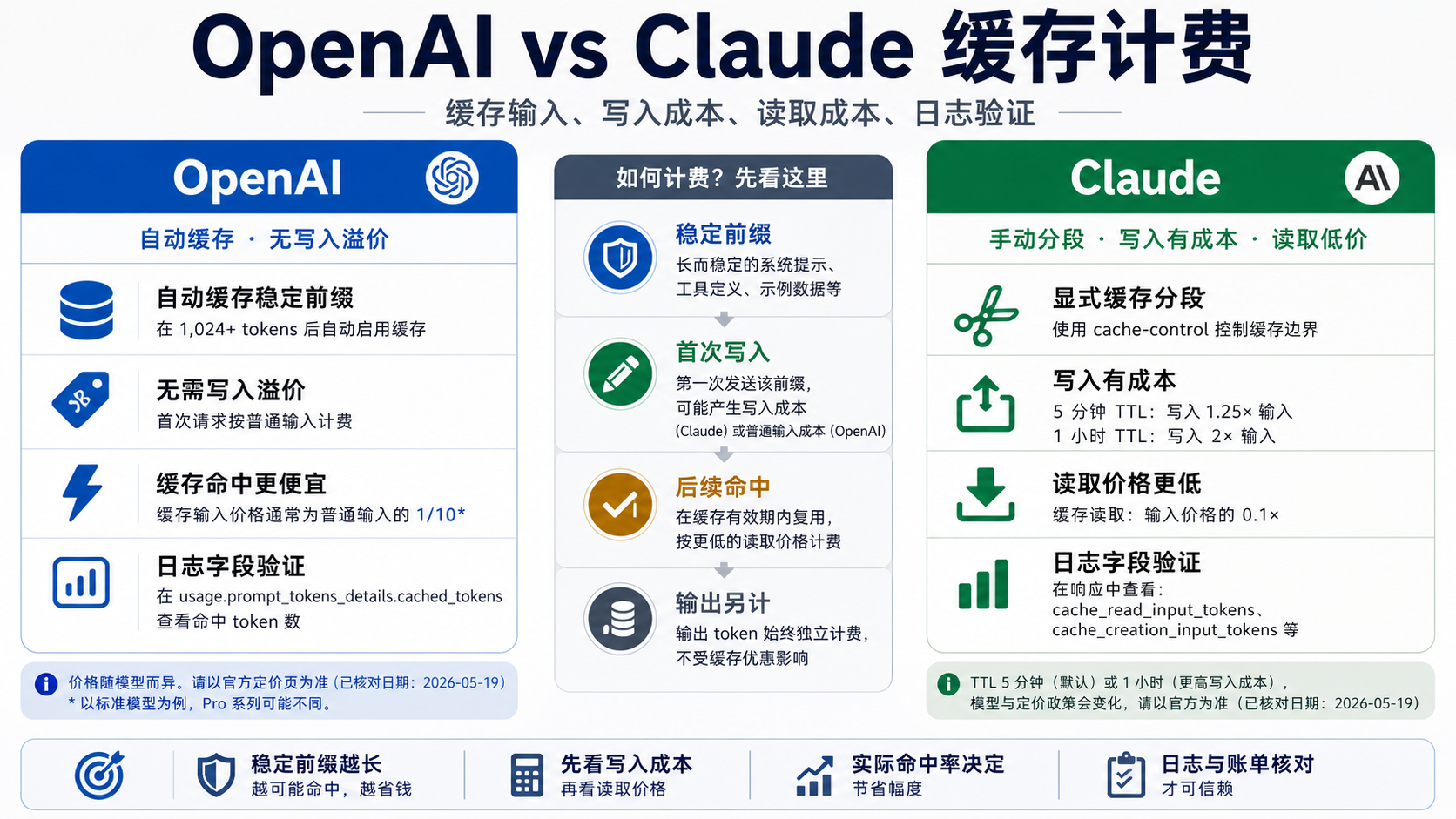
OpenAI 和 Claude 都能让重复的长前缀变便宜,但它们不是同一种账单。按 2026-05-19 检查到的官方价格和文档,OpenAI 当前 GPT-5.5、GPT-5.4、GPT-5.4 mini 的标准价格行把 cached input 计为普通输入的十分之一,并且没有单独的“写入缓存”溢价;Claude 的缓存读取同样是基础输入价的 0.1 倍,但第一次创建缓存要先付写入成本:5 分钟缓存是 1.25 倍基础输入,1 小时缓存是 2 倍基础输入。
所以决策不能只问“谁折扣更高”。如果你的系统提示、工具定义、产品目录、检索上下文或代码库摘要会稳定复用,OpenAI 更像自动命中的低摩擦折扣;Claude 更像可显式控制缓存边界和 TTL 的工程工具。真正该先做的是把账单拆成普通输入、缓存写入、缓存读取、缓存输入、缓存未命中和输出 token,然后在日志里确认 OpenAI 的 usage.prompt_tokens_details.cached_tokens,或 Claude 的 cache_read_input_tokens、cache_creation_input_tokens 和 input_tokens。
| 场景 | 更先看哪边 | 原因 | 必须验证 |
|---|---|---|---|
| 长系统提示每轮都一样 | OpenAI | 自动缓存、无写入溢价,命中后 cached input 更低 | cached_tokens > 0 |
| 需要固定工具、系统提示、消息层级缓存边界 | Claude | 可以显式控制 cache breakpoint 和 TTL | cache_creation_input_tokens 与 cache_read_input_tokens |
| 只有一两次重复请求 | 都不该高估 | 写入、命中或输出成本可能吃掉节省 | 命中率、重复次数、输出占比 |
| 提示经常插入动态内容 | 先改布局 | 前缀不稳定会导致 miss | prefix hash 与请求形状 |
| 使用 Batch、长上下文或云市场 | 单独复核 | 基础价格表不能覆盖所有修饰项 | 当前官方价格页 |
