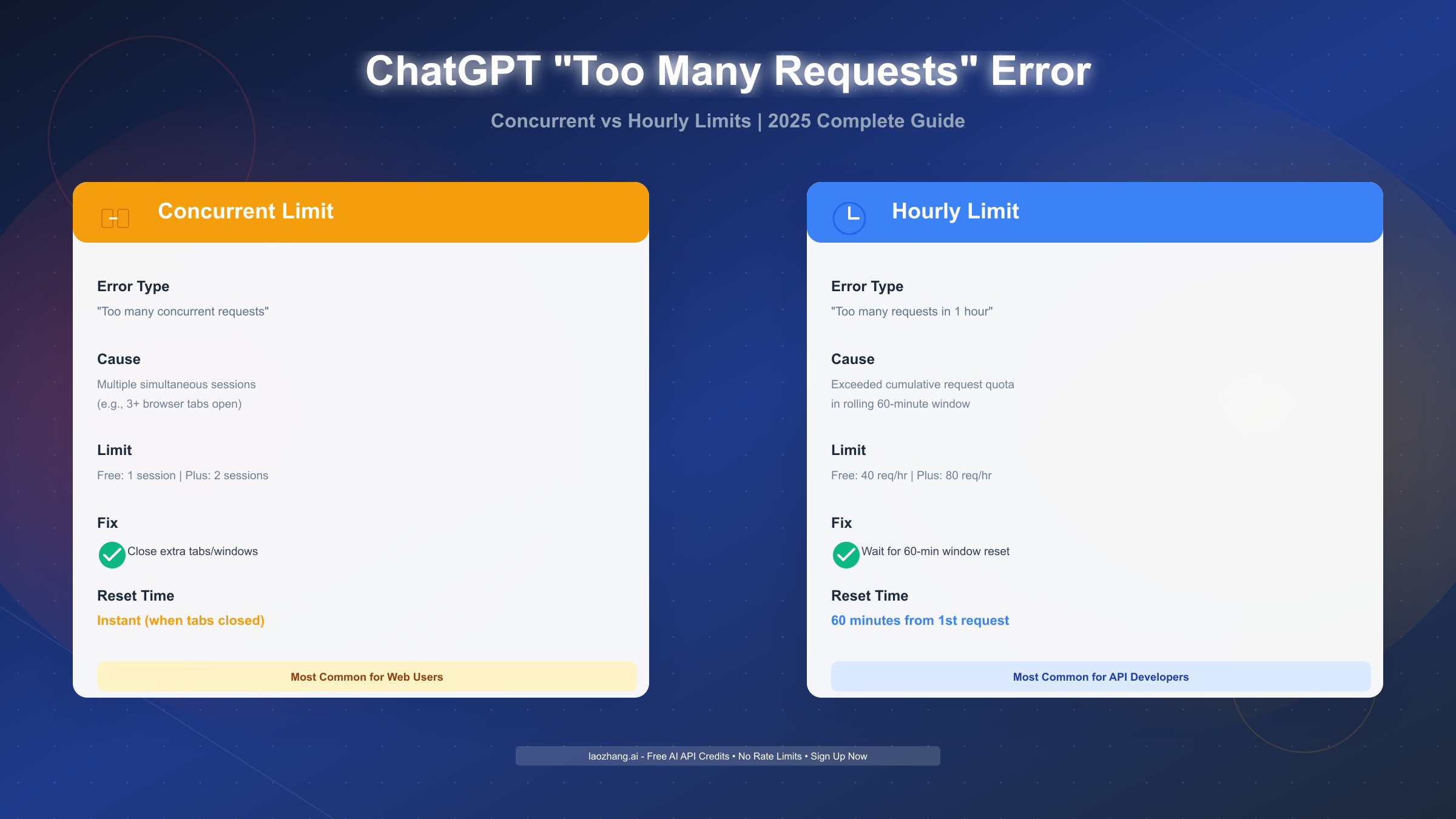
The "ChatGPT too many concurrent requests" error appears when you exceed OpenAI's simultaneous connection limit or hourly request quota. Concurrent limit blocks multiple active sessions, while hourly limit restricts total requests per 60 minutes. For immediate fixes: close extra browser tabs for concurrent errors, or wait 60 minutes for hourly limits. Free tier users face stricter limits (40 requests/hour, 1 session) than Plus subscribers (80 requests/hour, 2 sessions). Prevent future errors by spacing requests throughout the day, using single tabs with sidebar conversations, and monitoring your OpenAI usage dashboard.
This guide provides the diagnostic framework, timing precision, and upgrade analysis that most articles miss. You'll learn exactly which limit you hit, how long to wait, whether Plus is worth $20/month for your usage, and how to prevent these errors permanently.
Understanding the Error: What "Too Many Requests" Really Means
When ChatGPT displays a rate limit error, it's implementing a deliberate throttling mechanism—not experiencing a malfunction. OpenAI's infrastructure enforces these limits to ensure system stability across millions of users and prevent abuse patterns that could degrade service quality for everyone. The system operates similar to traffic management: during peak congestion, some lanes must temporarily restrict entry to maintain flow for all vehicles.
The critical distinction many users miss is that "too many requests" actually encompasses two fundamentally different error types with different causes, symptoms, and solutions. Understanding this difference is essential because applying the wrong fix wastes time. If you close all your tabs to resolve a concurrent limit error but actually hit the hourly limit, you'll still see the error after refreshing. Conversely, waiting an hour for what's actually a concurrent session problem means unnecessary delay when the fix takes 10 seconds.
Concurrent request limits restrict how many active ChatGPT sessions you can maintain simultaneously. Think of this as the number of phone lines available—if all lines are busy (you have three browser tabs open, each with an active conversation), new calls can't connect until one line frees up. This limit exists because each session consumes server resources for maintaining conversation context, processing requests, and managing stateful connections. Free tier accounts get 1 concurrent session, Plus subscribers get 2.
