-bench Verified, Terminal-Bench, Toolathlon, and MCP Atlas matter if you are building agents that need to use tools, keep state, and recover from multi-step tasks instead of just generating a clever answer. Higher FACTS and SimpleQA Verified matter if your users will punish confident mistakes more than they reward slightly cheaper tokens. Those are all places where Gemini 3 Flash looks like more than a marginal upgrade.
Where Gemini 2.5 Flash Still Makes More Sense
The fact that Gemini 3 Flash is stronger does not mean Gemini 2.5 Flash became irrational overnight.
Gemini 2.5 Flash still makes more sense in three common situations.
1. Your workload is high-volume and price-sensitive. If you are running classification, lightweight summarization, extraction, or support-routing pipelines at large scale, the lower token price of Gemini 2.5 Flash still matters. Saving $0.20 per input million and $0.50 per output million becomes real money when your workload is large enough.
2. You want the stable lane while you evaluate the replacement. The official docs still present Gemini 2.5 Flash as Stable / GA, while Gemini 3 Flash remains Preview. The official rate-limits page also says preview models can have more restrictive limits. For teams with low appetite for lifecycle churn, that alone can justify keeping 2.5 Flash as the default until your internal evals are done.
3. You care about low-cost grounding more than frontier Flash quality. Gemini 2.5 Flash's free Search and Maps grounding allowances still make it easier to prototype grounded assistants and search-heavy utilities without forcing a paid-grounding story from day one.
There is also a softer but important point: real-world migration pain tends to show up first in niche workloads, not in launch benchmarks. Public community threads are not official proof, but they are useful reminders that "newer" and "better for my product" are not identical. That is why the safer recommendation is still workload-specific rather than universal.
The strongest pro-2.5 position is not "2.5 Flash is the better model." The strongest pro-2.5 position is "2.5 Flash is still the better default for some budgets, some teams, and some grounded prototype lanes while the migration window is still open."
One more point helps keep this comparison honest: the shared 1M context window does not remove the need for evals. Both models can ingest large contexts, but the practical question is what quality you get per dollar and per second inside your own prompt stack. If your application mainly does short or medium text tasks, the raw capability gap may not justify the cost gap. If your application does coding, tool use, multimodal reasoning, or search-rich workflows, the quality delta is much more likely to pay for itself.
Which Model To Use For Which Workload
The fastest way to make this comparison useful is to turn it into routing advice.
| Workload | Pick first | Why |
|---|---|---|
| Coding agents and agentic developer tools | Gemini 3 Flash | Official benchmark and feature delta strongly favor 3 Flash |
| Tool-heavy assistants with multimodal input | Gemini 3 Flash | Better reasoning, tool-use support, and Computer Use make the upgrade worth it |
| Search-heavy products where quality matters more than the cheapest grounding path | Gemini 3 Flash | Higher capability plus newer Gemini 3 tooling stack |
| Budget-first summarization and extraction pipelines | Gemini 2.5 Flash | Lower cost still wins when quality headroom is not the bottleneck |
| Grounded prototypes on the cheapest possible path | Gemini 2.5 Flash | Free grounding allowances are still easier to work with |
| Conservative production default with low change tolerance | Gemini 2.5 Flash for now | Stable status buys operational calm while you test 3 Flash |
| Greenfield product where Flash quality is the main priority | Gemini 3 Flash | It is the direction Google is clearly pushing developers toward |
| Mixed fleet with strong eval discipline | Both | Use 3 Flash where the quality delta pays for itself and keep 2.5 Flash where cost or stability wins |
My practical recommendation is simple:
- For new capability-first builds: start with Gemini 3 Flash.
- For existing cost-sensitive 2.5 Flash deployments: keep 2.5 Flash running, but start evaluation now.
- For mixed environments: route by workload instead of forcing one universal default.
If you are also comparing Gemini 3 Flash to the more expensive Pro lane, Gemini 3 Flash vs Pro capabilities is the better follow-up.