先给结论:谁更便宜取决于复用方式
如果你的重复前缀足够长、足够稳定,而且请求会在缓存有效窗口内连续出现,OpenAI 的优势是简单:近期支持的模型会自动尝试缓存,提示词达到 1024 tokens 以上才有资格命中,第一次未命中按普通输入计费,后续命中按该模型的 cached input 价格行计费。对很多“同一个系统提示 + 不同用户问题”的 API 服务来说,这种模型意味着你可以先改日志,再逐步优化前缀,而不必先重写整套请求格式。
Claude 的优势不是“更省”这个单一结论,而是控制更明确。你可以通过自动的顶层 cache control 或显式的块级 cache control 来告诉系统哪些部分应该形成缓存;默认 5 分钟 TTL 适合短窗口内的会话和 agent 步骤,1 小时 TTL 适合预热后的多请求复用。代价是第一次写入不是普通输入价格:5 分钟写入是 1.25 倍,1 小时写入是 2 倍。只有后续读取足够多,写入溢价才会被摊薄。
这也解释了为什么“缓存降 50%”或“缓存降 90%”这类短说法不够用。50% 多来自旧模型时期或旧文章,不能直接套到当前 OpenAI 价格行;90% 只描述命中读取或 cached input 的折扣部分,也不能覆盖首次请求、未命中和输出 token。预算时要用“这轮请求落入哪个桶”来算,而不是用一个宣传数字覆盖全部请求。
计费词先拆清楚
缓存计费最容易误判的地方,是把 OpenAI 的 cached input 和 Claude 的 cache read 当成同一种东西,再把 Claude 的 cache write 忽略掉。OpenAI 的 cached input 是命中后的输入 token 价格行;Claude 的缓存计费至少有两个额外桶:创建或刷新缓存时的 cache write,以及命中后读取缓存的 cache read。两者都还会同时产生普通输入 token 和输出 token,所以请求总价不是一个折扣乘法。
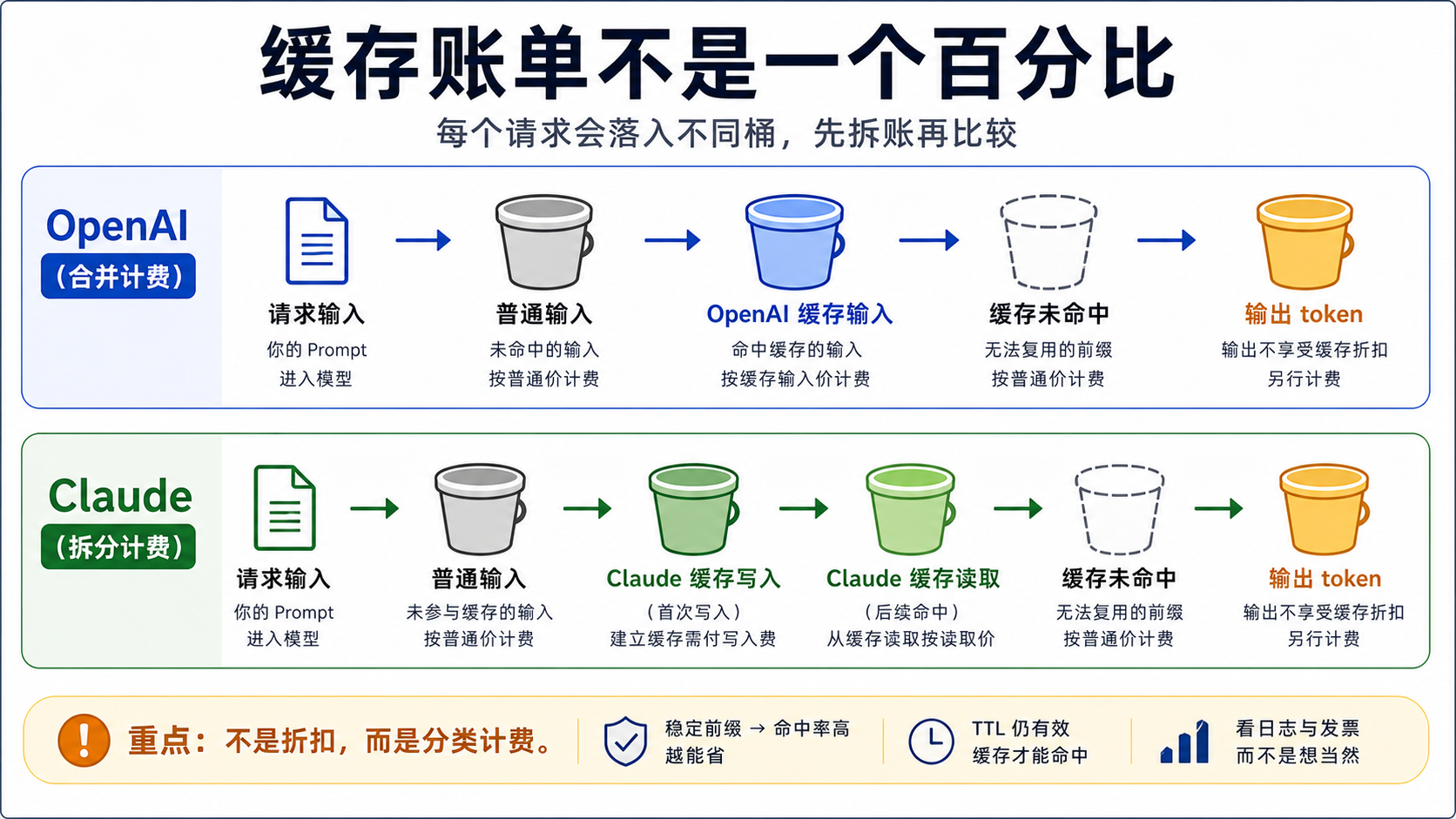
| 账单桶 | OpenAI | Claude | 预算含义 |