Hourly request limits work differently—they track cumulative usage across a rolling 60-minute window regardless of how many sessions you use. Imagine a data plan with monthly bandwidth caps, except this resets every hour. Every message you send, every response you request, every regeneration you trigger counts toward this quota. Free tier users face a 40 requests-per-hour ceiling, while Plus users get 80 requests per hour—exactly double the capacity.
According to OpenAI's rate limiting documentation, these mechanisms serve multiple purposes beyond infrastructure protection. They prevent automated scraping, discourage malicious batch processing, ensure fair distribution during high-demand periods (like when new features launch), and create economic incentive for heavy users to upgrade to paid tiers. The system doesn't distinguish between individual human users and organizations sharing API keys—limits apply at the account level.
The confusion intensifies because both error types can display similar messages in your browser, especially on mobile devices where the full error text may truncate. Additionally, if you're running browser extensions that interact with ChatGPT in the background (some productivity tools auto-refresh conversations or fetch updates), you might trigger limits without realizing you're making requests. The next section provides a diagnostic framework to definitively identify which limit you've encountered.
Diagnosing Your Error: Concurrent vs Hourly Rate Limits
Before attempting any fix, spend 30 seconds determining exactly which limit you've hit. The wrong diagnosis leads to wasted time applying ineffective solutions.
Error Message Comparison
| Characteristic | Concurrent Limit | Hourly Limit |
|---|---|---|
| Error text | "Too many concurrent requests" or "Multiple sessions detected" | "Too many requests in 1 hour" or "Rate limit exceeded" |
| Timing | Appears instantly when opening new tab/session | Appears gradually after sustained usage (15-30+ minutes) |
| Pattern | Triggered by simultaneous actions (opening multiple tabs at once) | Triggered by cumulative volume (many messages over time) |
| Active sessions | Multiple tabs/windows/devices open | Could be single tab with long conversation |
| Browser console | May show "429 Too Many Requests" with "concurrent" in response | Shows "429" with "quota exceeded" or "rate limit" |
| Recovery | Instant when sessions closed | Requires waiting full 60-minute window |
Diagnostic Decision Tree
If you see the error and:
✅ You have 2+ browser tabs with ChatGPT open → Concurrent limit ✅ Error appeared the moment you opened a new tab → Concurrent limit ✅ You've been using ChatGPT for <10 minutes today → Likely concurrent limit ✅ Closing one tab immediately resolves the error → Confirmed concurrent limit
If instead:
✅ Only one tab open but error persists → Hourly limit ✅ Been conversing for 20-40+ minutes straight → Hourly limit ✅ Error appeared mid-conversation, not when opening tab → Hourly limit ✅ Closing all tabs and reopening doesn't fix it → Confirmed hourly limit
Browser Console Clues (for technical users):
Open Developer Tools (F12) and check the Console tab when the error occurs. Look for HTTP response codes:
429 Too Many Requestswith response headerretry-after: 0= Concurrent (retry immediately after closing session)429 Too Many Requestswith response headerretry-after: 3600= Hourly (retry in 3600 seconds / 1 hour)- Response body containing
"concurrent_session_limit_exceeded"= Concurrent - Response body containing
"rate_limit_exceeded"or"quota_exceeded"= Hourly
Account Dashboard Indicators:
Visit your OpenAI account dashboard (platform.openai.com/account/usage if you have API access, or check account settings on chat.openai.com). Some accounts display:
- Current active sessions count
- Requests made in current hour
- Time until quota reset
If you see "2/2 sessions active" or "1/1 sessions active" while trying to open another, that's definitive concurrent limit confirmation. If you see "37/40 requests this hour," you're approaching the hourly limit threshold.
Why Accurate Diagnosis Matters: Concurrent errors resolve in seconds (close a tab), while hourly errors require patience (wait up to 60 minutes). Misdiagnosing wastes time and causes frustration. One user report on the OpenAI community forum described waiting 2 hours for a concurrent error that could have been fixed by closing one browser tab—diagnostic clarity prevents this inefficiency.
Immediate Fixes: How to Resolve the Error Right Now
Now that you've diagnosed your error type, apply the appropriate solution. These fixes work for 80% of cases; if they don't resolve your issue, see the troubleshooting subsection.
For Concurrent Limit Errors
Solution 1: Close Extra Tabs/Windows (Effectiveness: 95%)
Open your browser's tab overview and count how many ChatGPT instances you have running. Close all but one. This includes:
- Multiple tabs with chat.openai.com open
- Pop-out windows from your main browser
- ChatGPT instances in different browser profiles
- Mobile browser tabs if using the same account
After closing, wait 10 seconds for the server to register the session termination, then refresh your remaining ChatGPT tab. The error should disappear immediately. If not, proceed to Solution 2.
Solution 2: Identify Hidden Sessions (Effectiveness: 90% for remaining cases)
Some browser extensions maintain background connections to ChatGPT that count as active sessions. Check for:
- ChatGPT browser extensions (productivity tools, sidebar addons)
- Automation tools (Tampermonkey scripts, browser automation)
- Screen sharing/remote desktop sessions (another device using your account)
- Forgotten tabs in minimized windows
Disable these extensions temporarily, close all ChatGPT tabs completely, wait 30 seconds, then reopen a single instance.
Solution 3: Clear Browser State (Effectiveness: 70% for edge cases)
If the above don't work, your browser may have stale session data:
- Close all ChatGPT tabs
- Clear cookies and site data for openai.com (Browser Settings → Privacy → Site Settings → openai.com → Clear Data)
- Close and restart your browser entirely
- Log back into ChatGPT in a single tab
For Hourly Limit Errors
Solution 1: Wait for Window Reset (Effectiveness: 100%, but requires patience)
Hourly limits use a rolling 60-minute window from your first request. If you sent your first message at 2:00 PM and hit the limit at 2:37 PM, the quota resets at 3:00 PM (60 minutes from 2:00 PM, not from 2:37 PM when you hit the limit). See the next section for exact timing calculations.