How To Migrate Without Breaking Production
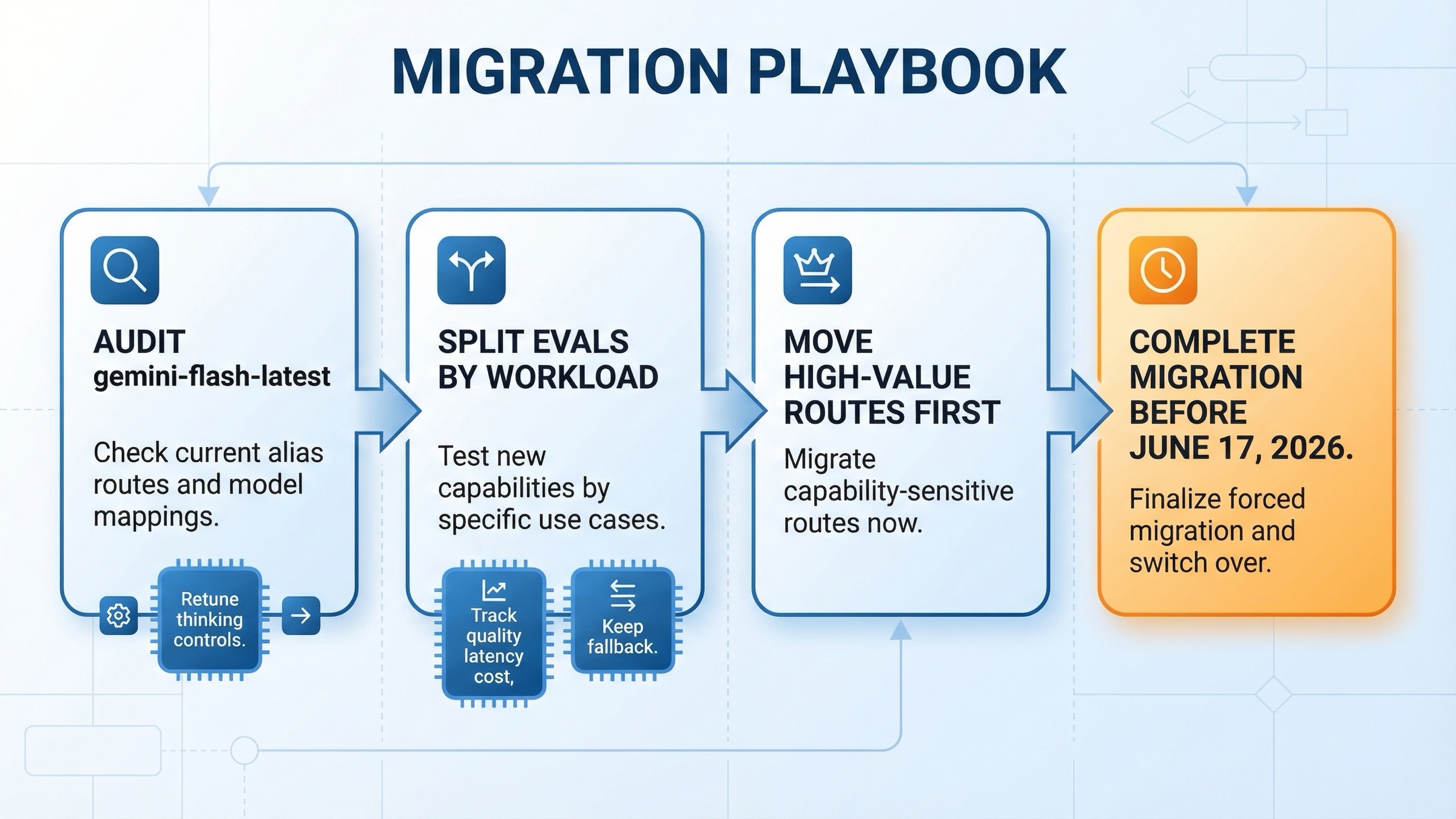
The wrong migration plan is "replace the model name and hope." The right plan is staged.