|---|---|---|---|
| 普通输入 | 未缓存或不合资格部分 | 新输入、未缓存部分 | 每次都可能存在 |
| 缓存写入 | 没有单独写入溢价 | 5 分钟 1.25x,1 小时 2x | Claude 首次成本必须算入 |
| 缓存读取 | cached input 价格行 | cache read 0.1x 基础输入 | 命中后才出现 |
| 缓存未命中 | 回到普通输入 | 回到普通输入或重新写入 | 动态前缀会放大成本 |
| 输出 token | 不受 prompt cache 折扣影响 | 不受 prompt cache 折扣影响 | 长输出会稀释节省比例 |
这个拆法会改变工程优先级。你不是先问“这家便宜几成”,而是先问“我的稳定前缀是不是足够长、是不是放在请求开头、是不是在 TTL 内重复、是不是被日志证明命中”。只有这些问题成立,缓存价格才会进入账单。
当前价格行怎么用
本文只把价格当作 2026-05-19 的快照使用。OpenAI 当前价格页显示,GPT-5.5 标准短上下文价格行为每百万 token 输入 5 美元、cached input 0.50 美元、输出 30 美元;GPT-5.4 为 2.50 / 0.25 / 15 美元;GPT-5.4 mini 为 0.75 / 0.075 / 4.50 美元。重点不是记住这些数字,而是记住 cached input 行是普通输入的十分之一,并且当前标准行没有额外写入溢价。Pro 行是否支持 cached input 要单独看当前价格表,不能从标准模型推导。
Claude 当前价格页把缓存写入和缓存读取列出来。Opus 4.7、4.6、4.5 的基础输入是每百万 token 5 美元,5 分钟写入 6.25 美元,1 小时写入 10 美元,读取 0.50 美元,输出 25 美元;Sonnet 4.6、4.5 是 3 / 3.75 / 6 / 0.30 / 15 美元;Haiku 4.5 是 1 / 1.25 / 2 / 0.10 / 5 美元。Claude 的价格表让“写入”这件事显性化,因此它更适合你主动设计缓存段,而不是盲目期待自动命中。