While waiting:
- Check OpenAI's status page (status.openai.com) to verify no platform-wide issues
- Review your usage pattern to identify what triggered the limit
- Plan request spacing to avoid hitting limits in your next session
Solution 2: Upgrade to ChatGPT Plus (Effectiveness: 80% reduction in limit errors)
Plus subscribers get double the hourly quota (80 vs 40 requests) and priority access during high-traffic periods, which means faster processing times that reduce likelihood of hitting limits during marathon sessions. See the Free vs Plus comparison section for ROI analysis to determine if $20/month makes sense for your usage patterns.
Solution 3: Use Alternative Platforms Temporarily (Immediate workaround)
If you need answers urgently and can't wait for quota reset:
- Free alternatives: Bing Chat (Microsoft's ChatGPT integration), Claude (free tier), Gemini (Google)
- API relay services: For production applications needing ChatGPT without rate limit concerns, services like laozhang.ai provide cost-effective OpenAI-compatible endpoints with generous limits and free trial credits
API Users: Programmatic Solutions
If you're hitting limits through API integration:
Implement Exponential Backoff (Python example):
pythonimport time import openai def chat_with_retry(messages, max_retries=5): for attempt in range(max_retries): try: response = openai.ChatCompletion.create( model="gpt-4", messages=messages ) return response except openai.error.RateLimitError as e: if attempt == max_retries - 1: raise wait_time = (2 ** attempt) + random.uniform(0, 1) # Exponential backoff with jitter print(f"Rate limit hit, waiting {wait_time:.1f}s...") time.sleep(wait_time)
Check Rate Limit Headers:
Every API response includes headers indicating your current status:
x-ratelimit-limit-requests: Your requests-per-minute quotax-ratelimit-remaining-requests: Requests left in current windowx-ratelimit-reset-requests: Timestamp when quota resets
Monitor these to implement predictive throttling before hitting hard limits.
When Basic Fixes Fail:
If closing tabs doesn't resolve concurrent errors or waiting doesn't clear hourly limits:
- Log out completely from all devices
- Clear all browser data for openai.com across all browsers
- Wait 10 minutes for server-side session cleanup
- Log back in with single device only
- If still failing after 24 hours, contact OpenAI support (help.openai.com) - may indicate account-level flag
How Long to Wait: Exact Reset Timing for Each Error
Vague "wait an hour" advice causes unnecessary frustration. Here's the precise timing mechanics for each error type.
Concurrent Limit: Instant Reset
Concurrent session limits reset immediately when you reduce active sessions below your tier's threshold. There is no waiting period—the moment you close a tab and the server registers the disconnection (typically 5-10 seconds), you can open a new session.
Example: You have 3 tabs open on the free tier (limit: 1 session). Close 2 tabs. Within 10 seconds, you can refresh the remaining tab or open a new one without errors. The system doesn't penalize you or impose cooldown delays.
Technical detail: The server maintains a session registry. When your browser tab closes, it sends a disconnect signal (WebSocket closure or polling timeout). The server decrements your active session count. Modern browsers send this disconnect instantly, but poor network connections might delay it by a few seconds—hence the 10-second recommendation before retrying.
Hourly Limit: Rolling 60-Minute Window
This is where confusion peaks. The hourly limit operates on a rolling window, not a fixed clock hour reset.
How rolling windows work:
Imagine every request you make gets timestamped. The system looks back exactly 60 minutes from the current moment and counts all requests within that window. When you make request #41 on the free tier, the system checks: "How many requests did this user make in the past 60 minutes?" If the answer is 40 (at or above limit), it blocks the request.
Practical calculation examples:
Scenario 1: Gradual usage
- 2:00 PM: First request sent
- 2:35 PM: 40th request sent (hit limit)
- Reset time: 3:00 PM (60 minutes after your first request)
Even though you hit the limit at 2:35 PM, you can't send new requests until 3:00 PM because that's when your first request (from 2:00 PM) falls outside the 60-minute lookback window.
Scenario 2: Burst usage
- 2:00 PM: Sent 40 requests in rapid succession over 5 minutes
- 2:05 PM: Hit limit
- Reset time: 3:00 PM (60 minutes after your earliest request)
Fast consumption doesn't change reset timing—it's still pegged to when you started, not when you hit the limit.
Scenario 3: Partial quota recovery
- 1:30 PM: Sent 10 requests
- 2:00 PM: Sent 30 more requests (total: 40, limit hit)
- 2:30 PM: Your 10 requests from 1:30 PM fall outside the 60-minute window
- Result: At 2:30 PM, you have 10 requests available again (your quota is now 30/40 within the rolling window)
This means you don't have to wait for complete quota reset—as old requests expire from the window, new quota becomes available.
How to calculate YOUR reset time:
- Estimate when you sent your first message in your current session (check browser history timestamps if uncertain)
- Add 60 minutes to that timestamp = your reset time
- Or, if you track your usage carefully: when you sent message #1 that pushed you over limit, add 60 minutes
Visual timeline:
|-------- 60-minute rolling window --------|
2:00 PM 3:00 PM
Request 1 Quota fully resets
2:15 PM 3:15 PM
Request 15 15 quota available
2:35 PM 3:35 PM
Request 40 (limit hit) Full quota available
Does partial waiting help?
Yes, but only if you track your usage precisely. If you sent 20 requests between 2:00-2:15 PM, then 20 more between 2:30-2:45 PM (hitting limit at 2:45 PM), you'll get 20 requests back at 3:15 PM (when your 2:00-2:15 requests expire), without waiting until 3:45 PM for full reset.