1. Audit whether you are already using the alias. The official release notes say Google switched gemini-flash-latest to gemini-3-flash-preview on January 21, 2026. If your application points at the alias instead of a pinned model ID, part of your migration may already have happened. Confirm the actual model route before you change anything else.
2. Split your evals by workload family. Do not run one blended benchmark and call it done. Separate:
- coding and agentic tasks
- support or chat tasks
- grounded search tasks
- extraction and summarization tasks
- multimodal tasks
Gemini 3 Flash is likely to win some of those groups more decisively than others.
3. Re-test your thinking configuration. If your current 2.5 Flash setup depends on thinking_budget, you need a new tuning pass for Gemini 3 Flash's thinking_level. Google's own Vertex AI guidance says users coming from a budget of 0 should start with MINIMAL when they want similar latency and cost behavior.
4. Watch three things, not one. During rollout, track:
- quality delta
- latency delta
- effective cost delta
If you only track benchmark-style quality, you can talk yourself into paying more for an upgrade that your users do not actually notice. If you only track cost, you can miss a meaningful capability gain.
5. Keep a fallback until the cutover is justified. Because Gemini 2.5 Flash still has a fixed shutdown date rather than an immediate removal, you can migrate in a disciplined way. That is a gift. Use it. Keep the stable route alive while you gather evidence, then move the workloads where Gemini 3 Flash clearly wins.
If you want a simple calendar rule, this is the one I would use on March 20, 2026:
- now through April 2026: benchmark Gemini 3 Flash against your current 2.5 Flash routes, especially if you are still using
gemini-flash-latest - April through May 2026: move capability-sensitive workloads first, keep a fallback for cost-sensitive or grounding-heavy routes
- before June 17, 2026: finish the forced migration plan for any remaining pinned
gemini-2.5-flashusage
That timeline is not a Google requirement. It is just the most defensible operating posture given the current official shutdown date and the fact that preview-to-stable behavior can still change.
That is the defensible migration stance on March 20, 2026:
- move first where better reasoning, tool use, and multimodal quality materially help
- wait briefly where lower cost and stability still dominate
- do not wait forever because the replacement path is already official
If rate-limit behavior is part of your migration risk model, our Gemini API rate limits per tier guide covers the surrounding quota structure.
FAQ
Is Gemini 3 Flash better than Gemini 2.5 Flash?
Yes, in the broad capability sense. Google's own DeepMind benchmark table puts Gemini 3 Flash ahead on reasoning, coding, multimodal, agentic, and factuality benchmarks. But "better" is not the full decision because Gemini 3 Flash is also more expensive and still Preview.
Should I migrate from Gemini 2.5 Flash to Gemini 3 Flash right now?
Yes for evaluation and targeted rollout, not necessarily for a blind full cutover. The official deprecations table already names Gemini 3 Flash as the replacement for Gemini 2.5 Flash, so the migration should be active now even if the production default stays on 2.5 Flash for a little longer.
Is Gemini 2.5 Flash still worth using in 2026?
Yes. It is still cheaper, still Stable / GA, and still easier for low-cost grounded prototypes. It is no longer the obvious long-term default, but it is still a rational short-term default for some workloads.
What is the most important migration caveat most pages miss?
The control surface changed. Gemini 2.5 Flash uses thinking_budget, while Gemini 3 Flash uses thinking_level. If your latency and cost envelope depends on that tuning, you need to re-test it instead of assuming equivalent behavior.
If I am starting a new product today, should I choose Gemini 3 Flash or Gemini 2.5 Flash?
Choose Gemini 3 Flash if product quality, coding ability, tool use, and multimodal reasoning matter most. Choose Gemini 2.5 Flash if the main priority is lower-cost stable throughput and cheap grounded experimentation.