价格还受 Batch、Scale Tier、长上下文、数据驻留、云市场和限速策略影响。正文里的数字适合解释基础数学,不适合替代你上线前的最终报价核对。只要文章或系统要写入具体金额,就应该保留检查日期。
一个重复前缀的回本例子
假设你有 100k tokens 的稳定前缀,后面跟着较短的用户问题。你连续跑 10 次请求,并且输出 token 暂时先单独排除。OpenAI GPT-5.4 的普通输入价是 2.50 美元/百万 token,cached input 是 0.25 美元/百万 token。第一次没有命中时,100k 前缀大约按普通输入计 0.25 美元;后面 9 次命中,每次 100k cached input 约 0.025 美元,9 次约 0.225 美元。10 次重复前缀输入合计约 0.475 美元,再加上每次的新输入和输出。
Claude Sonnet 4.6 的基础输入价是 3 美元/百万 token,5 分钟写入是 3.75 美元/百万 token,读取是 0.30 美元/百万 token。第一次为 100k 前缀创建 5 分钟缓存大约是 0.375 美元;后面 9 次命中读取约 0.03 美元一次,9 次约 0.27 美元。10 次合计约 0.645 美元,再加普通输入和输出。如果使用 1 小时 TTL,首次写入会更贵,但跨更长窗口的复用可能更稳。
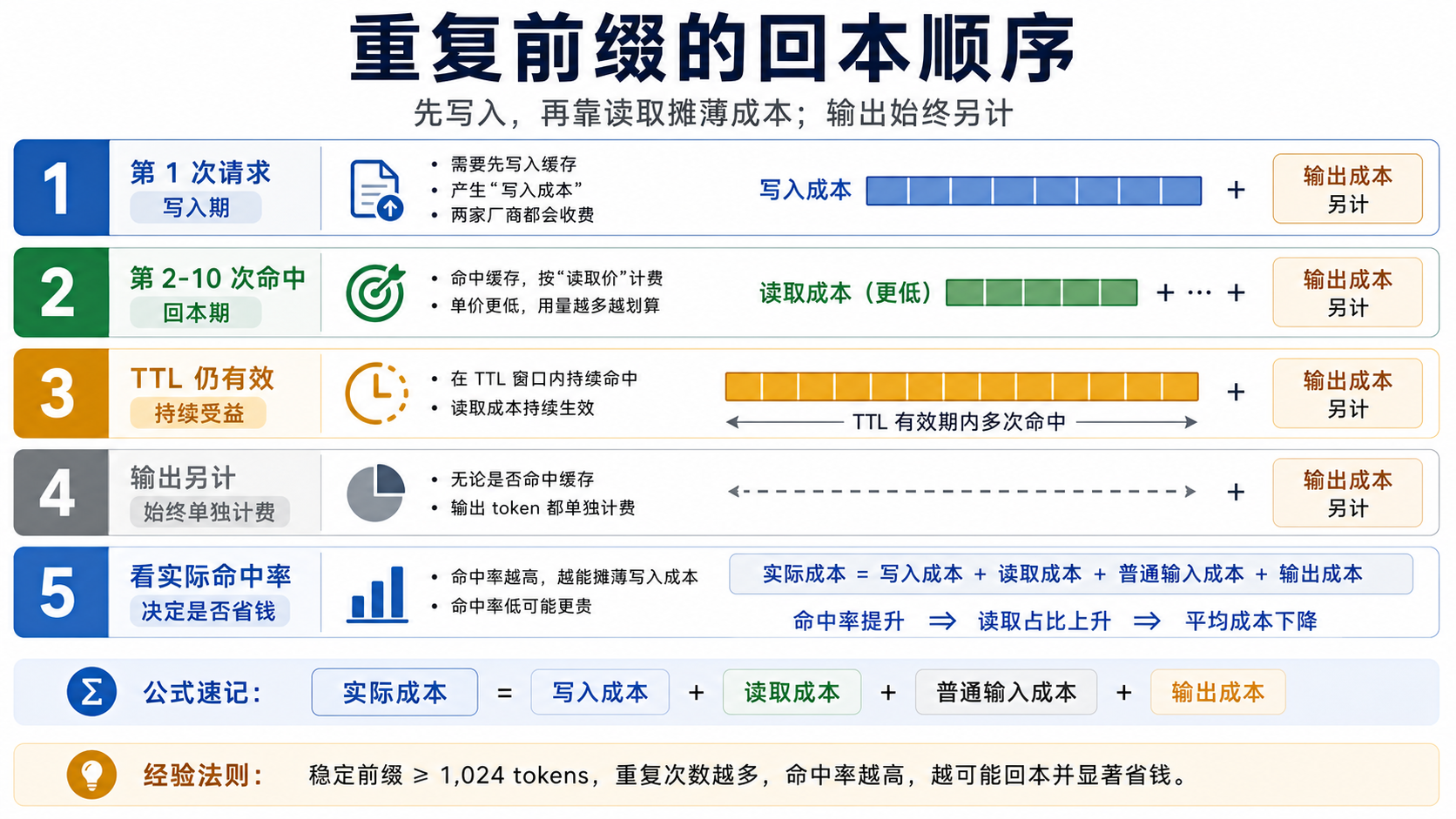
这个例子只说明账单结构,不说明所有工作负载都选择 OpenAI。Claude 的显式边界可能让复杂 agent、长工具定义和多段上下文更可控;OpenAI 的自动缓存可能让高并发稳定前缀更容易先吃到折扣。最终要把命中率、TTL 内重复次数、输出占比和未命中成本放进同一张表。
提示布局决定能不能命中
缓存不是语义相似就会便宜。OpenAI 的规则依赖重复前缀,稳定内容要尽量放在请求前面:系统提示、工具定义、静态政策、长文档摘要、产品目录、few-shot 示例都应该在动态用户输入之前。如果你每次在开头插入时间戳、随机追踪 ID、用户昵称或会变的检索片段,前缀就会变动,命中会下降。prompt_cache_key 可以帮助常见前缀的路由和命中率,但高流量同前缀也可能被分散到更多机器,仍要看实际 cached_tokens。