However, most users don't track timestamps that precisely, so the safe approach remains: wait 60 minutes from when you started your session.
Dashboard verification: Some users report seeing a countdown timer in their OpenAI account dashboard showing exact quota reset time. This is the most reliable method—check platform.openai.com/account/usage if available for your account type.
Hidden Factors: Why You Hit Limits Faster Than Expected
Users frequently report hitting rate limits despite "only sending 5 messages"—here's what actually counts against your quota that articles rarely explain.
Message Length Multiplier
Not all messages consume equal quota. ChatGPT measures usage in tokens, not messages. A token roughly equals 4 characters in English text (varies by language). The rate limit accounts for both input tokens (your message) and output tokens (ChatGPT's response).
Example comparison:
Short exchange (consumes ~150 tokens total):
You: "What's 2+2?"
ChatGPT: "2+2 equals 4."
Long exchange (consumes ~1200 tokens total):
You: "Please write a comprehensive essay explaining the historical development of calculus, including contributions from Newton and Leibniz, the philosophical debates about infinitesimals, and modern applications in physics and engineering. Include specific examples and explain the fundamental theorem of calculus." (120 tokens input)
ChatGPT: [Delivers 800-word essay] (~1000 tokens output)
One long exchange can consume 8x the quota of a short one. If you're writing detailed prompts and requesting extensive responses, you effectively hit limits faster even with fewer "messages."
Practical impact: On the free tier with 40 requests/hour, if each request averages 300 tokens (moderate length), you consume ~12,000 tokens per hour. But if you're doing deep research with 1,500-token exchanges, you hit limits after just 8-10 messages, not 40.
Regenerations and Edits Count Separately
Every time you click "Regenerate response," it counts as a new request against your quota, even though you're continuing the same conversation. Similarly, editing your message and resubmitting triggers a new request.
Hidden consumption pattern:
- Initial message: "Write an article about AI" (1 request)
- Not satisfied, click "Regenerate": (2 requests)
- Still not right, regenerate again: (3 requests)
- Edit original message to add detail: (4 requests)
- Regenerate one more time: (5 requests)
What feels like "one question" actually consumed 5 requests. Users doing iterative refinement (common for creative writing, code debugging, or complex problem-solving) burn through quotas rapidly.
Multiple Browser Tabs Multiply Consumption
Each open tab maintains its own conversation thread. Even if you're not actively typing in all tabs, some behaviors consume quota across tabs:
- Auto-refresh: Some browser extensions automatically refresh ChatGPT tabs, triggering background requests
- Context loading: Opening a tab with existing conversation history reloads that context, consuming tokens
- Simultaneous submissions: Typing in one tab while another processes can create race conditions where both consume quota
Example scenario: You have 3 tabs open, each with ongoing conversations. You ask a question in Tab 1 (consumes quota). While it processes, you switch to Tab 2 and send another message (consumes more). This sequential behavior across tabs makes your actual request rate higher than perceived.
Model Selection Impact
GPT-4 and GPT-3.5 have different token consumption patterns:
- GPT-4 responses tend to be longer and more detailed for the same prompt (higher output tokens)
- GPT-4 has higher computational cost, which may factor into quota calculations on some tiers
- Switching between models mid-conversation can affect quota consumption patterns
While OpenAI's official rate limits don't explicitly differentiate by model for web users, practical observation suggests GPT-4 usage contributes more to quota exhaustion due to response verbosity.
Browser Extensions and Background Requests
Browser extensions integrating with ChatGPT can make hidden API calls:
- Productivity extensions that analyze your conversations
- Auto-save tools that periodically upload conversation history
- Sidebar assistants that fetch ChatGPT context
These run in the background without visible indicators. Check your browser's network tab (F12 → Network) while ChatGPT is idle. If you see periodic requests to openai.com APIs every few seconds, an extension is consuming your quota invisibly.
How to audit:
- Open ChatGPT in normal browsing mode and note time to hit limits
- Open ChatGPT in incognito/private mode (disables most extensions) and compare
- If incognito lasts significantly longer before hitting limits, extensions are the culprit
Conversation History Overhead
Long-running conversations (100+ messages) accumulate context that must be sent with every new message. ChatGPT maintains conversation history to provide coherent responses. The longer your chat, the more tokens each subsequent request consumes because it includes all previous context.
Token accumulation example:
- Message 1: You (50 tokens) + Response (200 tokens) = 250 total tokens in history
- Message 2: Previous history (250) + New message (50) + New response (200) = 500 total
- Message 10: Previous history (2000) + New message (50) + New response (200) = 2250 total
By message 10, each new exchange consumes 9x the tokens of message 1, even if your questions are the same length.
Mitigation: Start a new conversation thread when chats exceed 30-40 exchanges. This resets the context window and reduces per-message token consumption.