Claude 的布局更像显式合约。它按 tools、system、messages 的层级和 cache breakpoint 来理解前缀,前面的层级变化会影响后面的缓存段。如果你把高频变化内容放进工具定义或系统提示,后面再精细设置 breakpoint 也会被破坏。Claude 的好处是你能把“稳定的大块”和“每轮变化的小块”分开设计,坏处是工程纪律不够时会频繁写入、刷新或未命中。
上线前可以做一个最小验证:为稳定前缀生成 hash,记录模型、请求路径、endpoint、工具版本、系统提示版本和用户动态内容位置。只要 hash 变了,缓存命中预期就要重新计算。只要模型或价格行变了,成本表也要重新核对。
日志字段比体感更可信
不要用“我重复发了同一段话”来判断缓存已经省钱。OpenAI 要看响应里的 usage.prompt_tokens_details.cached_tokens。如果请求低于 1024 tokens,或前缀没有匹配,通常会看到 cached tokens 为 0。你还应该同时记录总输入、输出、模型名、请求时间、前缀 hash 和是否使用了 prompt_cache_key,否则账单异常时很难回放。
Claude 要同时看 cache_read_input_tokens、cache_creation_input_tokens 和 input_tokens。cache_creation_input_tokens 说明本次产生了写入成本,cache_read_input_tokens 说明本次从缓存读取了输入,input_tokens 则提醒你仍然有普通新输入。把三个字段合起来,才能知道某次请求是 hit、write、miss,还是同时包含多个桶。
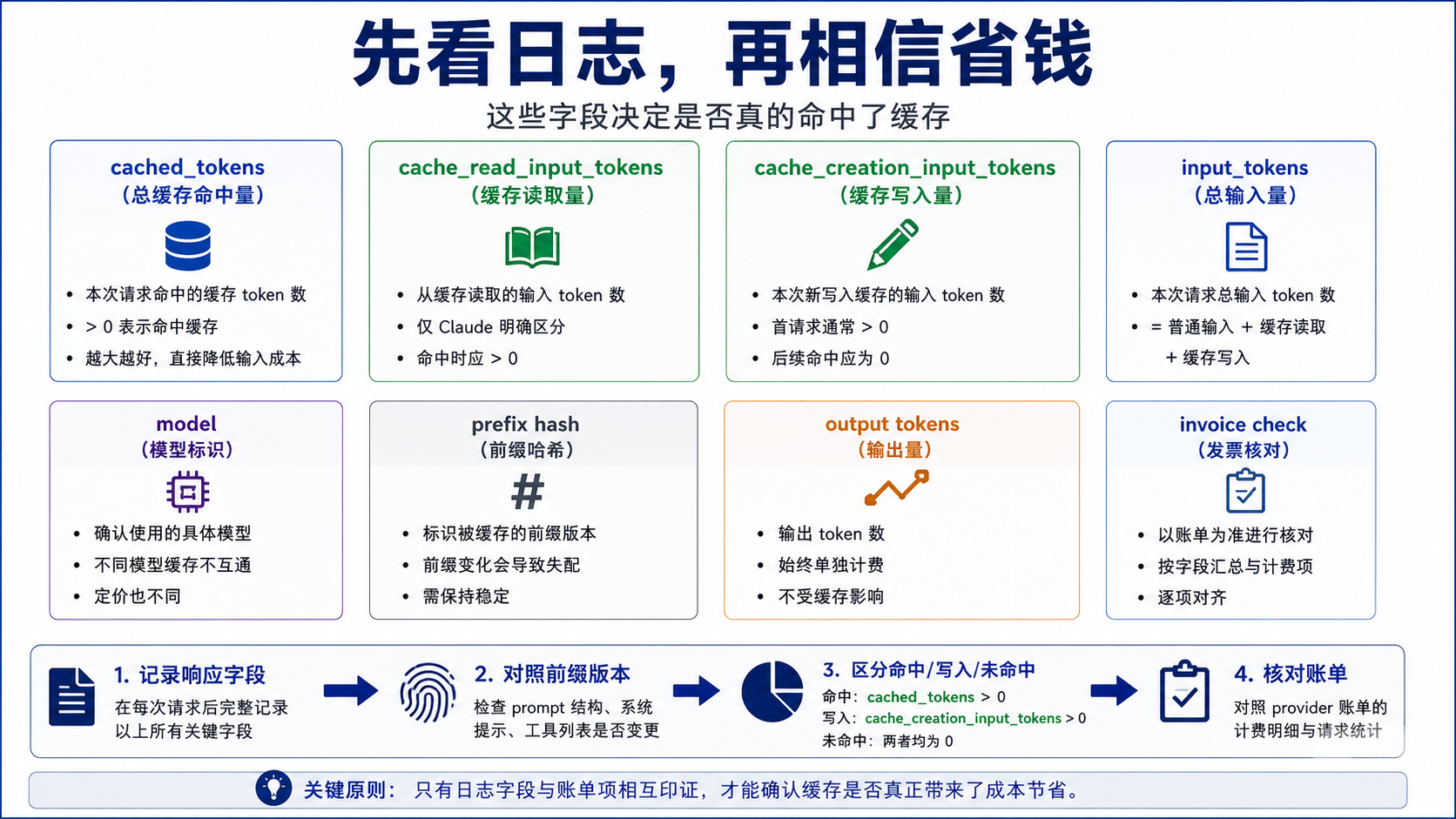
一个实用的日志表至少包含这些列:provider、model、request_id、endpoint、prefix_hash、prompt_cache_key 或 cache breakpoint、input_tokens、cached_tokens、cache_creation_input_tokens、cache_read_input_tokens、output_tokens、invoice_period、estimated_cost、actual_invoice_cost。先用 24 小时小样本看命中率,再决定是否为了缓存重构提示布局。