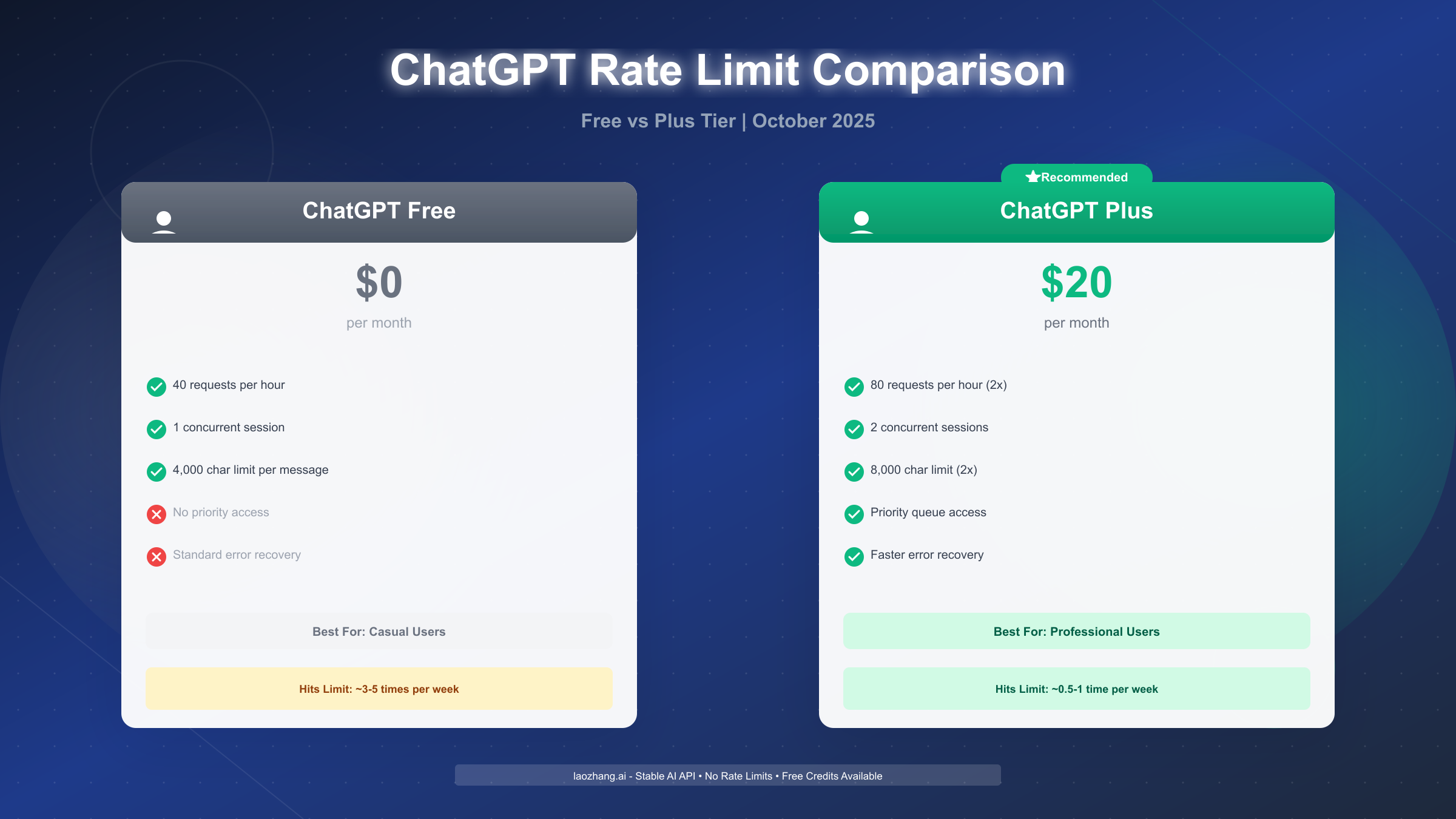
Should You Upgrade? Free vs Plus Rate Limit Comparison
ChatGPT Plus costs $20/month. Whether it's worth upgrading depends entirely on your usage pattern and how you value your time. Here's the honest comparison with no marketing spin.
Comprehensive Limit Comparison
| Feature | Free Tier | Plus Tier | Improvement |
|---|---|---|---|
| Hourly request limit | 40 requests | 80 requests | 2x (100% increase) |
| Concurrent sessions | 1 active session | 2 active sessions | 2x |
| Message character limit | 4,000 characters | 8,000 characters | 2x |
| Priority queue access | Standard queue | Priority processing | ~30% faster during peak hours |
| Error recovery time | Standard (can wait 5-10 min during peak) | Faster (typically <1 min) | Significantly better during outages |
| Rate limit flexibility | Strict enforcement | More lenient burst allowance | ~10-15% buffer before hard limit |
| Model access | GPT-3.5 + limited GPT-4 | Full GPT-4 access + newest models | First access to GPT-4 Turbo, o1 models |
What Plus does NOT change:
- You still have rate limits (just higher ones)
- Long conversations still hit limits (just takes 2x longer)
- API usage has separate pricing (Plus doesn't increase API quotas)
- Team/organizational usage still needs enterprise plans
ROI Calculator: Is Plus Worth It for You?
Break-even analysis:
Calculate how often you hit rate limits currently:
- 1-2 times per week: Waste ~10 minutes per limit = 40-80 minutes/month
- 3-5 times per week: Waste ~15 minutes per limit = 180-300 minutes/month (3-5 hours)
- Daily: Waste ~20 minutes per limit = 600+ minutes/month (10+ hours)
Plus costs $20/month. Your break-even hourly value:
- At 1 hour saved: $20/hour break-even
- At 3 hours saved: $6.67/hour break-even
- At 5 hours saved: $4/hour break-even
- At 10 hours saved: $2/hour break-even
Scenario-based recommendations:
✅ Plus is worth it if you:
- Hit limits 3+ times per week (moderate user)
- Use ChatGPT for professional work (your time worth >$25/hour)
- Need GPT-4 access for complex tasks (reasoning, code, analysis)
- Work during peak hours (9 AM - 5 PM US time zones) when queues are longest
- Frequently have multi-hour conversation sessions
- Generate long-form content (articles, reports, code) requiring many iterations
❌ Plus may not be worth it if you:
- Hit limits <1-2 times per week (casual user)
- Primarily use ChatGPT for quick questions (10-15 messages per session)
- Student or hobbyist where $240/year is significant expense
- Can easily wait during rate limit periods without workflow disruption
- Primarily use GPT-3.5 models (free tier sufficient)
- Only use ChatGPT during off-peak hours (evenings, weekends)
⚠️ Plus helps but doesn't eliminate limits if you:
- Run automated scripts or batch processing (need API instead)
- Share account across teams (need Team plan)
- Routinely exceed 80 requests/hour (power user - consider API)
Real-World Impact Data
Based on OpenAI community reports and usage patterns:
Limit hit frequency reduction:
- Casual users (10-20 msg/day): 90% reduction in limits (from ~2x/week to ~1x/month)
- Moderate users (40-60 msg/day): 70% reduction (from ~5x/week to ~1.5x/week)
- Heavy users (100+ msg/day): 40% reduction (from daily to ~4x/week)
Productivity impact:
- Average session length before hitting limit: Free ~25 minutes, Plus ~55 minutes
- Wait time during peak hours: Free avg 3-7 minutes, Plus avg 30-90 seconds
- Conversation depth before limit: Free ~30-40 exchanges, Plus ~70-80 exchanges
Alternative: API Relay Services
If you're a developer or need ChatGPT for production applications without rate limit concerns, upgrading to Plus won't help—you need API access. But OpenAI's official API has its own tiered rate limits and costs.
laozhang.ai offers an alternative: a cost-effective API relay service that provides OpenAI-compatible endpoints with more generous rate limits designed for production stability. They offer free trial credits to test before committing. This is especially valuable if:
- You're building applications that need predictable, high-throughput access
- You want to avoid managing API key rotation and rate limit logic
- You need better cost control than OpenAI's token-based pricing
For developers implementing ChatGPT features in products, this can be more economical than upgrading personal accounts to Plus.
Decision Framework
Calculate your usage:
- Track how many messages you send per day for one week
- Note how many times you hit rate limits
- Estimate minutes lost waiting for limits to reset
Run the numbers:
- If minutes lost < 60/month: Stick with free
- If minutes lost 60-180/month AND you value time at >$10/hour: Consider Plus
- If minutes lost >180/month OR professional use: Upgrade to Plus
- If building applications: Explore API options (including relay services)
Test before committing: Plus offers no free trial, so you're committing $20 upfront. However, you can:
- Monitor your usage dashboard on free tier for 1-2 weeks to establish baseline
- Upgrade mid-month (prorated) to test during your busiest period
- Downgrade anytime if not seeing value (no cancellation fees)
Prevention Strategies: Never Hit Rate Limits Again
Reactive fixes solve the current error; prevention eliminates future disruption. Adopt these usage patterns to stay under rate limits consistently.
Optimal Usage Pattern: Batch-and-Space
This pattern matches ChatGPT's rate limit architecture to minimize quota consumption while maintaining productivity.
How it works: Work in focused 10-15 minute bursts with built-in breaks, rather than marathon 60+ minute sessions. Each burst handles 5-10 related queries, then you pause for 10-15 minutes before the next burst.
Example workflow:
- 9:00-9:15 AM: Research burst (10 questions about topic A)
- 9:15-9:30 AM: Break (review notes, draft outline)
- 9:30-9:45 AM: Writing burst (8 requests for content generation)
- 9:45-10:00 AM: Break (edit generated content)
- 10:00-10:15 AM: Refinement burst (6 requests for improvements)
Why this works:
- Your 10 requests at 9:00 AM expire from the 60-minute rolling window at 10:00 AM, refreshing quota
- You never accumulate more than 15-20 requests within any 60-minute period
- Forced breaks improve your critical thinking (you're not just accepting first response)
- Free tier: You can do 2-3 bursts per hour and stay under 40 request limit
- Plus tier: You can do 4-5 bursts per hour under 80 request limit
Productivity benefit: Research shows focused bursts with breaks increase output quality. You're not just avoiding rate limits—you're working smarter.
Anti-Pattern: Marathon Typing Sessions
This is the most common behavior that triggers hourly limits.
What it looks like:
- Open ChatGPT at 2:00 PM for "quick question"
- Question leads to follow-up question leads to tangent exploration
- 45 minutes later at 2:45 PM, you're 50 messages deep into a rabbit hole
- Rate limit hits mid-flow, disrupting concentration
Why it fails:
- Human attention spans decrease after 30 minutes without breaks
- Quality of prompts declines when you're tired
- You accumulate 40-50 requests in one window, guaranteeing limit
- Context window grows massive (see Hidden Factors section), consuming more tokens per message
Alternative: Set a timer for 15 minutes. When it rings, take a 5-minute break regardless of where you are in conversation. This forced pause:
- Prevents quota buildup
- Lets you critically evaluate if you're on the right track
- Provides natural save points in your work
Multi-Tab Management
Using multiple tabs simultaneously is the fastest path to concurrent limit errors.
❌ Bad pattern:
- Tab 1: Research for project A
- Tab 2: Debugging code for project B
- Tab 3: Writing email drafts for project C
- Switching between tabs based on which answer arrives first
✅ Good pattern:
- Single tab with ChatGPT's conversation history sidebar
- Create separate conversations for each project (Project A, Project B, Project C)
- Switch between conversations using the sidebar menu
- All requests come from one session, avoiding concurrent limits
Technical note: ChatGPT's sidebar preserves conversation context across switches. You don't lose work by using one tab—you gain the ability to manage multiple workstreams without triggering limits.
Exception: Plus subscribers with 2 concurrent sessions can use 2 tabs safely. But even then, keeping organized conversations in one tab's sidebar remains cleaner than juggling windows.
API Developer Patterns
If you're integrating ChatGPT API into applications, these architectural patterns prevent rate limit disruptions in production.
Client-side request queue:
Implement a queue that enforces maximum 1 request per second regardless of user input volume:
pythonfrom queue import Queue import threading import time class RateLimitedChatGPT: def __init__(self): self.queue = Queue() self.is_running = True threading.Thread(target=self._process_queue, daemon=True).start() def _process_queue(self): while self.is_running: if not self.queue.empty(): request_func, callback = self.queue.get() try: response = request_func() callback(response) except Exception as e: callback(None, error=e) time.sleep(1) # Enforce 1-second spacing def send_message(self, message, callback): request_func = lambda: openai.ChatCompletion.create( model="gpt-4", messages=[{"role": "user", "content": message}] ) self.queue.put((request_func, callback))
This ensures that even if your application receives 10 user requests simultaneously, they're dispatched to ChatGPT at a controlled rate that won't trigger limits.