价格修饰项要单独放一层
很多团队的预算错误来自把基础价格套到所有入口。Batch API 可能改变单价,但也改变延迟和作业形态;长上下文价格行可能不同;云市场、数据驻留和企业协议可能有独立价格;Claude 的 1 小时缓存可以改善某些长窗口复用,但写入价格更高;OpenAI 的扩展保留策略也要看支持模型和当前文档。把这些修饰项混进基础回本例子,会让文章看起来简单,却让上线预算失真。
限速也不能混为一谈。OpenAI 文档说明 cached tokens 仍然计入 TPM,因此“省输入钱”不等于“释放全部吞吐”。Anthropic 文档在 1 小时缓存讨论里给出了不同的 rate limit 影响描述。对生产系统来说,成本表旁边应该还有一张容量表:每分钟请求数、输入 token、缓存读取 token、输出 token、重试量和失败率。
什么时候选 OpenAI
优先考虑 OpenAI 的典型场景,是你有稳定长前缀、希望低改造成本地获得缓存折扣,并且不需要人工控制多个缓存段。客服机器人、固定政策问答、长系统提示的工具调用、相同 schema 的批量分析,都可能符合这个模式。你要做的工程动作是把稳定内容固定在前面,减少前缀噪声,记录 cached_tokens,并按模型价格行估算。
不该把 OpenAI 缓存理解成“所有重复内容都自动便宜”。低于资格阈值、前缀顺序变化、模型不支持、请求分散、动态内容插入过早,都会让 cached input 不出现。还有一个常见误区:输出 token 如果很长,输入缓存节省会被输出成本稀释。生成长报告、长代码或长推理时,输出预算仍然要单独控制。
什么时候选 Claude
优先考虑 Claude 的场景,是你愿意为缓存边界和 TTL 付出工程纪律。长工具定义、多阶段 agent、代码库摘要、固定系统指令、多段上下文复用、需要预热的工作流,都可能从 Claude 的 cache control 中受益。你可以明确哪些部分应该缓存、缓存多久、什么时候刷新,也可以把写入和读取分别计入指标。