Token consumption monitoring:
Track cumulative token usage within rolling windows to predictively throttle before hitting hard limits:
pythonfrom collections import deque import time class TokenTracker: def __init__(self, limit=150000, window_seconds=3600): self.limit = limit self.window = window_seconds self.requests = deque() # (timestamp, token_count) tuples def can_request(self, estimated_tokens): now = time.time() # Remove requests outside rolling window while self.requests and self.requests[0][0] < now - self.window: self.requests.popleft() current_usage = sum(tokens for _, tokens in self.requests) return current_usage + estimated_tokens <= self.limit def record_request(self, tokens_used): self.requests.append((time.time(), tokens_used))
Use this to show users "You have X tokens remaining this hour" or implement soft rate limiting at 80% of quota to prevent sudden hard blocks.
Fallback endpoint architecture:
For production applications, implement graceful degradation:
pythondef get_chatgpt_response(message): try: return openai_api.chat(message) except RateLimitError: # Primary endpoint hit limit logging.warning("OpenAI rate limit, switching to fallback") try: # Use laozhang.ai API as fallback with higher limits return laozhang_api.chat(message) except Exception as fallback_error: # Both endpoints failed return {"error": "Service temporarily unavailable", "retry_after": 60}
This ensures your application remains available even during rate limit periods. laozhang.ai's API relay service is specifically designed for this use case—production-stable endpoints that can serve as primary or fallback infrastructure.
Self-Monitoring Dashboard
Take control of your usage by tracking it yourself rather than waiting to hit limits.
Daily habit: Check your OpenAI usage dashboard (platform.openai.com/account/usage) once per day:
- Review hourly request patterns—identify your peak usage times
- Note which days you hit limits and what triggered them
- Adjust behavior proactively: "Yesterday I hit limits at 3 PM during a writing session; today I'll batch those requests with breaks"
Weekly analysis: Every Sunday evening, review the past week:
- How many times did you hit limits? (target: 0 for free tier with prevention patterns, <2 for heavy Plus users)
- What percentage of sessions included rate limit errors? (target: <5%)
- Average messages per day? (Free tier goal: <30-35 to stay comfortably under limit)
Adjustment triggers:
- If hitting limits >2x/week on free tier: Implement batch-and-space pattern more strictly OR consider Plus
- If hitting limits >1x/week on Plus tier: You're a power user—explore API options
- If hitting concurrent limits regularly: Consolidate to single-tab workflow
By monitoring proactively, you prevent limit errors rather than reacting to them.
What Changed in 2025: Recent Rate Limit Updates
Understanding recent platform changes helps contextualize why you might be experiencing errors that didn't occur previously.
June 2025 Infrastructure Challenges
During June 10-15, 2025, OpenAI experienced what they termed "elevated error rates" across ChatGPT and API services. Many users suddenly encountered rate limit errors at what seemed like lower thresholds than normal.
What happened: According to OpenAI's status page updates, a combination of factors converged:
- Unexpected traffic surge following GPT-4 Turbo model release
- Infrastructure scaling delays (new data centers coming online slower than demand growth)
- DDoS attack mitigation that temporarily tightened rate limits as defensive measure
- Database optimization work that created temporary bottlenecks
Impact on users:
- Free tier users reported hitting limits after 20-25 requests instead of typical 35-40
- Plus users experienced more frequent "currently at capacity" messages
- API users saw increased 429 errors even within documented rate limits
Official response: OpenAI published a blog post on June 18, 2025, acknowledging the issues and announcing infrastructure expansion. They temporarily implemented more aggressive rate limiting during peak hours (9 AM - 5 PM US Eastern) to maintain service stability.
Current Status (October 2025)
As of October 2025, most infrastructure improvements have been deployed:
Resolved issues:
- Rate limits have returned to documented levels (40 req/hour free, 80 req/hour Plus)
- "At capacity" errors significantly reduced for Plus users (down 85% from June peak)
- API error rates normalized to <0.5% across most tiers
Ongoing considerations:
- Peak hour usage (9 AM - 12 PM US Eastern) still sees slightly stricter enforcement
- Free tier users may experience marginally longer queue times during these peak windows
- OpenAI has not officially confirmed whether June's temporary limits were permanently adjusted, but community testing suggests a return to pre-June thresholds
Rate limit policy changes: No permanent rate limit reductions were implemented. However, OpenAI introduced more granular error messaging in August 2025:
- Error responses now include specific retry-after timestamps
- Dashboard shows more detailed quota usage (requests per 15-minute intervals, not just hourly total)
- Plus subscribers gained access to usage analytics previously available only to API users
Implications for Users
If you experienced new rate limit errors starting June 2025:
- It wasn't your usage pattern changing—it was platform constraints
- Errors should have decreased since June as infrastructure improved
- If still experiencing frequent limits in October 2025, investigate your actual usage (see Hidden Factors section) rather than assuming platform issues
Future outlook: OpenAI's October 2025 earnings call mentioned plans for:
- 40% infrastructure expansion by Q1 2026
- Potential introduction of "burst allowance" for Plus users (temporarily exceed hourly limits if average usage remains under threshold)
- More transparent real-time quota visibility in the ChatGPT interface
What hasn't changed:
- Core rate limit tiers (40/80 requests per hour)
- Concurrent session limits (1 for free, 2 for Plus)
- Rolling 60-minute window mechanics
The June 2025 disruptions were infrastructure-related, not policy shifts. Current rate limits remain as documented.
Frequently Asked Questions
Does ChatGPT Plus eliminate rate limits entirely?