Claude 的风险也来自显式控制:写入成本一定要先算,TTL 过短会导致重复写入,1 小时 TTL 写入更贵,层级前面的变化会让后面的缓存段失效。如果你的请求变化大、重复次数少,或者团队没有记录 cache_creation_input_tokens 和 cache_read_input_tokens,Claude 的“可控”会变成“误以为省钱”。
实施检查清单
- 把稳定内容移到请求前缀:系统提示、工具、示例、固定上下文在前,用户动态内容在后。
- 为前缀生成稳定 hash:任何版本变动都要能解释命中率变化。
- 分别记录 OpenAI 和 Claude 的 usage 字段,不要只记录总 token。
- 用同一模型、同一路径、同一前缀做小样本压测,至少覆盖首次请求和后续命中。
- 把输出 token 单独列账,避免把输入缓存节省误当成整单节省。
- 每次价格页、模型名、TTL 或云平台入口变化后,重新跑一遍回本表。
- 在账单周期结束后,用发票明细对照日志估算;如果差距大,先查 miss、write、模型路由和价格修饰项。
这套检查清单比“打开缓存”更重要。缓存本身只是一个价格机制,真正的成本优化来自稳定前缀、可复现请求、可解释日志和可复核账单。
与相邻主题的边界
如果你要比较 OpenAI、Claude、Gemini 的整体 API 成本,可以先看多提供商 API 成本对比。那类页面应该处理模型价格、输出成本、吞吐和任务选择。本文只处理 prompt caching 计费,不评价模型质量,也不把缓存价格当成总拥有成本。
如果你要写 Claude 具体代码,需要再看 cache control、breakpoint、SDK 形状和错误处理。本文只解释为什么 Claude 的写入和读取要分开算,以及这些字段如何进入预算。把实现细节和账单边界分开,反而更容易定位问题:命不中是布局问题,写入太多是 TTL 或边界问题,账单偏高可能是输出或特殊价格问题。
常见问题
OpenAI prompt caching 现在还是 50% 折扣吗?
不能这样概括。旧发布和旧文章常用 50% 描述 GPT-4o 或 o1 时代的缓存输入价格,但 2026-05-19 检查到的当前 OpenAI 标准 GPT-5.5、GPT-5.4、GPT-5.4 mini 价格行把 cached input 列为普通输入的十分之一。以后刷新文章时,应重新看当前价格页,而不是沿用旧百分比。
Claude 为什么要把写入和读取分开?
因为 Claude 的缓存模型显式暴露了创建缓存和读取缓存两个动作。第一次把一段前缀写入缓存时会产生写入成本,后续在 TTL 内命中时按读取价格计费。这个设计让你能控制缓存边界,但也要求你把首次写入、重复读取和未命中分开预算。
输出 token 会被缓存折扣影响吗?
不会。Prompt caching 主要作用在重复输入前缀上,输出 token 仍然按模型输出价格计费。输出很长时,输入缓存带来的节省会被输出成本稀释,所以成本表必须把 output tokens 单列出来。
提示词低于 1024 tokens 还会命中吗?
OpenAI 文档把 1024 tokens 作为 prompt caching 的资格阈值;低于这个长度通常不会产生 cached tokens。Claude 的最小缓存 token 数按模型变化,当前文档列出的不同模型有不同阈值。不要把一个模型的阈值写成所有模型的永久规则。
Claude 现在只能手动设置缓存吗?
不准确。Claude 文档现在同时支持自动顶层 cache control 和显式块级 cache control。实际区别在于 Claude 仍然需要你接受它的缓存合约和层级规则;OpenAI 则更偏自动命中 stable prefix。
为什么缓存命中率和账单对不上?
常见原因包括前缀 hash 变化、动态内容放得太靠前、TTL 过期、模型或 endpoint 不一致、Claude 重复写入、OpenAI cached tokens 仍计入 TPM、输出 token 占比过高,以及价格修饰项没有纳入估算。先按日志字段分桶,再查发票。
我应该为了缓存改供应商吗?
只有当缓存前缀足够长、重复频率足够高、输出成本可控、日志能证明命中时,才值得把缓存计费纳入供应商切换。否则先调整提示布局和日志,等有命中率样本后再比较 OpenAI 与 Claude 的真实成本。