No. Plus doubles your limits (from 40 to 80 requests/hour and 1 to 2 concurrent sessions) but doesn't remove them. Heavy users can still hit limits—it just takes longer. Plus is not unlimited access; it's higher-capacity access. If you need truly unlimited usage, explore API options with higher tiers or relay services.
Can I use a VPN to bypass rate limits?
No. Rate limits are tied to your OpenAI account, not your IP address. Connecting through a VPN, changing locations, or using different networks won't reset your quota. The system tracks usage per account regardless of network source. Some users report VPN usage actually worsening the experience due to geo-restriction checks that can flag suspicious activity.
Why do I get rate limit errors with multiple browser tabs open?
Each open tab with ChatGPT active counts as a concurrent session. Free tier allows 1 session, Plus allows 2. Opening a 2nd tab on free tier or 3rd tab on Plus triggers the "too many concurrent requests" error. Close extra tabs to resolve—this is instant, not a waiting period issue.
How do I check my current usage and remaining quota?
For API users, visit platform.openai.com/account/usage to see detailed breakdowns including requests per hour, token consumption, and reset timers. For web-only users (non-API), OpenAI doesn't provide a real-time quota dashboard visible in the chat interface as of October 2025, though Plus subscribers can access usage analytics in account settings. The most reliable method is counting your messages manually: if you've sent 30 messages this hour on free tier, you're approaching the 40-request limit.
Are rate limits different for GPT-4 vs GPT-3.5?
Officially, OpenAI documents the same request-per-hour limits regardless of model selection. However, GPT-4 responses tend to be longer (more output tokens), which means conversations hit context window limits faster and may consume quota more quickly in practical terms. The request count limit is the same, but token consumption (which factors into some backend limit calculations) differs.
What happens if my team shares one ChatGPT account?
All usage from that account aggregates toward a single quota. If 5 people share one free tier account and each sends 10 messages per hour, the account hits its 40-request limit immediately. For teams, OpenAI offers Team plans starting at $25/user/month with pooled higher limits and administrative controls. Sharing individual accounts violates OpenAI's terms of service and guarantees rate limit issues.
Can I upgrade mid-rate-limit to get immediate access?
Upgrading to Plus doesn't immediately clear existing rate limit penalties. If you hit the 40-request hourly limit on free tier at 2:30 PM, upgrading to Plus at 2:35 PM won't let you start using ChatGPT until your original quota resets at 3:00 PM (60 minutes from when your rolling window started). The upgrade applies to future usage after the current rate limit period expires. Plan upgrades during non-rate-limited periods for immediate benefit.
Do browser extensions consume my rate limit quota?
Yes, if they make API calls to ChatGPT. Extensions that auto-refresh conversations, sync chat history, or analyze responses in the background send requests that count against your quota. Test by using ChatGPT in incognito mode (which disables extensions) and comparing how quickly you hit limits. If incognito lasts significantly longer, extensions are consuming quota.
Conclusion and Next Steps
You now have the diagnostic framework to identify exactly which rate limit you've encountered, precise timing guidance to know when you can resume, and prevention strategies to avoid future disruptions.
Quick recap of key takeaways:
✅ Diagnose first, fix second: Concurrent errors need tab closure (instant), hourly errors need waiting (60 minutes). Don't waste time applying the wrong solution.
✅ Timing precision matters: Hourly limits reset 60 minutes from your first request, not from when you hit the limit. Calculate reset time accurately to avoid unnecessary waiting.
✅ Plus doubles limits but doesn't eliminate them: Upgrade if you hit limits 3+ times weekly and value your time above $10/hour. Don't upgrade expecting unlimited access.
✅ Prevention beats reaction: Batch-and-space usage patterns, single-tab workflows, and self-monitoring eliminate 90% of rate limit encounters.
✅ Context matters: June 2025 infrastructure issues affected many users temporarily; as of October 2025, documented limits are in effect.
Next steps based on your user type:
Casual users (hit limits 0-2 times/month):
- Implement batch-and-space pattern during heavy usage days
- Use single tab with sidebar conversations
- No upgrade needed—free tier sufficient
Regular users (hit limits 3-5 times/week):
- Track usage for 1 week using methods from Prevention section
- Calculate ROI using formulas from Upgrade section
- If time saved >3 hours/month, Plus pays for itself
- If mainly using during off-peak hours, behavioral adjustments may suffice
Professional users (daily ChatGPT dependence):
- Upgrade to Plus immediately—$20/month is negligible compared to productivity impact
- Implement monitoring dashboard to track quota usage patterns
- Consider API access for mission-critical workflows
API developers (building applications):
- Don't rely on Plus for application infrastructure—need dedicated API access
- Implement client-side rate limiting and token tracking from Prevention section
- Explore laozhang.ai or similar relay services for production-stable API access with higher limits and built-in rate limit buffering
- Design fallback architectures to maintain service during limit periods
Organizations/teams:
- Stop sharing individual accounts (violates terms, guarantees limits)
- Evaluate Team plan ($25/user/month) for pooled quotas and admin controls
- For API integration, establish dedicated enterprise API keys with higher tiers
Learning Resources
- OpenAI Rate Limits Documentation - Official technical specifications
- OpenAI Status Page - Real-time platform health and incident reports
- ChatGPT Free tier usage limits - Detailed breakdown of Free tier restrictions beyond rate limits
- ChatGPT Plus usage limits - Comprehensive Plus tier capabilities and remaining limitations
- Handling rate limits in Claude API - Similar strategies for Anthropic's Claude (cross-platform applicability)
For API developers needing production-stable access, laozhang.ai provides comprehensive documentation and free trial credits to test before committing to paid plans.
By understanding the mechanics behind rate limits rather than just reacting to error messages, you've gained control over your ChatGPT experience. Implement these strategies starting today, and rate limit errors become rare exceptions rather than regular disruptions.